 新的 MLPerf 推理網絡部分展現 NVIDIA InfiniBand 網絡和 GPUDirect RDMA 的強大能力
新的 MLPerf 推理網絡部分展現 NVIDIA InfiniBand 網絡和 GPUDirect RDMA 的強大能力

在 MLPerf Inference v3.0中,NVIDIA 首次將網絡納入了 MLPerf 的評測項目,成為了 MLPerf 推理數據中心套件的一部分。網絡評測部分旨在模擬在真實的數據中心中,網絡軟、硬件對于端到端推理性能的影響。
在網絡評測中,有兩類節點:前端節點生成查詢,這些查詢通過業界標準的網絡(如以太網或 InfiniBand 網絡)發送到加速節點,由加速器節點進行處理和執行推理。
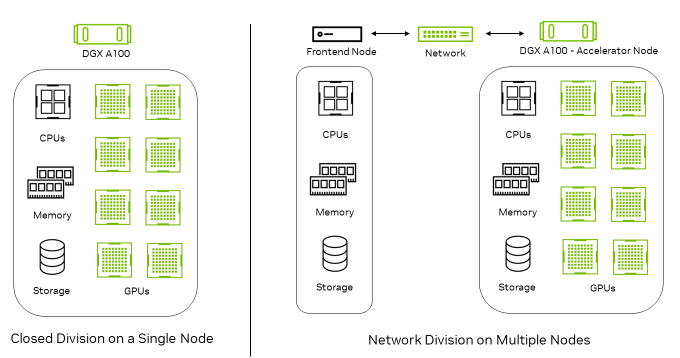
圖 1:單節點封閉測試環境與多節點網絡測試環境
圖 1 顯示了在單個節點上運行的封閉測試環境,以及在網絡測試環境中通過前端節點生成查詢,然后傳輸到加速器節點上進行推理的工作流程。
在網絡測試場景中,加速器節點包含了推理加速器以及所有網絡組件,包括網卡(NIC)、網絡交換機和完整的網絡體系。因此,網絡評測旨在測試加速器節點和網絡的性能,因為前端節點在基準測試中的作用有限,可以排除它們對測試的影響。
MLPerf 推理 v3.0 網絡評測中的
NVIDIA 網絡性能表現
在 MLPerf 推理 v3.0 中,NVIDIA 提交了在 ResNet-50 和 BERT 兩種場景下的網絡性能結果,從 NVIDIA 提交的性能結果來看,憑借 NVIDIA ConnectX-6 InfiniBand 智能網卡和 GPUDirect RDMA 技術提供的超高網絡帶寬和極低延遲,ResNet-50 在網絡環境中達到了 100% 的單節點性能。

表 1:ResNet-50 和 BERT 上網絡評測性能和單機封閉測試性能的比較,有限帶寬實現了理想性能
NVIDIA 平臺在 BERT 工作負載方面也表現出了出色的性能,和單機封閉測試結果性能僅有輕微的差異,這主要是由于主機端的一些開銷而導致。
在 NVIDIA 網絡評測中用到的關鍵技術
大量的全棧技術使 NVIDIA 網絡評測中的強大性能得以實現:
-
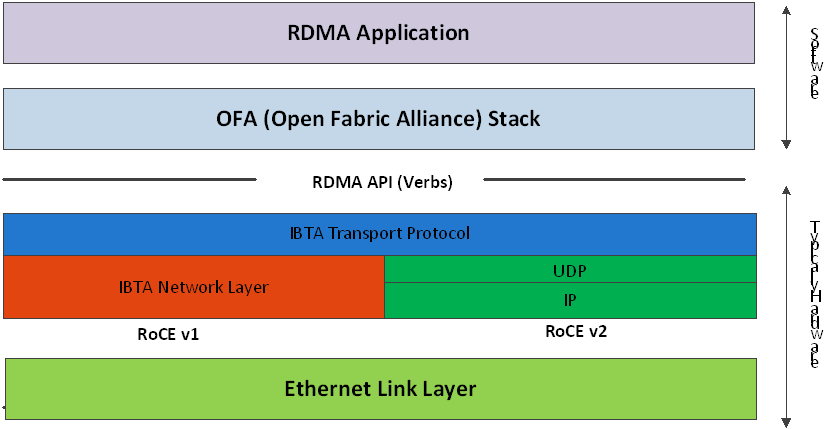
InfiniBand RDMA 網絡,為張量通信提供低延遲和高帶寬,基于 Mellanox OFED 軟件堆棧中的 IBV verbs 實現。
-
通過以太網 TCP Socket 進行配置交換、運行狀態同步和心跳監控。
-
利用 CPU、GPU 和 NIC 資源獲得最佳性能時 NUMA-Aware。
網絡評測部分實施細節
以下是 MLPerf 推理中網絡評測部分的實現細節:
- 采用高吞吐量、低延遲的 InfiniBand 網絡進行通信
- 網絡評測部分推理流程
- 性能優化
通過高吞吐量、低延遲的
InfiniBand 網絡進行通信
網絡評測過程要求提交者通過查詢調度庫(QDL)從負載生成器獲取查詢,然后根據提交者設置的方式將查詢發送到加速器節點。
-
在生成輸入張量序列的前端節點,QDL 通過測試端(SUT)的 API 對 LoadGen 系統進行抽象,這樣用于本地測試的加速器的 MLPerf 推理 LoadGen 就變得可見。
-
在加速器節點,通過 QDL 與負責推理請求和響應的 LoadGen 直接交互。在 NVIDIA 的 QDL 實現中,我們使用 InfiniBand IBV verbs 和以太網 TCP Socket 實現了無縫數據通信和同步。
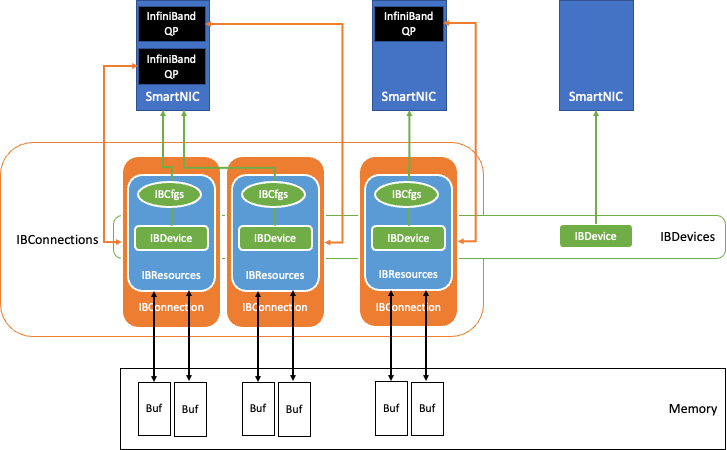
圖 2:QDL 內部的 InfiniBand 數據交換組件
圖 2 顯示了基于 InfiniBand 網絡技術的 QDL 中的數據交換組件。
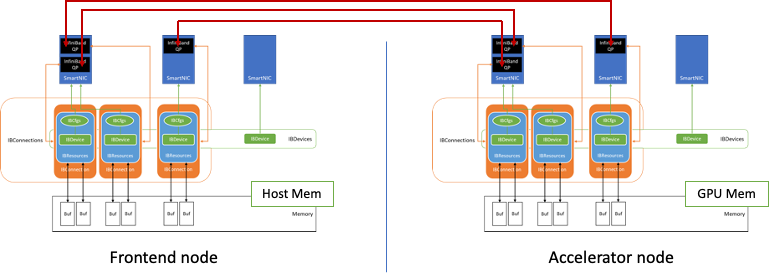
圖 3:前端節點和加速器節點之間建立連接的示例
圖 3 顯示了如何使用該數據交換組件在兩個節點之間建立連接。
InfiniBand 網絡的隊列對(QPs)是節點之間的連接的基礎。NVIDIA 采用了無損可靠連接(RC)方式(和 TCP 類似)和傳輸模式,并利用 InfiniBand HDR 光纖網絡來維持高達 200 Gbits/sec 的吞吐量。
基準測試開始時,QDL 在初始化過程中會發現系統中的所有 InfiniBand 網卡,并根據存儲在 IBCfgs 中的配置信息,指定網卡作為測試的 IBDevice 實例。在這個測試過程中,用于 RDMA 傳輸的內存區域被分配、固定和注冊為 RDMA 緩沖區,并與相應的的 Handle 一起保存在 IBResources 中。
利用 GPUDirect RDMA 技術,可以將加速器節點的 GPU 顯存作為 RDMA 緩沖區,并將 RDMA 緩沖區信息以及相應的保護密鑰通過以太網的 TCP Socket 發送給相對應的節點,這樣就為 QDL 創建 IBConnection 實例。
由于 QDL 支持 NUMA-Aware,可將最近的 NUMA 主機內存、CPU 和 GPU 映射到每張網卡,每個 NIC 都通過 IBConnection 與對端網卡 NIC 進行通信。
網絡評測部分推理流程
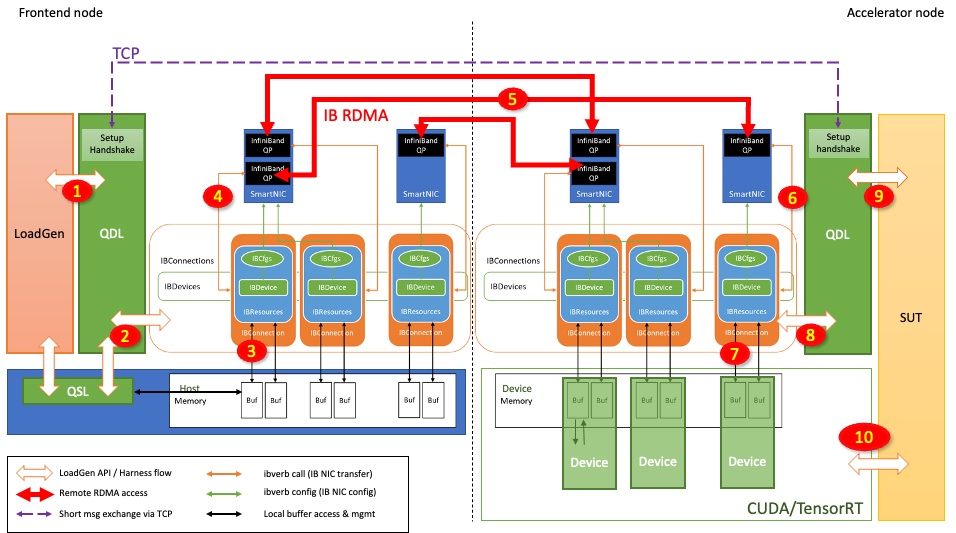
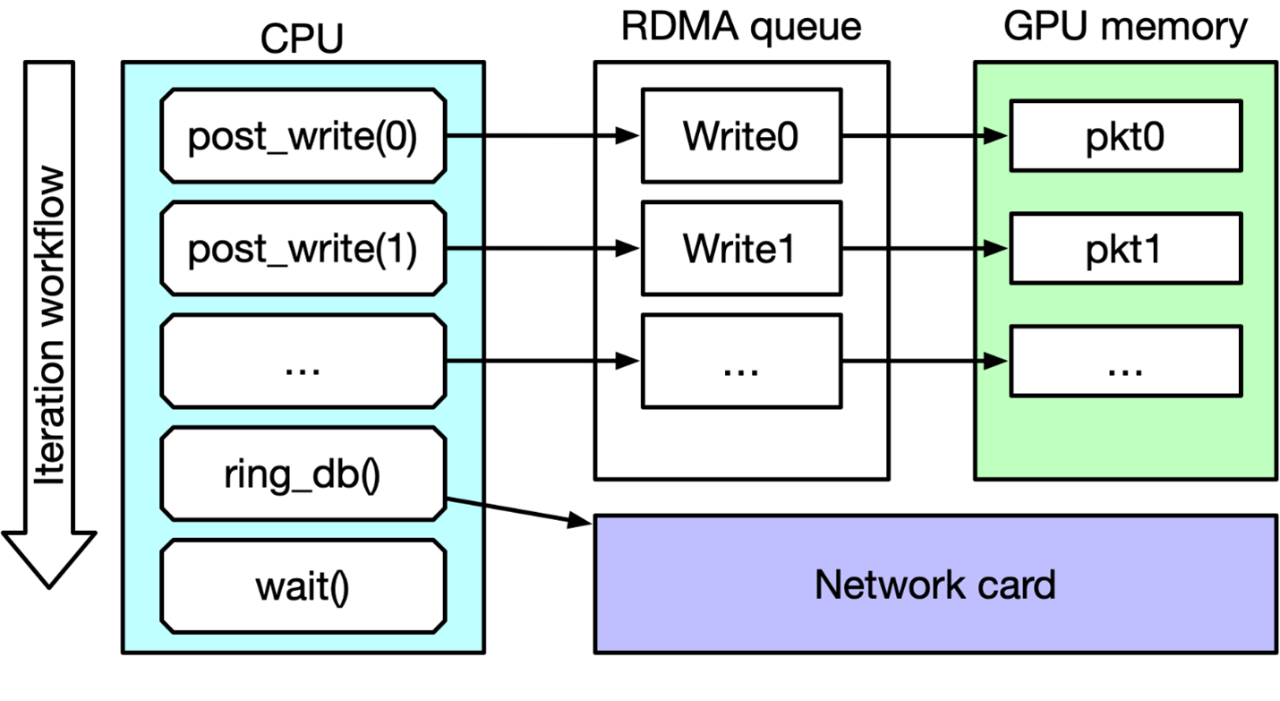
圖 4:使用 Direct GPU RDMA 從前端節點到加速器節點的推理請求流
圖 4 顯示了推理請求是如何從前端節點發送到加速器節點并在加速器節點上被處理的:
-
LoadGen 生成一個查詢(推理請求),其中包含輸入張量。
-
QDL 通過仲裁的方式將該查詢重定向到適當的 IBConnection。
-
查詢樣本庫(QSL)可能已經被注冊在 RDMA 緩沖區內。如果沒有,則 QDL 將查詢復制到 RDMA 緩沖區。
-
QDL 啟動相應的 QP 的 RDMA 傳輸。
-
通過網絡交換機實現 InfiniBand 網絡傳輸。
-
查詢到達對等方的 QP。
-
然后通過直接內存訪問技術將查詢傳輸到目的地 RDMA 緩沖區。
-
加速器節點的 QDL 確認 RDMA 傳輸完成。
-
QDL 允許加速器節點能夠批處理查詢,QDL 標記一批查詢,發布到加速器節點的某個加速器上去執行。
-
加速器節點的加速器使用 CUDA 和 TensorRT 執行推理,在 RDMA 緩沖區中生成響應。
當在步驟 10 最終執行推理后,會生成輸出張量,并將其置于 RDMA 緩沖區中。然后加速器節點開始以類似的方式但以相反的方向將響應張量傳輸到前端節點。
性能優化
NVIDIA 使用 InfiniBand RDMA_Write 的方式實現了最短的延遲。要成功地應用 RDMA_Write,發送方必須對于對端的內存緩沖區可見。
前端節點和加速器節點都需要管理緩沖區跟蹤器,以確保每個查詢和響應都保存在內存中,直到用完為止。例如,ResNet-50 要想達到理想的性能需要每個連接(QP)管理多達 8K 個交易。
NVIDIA 用到了以下一些關鍵優化。
以下關鍵優化支持更好的可擴展性:
-
每個 IBConnection(QP)的交易跟蹤器:每個 IBConnection 都有一個獨立的交易跟蹤器,從而實現無死鎖的、關聯內交易記賬。
-
每個網卡支持多個 QP:任意數量的 IBConnections 可以在任何網卡上實例化,從而可以輕松地自發支持大量交易。
以下關鍵優化提高了 InfiniBand 網絡的資源效率:
-
使用 INLINE 的方式傳輸小消息:通過 INLINE 傳輸小消息(通常指小于 64 字節)可避免 PCIe 傳輸,從而顯著提高性能和效率。
-
使用 UNSIGNALLED RDMA Write:由于 UNSIGNALLED 的操作需要在 CQ 隊列中等待直到 SIGNALLED 操作發生,再觸發到目前為止在同一節點中排隊的所有事務的完成處理(批量完成),因此 CQ 維護變得更加高效。
-
使用 Solicited IB 傳輸:Unsolicited 的 RDMA 操作可以在遠端節點中排隊等待,直到 solicited RDMA 操作發生,再觸發遠端節點中的批量完成。
-
基于事件的 CQ 管理:避免 CPU 一直忙于等待 CQ,釋放 CPU 個周期。
以下關鍵優化提高了內存系統的效率:
-
通過 RDMA 傳輸避免了前端節點內的內存拷貝:發送輸入張量時,通過直接將張量存在在 RDMA 注冊的內存中來避免主機內存拷貝。
-
在加速器節點中聚合 CUDA 的 memcpys:通過盡可能多地集中連續內存中的張量,提高 GPU 顯存拷貝和 PCIe 傳輸的效率。
每家的 QP 實現涵蓋了能支持的最大完成隊列條目數(CQE),以及支持的最大 QP 條目數。擴展每個網卡能支持的 QP 數量,對于降低延遲,同時保持足夠的實時交易量以實現最大吞吐量很重要。
如果 CQ 通過輪詢的方式在短時間內處理大量事務,會對主機 CPU 造成顯著的壓力,在這種情況下,采用基于事件的 CQ 管理,以及減少通知的數量會對此非常有幫助。通過盡可能多地聚集連續內存空間中的數據,如果可能,聚集在 RDMA 注冊的內存空間,可以最大限度地提高內存訪問效率。這對于實現最大性能至關重要。
總結
NVIDIA 平臺在其首次提交的網絡測試結果中表現出色,充分體現了 NVIDIA 在 MLPerf 推理:數據中心封閉部門評測項目中一貫的領先地位,這些結果歸功于許多 NVIDIA 平臺的強大功能實現:
-
NVIDIA A100 Tensor Core GPU
-
NVIDIA DGX A100
-
NVIDIA ConnectX-6 InfiniBand 網絡
-
NVIDIA TensorRT
-
GPUDirect RDMA
這個結果進一步證明了 NVIDIA AI 平臺在行業標準的、業界公認的真實數據中心部署中的高性能和多樣性。
掃描下方二維碼,查看更多有關NVIDIA InfiniBand 的信息。

 ?
?更多精彩內容 跨越距離:NVIDIA 平臺解決邊緣的 HPC 問題
GreatSQL & NVIDIA InfiniBand NVMe SSD 存算分離池化方案:實現高性能分布式部署
NVIDIA Quantum InfiniBand 打造 AI 時代 GPU 計算的高性能存儲技術
原文標題:新的 MLPerf 推理網絡部分展現 NVIDIA InfiniBand 網絡和 GPUDirect RDMA 的強大能力
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3749瀏覽量
90856
原文標題:新的 MLPerf 推理網絡部分展現 NVIDIA InfiniBand 網絡和 GPUDirect RDMA 的強大能力
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
InfiniBand網絡內計算的關鍵技術和應用
端到端InfiniBand網絡解決LLM訓練瓶頸

IB Verbs和NVIDIA DOCA GPUNetIO性能測試
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
RDMA在高速網絡中的應用及其實現策略
利用NVIDIA組件提升GPU推理的吞吐
深入探索InfiniBand網絡、HDR與IB技術

一文詳解超算中的InfiniBand網絡、HDR與IB

什么是NVIDIA?InfiniBand網絡VSNVLink網絡

NVIDIA發布專為大規模AI量身訂制的全新網絡交換機-X800系列
NVIDIA 發布全新交換機,全面優化萬億參數級 GPU 計算和 AI 基礎設施

rdma網絡是什么?RDMA網絡有什么應用場景?
RDMA和TCP/IP有什么區別
態路小課堂丨InfiniBand與以太網:AI時代的網絡差異






 工商網監
工商網監
評論