 北大提出MotionBERT:人體運動表征學習的統一視角
北大提出MotionBERT:人體運動表征學習的統一視角
導 讀
本文是對發表于計算機視覺領域頂級會議 ICCV 2023 的論文MotionBERT: A Unified Perspective on Learning Human Motion Representations的解讀。該論文由北京大學王亦洲課題組與上海人工智能實驗室合作完成。
這項工作提出了一個統一的視角,從大規模、多樣化的數據中學習人體運動的通用表征,進而以一個統一的范式完成各種以人為中心的下游視頻任務。實驗表明提出的框架在三維人體姿態估計、動作識別、人體網格重建等多個下游任務上均能帶來顯著提升,并達到現有最佳的表現。
?
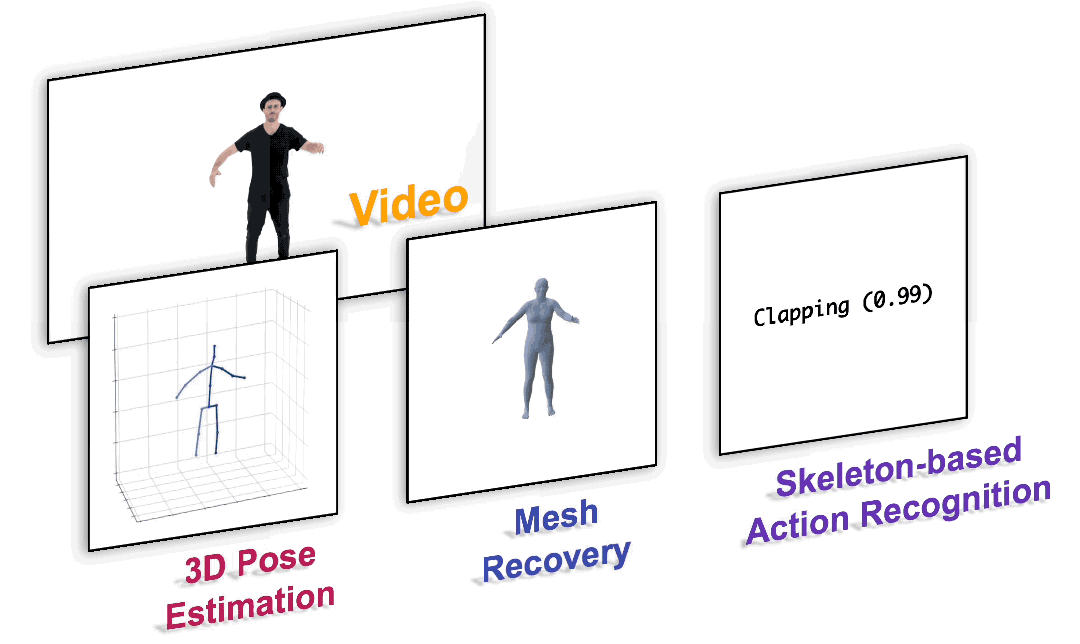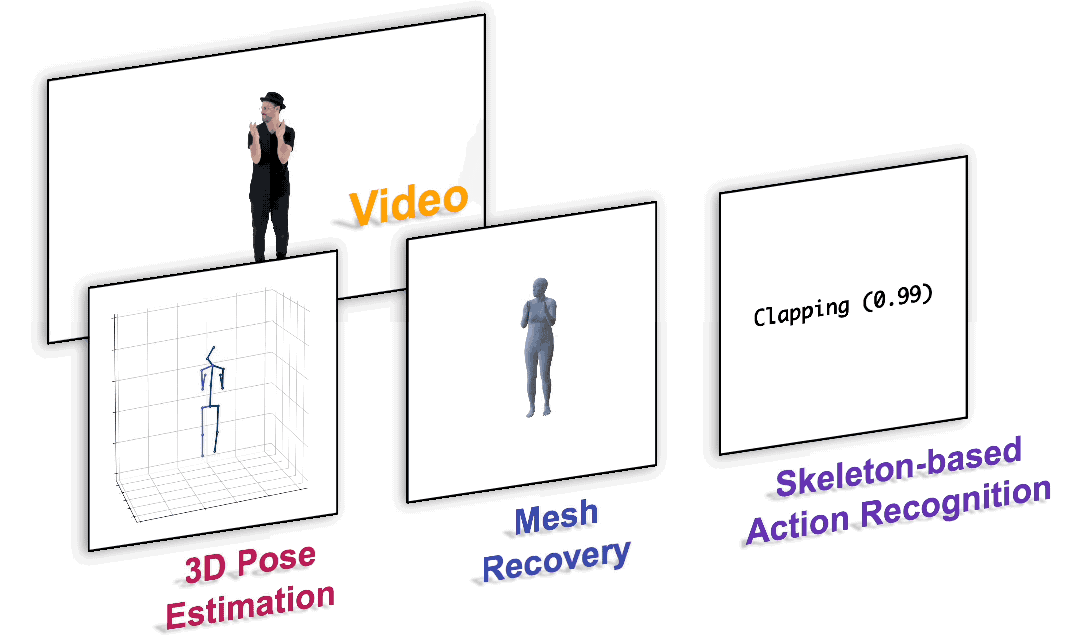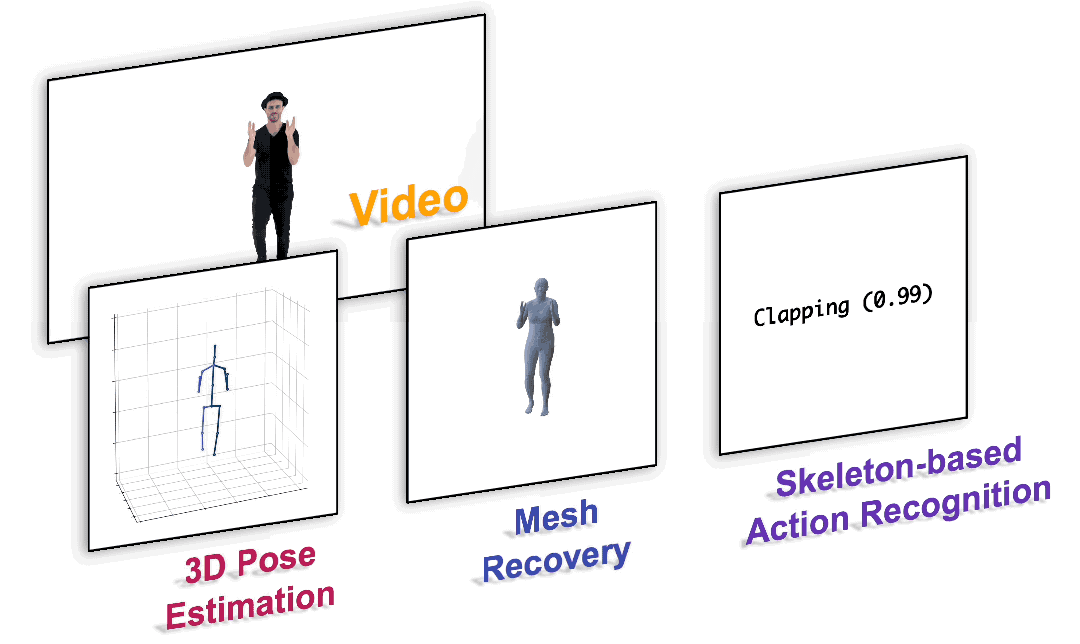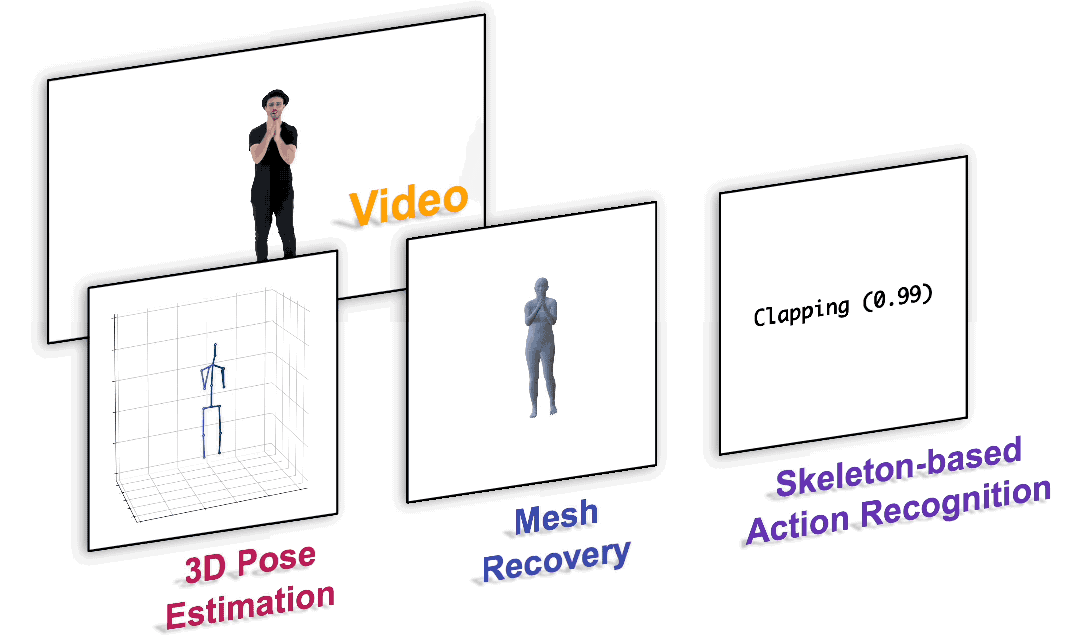
?
圖1. 以統一的范式完成各種以人為中心的視頻任務
01
背景介紹
感知和理解人類活動一直是機器智能的核心追求。為此,研究者們定義了各種任務來從視頻中估計人體運動的語義標簽,例如骨骼關鍵點、行為類別、三維表面網格等。盡管現有的工作在這些任務上已經取得了顯著的進步,但它們往往被建模為孤立的任務。理想情況下,我們可以構建一個統一的以人為中心的運動表征,其可以在所有相關的下游任務中共享。
構建這種表征的一個重要挑戰是人體運動數據資源的異質性。運動捕捉(MoCap)系統提供了基于標記和傳感器的高精度 3D 運動數據,但其內容通常被限制在簡單的室內場景。動作識別數據集提供了動作語義的標注,但它們要么不包含人體姿態標簽,要么只有日常活動的有限動作類別。具備外觀和動作多樣性的非受限人類視頻可以從互聯網大量獲取,但獲取精確的姿勢標注需要額外的努力,且獲取準確真實(GT)的三維人體姿態幾乎是不可能的。因此,大多數現有的研究都致力于使用單一類型的人體運動數據解決某一特定任務,而無法受益于其他數據資源的特性。
在這項工作中,我們提供了一個新的視角來學習人體運動表征。關鍵的想法是,我們可以以統一的方式從多樣化的數據來源中學習多功能的人體運動表征,并利用這種表征以統一的范式處理不同的下游任務。
02
方法概覽
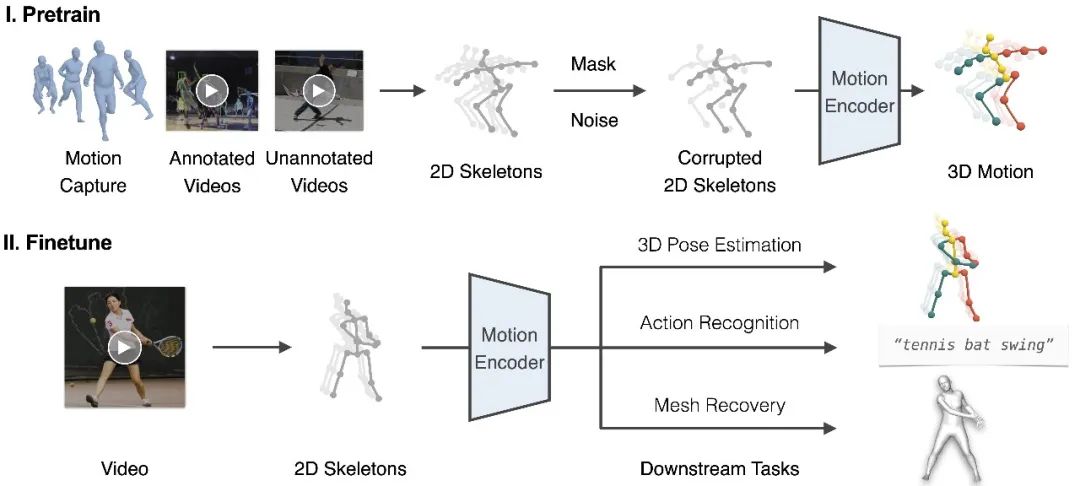
圖2. 框架概覽
我們提出了一個包括預訓練和微調兩個階段的框架,如圖2所示。在預訓練階段,我們從多樣化的運動數據源中提取 2D 關鍵點序列,并添加隨機掩碼和噪聲。隨后,我們訓練運動編碼器從損壞的 2D 關鍵點中恢復 3D 運動。這個具有挑戰性的代理任務本質上要求運動編碼器(i)從時序運動中推斷出潛在的 3D 人體結構;(ii)恢復錯誤和缺失的數據。通過這種方式,運動編碼器隱式地學習到人體運動的常識,如關節拓撲,生理限制和時間動態。在實踐中,我們提出雙流空間-時間變換器(DSTformer)作為運動編碼器來捕獲骨骼關鍵點之間的長距離關系。我們假設,從大規模和多樣化的數據資源中學習到的運動表征可以在不同的下游任務之間共享,并有利于它們的性能。因此,對于每個下游任務,我們僅需要微調預訓練的運動表征以及一個簡單的回歸頭網絡(1-2層 MLP)。
在設計統一的預訓練框架時,我們面臨兩個關鍵挑戰:
如何構建合適的代理任務(pretext task)學習的運動表征。
如何使用大規模但異質的人體運動數據。
針對第一個挑戰,我們遵循了語言和視覺建模的成功實踐[1]來構建監督信號,即遮蔽輸入的一部分,并使用編碼的表征來重構整個輸入。我們注意到這種“完形填空”任務在人體運動分析中自然存在,即從 2D 視覺觀察中恢復丟失的深度信息,也就是 3D 人體姿態估計。受此啟發,我們利用大規模的 3D 運動捕捉數據[2],設計了一個 2D 至 3D 提升(2D-to-3D lifting)的代理任務。我們首先通過正交投影 3D 運動來提取 2D 骨架序列 x。然后,我們通過隨機遮蔽和添加噪聲來破壞 x,從而產生破壞的 2D 骨架序列,這也類似于 2D 檢測結果,因為它包含遮擋、檢測失敗和錯誤。在此之后,我們使用運動編碼器來獲得運動表征并重建 3D 運動。
對于第二個挑戰,我們注意到 2D 骨架可以作為一種通用的中介,因為它們可以從各種運動數據源中提取。因此,可以進一步將 RGB 視頻納入到 2D 到 3D 提升框架以進行統一訓練。對于 RGB 視頻,2D 骨架可以通過手動標注或 2D 姿態估計器給出。由于這一部分數據缺少三維姿態真值(GT),我們使用加權的二維重投影誤差作為監督。
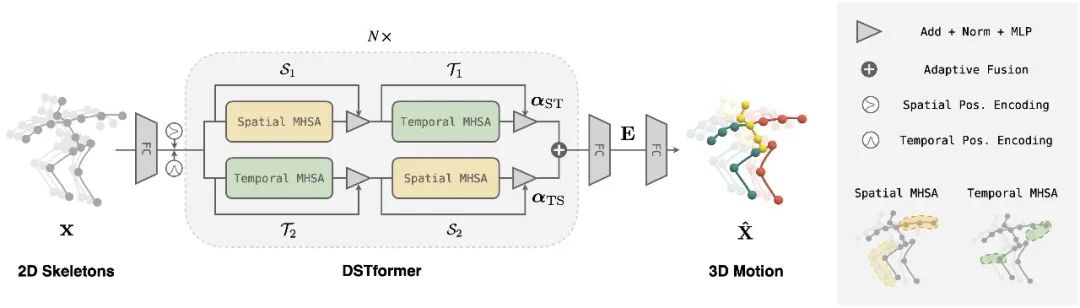
圖3. DSTformer 網絡結構
在運動編碼器的具體實現上,我們根據以下原則設計了一個雙流時空變換器(DSTformer)網絡結構(如圖3所示):
兩個流都有綜合建模時空上下文信息的能力。
兩個流側重不同方面的時空特征。
將兩個流融合在一起時根據輸入的時空特征動態平衡融合權重。
03
實驗結論
我們在三個下游任務上進行了定性和定量的評估,所提出的方法均取得了最佳表現。
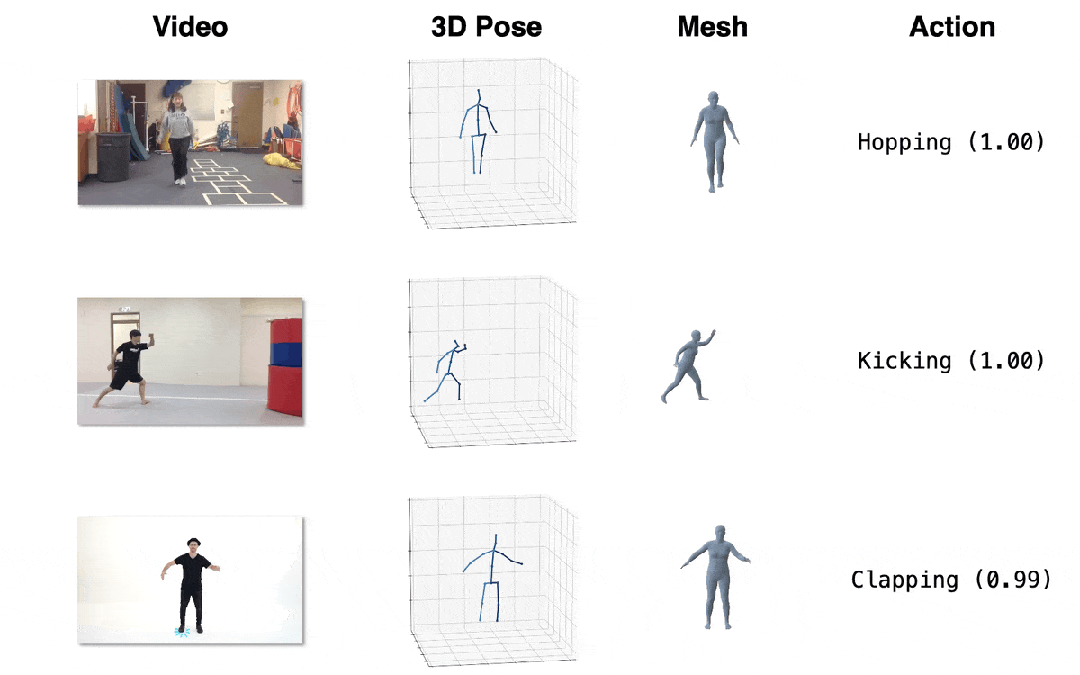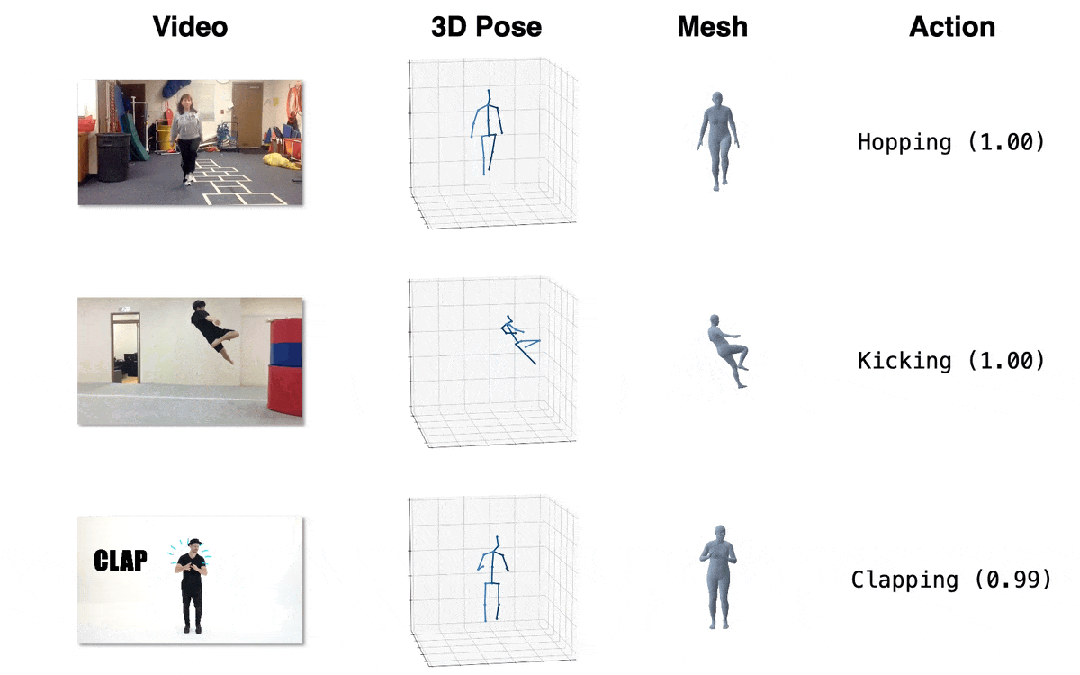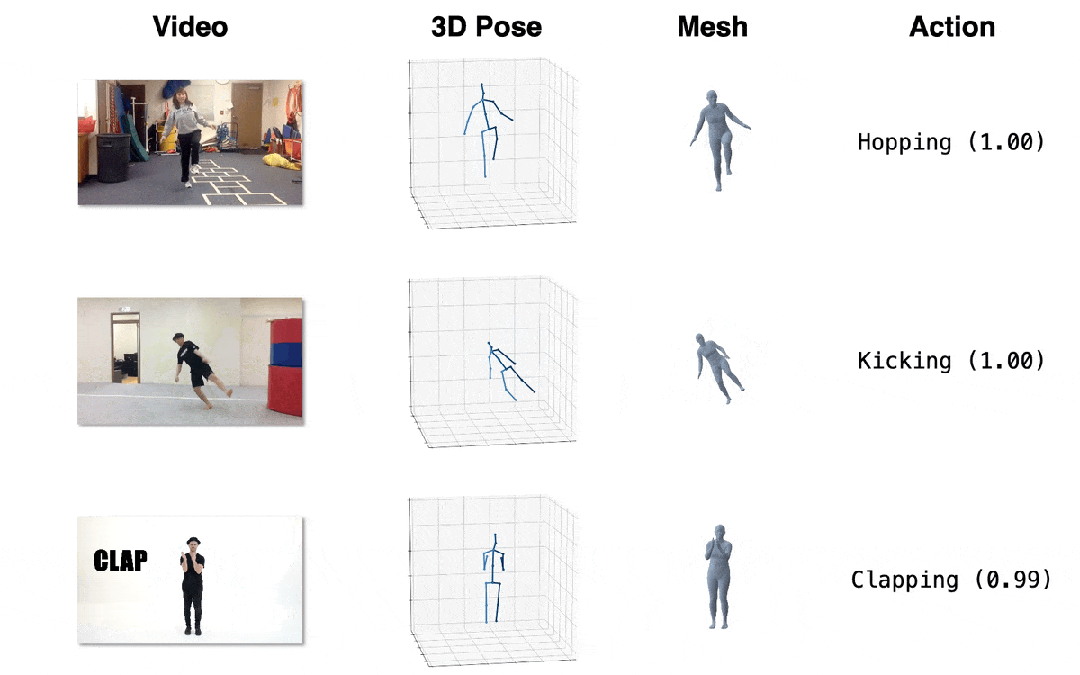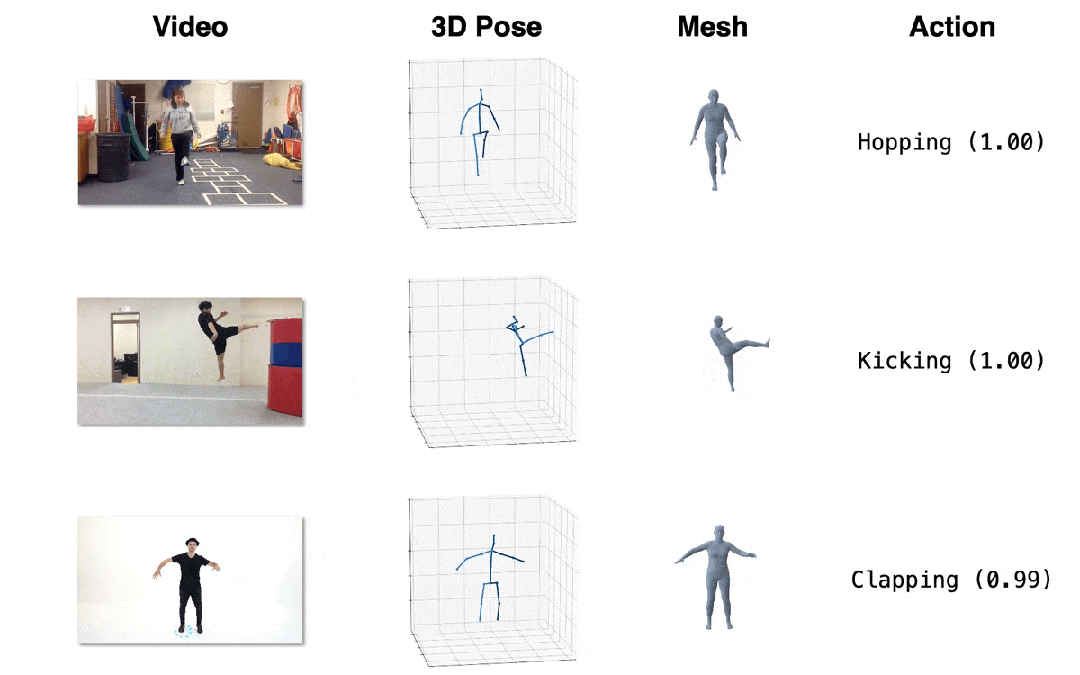
圖4. 效果展示
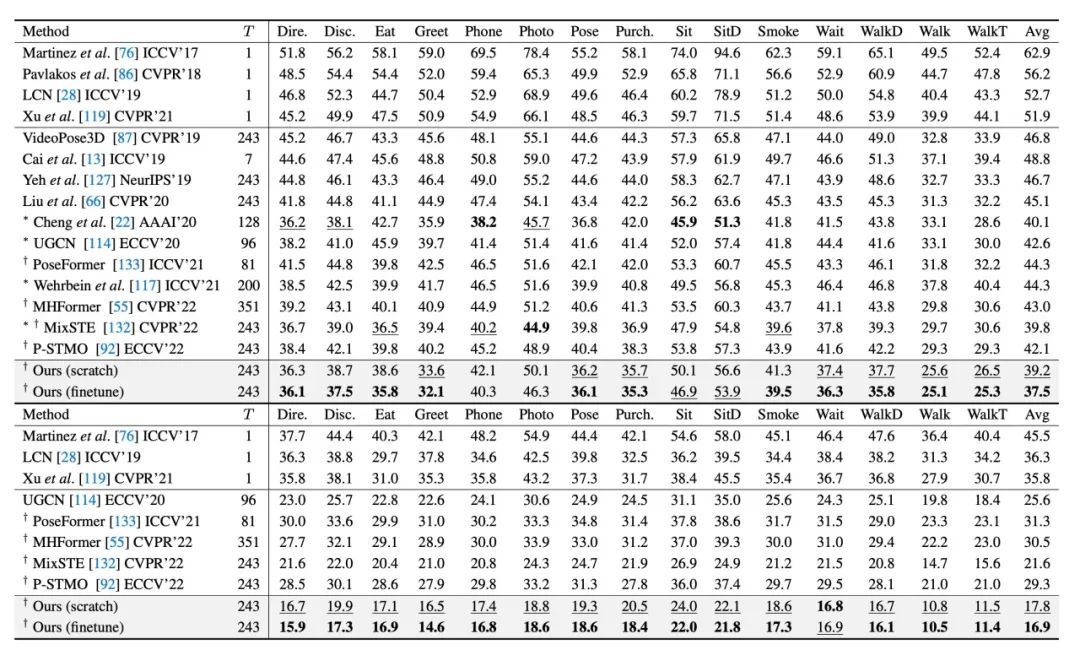
表1. 三維人體姿態估計的定量評估。數字代表 Human3.6M 上的平均關節誤差 MPJPE(mm)。(上)使用檢測到的 2D 姿態序列作為輸入。(下)使用真值(GT)2D 姿態序列作為輸入。
對于三維人體姿態估計任務,我們在 Human3.6M[3]上進行了定量測試。如表1所示,本文的兩個模型都優于最先進的方法。所提出的預訓練運動表征額外降低了誤差,這證明了在廣泛而多樣的人體運動數據上進行預訓練的好處。
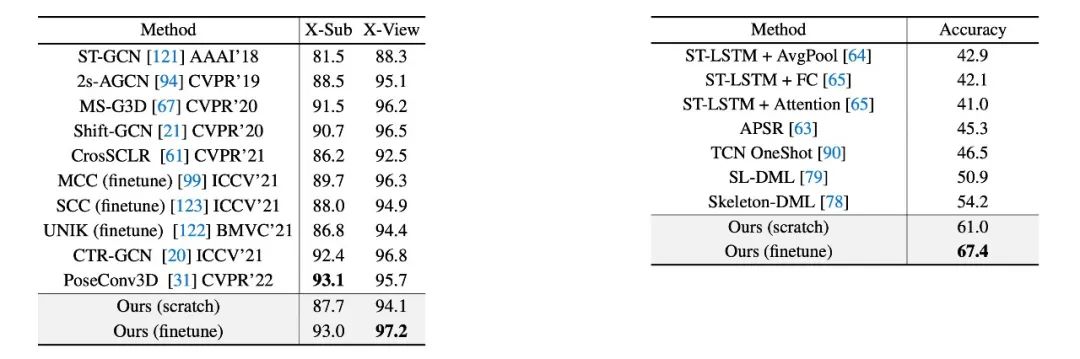
表2. 基于骨架的動作識別準確度的定量評估。(左)NTU-RGB+D 上的跨角色(X-Sub)和跨視角(X-View)識別準確度。(右)NTU-RGB+D-120 上的單樣本學習識別精度。所有結果都是第一選項準確度(%)。
對于基于骨架的動作識別任務,我們在 NTU-RGB+D[4]和 NTU-RGB+D-120[5]上進行了定量測試。在完全監督的場景下本文的方法與最先進的方法相當或更好,如表2(左)所示。值得注意的是,預訓練階段帶來了很大的性能提升。此外,本文研究了可用于未見動作和稀缺標簽的單樣本學習設置。表2(右)說明所提出的模型大幅度優于此前最佳的模型。值得注意的是,預訓練運動表征只需1-2輪微調即可達到最佳性能。
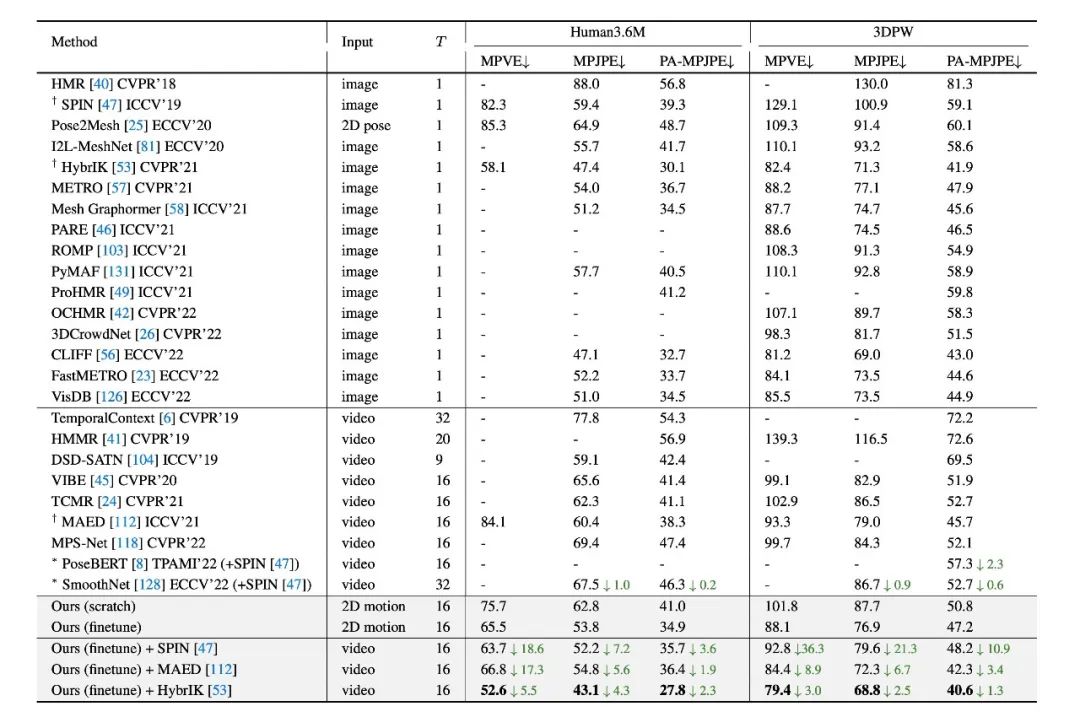
表3. 人體表面網格重建的定量評估。數字代表平均三維位置誤差(mm)。
對于人體表面網格重建任務,我們在 Human3.6M[3] 和 3DPW[6]數據集上進行了定量測試。本文的模型超過了此前所有基于視頻的方法。此外,所提出的預訓練運動表征可以和 RGB 圖像的方法相結合并進一步改善其表現。
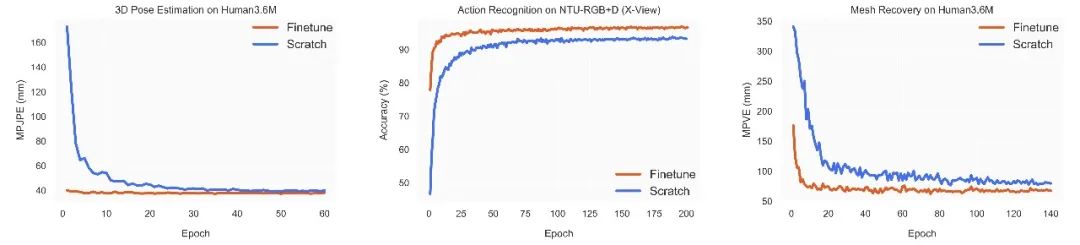
圖5. 在三個下游任務上隨機初始化訓練和微調預訓練運動表征的學習曲線對比。
我們還比較了微調預訓練運動表征和隨機初始化訓練模型的訓練過程。如圖5所示,使用預訓練運動表征的模型在所有三個下游任務上都具有更好的性能和更快的收斂速度。這表明該模型在預訓練期間學習了關于人體運動的可遷移知識,有助于多個下游任務的學習。
04
總 結
在這項工作中,我們提出了:
一個統一的視角以解決各種以人為中心的視頻任務。
一個預訓練框架以從大規模和多樣化的數據源中學習人體運動表征。
一個通用的人體運動編碼器 DSTformer 以全面建模人體運動的時空特征。
在多個基準測試上的實驗結果證明了學習到的運動表征的多功能性。未來的研究工作可以探索將學習到的運動表征作為一種以人為中心的語義特征與通用視頻架構融合,并應用到更多視頻任務(例如動作評價、動作分割等)。
-
編碼器
+關注
關注
45文章
3595瀏覽量
134157 -
模型
+關注
關注
1文章
3172瀏覽量
48713 -
數據源
+關注
關注
1文章
62瀏覽量
9665
原文標題:ICCV 2023 | 北大提出MotionBERT:人體運動表征學習的統一視角
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多站低頻雷達運動人體微多普勒特征提取與跟蹤技術【論文干貨】
人體上肢運動表面肌電特征研究
基于多區域的人體運動跟蹤研究

監測人體健康和運動表現
基于多區域的人體運動跟蹤分析
基于塊稀疏模型的人體運動模式識別方法
基于多視角自步學習的人體動作識別方法





 工商網監
工商網監
評論