") 讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
FlashAttention新升級!斯坦福博士一人重寫算法,第二代實現(xiàn)了最高9倍速提升。
繼超快且省內(nèi)存的注意力算法FlashAttention爆火后,升級版的2代來了。FlashAttention-2是一種從頭編寫的算法,可以加快注意力并減少其內(nèi)存占用,且沒有任何近似值。比起第一代,F(xiàn)lashAttention-2速度提升了2倍。甚至,相較于PyTorch的標(biāo)準(zhǔn)注意力,其運行速度最高可達(dá)9倍。
一年前,StanfordAILab博士Tri Dao發(fā)布了FlashAttention,讓注意力快了2到4倍,如今,F(xiàn)lashAttention已經(jīng)被許多企業(yè)和研究室采用,廣泛應(yīng)用于大多數(shù)LLM庫。如今,隨著長文檔查詢、編寫故事等新用例的需要,大語言模型的上下文以前比過去變長了許多——GPT-4的上下文長度是32k,MosaicML的MPT上下文長度是65k,Anthropic的Claude上下文長度是100k。但是,擴大Transformer的上下文長度是一項極大的挑戰(zhàn),因為作為其核心的注意力層的運行時間和內(nèi)存要求,是輸入序列長度的二次方。Tri Dao一直在研究FlashAttention-2,它比v1快2倍,比標(biāo)準(zhǔn)的注意力快5到9倍,在A100上已經(jīng)達(dá)到了225 TFLOP/s的訓(xùn)練速度!

項目鏈接:
https://github.com/Dao-AILab/flash-attention
 ?
?FlashAttention-2:更好的算法、并行性和工作分區(qū)
端到端訓(xùn)練GPT模型,速度高達(dá)225 TFLOP/s
雖說FlashAttention在發(fā)布時就已經(jīng)比優(yōu)化的基線快了2-4倍,但還是有相當(dāng)大的進(jìn)步空間。比方說,F(xiàn)lashAttention仍然不如優(yōu)化矩陣乘法(GEMM)運算快,僅能達(dá)到理論最大FLOPs/s的25-40%(例如,在A100 GPU上的速度可達(dá)124 TFLOPs/s)。
對注意力計算重新排序
我們知道,F(xiàn)lashAttention是一種對注意力計算進(jìn)行重新排序的算法,利用平鋪、重新計算來顯著加快計算速度,并將序列長度的內(nèi)存使用量從二次減少到線性。
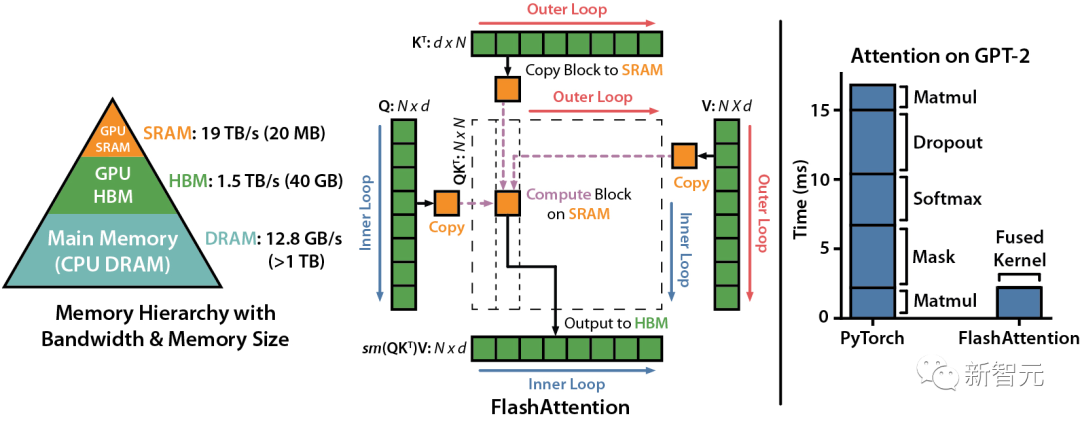
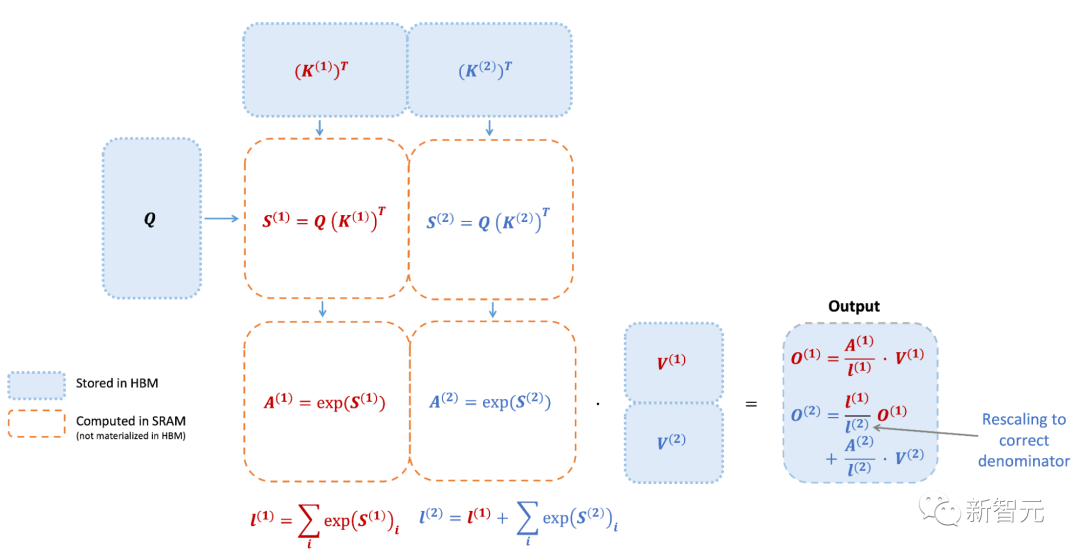
然而,F(xiàn)lashAttention仍然存在一些低效率的問題,這是由于不同線程塊之間的工作劃分并不理想,以及GPU上的warp——導(dǎo)致低占用率或不必要的共享內(nèi)存讀寫。
更少的non-matmulFLOP(非矩陣乘法浮點計算數(shù))
研究人員通過調(diào)整FlashAttention的算法來減少non-matmul FLOP的次數(shù)。這非常重要,因為現(xiàn)代GPU有專門的計算單元(比如英偉達(dá)GPU上的張量核心),這就使得matmul的速度更快。例如,A100 GPU FP16/BF16 matmul的最大理論吞吐量為312 TFLOPs/s,但non-matmul FP32的理論吞吐量僅為 19.5 TFLOPs/s。另外,每個非matmul FLOP比matmul FLOP要貴16倍。所以為了保持高吞吐量,研究人員希望在matmul FLOP上花盡可能多的時間。研究人員還重新編寫了FlashAttention中使用的在線softmax技巧,以減少重新縮放操作的數(shù)量,以及邊界檢查和因果掩碼操作,而無需更改輸出。更好的并行性
FlashAttention v1在批大小和部數(shù)量上進(jìn)行并行化處理。研究人員使用1個線程塊來處理一個注意力頭,共有 (batch_size * head number) 個線程塊。
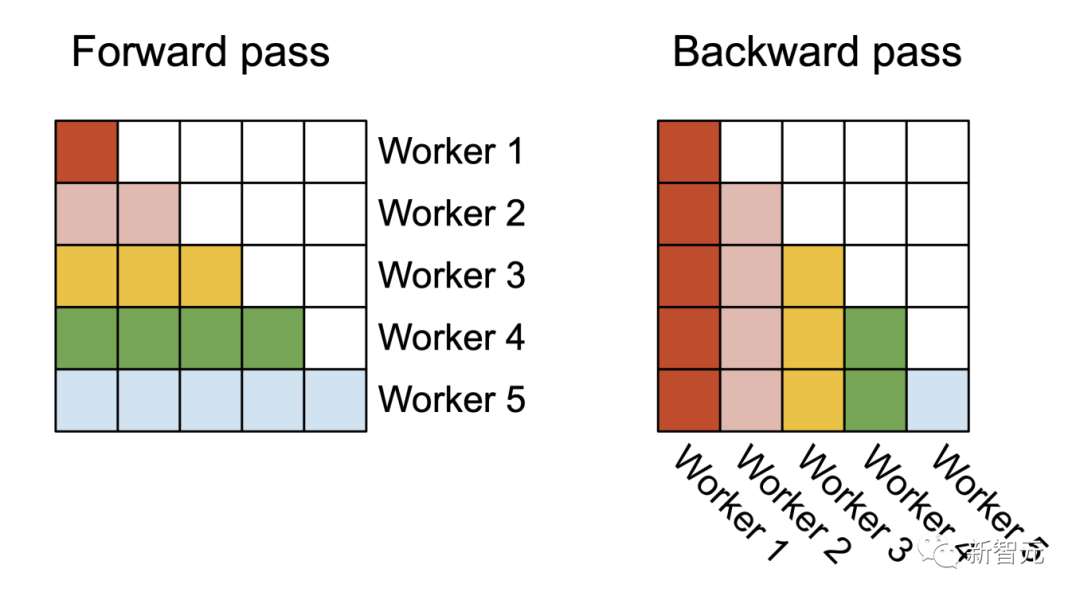
每個線程塊都在流式多處理器 (SM)運行,例如,A100 GPU上有108個這樣的處理器。當(dāng)這個數(shù)字很大(比如 ≥80)時,這種調(diào)度是有效的,因為在這種情況下,可以有效地使用GPU上幾乎所有的計算資源。在長序列的情況下(通常意味著更小批或更少的頭),為了更好地利用GPU上的多處理器,研究人員在序列長度的維度上另外進(jìn)行了并行化,使得該機制獲得了顯著加速。
更好的工作分區(qū)
即使在每個線程塊內(nèi),研究人員也必須決定如何在不同的warp(線程束)之間劃分工作(一組32個線程一起工作)。研究人員通常在每個線程塊使用4或8個warp,分區(qū)方案如下圖所示。研究人員在FlashAttention-2中改進(jìn)了這種分區(qū),減少了不同warp之間的同步和通信量,從而減少共享內(nèi)存讀/寫。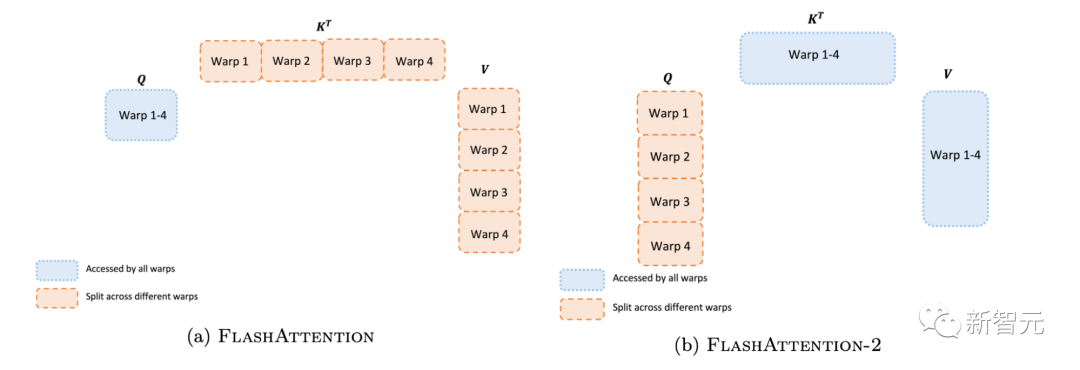 對于每個塊,F(xiàn)lashAttention將K和V分割到4個warp上,同時保持Q可被所有warp訪問。這稱為「sliced-K」方案。然而,這樣做的效率并不高,因為所有warp都需要將其中間結(jié)果寫入共享內(nèi)存,進(jìn)行同步,然后再將中間結(jié)果相加。而這些共享內(nèi)存讀/寫會減慢FlashAttention中的前向傳播速度。在FlashAttention-2中,研究人員將Q拆分為4個warp,同時保持所有warp都可以訪問K和V。在每個warp執(zhí)行矩陣乘法得到Q K^T的一個切片后,它們只需與共享的V切片相乘,即可得到相應(yīng)的輸出切片。這樣一來,warp之間就不再需要通信。共享內(nèi)存讀寫的減少就可以提高速度。
對于每個塊,F(xiàn)lashAttention將K和V分割到4個warp上,同時保持Q可被所有warp訪問。這稱為「sliced-K」方案。然而,這樣做的效率并不高,因為所有warp都需要將其中間結(jié)果寫入共享內(nèi)存,進(jìn)行同步,然后再將中間結(jié)果相加。而這些共享內(nèi)存讀/寫會減慢FlashAttention中的前向傳播速度。在FlashAttention-2中,研究人員將Q拆分為4個warp,同時保持所有warp都可以訪問K和V。在每個warp執(zhí)行矩陣乘法得到Q K^T的一個切片后,它們只需與共享的V切片相乘,即可得到相應(yīng)的輸出切片。這樣一來,warp之間就不再需要通信。共享內(nèi)存讀寫的減少就可以提高速度。
 ?新功能:頭的維度高達(dá)256,多查詢注意力
?新功能:頭的維度高達(dá)256,多查詢注意力FlashAttention僅支持最大128的頭的維度,雖說適用于大多數(shù)模型,但還是有一些模型被排除在外。FlashAttention-2現(xiàn)在支持256的頭的維度,這意味著GPT-J、CodeGen、CodeGen2以及Stable Diffusion 1.x等模型都可以使用FlashAttention-2來獲得加速和節(jié)省內(nèi)存。v2還支持多查詢注意力(MQA)以及分組查詢注意力(GQA)。
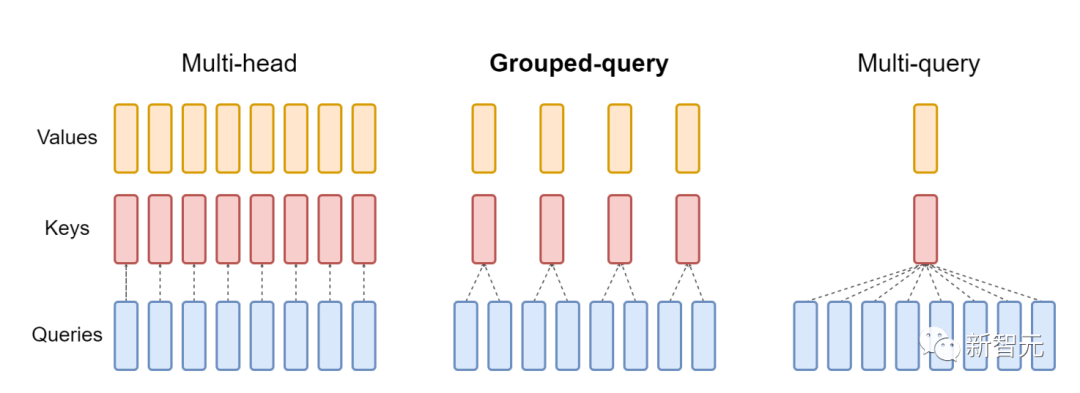
▲GQA為每組查詢頭共享單個key和value的頭,在多頭和多查詢注意之間進(jìn)行插值
這些都是注意力的變體,其中多個查詢頭會指向key和value的同一個頭,以減少推理過程中KV緩存的大小,并可以顯著提高推理的吞吐量。
 ?
?注意力基準(zhǔn)
研究人員人員在A100 80GB SXM4 GPU 上測量不同設(shè)置(有無因果掩碼、頭的維度是64或128)下不同注意力方法的運行時間。
 研究人員發(fā)現(xiàn)FlashAttention-2比第一代快大約2倍(包括在xformers庫和Triton中的其他實現(xiàn))。與PyTorch中的標(biāo)準(zhǔn)注意力實現(xiàn)相比,F(xiàn)lashAttention-2的速度最高可達(dá)其9倍。
研究人員發(fā)現(xiàn)FlashAttention-2比第一代快大約2倍(包括在xformers庫和Triton中的其他實現(xiàn))。與PyTorch中的標(biāo)準(zhǔn)注意力實現(xiàn)相比,F(xiàn)lashAttention-2的速度最高可達(dá)其9倍。
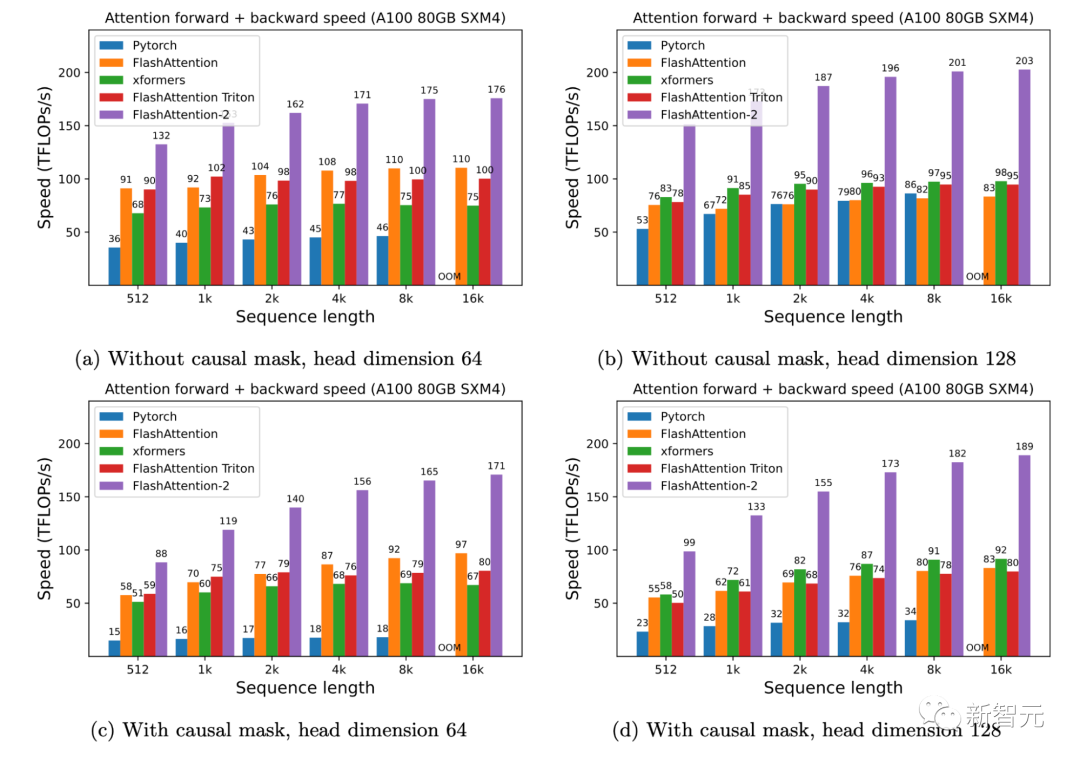
▲A100 GPU上的前向+后向速度
只需在H100 GPU上運行相同的實現(xiàn)(不需要使用特殊指令來利用TMA和第四代Tensor Core等新硬件功能),研究人員就可以獲得高達(dá)335 TFLOPs/s的速度。
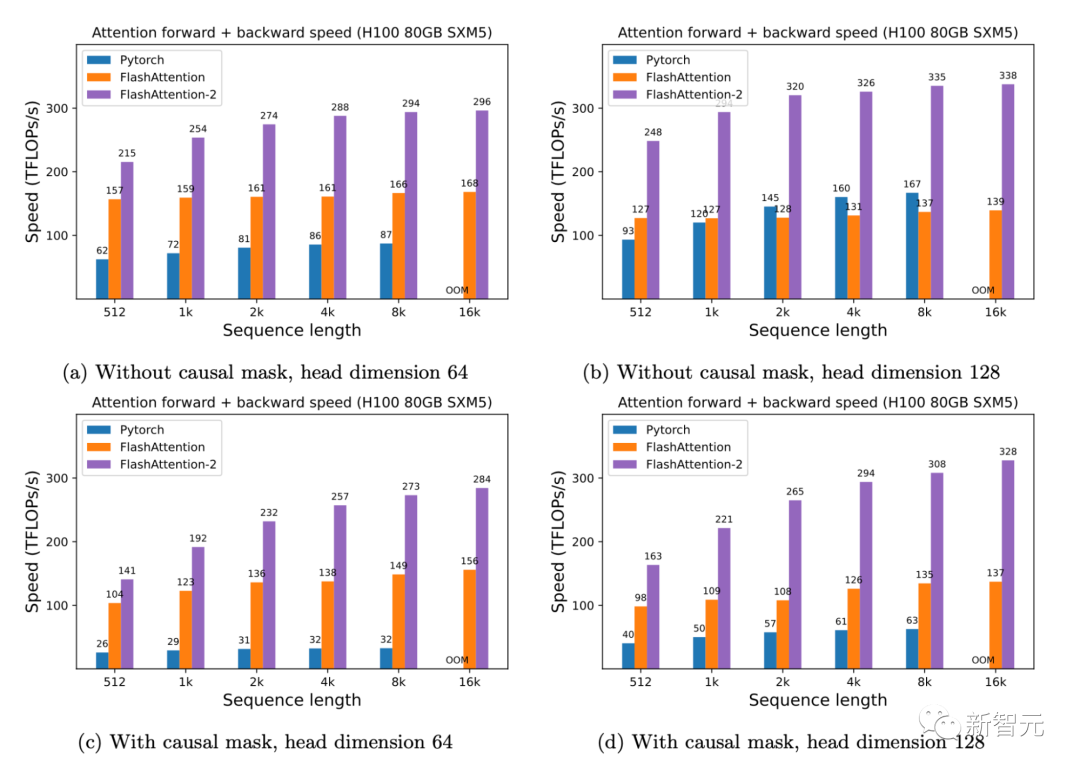
▲H100 GPU上的前向+后向速度
當(dāng)用于端到端訓(xùn)練GPT類模型時,F(xiàn)lashAttention-2能在A100 GPU上實現(xiàn)高達(dá)225TFLOPs/s的速度(模型FLOPs利用率為72%)。與已經(jīng)非常優(yōu)化的FlashAttention模型相比,端到端的加速進(jìn)一步提高了1.3倍。
 ?
? ?
?未來的工作
速度上快2倍,意味著研究人員可以用與之前訓(xùn)練8k上下文模型相同的成本,來訓(xùn)練16k上下文長度的模型。這些模型可以理解長篇書籍和報告、高分辨率圖像、音頻和視頻。同時,F(xiàn)lashAttention-2還將加速現(xiàn)有模型的訓(xùn)練、微調(diào)和推理。在不久的將來,研究人員還計劃擴大合作,使FlashAttention廣泛適用于不同類型的設(shè)備(例如H100 GPU、AMD GPU)以及新的數(shù)據(jù)類型(例如fp8)。下一步,研究人員計劃針對H100 GPU進(jìn)一步優(yōu)化FlashAttention-2,以使用新的硬件功能(TMA、第四代Tensor Core、fp8等等)。將FlashAttention-2中的低級優(yōu)化與高級算法更改(例如局部、擴張、塊稀疏注意力)相結(jié)合,可以讓研究人員用更長的上下文來訓(xùn)練AI模型。研究人員也很高興與編譯器研究人員合作,使這些優(yōu)化技術(shù)更好地應(yīng)用于編程。
 ?作者介紹
?作者介紹Tri Dao曾在斯坦福大學(xué)獲得了計算機博士學(xué)位,導(dǎo)師是Christopher Ré和Stefano Ermon。根據(jù)主頁介紹,他將從2024年9月開始,任職普林斯頓大學(xué)計算機科學(xué)助理教授。
Tri Dao的研究興趣在于機器學(xué)習(xí)和系統(tǒng),重點關(guān)注高效訓(xùn)練和長期環(huán)境:- 高效Transformer訓(xùn)練和推理 - 遠(yuǎn)程記憶的序列模型 - 緊湊型深度學(xué)習(xí)模型的結(jié)構(gòu)化稀疏性。
值得一提的是,Tri Dao今天正式成為生成式AI初創(chuàng)公司Together AI的首席科學(xué)家。

原文標(biāo)題:讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2904文章
44306瀏覽量
371463
原文標(biāo)題:讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
阿里通義千問發(fā)布Qwen2.5-Turbo開源AI模型
SystemView上下文統(tǒng)計窗口識別阻塞原因
鴻蒙Ability Kit(程序框架服務(wù))【應(yīng)用上下文Context】
編寫一個任務(wù)調(diào)度程序,在上下文切換后遇到了一些問題求解
OpenAI發(fā)布GPT-4o模型,支持文本、圖像、音頻信息,速度提升一倍,價格不變
微信大模型擴容并開源,推出首個中英雙語文生圖模型,參數(shù)規(guī)模達(dá)15億
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
關(guān)于嵌入式C語言的弱符號和弱引用解析
TC397收到EVAL_6EDL7141_TRAP_1SH 3上下文管理EVAL_6EDL7141_TRAP_1SH錯誤怎么解決?
OpenAI一鍵調(diào)用GPTs功能上線
ISR的上下文保存和恢復(fù)是如何完成的?
成都匯陽投資關(guān)于多模態(tài)驅(qū)動應(yīng)用前景廣闊,上游算力迎機會!
成都匯陽投資關(guān)于谷歌攜 Gemini 王者歸來,AI 算力和應(yīng)用值得期待
降低Transformer復(fù)雜度O(N^2)的方法匯總






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論