 張俊林:大語言模型帶來的交互方式變革
張俊林:大語言模型帶來的交互方式變革
7 月 8 日,在機器之心舉辦的 2023 WAIC AI 開發者論壇上,新浪微博新技術研發負責人張俊林先生發表了主題演講《自然語言交互:大語言模型帶來的交互方式變革》。在演講中,他主要介紹了大型語言模型為人機交互方式帶來的變革,其中的核心觀點是:無論是人機交互還是 AI 之間的交互,都采用自然語言的方式,由此人操作數據的方式將變得更加簡單與統一。而大語言模型處于人機交互的中心位置,復雜的中間過程將會隱藏到幕后,由語言模型通過 Planning+Programming 的方式解決。
以下為張俊林先生的演講內容,機器之心進行了不改變原意的編輯。
現在國內外很多人都在做大模型;而做大模型考慮的核心問題有兩個:
第一是基座大模型。打造功能強大的基座需要大量數據、算力和資金。盡管 ChatGPT 出來震驚了世界,但主要原因不在基座模型。強大的基座大模型不是在 ChatGPT 出現時橫空出世的,而是慢慢發展起來的 —— 從 2020 年開始國外開發的模型規模逐步增大,效果也在逐漸變好,ChatGPT 的基座大模型可能相比之前效果有所提升,但并沒有發生質的飛躍。所以 ChatGPT 影響力如此大的主要原因不是基座大模型。
第二是大模型的命令理解能力。如果要考慮 ChatGPT 為什么有這么大的影響力這個問題,主要原因在此。ChatGPT 做到了讓大模型能夠理解人的語言和命令,這個可能是最關鍵的因素,也是 ChatGPT 比過去大模型更加獨特的地方。
有一句古詩特別適合形容大模型的這兩個關鍵組件:「舊時王謝堂前燕,飛入尋常百姓家。」
「堂前燕」就是基座大模型,但是在 ChatGPT 時代之前,主要是研究人員在關注和改進。「飛向尋常百姓家」是指 RLHF,也就是 Instruct Learning(指示學習),是 RLHF 讓我們所有人都能用自然語言和大模型進行交互。這樣一來,每個人都能用它,每個人都能體會到它基座模型的強大能力。我認為這是 ChatGPT 可以引起這么大轟動的根本原因。
今天我要分享的主題是「自然語言交互」,我認為這可能是 ChatGPT 為主的大型語言模型(LLM)帶給我們的最根本的變革。
傳統人機交互方式
首先我們看一下傳統的人機交互方式。
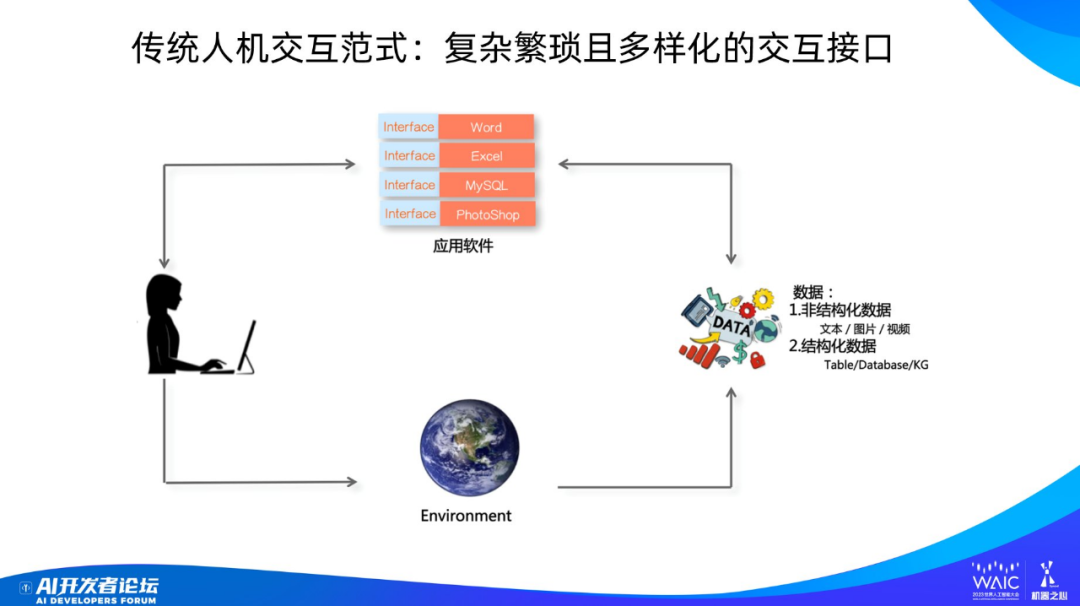
人機交互的本質是人和數據的關系問題。人在環境中進行一些行為,會產生各種類型的數據,這些數據可以分成兩大類:一類是非結構化數據,如文本、圖片、視頻;另一類是結構化數據。企業可能更關注結構化數據,因為企業的內部數據很多都是以數據庫或表格的形式存在的。人需要處理各種類型的數據,典型的行為比如創作、增、刪、改、查等。
在大模型出來之前,人和數據怎么發生關系?人不能直接與數據發生關系,需要通過一個中介,這個中介就是應用軟件。舉個例子,即使你做最簡單的文本編輯,你也需要一個文本編輯器,高級一點的文本處理工具就是 Word;要是做表格就需要 Excel,操作數據庫就需要 MySQL,加工圖像就需要 PhotoShop。
從這里可以看到傳統交互方式的一個特點:處理不同類型的數據要用不同的應用軟件,這是多樣化的一種交互接口。另一個特點是傳統交互方式很復雜繁瑣,很多數據需要專業人士來處理。以處理圖像為例,即使給你提供了 PhotoShop, 普通人可能也很難很好地處理圖像,因為其中涉及到很復雜的操作,需要從多級菜單中找到自己想要的功能,只有經過訓練的專業人士才能勝任。
總結起來,在大模型出現之前,我們和數據的關系以及交互方式是復雜繁瑣且多樣化的。
大模型時代的人機交互方式
大模型出現之后,情況發生了什么本質的變化呢?
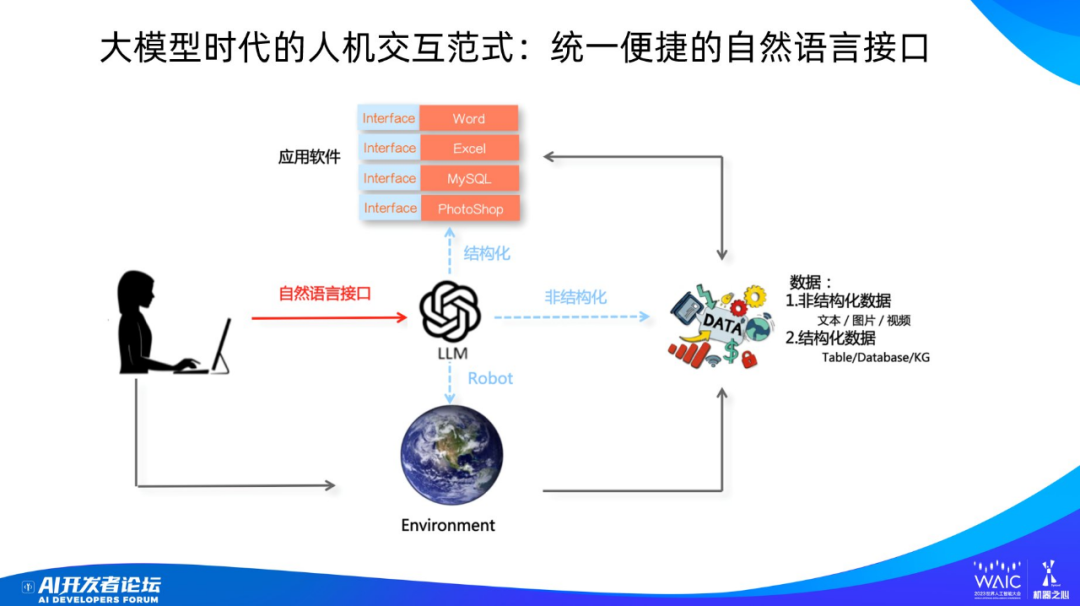
其實關鍵的變化只有一個:大語言模型站到了人機交互的中心位置。
過去人是通過某個應用軟件與某種數據交互,現在變成了人和大模型交互,而且方式很直接、很統一,就是自然語言。也就是說,如果你要做什么事,你就直接跟大模型說就行了。
其實這本質上還是人和數據的關系,只是由于大模型的出現,應用軟件被屏蔽到了幕后。
再看看將來的發展趨勢。短期來看,對于文本類或非結構化的數據,LLM 可以替代一些應用軟件,比如多模態大模型對 PhotoShop 的取代。也就是說,LLM 可以自行完成一些常見任務,不再需要幕后應用的功能支持。目前來看多數結構化數據還是需要對應的管理軟件,只是大模型走到前臺了,管理軟件被隱藏在后臺。而如果把目光放得更長遠一點,大模型可能會逐步替代各種功能軟件,我們若干年以后再看,很可能只有中間的大模型了。
這就是有了大模型之后,人和數據的交互方式出現的根本性變化。這是非常重要的變化。
大模型時代的人機交互看起來非常簡單,如果想做什么事,只需要說就行了,剩下的交給 LLM 去做。但背后的事實是怎樣呢?
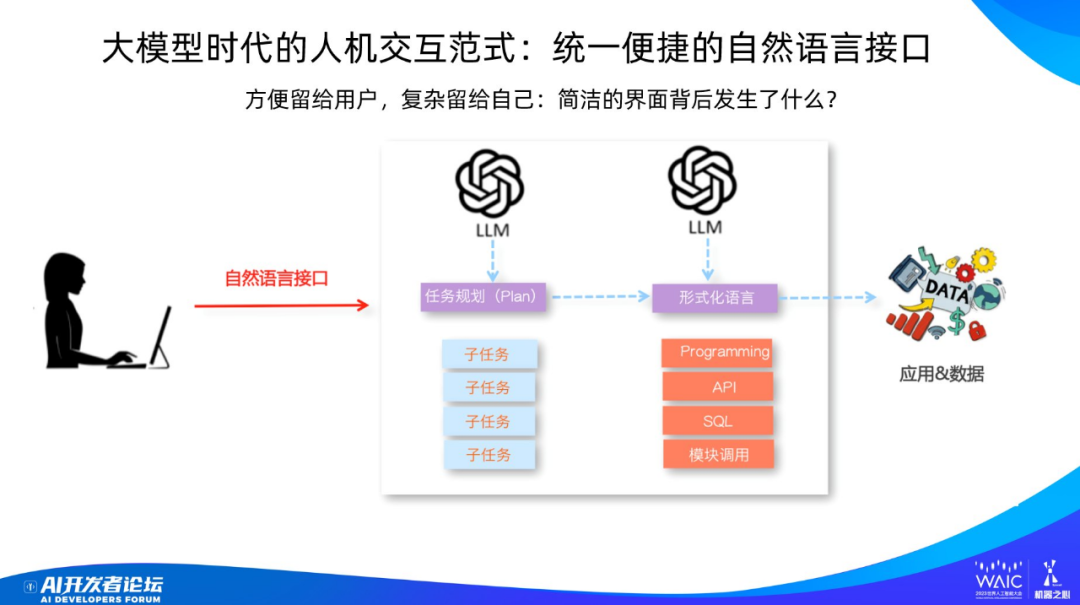
舉個例子說明一下,蘋果公司做的產品口碑特別好,為什么?是因為他們為用戶提供了簡單到極致的操作,而把復雜的部分都隱藏到了幕后。
大模型就和蘋果公司做軟件的思路類似。看起來 LLM 與人的交互模式很簡單,但其實復雜的事情都是 LLM 在背后替用戶做了。
LLM 需要做的復雜事情可分為三大類:
一、理解自然語言。目前大模型的語言理解能力很強,即使小規模的大模型,語言理解能力也非常強。
二、任務規劃。對于復雜的任務,最好的解決方法是把它先拆成若干個簡單任務,然后再逐個解決,一般這樣效果才會好。這就是任務規劃要負責的工作。
三、形式化語言。盡管人和機器交互用的是自然語言,但后續的數據處理一般需要用到形式化語言,比如 Programming(程序)、API、SQL、模塊調用。形式有很多,但歸根結底都是 Programming,因為 API 本質上就是函數調用外部工具,SQL 是一種特殊的程序語言,模塊調用其實就是 API。我相信隨著大模型往后發展,其內部的形式化語言很可能會統一成 Programming 的邏輯。也就是說,復雜任務在規劃成更簡單的子任務后,每個子任務解決方案的外在形式往往是 Programming 或 API 調用這種形式。
下面我們看看針對不同類型的數據,在大模型時代,人和數據是怎么交互的?文本類的就無需多提了,ChatGPT 就是典型。
使用自然語言操作非結構化數據
我們從非結構化的數據說起,首先是圖片。
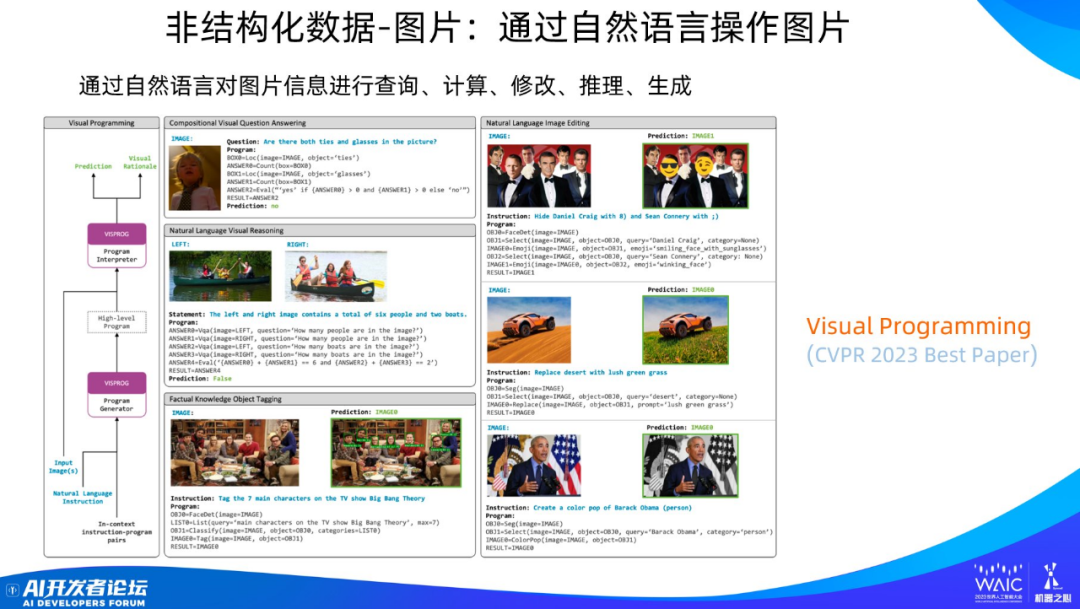
如圖所示,這是典型的 Planning+Programming 模式,可以充分說明上面提到大模型在幕后做的三件事。在這個例子中,人通過語言來操作圖片,包括增刪改查等等。這個工作叫 Visual Programming,獲得了 CVPR 2023 的最佳論文獎。
以圖中下方《生活大爆炸》的劇照為例。用戶提交了一張合影照片,并給大模型提出了一個任務:「在圖片上標記電視劇《生活大爆炸》中 7 個主角的名字」
LLM 怎么完成這個任務呢?首先,LLM 將這個任務映射成程序語句(下面五行)。為什么有五行?這就是 Planning,每一行都是一個子任務,按順序執行。
簡單解釋一下每行程序的含義:第一句程序語句的含義是把這張圖片中的人臉識別出來;第二句是讓語言模型發出一個查詢,找到《生活大爆炸》主角的名字;第三句是讓模型把人臉和人名對應起來,這是分類任務;第四句是讓模型把圖片里的人臉框出來,并且打上名字。第五句輸出編輯好的圖片。
可以看到,這個過程中包含 Planning 和 Programming,它們兩位一體,集成在一起,不太容易看到 Planning 這一步,其實是有的。
對于視頻也是類似。給你一段視頻,你可以用自然語句問問題,比如:「這個視頻里面這個人在干嘛?」
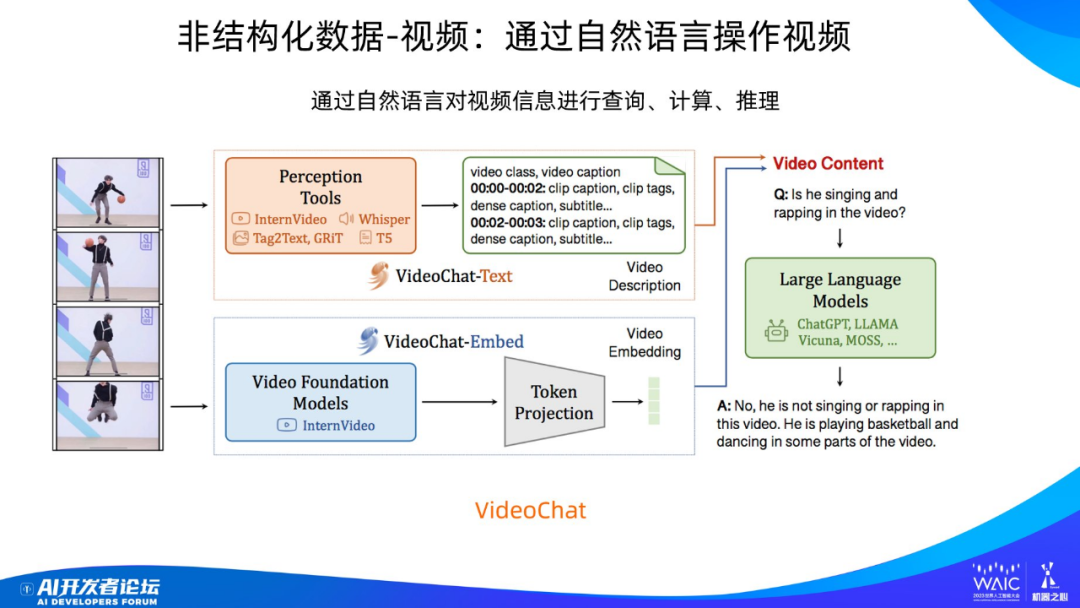
當然,這個任務本質上是一個多模態任務。可以看到,模型首先要對視頻進行編碼,圖中上方是編碼文本信息,下方是編碼視覺信息。其中文本來自于語音識別。所以這是集成了文本和圖片的模型,盡管圖里沒有畫出來,但其內部同樣會做各種規劃以及推理。
這里跑題一下,我談談對多模態大模型的看法。現在大家普遍看好多模態方向,但我個人對多模態大模型的發展沒有大多數人那么樂觀。原因很簡單:雖然現在很多同時處理文本和圖像的模型效果還可以,但究其原因,并不是圖像或視頻技術獲得了突破,而是文本模型能力太強,是它帶著圖像模型在飛。也就是說,從技術能力上講,文本和圖像模型并不對等,而是文強圖弱,以文補圖。實際上現在圖像和視頻方面還有嚴重的技術障礙沒有突破。在圖像處理上方盤旋著一朵 “技術烏云”,如果無法突破,多模態就面臨著陰影和極大障礙,在應用方面很難取得重大進展。
使用自然語言操作結構化數據
下面來看結構化數據,這類數據包含三類典型:表格、SQL、知識圖譜。
首先來看表格。我們能夠通過自然語言操作表格數據,微軟的 Office Copilot 已經做到了。問題是怎么做到的?當然我們不知道微軟到底是怎么做的,但其他研究者也有類似的研究工作。

這里看個例子。對于一張銷售數據表,其中有很多列,列和列之間的數據有關系,比如一列是銷量、一列是單價、一列是銷售額。LLM 能很好地處理表格,因為 LLM 在預訓練模型里面學到很多知識,比如銷售額 = 單價 × 銷量。LLM 能夠利用學到的知識來處理表格數據。
對于這張銷售數據表,用戶可以發出一個查詢:「把銷售額在 200-500 之間的記錄點亮。」
LLM(這里是 GPT-4)首先會把這個任務規劃成子任務,這里是三個子任務:1)先篩選出銷售額在 200-500 之間的條目;2)把背景點亮成藍色;3)把點亮的數據嵌入回表格。
對于第一步的篩選過程,模型是怎么做的呢?這里簡單介紹一下這個流程。首先是寫 prompt。圖中可以看到,這個 prompt 特別長。
現在寫 prompt 已經成為一門學問。有人說 prompt 就像是念咒語,我認為這更像是給大模型做 PUA。我們可以把大模型比作能扮演各種不同類型角色的人,為了讓它做好當前的任務,我們需要把它調整為最適合做這個任務的角色。為此,我們需要寫 prompt 把這個角色誘導出來:「你是很博學的,你特別適合干這個事兒,你應該干的更專業點,不要太隨意。」。諸如此類。
然后再把表格的 schema(即表格每一列的含義)告訴它。GPT-4 就會生成一個 API,這個 API 是一個過濾器,可從所有數據中過濾出滿足 200-500 的數據。但看標紅的地方,模型在生成 API 時參數寫錯了。這時候怎么辦?我們可以給它一些文檔,讓 GPT-4 學習,文檔中有很多例子告訴它這種情況應該怎么調用 API 和寫參數。GPT-4 看完之后,就把 API 改了一下,就改對了。
然后就是執行,就篩選出所需數據。
另一種結構化數據是數據庫。我們的目的是用自然語言操作數據庫,本質上就是將人的自然語言映射成 SQL 語句。

舉個例子,這是谷歌的 SQL-PaLM,基于 PaLM 2。PaLM 2 是谷歌 4 月份重新訓練的一個基座大模型,是為了對標 GPT-4 做的。
SQL-PaLM 操作數據庫的方式有兩種。一是在上下文學習(in-context learning), 也就是給模型一些例子,包括數據庫的 schema、自然語言的問題和對應的 SQL 語句,然后再問幾個新問題,要求模型輸出 SQL 語句。另一種方式是微調(fine-tuning)。
現在這個模型的表現如何呢?在比較復雜的數據庫表上,其準確率為 78%,已經接近實用化水準了。這意味著隨著技術的進一步快速發展,很可能 SQL 語句不需要人寫了;未來你說話把要啥說清楚就行,剩下的交給機器做就可以了。
另一個典型的結構化數據是知識圖譜。問題還是一樣:我們怎樣用自然語言操作知識圖譜?
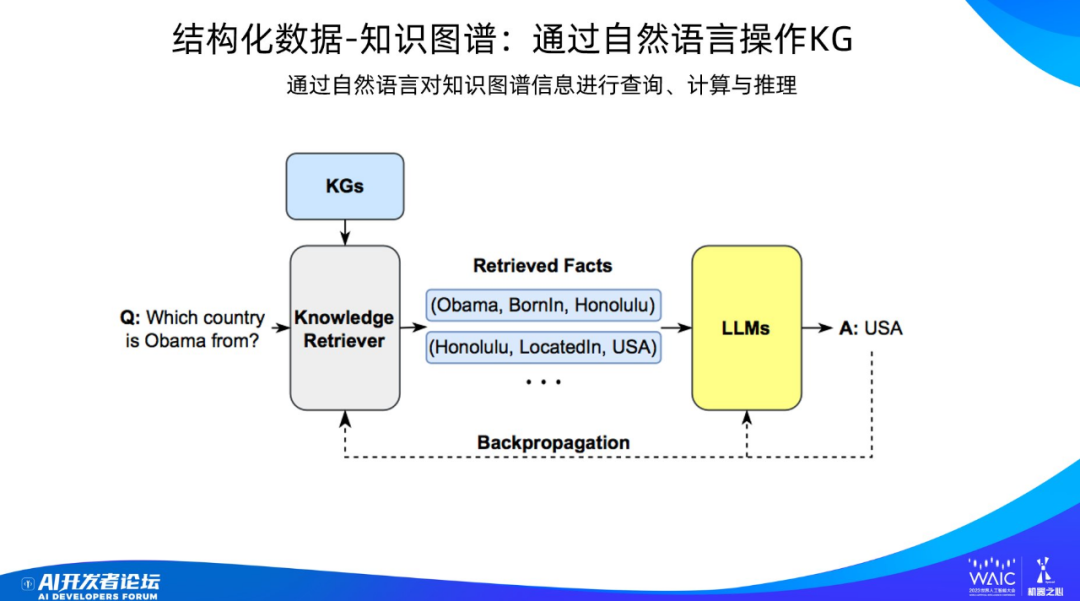
這里用戶提出一個問題:「奧巴馬是哪個國家的?」大語言模型怎么給出答案的?它一樣會進行規劃,把任務拆成知識圖譜可操作的 API;這會查詢得到兩個子知識,再去做推理,就能輸出正確答案「美國」。
大模型和環境的關系
上面講的是人和數據的關系,另外還有大模型和環境的關系。最典型的是機器人,現在一般叫具身智能,也就是說怎么給機器人以大腦,讓機器人在世界里游走。
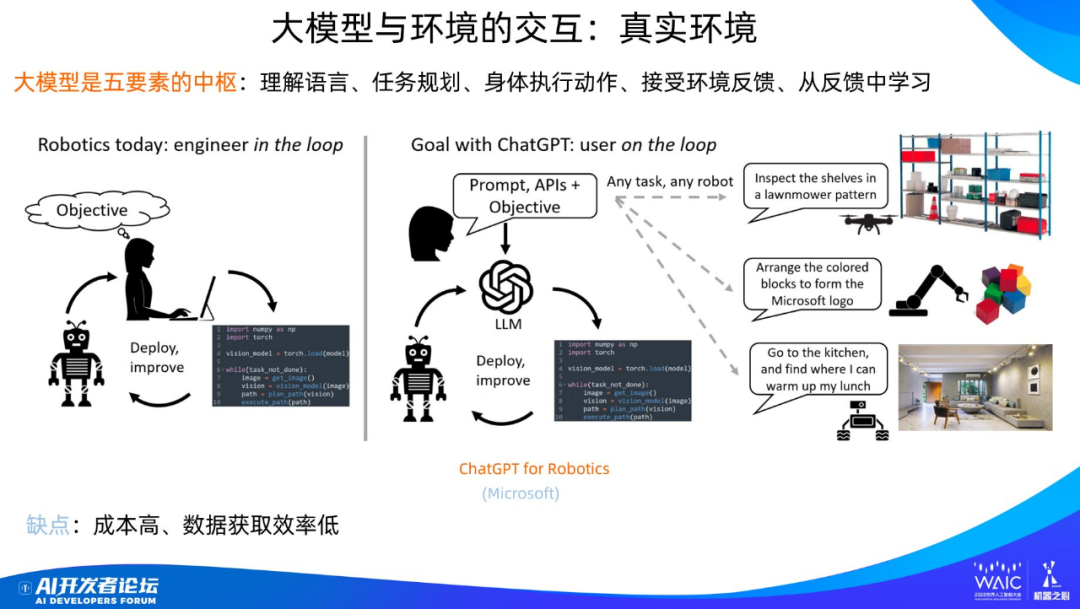
具身智能有五個核心要素:理解語言、任務規劃、身體執行動作、接受環境反饋、從反饋中學習。
大模型階段的具身智能和之前最大的不同是這五個環節的核心現在都可由大模型接管。如果你要指揮機器人,只需用自然語言發出需求即可,所有這五個步驟都由大模型去規劃與控制。大模型可以給機器人一個強大的大腦,更好理解人類的語言與命令,使用大模型學到的世界知識指導行為,在這些方面比以前的方法有質的提升。
但是有一個問題:很多研究人員并不看好這個方向。原因是什么?如果你要用實體機器人在現實生活中學習鍛煉,會面臨成本高、數據獲取效率低的問題,因為實體機器人非常貴,在真實世界里行動范圍有限,獲取數據的效率非常低,學習的速度就慢,而且還不能摔倒,因為摔倒意味著很大一筆維修費。
更多人的做法是創造一個虛擬環境,讓機器人在虛擬環境中探索。虛擬環境能緩解成本高、數據獲取效率低的問題。《我的世界》就是一個常用的虛擬環境。這是一個開放世界,類似于荒野求生,游戲角色在里面學會更好地生存就行了,所以特別適合用來代替機器人在真實世界的活動。
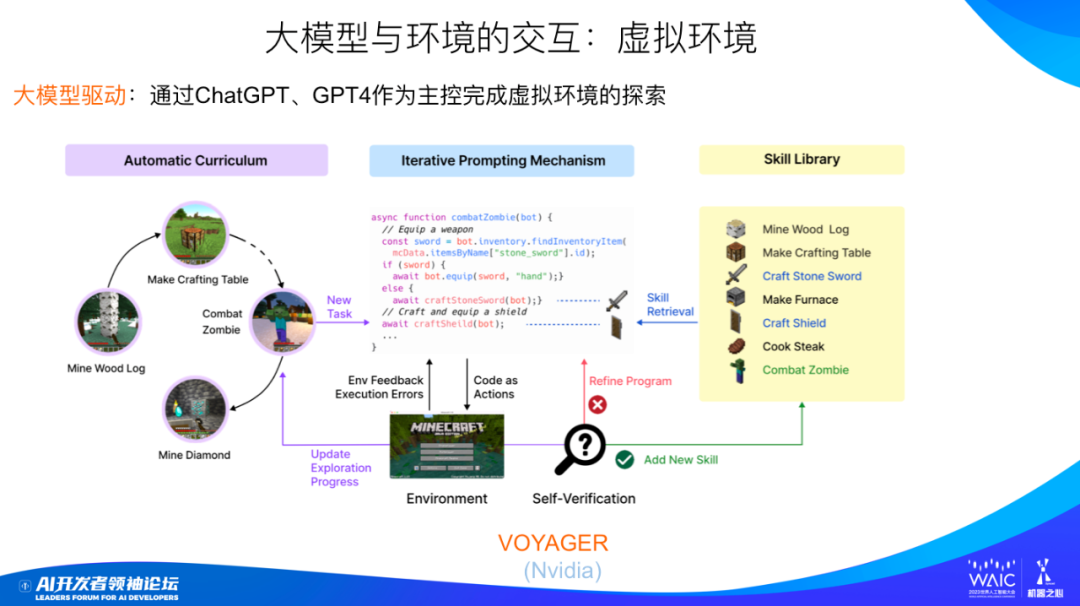
虛擬環境的成本非常低,數據獲取效率非常高。但也有問題:虛擬世界的復雜性遠遠比不上真實世界。
英偉達開發的 Voyager 就是讓機器人在《我的世界》里對陌生環境進行探索,它背后起到最主要驅動作用的大模型也是基于 GPT-4,機器人和 GPT-4 之間也是通過自然語言進行交流。圖中左側可以看到,模型會循序漸進、由易到難地學做各種不同任務難度的事,從最簡單的伐木到后面做桌子、打僵尸等,一般機器學習語境下,我們把這種 “由易到難、循序漸進” 的學習模式叫做 “課程學習”。而 “課程學習” 這些任務都是由 GPT-4 根據當前狀態產生的,你只要在 prompt 里 PUA 大模型讓它由易到難地產生下一步任務就行了。
假設現在的任務是打僵尸。面對這個任務,GPT-4 會自動生成能在《我的世界》環境下運行的對應的 “打僵尸” 的函數及程序代碼,在寫這個函數的時候,可以復用解決之前比較簡單任務時形成的工具,比如角色之前學會制作的石劍和盾牌,此時把這些工具通過 API 函數調用來直接使用。形成 “打僵尸” 函數后,可以執行代碼來和環境交互,如果發生錯誤,把錯誤信息反饋給 GPT-4,GPT-4 就會進一步修正程序。假如程序執行成功,那么這些經驗就會作為一個新的知識放到工具庫里面,下一次還能用。之后依據 “課程學習”,GPT-4 會產生下一個更有難度的任務。
未來的大模型
上面是從人和數據的關系,以及大模型和環境的關系角度,來說明自然語言交互無處不在。接下來,我們看下自然語言交互在 AI 和 AI 交互過程中是如何發揮作用的。
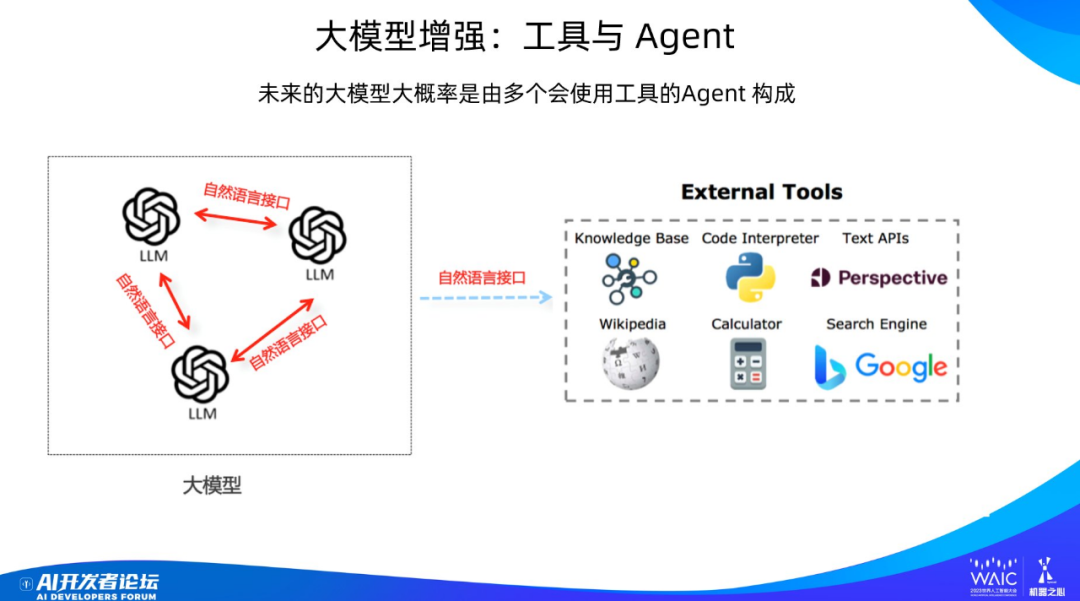
最近大半年基座大模型方面有什么值得關注的研究進展?除了模型規模在繼續變大,總體而言進展不太大,大部分新進展集中在 instruct 部分,這得益于 Meta 開源的 LLaMA 模型。要說基座模型的進展,我認為值得關注的有兩個,一是模型輸入窗口長度的快速增長,這塊技術進展非常快,目前看開源模型 100K 長度甚至更長的輸入很快能夠達到;二是大模型增強。
我相信未來大模型大概率會是上圖這個模式。之前的大模型是靜態的單個大模型,將來的應該是由多個不同角色的智能體(agent)構成的大模型,它們之間通過自然語言進行通訊與交流,一起聯合起來做任務。智能體還可以通過自然語言接口調用外部工具解決現有大模型的缺點,比如數據過時、幻覺嚴重、計算能力弱等。
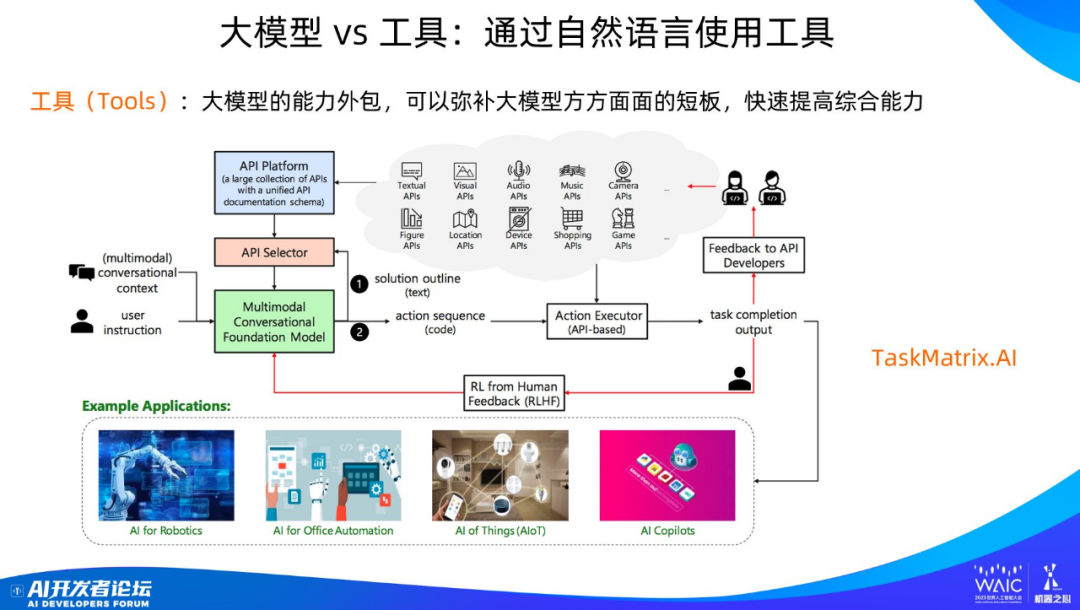
目前大模型使用工具的模式比較統一,如圖所示,可以通過一個 API 管理平臺來管理大量可用的外部工具。用戶給出問題后,模型根據問題需求,判斷是否應該使用工具,如果覺得需要使用工具,則進一步決定需要使用哪個工具,并調用對應工具的 API 接口,填寫對應的參數,調用完成后整合工具返回的結果形成答案,再把答案返回給用戶。
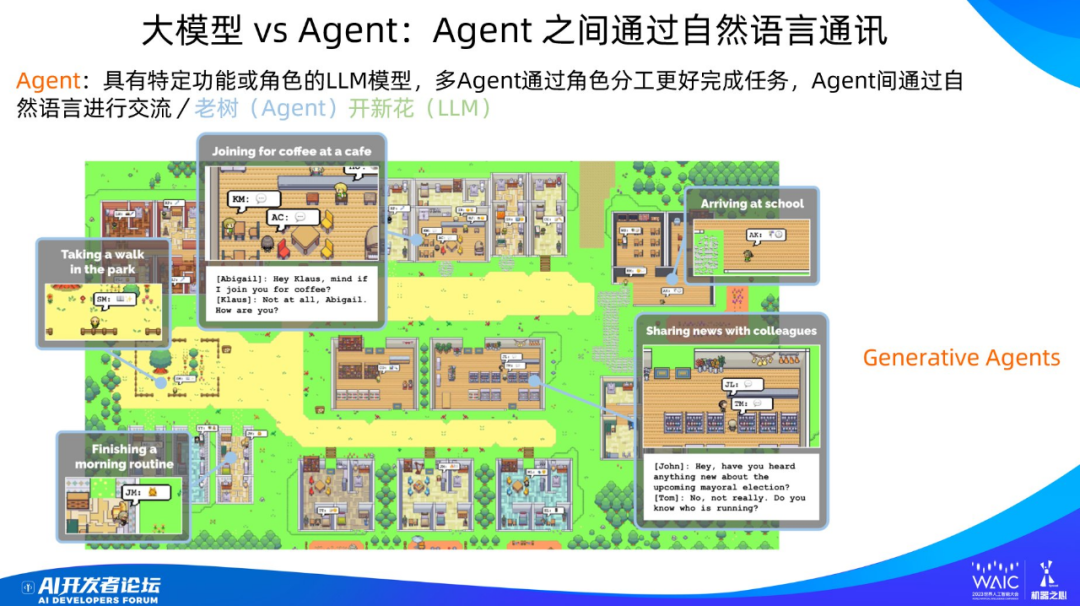
智能體是非常值得關注的技術,但大模型時代的智能體我們目前對其還沒有統一的定義。你可以認為智能體是對大語言模型賦予的不同角色,這些角色通過分工的方式完成任務。智能體是有悠久歷史的研究方向,幾十年歷史肯定有了,只是在大模型時代,由于 LLM 的能力加持,使得智能體有了完全不同的能力,并蘊含著巨大的技術潛力。另外,關于其定義,我覺得傳統的智能體定義可能無法滿足新形勢下的情況,大模型時代可能需要重新定義智能體的含義。
上面展示了一個類似游戲沙盒環境下的模擬人類社會的智能體系統,每個智能體有自己的職業身份,不同智能體可以通過自然語言進行交流,并能舉辦各種聚會活動,看上去就是科幻劇《西部世界》的雛形。

如果歸納下 Agent 之間的協作方式,主要有兩種:競爭型和協作型。競爭型就是不同 Agent 之間互相質疑、爭吵、討論,以此可以得到更好的任務結果。協作型就是通過角色和能力分工,各自承擔任務環節中的一個,通過互相幫助和協作來共同完成任務。
最后我們討論一下自然語言交互的優勢和問題。用自然語言進行交互的好處是比較自然、比較便捷、比較統一,用戶做事情幾乎不需要學習成本;但是自然語言也有模糊性和語言歧義等缺點。
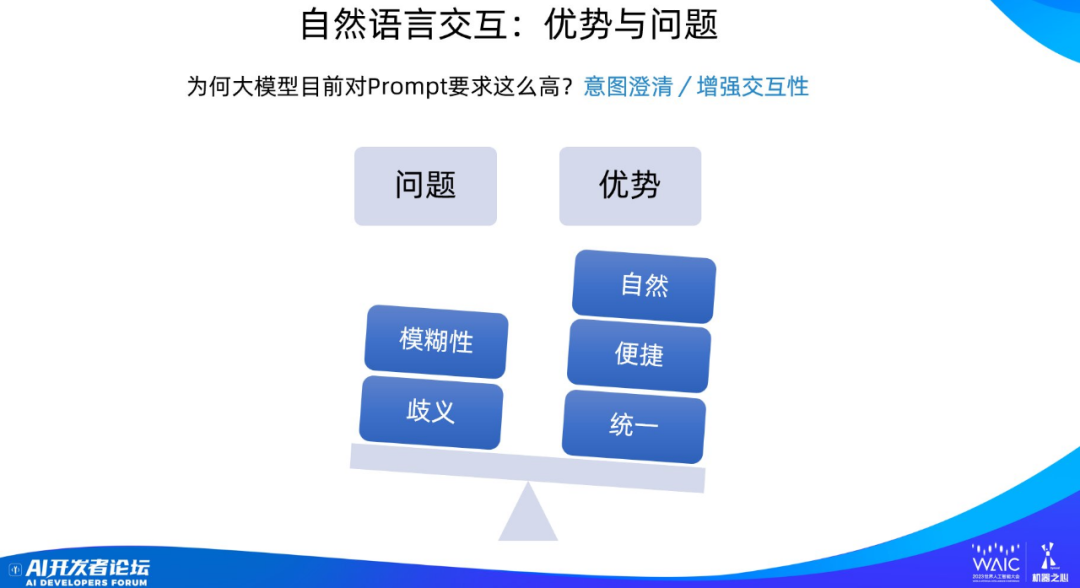
自然語言的模糊性是說有時候你用自然語言不容易講清楚真實的意圖,你以為你說明白了,其實并沒有,但是你未必會意識到你沒說清楚。這也是為什么現在用好大模型對于寫 prompt 的要求比較高,畢竟如果用戶說不清楚自己的意圖,模型也不可能做好。
自然語言的歧義問題是一直存在且普遍存在的。比如「把蘋果拿給我」其實有不同的含義,聽者也可以有不同的理解,你怎么讓大模型知道到底是哪個含義?
考慮到自然語言的模糊性和歧義性,從人機交互的角度來講,將來大模型應該增強交互的主動性,也就是說讓模型主動向用戶發問。如果模型覺得用戶的話有問題,不確定到底什么意思,它應該反問「你到底什么意思」或者「你說的是不是這個意思」。這點是大模型未來應該加強的部分。
-
人機交互
+關注
關注
12文章
1200瀏覽量
55324 -
語言模型
+關注
關注
0文章
508瀏覽量
10245 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7496
原文標題:張俊林:大語言模型帶來的交互方式變革
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
語言模型自動化的優點

如何利用大型語言模型驅動的搜索為公司創造價值

【實操文檔】在智能硬件的大模型語音交互流程中接入RAG知識庫
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
大語言模型:原理與工程時間+小白初識大語言模型
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
對話思爾芯CEO林俊雄:國產EDA的二十年是堅守,也是突破






 工商網監
工商網監
評論