 斯坦福博士一己之力讓Attention提速9倍!
斯坦福博士一己之力讓Attention提速9倍!
【導讀】FlashAttention新升級!斯坦福博士一人重寫算法,第二代實現了最高9倍速提升。
繼超快且省內存的注意力算法FlashAttention爆火后,升級版的2代來了。
FlashAttention-2是一種從頭編寫的算法,可以加快注意力并減少其內存占用,且沒有任何近似值。
比起第一代,FlashAttention-2速度提升了2倍。
甚至,相較于PyTorch的標準注意力,其運行速度最高可達9倍。
一年前,StanfordAILab博士Tri Dao發布了FlashAttention,讓注意力快了2到4倍,如今,FlashAttention已經被許多企業和研究室采用,廣泛應用于大多數LLM庫。
如今,隨著長文檔查詢、編寫故事等新用例的需要,大語言模型的上下文以前比過去變長了許多——GPT-4的上下文長度是32k,MosaicML的MPT上下文長度是65k,Anthropic的Claude上下文長度是100k。
但是,擴大Transformer的上下文長度是一項極大的挑戰,因為作為其核心的注意力層的運行時間和內存要求,是輸入序列長度的二次方。
Tri Dao一直在研究FlashAttention-2,它比v1快2倍,比標準的注意力快5到9倍,在A100上已經達到了225 TFLOP/s的訓練速度!

論文地址:https://tridao.me/publications/flash2/flash2.pdf
項目地址:https://github.com/Dao-AILab/flash-attention
FlashAttention-2:更好的算法、并行性和工作分區
端到端訓練GPT模型,速度高達225 TFLOP/s
雖說FlashAttention在發布時就已經比優化的基線快了2-4倍,但還是有相當大的進步空間。
比方說,FlashAttention仍然不如優化矩陣乘法(GEMM)運算快,僅能達到理論最大FLOPs/s的25-40%(例如,在A100 GPU上的速度可達124 TFLOPs/s)。
GEMM如何用于卷積
在過去的幾個月里,研究人員一直在開發FlashAttention-2,它的性能指標比第一代更強。
研究人員表示,2代相當于完全從頭重寫,使用英偉達的CUTLASS 3.x及其核心庫CuTe。從速度上看,FlashAttention-2比之前的版本快了2倍,在A100 GPU上的速度可達230 TFLOPs/s。
當使用端到端來訓練GPT之類的語言模型時,研究人員的訓練速度高達225 TFLOPs/s(模型的FLOP利用率為72%)。
對注意力計算重新排序
我們知道,FlashAttention是一種對注意力計算進行重新排序的算法,利用平鋪、重新計算來顯著加快計算速度,并將序列長度的內存使用量從二次減少到線性。
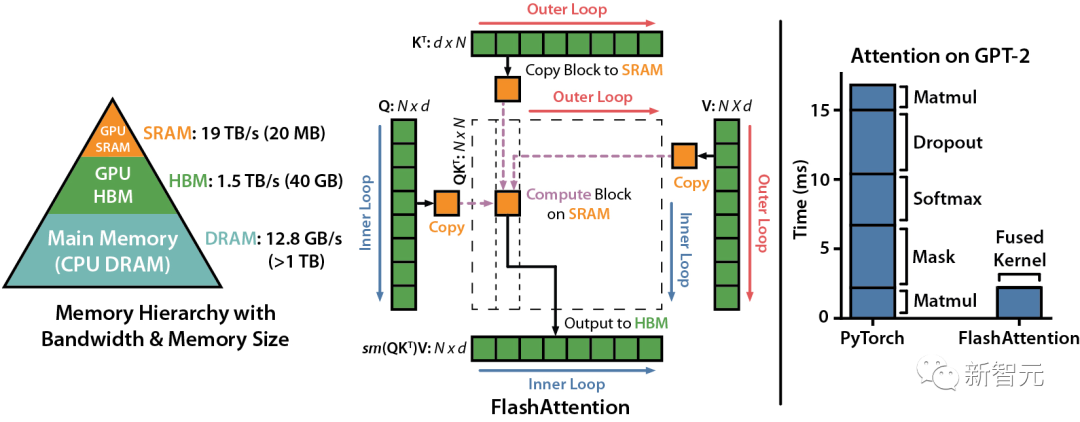
研究人員將輸入塊從HBM(GPU內存)加載到SRAM(快速緩存),并對該模塊執行注意,更新HBM中的輸出。
由于沒有將大型中間注意力矩陣寫入HBM,內存的讀/寫量也跟著減少,進而帶來了2-4倍的執行時間加速。
下圖是FlashAttention的前向傳遞圖:通過平鋪和softmax重新縮放,研究人員人員按模塊進行操作,避免從HBM讀取或是寫入,同時獲得正確輸出,無需近似。
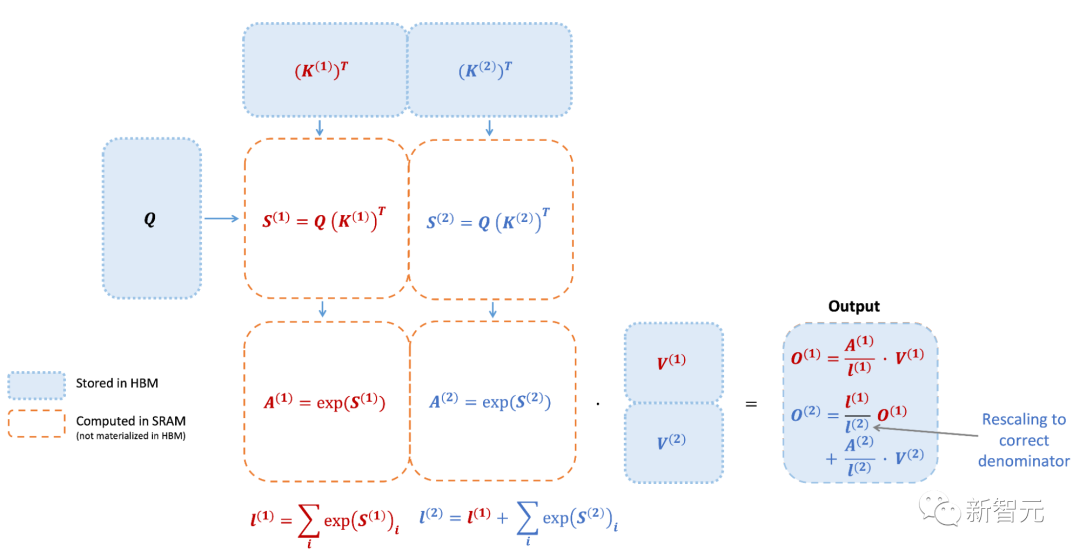
然而,FlashAttention仍然存在一些低效率的問題,這是由于不同線程塊之間的工作劃分并不理想,以及GPU上的warp——導致低占用率或不必要的共享內存讀寫。
更少的non-matmul FLOP(非矩陣乘法浮點計算數)
研究人員通過調整FlashAttention的算法來減少non-matmul FLOP的次數。這非常重要,因為現代GPU有專門的計算單元(比如英偉達GPU上的張量核心),這就使得matmul的速度更快。
例如,A100 GPU FP16/BF16 matmul的最大理論吞吐量為312 TFLOPs/s,但non-matmul FP32的理論吞吐量僅為 19.5 TFLOPs/s。
另外,每個非matmul FLOP比matmul FLOP要貴16倍。
所以為了保持高吞吐量,研究人員希望在matmul FLOP上花盡可能多的時間。
研究人員還重新編寫了FlashAttention中使用的在線softmax技巧,以減少重新縮放操作的數量,以及邊界檢查和因果掩碼操作,而無需更改輸出。
更好的并行性
FlashAttention v1在批大小和部數量上進行并行化處理。研究人員使用1個線程塊來處理一個注意力頭,共有 (batch_size * head number) 個線程塊。
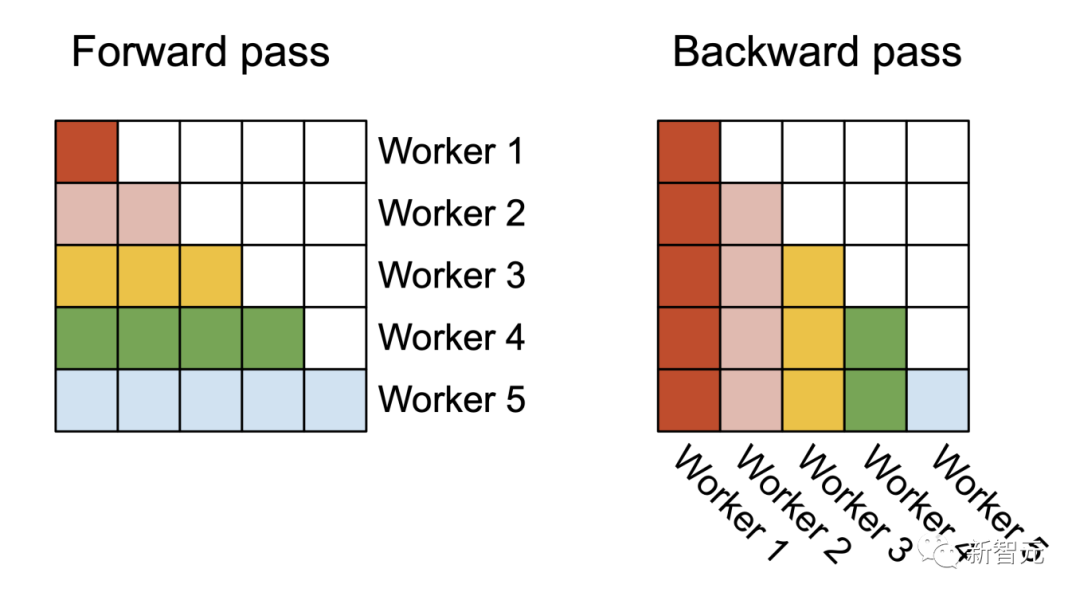
在前向處理(左圖)中,研究者將Worker(線程塊)并行化,每個Worker負責處理注意力矩陣的一個行塊。在后向處理過程中(右圖),每個Worker處理注意力矩陣的一個列塊
每個線程塊都在流式多處理器 (SM)運行,例如,A100 GPU上有108個這樣的處理器。當這個數字很大(比如 ≥80)時,這種調度是有效的,因為在這種情況下,可以有效地使用GPU上幾乎所有的計算資源。
在長序列的情況下(通常意味著更小批或更少的頭),為了更好地利用GPU上的多處理器,研究人員在序列長度的維度上另外進行了并行化,使得該機制獲得了顯著加速。
更好的工作分區
即使在每個線程塊內,研究人員也必須決定如何在不同的warp(線程束)之間劃分工作(一組32個線程一起工作)。研究人員通常在每個線程塊使用4或8個warp,分區方案如下圖所示。
研究人員在FlashAttention-2中改進了這種分區,減少了不同warp之間的同步和通信量,從而減少共享內存讀/寫。
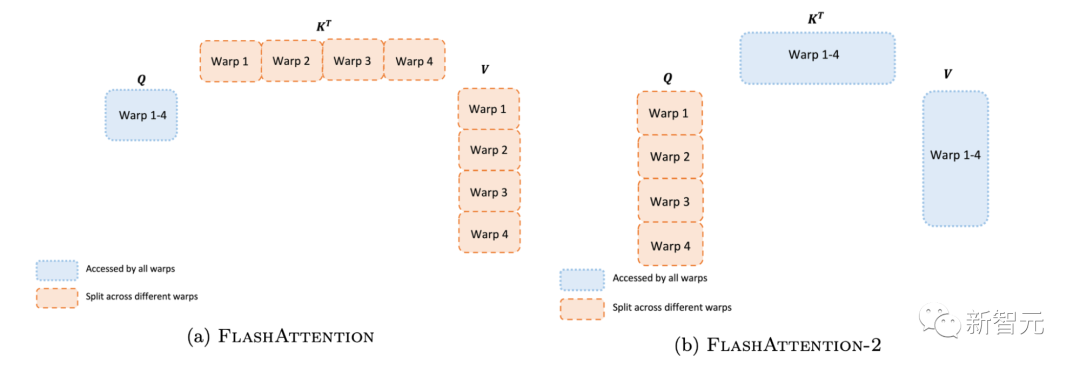
對于每個塊,FlashAttention將K和V分割到4個warp上,同時保持Q可被所有warp訪問。這稱為「sliced-K」方案。
然而,這樣做的效率并不高,因為所有warp都需要將其中間結果寫入共享內存,進行同步,然后再將中間結果相加。
而這些共享內存讀/寫會減慢FlashAttention中的前向傳播速度。
在FlashAttention-2中,研究人員將Q拆分為4個warp,同時保持所有warp都可以訪問K和V。
在每個warp執行矩陣乘法得到Q K^T的一個切片后,它們只需與共享的V切片相乘,即可得到相應的輸出切片。
這樣一來,warp之間就不再需要通信。共享內存讀寫的減少就可以提高速度。
新功能:頭的維度高達256,多查詢注意力
FlashAttention僅支持最大128的頭的維度,雖說適用于大多數模型,但還是有一些模型被排除在外。
FlashAttention-2現在支持256的頭的維度,這意味著GPT-J、CodeGen、CodeGen2以及Stable Diffusion 1.x等模型都可以使用FlashAttention-2來獲得加速和節省內存。
v2還支持多查詢注意力(MQA)以及分組查詢注意力(GQA)。
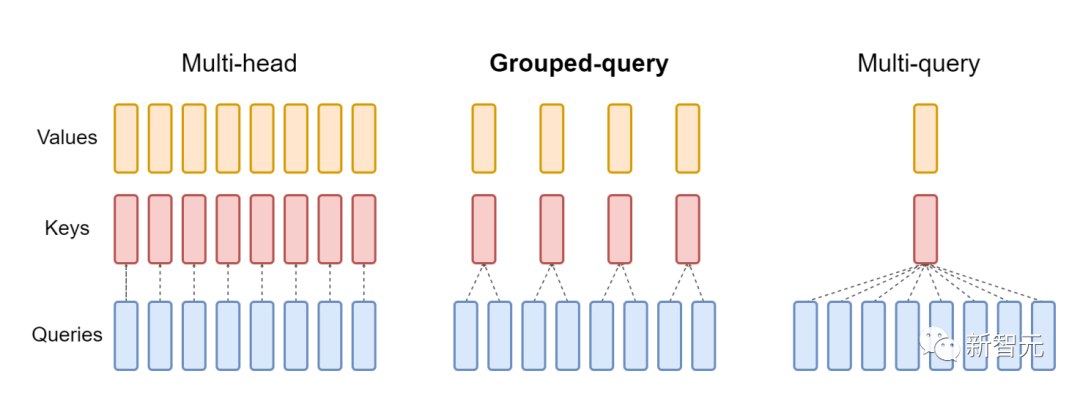
GQA為每組查詢頭共享單個key和value的頭,在多頭和多查詢注意之間進行插值
這些都是注意力的變體,其中多個查詢頭會指向key和value的同一個頭,以減少推理過程中KV緩存的大小,并可以顯著提高推理的吞吐量。
注意力基準
研究人員人員在A100 80GB SXM4 GPU 上測量不同設置(有無因果掩碼、頭的維度是64或128)下不同注意力方法的運行時間。
研究人員發現FlashAttention-2比第一代快大約2倍(包括在xformers庫和Triton中的其他實現)。
與PyTorch中的標準注意力實現相比,FlashAttention-2的速度最高可達其9倍。
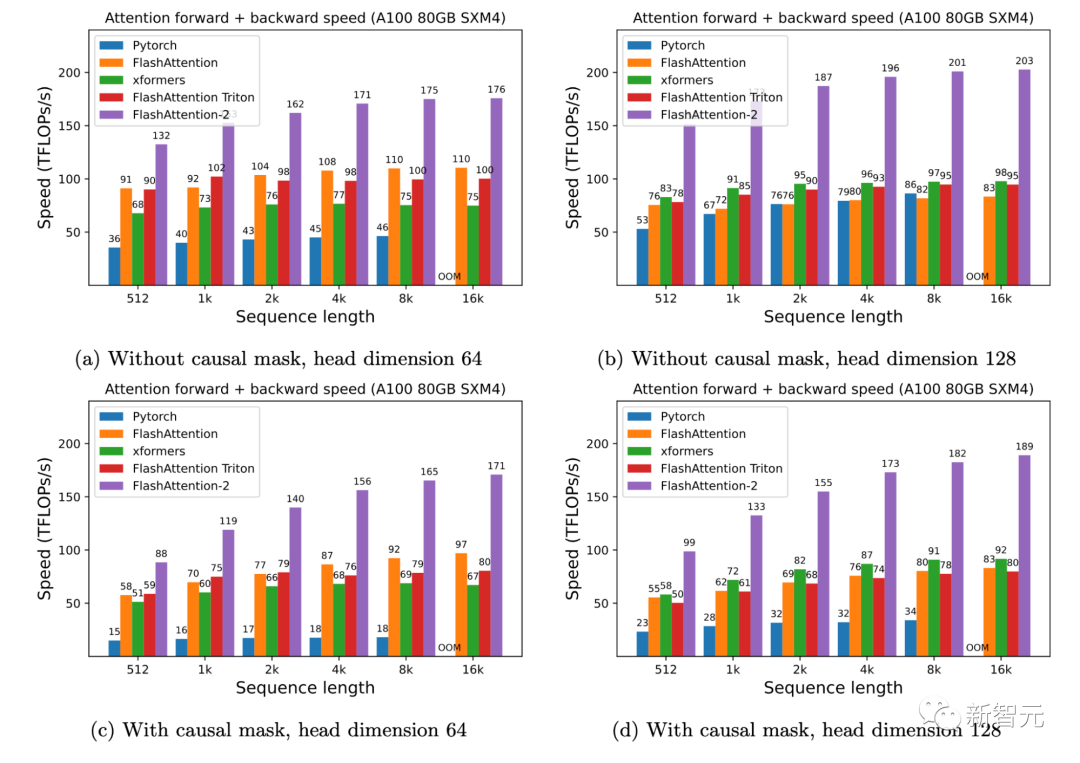
A100 GPU上的前向+后向速度
只需在H100 GPU上運行相同的實現(不需要使用特殊指令來利用TMA和第四代Tensor Core等新硬件功能),研究人員就可以獲得高達335 TFLOPs/s的速度。
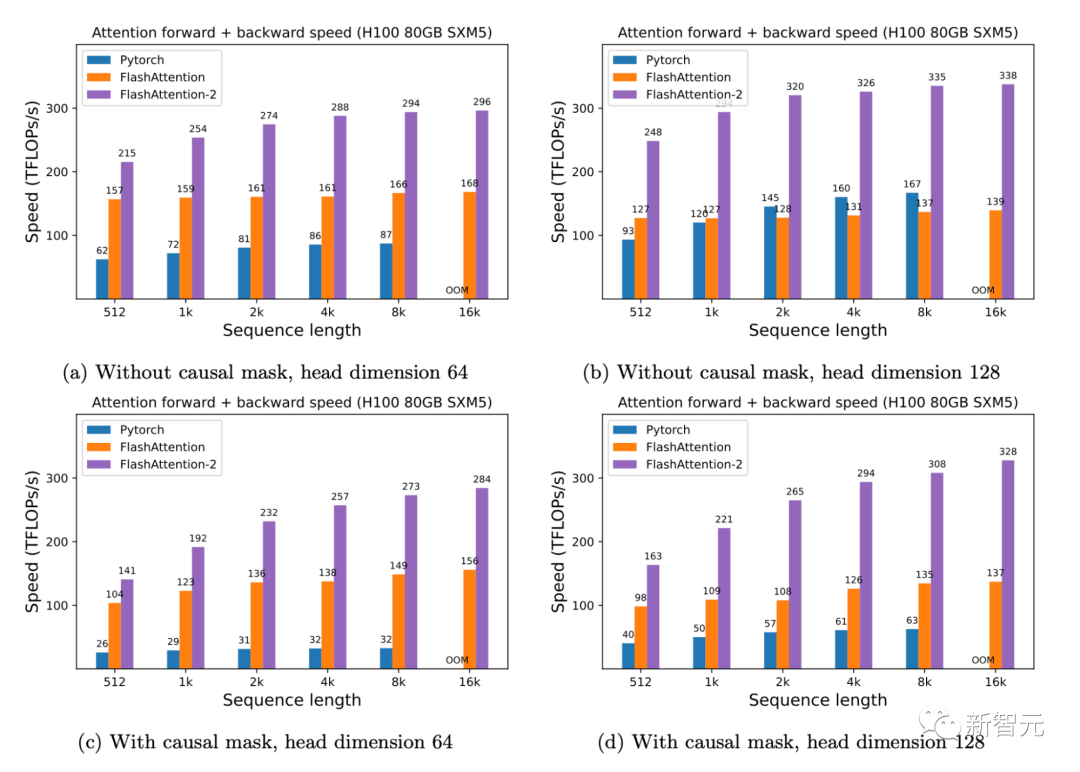
H100 GPU上的前向+后向速度
當用于端到端訓練GPT類模型時,FlashAttention-2能在A100 GPU上實現高達225TFLOPs/s的速度(模型FLOPs利用率為72%)。
與已經非常優化的FlashAttention模型相比,端到端的加速進一步提高了1.3倍。

未來的工作
速度上快2倍,意味著研究人員可以用與之前訓練8k上下文模型相同的成本,來訓練16k上下文長度的模型。這些模型可以理解長篇書籍和報告、高分辨率圖像、音頻和視頻。
同時,FlashAttention-2還將加速現有模型的訓練、微調和推理。
在不久的將來,研究人員還計劃擴大合作,使FlashAttention廣泛適用于不同類型的設備(例如H100 GPU、AMD GPU)以及新的數據類型(例如fp8)。
下一步,研究人員計劃針對H100 GPU進一步優化FlashAttention-2,以使用新的硬件功能(TMA、第四代Tensor Core、fp8等等)。
將FlashAttention-2中的低級優化與高級算法更改(例如局部、擴張、塊稀疏注意力)相結合,可以讓研究人員用更長的上下文來訓練AI模型。
研究人員也很高興與編譯器研究人員合作,使這些優化技術更好地應用于編程。
-
算法
+關注
關注
23文章
4601瀏覽量
92671 -
矩陣
+關注
關注
0文章
422瀏覽量
34504 -
模型
+關注
關注
1文章
3178瀏覽量
48730
原文標題:斯坦福博士一己之力讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
斯坦福開發過熱自動斷電電池
關于斯坦福的CNTFET的問題
回收新舊 斯坦福SRS DG645 延遲發生器
銷售現貨 斯坦福 SR650 橢圓過濾器
DG645 斯坦福 SRS DG645 延遲發生器 現金回收
"現代愛迪生"鎳氫反應電池發明者斯坦福逝世
斯坦福開啟以人為中心的AI計劃
華為要用一己之力發展ARM服務器芯片,能成功么?
斯坦福“以人為本人工智能研究院”——Stanford HAI正式上線!
讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升

維修斯坦福SR560可編程濾波器燒了overload






 工商網監
工商網監
評論