") PVT++:通用的端對端預(yù)測性目標(biāo)跟蹤框架
PVT++:通用的端對端預(yù)測性目標(biāo)跟蹤框架
本文提出通用的端對端預(yù)測性跟蹤框架PVT++,旨在解決目標(biāo)跟蹤的部署時的延遲問題。多種預(yù)訓(xùn)練跟蹤器在PVT++框架下訓(xùn)練后“在線”跟蹤效果大幅提高,某些情況下甚至取得了與“離線”設(shè)定相當(dāng)?shù)男Ч?/p>

PVT++ 論文:https://arxiv.org/abs/2211.11629 代碼:https://github.com/Jaraxxus-Me/PVT_pp
引言
單目標(biāo)跟蹤(SOT)是計算機(jī)視覺領(lǐng)域研究已久的問題。給定視頻第一幀目標(biāo)的初始位置與尺度,目標(biāo)跟蹤算法需要在后續(xù)的每一幀確定初始目標(biāo)的位置與尺度。將這類視覺方法部署在機(jī)器人上可以實(shí)現(xiàn)監(jiān)測、跟隨、自定位以及避障等智能應(yīng)用。大多數(shù)目標(biāo)跟蹤算法的研究與評估都基于“離線”假設(shè),具體而言,算法按照(離線)視頻的幀號逐幀處理,得出的結(jié)果與對應(yīng)幀相比以進(jìn)行準(zhǔn)確率/成功率計算。
然而,這一假設(shè)在機(jī)器人部署中通常是難以滿足的,因?yàn)樗惴ū旧淼难舆t在機(jī)器人硬件上不可忽視,當(dāng)算法完成當(dāng)前幀時,世界已經(jīng)發(fā)生了變化,導(dǎo)致跟蹤器輸出的結(jié)果與實(shí)際世界的目標(biāo)當(dāng)前狀態(tài)不匹配。換言之,如圖二(a) 所示,由于算法的延遲總存在(即使算法達(dá)到實(shí)時幀率),輸出的結(jié)果“過時”是不可避免的。
這一思想起源于ECCV2020 “Towards Streaming Perception”。
由于機(jī)載算力受限,平臺/相機(jī)運(yùn)動劇烈,我們發(fā)現(xiàn)這一問題在無人機(jī)跟蹤中尤為嚴(yán)重,如圖一所示,相比“離線”評估,考慮算法延遲的“在線”評估可能使得其表現(xiàn)大幅下降。
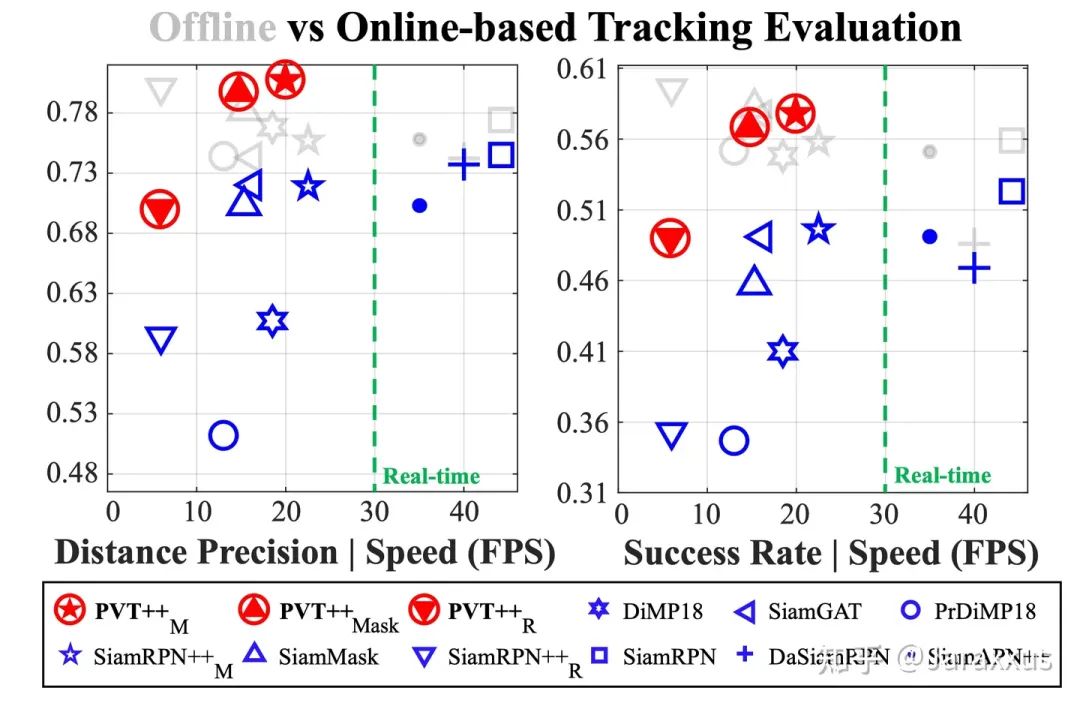
圖一. “離線”評估與“在線”評估中各個跟蹤器的表現(xiàn)以及PVT++在“在線”跟蹤中的效果。灰色圖標(biāo)代表離線評估,藍(lán)色圖標(biāo)代表相同方法在線評估,紅色圖標(biāo)代表相同方法使用PVT++轉(zhuǎn)換為預(yù)測性跟蹤器。
如圖二(b)所示,為解決這一問題,預(yù)測性跟蹤器需要提前預(yù)測世界未來的狀態(tài),以彌補(bǔ)算法延遲導(dǎo)致的滯后性。
這一理論詳見ECCV2020 “Towards Streaming Perception”以及我們過往的工作“Predictive Visual Tracking (PVT)"。
而與以往的在跟蹤器后使用卡爾曼濾波的方法不同,在本文中,我們從跟蹤器能提供的視覺特征出發(fā),研發(fā)了端對端的預(yù)測性目標(biāo)跟蹤框架(PVT++)。我們的PVT++有效利用了預(yù)訓(xùn)練跟蹤器可提供的視覺特征并可從數(shù)據(jù)中學(xué)習(xí)目標(biāo)運(yùn)動的規(guī)律,進(jìn)而做出更準(zhǔn)確的運(yùn)動預(yù)測。
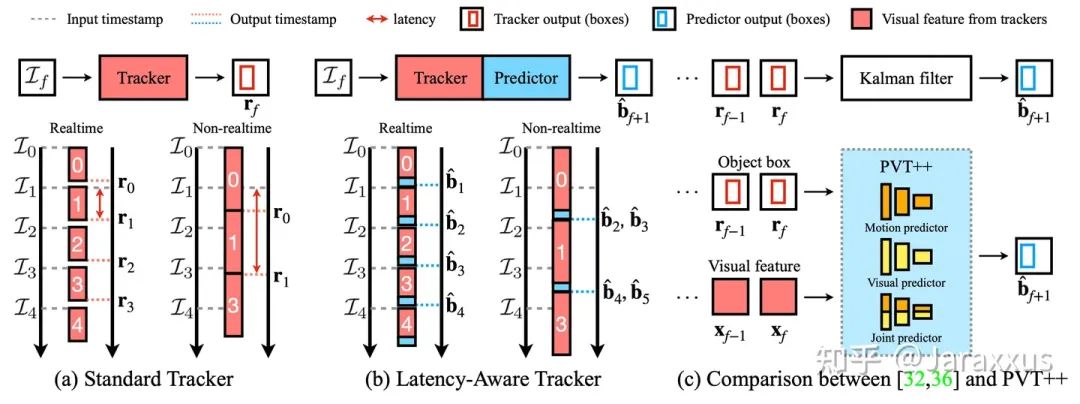
圖二. (a) 常規(guī)的跟蹤器有延遲,所以結(jié)果總是滯后的。(b) 預(yù)測性跟蹤提前預(yù)測世界的狀態(tài),彌補(bǔ)延遲帶來的滯后性。(c) 與基于卡爾曼濾波的方法不同,我們的PVT++有效利用了跟蹤器自帶的視覺特征并可從數(shù)據(jù)中學(xué)習(xí)運(yùn)動的規(guī)律,進(jìn)而做出更準(zhǔn)確的預(yù)測。
PVT++是一個通用的可學(xué)習(xí)框架,能適用不同類型的跟蹤器,如圖一所示,在某些場景下,使用PVT++后甚至能取得與“離線”評估相當(dāng)?shù)摹霸诰€”結(jié)果。
貢獻(xiàn)
我們研發(fā)了端對端的預(yù)測性目標(biāo)跟蹤框架PVT++,該通用框架適用于不同類型的跟蹤器并能普遍帶來大幅效果提升。
為實(shí)現(xiàn)“從數(shù)據(jù)中發(fā)現(xiàn)目標(biāo)運(yùn)動的規(guī)律”,我們提出了相對運(yùn)動因子,有效解決了PVT++的泛化問題。
為引入跟蹤器已有的視覺特征實(shí)現(xiàn)穩(wěn)定預(yù)測,我們設(shè)計了輔助分支 和 聯(lián)合訓(xùn)練機(jī)制,不僅有效利用了跟蹤器的視覺知識而且節(jié)省了計算資源。
除了PVT++方法,我們還提出了能夠進(jìn)一步量化跟蹤器性能的的 新型評估指標(biāo) e-LAE,該指標(biāo)不僅實(shí)現(xiàn)了考慮延遲的評估,而且可以區(qū)分實(shí)時的跟蹤器。
方法介紹
為了將整個問題用嚴(yán)謹(jǐn)?shù)臄?shù)學(xué)公式成體系地定義出來,我們花了很多時間反復(fù)打磨PVT++的方法部分?jǐn)⑹觯欢豢杀苊夥柶嘟Y(jié)構(gòu)也比較復(fù)雜(被reviewer們多次吐槽...),讀起來有些晦澀難懂容易lost,在此僅提供一些我intuitive的想法,以方便讀者能夠更快理解文章的核心思想。
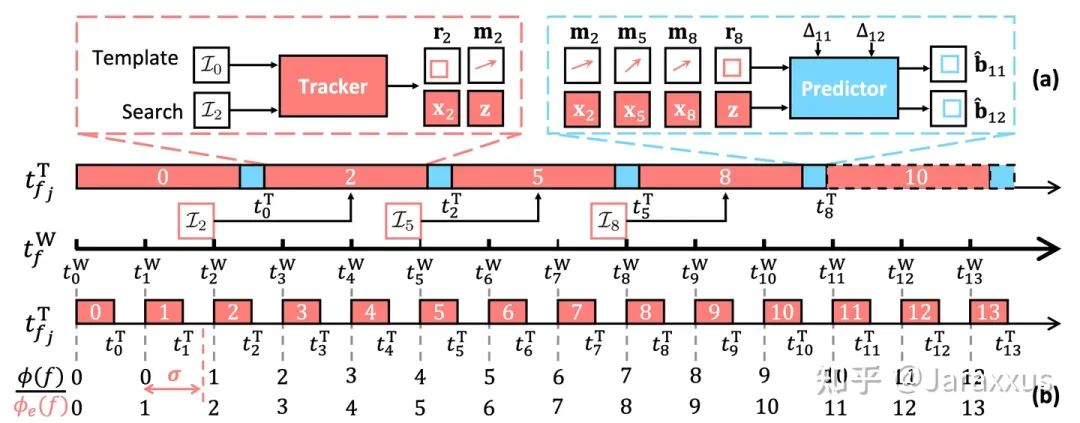
圖三. (a) PVT++宏觀框架與 (b) e-LAE評估指標(biāo)
e-LAE評估指標(biāo)
與“離線”設(shè)定不同,“在線”跟蹤(LAE)依照算法實(shí)際部署的情況設(shè)計,具體而言,其遵循以下兩條原則:

類似的評估方式最早被提出于ECCV2020 “Towards Streaming Perception”,在以前的研究PVT中,我們針對跟蹤算法做了上述調(diào)整。
然而,這樣的評估方式有一個缺陷,假設(shè)算法速度快于世界幀率(例如圖三下方的算法時間戳),無論算法有多快,評估時的算法滯后永遠(yuǎn)是一幀。換言之,假設(shè)有兩個精度一樣的跟蹤器A與B,A的速度>B>世界幀率,那么這樣的評估指標(biāo)得到的A,B的結(jié)果是一樣的,這樣以來,LAE便無法將實(shí)時跟蹤器的速度納入評估中,無法對實(shí)時跟蹤器進(jìn)行有效比較。

基于e-LAE,我們在機(jī)器人平臺AGX Xavier上進(jìn)行了眾多跟蹤器詳盡的實(shí)驗(yàn),涉及17個跟蹤器,三個數(shù)據(jù)集,詳見原文圖五,e-LAE可以區(qū)分一些精度接近而速度有一些差距的實(shí)時跟蹤器,如HiFT與SiamAPN++(原文Remark 2)。我們正在進(jìn)一步檢查所有結(jié)果,最終確認(rèn)后也會將評估的原始結(jié)果開源。
PVT++
無論算法的速度有多快,其延遲總存在,故而我們設(shè)計了端對端預(yù)測性跟蹤框架彌補(bǔ)延遲。如圖三 (a) 所示,PVT++的結(jié)構(gòu)非常直觀簡單,跟蹤器模塊即普通的已有的(基于深度學(xué)習(xí)的)跟蹤算法,預(yù)測器接受跟蹤器輸出的歷史運(yùn)動m ,跟蹤器的歷史視覺特征x,y,以及預(yù)設(shè)的落后幀數(shù)Δ作為輸入,輸出未來幀的目標(biāo)位置。
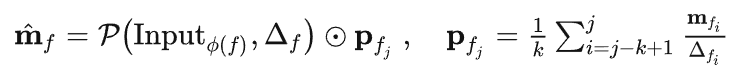
PVT++的結(jié)構(gòu)看上去雖然簡單直觀,但使用離線數(shù)據(jù)訓(xùn)練這一套框架使之協(xié)助在線無人機(jī)跟蹤并非易事,其獨(dú)道之處在于以下三點(diǎn):
相對運(yùn)動因子:我們發(fā)現(xiàn)訓(xùn)練PVT++會遇到一個核心問題,訓(xùn)練集與測試集的域差距。試想,如果用于訓(xùn)練PVT++的數(shù)據(jù)來自VID,LaSOT,GOT10k這些目標(biāo)運(yùn)動尺度較小,方向速度較規(guī)律的數(shù)據(jù)集,PVT++自然會嘗試擬合這些運(yùn)動規(guī)律而難以泛化到目標(biāo)運(yùn)動更復(fù)雜,尺度更大的無人機(jī)跟蹤場景。為了解決這一問題,我們將PVT++的訓(xùn)練目標(biāo)改為學(xué)習(xí)/擬合特殊設(shè)計的相對運(yùn)動因子,即原文公式(4):
這里pfj可以簡單理解為過去幾幀的平均速度,在左側(cè)的公式中,我們可以先假設(shè)目標(biāo)是勻速運(yùn)動的,即未來幀的相對位置變化正比于未來幀的時間間隔和平均速度,此后我們的神經(jīng)網(wǎng)絡(luò)只需要在這一假設(shè)上做出調(diào)整即為未來的真實(shí)運(yùn)動。這一設(shè)計也就使得預(yù)測器需要學(xué)習(xí)的東西是“相對于勻速運(yùn)動假設(shè)的偏差值”,即相對運(yùn)動因子,而非絕對的運(yùn)動值。我們發(fā)現(xiàn)這一預(yù)測目標(biāo)在大多數(shù)時候與目標(biāo)的絕對運(yùn)動是無關(guān)的,故而訓(xùn)練出的網(wǎng)絡(luò)也就不易擬合訓(xùn)練集中的絕對運(yùn)動,有著更好的泛化性。這一設(shè)計是PVT++能work的核心原因。預(yù)測器輸出的相對運(yùn)動會用于后續(xù)設(shè)計與真值的L1損失作為訓(xùn)練損失函數(shù)。
輕量化預(yù)測器結(jié)構(gòu):另一個問題是,預(yù)測器本身必須足夠輕量才能避免預(yù)測模塊引入額外的延遲,否則會導(dǎo)致整個系統(tǒng)失效。為此,我們設(shè)計了輕量有效的網(wǎng)絡(luò)架構(gòu),包含encoder - interaction - decoder三部分,并能兼容運(yùn)動軌跡信息與視覺特征,具體如圖四,其中大多數(shù)網(wǎng)絡(luò)層都可以有著非常小的通道數(shù)以實(shí)現(xiàn)極低的延遲(詳見原文表3)。此外,我們預(yù)測器的設(shè)計也最大程度上復(fù)用了跟蹤器能提供的視覺特征,因此節(jié)省了提取視覺特征所需要的計算資源。
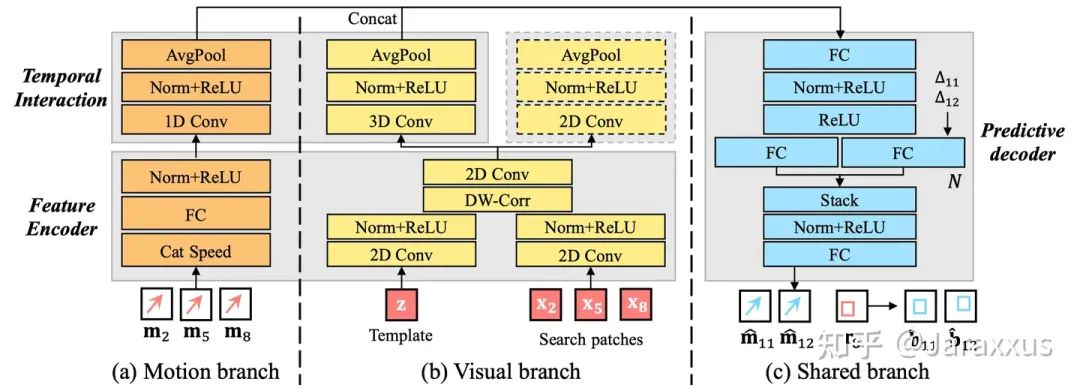
圖四. PVT++中預(yù)測器的輕量化網(wǎng)絡(luò)架構(gòu)。
如何有效利用跟蹤器已有的視覺特征:最后,為了使輕量的預(yù)測器做出穩(wěn)健的預(yù)測,我們設(shè)計了一系列訓(xùn)練策略使得參數(shù)量很少的預(yù)測器有效利用(較大型)預(yù)訓(xùn)練跟蹤器的能提供的魯棒視覺表征。具體而言,我們發(fā)現(xiàn)以下兩點(diǎn)設(shè)計尤為重要:
輔助分支:預(yù)測器的視覺分支(圖四(b))需要當(dāng)前的相對運(yùn)動信息作為監(jiān)督信號(圖四的虛線框部分)才能用于預(yù)測未來的運(yùn)動。詳見原文5.3節(jié)。
聯(lián)合訓(xùn)練:在訓(xùn)練PVT++時,跟蹤器模塊需要在早期的訓(xùn)練epoch中以較小的學(xué)習(xí)率聯(lián)合預(yù)測器一起訓(xùn)練,進(jìn)而使視覺特征既適用跟蹤器做定位,又適合預(yù)測器做預(yù)測。詳見附錄B中的訓(xùn)練設(shè)定與我們的開源代碼。
更多關(guān)于方法的細(xì)節(jié)介紹歡迎大家參考我們的原文(p.s.,我們的附錄B提供了一個符號表輔助閱讀...)
實(shí)驗(yàn)部分
全文的實(shí)驗(yàn)設(shè)計包括e-LAE的評估(原文圖五)與PVT++的效果、分析兩部分,在這里著重介紹PVT++有關(guān)的實(shí)驗(yàn)。
設(shè)置
為了公平比較基線跟蹤器,PVT++采用與他們訓(xùn)練相同的LaSOT+GOT10k+VID作為訓(xùn)練集(均為視頻)(實(shí)際上僅用VID也可以取得較好效果,詳見附錄L)。具體而言,我們直接加載了跟蹤器原作者提供的模型參數(shù)作為我們的跟蹤器模塊,再使用離線數(shù)據(jù)訓(xùn)練PVT++。
評估時我們使用了四個無人機(jī)跟蹤權(quán)威數(shù)據(jù)集DTB70,UAVDT,UAV20L以及UAV123,廣泛驗(yàn)證了PVT++的泛化性。
整體效果
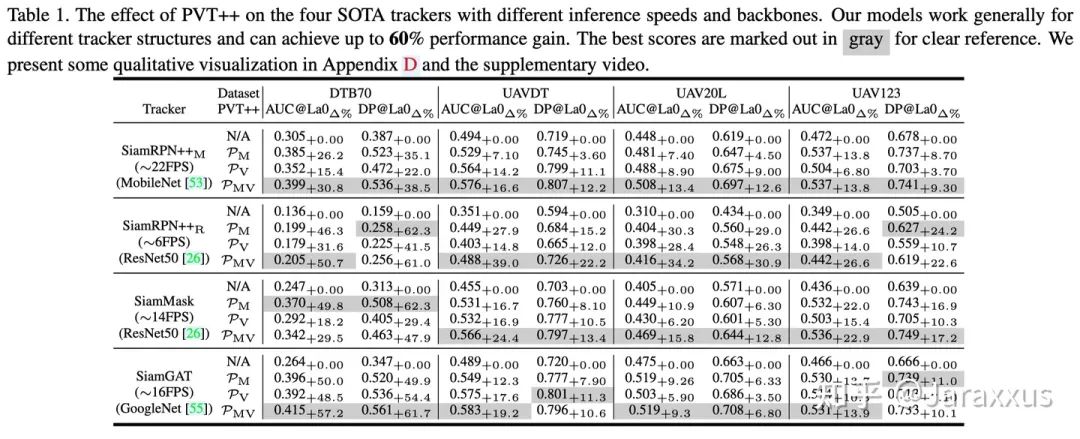
表一
PVT++的整體效果如表一所示,我們共將四個跟蹤器轉(zhuǎn)化為了預(yù)測性跟蹤器,在四個無人機(jī)跟蹤數(shù)據(jù)集中,PVT++能起到廣泛而顯著的效果。可以發(fā)現(xiàn)PVT++在某些場景下能達(dá)到超過60%的提升,甚至與跟蹤器的離線效果相當(dāng)。另外我們也發(fā)現(xiàn)并不是所有的情況下視覺信息都是有效可靠的,例如在DTB70中,僅用PVT++的motion分支也可以起到一定的效果。
消融實(shí)驗(yàn)
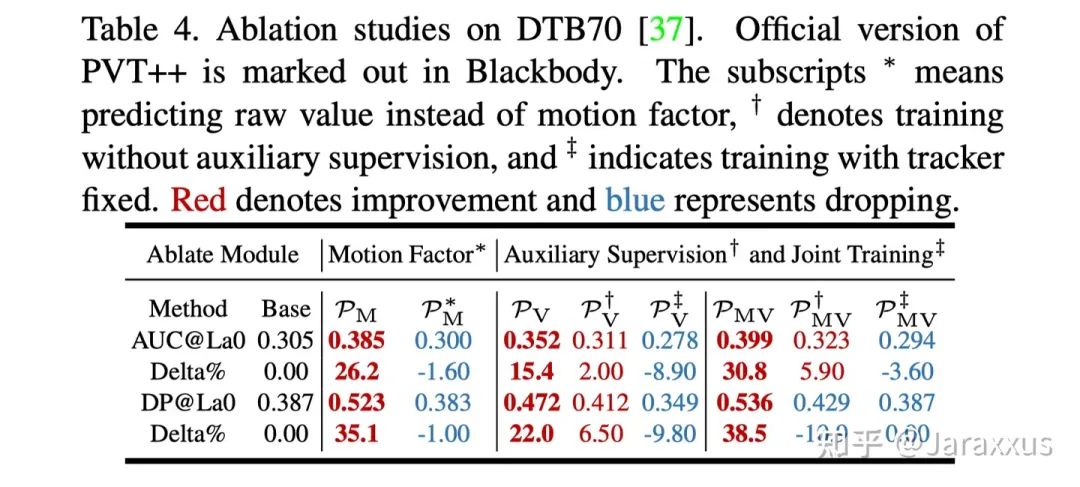
這里著重展示一下消融實(shí)驗(yàn)表四,如果不預(yù)測相對運(yùn)動因子而是直接用絕對運(yùn)動的值作為預(yù)測目標(biāo)(和損失函數(shù)設(shè)計),預(yù)測器完全不work,甚至?xí)胴?fù)面影響。當(dāng)引入視覺特征以后,輔助分支的監(jiān)督和聯(lián)合訓(xùn)練都是必要的,其中聯(lián)合訓(xùn)練的重要性更大。
與其他方法對比
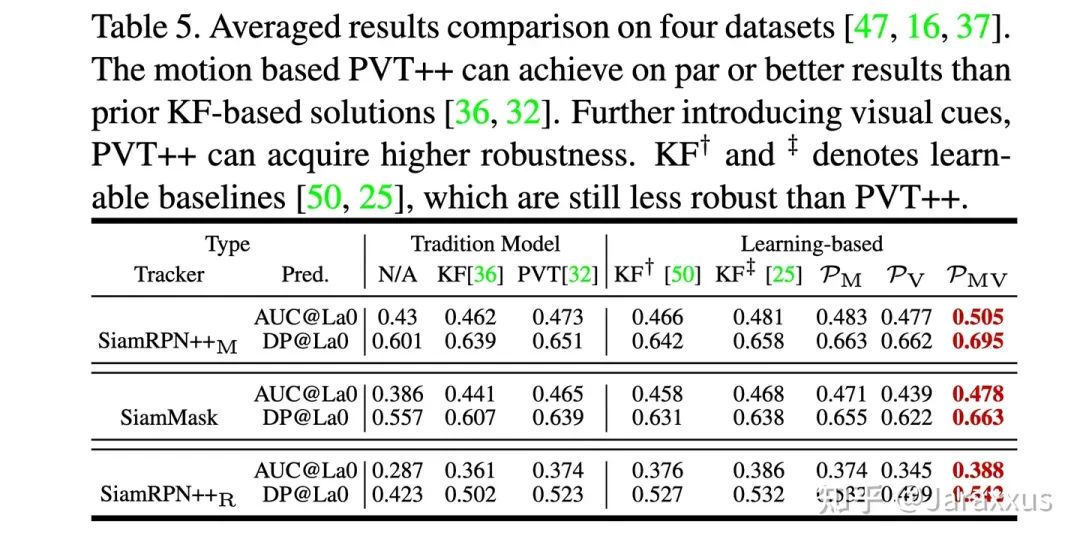
表五
如表五,我們嘗試了直接在跟蹤器后加入卡爾曼濾波(即沿用ECCV2020 “streaming”的思想)以及我們之前雙濾波(PVT)的方案,并且在審稿人的建議下設(shè)計了可學(xué)習(xí)的基線方法(具體而言,我們將卡爾曼濾波中的噪聲項(xiàng)作為可學(xué)習(xí)參數(shù))。這些方法都沒有利用跟蹤器已有的視覺特征,所以綜合效果差于聯(lián)合了運(yùn)動與視覺特征的PVT++。
可視化
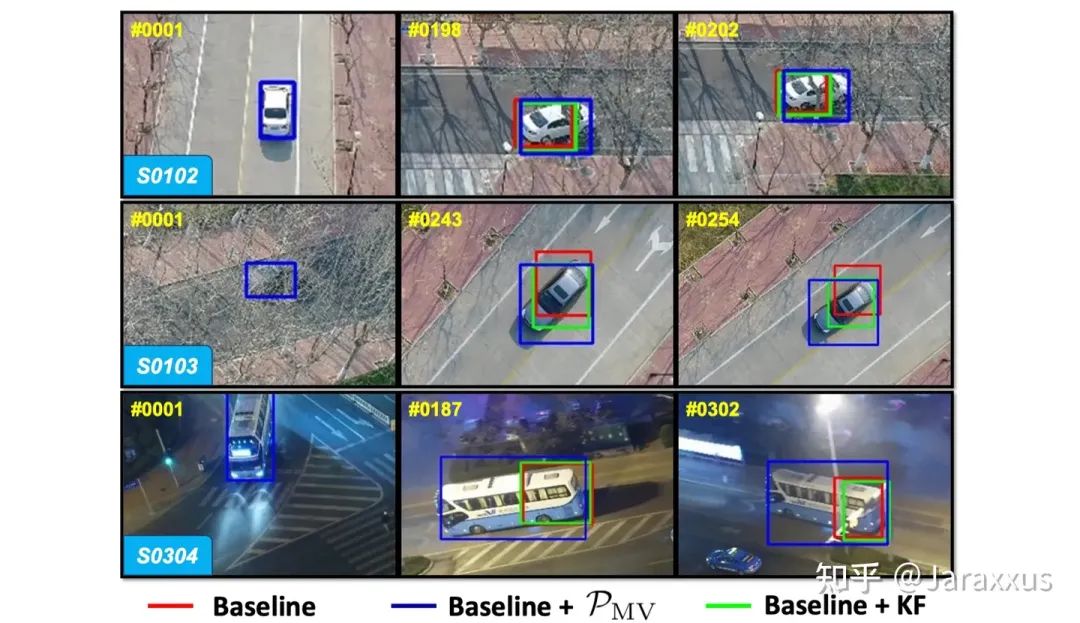
圖五. PVT++與卡爾曼濾波的可視化對比
在圖五中的三個序列中,我們發(fā)現(xiàn)卡爾曼濾波預(yù)測器很難處理目標(biāo)平面內(nèi)旋轉(zhuǎn)以及無人機(jī)視角變化的情況,在這些挑戰(zhàn)中,引入視覺信息進(jìn)行目標(biāo)尺度預(yù)測是尤為有效的。
另外本文也進(jìn)行了更為詳盡的實(shí)驗(yàn),如屬性分析、與其他運(yùn)動預(yù)測方法(如NEXT)的對比、PVT++作用在最新的基于transformer的跟蹤器等,歡迎大家參閱我們的附錄。
局限性與討論
PVT++的局限性在于兩點(diǎn):
預(yù)測器使用的視覺特征并不總是魯棒,我們發(fā)現(xiàn)在DTB70這類目標(biāo)運(yùn)動速度很快導(dǎo)致圖片模糊/目標(biāo)出視野,但目標(biāo)運(yùn)動本身很規(guī)律的數(shù)據(jù)集中其實(shí)單靠運(yùn)動分支就可以起到很好的效果。
訓(xùn)練策略有些復(fù)雜,特別是聯(lián)合訓(xùn)練時跟蹤器模塊在早期epoch用較小學(xué)習(xí)率微調(diào)這一些細(xì)節(jié)我們嘗試了很多次實(shí)驗(yàn)才發(fā)現(xiàn)。
e-LAE的局限性在于可復(fù)現(xiàn)性與平臺依賴性:
由于這套在線評估系統(tǒng)與算法的實(shí)際延遲緊密相關(guān),而延遲又與硬件平臺的狀態(tài)有關(guān),我們發(fā)現(xiàn)甚至同一型號的硬件上的同一實(shí)驗(yàn)結(jié)果也會略有不同(就是說甚至同一臺AGX放久了好像也會稍微慢一點(diǎn)....)。我們已經(jīng)嘗試在同一硬件上集中多次運(yùn)行以盡可能降低硬件的不穩(wěn)定性帶來的影響并會將原始結(jié)果開源以方便大家復(fù)現(xiàn)結(jié)果。另外我們也提供了一個“模擬”AGX硬件的腳本,可以將硬件上統(tǒng)計的延遲時間直接使用(而不是每次都一定要在機(jī)器人硬件上運(yùn)行),詳見我們的開源代碼。
預(yù)測性“在線”目標(biāo)跟蹤依然是一個相當(dāng)困難的研究問題,可能并不是增大數(shù)據(jù)量/模型參數(shù)量能輕易解決的,仍有著較大的提升空間。現(xiàn)在視覺領(lǐng)域正快速涌現(xiàn)一批批“奇觀”,在線延遲也potentially有著其他的解決方案值得研究。譬如最近有一篇比較出圈的工作叫OmniMotion,我們能不能依賴點(diǎn)的correspondence,考慮從目標(biāo)上每個point的運(yùn)動規(guī)律出發(fā),推理物體local到global的未來運(yùn)動?這樣也許能實(shí)現(xiàn)比PVT++更出彩的效果。
另外將算法延遲問題引入如今大火的一些foundation model研究中也是有意思的方向。譬如SAM和DINOv2的視覺特征是不是比ImageNet pre-train的ResNet更適合做視覺運(yùn)動預(yù)測?如果是的話又該怎么處理這些超大規(guī)模預(yù)訓(xùn)練出的視覺特征?或許可以從TrackAnything入手研究。
致謝
PVT++是我本科期間的最后一項(xiàng)工作,算得上是本科的收官之作了,雖然看上去沒有很fancy的cv概念,工程量也很大,但我個人非常喜歡,可能是我近三年實(shí)驗(yàn)上最扎實(shí)的工作了,當(dāng)時發(fā)現(xiàn)相對運(yùn)動因子和聯(lián)合訓(xùn)練帶來巨大的提升那種欣喜和意外是難以言喻的。該工作從第一次討論(2022年初)到如今中稿已經(jīng)是整整一年半,期間磕磕碰碰遇到了不少銳評,困難,與坎坷(差點(diǎn)就打算永遠(yuǎn)掛在arvix上了quqqq),附錄甚至在多輪審稿中修修補(bǔ)補(bǔ)到了Appendix M(都快夠一個正文了就是說><)。非常感謝在此期間合作的子淵,杰哥,一鳴大哥,三位老師,以及CMU的朋友們每次耐心的討論修改與對我的鼓勵支持。
本文初稿完成于2022年暑期,是我和子淵上半年在上海期智研究院與趙行老師合作的項(xiàng)目。MARS Lab是一個氛圍很好的實(shí)驗(yàn)室,大家有著可靠的強(qiáng)大實(shí)力卻又都溫和而謙虛,可謂志同道合。我不久前回國在云錦路西岸也受了老師同學(xué)們很多照顧,討論產(chǎn)生了不少idea,非常期待未來可能的合作交流。22年春季正值上海疫情嚴(yán)峻,非常感謝當(dāng)時研究院的老師、同學(xué)們提供的幫助。我們主要受 ECCV2020 “Towards Streaming Perception” 啟發(fā),我們的代碼基于目標(biāo)跟蹤知名開源庫 pysot,在此向有關(guān)的作者、開發(fā)者們致以誠摯的謝意。
-
算法
+關(guān)注
關(guān)注
23文章
4601瀏覽量
92671 -
框架
+關(guān)注
關(guān)注
0文章
399瀏覽量
17437 -
目標(biāo)跟蹤
+關(guān)注
關(guān)注
2文章
88瀏覽量
14876
原文標(biāo)題:ICCV 2023 | 漲點(diǎn)!PVT++:通用的端對端預(yù)測性目標(biāo)跟蹤框架
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
無線傳感網(wǎng)多簇頭協(xié)助的目標(biāo)跟蹤(二)
基于kalman預(yù)測和自適應(yīng)模板的目標(biāo)相關(guān)跟蹤研究

目標(biāo)跟蹤中目標(biāo)匹配的特征融合算法研究
基于KCFSE結(jié)合尺度預(yù)測的目標(biāo)跟蹤方法

機(jī)器人目標(biāo)跟蹤
基于融合的快速目標(biāo)跟蹤算法
改進(jìn)霍夫森林框架的多目標(biāo)跟蹤算法
最常見的目標(biāo)跟蹤算法
采用帶有transformer的端到端框架獲取對應(yīng)集合結(jié)果

DIMP:Learning Discriminative Model Prediction for Tracking 學(xué)習(xí)判別模型預(yù)測的跟蹤
利用TRansformer進(jìn)行端到端的目標(biāo)檢測及跟蹤
PowerBEV的高效新型端到端框架基于流變形的后處理方法

理想汽車自動駕駛端到端模型實(shí)現(xiàn)

ZETA端智能?紅牛:助力國際飲料巨頭實(shí)現(xiàn)生產(chǎn)設(shè)備預(yù)測性維護(hù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論