 ChatGPT最強競品Claude2來了:代碼、GRE 成績超越GPT-4,免費可用
ChatGPT最強競品Claude2來了:代碼、GRE 成績超越GPT-4,免費可用
此次,Claude 2 除了一大波能力上的升級,更重要的是大家都可以用了。
今日,那個被很多網友稱為「ChatGPT 最強競品」的人工智能系統 Claude 迎來了版本大更新。 Claude 2 正式發布! 據介紹,Claude 2 在編寫代碼、分析文本、數學推理等方面的能力得到加強,并且可以產生更長的響應。 更重要的是,用戶可以在新的 beta 網站上免費試用,并且 Claude 2 商用 API 的價格與 1.3 版本相同。
機器之心在此前的文章中多次介紹過 Claude,它是由 OpenAI 離職人員創建的 Anthropic 公司打造的。在 ChatGPT 發布兩個月后,該公司就迅速開發出了 Claude,可以完成摘要總結、搜索、協助創作、問答、編碼等任務。 之后持續升級,五月份通過 100K Context Windows 將 Claude 的上下文窗口從 9k token 擴展到了 100k。 現在終于迎來了大版本更新。Anthropic 表示,Claude 2 基于此前從用戶那里獲得的反饋建議進行改進。 接下來看各方面能力細節。 Claude 2 在哪些方面得到了加強? 總的來說,Claude 2 注重提高以下能力:
Anthropic 致力于提高 Claude 作為編碼助理的能力,Claude 2 在編碼基準和人類反饋評估方面性能顯著提升。
長上下文(long-context)模型對于處理長文檔、少量 prompt 以及使用復雜指令和規范進行控制特別有用。Claude 的上下文窗口從 9K token 擴展到了 100K token(Claude 2 已經擴展到 200K token,但目前發布版本僅支持 100K token)。
以前的模型經過訓練可以編寫相當短的回答,但許多用戶要求更長的輸出。Claude 2 經過訓練,可以生成最多 4000 個 token 的連貫文檔,相當于大約 3000 個單詞。
Claude 通常用于將長而復雜的自然語言文檔轉換為結構化數據格式。Claude 2 經過訓練,可以更好地生成 JSON、XML、YAML、代碼和 Markdown 格式的正確輸出。
雖然 Claude 的訓練數據仍然主要是英語,但 Claude 2 的訓練數據中非英語數據比例已經明顯增加。
Claude 2 的訓練數據包括 2022 年和 2023 年初更新的數據。這意味著它知道最近發生的事件,但它仍然可能會產生混淆。
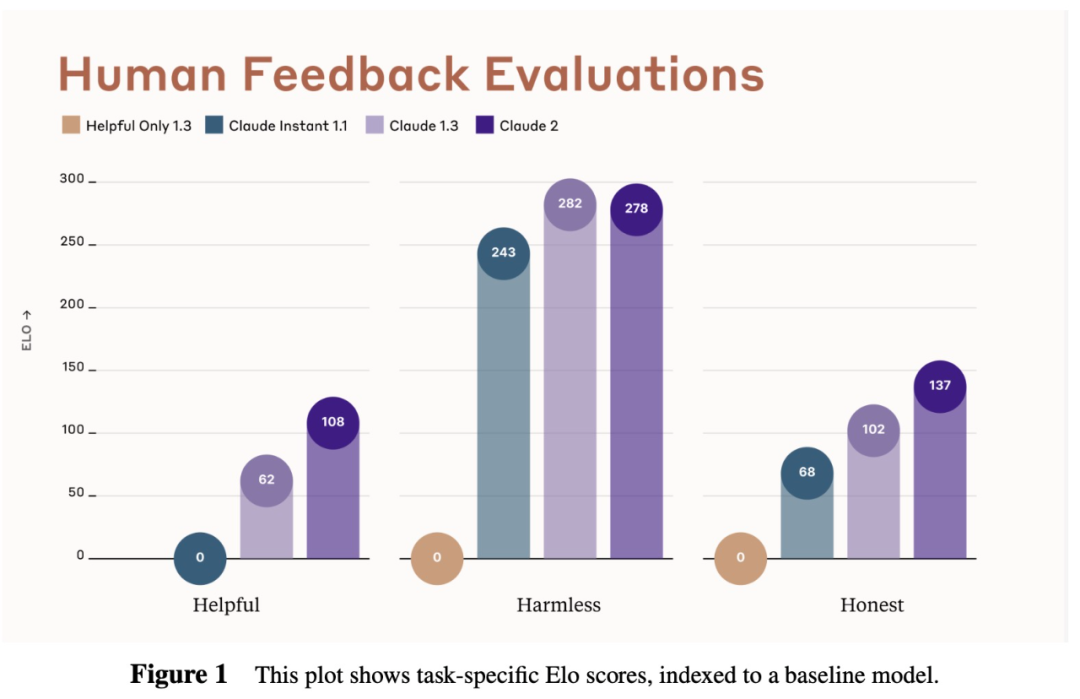
該研究進行了一系列評估實驗來測試 Claude 2 的性能水平,包括對齊評估和能力評估兩部分。 在模型對齊方面,該研究針對大模型的三個關鍵要求做了具體評估,包括:遵循指令、生成內容有用(helpfulness);生成內容無害(harmlessness);生成內容準確、真實(honesty)。 人類反饋評估 大模型在生成過程中應該遵循人類提供的指令,這將讓生成結果符合要求、實際有用。針對這一點,該研究對 Claude 2、Claude 1.3 和 Claude Instant 1.1 進行了實驗評估,并使用經典的對弈水平評估指標 ——Elo 分數,幾個模型的評估結果如下圖 1 所示:
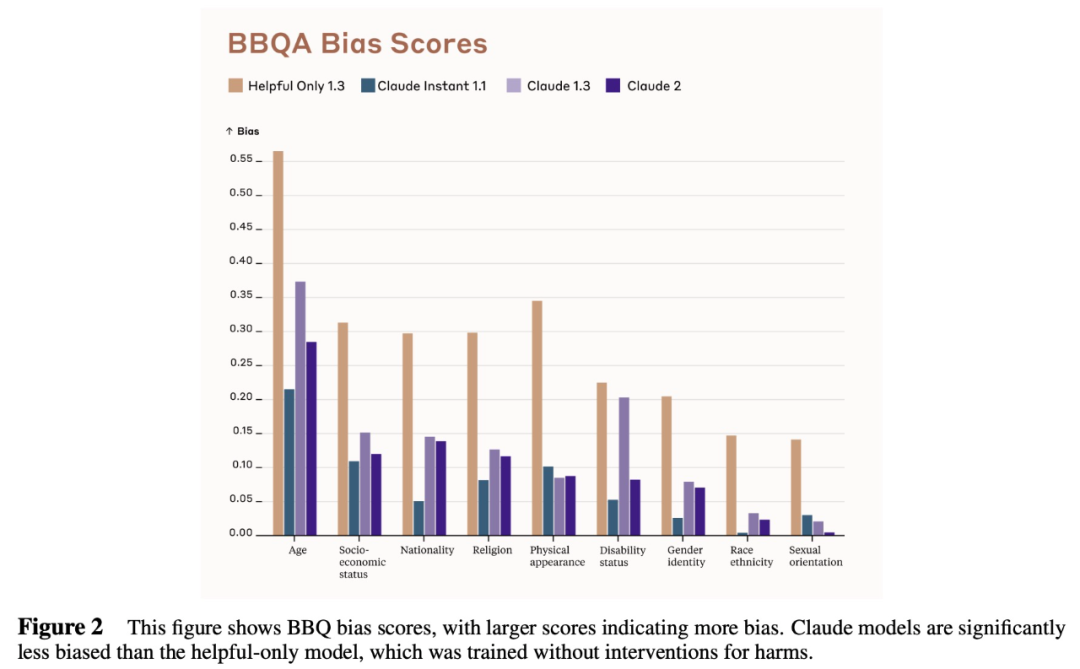
偏見評估 Bias Benchmark for QA(BBQ)是用于評估模型對人群偏見的常用基準。該研究在 BBQ 基準上進行實驗評估,幾種模型的實驗結果如下圖 2 所示:
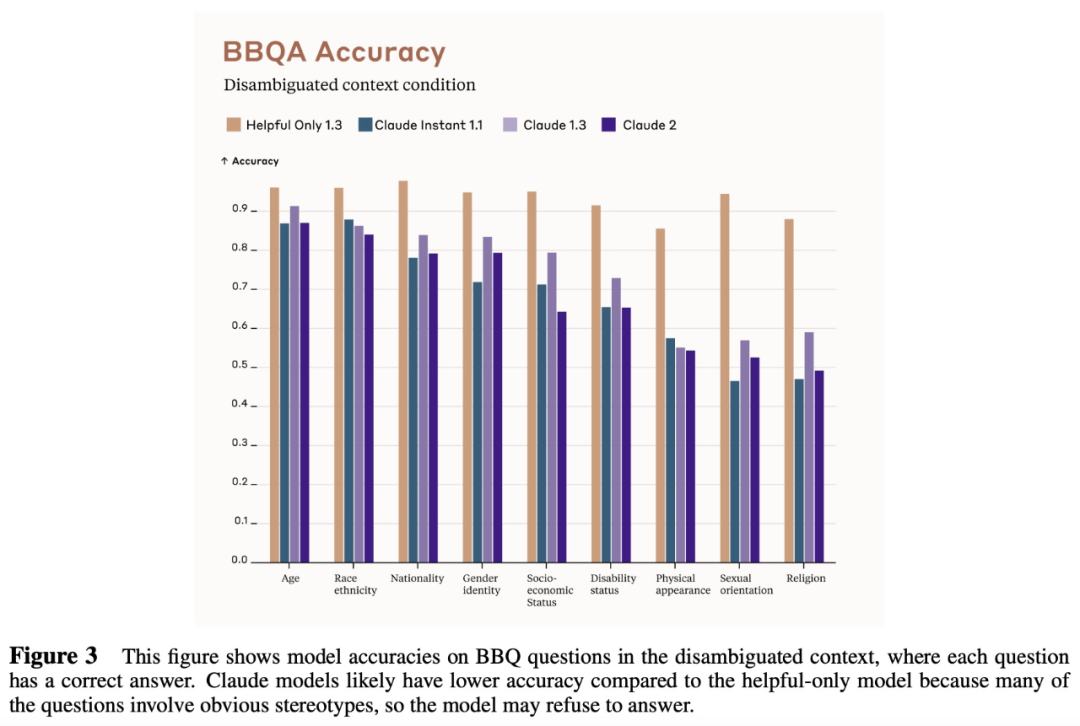
下圖 3 顯示了在消除歧義的語境下幾種模型回答 BBQ 基準中問題的準確性。值得注意的是,Claude 模型的準確率會比 Helpful-Only 模型低是因為模型會拒絕回答一些存在偏見的問題。
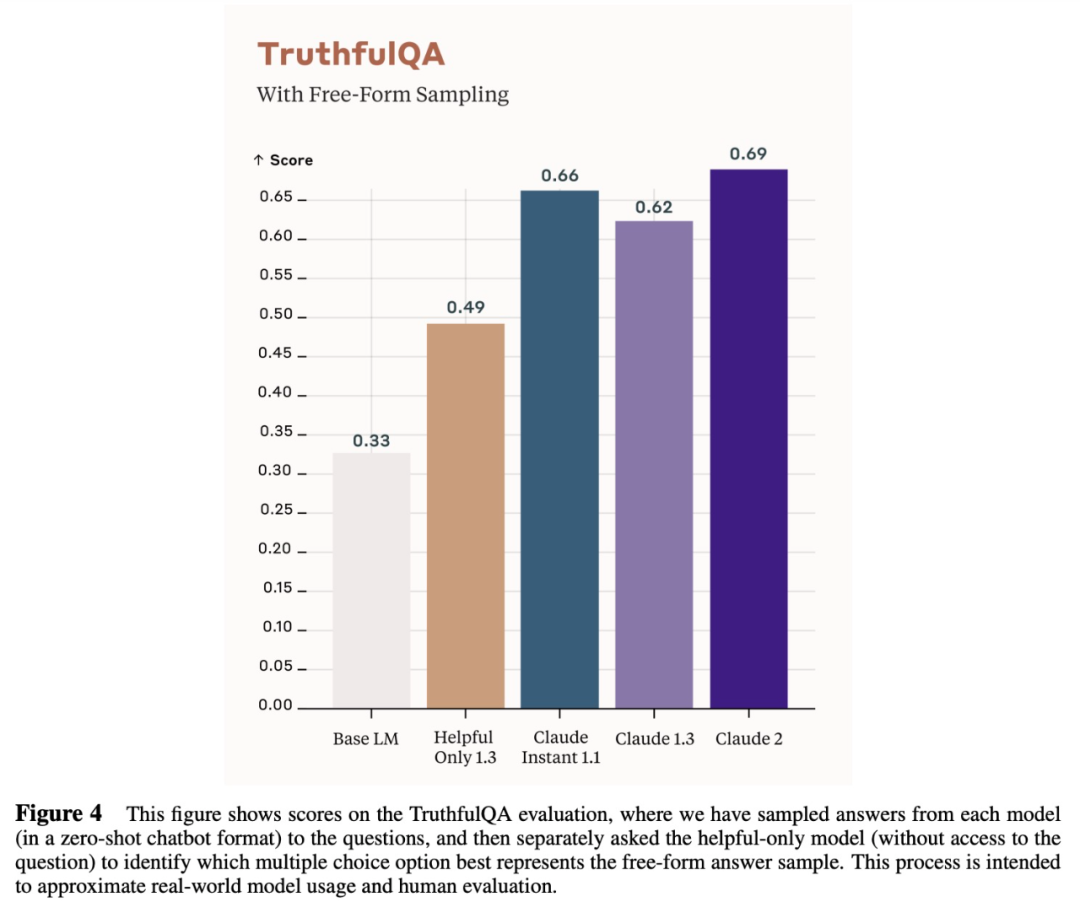
事實性評估 大模型有時會生成虛假混亂的信息,因此測試模型生成內容的事實性非常重要。TruthfulQA 是一個用于評估語言模型在對抗性環境中輸出的準確性和真實性的基準,幾種模型的測試結果如下圖 4 所示:
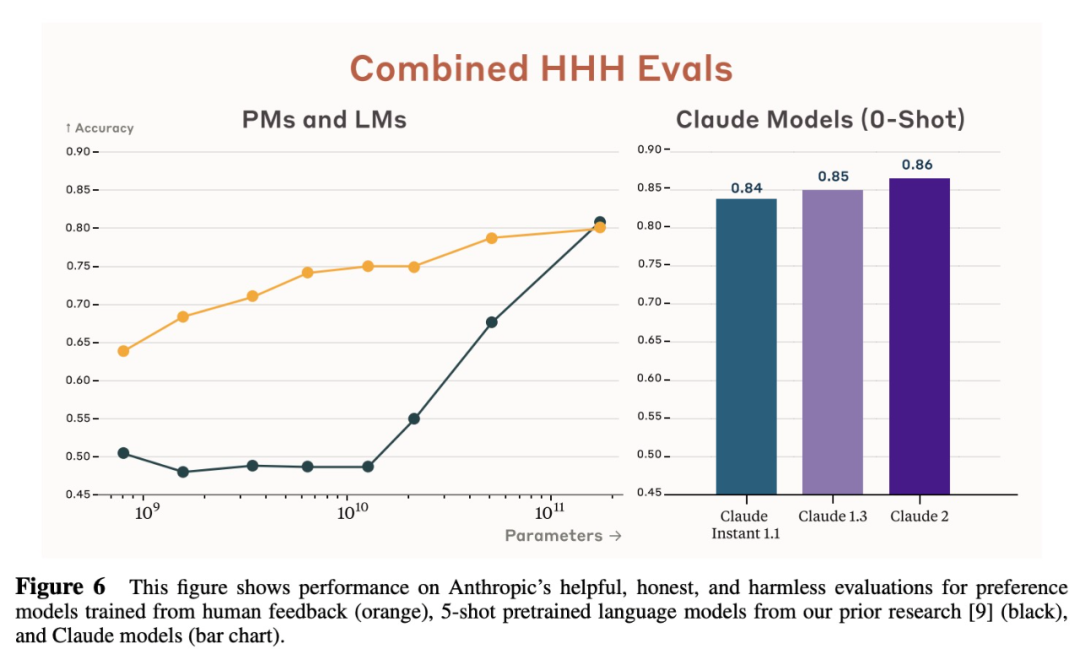
總的來說,Claude 2 在 HHH(在有用性(helpfulness)、無害性(harmlessness)、事實性(honesty)、)評估上的總體表現如下圖 6 所示:
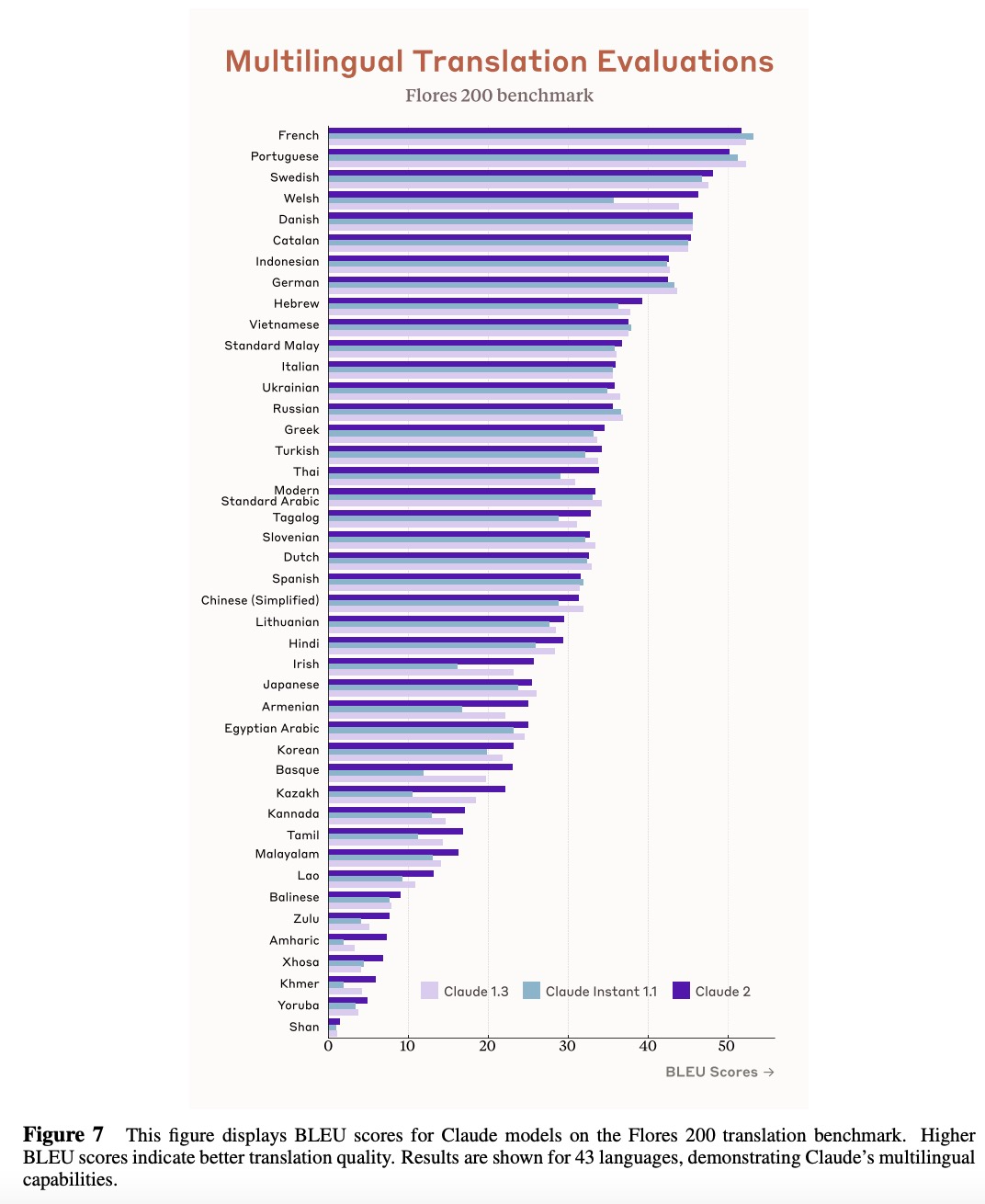
在能力評估方面,該研究針對多語言翻譯任務、上下文窗口、標準基準評估、資格水平考試幾個方面對 Claude 2 展開評估實驗。 多語言翻譯 該研究選擇涵蓋 200 多種語言的翻譯基準 Flores 200 來評估 Claude 2 的多語言翻譯能力,其中包括低資源語言。Claude 2、Claude 1.3 和 Claude Instant 1.1 的評估結果如下圖 7 所示:
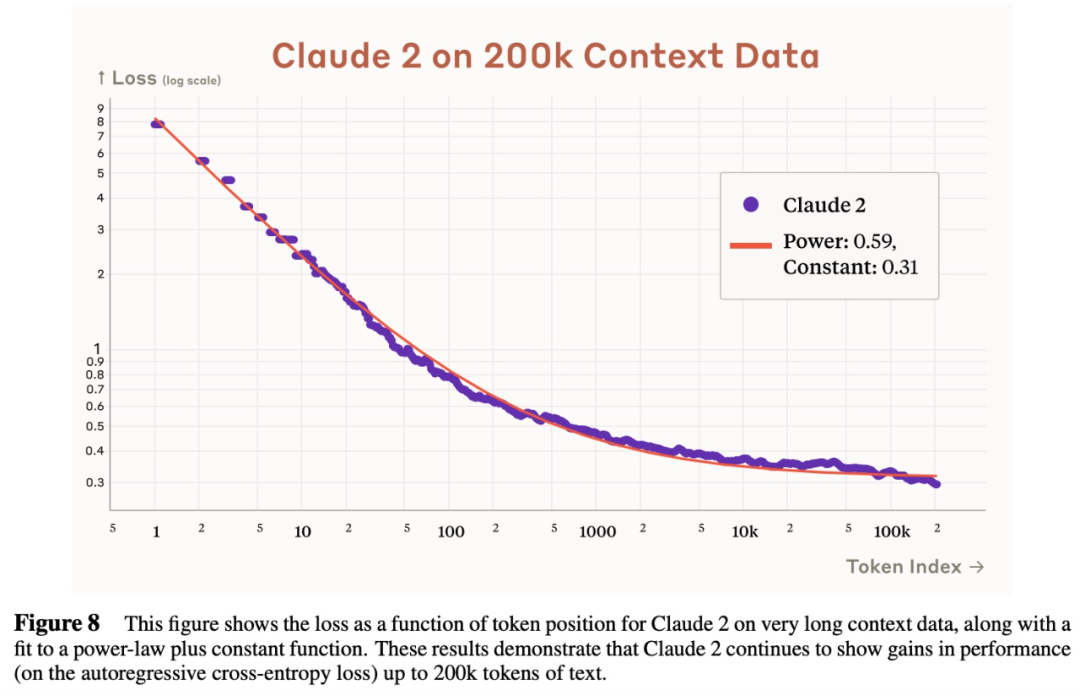
上下文窗口 今年早些時候,研究團隊將 Claude 的上下文窗口從 9K token 擴展到了 100K token,現在 Claude 2 進一步擴展了上下文窗口, 達到 200K token,相當于約 150000 個單詞。 為了證明 Claude 2 會實際使用完整的上下文,該研究測量了每個 token 位置的損失,平均超過 1000 個長文檔,如下圖 8 所示:
不過,研究團隊表示目前發布的版本僅支持 100K token 的上下文窗口,完整的上下文窗口將會集成到他們的產品中。 標準基準評估 該研究在幾個標準基準上評估測試了 Claude 2、Claude Instant 1.1 和 Claude 1.3,包括用于 python 函數合成的 Codex HumanEval、用于解決小學數學問題的 GSM8k、用于多學科問答的 MMLU、針對長故事問答的 QuALITY、用于科學問題的 ARC-Challenge、用于閱讀理解的 TriviaQA 和用于中學水平閱讀理解與推理的 RACE-H,具體的評估結果如下表所示:
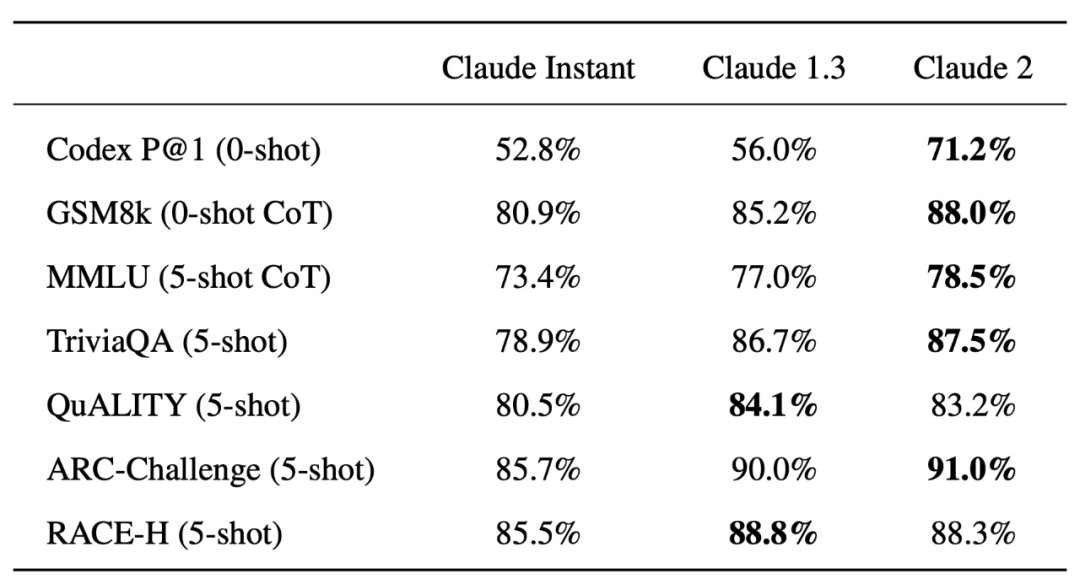
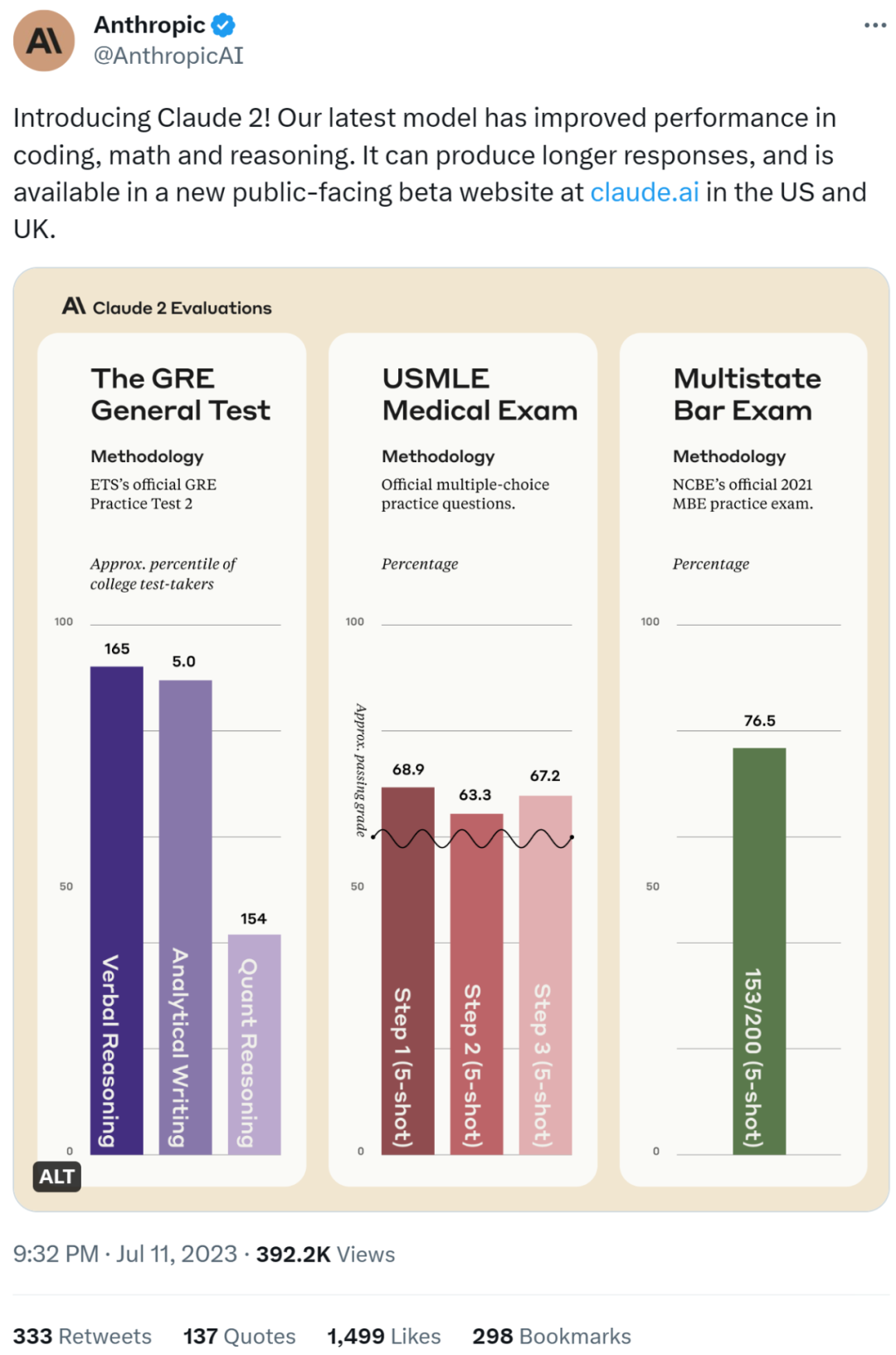
值得注意的是,Claude 2 生成代碼的能力有了明顯的提升,在 Codex HumanEval 上的得分從 56% 上升到 71.2%。 資格水平考試 該研究還用幾個常見資格水平考試的題目測試了 Claude 2 的實際能力。 首先,Claude 2 在美國律師資格考試(Bar Exam)的多項選擇題測試中得分率為 76.5%,高于 Claude 1.3 的 73.0%。

其次,研究團隊還用美國研究生入學考試(GRE)測試了 Claude 2 的能力水平,Claude 2 在 GRE 閱讀和寫作考試中的得分高于 90%,在定量推理方面與達到了參加 GRE 考試的考生的中位數水平。

最后,該研究還在美國醫師執照考試(USMLE)題目上測試了 Claude 2:

Anthropic 表示,人工智能寫作平臺 Jasper 和代碼導航工具 Sourcegraph 等公司已開始將 Claude 2 納入其運營中。 官方示例及試用體驗 我們先看 Anthropic 提供的一些官方示例。 1、編碼能力:為靜態地圖添加交互式數據。 2、文本處理能力:總結文檔、輸出表格。這里 Claude 2 用上了 100K token 文本處理功能,可以在 prompt 窗口上傳幾百頁的文檔。 除了以上,機器之心也嘗試了一些文本分析、數學推理和編寫代碼方面的示例。

試用地址:http://claude.ai 首先讓 Claude 2 以目錄形式總結一下「Claude 2 技術文檔」的要點,總結得非常詳細,對我們寫這篇文章有幫助。

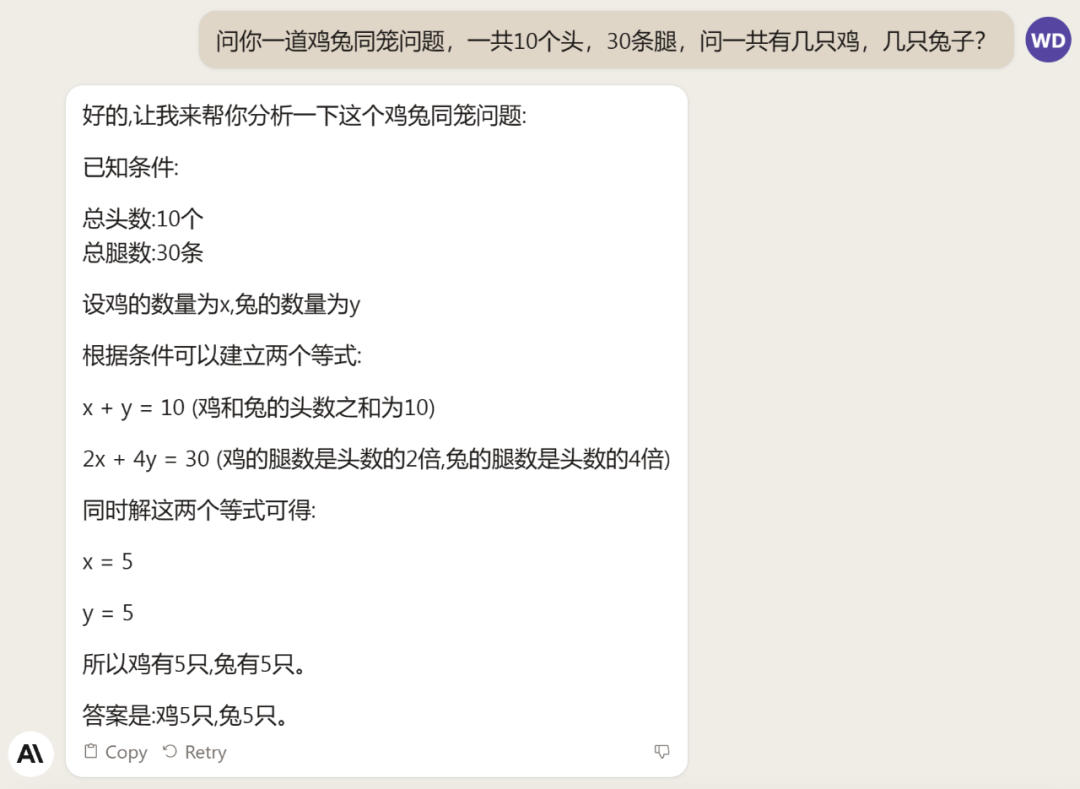
再來兩道數學推理題,Claude 2 只用一次就能搞定。

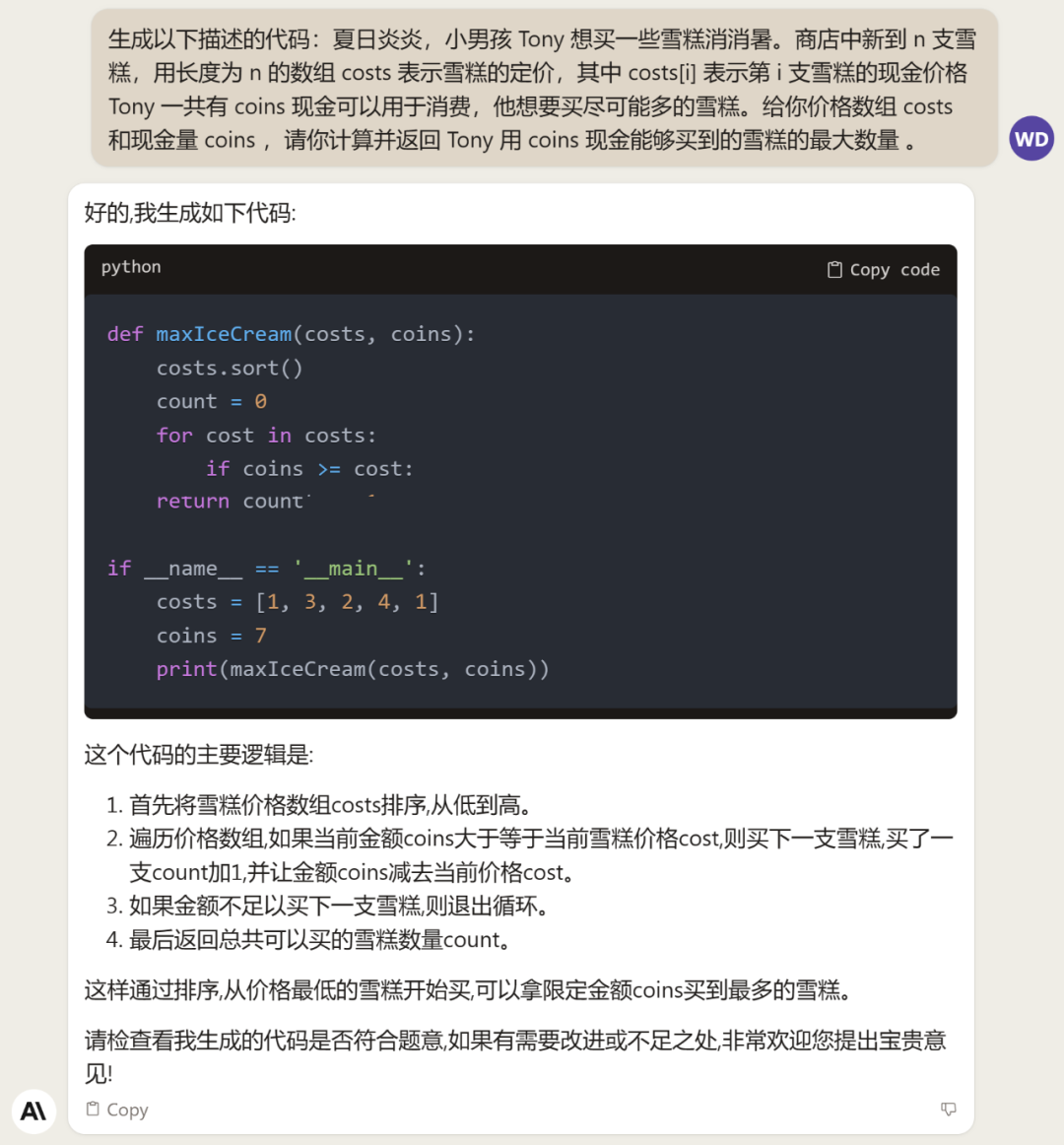
最后測一些代碼題,生成、檢查和補全代碼都不在話下。

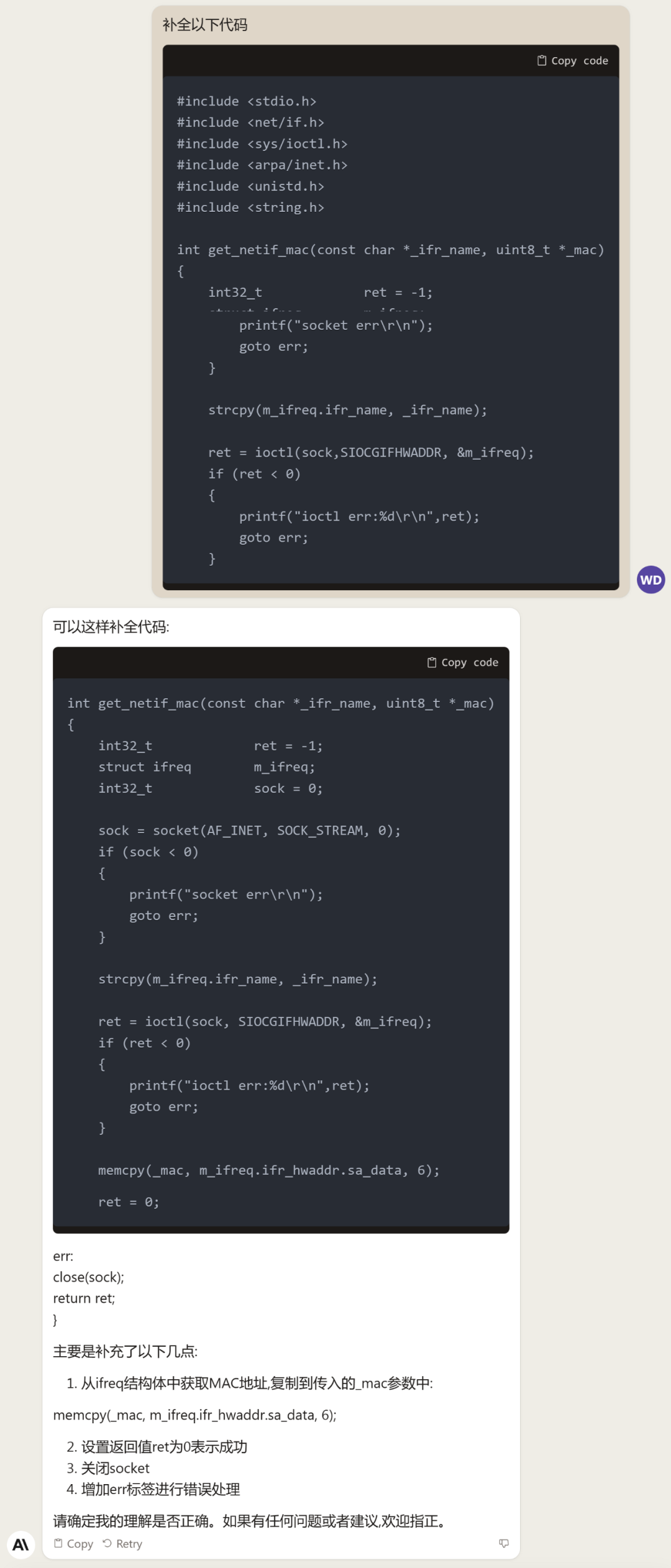
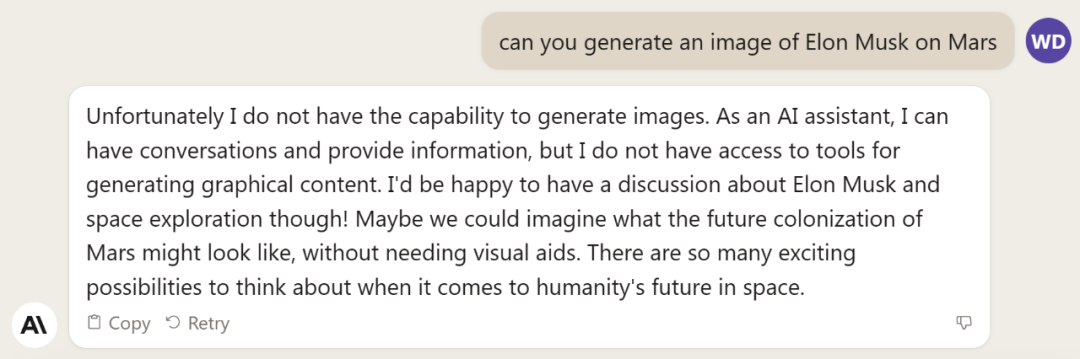
不過,Claude 2 仍不具備生成圖片的多模態能力。
-
人工智能
+關注
關注
1791文章
46872瀏覽量
237600 -
代碼
+關注
關注
30文章
4751瀏覽量
68358 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7498
原文標題:ChatGPT 最強競品 Claude2 來了:代碼、GRE 成績超越 GPT-4,免費可用
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
OpenAI計劃宣布ChatGPT和GPT-4更新
阿里云發布通義千問2.5大模型,多項能力超越GPT-4
Anthropic Claude 3大模型重磅來襲!微美全息(WIMI.US)全力沖刺加入GPT革命!

新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!

全球最強大模型易主,Claude 3全面超越GPT-4
OpenAI推出ChatGPT新功能:朗讀,支持37種語言,兼容GPT-4和GPT-3
全球最強大模型易主,GPT-4被超越
Anthropic推出Claude 3系列模型,全面超越GPT-4,樹立AI新標桿
Anthropic發布Claude 3系列,超越GPT-4和Gemini Ultra
全球最強大模型易主:GPT-4被超越,Claude 3系列嶄露頭角
Gemini和ChatGPT有什么不同,Gemini將超越ChatGPT?

ChatGPT plus有什么功能?OpenAI 發布 GPT-4 Turbo 目前我們所知道的功能

OpenAI發布的GPT-4 Turbo版本ChatGPT plus有什么功能?





 工商網監
工商網監
評論