 LinkedIn圖數據庫 LIquid:為9.3億會員提供實時數據訪問
LinkedIn圖數據庫 LIquid:為9.3億會員提供實時數據訪問
最近,LinkedIn 分享了其圖數據庫 LIquid 是如何自動索引和實時訪問會員、學校、技能、公司、職位、工作、事件等之間的關系數據的。這個知識圖譜被稱為 LinkedIn 的“Economic Graph”,有 2700 億條邊,并且還在不斷增長,目前每秒處理 200 萬次查詢。
LinkedIn 將其“你可能認識的人(People You May Know,PYMK)”推薦系統從傳統的 GAIA 系統遷移到了 LIquid。這一變化顯著改善了每秒查詢數(QPS)、延遲和 CPU 利用率。QPS 從 120 增加到 18000,延遲從超過 15 秒下降到平均 50 毫秒以下,CPU 利用率下降了 3 倍以上。LIquid 還引入了新的數據庫索引技術,支持實時數據查詢,實現了即時推薦。
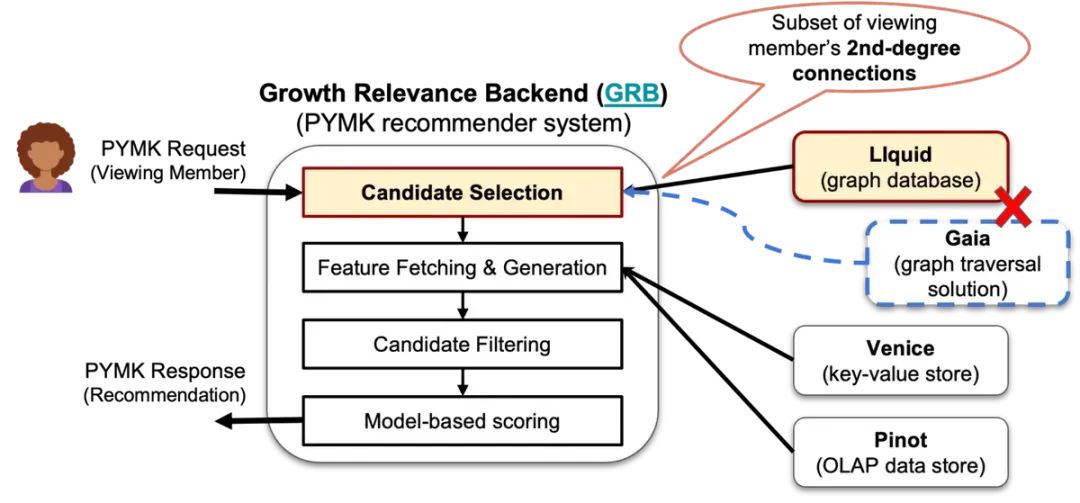
圖片來源:https://engineering.linkedin.com/blog/2023/how-liquid-connects-everything-so-our-members-can-do-anything
上圖是系統的架構圖,使用了 LIquid,可以以較小的延遲和可接受的硬件成本來執行圖查詢。通過 LIquid 對 Economic Graph 的查詢生成數百個候選對象,并應用第二個排名函數。這個排名函數使用 Venice 的機器學習功能和 Apache Pinot 的分析見解來評分并選擇最佳候選對象。過濾步驟為呈現和最終評分準備好了這個排名列表。
LIquid 的設計使其能夠伸縮到當前十倍的規模,可以支持 LinkedIn 9.3 億多會員的有機增長和新的語義領域。它提供 99.99% 的可用性,并可以自動根據圖的大小和活動量的增加進行自動伸縮。
圖數據庫使用基于 Datalog 的可組合聲明式查詢語言,幫助開發人員高效地訪問和使用數據。可組合語言能夠讓開發人員在現有的特性(叫作模塊)上進行構建,聲明式語言能夠讓開發人員專注于表達他們想要開發的東西,而 LIquid 自動化了高效的訪問過程。開發人員因此可以快速變更數據集,大大減少了調整和更新數據庫所需的時間。
LinkedIn 工程總監 Bogdan Artintescu 描述了 LIquid 的發展路線圖:
要讓會員能夠做更多的事情,我們需要在回答會員的問題方面提供更加完善的能力。我們可以沿著兩個方向做出改進。首先,復雜的查詢和添加到 Economic Graph 的數據源的多樣性將會驅動新特性的開發和呈現。其次,豐富數據將提高推理能力。這可以通過創建派生數據(通過確定性算法或概率機器學習方法)或通過知識圖譜(KG)模式中更豐富的語義改進推理來實現。我們計劃專注于高性能圖形計算和分析,并建立一個 KG 生態系統,讓我們的開發人員能夠進一步增強會員體驗。
LIquid 的成功激勵了 LinkedIn 的其他團隊和微軟的姐妹團隊將它作為圖數據索引。
-
數據庫
+關注
關注
7文章
3767瀏覽量
64279 -
機器學習
+關注
關注
66文章
8381瀏覽量
132428 -
數據集
+關注
關注
4文章
1205瀏覽量
24648
原文標題:LinkedIn 圖數據庫 LIquid:為 9.3 億會員提供實時數據訪問
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

實時數據與數字孿生的關系
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

數據庫數據恢復—SqlServer數據庫底層File Record被截斷為0的數據恢復案例
態勢數據如何存儲在數據庫里面呢
【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例
應用方案:實時數據加密
虹科干貨丨無模式數據庫的利與弊
無模式數據庫的利與弊

數據庫數據恢復—未開啟binlog的Mysql數據庫數據恢復案例
常見的存儲Idea數據庫的地方
關于JSON數據庫

聊聊日志即數據庫
oracle數據庫中間件有哪些
什么是JSON數據庫





 工商網監
工商網監
評論