 基于多曝光圖像生成的低照度圖像增強方法
基于多曝光圖像生成的低照度圖像增強方法
低照度圖像會使很多計算機視覺算法的魯棒性降低,嚴重影響機器人領域的許多視覺任務,如自動駕駛、圖像識別以及目標追蹤等。為獲取具有更多細節信息以及更大動態范圍的增強圖像,提出了一種基于多曝光圖像生成的低照度圖像增強方法。該方法通過分析真實拍攝的多曝光圖像,發現不同曝光時長的圖像的像素值之間存在線性關系,使得正交分解的思想可以應用于多曝光圖像生成。多曝光圖像是根據物理成像機制生成的,與真實拍攝圖像更為相近。在將原圖分解得到光照不變量和光照分量后,通過設計自適應算法生成不同的光照分量,再與光照不變量合成可以得到多曝光圖像。最后利用多曝光圖像融合方法獲取具有更大動態范圍的增強圖像。該融合結果與輸入圖像保持一致,最終的增強圖像可有效保留原始圖像的色彩,自然度高。在真實拍攝的低照度圖像公開數據集上進行了實驗并與現有先進算法進行對比,結果表明,本文方法得到的增強圖像與參考圖像之間的結構相似性提高了2.1%,特征相似性提高了4.6%,增強圖像與參考圖像更接近且自然度更高。
在低光照條件下或相機曝光時間不足的情況下拍攝的圖像稱為低照度圖像。低照度圖像通常具有低亮度、低對比度以及結構信息模糊的特點,這給很多機器人視覺任務帶來了困難,如低照度圖像的人臉識別、目標跟蹤[1]、自動駕駛[2]、特征提取[3]等任務。低照度圖像的增強方法不僅可以改善圖像的視覺效果,還可以提高后續機器人視覺任務算法的魯棒性,具有重要的實際應用價值。
根據是否需要依賴大量的數據進行訓練,目前已有的低照度圖像增強算法可以分為傳統方法和基于深度學習的方法兩類。在傳統的低照度圖像增強方法中,基于直方圖的方法[4-5]通過調整圖像的直方圖來提高圖像的對比度,達到增強低照度圖像的目的,這類方法簡單高效,但缺乏物理機制,常常導致圖像的過增強或欠增強,并且圖像的噪聲也會被明顯地放大。基于Retinex理論[6]的方法先通過將圖像分解得到光照分量和反射分量,再分別進行增強。Wang等[7]設計了一個低通濾波器將圖像分解為反射圖像和光照圖像,并使用一個雙對數變換對圖像進行增強來平衡自然度和圖像細節。Guo等[8]先對低照度圖像的RGB三通道取最大值得到一個初始的光照圖像,再通過結構先驗信息來修正初始光照,使用伽馬校正法調整圖像亮度,再將調整后的光照圖像與反射圖像合成得到最終的增強結果。Ren等[9]提出了一種抑制噪聲的序列評估模型來分別估計光照分量和反射分量,在這種噪聲抑制的序列分解過程中,對每個分量進行空間平滑并巧妙地利用權重矩陣來抑制噪聲和提高對比度,最后將估計得到的反射分量與伽馬校正后的光照分量合并得到增強圖像,最終達到低照度增強聯合去噪的目的。
基于深度學習的方法[10-13]通過對大量數據的訓練,在低照度圖像增強上取得了很好的效果。Lore等[10]最先提出了一個用于對比度增強和噪聲消除的深度自動編碼器來增強低照度圖像。Wei等[11]將Retinex模型和深度神經網絡結合用于低照度圖像增強中。Jiang等[12]利用生成式對抗網絡實現了低照度圖像增強模型,該模型無需使用配對的訓練數據進行訓練。Guo等[13]將低照度圖像增強任務轉換為一項具有深度網絡的特定曲線估計任務。這些基于深度學習的方法的訓練過程通常需要耗費大量的時間和計算資源。并且這些方法的效果在很大程度上取決于訓練數據,不準確的參考圖像會影響訓練結果,比如在真實拍攝的正常光照圖像中,由于光照不均勻可能存在局部高光照區域過曝光或局部低光照區域欠曝光的問題。
在低照度圖像增強中,不均勻的光照也是一個需要解決的問題。對于局部低照度圖像來說,將圖像亮度提升過高會導致圖像的高光照區域過曝光,而亮度提升不足又無法將低光照區域的圖像細節信息展示出來。得益于拍照設備的進步,可以固定拍照設備并在短時間內獲取不同曝光時長的圖像,并將拍攝所得的一組圖像融合得到具有更大動態范圍的圖像。Wang等[14]在YUV色彩空間中設計了一種基于邊緣信息保留的平滑多尺度曝光融合算法,可以同時保留場景中高光照區域和低光照區域中的細節,為了彌補融合過程中丟失的細節信息,設計了一個矢量場構造算法從矢量字段中提取可見的圖像細節,且該方法可避免圖像融合過程中出現的顏色失真。圖像融合的方法雖然可以有效地提高圖像動態范圍,但需要預先獲取一組不同曝光時長的圖像,無法對單張低照度圖像增強。拍攝動態場景或拍攝時相機發生抖動都會使得所拍攝的圖像對準困難,進而導致融合結果中存在偽影。
為了將圖像融合的方法應用到低照度圖像增強中達到提高圖像動態范圍的目的,需要先根據單張圖像生成一組用于融合的信息。目前已有一些方法將圖像融合的思想用于低照度圖像增強。其中,Fu等[15]先通過一種基于形態學閉合的光照估計算法將圖像分解得到光照圖像和反射圖像,再分別使用Sigmoid函數和自適應直方圖均衡化算法對照明圖像進行處理得到亮度提升后的光照圖像和對比度增強的光照圖像,將兩個增強后的光照圖像進行融合再與反射圖像合成得到最終的增強圖像。Cai等[16]采集了589組多曝光圖像,并用13種已有的方法對多曝光圖像進行融合,選取最優結果作為參考圖像,設計了一個卷積神經網絡在這個數據集上進行訓練,最終得到一個低照度圖像增強器。基于圖像融合的單張低照度圖像增強方法有效解決了圖像融合需要多張曝光圖像作為輸入圖像的問題,但Fu等[15]和Cai等[16]的方法仍然存在缺乏物理機制的問題。
針對目前方法存在的問題,本文提出了一個基于多曝光圖像生成的低照度圖像增強方法。首先從物理成像機制出發,分析了曝光圖像之間的關系,發現不同曝光時長的圖像之間存在與陰影和非陰影圖像之間相似形式的關系。基于此,首次提出將正交分解方法[17]用于多曝光圖像融合,即使用正交分解的方法將圖像分解得到光照分量與光照不變量,通過改變光照分量生成具有不同曝光時長的圖像。再利用圖像融合的方法將生成圖像融合得到具有高動態范圍的圖像。由于生成的圖像與真實拍攝的圖像比較接近,融合所得的增強圖像自然度也保持得很好。同時,由單張圖像生成的多曝光圖像是逐像素對應的,融合結果不存在偽影,也解決了拍攝多曝光圖像時相機需要固定的問題。并且,本文方法無需依賴大量的數據進行訓練,具有很好的通用性。
2 多曝光圖像的生成與低照度圖像增強
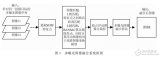
本文方法主要包含3個部分:(1)圖像正交分解。將原圖分解得到一個光照分量和一個光照不變量。(2)多曝光圖像生成。通過改變光照分量的大小生成多曝光光照分量,并將其與原始光照不變量合成,得到多曝光圖像;(3)多曝光圖像融合。將多曝光圖像融合,得到最終增強后的圖像。圖 1所示為本文算法框架。
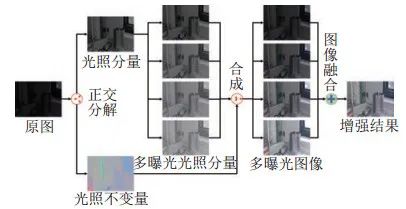
圖 1算法框架
2.1
多曝光圖像之間的線性關系
通過實驗發現,在光照和相機參數固定的情況下所拍攝的不同曝光度的圖像之間存在線性關系,如圖 2所示,圖 2(a)為一組不同曝光時長下拍攝的色板圖像,圖 2(b)分別展示了RGB三通道在不同曝光度下色板中24個顏色的真實像素值與擬合線,綠色圓圈代表了真實像素值,紅色實線代表擬合線,像素值均為伽馬校正前的RGB像素值,橫坐標代表前4張色板圖像的像素值,縱坐標代表第5張色板圖像的像素值。
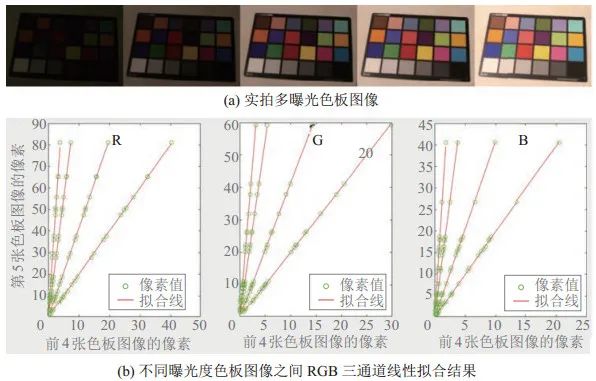
圖 2實拍多曝光圖像的像素間的線性關系
圖 2中所示的線性關系可以表達為
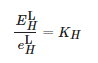
(1)
其中E 和e 分別代表長曝光時間和短曝光時間的像素值,H 代表R、G、B三個通道,L代表伽馬校正前的情形,KH為不同曝光下的像素之間的比值。由于3個通道的KH的擬合值大小近似,故在本文中,設置KR=KG=KB。
2.2
圖像正交分解
對式(1)中的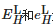 進行伽馬校正后可以得到:
進行伽馬校正后可以得到:
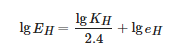
(2)
這與同一物體在陰影區域和非陰影區域中的像素所展示出的RGB三通道之間的關系[18]有相似的表達形式。
與文[17]中相似,由式(1)可以得到:
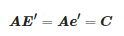
(3)
其中
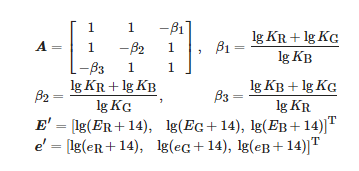
C可以由像素值計算得到。
對圖像中任一像素,像素值為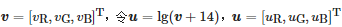 ,由式(3)可得:
,由式(3)可得:
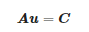
(4)
本課題組首次在文[17]中提出正交分解方法,如式(5)所示:
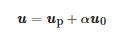
(5)
其中u0為方程(4)的自由解,滿足Au0=0 ,∥u0∥=1 ,up是方程(4)滿足up⊥u0的唯一特解。圖像的任意一個像素所對應的up與α 均可通過圖像的像素值計算得到。圖 3所示為陰影圖像中與多曝光圖像中正交分解的示意圖。通過線性代數可知自由解u0只與KH相關:在陰影圖像中,KH為只受光照條件影響的參數;在多曝光圖像中,KH為只受不同曝光時間下入射光影響的參數。而特解up垂直于自由解u0意味著特解up與自由解u0互相獨立正交,即特解up具有光照不變性質。這意味著,對于一個給定的像素,無論該像素點在何種曝光時間下拍攝,在對該點的像素值進行正交分解后都可得到一個垂直于自由解且不受不同曝光時間下入射光影響的唯一特解up,而α 的大小則體現了光照的變化。整張圖像的up組成了光照不變量,整張圖像的α 組成了光照分量。
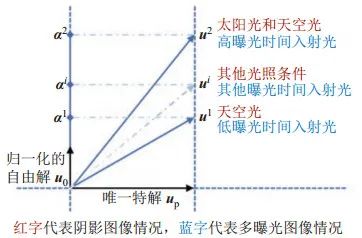
圖 3陰影圖像與多曝光圖像中的正交分解示意圖
2.3
自適應生成多曝光圖像
在得到原圖的光照不變量與光照分量后,對光照分量進行增強或減弱即可得到具有不同曝光時長的光照分量:
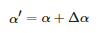
(6)
其中Δα 為光照增量,通過控制Δα 的大小,即可得到不同曝光時長的光照分量。再通過式(7)即可生成不同曝光時長的圖像:
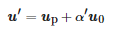
(7)
最后根據式(8)對u′ 變換得到相應RGB空間內的像素值,其中13×1表示3×1 維的全1矩陣。
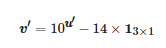
(8)
圖 4所示為一組真實拍攝的多曝光圖像和通過控制Δα 的大小生成的多曝光圖像,生成圖像均為通過將實拍圖 1作為原始圖像生成所得。從圖中可以看出,生成圖像與實拍圖像之間的差異隨著生成圖像與原始圖像之間的亮度差的增大而增大。

圖 4一組實拍多曝光圖像與生成的多曝光圖像
為了自動地生成具有不同曝光時長的多曝光圖像,設計了自適應生成多曝光圖像的算法,可以根據原圖的亮度自動選擇光照增量Δα 的大小,并生成N 張不同曝光時長的圖像。
將圖像中任一像素(像素值v=[vR,vG,vB]T的亮度定義如下:
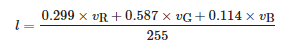
(9)
整張圖像的亮度L如下:
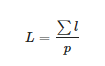
(10)
其中p 代表整個圖像的像素總數。
記N張生成圖像所對應的光照增量為Δαi,i= 1,2,?,N ,首先確定其中最小的光照增量Δα1和最大的光照增量ΔαN,之后在Δα1到ΔαN之間根據式(11)均勻生成N個光照增量:
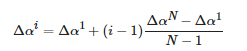
(11)
當L<0.3 時,只生成光照分量增大的圖像,即令最小的光照增量Δα1=0 。根據式(12)求最大的光照增量ΔαN?:
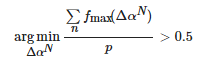
(12)
其中,
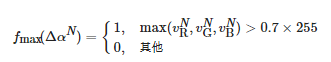
(13)
其中,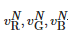 分別代表原像素在光照分量增加了ΔαN?之后的R、G、B三通道的像素值。
分別代表原像素在光照分量增加了ΔαN?之后的R、G、B三通道的像素值。
由于生成圖像與原圖之間的光照增量越大,所生成的圖像與真實的不同曝光圖像之間的誤差越大,故當ΔαN>1.2 時,令ΔαN=1.2 。
當L>0.3 時,既生成光照分量增大的圖像,也生成光照分量減小的圖像。ΔαN的獲取方式與當L<0.3 時的方式相同。根據式(14)求Δα1?:
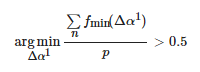
(14)
其中,

(15)
其中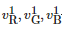 分別代表原像素在光照分量增加了Δα1之后的R、G、B三通道的像素值。當Δα1
分別代表原像素在光照分量增加了Δα1之后的R、G、B三通道的像素值。當Δα1
本文中設置N= 5,圖 5所示為一組自適應生成的多曝光圖像。從圖中可以看出,生成圖 5在低光照區域的雕塑上得到了顯著增強,但在高光照區域(即窗外場景中)過曝光;而在生成圖 3中,高光照區域得到了合適的曝光,但低光照區域欠曝光。上述現象說明模擬自然拍攝生成的不同曝光圖像無法同時恰當地展示出高光照區域和低光照區域的圖像信息。

圖 5一組自適應生成的多曝光圖像
2.4
多曝光圖像融合
為了得到更大動態范圍的增強圖像,本文采用多尺度曝光融合方法[14]將多曝光圖像融合生成最終的增強圖像。與該方法利用拍攝所得的一組多曝光圖像進行融合不同,本文將單張圖像自適應生成的N 張不同曝光圖像用于融合,實現了對單張低照度圖像的增強,并且可以有效避免拍攝動態場景或相機抖動所帶來的偽影問題。具體算法如下:
(1) 根據原圖通過2.3節中的方法生成N 張多曝光圖像Qk(k=1,2,?,N ),本文中設置 N= 5。
(2) 將Qk(k=1,2,?,N ),從RGB顏色空間轉換到YUV顏色空間得到 Ik(k=1,2,?,N )。
(3) 根據式(16)計算多曝光圖像的加權圖:
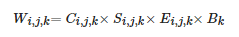
(16)
其中i,j 代表像素位置,C、S、E和B分別代表根據對比度、飽和度、曝光時長以及圖像亮度計算得到的權重,具體計算方法參考文[14]。為使得權重的和為1,對Wij,k歸一化得到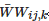 。
。
(4) 對Ik和分別建立拉普拉斯金字塔和高斯金字塔得到 ,n 代表金字塔的層數,與文[14]相同,n=?log2min(h,w)??2 ,h 和w 分別代表圖像的行數和列數,??? 為向下取整符號。
,n 代表金字塔的層數,與文[14]相同,n=?log2min(h,w)??2 ,h 和w 分別代表圖像的行數和列數,??? 為向下取整符號。
(5) 對1到n?1 層金字塔根據式(17)進行融合:
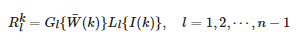
(17)
(6) 對第n層金字塔根據式(18)進行融合:
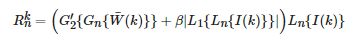
(18)
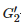 代表高斯濾波器,用于平滑
代表高斯濾波器,用于平滑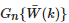 ,當k= 1,2時,令β=1.5 ;當k=3,4,5 時,令β=0 。
,當k= 1,2時,令β=1.5 ;當k=3,4,5 時,令β=0 。
(7) 由下式得到最終的低照度圖像增強結果:
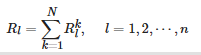
(19)
3 實驗結果與分析
3.1
參數設置
為了確定生成多曝光圖像張數N與算法性能之間的關系,在LOL數據集[11]的500張圖像上對本文算法進行測試,并采用3個評價指標對N取不同值時的增強結果進行評價,如圖 6所示。
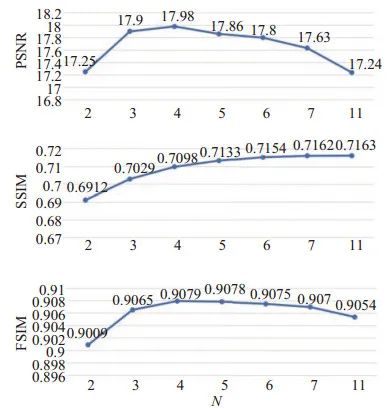
圖 6參數N的選擇與LOL數據集上的評價結果
峰值信噪比(PSNR)、結構相似性(SSIM)和特征相似性(FSIM)[19]這3個全參考的評價指標,均為值越大說明增強效果越好。從圖 6中可以看出,指標PSNR先是隨著N的增大而提高,在 N= 4時達到最大,之后隨著N的增大而降低,這是因為當 N太小時輸入信息不足,而當N太大時融合結果中的噪聲會被放大,指標PSNR反而會降低;指標SSIM隨著 N的增大而提高,這是因為當輸入圖像增多,提供的信息也隨之增多,融合所得結果的結構也越清晰;指標FSIM在N= 2時較低,在N> 2時N的取值對指標FSIM影響不大。綜合考慮這3個指標,本文中將N設置為5。
3.2
公開數據集上的對比實驗
本節分別從主觀恢復效果和客觀評價指標2個方面,對本文方法與5個代表性的低照度增強方法在2個公開數據集的測試集上進行對比。其中,NPE方法[7]、LIME方法[8]、JED方法[9]為傳統方法,RetinexNet方法[11]和ZeroDCE++方法[13]為基于深度學習的方法。LOL數據集[11]的測試集包含15組圖像,其中低照度圖像和參考圖像均為相機拍攝所得。MIT數據集[20]的測試集包含500組圖像,其中低照度圖像為相機拍攝所得,參考圖像為由5位攝影師(A/B/C/D/E)利用軟件手動調整所得,本文采用攝影師C的調整結果作為參考圖像,并將圖像轉為400×400像素大小的PNG格式圖像用于測試。圖 7展示了LOL測試集[11]上的低照度圖像增強結果,圖 8和圖 9分別展示了MIT測試集[20]上的室外和室內低照度圖像增強結果。從圖 7可以看出,本文方法的增強結果與參考圖像最為接近,說明本文方法的增強結果最接近真實拍攝圖像。NPE方法[7]成功提升了圖像的亮度,且增強了圖像的飽和度,使得圖像色彩更鮮明,但是在一些情況下會存在顏色失真的問題,如在圖 9(a)的恢復結果中臉部皮膚泛紅,在圖 9(b)的恢復結果中黑色衣服發白。
LIME方法[8]同樣成功提升了圖像的亮度,且圖像的對比度得到了增強,但存在局部高光照區域過增強的問題,如在圖 9(e)的恢復結果中,臉部由于過增強得到了過曝光的增強結果。JED方法[9]的增強結果中圖像亮度略低于其他方法,且去噪算法導致恢復圖像存在過平滑現象而缺失細節紋理信息。RetinexNet方法[11]的增強結果很好地突出了圖像的結構信息,但是增強圖像與真實拍攝圖像的風格差異較大,存在不自然的問題。ZeroDCE++方法[13]同樣存在增強結果的風格變化問題,如圖 8(b)和圖 9中所示,ZeroDCE++方法[13]的增強結果發白。與以上方法相比,本文方法的增強結果對原始色彩的保持更好,與真實拍攝圖像的顏色更接近,且能夠成功地將高光照區域和低光照區域的圖像信息同時展現在增強結果中,沒有對高光照區域過增強導致過曝光。

圖 7LOL測試數據集[11]上低照度圖像的增強結果

圖 8MIT測試數據集[20]上室外低照度圖像的增強結果

圖 9MIT測試數據集[20]上室內低照度圖像的增強結果
為了定量評價本文方法的增強效果,采用全參考的評價指標PSNR、SSIM和FSIM[19]對各個方法的增強結果進行評價。其中PSNR越大,說明增強結果與參考圖像在像素值上越接近;SSIM越大,說明增強結果與參考圖像在結構上越接近;FSIM越大,說明增強結果與參考圖像在特征上越接近。
表 1給出了LOL測試集[11]上不同方法的定量評價結果,表 2給出了MIT測試集[20]上不同方法的定量評價結果。其中最優的指標值以紅色表示,次優的指標值以藍色表示。從表 1可以看出,本文方法在LOL測試集[11]上3個評價指標均最優,即本文方法得到了與真實拍攝圖像最為接近的增強結果。從表 2可以看出,本文方法在MIT測試集[20]上SSIM和FSIM均取得最優結果,PSNR取得了次優的結果,說明本文方法的增強結果與手工調整的參考圖像在結構和特征上最為接近。
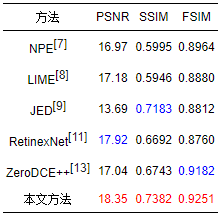
表 1LOL測試集[11]上的定量評價結果
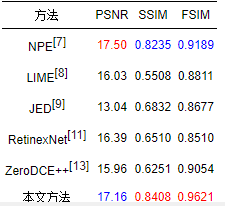
表 2MIT測試集[20]上的定量評價結果
3.3
多曝光融合實驗分析
本節首先對本文所生成的多曝光圖像與固定相機拍攝的多曝光圖像在融合增強性能方面進行了對比,效果如圖 10所示。其中圖 10(a)(b)為固定相機后拍攝的具有不同曝光時長的圖像,圖 10(c)為本文方法將圖 10(a)作為輸入圖像得到的增強結果,圖 10(d)為將圖 10(a)(b)作為輸入圖像融合得到的結果。從圖中可以看出,本文方法增強結果圖 10(c)的對比度好于實拍多曝光圖像的融合結果圖 10(d),并且從紅框放大區域可以看出,本文方法結果的清晰度要更高。從圖 10(d)的黃框中可以看到,由于拍攝到動態場景(騎摩托車的人)而在融合中產生了偽影,但此問題在本文方法的結果中則不存在。

圖 10本文方法與實拍多曝光圖像融合結果對比
其次,對本文生成的多曝光圖像融合結果與單一增加曝光結果進行了圖像增強效果對比,如圖 11所示。在僅僅增加曝光量的實驗結果中,原圖像中光照低的部分(如建筑)得到了明顯的增強,但原圖像中光照高的部分(如天空和燈)則由于過曝光而丟失了原有圖像的信息,在多曝光融合的結果中,則成功將低光照和高光照部分的信息同時保留,說明本文方法可以在有效提高圖像亮度的同時得到具有更大動態范圍的增強結果。

圖 11多曝光融合結果與增加曝光結果對比
4 結論
提出了一個基于多曝光圖像生成的低照度圖像增強方法。該方法基于物理機制,根據單張低照度圖像生成多曝光圖像,實現了單張圖像的低照度增強,其效果優于一些現有的單張低照度圖像增強方法以及多張曝光圖像融合的方法。本文提出的根據單張低照度圖像進行增強的方式,可有效避免偽影的產生,與使用多張曝光圖像進行融合的方式相比具有更好的通用性。
審核編輯:劉清
-
機器人
+關注
關注
210文章
28231瀏覽量
206615 -
低通濾波器
+關注
關注
14文章
473瀏覽量
47341 -
RGB
+關注
關注
4文章
798瀏覽量
58394 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930 -
自動駕駛
+關注
關注
783文章
13694瀏覽量
166166
原文標題:基于多曝光圖像生成的低照度圖像增強
文章出處:【微信號:機器視覺沙龍,微信公眾號:機器視覺沙龍】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于Matlab的圖像增強與復原技術在SEM圖像中的應用

運動相機的多曝光圖像融合技術
基于Retinex圖像增強
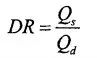
一種全新的遙感圖像描述生成方法

一種基于改進的DCGAN生成SAR圖像的方法

基于圖像的數據增強方法發展現狀綜述


基于差分卷積神經網絡的低照度車牌圖像增強網絡






 工商網監
工商網監
評論