") 【AI簡報(bào)20230714期】人工智能在日常生活中的應(yīng)用,國產(chǎn)AI芯片最新進(jìn)展公布!
【AI簡報(bào)20230714期】人工智能在日常生活中的應(yīng)用,國產(chǎn)AI芯片最新進(jìn)展公布!
1. 大模型時(shí)代,國產(chǎn)AI芯片最新進(jìn)展!算力集群化是必然趨勢
原文:https://mp.weixin.qq.com/s/k-InpBMMJTUltuMcB2hKSg在剛過去的2023世界人工智能大會(huì)上,大模型可以說是其中的大亮點(diǎn)之一,華為盤古、商湯日日新、網(wǎng)易伏羲等30多款國產(chǎn)AI大模型集中亮相。與此同時(shí),各類人工智能芯片公司、算力提供商也針對(duì)大模型展示了相應(yīng)的方案。大模型時(shí)代,國產(chǎn)AI芯片進(jìn)展如何?在這次大會(huì)上,瀚博半導(dǎo)體、燧原科技、登臨科技、天數(shù)智芯等紛紛展示了針對(duì)大模型的產(chǎn)品方案,呈現(xiàn)出國產(chǎn)AI芯片在大模型領(lǐng)域的進(jìn)展情況。瀚博半導(dǎo)體成立于2018年12月,是一家自研GPU芯片及解決方案提供商。在此次大會(huì)上,瀚博發(fā)布了第二代GPU SG100,并推出南禺系列GPU加速卡VG1600、VG1800、VG14,以及LLM大模型AI加速卡VA1L、AIGC大模型一體機(jī)、VA12高性能生成式AI加速卡等6款新品。據(jù)介紹,瀚博SG100芯片采用7nm先進(jìn)制程,具備業(yè)界領(lǐng)先的渲染性能,同時(shí)兼具低延時(shí)高吞吐的AI算力和強(qiáng)大的視頻處理能力。值得關(guān)注的,針對(duì)大模型時(shí)代算力需求,瀚博本次首發(fā)了LLM大模型AI加速卡VA1L,具備200 TOPS INT8/72 TFLOPS FP16算力,并支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC網(wǎng)絡(luò)模型。與此同時(shí),瀚博此次還推出了AIGC大模型一體機(jī),共使用8張LLM大模型AI加速卡VA1L,支持512GB顯存,進(jìn)而支持1750億參數(shù)的大模型。另外,作為瀚博VA1和VA10的升級(jí)版,VA12是一塊通用AI加速卡,支持檢測、分類、分割、視頻增強(qiáng)、語義理解、BERT、Transfomer和視頻編解碼等應(yīng)用。燧原科技在此次大會(huì)上發(fā)布了燧原曜圖文生圖MaaS平臺(tái)服務(wù)產(chǎn)品。該產(chǎn)品以燧原科技“邃思”系列芯片為算力支撐,由首都在線提供計(jì)算服務(wù),燧原曜圖MaaS平臺(tái)服務(wù)產(chǎn)品為用戶提供面向AIGC時(shí)代的高效易用、安全可靠、企業(yè)級(jí)的文生圖服務(wù)。燧原科技表示,它具備開箱即用可用、所想即所見、創(chuàng)意無限的文本生成圖像能力,通過軟硬一體方案降低大規(guī)模AIGC應(yīng)用的工程難度與算力成本,開啟AIGC應(yīng)用規(guī)模化落地時(shí)代。燧原科技創(chuàng)始人兼CEO趙立東在某論壇上提到,目前燧原已經(jīng)為大型科研機(jī)構(gòu)部署了千卡規(guī)模的AI訓(xùn)練算力集群,并成功落地;而且與騰訊合作,在OCR文字識(shí)別、智能交互、智能會(huì)議等方面,性能達(dá)到了業(yè)界同類產(chǎn)品兩倍以上,性價(jià)比上具有很高優(yōu)勢。此外,在智慧城市方面,燧原完成2022年成都高新區(qū)國產(chǎn)化AI視頻基礎(chǔ)設(shè)施平臺(tái)項(xiàng)目建設(shè)。此次大會(huì)上,登臨科技展示了最新一代創(chuàng)新通用GPU產(chǎn)品Goldwasser II系列以及基于開源大語言模型可交互界面。據(jù)了解,Goldwasser II針對(duì)基于Transformer和生成式AI 大模型進(jìn)行專門優(yōu)化,在性能有大幅提升,已于2022年流片,目前已開始規(guī)模化量產(chǎn)和商業(yè)客戶驗(yàn)證。據(jù)現(xiàn)有客戶測試結(jié)果,二代產(chǎn)品針對(duì)基于transformer類型的模型提供3-5倍的性能提升,大幅降低類ChatGPT及生成式AI應(yīng)用的硬件成本。天數(shù)智芯在此次會(huì)上也展示了在大模型訓(xùn)練、推理所取得的顯著進(jìn)展,包括圖片識(shí)別/以圖搜圖、3D建模、大模型推理等。在大模型領(lǐng)域,天數(shù)智芯今年上半年,搭建了40P算力320張?zhí)燠?00加速卡算力集群,完成智源研究院70億參數(shù)大模型全量訓(xùn)練,天垓100是天數(shù)智芯2018年研發(fā)的通用AI訓(xùn)練芯片,據(jù)天數(shù)智芯董事長蓋魯江介紹,目前天垓100這款產(chǎn)品還已經(jīng)成功跑通了清華智譜 AI 大模型ChatGLM,Meta研發(fā)的LLaMA模型。此外,天數(shù)智芯正在幫智源研究院跑650億參數(shù)的模型,預(yù)計(jì)10月份可以跑完。針對(duì)于A800芯片在無許可證的情況下將被禁售的話題,蓋魯江談到,事實(shí)上,不管英偉達(dá)的產(chǎn)品能不能賣給中國,我們的產(chǎn)品已經(jīng)能夠用起來了。算力集群化是發(fā)展趨勢伴隨大模型帶來的生成式AI突破,人工智能正在進(jìn)入一個(gè)新的時(shí)代。算力是人工智能產(chǎn)業(yè)創(chuàng)新的基礎(chǔ),大模型的持續(xù)創(chuàng)新,驅(qū)動(dòng)算力需求的爆炸式增長。可以說,大模型訓(xùn)練的效率或者是創(chuàng)新的速度,根本上取決于算力的大小。然而,中國的算力已經(jīng)成為一個(gè)越來越稀缺的資源。華為輪值董事長胡厚崑在某論壇上談到,大模型的研發(fā)高度依賴高端AI芯片、集群及生態(tài)。高計(jì)算性能、高通信帶寬和大顯存成為大模型訓(xùn)練必不可少的算力底座,單AI芯片進(jìn)步速度還未跟上大模型對(duì)大算力的需求,算力集群化成為不可逆轉(zhuǎn)的發(fā)展趨勢。在2023世界人工智能大會(huì)上,華為宣布昇騰AI集群全面升級(jí),集群規(guī)模從最初的4000卡集群擴(kuò)展至16000卡,擁有更快的訓(xùn)練速度和30天以上的穩(wěn)定訓(xùn)練周期。胡厚崑表示,華為在各個(gè)單點(diǎn)創(chuàng)新的基礎(chǔ)上,充分發(fā)揮云、計(jì)算、存儲(chǔ)、網(wǎng)絡(luò)以及能源的綜合優(yōu)勢,進(jìn)行架構(gòu)創(chuàng)新,推出了昇騰AI集群,相當(dāng)于把AI算力中心當(dāng)成一臺(tái)超級(jí)計(jì)算機(jī)來設(shè)計(jì),使得昇騰AI集群性能更高,并且可靠性更高。據(jù)他介紹,昇騰AI集群目前已經(jīng)可以達(dá)到10%以上的大模型訓(xùn)練效率的提升,可以提供10倍以上的系統(tǒng)穩(wěn)定的提高,支持長期穩(wěn)定訓(xùn)練。華為昇騰計(jì)算業(yè)務(wù)總裁張迪煊表示,基于昇騰AI,原生孵化和適配了30多個(gè)大模型,到目前為止,中國有一半左右的大模型創(chuàng)新,都是由昇騰AI來支持的。除了華為,阿里、騰訊等也打造了較大的算力集群,不過主要還是依靠英偉達(dá)的GPU芯片。阿里云表示,其擁有國內(nèi)最強(qiáng)的智能算力儲(chǔ)備,智算集群可支持最大十萬卡GPU規(guī)模,承載多個(gè)萬億參數(shù)大模型同時(shí)在線訓(xùn)練。騰訊云此前大量采購了英偉達(dá)A100/H800芯片,發(fā)布新一代HCC高性能計(jì)算集群,用于大模型訓(xùn)練、自動(dòng)駕駛、科學(xué)計(jì)算等領(lǐng)域。基于新一代集群,騰訊團(tuán)隊(duì)在同等數(shù)據(jù)集下,將萬億參數(shù)的AI大模型混元NLP訓(xùn)練由50天縮短到4天。小結(jié)無論是大模型的訓(xùn)練,還是后期的推理部署,對(duì)算力的需求都相當(dāng)大。雖然,當(dāng)前國產(chǎn)AI芯片與國際領(lǐng)先GPU產(chǎn)品在大模型的訓(xùn)練上有差距,不過可以看到,已經(jīng)有不少產(chǎn)品,在較大模型的訓(xùn)練上已經(jīng)取得成績,后續(xù)必然還會(huì)有更大的進(jìn)展。同時(shí),為了滿足大模型對(duì)大算力的需求,算力集群化將會(huì)是未來趨勢。
2. 大模型加速涌向移動(dòng)端!ControlNet手機(jī)出圖只需12秒,高通AI掌門人:LLaMA也只是時(shí)間問題
原文:https://mp.weixin.qq.com/s/je05z93KcAIT81NvoyFsuw大模型重塑一切的浪潮,正在加速涌向移動(dòng)應(yīng)用。不久前,高通剛在MWC上露了一手純靠手機(jī)跑Stable Diffusion,15秒就能出圖的騷操作: 3個(gè)月后的CVPR 2023上,參數(shù)加量到15億,ControlNet也已在手機(jī)端閃亮登場,出圖全程僅用了不到12秒:
更令人意想不到的速度是,高通技術(shù)公司產(chǎn)品管理高級(jí)副總裁兼AI負(fù)責(zé)人Ziad Asghar透露:從技術(shù)角度來說,把這些10億+參數(shù)大模型搬進(jìn)手機(jī),只需要不到一個(gè)月的時(shí)間。并且這還只是個(gè)開始。在與量子位的交流中,Ziad認(rèn)為:
大模型正在迅速重塑人機(jī)交互的方式。這會(huì)讓移動(dòng)應(yīng)用的使用場景和使用方式發(fā)生翻天覆地的變化。“大模型改變終端交互方式”每一個(gè)看過《鋼鐵俠》的人,都很難不羨慕鋼鐵俠無所不能的助手賈維斯。
盡管語音助手早已不是什么新鮮事物,但其現(xiàn)如今的形態(tài)多少還是離科幻電影中的智能助手有點(diǎn)差距。而大模型,在Ziad看來,正是一個(gè)破局者。
大模型有能力真正重塑我們與應(yīng)用交互的方式。這種改變的一種具體的表現(xiàn),就是all in one。也就是說,通過大模型加持下的數(shù)字助手這一個(gè)應(yīng)用入口,人們就可以在手機(jī)這樣的終端上操控一切:通過自然語言指令,數(shù)字助手能自動(dòng)幫你管理所有手機(jī)上的APP,完成辦理銀行業(yè)務(wù)、撰寫電子郵件、制定旅程并訂票等等各種操作。
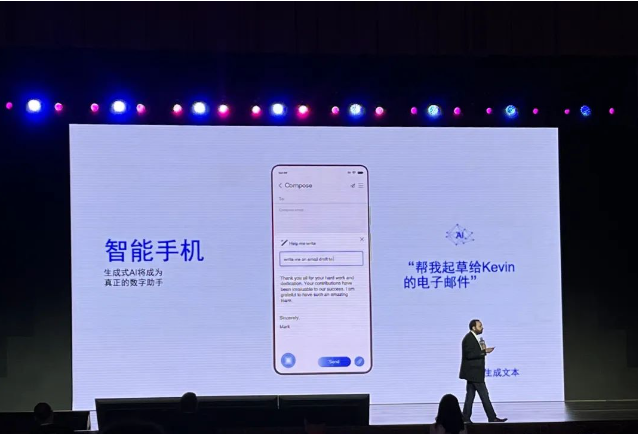

這樣一來,整個(gè)推理過程可以完全只靠手機(jī)實(shí)現(xiàn)——開著飛行模式不聯(lián)網(wǎng)也能做到。這類AI技術(shù)的部署并非易事,Ziad表示在相關(guān)軟件、工具和硬件方面,高通準(zhǔn)備了2-3年的時(shí)間。但現(xiàn)在,當(dāng)高通AI模型增效工具包、高通AI軟件棧和高通AI引擎等軟硬件工具齊備之后,正如前文所言,高通只花了不到一個(gè)月的時(shí)間,就實(shí)現(xiàn)了Stable Diffusion在驍龍平臺(tái)上的高速運(yùn)行。也就是說,當(dāng)基礎(chǔ)技術(shù)準(zhǔn)備就緒,包括大模型在內(nèi)的生成式AI部署,就會(huì)更加容易,原本無法想象的“大模型部署到終端變成數(shù)字助手”,現(xiàn)在看來也并非不可能。具體而言,在硬件上混合AI和軟件AI技術(shù)的“雙重”架構(gòu)下,部署在手機(jī)等終端中的大模型,可以在終端側(cè)根據(jù)用戶習(xí)慣不斷優(yōu)化和更新用戶畫像,從而增強(qiáng)和打造定制化的生成式AI提示。這些提示會(huì)以終端側(cè)為中心進(jìn)行處理,只在必要時(shí)向云端分流任務(wù)。
Ziad也進(jìn)一步向我們解釋說:
云不了解你,但終端設(shè)備了解你。如果模型可以在設(shè)備上進(jìn)行微調(diào),那它的功能將非常強(qiáng)大。這也是突破大模型幻覺和記憶瓶頸的方式之一。高通可以做到通過一系列技術(shù)讓大模型在不聯(lián)網(wǎng)的情況下,借助終端設(shè)備數(shù)據(jù)長時(shí)間提供“專屬”服務(wù),同時(shí)也保護(hù)了用戶隱私。值得關(guān)注的是,Ziad還透露,在Stable Diffusion和ControlNet之外,基于高通全棧式的軟件和硬件能力,研究人員正在將更多生成式AI模型遷移到手機(jī)之中,參數(shù)量也正在向百億級(jí)別進(jìn)發(fā)。
很快,你就會(huì)在終端上看到像LLaMA 7B/13B這樣的模型。一切工具已經(jīng)就緒,剩下的只是時(shí)間問題。而且,雖然目前能在終端側(cè)部署的只是“特定”的大模型,但隨著技術(shù)的不斷應(yīng)用成熟,能部署的大模型數(shù)量、模態(tài)類型和部署形式,都會(huì)飛速進(jìn)化。Ziad表示:
隨著更多更好的AI算法被開源出來,我們也能更快地沿用這套軟硬件技術(shù)將它們部署到終端側(cè),這其中就包括文生視頻等各種多模態(tài)AI。這樣來看,未來用戶將自己想用的大模型遷移到手機(jī)端,成為超級(jí)助手的核心,也并非不可能實(shí)現(xiàn)。大模型正在重塑移動(dòng)互聯(lián)網(wǎng)實(shí)際上,手機(jī)上的交互變革,還只是冰山一角。早在生成式AI、大模型技術(shù)爆發(fā)之前,在移動(dòng)互聯(lián)網(wǎng)時(shí)代,AI需求已經(jīng)呈現(xiàn)出向邊緣設(shè)備轉(zhuǎn)移的趨勢。正如Ziad的觀點(diǎn)“終端側(cè)AI是AI的未來”一樣,隨著以大模型為代表的生成式AI浪潮加速改變人機(jī)交互方式,更多終端側(cè)如筆記本電腦、AR/VR、汽車和物聯(lián)網(wǎng)終端等,也都會(huì)因?yàn)檫@場變革迎來重塑,甚至反過來加速AI規(guī)模化落地。在這個(gè)過程中,不僅硬件會(huì)誕生新的衡量標(biāo)準(zhǔn),軟件上以大模型為核心的超級(jí)AI應(yīng)用,更是有可能出現(xiàn)。首先是硬件上,由于終端側(cè)算力會(huì)成為延展生成式AI落地應(yīng)用不可或缺的一部分,對(duì)于移動(dòng)端芯片本身來說,AI處理能力也會(huì)日益凸顯,甚至成為新的設(shè)計(jì)基準(zhǔn)之一。隨著大模型變得更受歡迎、更多應(yīng)用不斷接入其能力,更多潛在的用戶也會(huì)意識(shí)到大模型具備的優(yōu)勢,從而導(dǎo)致這類技術(shù)使用次數(shù)的迅猛上升。但云端算力終究有限。Ziad認(rèn)為:
隨著AI計(jì)算需求的增加,云端算力必然無法承載如此龐大的計(jì)算量,從而導(dǎo)致單次查詢成本急劇增加。要解決這一問題,就應(yīng)當(dāng)讓更多算力需求“外溢”到終端,依靠終端算力來緩解這一問題。為了讓更多大模型在終端就能處理甚至運(yùn)行,從而降低調(diào)用成本,必然需要在確保用戶體驗(yàn)的同時(shí),提升移動(dòng)端芯片處理AI的能力。長此以往,AI處理能力會(huì)成為衡量硬件能力的benchmark,如同過去手機(jī)芯片比拼通用算力和ISP影像能力一樣,成為整個(gè)移動(dòng)端芯片的新“賽點(diǎn)”。等多的內(nèi)容,如果感興趣,可以直接點(diǎn)擊原文,您會(huì)收獲更多的知識(shí)。
3. 英特爾AI芯片中國定制版發(fā)布!打的就是英偉達(dá)A100
原文:https://mp.weixin.qq.com/s/5njVFAcZnMP0rEb5VZcLhAAIGC時(shí)代,誰說煉大模型就一定得用GPU?英特至強(qiáng)CPU,運(yùn)行擴(kuò)散模型Stable Diffusion只需5秒就能出圖。而在這兩天,專門搭載在該CPU上使用的AI加速器更是新鮮出爐。它叫Gaudi2,面向中國市場發(fā)布,用于加速AI訓(xùn)練及推理,有了它,大規(guī)模部署AI便多了一種新選擇。
性能上,它在MLPerf最新報(bào)告中的多種訓(xùn)練和推理基準(zhǔn)測試中都直接超越了英偉達(dá)A100,并提供了約2倍的性價(jià)比。至于H100,它雖然還不能敵過,但若拉上成本,則也能“扳回一局”。
這款主打超強(qiáng)性價(jià)比的AI加速器,究竟什么來頭?全新Gaudi2加速器,性能超A100Gaudi2深度學(xué)習(xí)加速器暨Gaudi2夾層卡HL-225B,以第一代Gaudi高性能架構(gòu)為基礎(chǔ),加速高性能大語言模型運(yùn)行。(ps. Gaudi1代處理器誕生于2019年,其背后公司來自以色列,當(dāng)年年底被英特爾以20億美元收購,如今成為英特爾“叫板”英偉達(dá)的重要底氣。)Gaudi2采用7nm制程工藝,具備24個(gè)可編程Tensor處理器核心(TPCs),支持面向AI的各類高級(jí)數(shù)據(jù)類型:FP8、BF16、FP16、TF32和FP32。它配備21個(gè)100 Gbps(RoCEv2)以太網(wǎng)接口,可通過直接路由實(shí)現(xiàn)Gaudi處理器間通信(相比原版少了3個(gè),但英特爾公司執(zhí)行副總裁Sandra Rivera介紹,這對(duì)整體性能影響基本不大)。同時(shí),它還能做到2.4TB/秒的總內(nèi)存帶寬,先進(jìn)的HBM控制器則針對(duì)隨機(jī)訪問和線性訪問進(jìn)行了優(yōu)化,在各種訪問模式下都可以提供這一保證。此外,48MB片上SRAM和集成多媒體處理引擎亦是標(biāo)配。



國內(nèi)AI產(chǎn)品需求非常大,產(chǎn)品完全不夠用。因此市場就在那里,在這種情況下我們不用特別設(shè)什么份額的目標(biāo),就把最好的產(chǎn)品帶出來,滿足市場需求,幫助大家創(chuàng)新,這就是我們想要做的事情。而據(jù)量子位現(xiàn)場獲悉,明年,能夠進(jìn)一步縮小差距甚至超越英偉達(dá)H100的Gaudi3就將問世。與此同時(shí),2025年之時(shí),英特爾還將整合既有的GPU Max產(chǎn)品線和Gaudi系列,取兩者之長,推出更加完整的下一代GPU產(chǎn)品。而在這之中,英特爾將對(duì)大家最為關(guān)心的可持續(xù)軟件生態(tài)做大筆投入。
4. 李飛飛「具身智能」新成果!機(jī)器人接入大模型直接聽懂人話,0預(yù)訓(xùn)練就能完成復(fù)雜指令
原文:https://mp.weixin.qq.com/s/XleXS_5shzZNiOSxUFZfgQ李飛飛團(tuán)隊(duì)具身智能最新成果來了:大模型接入機(jī)器人,把復(fù)雜指令轉(zhuǎn)化成具體行動(dòng)規(guī)劃,無需額外數(shù)據(jù)和訓(xùn)練。

打開上面的抽屜,小心花瓶!
大語言模型+視覺語言模型就能從3D空間中分析出目標(biāo)和需要繞過的障礙,幫助機(jī)器人做行動(dòng)規(guī)劃。
然后重點(diǎn)來了, 真實(shí)世界中的機(jī)器人在未經(jīng)“培訓(xùn)”的情況下,就能直接執(zhí)行這個(gè)任務(wù)。
新方法實(shí)現(xiàn)了零樣本的日常操作任務(wù)軌跡合成,也就是機(jī)器人從沒見過的任務(wù)也能一次執(zhí)行,連給他做個(gè)示范都不需要。可操作的物體也是開放的,不用事先劃定范圍,開瓶子、按開關(guān)、拔充電線都能完成。目前項(xiàng)目主頁和論文都已上線,代碼即將推出,并且已經(jīng)引起學(xué)術(shù)界廣泛興趣。

- 具身智能(Embodied AI)
- 視覺推理(Visual Reasoning)
- 場景理解(Scene Understanding)
5. 國產(chǎn)7nm全功能GPU上海發(fā)布!還有大模型加速卡、AIGC大模型一體機(jī)等6款新品
原文:https://mp.weixin.qq.com/s/MhFOeWOowpk_j0CB9zcFQQ7月6日下午,瀚博半導(dǎo)體在2023世界人工智能大會(huì)上正式發(fā)布第二代GPU SG 100。一并推出的還有南禺系列GPU加速卡 VG1600、VG1800、VG14以及LLM大模型AI加速卡VA1L、AIGC大模型一體機(jī)、VA12高性能生成式AI加速卡等6款新品,為AI大模型、圖形渲染和高質(zhì)量內(nèi)容生產(chǎn)提供完整解決方案。本次發(fā)布會(huì)以“智渲同芯,共生未來”為主題,瀚博半導(dǎo)體創(chuàng)始人兼CTO張磊在發(fā)布會(huì)上發(fā)表了《從像素到杰作:***加速AI大模型和元宇宙》主題演講,吸引眾多行業(yè)伙伴、知名媒體以及投資機(jī)構(gòu)到場。張磊以AGI時(shí)代的算力需求與挑戰(zhàn)為引,全面展示了瀚博針對(duì)人工智能與元宇宙行業(yè)的最新產(chǎn)品研發(fā)成果,此次瀚博半導(dǎo)體新品發(fā)布會(huì)賦能大模型創(chuàng)新應(yīng)用,聯(lián)合上下游企業(yè)共同打造國產(chǎn)大模型生態(tài)圈,以全新姿態(tài)把握時(shí)代機(jī)遇,開啟人工智能+元宇宙的瀚博算力序章。



與此同時(shí),瀚博更重磅推出AIGC大模型一體機(jī),共使用8張LLM大模型AI加速卡VA1L,支持512GB顯存,進(jìn)而支持1750億參數(shù)的大模型。本次大模型一體機(jī)解決方案擁有業(yè)內(nèi)最低門檻,也是目前針對(duì)AI大語言模型最低價(jià)格的大模型一體機(jī)方案。此外,新品還提供兩個(gè)特殊選配:具有對(duì)話功能的2卡單獨(dú)運(yùn)行語音轉(zhuǎn)文字或者文字轉(zhuǎn)語音版本以及使用SG 100做云端實(shí)時(shí)渲染的2U 11卡版本,提供大模型會(huì)話數(shù)字人實(shí)時(shí)渲染,使大模型推理更高效,服務(wù)于大模型行業(yè)發(fā)展。

6. 人工智能在日常生活中的十大應(yīng)用
原文:https://mp.weixin.qq.com/s/HqVbMOBwpIaHt1eQz3C2Cg7月6日下午,瀚博半導(dǎo)體在2023世界人工智能大會(huì)上正式發(fā)布第二代GPU SG 100。一并推出的還有南禺系列GPU加速卡 VG1600、VG1800、VG14以及LLM大模型AI加速卡VA1L、AIGC大模型一體機(jī)、VA12高性能生成式AI加速卡等6款新品,為AI大模型、圖形渲染和高質(zhì)量內(nèi)容生產(chǎn)提供完整解決方案。本次發(fā)布會(huì)以“智渲同芯,共生未來”為主題,瀚博半導(dǎo)體創(chuàng)始人兼CTO張磊在發(fā)布會(huì)上發(fā)表了《從像素到杰作:***加速AI大模型和元宇宙》主題演講,吸引眾多行業(yè)伙伴、知名媒體以及投資機(jī)構(gòu)到場。
今年,人工智能在公眾使用方面取得了驚人的新進(jìn)展。一張人工智能生成的圖像甚至在與人類藝術(shù)家競爭時(shí)獲得了藝術(shù)獎(jiǎng)(https://www.nytimes.com/2022/09/02/technology/ai-artificial-intelligence-artists.html)。事實(shí)是,人工智能就在我們身邊。它被用來幫助篩查癌癥,打擊偷獵瀕危大象的行為,并能夠從太空探測考古遺址。但人工智能并不局限于科學(xué)前沿。事實(shí)上,人工智能無處不在。你可能在日常生活中也使用人工智能。“人工智能技術(shù)滲透到了我們生活的方方面面,這幾乎是潛移默化的,”IEEE高級(jí)會(huì)員Guangjie Han說,“它為我們的設(shè)備提供動(dòng)力,同時(shí)通過分析我們在這些設(shè)備上產(chǎn)生的數(shù)據(jù)而不斷進(jìn)行改進(jìn)。”人工智能在日常生活中的常見用途包括:1. 智能助理:智能手機(jī)或智能家居設(shè)備上的語音助手由人工智能支持。有時(shí),請求可以在手機(jī)上處理。有時(shí)請求會(huì)被發(fā)送到云服務(wù)器進(jìn)行處理。2. 智能家居設(shè)備:通過人工智能,智能恒溫器可以自動(dòng)調(diào)整家中的暖通空調(diào)系統(tǒng),而攝像頭可以提醒消費(fèi)者有人、車或包裹到達(dá)。3. 電子商務(wù):人工智能在網(wǎng)上購物中無處不在。值得注意的應(yīng)用程序擴(kuò)展包括了產(chǎn)品建議,可以幫助管理銷售和退貨的聊天機(jī)器人,以及定制的購物體驗(yàn)。4. 零售業(yè)的趨勢識(shí)別:在線商店不僅僅是在你購物時(shí)提供推薦,他們還積極使用商店和競爭對(duì)手的銷售數(shù)據(jù)來識(shí)別趨勢。通過使用人工智能進(jìn)行設(shè)計(jì)和制造,以便滿足公眾的需求。5. 內(nèi)容推薦:人工智能支持的內(nèi)容推薦引擎使用產(chǎn)品目錄和消費(fèi)者數(shù)據(jù)進(jìn)行培訓(xùn),以提供更個(gè)性化的推薦。6. 導(dǎo)航和旅行:紙質(zhì)地圖已經(jīng)成為過去。人工智能生成的路線可以優(yōu)化旅行時(shí)間或減少油耗。7. 藥物研究:通過識(shí)別其潛在危險(xiǎn)和作用機(jī)制,人工智能系統(tǒng)能夠幫助尋找新的藥物應(yīng)用。這項(xiàng)技術(shù)幫助建立了幾個(gè)藥物發(fā)現(xiàn)平臺(tái),使企業(yè)能夠重復(fù)使用當(dāng)前的藥物和生物活性物質(zhì)進(jìn)行研究。8. 面部識(shí)別解鎖手機(jī):看向手機(jī)即可解鎖。這些功能得到了人工智能的支持,它利用相機(jī)和傳感器技術(shù)來準(zhǔn)確測量你的面部。9. 金融欺詐檢測:人工智能非常擅長模式分析,事實(shí)證明,我們大多數(shù)人使用信用卡的方式相當(dāng)可預(yù)測。這使得它非常適合確定哪些信用卡交易可能是非法的。如果你曾經(jīng)接到銀行的電話,詢問你是否進(jìn)行了交易,那很可能是人工智能算法的結(jié)果。10. 自動(dòng)更正:人工智能系統(tǒng)使用機(jī)器學(xué)習(xí)、深度學(xué)習(xí)和自然語言處理來識(shí)別文字處理器、短信應(yīng)用程序和其他文本媒體中的錯(cuò)誤語言使用,并提供更正和建議。在可預(yù)見的未來,人工智能系統(tǒng)的大部分工作將集中在構(gòu)建更大、更少偏見的數(shù)據(jù)集上,用于訓(xùn)練模型。“這些系統(tǒng)的訓(xùn)練在很大程度上取決于人工智能模型訓(xùn)練的數(shù)據(jù),”IEEE會(huì)士(Fellow)Karen Panetta說,“它可以體驗(yàn)的場景越多,效果就越好,但這需要精心策劃、注釋的數(shù)據(jù)集。這些數(shù)據(jù)集必須多樣化,以減少偏差,并動(dòng)態(tài)更新,以反映新的條件和現(xiàn)實(shí)世界應(yīng)用中出現(xiàn)的場景。”同時(shí),這也在提醒人們,在某些改變生活的環(huán)境中不要過度依賴人工智能系統(tǒng)。Panetta說:“人工智能需要被解釋。例如,許多公司正在銷售評(píng)估人們表現(xiàn)并確定薪酬的產(chǎn)品。然而,這些系統(tǒng)做出的決定無法解釋人工智能是如何決定結(jié)果的。人工智能不應(yīng)該影響某人的生計(jì)。”盡管人工智能盛行,但它仍有很大的發(fā)展和改進(jìn)空間。
———————End———————
RT-Thread線下入門培訓(xùn)
7月 - 南京
1.免費(fèi)2.動(dòng)手實(shí)驗(yàn)+理論3.主辦方免費(fèi)提供開發(fā)板4.自行攜帶電腦,及插線板用于筆記本電腦充電5.參與者需要有C語言、單片機(jī)(ARM Cortex-M核)基礎(chǔ),請?zhí)崆鞍惭b好RT-Thread Studio 開發(fā)環(huán)境
報(bào)名通道

立即掃碼報(bào)名
(報(bào)名成功即可參加)
點(diǎn)擊閱讀原文進(jìn)入官網(wǎng)
原文標(biāo)題:【AI簡報(bào)20230714期】人工智能在日常生活中的應(yīng)用,國產(chǎn)AI芯片最新進(jìn)展公布!
文章出處:【微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
RT-Thread
+關(guān)注
關(guān)注
31文章
1274瀏覽量
39944
原文標(biāo)題:【AI簡報(bào)20230714期】人工智能在日常生活中的應(yīng)用,國產(chǎn)AI芯片最新進(jìn)展公布!
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
芯片和封裝級(jí)互連技術(shù)的最新進(jìn)展
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第4章-AI與生命科學(xué)讀后感
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第二章AI for Science的技術(shù)支撐學(xué)習(xí)心得
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第一章人工智能驅(qū)動(dòng)的科學(xué)創(chuàng)新學(xué)習(xí)心得
人工智能ai 數(shù)電 模電 模擬集成電路原理 電路分析
人工智能ai4s試讀申請
名單公布!【書籍評(píng)測活動(dòng)NO.44】AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新
開啟全新AI時(shí)代 智能嵌入式系統(tǒng)快速發(fā)展——“第六屆國產(chǎn)嵌入式操作系統(tǒng)技術(shù)與產(chǎn)業(yè)發(fā)展論壇”圓滿結(jié)束
報(bào)名開啟!深圳(國際)通用人工智能大會(huì)將啟幕,國內(nèi)外大咖齊聚話AI
美國政府推動(dòng)美國科技公司在阿聯(lián)酋發(fā)展人工智能
百度首席技術(shù)官王海峰解讀文心大模型的關(guān)鍵技術(shù)和最新進(jìn)展

利用OpenVINO實(shí)現(xiàn)混合式AI部署:邁向無所不在的人工智能





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論