") YOLOv8模型ONNX格式INT8量化輕松搞定
YOLOv8模型ONNX格式INT8量化輕松搞定
ONNX格式模型量化
深度學習模型量化支持深度學習模型部署框架支持的一種輕量化模型與加速模型推理的一種常用手段,ONNXRUNTIME支持模型的簡化、量化等腳本操作,簡單易學,非常實用。 ONNX 模型量化常見的量化方法有三種:動態(tài)量化、靜態(tài)量化、感知訓練量化,其中ONNXRUNTIME支持的動態(tài)量化機制非常簡單有效,在保持模型精度基本不變的情況下可以有效減低模型的計算量,可以輕松實現(xiàn)INT8量化。
動態(tài)量化:此方法動態(tài)計算激活的量化參數(shù)(刻度和零點)。 靜態(tài)量化:它利用校準數(shù)據(jù)來計算激活的量化參數(shù)。 量化感知訓練量化:在訓練時計算激活的量化參數(shù),訓練過程可以將激活控制在一定范圍內(nèi)。當前ONNX支持的量化操作主要有:

Opset版本最低不能低于10,低于10不支持,必須重新轉(zhuǎn)化為大于opset>10的ONNX格式。模型量化與圖結(jié)構(gòu)優(yōu)化有些是不能疊加運用的,模型開發(fā)者應該意識這點,選擇適當?shù)哪P蛢?yōu)化方法。 ONNXRUNTIME提供的模型量化接口有如下三個:
quantize_dynamic:動態(tài)量化 quantize_static:靜態(tài)量化 quantize_qat:量化感知訓練量化
FP16量化
首先需要安裝好ONNX支持的FP16量化包,然后調(diào)用相關接口即可實現(xiàn)FP16量化與混合精度量化。安裝FP16量化支持包命令行如下:
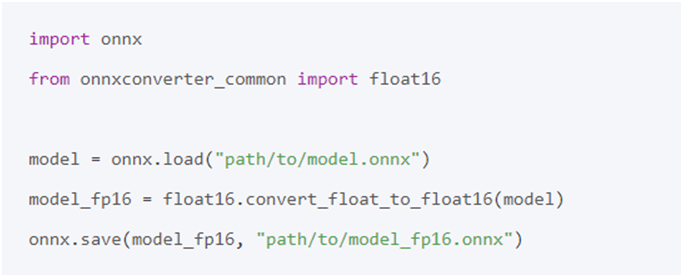
pip install onnx onnxconverter-common
實現(xiàn)FP16量化的代碼如下:
INT8量化
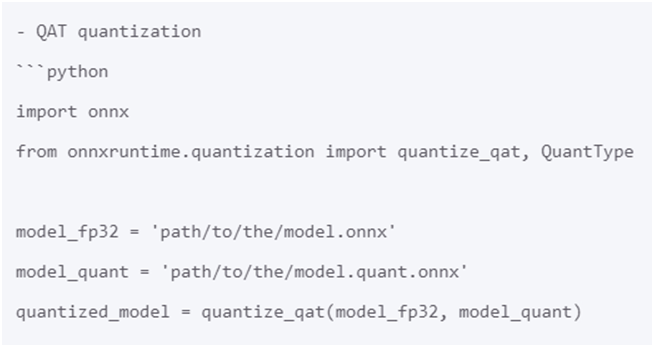
最簡單的量化方式是動態(tài)量化與靜態(tài)量化。選擇感知訓練量化機制,即可根據(jù)輸入ONNX格式模型生成INT8量化模型,代碼如下:
案例說明
YOLOv8自定義模型ONNXINT8量化版本對象檢測演示 以作者訓練自定義YOLOv8模型為例,導出DM檢測模型大小為,對比導出FP32版本與INT8版本模型大小,相關對比信息如下:

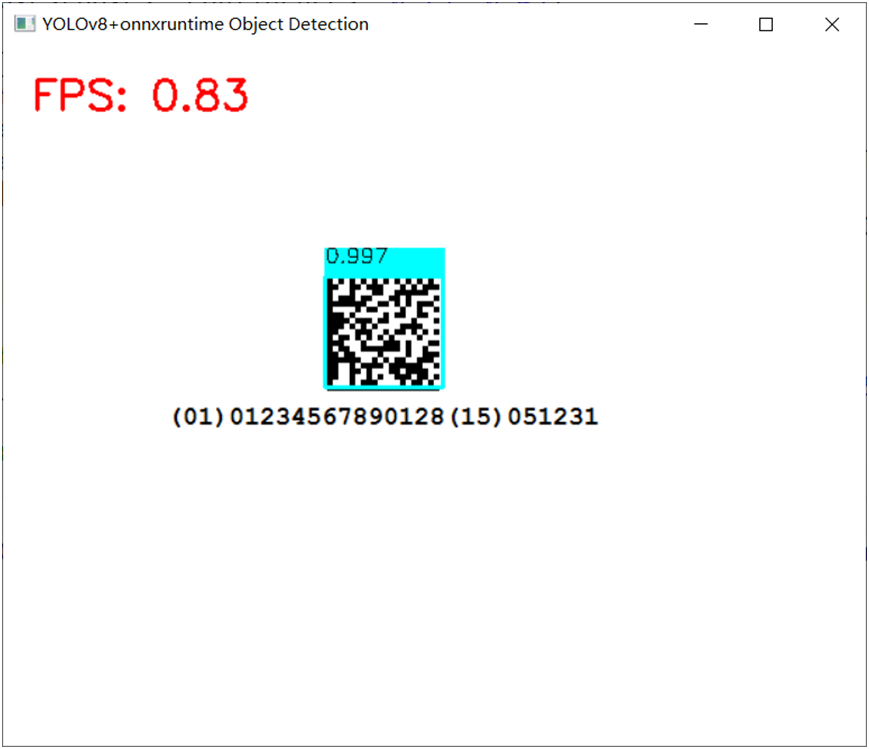
使用FP32版本實現(xiàn)DM碼檢測,運行截圖如下:
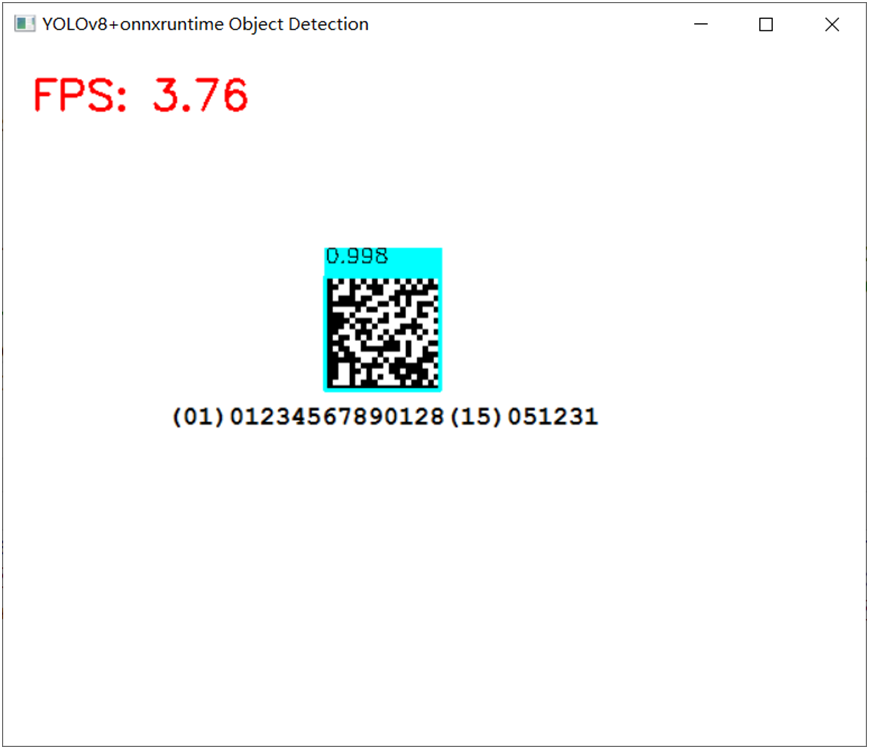
使用INT8版本實現(xiàn)DM碼檢測,運行截圖如下:
ONNXRUNTIME更多演示
YOLOv8對象檢測 C++

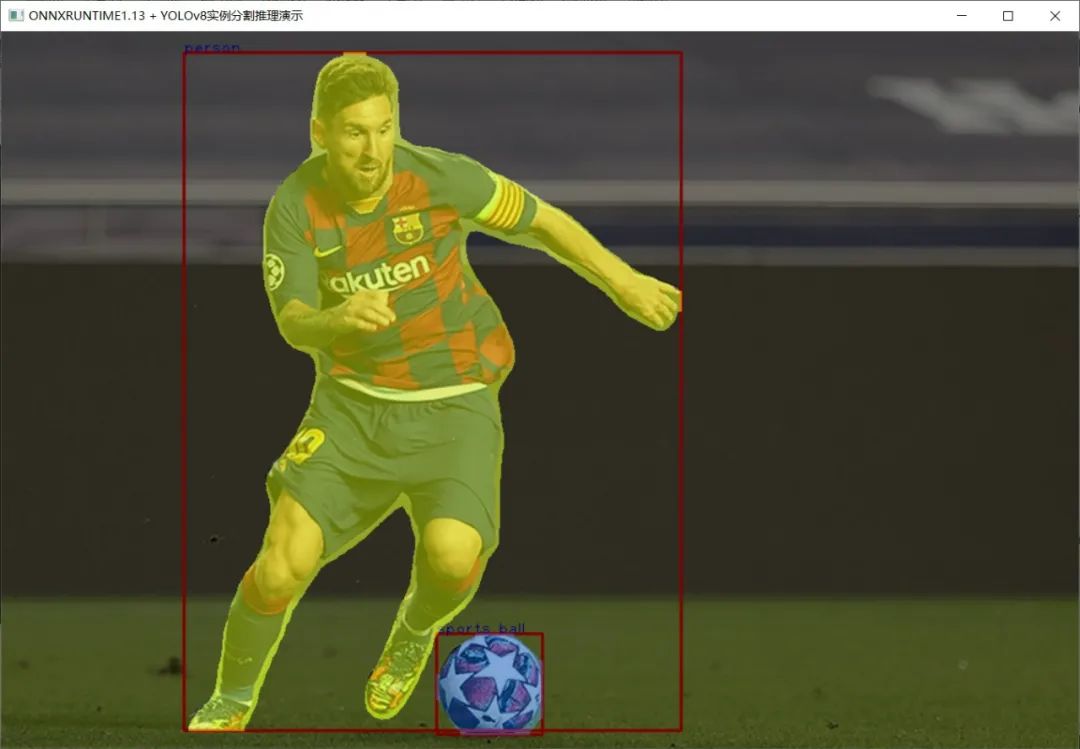
YOLOv8實例分割模型 C++ 推理:
UNet語義分割模型 C++ 推理:

Mask-RCNN實例分割模型 C++ 推理:
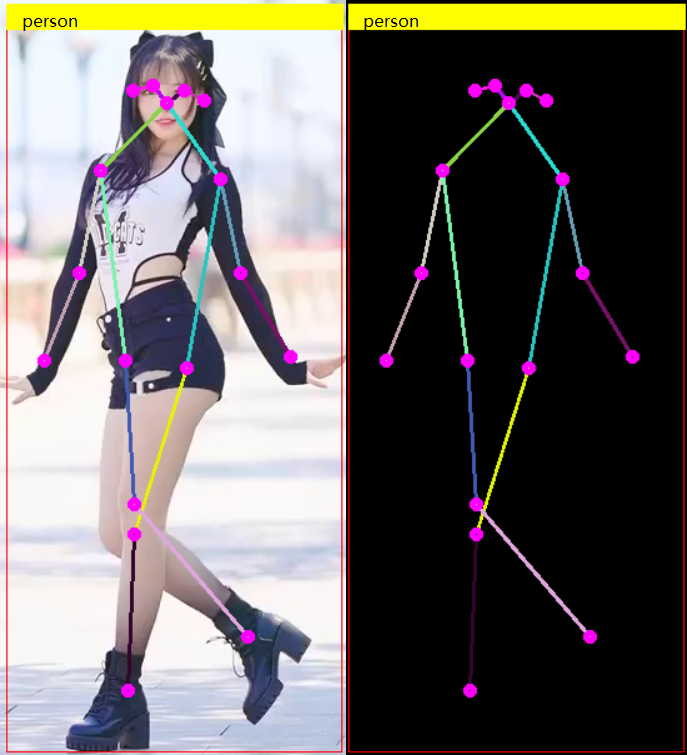
YOLOv8姿態(tài)評估模型 C++ 推理:

人臉關鍵點檢測模型 C++ 推理:


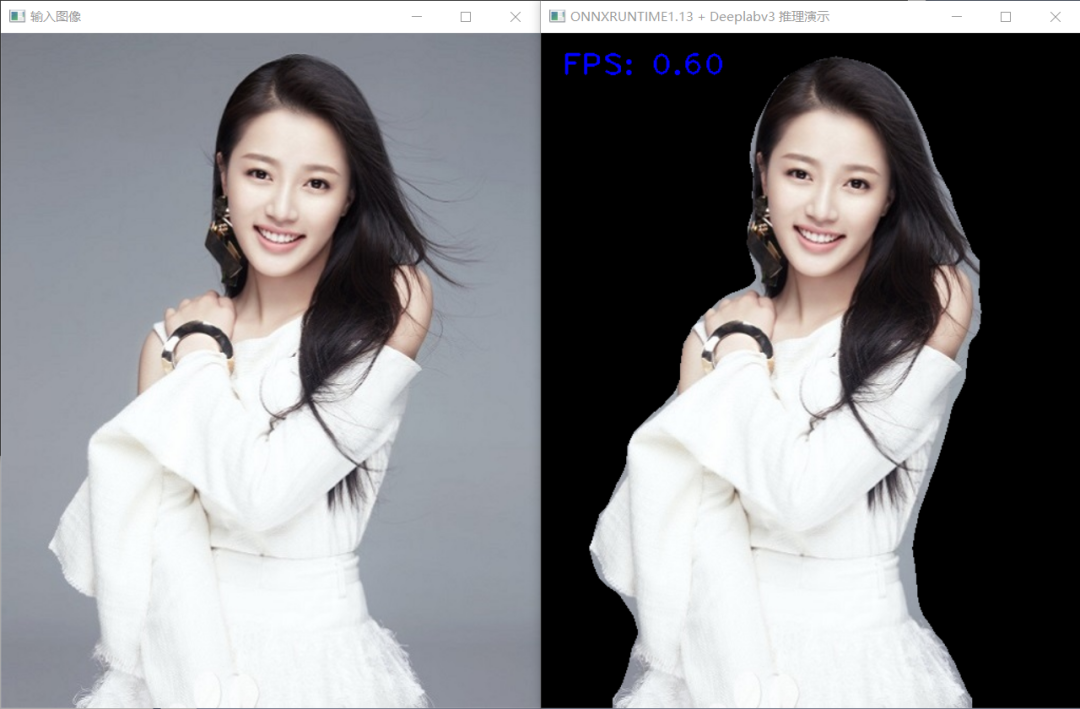
學會用C++部署YOLOv5與YOLOv8對象檢測,實例分割,姿態(tài)評估模型,TorchVision框架下支持的Faster-RCNN,RetinaNet對象檢測、MaskRCNN實例分割、Deeplabv3 語義分割模型等主流深度學習模型導出ONNX與C++推理部署,輕松解決Torchvision框架下模型訓練到部署落地難題。
審核編輯:劉清
-
C++語言
+關注
關注
0文章
147瀏覽量
6969 -
python
+關注
關注
56文章
4782瀏覽量
84451
原文標題:YOLOv8模型ONNX格式INT8量化輕松搞定
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
esp-dl int8量化模型數(shù)據(jù)集評估精度下降的疑問求解?
yolov7 onnx模型在NPU上太慢了怎么解決?
INT8量化常見問題的解決方案
【愛芯派 Pro 開發(fā)板試用體驗】yolov8模型轉(zhuǎn)換
NCNN+Int8+yolov5部署和量化

Int8量化-ncnn社區(qū)Int8重構(gòu)之路
使用YOLOv8做目標檢測和實例分割的演示
YOLOv8自定義數(shù)據(jù)集訓練到模型部署推理簡析
在AI愛克斯開發(fā)板上用OpenVINO?加速YOLOv8目標檢測模型

AI愛克斯開發(fā)板上使用OpenVINO加速YOLOv8目標檢測模型

教你如何用兩行代碼搞定YOLOv8各種模型推理

三種主流模型部署框架YOLOv8推理演示
OpenCV4.8+YOLOv8對象檢測C++推理演示
Yolo系列模型的部署、精度對齊與int8量化加速
基于YOLOv8的自定義醫(yī)學圖像分割






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論