 三句話生成CPU!中科院ChipGPT攻克AI芯片設計?
三句話生成CPU!中科院ChipGPT攻克AI芯片設計?
中科院計算所的 ChipGPT 引人矚目。
自動生成電路想法源自圖靈老師邱奇,被稱為編程語言圣杯。
前段時間,紐約大學 Chat-Chip 項目,引爆熱潮。與此同時,中科院計算所在 arXiv 發布 ChipGPT 工作,兩隊人馬爭先后,只相差一日!
這場「人工智能芯片大戰」激戰正酣,各施法寶,令芯片業翻手為云,覆手為雨。
即便短期內人工智能難完全取代人工,但人工與人工智能聯袂設計,相得益彰,必將極大增強芯片設計生產力與創新力,關系到芯片設計之未來!

論文地址:https://arxiv.org/abs/2305.1401
杜克大學陳怡然老師在微博上表達了對芯片自動生成領域的關注,認為這個話題令人振奮,而中科院計算所 ChipGPT 也同樣引人矚目,但是想要真正做到自動化芯片生成還有很長的路要走。
ChipGPT 作者的指導老師王穎博士認為,現有的工作只是初步評估了大語言模型交互式芯片設計的潛力,如何將其融入現有EDA流程實現無人值守芯片設計將成為下一個目標。

陳教授這里提到的 ChipGPT,雖然同樣也是基于大語言模型的自動設計芯片,但與 Chip-Chat 不同,中科院計算所提出的 ChipGPT 還探索針對芯片性能和面積的優化方法。
不僅如此,ChipGPT 還在芯片設計上,比 ChatGPT 節省了多達 47% 面積。
大模型芯片設計 PK 戰:Chip-Chat vs ChipGPT?
雖說這兩篇工作都借大模型力量生成芯片,見識廣闊,一覽眾山小。但目前人工智能還處在發展初期,后續工作仍浩浩蕩蕩。
對此,ChipGPT 作者稱,要大模型玩轉芯片自動設計,三大難題迫在眉睫:
第一個問題是,我到底要往模型的對話里塞什么玩意兒?芯片設計涉及的知識太過廣博深奧,要把所有內容都嘟嘟嘟往模型的上下文里塞,下場恐怕和「狗熊掰苞米」一樣,統統忘光光。如何精選模型的「餐飲內容」, 這可是個讓芯片設計師們頭發都白了的難題。
第二個問題是,如何通過「Prompt Engineering」讓這個大模型生成出來的芯片更好更強大?要知道,Prompt Engineering 本身就是一門高深莫測的玄學,讓大模型一下子領會,簡直難上加難。
第三個問題是,如何控制大模型生成出來的 HDL,讓設計出來的芯片在性能、功耗和面積之間達到最佳的平衡?任何芯片都面臨這三者之間的博弈,要讓大模型自由自在地搞定,簡直是癡人說夢。
要是能爬得過這「三座大山」,芯片自動設計的未來可就指日可待了。不過話又說回來,就算解決了這三個問題,真正產業化可還遙遙無期呢。
所以呢,芯片設計師們暫時還是放心吧,你們的飯碗短期內應該還是很穩的!
芯片合成實力之源泉,大模型輸入有何高深玄機?
HDL = ChipGPT(Specification)
HDL = Chat-Chip(Prompt List)
Chip-Chat 純聊天輸入難定制所需,ChipGPT 研究從芯片規范說明抽絲剝繭入手!
Chip-Chat 聊天玩自由來去無蹤跡,ChipGPT 一絲不茍只信規范說明(Specification)指點迷津。雖聊天可研究發揮,生產更憑規范保證準確。
故 ChipGPT 研究從規范說明著手,將其放入聊天、試圖直接應用芯片規范說明,卻發現難題重重:
第一,從規范說明提取會得大量無用信息,如模塊運行錯誤模式與復雜時序等等。大模型收費看 token 數,所以更應從規范說明中精煉有用信息。
第二,芯片規范說明混亂無序,GPT 自動提取難保生成準確。故 ChipGPT 選擇手工提取,建立規范說明表格,將輸入歸于表格信息。
基于芯片說明書與基于簡單提示,ChipGPT 與 Chip-Chat 應用場景天差地別!
ChipGPT 研究目標與基于提示的 Chip-Chat 大相徑庭。
ChipGPT 旨在為研究者提供整體框架,指導大模型芯片硬件自動生成。Chip-Chat 則在告訴研究者大模型給硬件自動生成帶來何種新挑戰與機遇。
故 ChipGPT 可謂指南書,引導工程師與研究者遨游大模型芯片合成之道。
ChipGPT 為芯片自動生成研究提供指南,想玩轉大模型芯片設計者可從中「取經」。它從芯片規范說明提取入手,避免大模型直接處理規范說明種種負面影響。手工建立規范說明表格,將輸入信息歸類,較好解決大模型處理不規則信息難題。
相比之下,Chip-Chat 是大模型在硬件自動生成領域新嘗試,更似讓研究者知悉大模型給該領域帶來機遇與挑戰,屬測試探索應用。故兩者雖同大模型自動生成芯片研究,應用場景與目的差異頗大。

終結玄學!ChipGPT 讓 Prompt Engineering 逐漸「可控」
基于規范說明的輸入也會分解為小的提示,但在芯片生成中,不規則的提示會帶來一些問題:
1) 大模型自動設計芯片,輸出結果可重復性與穩定性堪憂!
如圖 7 所示,大模型玩轉芯片設計,生成的代碼穩定性是一個大問題。就算給同樣的提示,它生成的 Verilog 代碼也常常會「前后不搭調」,影響生成結果的可重復性和穩定性。
這可讓想用大模型自動設計芯片的人又愛又恨,成了這一路上最大的絆腳石。
要解決這個難題,使用確定的 Module 接口是個不錯的辦法。明確接口后,大模型處理輸入的不確定性就可以大幅減少,生成結果的穩定性自然也會提高。
這就像家長提前告知孩子作業要求一樣,大模型事先知道需遵守的「規矩」,自然也能高效穩定地完成「作業」了。

2)芯片連接信號,如何解開這段全局最難理清的「頭疼之鏈」?
大模型一口吃個胖子,不利于身體健康。同樣,使用一個提示同時處理多個限制,會讓大模型生成的代碼質量大打折扣。
就像人吃飯一樣,一次吃太多會造成消化不良。大模型也一樣,一次處理太多限制,容易搞混導致輸出錯誤。
圖 8 中,若把額外信號限制也放入同一個提示,大模型處理起來難免手忙腳亂,就會對芯片設計的正確性造成極大影響。
相比之下,如果把額外限制(如 Ready-Valid 信號)提取出來,放到下一輪的提示中,大模型就能逐一輕松地「消化」,然后才能正確地合成接口。
這就好比人吃飯時,分多次適量地吃,而不是一口氣吃太多,更有利于消化吸收。
所以,對大模型來說,盡量避免一次處理過多限制是一個簡單高效的原則。要想讓它生成高質量的代碼,最佳方法就是分步驟輸入,不要一次「塞」太多需考慮的因素。
對芯片自動設計而言,提取額外限制,分步驟通過多輪提示輸入,可以較好地解決大模型處理多個限制帶來的難題,讓其有條不紊地完成設計任務。

3)大規模模塊生成,要實現自動設計的「勝在規模」效應,仍需跨越幾道坎?
要讓大模型自動生成大規模模塊,直接使用整個大模塊的描述輸入,效果可能會「一塌糊涂」。這就像讓孩子直接處理整本教科書一樣,勢必會被難度「嚇倒」,無從下手。
相比之下,從小功能模塊開始,逐步組合生成大模塊,可以避免難度過大帶來的問題。這就像教科書分章節講解一樣,讓讀者循序漸進,逐步掌握。
ChipGPT 使用的「從小到大」方法,先從小模塊功能入手,逐步使用一系列提示代替單個提示,組合生成大模塊,避免了直接處理大模塊描述帶來的問題。
所以,對大模型自動化生成大規模模塊來說,使用「循序漸進」的方法至關重要。直接處理整個大模塊的描述,難度和復雜性都太大,很難取得好結果。
而通過從小功能模塊開始,逐步組合和輸入,讓大模型逐步掌握并生成大模塊,可以較好地避開這一難題。
這其實也是人工智能發展的一般規律,通過避免一次處理過高難度的任務,選擇循序漸進的訓練和生成方法,可以最大限度發揮人工智能的學習和生成能力。
對芯片自動設計而言,要實現大規模模塊的自動生成,采用 ChipGPT 的這種「從小到大」的方法,從小功能模塊開始組合輸入,逐漸生成大模塊,無疑是一條較為可行的路徑。
甩鍋大模型無濟于事,PPA 平衡終究需靠一己之力?
大模型雖然聰明,但生成代碼質量不比人工,這也是研究工作面臨的最大難題。
一般來說,基于 GPT 的設計依靠反饋迭代,但現有反饋方式只關注功能,很難生成考慮性能、功耗和面積的芯片。
ChipGPT 的作者意識到這一短板,所以加入輸出管理器以管理反饋,及時優化芯片的 PPA。
這就像老師不僅檢查作業的正確性,還關注字跡、表達等方面一樣,可以幫助學生在更廣泛的方面提高。輸出管理器就相當于老師,不僅檢查功能性反饋,還關注 PPA 等方面,及時提醒大模型進行改進。
所以,對大模型自動化設計芯片來說,僅靠功能反饋是不夠的,還需要考慮 PPA 等方面,以生成全面優質的設計。
單純依靠大模型自己完成這一任務難度較大,容易忽略某些方面。而加入輸出管理器可以有效彌補這一不足,及時檢查 PPA 等指標,讓大模型得到全面反饋,以生成更加優質的代碼。

大模型自動設計不止局限于生成一種設計方案,它可以產生多種方案供選擇,這給研究工作帶來更大靈活性。
ChipGPT 通過加入后端組件,每輪可以生成不同代碼,然后使用枚舉法選擇最符合目標的代碼,這種方法比 GPT 單純隨機輸出的效果要好很多。
就像 GPT 自動生成的矩陣乘法電路,雖然實現同一功能,卻可以產生不同方案,在時間延遲和面積之間作出權衡。
利用這一優勢,可以產生不同版本的代碼,如表 3 所示 button-count 產生 5 個程序,通過檢查后,面積不同。

表 4 顯示如果按不同標準選擇,最終輸出也不同。
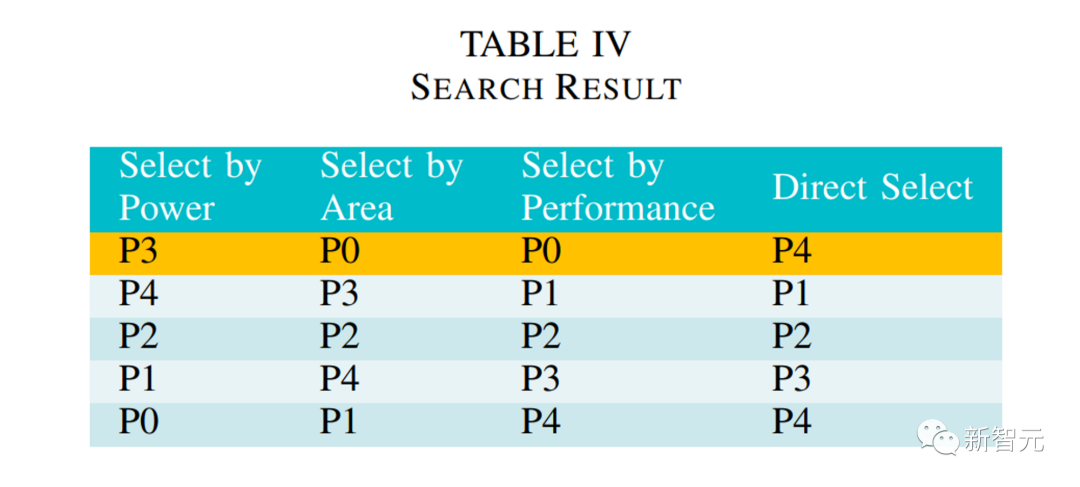
所以,ChipGPT 這種加入選擇機制的方法,可以根據不同目標選擇最優方案,顯著提高效果。
如作者提到,如果目標是最優面積,與不加入反饋方法相比,面積優化率可以達 47%。
這表明,大模型自動設計不應局限于生成一種方案,加入選擇機制可以產生更優設計。

ChipGPT 這種每輪生成不同代碼,然后選擇最符合目標的方案的方法,可以發揮大模型產生多種方案的優勢,獲得更優設計方案。
對研究人員來說,這不僅為大模型自動化設計芯片提供了新思路,也說明選擇機制在發揮大模型潛能方面作用巨大。
自動設計并不等同于盲目生成,加入選擇機制可以讓大模型在自動設計的同時達到優化目標,這是實現高質量設計的關鍵因素之一。
芯片設計方法之爭,ChipGPT 竟力壓群雄?
ChipGPT 的結論表明,與傳統敏捷方法相比,代碼量可以減少 5.32-9.25 倍。利用大語言模型,ChipGPT 可以顯著加速芯片開發。
在優化面積模式下,ChipGPT 的面積減少最大可達 47%, 比原始 ChatGPT 模型減少更多。它還將大語言模型的正確性從概率正確提高到規則正確。
簡而言之,ChipGPT 讓芯片開發速度飆升,效率大幅提高。與傳統方法相比,編碼量少了 5-9 倍,這意味著開發周期可以縮短很多。利用大語言模型,ChipGPT 讓芯片開發一下子就「升級」了。

在優化面積方面,ChipGPT 也有亮眼表現,最大可以減少 47% 的面積,比 ChatGPT 原始大模型減少更多。這說明在自動化設計的同時,ChipGPT 還可以實現較高的設計優化。
另外,ChipGPT 還提高了大語言模型的正確性,從概率正確提高到規則正確。這意味著大語言模型的輸出結果更加準確可靠,而不僅僅依靠概率。
所以,總體來說,ChipGPT 在三個方面取得重要進展:
1) 大幅提高編程效率,編碼量減少 5-9 倍,芯片開發周期大幅縮短。
2) 實現較高設計優化,面積減少最大 47%, 優于 ChatGPT 模型。
3) 提高大語言模型的正確性,從概率正確到規則正確,輸出結果更加準確。
這充分證明了大語言模型可以促進芯片開發自動化,并在自動化的同時實現設計優化。這為大語言模型應用于更廣泛領域,特別是產業化應用提供了理論基礎和實證依據。
芯片自動生成難辨優勝,評價標準來破迷局!
ChipGPT 從三個角度評價芯片自動生成方案:
1) 正確性:生成的硬件描述是否正確。ChatGPT 和 ChipGPT 屬于概率正確。
2) 完備性:方法覆蓋的設計空間范圍。ChatGPT 和 ChipGPT 屬于通用硬件生成器,可以描述各種規模和類型的邏輯。
3) 表達能力:輸入語言的生產力。ChatGPT 和 ChipGPT 使用自然語言,屬于最高級。

所以,總體而言,ChatGPT 和 ChipGPT 在三個維度上屬于概率正確、通用硬件生成器和最高表達能力。這意味著它們可以概率生成正確的各類硬件描述,并且輸入方法屬于最高生產力的自然語言。
這為比較不同芯片自動生成方法提供了較全面客觀的評價體系。對研究人員和相關企業來說,這有助于選擇最適合的方法,發揮最大效益。

總之,要實現芯片自動生成的產業應用,選擇最優方法至關重要。
ChipGPT 提供的這套評價體系,為做出最佳選擇提供了較為客觀的判斷依據,這無疑也有利于相關技術的產業推廣。
所以,這些成果在一定程度上也為大語言模型等新技術的產業化應用奠定基礎。
下一步:無人值守的 AI 自動化芯片設計是否可能?
Chat-Chip 和 ChipGPT 已經證明了大語言模型在 RTL 設計方面所具備的巨大潛力,而考慮到大語言模型通常由包括代碼在內的大量且豐富的文本語料訓練而成,其知識儲備遠不止可以用來實現RTL設計,我們觀察發現其對芯片設計過程中的其他任務也有著一定的解決能力,例如根據 EDA 工具的 report 給出優化 PPA 的思路、甚至設計 specification 等。
此外,已有的工作如 AutoGPT、ChatGPT Plugins 等進一步證明了大語言模型具有任務分解、操作工具的能力,因此,一個自然的想法是能否讓大語言模型驅動完整的芯片設計過程:即自主分解用戶給出的由自然語言描述的芯片 / IP 設計需求、設計 specification、實現 RTL,并進一步通過與 EDA 工具交互實現調試和 PPA(性能 / 功耗 / 面積)優化,最后得到物理版圖。
為此,基于 ChipGPT 的自動化框架ChipGPT2.0已經搭建了這樣的一個原型,相比需要設計人員持續交互并處理反饋(Human-in-the-loop )的 Chat-chip 方法,ChipGPT2.0 可以初步完全自主設計 UART 控制器、8 位 CPU、RISC-V CPU 等常見的組件,所得到的設計具有一定的可用性,也就證明了無人值守的 AI 自動化芯片設計是可能的。
當然,正如前文所說,基于大語言模型的設計僅達到了概率正確,我們搭建的原型也并不是每次都能得到完全工程可用的實現,但我們相信這樣一套自動設計方法是對傳統的基于手動設計方法的重要補充。

大語言模型完全自主設計的UART控制器版圖

大語言模型完全自主設計的8位MCU版圖
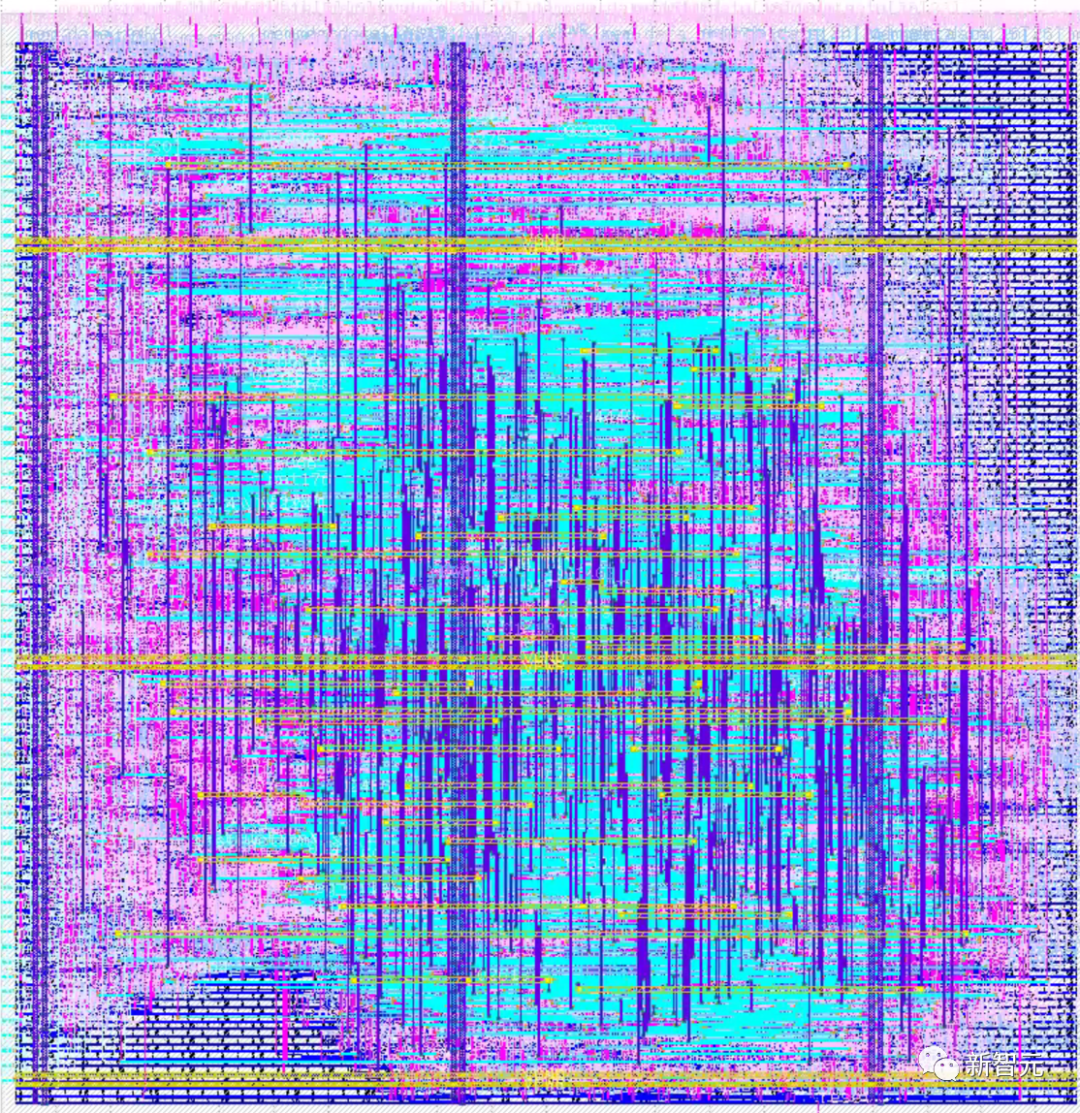
大語言模型完全自主設計的RISC-V CPU版圖
大語言模型是不是芯片自動生成的華山之路?
相比采用自然語言與大模型輔助設計的方法,程序合成的方法可以提供更高的方法魯棒性和穩定性。
這方面的代表性工作有中科院計算所智能處理器研究中心提出的自動化CPU設計方法,該方法以程序合成為中心,利用輸入輸出對(IO Examples)可以直接生成網表級電路。
這種方法的準確率高,該方法設計的 CPU 自動生成準確率近 100%,理論上通過擴增測試用例可以達 100% 功能正確。
所以,總體來說,相比大語言模型,該方法在以下兩點上更具優勢:
1) 無需人工干預和反饋。
目前大模型更多還是基于現有的流程做輔助設計,這個工作無需人工參與反復迭代的邏輯設計和驗證環節,從 IO 直接到電路,做的是全自動設計。無需專家工程師提供形式化的代碼(C、Chisel、Verilog)或者非形式化的自然語言描述。
2) 符號方法的準確率更高。
如基于輸入輸出對的符號方法理論上可以達到 100% 的準確率,更適用于處理器等設計。但大語言模型也具有優勢,如更通用、生產力更高等。
所以,選擇何種方法更適合,還需要根據實際應用場景和需求判斷。對研究人員和相關企業來說,理解不同方法的優缺點至關重要。要實現產業化應用,需選擇最適合的技術路徑。
ChipGPT 的技術雖較新穎,但傳統程序合成思路在某些方面仍占優。所以,結合實際情況選擇最佳技術,或將不同技術有機結合,這是產業化的關鍵。
總之,要實現芯片自動生成的廣泛應用,必須在不斷探索新方法的同時,理解每種方法的優勢所在。將不同方法的優點有效融合,這可能是取得最大效益的關鍵。
在一定程度上,產業化依賴于技術創新,但更需要對不同技術有 objective 的判斷和選擇。這也是促進任何新技術廣泛應用的基礎。

論文地址:https://arxiv.org/abs/2306.12456
結論出人意表?芯片自動生成之路恰恰漫長不過!
簡而言之,大模型在芯片自動設計中的應用還面臨以下困難:
1) 隨機性和魯棒性較差,會影響研究人員復現結果和現有算法對特性的約束。雖然 ChipGPT 采取措施加強穩定性,但大模型的魯棒性還需提高。
2) 仍缺乏芯片全流程優化算法。現有方案只用于芯片邏輯設計的「小優化」。如何大模型做前后端協同優化,改變這種局限,值得探索。
3) 芯片數據庫短缺。雖然閉源大模型較完善,但大量資源掌握在生產商手中。如果從開源庫生成高質量數據集或把閉源代碼庫當作數據庫,可以給開源模型訓練帶來優勢,此可逆轉這一劣勢。
所以,要實現大模型在芯片自動設計中的深入應用,還需努力解決這些難題。提高大模型的穩定性和魯棒性,開發芯片全流程優化算法,解決數據庫短缺問題,這些都是實現更深入應用的關鍵所在。
對研究人員和企業來說,這些難題同時也代表新的研究方向和市場機會。能夠有效解決這些問題,巨大潛力等著發掘。
現有設計方法只是起步,距離工程師自主設計和理解電路還較遠。
團隊介紹&致謝
ChipGPT 的一作為中科院計算所博士生常開顏,指導老師為中科院計算所王穎博士;上海科技大學碩士生任海蒙,中科院計算所博士生王夢迪參與工作;中科院計算所助理研究員梁勝文,中科院計算所韓銀和、李華偉、李曉維研究員提供支持。
感謝中科院計算所王穎老師,首都師范大學李冰老師對本文的建議和指導,感謝中科院計算所碩士生林鋼亮對本文的審閱。
-
cpu
+關注
關注
68文章
10829瀏覽量
211193 -
編程語言
+關注
關注
10文章
1939瀏覽量
34608 -
AI芯片
+關注
關注
17文章
1860瀏覽量
34919
原文標題:三句話生成CPU!中科院ChipGPT攻克AI芯片設計?
文章出處:【微信號:ICViews,微信公眾號:半導體產業縱橫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenAI又打出王炸!一句話生成60秒視頻,馬斯克:人類認輸吧

文生視頻Pika 1.0爆火!一句話生成視頻,普通人也能當“導演”

開關電源布線 一句話:要運行最穩定、波形最漂亮、電磁兼容性最好

求助,關于AIC3254寄存器的問題求解
啟英泰倫CI13LC系列:打造AI語音芯片性價比之王!

中科院重慶研究院在勢壘可光調諧新型肖特基紅外探測器研究獲進展
AI初創公司Alembic攻克LLM虛假信息難題
一句話讓你理解線程和進程

中科加禾完成天使輪數千萬元融資,專注編譯技術,推動國產算力和大數據發展
百度文心一言支持一鍵生成專屬數字分身
龍芯中科與中科信息簽訂合作框架協議
生成式 AI (3/4):如何緩解人才短缺,促進芯片設計多元化?

產學研三界頂級大咖分享:RISC-V場景Show暨開源生態高級別論壇定檔12/19
中科億海微榮登中國科學院優秀科創企業榜






 工商網監
工商網監
評論