 瘋搶!HBM成為AI新瓶頸!
瘋搶!HBM成為AI新瓶頸!
繼英偉達之后,全球科技巨頭實際上正在通過向 SK 海力士索取第五代高帶寬內存 (HBM) HBM3E 樣品來進行預訂。
半導體業內人士7月3日報道稱,全球各大科技巨頭已陸續向SK海力士索取HBM3E樣品。該名單包括 AMD、微軟和亞馬遜。
樣品請求是下訂單之前的強制性流程,旨在證明其 GPU、其他半導體芯片或云系統以及內存半導體之間的兼容性。這表明產品的良率足夠穩定,可以進行量產,標志著交付前的最后階段。HBM3E是當前頂級第四代HBM3的下一代產品。SK海力士是目前全球唯一一家量產HBM3芯片的公司。
SK海力士正忙于處理來自客戶的大量HBM3E樣品請求。英偉達首先要求提供樣品,這次的出貨量幾乎是千鈞一發。這些索取樣品的客戶公司可能會在今年年底收到樣品。全球領先的GPU公司Nvidia此前曾向SK海力士供應HBM3,并已索取HBM3E樣品。各大科技公司都在熱切地等待 SK 海力士的樣品。
隨著HBM3E需求的爆炸性增長,產量顯著增加。SK 海力士決定使用最新的尖端 10 納米級第五代 (1b) 技術大幅提高明年的產量。大部分增量將由 HBM3E 填充。這表明SK海力士正在以HBM為首要業務戰略,全力克服半導體低迷。據悉,SK海力士約40%的營業利潤來自HBM。
所有向 SK 海力士索取 HBM3E 樣品的公司都是人工智能行業的主要參與者。AMD 與 Nvidia 一起引領 GPU 市場。GPU 對于處理大量數據至關重要,是 ChatGPT 等生成型人工智能的大腦。為此,諸如 HBM 之類的高性能、大容量存儲器至關重要。瓜分GPU市場的Nvidia和AMD都已向SK海力士伸出了援手。
AMD最近發布了其下一代GPU MI300X,并表示將從SK海力士和三星電子獲得HBM3供應。此次,似乎是向SK海力士索取了HBM3E樣品,以確定第五代HBM的供應商。MI300X配備的HBM是Nvidia去年底推出的最新旗艦GPU H100的2.4倍。
亞馬遜和微軟是云服務領域的兩大巨頭。他們的市場份額加起來超過了50%。作為生存策略,云服務公司優先引入生成式AI技術,并大幅增加投資。亞馬遜旗下運營的全球第一云服務提供商(CSP)亞馬遜網絡服務近期投資1億美元建立人工智能創新中心。與此同時,微軟的Azure云服務正在擴大與ChatGPT開發商OpenAI的合作關系。
市場研究公司TrendForce表示:“亞馬遜網絡服務和谷歌等主要云服務公司正在開發自己的專用集成電路(ASIC)和配備Nvidia GPU的AI服務器,是當前HBM激增的推動力要求。”
以DRAM 4月的指標性產品DDR4 8Gb為例,批發價為每個1.48美元左右,環比下跌1%;4Gb產品價格為每個1.1美元左右,環比下跌8%。
在DRAM的整體頹勢之中,HBM(高帶寬內存,High Bandwidth Memory)卻在逆勢增長。身為DRAM的一種,與大部隊背道而馳,價格一路水漲船高。據媒體報道,2023年開年后三星、SK海力士兩家存儲大廠HBM訂單快速增加,HBM3規格DRAM價格上漲5倍。HBM3原本價格大約30美元每GB,現在的價格怕是更加驚人。
一邊是總體DRAM跌到成本價,一邊是“尖子生”HBM價格漲5倍。
6 月 18 日據 businesskorea 以及 etnews 報道,SK 海力士將擴展其 HBM3 后道工藝生產線,并已收到英偉達要求其送測 HBM3E 樣品的請求
據稱,考慮到對人工智能 (AI) 半導體的需求增加,S 海力士正在考慮將 HBM 的產能翻倍的計劃。
業內消息稱 SK 海力士于 6 月 14 日收到了 NVIDIA 對 HBM3E 樣品的請求,并正在準備發貨。HBM3E 是當前可用的最高規格 DRAM HBM3 的下一代,被譽為是第五代半導體產品。
SK 海力士目前正致力于開發該產品,目標是在明年上半年實現量產。SK 海力士副總裁樸明秀在今年 4 月的第一季度收益公告電話會議上透露:“我們正在為今年下半年準備 8Gbps HBM3E 產品樣品,并計劃在明年上半年實現量產。”
半導體產業聯盟查詢發現,目前 SK 海力士在 HBM 市場已經領先于三星電子。據市場研究公司 TrendForce 稱,截至去年,SK 海力士在全球 HBM 市場上占據 50% 的市場份額,而三星電子則保持在 40% 左右。
去年 6 月,SK 海力士成為世界上第一個大規模生產高性能 HBM3 的公司,從而一舉奠定其市場領導地位。在通過 HBM3 樣品的嚴格性能評估后,成功滿足了高端客戶的需求,目前已經在為 NVIDIA H100 供應。
如果他們成功交付第五代 HBM 產品,將進一步鞏固他們在超快速 AI 半導體市場上的領先地位。
HBM的優勢
直接地說,HBM將會讓服務器的計算能力得到提升。由于短時間內處理大量數據,AI服務器對帶寬提出了更高的要求。HBM的作用類似于數據的“中轉站”,就是將使用的每一幀、每一幅圖像等圖像數據保存到幀緩存區中,等待GPU調用。與傳統內存技術相比,HBM具有更高帶寬、更多I/O數量、更低功耗、更小尺寸,能夠讓AI服務器在數據處理量和傳輸速率有大幅提升。
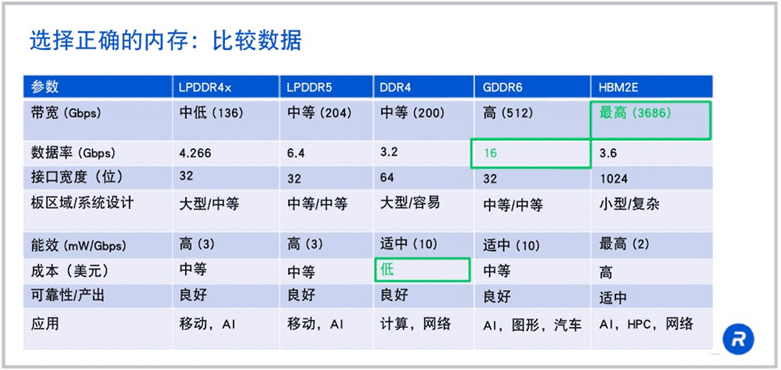
來源:rambus
可以看到HBM在帶寬方面有著“碾壓”級的優勢。如果 HBM2E 在 1024 位寬接口上以 3.6Gbps 的速度運行,那么就可以得到每秒 3.7Tb 的帶寬,這是 LPDDR5 或 DDR4 帶寬的 18 倍以上。
除了帶寬優勢,HBM可以節省面積,進而在系統中安裝更多GPU。HBM 內存由與 GPU 位于同一物理封裝上的內存堆棧組成。
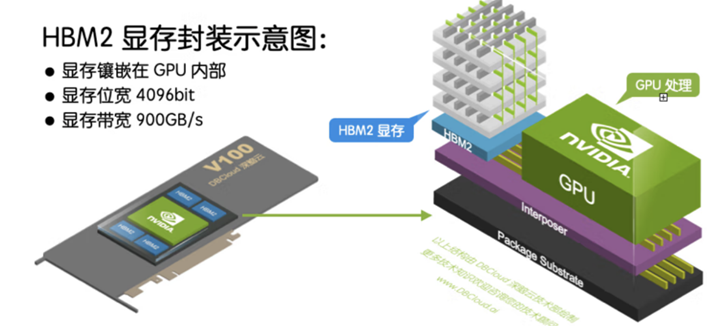
這樣的架構意味著與傳統的 GDDR5/6 內存設計相比,可節省大量功耗和面積,從而允許系統中安裝更多 GPU。隨著 HPC、AI 和數據分析數據集的規模不斷增長,計算問題變得越來越復雜,GPU 內存容量和帶寬也越來越大是一種必需品。H100 SXM5 GPU 通過支持 80 GB(五個堆棧)快速 HBM3 內存,提供超過 3 TB/秒的內存帶寬,是 A100 內存帶寬的 2 倍。
過去對于HBM來說,價格是一個限制因素。但現在大模型市場上正處于百家爭鳴時期,對于布局大模型的巨頭們來說時間就是金錢,因此“貴有貴的道理”的HBM成為了大模型巨頭的新寵。隨著高端GPU需求的逐步提升,HBM開始成為AI服務器的標配。
目前英偉達的A100及H100,各搭載達80GB的HBM2e及HBM3,在其最新整合CPU及GPU的Grace Hopper芯片中,單顆芯片HBM搭載容量再提升20%,達96GB。
AMD的MI300也搭配HBM3,其中,MI300A容量與前一代相同為128GB,更高端MI300X則達192GB,提升了50%。
預期Google將于2023年下半年積極擴大與Broadcom合作開發AISC AI加速芯片TPU也計劃搭載HBM存儲器,以擴建AI基礎設施。
-
芯片
+關注
關注
453文章
50406瀏覽量
421819 -
DRAM
+關注
關注
40文章
2303瀏覽量
183314 -
SK海力士
+關注
關注
0文章
948瀏覽量
38432
原文標題:瘋搶!HBM成為AI新瓶頸!
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HBM4到來前夕,HBM熱出現兩極分化
HBM3E量產后,第六代HBM4要來了!

AI時代核心存力HBM(上)
被稱為“小號HBM”,華邦電子CUBE進階邊緣AI存儲
中國AI芯片和HBM市場的未來
美光調整2024年資本支出預測,加強AI產業HBM投資力度
HBM:突破AI算力內存瓶頸,技術迭代引領高性能存儲新紀元

從兩會看AI產業飛躍,HBM需求預示存儲芯片新機遇

工業油污清洗的香餑餑:超聲波清洗機遭市場瘋搶!

HBM、HBM2、HBM3和HBM3e技術對比

深度解析HBM內存技術

HBM搶單大戰,才剛剛拉開帷幕

大模型時代必備存儲之HBM進入汽車領域

HBM4為何備受存儲行業關注?





 工商網監
工商網監
評論