 在大算力芯片領域“彎道超車”的機會
在大算力芯片領域“彎道超車”的機會
導讀
關于“彎道超車”,行業內很多人士對此嗤之以鼻,他們認為:做事情要腳踏實地,持之以恒,才有可能超越。
但這兩者并不矛盾:在已有的不斷發展的領域,我們需要“數十年如一日”不斷的努力,才有可能逐漸追趕上世界先進水平,才有可能從追趕到齊頭并進甚至超越;比如航天科技領域。但在一些行業變革期,我們需要盡早布局,大干快上,從而形成領先優勢;比如從燃油車向電動車發展的歷史發展機遇。
今天這篇文章,我們探討一下,在大算力芯片領域“彎道超車”的機會。
01.關于計算架構階段的劃分
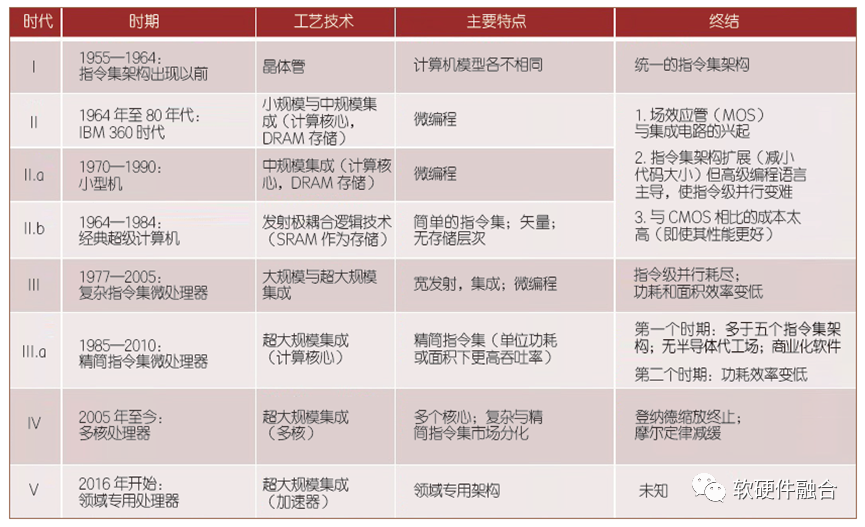
圖靈獎獲得者John Hennessy總結了計算機體系結構的四個時代和即將興起的第五個時代:
第一代,晶體管時代,指令集架構出現之前,計算機架構各不相同;
第二代,小規模和中等規模集成電路時代,出現支持指令集架構的CPU處理器;
第三代,大規模和超大規模集成電路時代,指令級并行以及CISC和RISC混戰;
第四代,超大規模集成電路的多核處理器并行時代;
第五代,從2016年超大規模的領域專用處理器(DSA)時代。
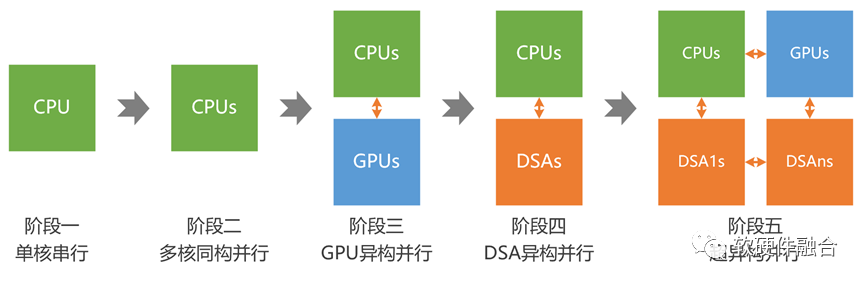
上面計算機體系結構的時代劃分,是站在單處理器引擎視角進行的。我們參考上述五個時代的劃分,并且站在多處理器引擎計算架構從簡單到復雜的發展視角,重新進行了如下的發展階段劃分:
第一階段,單CPU的串行計算;
第二階段,多CPU的同構并行計算;
第三階段,CPU+GPU的異構并行計算;
第四階段,CPU+DSA的異構并行計算;
第五階段,(還在萌芽期的)多種異構融合的超異構并行計算。
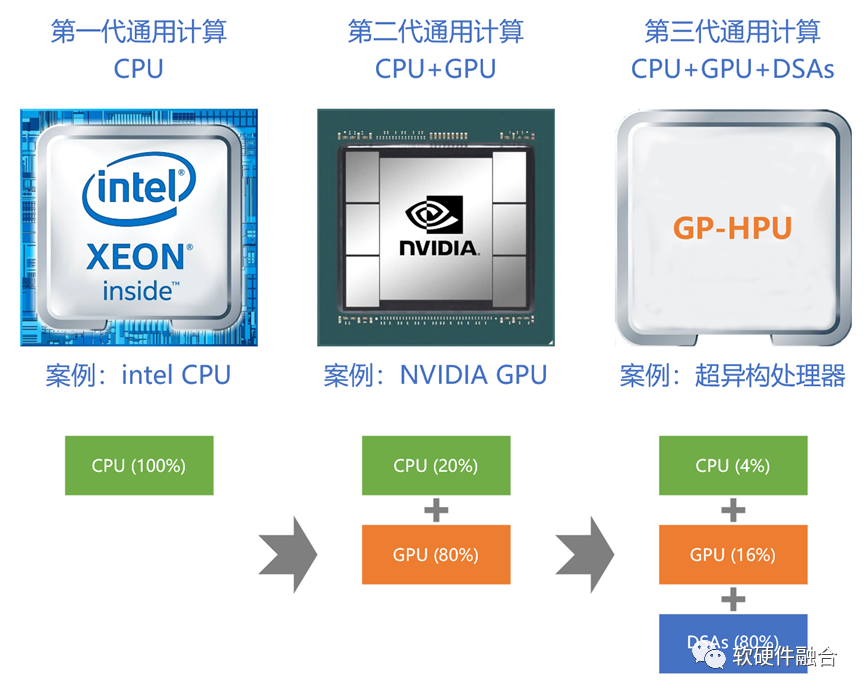
如果我們為計算架構再加一個約束——通用,則計算架構可以劃分為三個階段:
第一階段,CPU同構計算(單核CPU階段可以合并進CPU同構計算);
第二階段,基于GPU的同構計算(DSA是一種偏定制的架構,單個DSA的異構不屬于通用計算范疇);
第三階段,基于CPU+GPU+DSAs的超異構計算。
“二八定律”無處不在:隨著系統的擴大,會逐漸沉淀許多共性的計算任務。我們定性的分析一下,依據二八定律:
在CPU同構計算階段,100%工作由CPU完成;
但在GPU異構階段,80%工作由GPU完成,CPU只完成剩余的20%的工作;
而在超異構計算階段,則80%的工作由各類更高效的DSA完成,GPU只完成剩余20%工作的80%,即16%的工作,剩余的4%交給CPU。
02.從異構到超異構
2.1 CPU性能瓶頸,異構計算成為主流
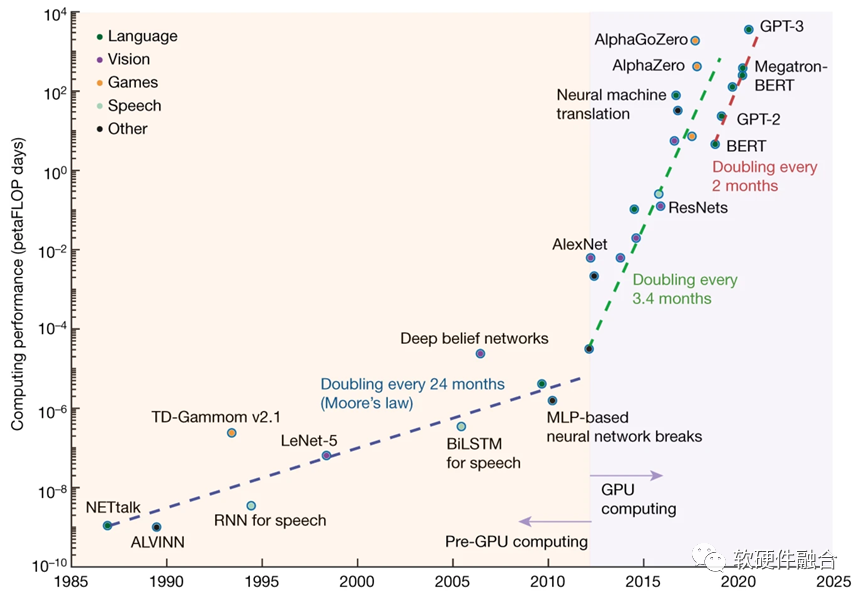
上世紀80-90年代,每18個月,CPU性能提升一倍;如今,CPU性能提升每年只有3%,要想性能翻倍,需要20年。雖然CPU的性能提升幾乎停滯,但對性能和算力的更高需求,是永無止境的,例如:
2012-2018年共6年時間里,人們對于AI算力的需求增長了超過30萬倍;隨著BERT、GPT等大模型的發展,算力需求每2個月就翻一倍。
隨著大模型的發展,對算力的需求水漲船高,要想實現L5級別的自動駕駛算力,則需要上萬TOPS。與此同時,隨著自動駕駛進入L5階段,對娛樂的需求必然猛增。多域融合的智能汽車綜合算力需求預計會超過兩萬TOPS。
Intel前SVP拉加·庫德里表示,要想實現元宇宙級別的用戶體驗,需要當前的算力提升1000倍。
從2012年深度學習興起開始,隨著AI等大算力場景的算力需求越來越大,異構計算已經成為計算架構的主流。
2.2 異構計算的問題
性能和靈活性的矛盾:系統越復雜,越需要靈活的處理器;性能挑戰越大,越需要定制的加速處理器。問題的本質在于:單一的處理器是無法兼顧性能和靈活性的。 由于在異構計算系統中,CPU不承擔主要的計算任務,因此加速處理器決定了異構系統的性能/靈活性特征:
GPU靈活性較好,但性能效率不夠極致;并且性能也逐漸接近瓶頸。
DSA性能好;但靈活性差,難以適應算法的多變;架構碎片化;落地困難。
FPGA功耗和成本高,定制開發,落地案例少,通常用于原型驗證。
ASIC功能完全固定,無法適應靈活多變的復雜計算場景。
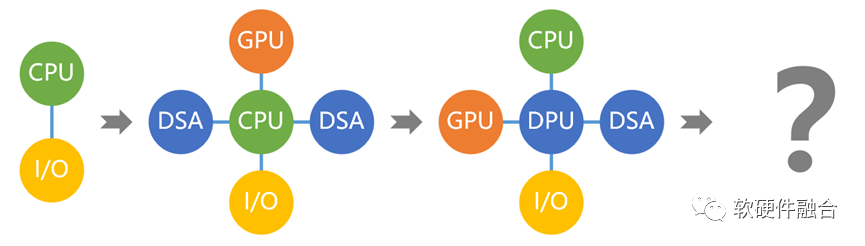
隨著異構計算成為主流,異構的系統越來越多。多異構共存的異構計算孤島問題凸顯:
加速處理器只考慮本領域問題,難以考慮全局協同;
各領域加速器之間交互困難;
中心單元的性能瓶頸問題;
物理空間有限,無法容納多個物理的異構加速卡。
2.3 多種異構的融合:超異構
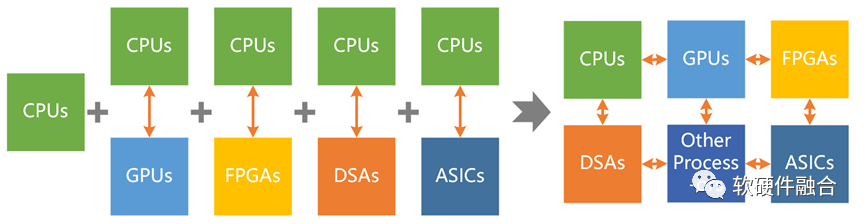
要想高性能,需要硬件層次的更高集成度,更需要系統層次的多種異構融合(即超異構)。 超異構計算:系統復雜度顯著上升,系統更難駕馭。如何在快速提升性能的同時,讓系統更好駕馭,是超異構計算要解決的關鍵問題。
03.大算力芯片的核心能力:通用、通用,還是通用
3.1 系統越來越大,對通用靈活性的要求遠高于對性能的要求
在云和邊緣數據中心,都是清一色的服務器。這些服務器,可以服務各行各業、各種不同類型的場景的服務端工作任務的處理。CSP每年投入數以億計資金,上架數以萬計的各種型號、各種配置的服務器的時候,嚴格來說,它并不知道,具體的某臺服務器最終會售賣給哪個用戶,這個用戶到底會在服務器上面跑什么應用。
并且,未來,這個用戶的服務器資源回收之后再賣個下一個用戶,下一個用戶又用來干什么,也是不知道的。因此,對CSP來說,最理想的狀態是,存在一種服務器,足夠通用,即不管是哪種用戶哪種應用運行其上,都足夠高效快捷并且低成本。
只有這樣,系統才夠簡單而穩定,運維才能簡單并且高效。然后要做的,就是把這種服務器大規模復制(大規模復制意味著單服務器成本的更快速下降)。 云和邊緣服務器場景,對系統的靈活性的要求遠高于對性能的要求,需要提供的是綜合性的通用解決方案。最直接的例子就是以CPU為核心的服務器:CPU通用靈活性是最好的,如果CPU的性能夠用,大家絕對不喜歡用各種加速;如今是CPU性能不夠,逼迫著大家不得不去使用各種硬件加速。 數據中心硬件加速最大的教訓是:在提升性能的同時,最好不要損失系統的靈活性。
其言下之意就是:目前各類加速芯片的優化方案損失了靈活性,從而使得芯片的落地很困難。這是目前全行業的痛點所在。
3.2 集群計算,對芯片的彈性可擴展能力提出了更高的要求
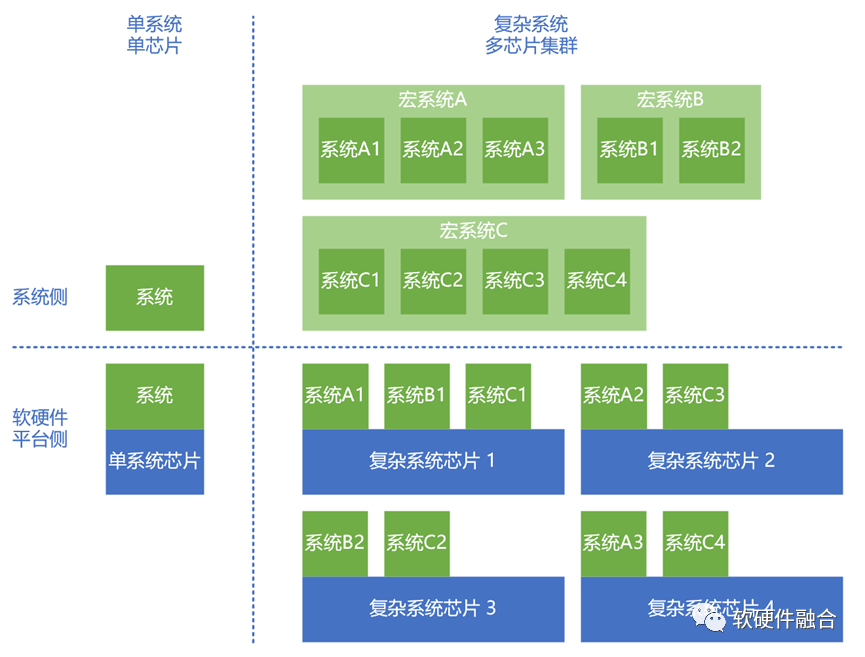
傳統的情況下,一個芯片對應一個系統。我們關注業務常見的需求,并把它實現在芯片的功能和特征里。但在集群計算,特別是目前云網邊端不斷融合的超大集群計算形式下,則需要關注的是“以不變應萬變”,即足夠通用的、數以萬計的計算設備組成的大規模計算集群,如何去覆蓋數以百萬計的眾多計算場景的問題。
這樣,對芯片內的資源彈性和芯片的可擴展性就提出了很高的要求,我們需要把數以萬計的計算芯片的計算資源合并到一個計算資源池,然后還可以非常方便的快速切分和重組,供不同規格計算任務的使用。
3.3 芯片研發成本越來越高,需要芯片的大規模落地,來攤薄研發成本
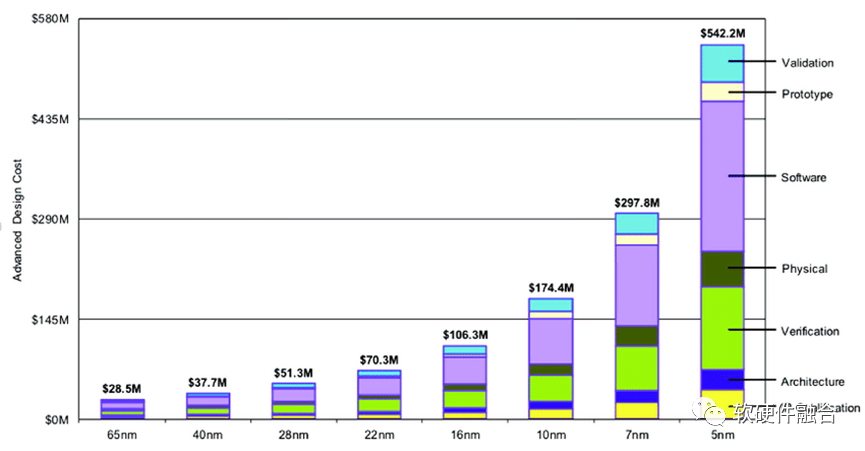
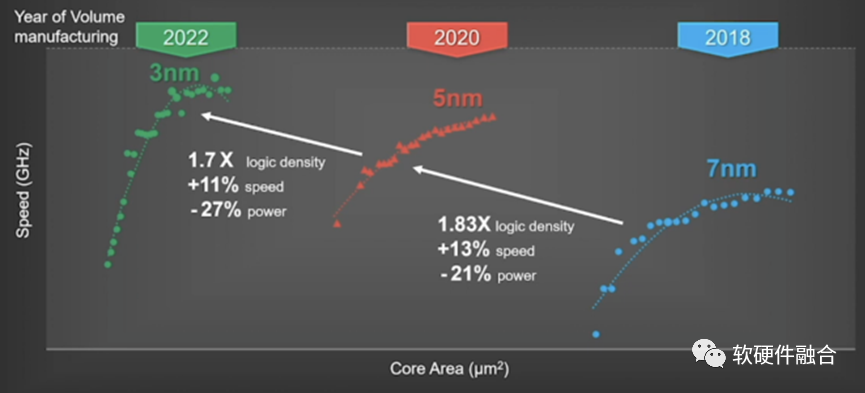
摩爾定律預示了:芯片工藝的發展,會使得晶體管數量大約每兩年提升一倍。雖然工藝的進步逐步進入瓶頸,但Chiplet越來越成為行業發展的重點,這使得芯片的晶體管數量可以再一次數量級的提升。 在先進工藝的設計成本方面,知名半導體研究機構Semiengingeering統計了不同工藝下芯片所需費用(費用包括了):
28nm節點開發芯片只需要5130萬美元;
16nm節點則需要1億美元;
7nm節點需要2.97億美元;
到了5nm節點,費用高達5.42億美元;
3nm節點的研發費用,預計將接近10億美元。
就意味著,大芯片需要足夠通用,足夠大范圍落地,才能在商業邏輯上成立。做一個保守的估算:
終端場景,(大)芯片的銷售量至少需要達到數千萬級才能有效攤薄一次性的研發成本;
在數據中心場景,則需要50萬甚至100萬以上的銷售量,才能有效攤薄研發成本。
04.超異構計算的載體:通用的超異構處理器
通用的超異構處理器(GP-HPU, General Purpose Hyper-heterogeneous Processing Unit, 通用超異構處理器),即能夠覆蓋幾乎所有場景的、以超異構計算為基礎架構的、綜合性的大算力單芯片。
4.1 超異構計算的關鍵,在于各類加速處理器的高效交互
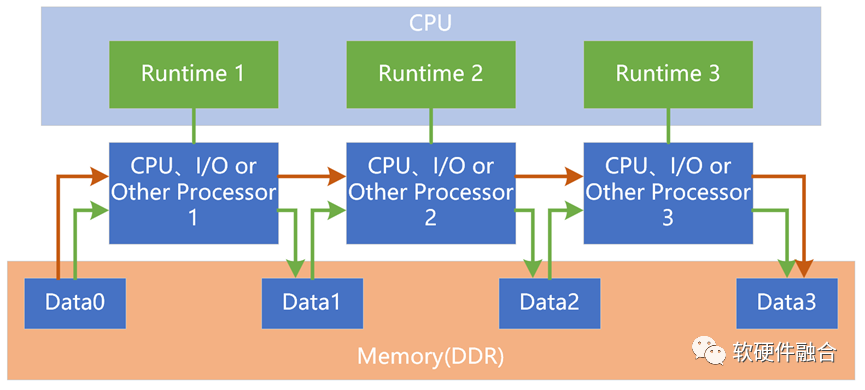
SOC和HPU都是多異構組成的混合計算,但SOC本質上屬于異構計算,而HPU屬于超異構計算。SOC僅僅是異構的集成,而HPU則需要實現異構的融合。 在SOC系統里,每個加速單元可以看做是CPU+加速單元組成一個異構子系統;不同的異構子系統之間在硬件上是沒有必然聯系,需要通過軟件構建異構子系統之間的交互和協同。
在CPU性能逐漸瓶頸的當下,這通常也意味著性能的約束。 而在HPU里,需要實現硬件層次的不同加速單元之間的直接的、高效的數據交互,不需要CPU的參與。在硬件層次,超異構需要實現CPU、GPU以及各種其他加速單元之間的對等的深度交互、協同和融合。
4.2 目前,多個獨立芯片組成超異構計算,還比較難
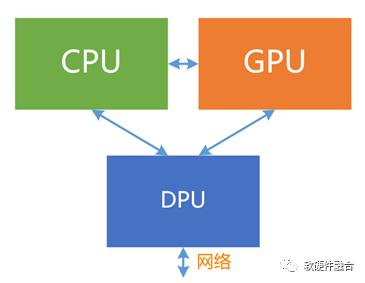
依據性能/靈活性特征,可以將系統分為三個層次:
基礎設施層。隨著系統越來越復雜,在系統中,有很多非常確定性的任務,比如虛擬化、網絡、存儲等,這些可以稱為基礎設施型任務。這類任務因為其確定性的特點,特別適合DSA/ASIC級別的加速處理器處理。
另一個極端,即不太好加速的應用部分。在硬件平臺上到底會運行什么樣的應用,通常是不可預知的,或者說應用是非常不確定的。因此,針對應用,最好是用CPU(+協處理器)平臺。CPU平臺還有另外一個價值,兜底,凡是無法加速或者不存在合適加速處理器的工作任務都可以放在CPU平臺處理。
處于兩個極端之間的部分任務,則通常是性能敏感的應用任務,比如AI訓練、視頻圖形處理、語音處理等。這類任務具有一定的確定性,但通常還是需要平臺的一些彈性的能力,其性能/靈活性特征處于前面兩個極端的中間。因此比較適合GPU、FPGA這樣的處理器平臺。
理論上,我們可以按照超異構計算的功能劃分和系統交互,把三類功能實現在CPU、GPU和DPU三芯片里,但目前三者處于相互競爭的狀態,三芯片協作的方式,本質上只能實現以CPU為中心的異構計算形態,而無法實現三者深度協同的超異構計算形態。 并且,三顆芯片,通常來自于不同的芯片公司,各個芯片都很難放棄以自己為核心的系統運行方式。要想這些芯片公司能夠更多的考慮和其他芯片的協同,從而實現三芯片的通力合作,很難很難。 基于CPU、GPU和DPU三芯片的超異構計算,還有很長的路要走。
4.3 在單芯片層次,實現相對簡單的超異構計算,是可行的路徑
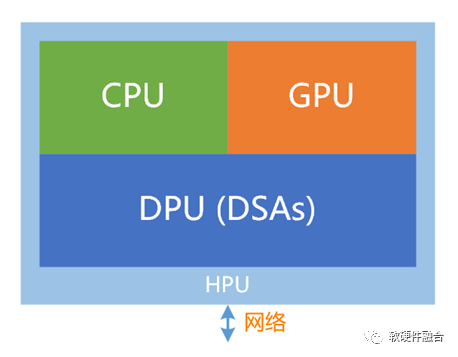
單芯片,不需要考慮和外部芯片的協同,只需要考慮內部不同單元間的深度交互。一切都在自己的掌控之下,因此單芯片超異構計算,是相對容易落地的實現方式。 此外,單芯片方式,也有其他的好處:
更高集成度,代表著更高的性能,以及更低的成本;
內部交互更高效,代表著沒有各類性能瓶頸約束,可以實現更高的性能。
05.超異構計算的挑戰,不在芯片集成,而在系統的融合和系統的可駕馭
5.1 硬件層次的多異構集成,不是難度
工藝持續進步、3D堆疊以及Chiplet多Die互聯,使得芯片從2D->3D->4D。這些技術的進步,意味著在芯片這個尺度,可以容納更多的晶體管,也意味著芯片的規模越來越大。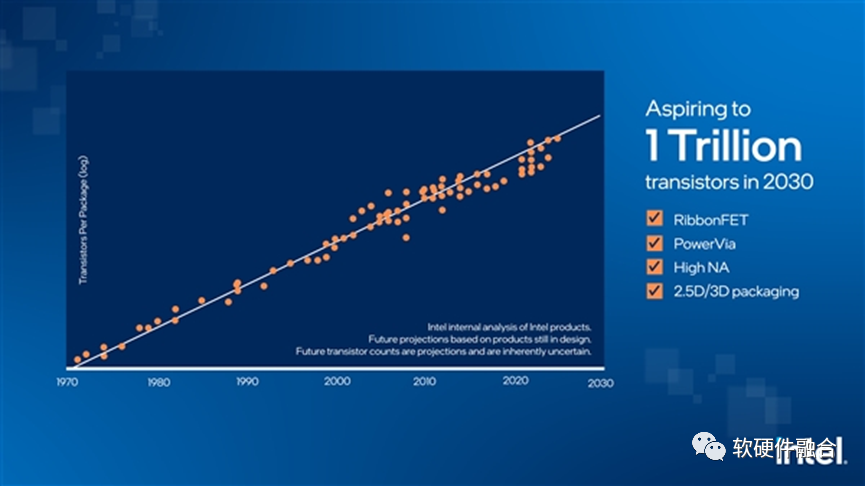
Intel宣布,在2030年,將實現單芯片層次集成1萬億晶體管,這意味著在單芯片層次,可以構建,相比目前,規模數量級提升的系統。 實現更多異構的集成,是芯片制造和封裝的核心競爭力,不是芯片設計公司(Fabless)的核心競爭力。
5.2 挑戰在于,軟件層次,如何把多個系統整合到一個宏系統
我們以NVIDIA 2000 TOPS的自動駕駛汽車中央控制器CCU為例。Thor能夠實現多域融合計算,它可以為自動駕駛和車載娛樂劃分任務。通常,這些各種類型的功能由分布在車輛各處的數十個控制單元控制。制造商可以利用Thor實現所有功能的融合,來整合整個車輛,而不是依賴這些分布式的ECU/DCU。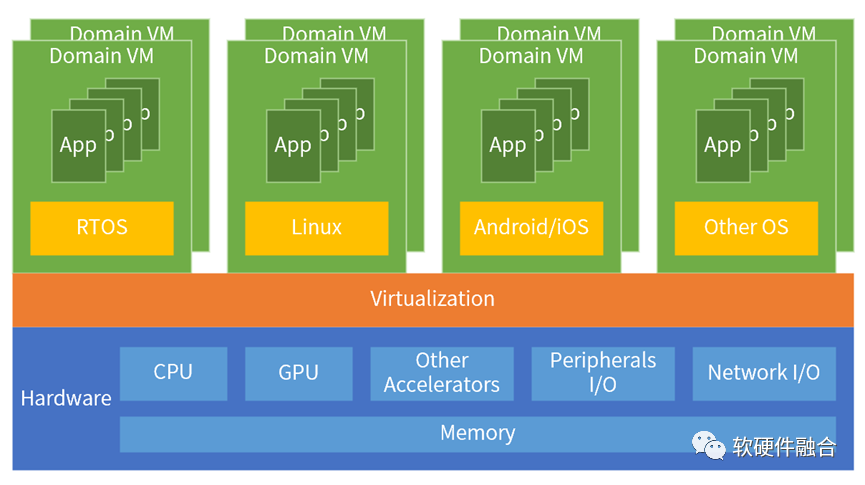
傳統SOC是單芯片單系統,而Thor實現了單芯片多個系統共存。在一個硬件上,把多個架構不同的系統整合成一個宏系統,則涉及到整個系統軟硬件架構的重構。 在系統和架構層面,如何實現更多系統的融合,是芯片設計公司的核心競爭力。
5.3 更大的挑戰在于,如何讓超異構更好駕馭
串行計算符合人類思維,編程相對最簡單;同構并行的編程,就要復雜很多;異構并行,則更是難上加難;那么超異構并行呢?那就是難上加難再加難。 要想駕馭超異構,核心的思路跟駕馭異構計算的思路一致,就是要想方設法降低軟硬件系統的復雜度。一些典型的降低復雜度的方法:
復雜大系統分解成簡單小系統,實現芯片內部的分布式計算,每個內部子節點的復雜度較低,更加可控一些。
依據系統的性能/靈活性特征進行分層。不同層次,采用不同的處理策略。
開放:讓處理器架構和生態收斂,防止碎片化。同時,行業內也能相互分工協作,而不是一家公司面對所有問題。
軟硬件深度融合,讓硬件具有更多軟件的能力。
06.第三代通用計算,大算力芯片“彎道超車”的歷史時機
CPU同構是第一代通用計算,成就了Intel的王者地位;GPU異構是第二代通用計算,隨著人工智能的火爆,助推NVIDIA市值超過了10000億美金,遠超Intel、AMD和高通的總和。 但技術發展不會停止。隨著AI大模型、自動駕駛、元宇宙等超高算力需求的領域快速發展,算力仍需持續快速提升,算力成本必須數量級下降,計算架構需要從同構、異構走向多種異構融合的超異構。
第一代和第二代通用計算CPU、GPU,我們已經落后,目前國內有眾多公司重擔在肩,在拼命追趕。而第三代通用計算(超異構計算)的發展機遇,給了我們“彎道超車”的歷史時機。 當前,Intel和NVIDIA正在通用超異構計算領域做早期布局,歷史機遇稍縱即逝。我們需要站在國家戰略的高度,快速布局,并大力投入。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19172瀏覽量
229188 -
電動車
+關注
關注
73文章
2996瀏覽量
113924 -
FPGA設計
+關注
關注
9文章
428瀏覽量
26489 -
加速器
+關注
關注
2文章
795瀏覽量
37772 -
DSA
+關注
關注
0文章
48瀏覽量
15124
原文標題:第三代通用計算,大算力芯片”彎道超車“的歷史時機
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
國產半導體新希望:Chiplet技術助力“彎道超車”!

論述RISC-C在IOT領域的發展機會
揭秘芯片算力:為何它如此關鍵?

邁信林與蘇州算力科技簽訂戰略框架協議,加碼開展算力領域業務
高算力芯片:未來科技的加速器?

iBeLink KS MAX 10.5T大算力領跑KAS新領域

弘信電子與AI算力服務器合資,助力國產算力芯片落地

大算力芯片里的HBM,你了解多少?





 工商網監
工商網監
評論