") 更強更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補全一切」
更強更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補全一切」
當前學界和工業(yè)界都對多模態(tài)大模型研究熱情高漲。去年,谷歌的 Deepmind 發(fā)布了多模態(tài)視覺語言模型 Flamingo ,它使用單一視覺語言模型處理多項任務,在多模態(tài)大模型領域保持較高熱度。Flamingo 具備強大的多模態(tài)上下文少樣本學習能力。
Flamingo 走的技術路線是將大語言模型與一個預訓練視覺編碼器結(jié)合,并插入可學習的層來捕捉跨模態(tài)依賴,其采用圖文對、圖文交錯文檔、視頻文本對組成的多模態(tài)數(shù)據(jù)訓練,在少樣本上下文學習方面表現(xiàn)出強大能力。但是,F(xiàn)lamingo 在訓練時只使用預測下一個文本單詞作為目標,并沒有對視覺部分施加專門的監(jiān)督信號,直接導致了在推理階段,其只能支持以文本作為輸出的多模態(tài)任務,大大限制了模型的能力以及應用場景。
Flamingo 目前并沒有開源,今年 3 月,非盈利機構(gòu) LAION 開源了 Flamingo 模型的復現(xiàn)版本 OpenFlamingo。
近日,智源研究院「悟道?視界」研究團隊提出了一種新的多模態(tài)大模型訓練范式,發(fā)布并開源了首個打通從多模態(tài)輸入到多模態(tài)輸出的「全能高手」,統(tǒng)一多模態(tài)預訓練模型 Emu 。
Emu 模型創(chuàng)造性地建立了統(tǒng)一的多模態(tài)預訓練框架,即將圖文對、圖文交錯文檔、視頻、視頻文本對等海量形式各異的多模態(tài)數(shù)據(jù)統(tǒng)一成圖文交錯序列的格式,并在統(tǒng)一的學習目標下進行訓練,即預測序列中的下一個元素 (所有元素,包含文本 token 和圖像 embedding)。此外,Emu 首次提出使用大量采用視頻作為圖文交錯數(shù)據(jù)源,視頻數(shù)據(jù)相比于 Common Crawl 上的圖文交錯文檔,視覺信號更加稠密,且圖像與文本之間的關聯(lián)也更加緊密,更加適合作為圖文交錯數(shù)據(jù)去激發(fā)模型的多模態(tài)上下文學習能力。
論文結(jié)果顯示,Emu 超越了此前 DeepMind 的多模態(tài)大模型 Flamingo,刷新 8 項性能指標。
除以文本作為輸出的任務指標之外,Emu 模型具有更加通用的功能,能夠同時完成以圖片作為輸出的任務,如文生圖;且具備很多新型能力,如多模態(tài)上下文圖像生成。Emu 的能力覆蓋圖像與文本的生成及視頻理解。
-
論文鏈接:https://arxiv.org/pdf/2307.05222.pdf
-
模型鏈接:https://github.com/baaivision/Emu
-
Demo 鏈接:https://emu.ssi.plus/
作為一種通用界面,Emu 可用于多種視覺、語言應用
超越 Flamingo、Kosmos,8 項基準測試表現(xiàn)優(yōu)異
在 8 個涵蓋多模態(tài)圖像 / 視頻和語言任務的基準測試中,Emu 均有不俗表現(xiàn),對比來自 DeepMind 的 Flamingo 與來自微軟的 Kosmos 亦有所超越。
Emu 在眾多常用測試基準上表現(xiàn)出極強的零樣本性能,展現(xiàn)了模型在遇到未知任務時強大的泛化能力。其中,Emu 在圖像描述 COCO Caption 的 CIDEr 得分為 112.4,且模型對圖片的描述中包含豐富的世界知識。此外,Emu 在圖像問答 VQAv2 和視頻問答 MSRVTT 數(shù)據(jù)集上也展現(xiàn)了強勁的視覺問答功能。
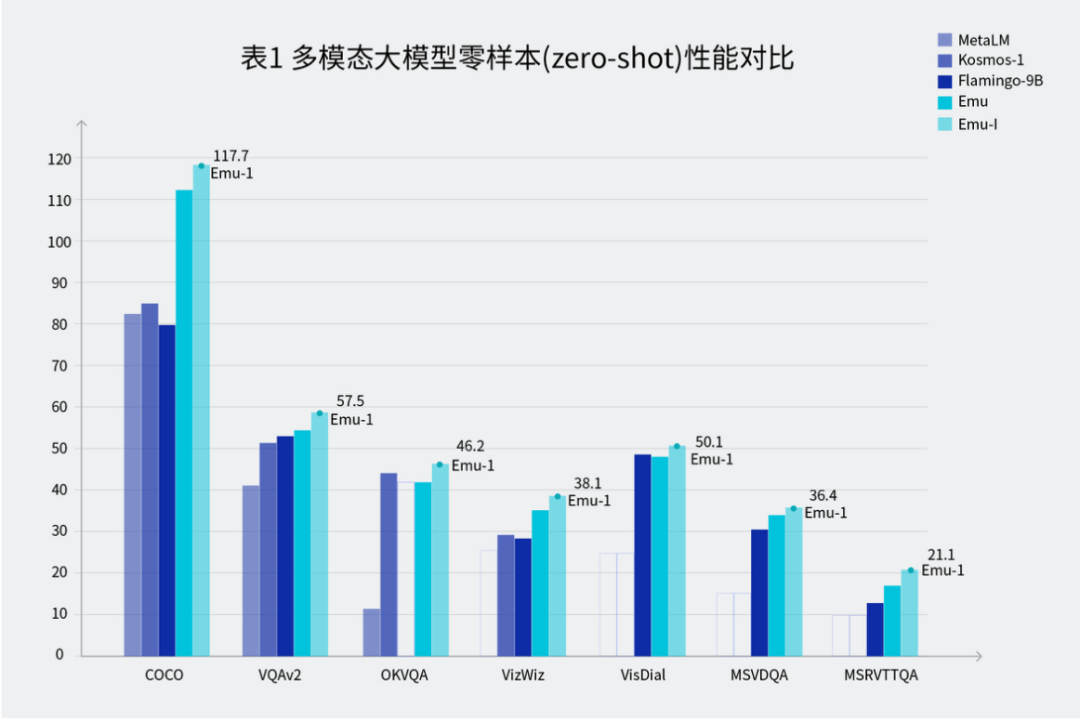
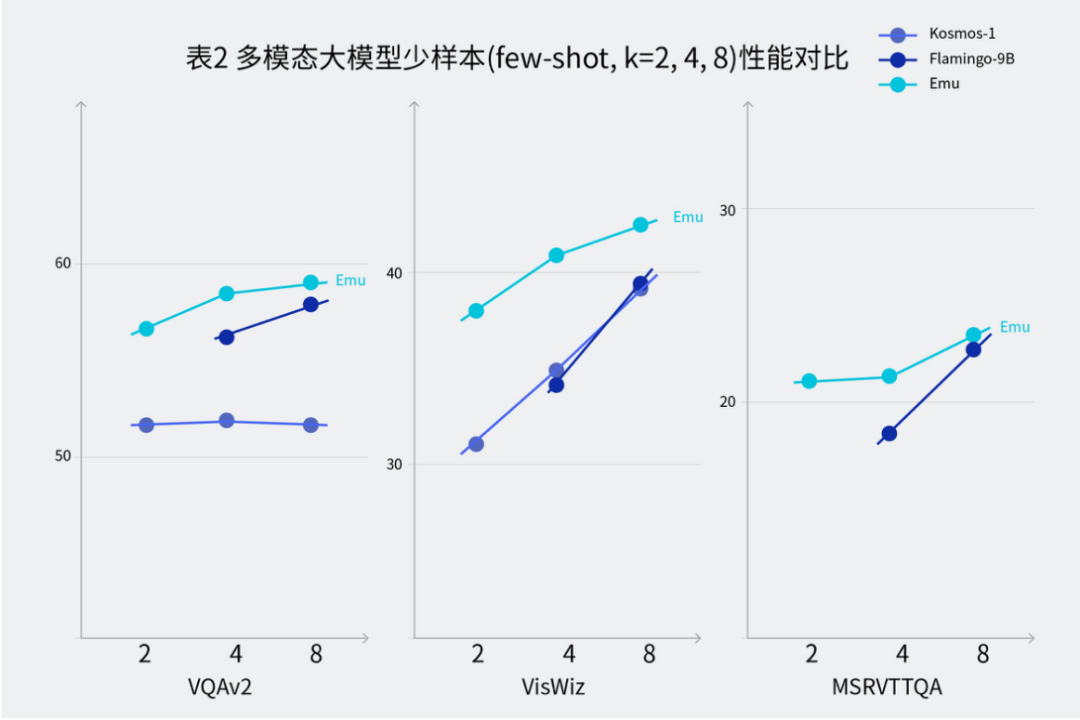
同時,Emu 具備強大的少樣本上下文學習能力,即對于給定任務提供幾個示例樣本,模型可以進行上下文學習從而更好地完成任務。Emu 在視覺問答數(shù)據(jù)集 VQAv2、VizWiz、MSRVTTQA 上的少樣本上下文學習表現(xiàn)突出。
全能高手:在多模態(tài)序列中進行「圖文任意模態(tài)生成」
Emu 模型能力覆蓋圖像與文本的生成及視頻理解, 相比其他多模態(tài)模型更具通用性,能完成任意圖生文以及文生圖的多模態(tài)任務。例如,精準圖像認知、少樣本圖文推理、視頻問答、文圖生成、上下文圖像生成、圖像融合、多模態(tài)多輪對話等。
Emu 是一個基于 Transformer 的多模態(tài)基礎模型,可以接受并處理形式各異的多模態(tài)數(shù)據(jù),輸出指定的多模態(tài)數(shù)據(jù)。Emu 將圖文對、圖文交錯文檔、視頻、視頻文本對等形式各異的海量多模態(tài)數(shù)據(jù)統(tǒng)一成圖文交錯序列的格式,并在統(tǒng)一的學習目標下進行訓練,即預測序列中的下一個元素 (所有元素,包含文本 token 和圖像 embedding)。訓練完成后,Emu 能對任意形式的多模態(tài)上下文序列進行多模態(tài)補全,對圖像、文本和視頻等多種模態(tài)的數(shù)據(jù)進行感知、推理和生成。
視頻理解、多模態(tài)上下文生成、多模態(tài)對話是 Emu 模型的技術亮點。
Emu 模型具有強大的視頻理解能力,如在下圖演示中,針對下面 “視頻中的女主人公在干什么” 這一問題,Emu 模型給出了具有精準事實細節(jié)(蘋果 VR 設備)、連貫動作描述(坐在飛機上并使用 VR 設備)、合理行動猜測(可能在看一段視頻或 360 度視角的飛機外景象)的豐富回答。
Emu 不只能理解視頻信息,還能做到對視頻中時序信息的精細理解。例如下圖展示的奶昔制作視頻,Emu 分步且完整地描述了奶昔制作步驟。
Emu 新增了圖像融合能力,可以對輸入的圖像進行創(chuàng)造性地融合,并生成新的圖片。例如下圖最后一行,將兩幅世界名畫作為輸入,Emu 可以生成風格、元素類似的全新畫作:
上下文圖像生成也是一項全新的功能,Emu 可以將輸入的文本 - 圖片對作為 prompt,結(jié)合上下文信息進行圖片生成。例如在下圖第一行,輸入兩張圖片,并輸入文本指令讓 Emu 生成以圖 1 的動物為中心,但以圖 2 為風格的圖片。依賴于強大的多模態(tài)上下文生成能力,Emu 可以完成相應的指令。下圖的第二行展示了如果在 “文生圖” 時提供了 context,Emu 會結(jié)合 context 的風格,生成油畫風格的圖片,而相同的文本在無 context 的情況下進行 “文生圖” 只會生成現(xiàn)實風格的圖片:
圖像生成方面,Emu 可以根據(jù)給定的文本生成多幅語義相關的圖像:
Emu 可根據(jù)一張或者多張圖或視頻進行問答和多輪對話。如下第一張圖所示,給出一張景點圖并詢問旅游注意事項,Emu 給出了 5 個要點,其中再就第 5 個要點 “ safety equipment” 提問時,Emu 能夠針對這一點進行更加詳細地闡述。最后,Emu 還可以根據(jù)圖片作詩。
Emu 還有一項突出的能力是它的世界知識更豐富。如下圖所示,給出兩張動物的圖,詢問這兩張圖的區(qū)別,Emu 可以準確描述動物的名稱及分布地:
Emu 模型可以準確識別畫作,例如下圖輸入莫奈的《日出?印象》這幅作品, Emu 不僅準確回答出了作品的名字,描述了畫面信息,還給出了很多背景知識,例如這是著名印象派風格的作品。而 mPLUG-Owl 、LLaVA 并不知道畫作的名稱,只是簡單描述了畫中場景。InstructBLIP 給出了作品名稱和描述,但在背景知識上略遜于 Emu。
再看下圖,給出阿加莎?克里斯蒂的肖像,問題是 “說出這位女性寫的 8 本書并推薦一本給我”,Emu 正確理解了這個問題,識別出作者并列出其 8 個作品,并從中挑選了偉大的代表作推薦。LLaVA 人物識別準確,只部分理解了題意,給出推薦作品,但并沒有給出 8 個代表作。mPLUG-Owl 識別出了人物 ,也是部分理解了問題,只給出了 4 部作品和一句話簡介。InstructBLIP 則給出了一個錯誤答案。
首次大量采用視頻數(shù)據(jù),創(chuàng)新性建立統(tǒng)一的多模態(tài)學習框架
現(xiàn)有多模態(tài)領域的研究工作常將大語言模型與預訓練視覺編碼器連接來構(gòu)建多模態(tài)大模型(LMM)。盡管現(xiàn)有的 LMMs 很有效,但主要以預測下一個文本 token 作為訓練目標,而對視覺模態(tài)缺乏監(jiān)督。這樣的訓練目標也限制了模型在推理應用時只能輸出文本回復,而不具有生成圖片回復的能力。
此外,數(shù)據(jù)直接影響到模型的搭建,視頻數(shù)據(jù)愈來愈成為圖像信息時代的主要信息形態(tài)。帶有交錯圖像字幕的視頻數(shù)據(jù),相比于圖文交錯文檔,天然包含更密集的視覺信號,且與文本編碼有更強的跨模態(tài)關聯(lián)性。而現(xiàn)有工作主要利用圖像 - 文本對及圖文文檔進行訓練,對視頻數(shù)據(jù)有所忽略。
如何把海量多模態(tài)數(shù)據(jù)包括視頻數(shù)據(jù)納入一個更加「統(tǒng)一」的多模態(tài)學習框架,從而提升多模態(tài)大模型的通用性,智源視覺團隊解決了幾個重要問題:
-
對不同來源的多模態(tài)交錯數(shù)據(jù)進行處理,以自動回歸的方式統(tǒng)一建模。
智源視覺團隊采用的多模態(tài)交錯數(shù)據(jù)具體包括圖像 - 文本對 (LAION-2B、LAION-COCO)、交錯圖像 - 文本數(shù)據(jù) (MMC4)、視頻 - 文本對 (Webvid-10M) 和交錯視頻 - 文本數(shù)據(jù) (YT-Storyboard-1B),將視覺表征與文本序列共同構(gòu)成多模態(tài)序列,并進行統(tǒng)一的自回歸建模。
Emu 以自動回歸的方式統(tǒng)一了不同模態(tài)的建模
-
特別地,Emu 首次采用了海量視頻作為圖文交錯序列數(shù)據(jù)。
視頻訓練數(shù)據(jù)源自研究團隊從 YouTube 上收集的 1800 萬個視頻(非原始視頻,故事板圖像)及其相應的字幕,二者結(jié)合創(chuàng)造了一個按時間戳順序排序的視頻和文本的自然交錯序列。
交錯的視頻 - 文本數(shù)據(jù)
-
預測多模態(tài)序列的下一個元素。
模型訓練方面,Emu 將自回歸地預測多模態(tài)序列中的下一個元素(既包含文本也包含圖像)作為統(tǒng)一的學習目標進行預訓練。在這種不同形式的數(shù)據(jù)、統(tǒng)一形式的目標下完成訓練后。Emu 便成為了一個 “通才” 模型,可以輕松應對各種多模態(tài)任務,包括圖生文以及文生圖。
原文標題:更強更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補全一切」
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術研究所】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關注
關注
2903文章
44275瀏覽量
371266
原文標題:更強更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補全一切」
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術研究所】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
利用OpenVINO部署Qwen2多模態(tài)模型
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測評榜首

云知聲推出山海多模態(tài)大模型
依圖多模態(tài)大模型伙伴CTO精研班圓滿舉辦
智譜AI發(fā)布全新多模態(tài)開源模型GLM-4-9B
人大系初創(chuàng)公司智子引擎發(fā)布全新多模態(tài)大模型Awaker 1.0
李未可科技正式推出WAKE-AI多模態(tài)AI大模型

蘋果發(fā)布300億參數(shù)MM1多模態(tài)大模型
韓國Kakao宣布開發(fā)多模態(tài)大語言模型“蜜蜂”
機器人基于開源的多模態(tài)語言視覺大模型

什么是多模態(tài)?多模態(tài)的難題是什么?

從Google多模態(tài)大模型看后續(xù)大模型應該具備哪些能力
成都匯陽投資關于多模態(tài)驅(qū)動應用前景廣闊,上游算力迎機會!
人工智能領域多模態(tài)的概念和應用場景
大模型+多模態(tài)的3種實現(xiàn)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論