 微軟聯合Meta發布免費商業應用的開源AI模型Llama 2
微軟聯合Meta發布免費商業應用的開源AI模型Llama 2
昔日的競爭對手,今日的合作盟友;
忽如一夜春風來,開源大模型迎來新局面;
今天是 OSS AI 勝利的一天;
隨著 Meta 最新發布一個新的開源 AI 模型——Llama 2,網上盛贊的聲音不絕于耳,甚至圖靈獎得主、卷積網絡之父、Meta 首席人工智能科學家 Yann LeCun 更是直言,「這將改變 LLM 市場的格局」。

而Llama 2 之所以能引起這么大的反響,不僅是因為它是開源的,更主要的原因便是它可以被免費地用于研究和商業用途。與此同時,Meta 還與微軟強強聯手,旨在驅動 OpenAI 的 ChatGPT、Bing Chat 和其他現代聊天機器人等應用程序。
在 Meta 看來,「開放的方法是當今人工智能模型開發的正確方法,特別是在技術快速發展的生成領域。通過公開提供人工智能模型,它們可以使每個人受益。為企業、初創企業、企業家和研究人員提供其開發的工具,這些工具的開發規模是他們自己難以構建的,并以他們可能無法獲得的計算能力為后盾,將為他們以令人興奮的方式進行實驗。」
僅是這一點,便是當前很多專注于大模型開發的企業無法做到的,也如網友評價的那番,格局一下被打開。
Llama 2 的前身
今日發布的 Llama 2 是 Llama(大羊駝)的后續版本。
今年 2 月,Meta 首次公開發布 LLaMA,作為具有非商業許可證的開源版本。這是一種先進的基礎大型語言模型,旨在幫助研究人員推進 AI 這一子領域的工作。更小、性能更高的模型(例如 LLaMA)使研究界中無法訪問大量基礎設施的其他人能夠研究這些模型,從而進一步實現這一重要且快速變化的領域的訪問民主化。
彼時,Meta提供多種尺寸的 LLaMA(7B、13B、33B 和 65B 參數)。僅從功能上來看,Llama 可以根據提示生成文本和代碼,與其他類似聊天機器人的系統相當。
然而,當時由于擔心被濫用,Meta 決定限制對模型的訪問,所以也只是對具有一定資格的研究者開放,還需要寫申請表格等。
不過,令人沒想到的是,不久之后便有人將 LLaMA 的權重(包括經過訓練的神經網絡的參數值文件)泄露到了 torrent 網站,使得并沒有完全開放的 LLaMA 大模型短時間內在 AI 社區大規模擴散開。
很快,經過微調的 LLaMA 的諸多模型如雨后春筍般涌現,“羊駝”家族一時太過擁擠,如斯坦福發布了 Alpaca(羊駝)、UC 伯克利開源了 Vicuna(小羊駝)、華盛頓大學提出了 QLoRA 還開源了 Guanaco(原駝)...國內哈工大還基于中文醫學知識的 LLaMA 模型指令微調出了一個“華駝”。
時下,Llama 2 的發布將這款開源大模型推向一個新的高度。相比上一代 Llama 模型,經過混合公開數據的訓練,Llama 2 的性能有了顯著提高。
Llama 2:從 7B 到 70B 參數不等
為此,Meta 發布了一篇長達 76 頁的論文《Llama 2: Open Foundation and Fine-Tuned Chat Models》詳述Llama 2大模型的預訓練、微調、安全性等相關的工作。

論文地址:https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6/10000000_663429262362723_1696968207443577320_n.pdf?_nc_cat=101&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=5ol-jUSglG4AX_EKgWk&_nc_ht=scontent-lax3-2.xx&oh=00_AfC4pQWErthyr1jwgSScKeyjXW3wwEUnqvIh7MNeb-Et3g&oe=64BBB691
據論文顯示,Llama 2 有兩種版本:Llama 2和Llama 2-Chat,后者針對雙向對話進行了微調。Llama 2 和 Llama 2-Chat 進一步細分為不同復雜程度的版本:70 億個參數、130 億個參數和 700 億個參數。
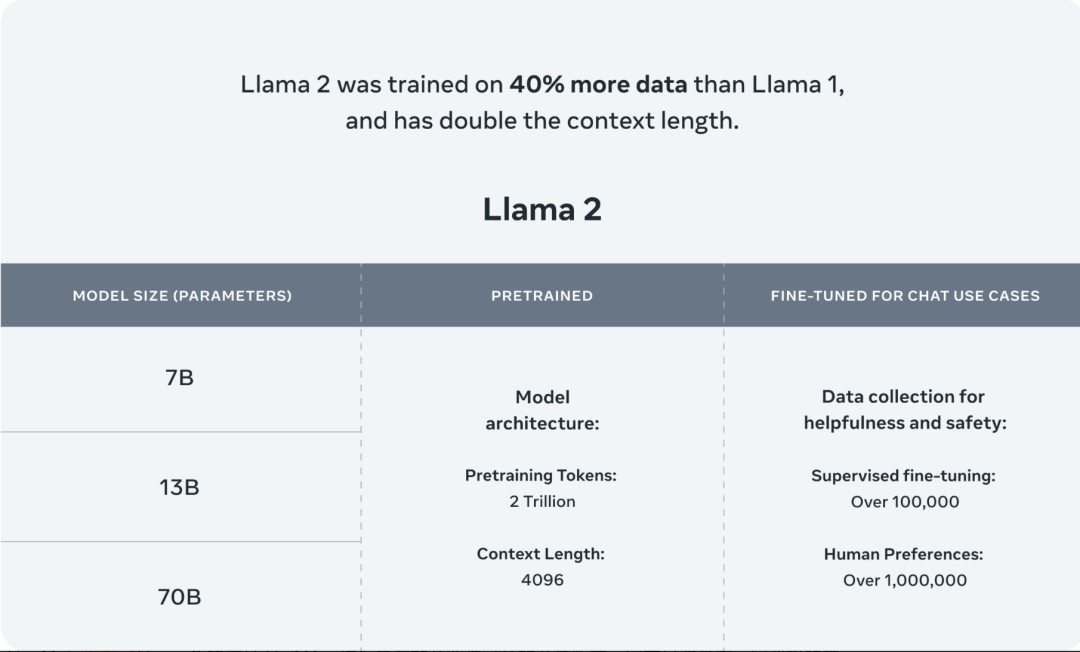
Meta 將 Llama 2 預訓練語料庫的規模增加了 40%,這一款模型(基本模型)接受了 2 萬億個 token 的訓練,上下文窗口包含了 4096 個 token,相比上一代,提升了一倍。上下文窗口決定了模型一次可以處理的內容的長度。在硬件方面,Meta 都使用了 NVIDIA A100。
Meta 還表示,Llama 2 微調模型是為類似于 ChatGPT 的聊天應用程序開發的,已經接受了“超過 100 萬條人工注釋”的訓練。
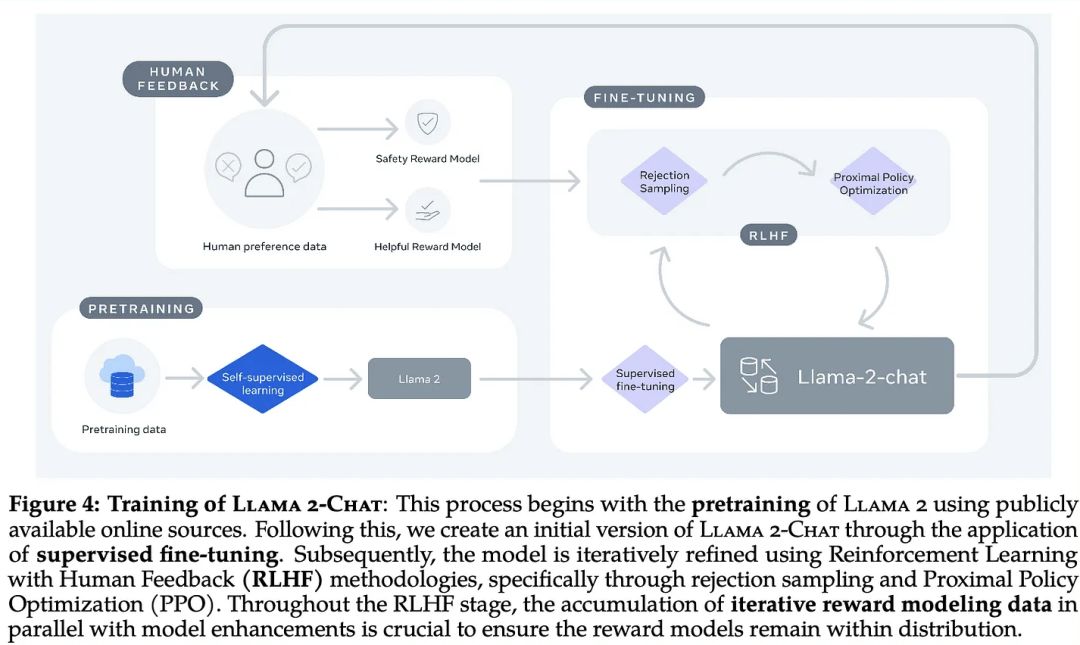
不過,Meta 在論文中并沒有透露訓練數據的具體來源,只是說它來自網絡,其中不包括來自 Meta 的產品或服務的數據。
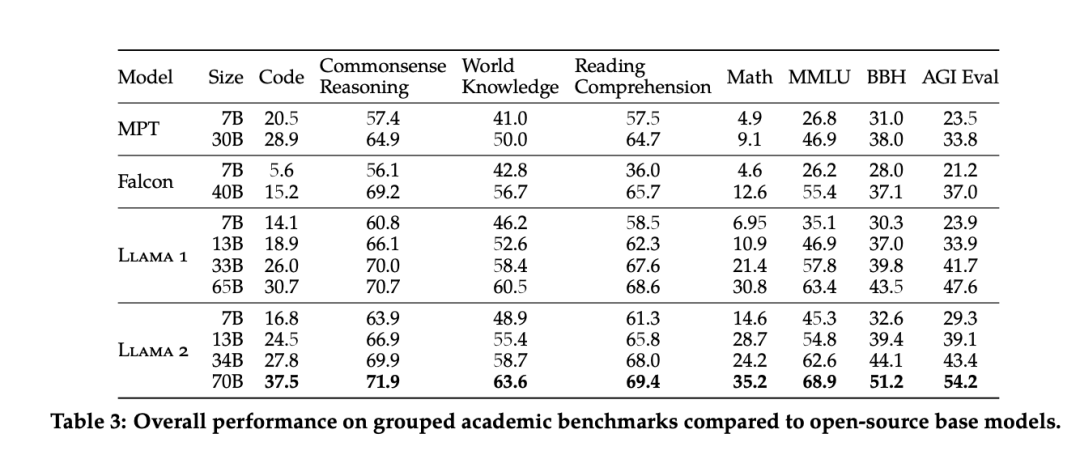
根據官方基準測試,Llama 2 在開源模型領域,一馬當先。其中,Llama 2 70B 模型的性能優于所有開放源碼模型。
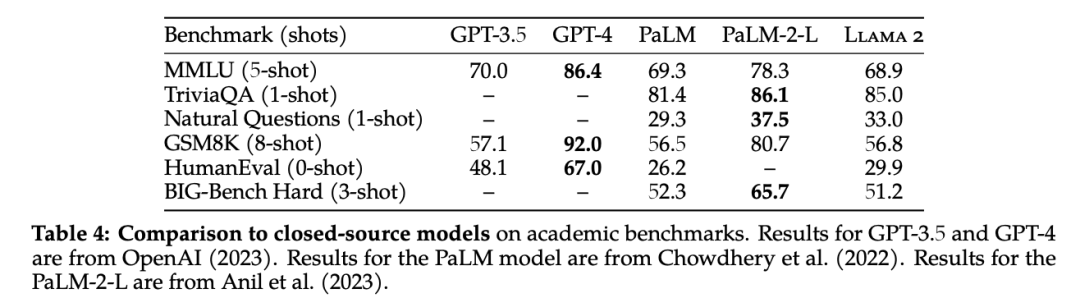
和閉源的大模型相比,Llama270B 在推理任務上接近 GPT-3.5,但在編碼基準上存在顯著差距。同時,其在性能上還無法與 OpenAI 的 GPT-4、PaLM-2-L 相媲美,在計算機編程方面 Llama 2 明顯落后于 GPT-4。
論及 Llama 2 此次真正的優勢,Nvidia 高級 AI 科學家 Jim Fan 高度評價道:
Llama-2 的訓練費用可能超過 2000 萬美元。Meta 通過發布具有商業友好許可的模型,為社區提供了令人難以置信的服務。由于許可證問題,大公司的人工智能研究人員對 Llama-1 持謹慎態度,但現在我認為他們中的很多人都會加入進來,貢獻自己的力量。
Meta 的團隊對 4K 提示進行了人類研究,以評估 Llama-2 是否有用。他們使用 "勝率 "作為比較模型的指標,其精神與 Vicuna 基準類似。70B 模型與 GPT-3.5-0301 大致持平,表現明顯強于 Falcon、MPT 和 Vicuna。
與學術基準相比,我更相信這些真實的人類評級。
Llama-2 還沒有達到 GPT-3.5 的水平,主要是因為它的編碼能力較弱。在 "HumanEval"(標準編碼基準)上,它還不如 StarCoder 或其他許多專門為編碼而設計的模型。盡管如此,我毫不懷疑 Llama-2 將因其開放的權重而得到顯著改善。
Meta 團隊在人工智能安全問題上不遺余力。事實上,這篇論文幾乎有一半的篇幅都在談論安全、紅線和評估。我們要為這種負責任的努力鼓掌!
在之前的研究中,幫助性和安全性之間存在著棘手的權衡問題。Meta 通過訓練兩個獨立的 reward 模型來緩解這一問題。這些模型還沒有開源,但對社區來說非常有價值。
我認為 Llama-2 將極大地推動多模態人工智能和機器人研究。這些領域需要的不僅僅是黑盒子訪問 API。
到目前為止,我們必須將復雜的感官信息(視頻、音頻、三維感知)轉換為文本描述,然后再輸入到 LLM,這樣做既笨拙又會導致大量信息丟失。將感官模塊直接嫁接到強大的 LLM 上會更有效。
Llama 2 的論文本身就是一部杰作。GPT-4 的技術詳解論文只分享了很少的信息,而 Llama-2 則不同,它詳細介紹了整個細節,包括模型細節、訓練階段、硬件、數據管道和注釋過程。例如,論文對 RLHF 的影響進行了系統分析,并提供了漂亮的可視化效果。
引用第 5.1 節:"我們認為,LLMs 在某些任務中超越人類注釋者的超強寫作能力,從根本上說是由 RLHF 驅動的"。

來源:https://twitter.com/DrJimFan/status/1681372700881854465
不過,值得注意的是,Llama 2 雖然允許了商業使用,但是它在社區許可協議中還添加了一條附加商業條款:
如果在 Llama 2 版本發布之日,被許可方或被許可方的關聯公司提供的產品或服務的每月活躍用戶數在上一個日歷月中超過 7 億,則您必須向Meta申請許可,Meta 可以自行決定向您授予該權利,并且您無權行使本協議項下的任何權利,除非或直到 Meta 明確授予您此類權利。

這意味著一些大廠,譬如亞馬遜、Google 這樣的巨頭想要使用 Llama 2,還存在一定限制。

Meta 與微軟強強聯手
當然,Meta 也并沒有將所有大廠拒絕門外。在此次官方公告中,Meta 宣布了和微軟的深度合作。
其中,作為 Llama 2 的首選合作伙伴微軟,Meta 表示,從今天開始,Llama 2 可在 Azure AI 模型目錄中使用,基于此,使用 Microsoft Azure 的開發人員能夠使用 Llama 2 進行構建,并利用其云原生工具進行內容過濾和安全功能。
與此同時,Llama 2 還經過優化,可以在 Windows 上本地運行,為開發人員提供無縫的工作流程,為跨不同平臺的客戶帶來生成式 AI 體驗。Llama 2 也可通過 Amazon Web Services (AWS)、Hugging Face 和其他提供商獲取。
有網友評論,微軟這一波又贏了!
除了與微軟合作之外,Meta 也與高通進行了合作。高通宣布,“計劃從 2024 年起,在旗艦智能手機和 PC 上支持基于 Llama 2 的 AI 部署,賦能開發者使用驍龍平臺的 AI 能力,推出激動人心的全新生成式 AI 應用。”
沒有 100% 完美的大模型
不過,對于 Llama 2,Meta 公司也承認它并非絕對的完美,因為其測試不可能捕獲所有現實世界場景,并且其基準測試可能缺乏多樣性,換句話說,沒有充分涵蓋編碼和人類推理等領域。
Meta 還承認,Llama 2 與所有生成式 AI 模型一樣,在某些層面存在偏差。例如,由于訓練數據的不平衡以及訓練數據中存在“有毒”文本,它可能會制造“幻覺”、生成“有毒性”的內容。
針對這一點,Meta 選擇和微軟合作的一部分,也包括使用 Azure AI Content Safety,該服務旨在檢測 AI 生成的圖像和文本中的“不當”內容,以減少 Azure 上有毒的 Llama 2 輸出。
同時,Meta 在論文中強調 Llama 2 用戶除了遵守有關“安全開發和使用”的準則外,還必須遵守 Meta 的許可條款和可接受的使用政策,在一定程度上減少有偏差性的內容。
開源大模型的未來
最后,如果說 OpenAI 引領大模型賽道,那么 Meta 則開辟了開源大模型的新大門。
以開源的方式,匯聚更多的創新,Llama 2 的開源也為眾人預測中的“未來,開源大模型會主導整個大模型的發展方向”帶來更多可能性。
這也正如 Ars Technica 總結的:開源人工智能模型的到來,不僅鼓勵透明度(用于制作模型的訓練數據而言),而且促進經濟競爭(不將技術限制于大公司)、鼓勵言論自由(沒有審查制度),并使人工智能的訪問民主化(沒有付費專區限制)。
同時,為了避免 Llama 2 開源存在的潛在爭議,Meta 還同時發布了一封主題為《支持 Meta 對當今人工智能的開放方法的聲明》的聲明,其寫道:
“我們支持對人工智能采取開放式創新方法。負責任和開放式創新為我們所有人提供了參與人工智能開發過程,為這些技術帶來可見性、審查和信任。今天開放的 Llama 模型將使每個人都從這項技術中受益。”
截至目前,已有近百位 AI 專家參與簽名,其中包括 Drew Houston(Dropbox 首席執行官)、Matt Bornstein(Andreessen Horowitz 合伙人)、Julien Chaumond(Hugging Face 首席技術官)、Lex Fridman(麻省理工學院研究科學家)和 Paul Graham(Y Combinator 的創始合伙人)等。
當然,也不容忽視的是,無論是開源還是閉源大模型,其都面臨著復雜的法律問題,因為他們需要判別用于訓練的數據池中是否存在受版權保護的資源。如何有效避免這些問題,也成為這些大模型開發公司下一階段需要解決的事情。
-
微軟
+關注
關注
4文章
6572瀏覽量
103963 -
AI
+關注
關注
87文章
30239瀏覽量
268479 -
大模型
+關注
關注
2文章
2339瀏覽量
2501
原文標題:微軟又贏麻了!聯合 Meta 發布免費商業應用的開源 AI 模型 Llama 2
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論