 BigCode背后的大規模數據去重方法有哪些?
BigCode背后的大規模數據去重方法有哪些?
目標受眾
本文面向對大規模文檔去重感興趣,且對散列 (hashing) 、圖 (graph) 及文本處理有一定了解的讀者。
動機
老話說得好: 垃圾進,垃圾出 (garbage in, garbage out),把數據處理干凈再輸入給模型至關重要,至少對大語言模型如此。雖然現在一些明星大模型 (嚴格來講,它們很多是 API) 的存在讓大家恍惚產生了數據質量好像不那么重要了的錯覺,但事實絕非如此。
在 BigScience 和 BigCode 項目中,在數據質量方面,我們面臨的一個很大的問題是數據重復,這不僅包括訓練集內的數據重復,還包括訓練集中包含測試基準中的數據從而造成了基準污染 (benchmark contamination)。已經有研究表明,當訓練集中存在較多重復數據時,模型傾向于逐字輸出訓練數據 [1] (這一現象在其他一些領域并不常見 [2]),而且訓得的模型也更容易遭受隱私攻擊 [1]。除了能避免上面兩個問題外,去重還有不少好處:
讓訓練更高效: 你可以用更少的訓練步驟獲得相同的,甚至是更好的性能 [3] [4]。
防止可能的數據泄漏和基準污染: 數據重復會損害你的模型性能報告的公信力,并可能讓所謂的改進淪為泡影。
提高數據可得性。我們大多數人都負擔不起重復下載或傳輸數千 GB 文本的成本,更不用說由此帶來的額外訓練成本了。對數據集進行去重,能使其更易于學習、傳輸及協作。
從 BigScience 到 BigCode
我想先分享一個故事,故事主要講述我如何接受數據去重這一任務,過程如何,以及在此過程中我學到了什么。
一切開始于 LinkedIn 上的一次對話,當時 BigScience 已經開始幾個月了。Huu Nguyen 注意到我在 GitHub 上的一個小項目并找到了我,問我是否有興趣為 BigScience 做數據去重工作。我當然愿意了,盡管當時我完全沒意識到由于數據量巨大,這項工作比想象中麻煩很多。
這項工作既有趣又充滿挑戰。挑戰在于,我對處理如此大規模的數據并沒有太多經驗。但項目組的每個人仍然歡迎我、信任我,還給了我數千美元的云計算預算。有多少回,我不得不從睡夢中醒來,反復確認我是否關閉了那些云實例。我不停地在試驗和錯誤中學習,在此過程中,新的視角被打開了。如果沒有 BigScience,可能我永遠不會有這種視角。
一年后的今天,我正在把從 BigScience 學到的東西應用到 BigCode 項目中去,去處理更大的數據集。除了英語 [3] LLM 之外,我們已經再次證明數據去重也能改進代碼模型 [4] 的性能。有了數據去重,我們可以用更小的數據集達到更優的性能。現在,親愛的讀者,我想與你分享我學到的知識,希望你能透過數據去重的鏡頭一瞥 BigCode 項目的幕后故事。
下表列出了 BigScience 項目中各數據集使用的去重方法,以供參考:
| 數據集 | 輸入數據量 | 輸出數據尺寸或數據精簡比 | 去重粒度 | 方法 | 參數 | 語種 | 耗時 |
|---|---|---|---|---|---|---|---|
| OpenWebText2[5] | 對 URL 去重后: 193.89 GB(69M) | 使用 MinHash LSH 后: 65.86 GB(17M) | URL + 文檔 | URL(精確匹配)+ 文檔(MinHash LSH) | 英語 | ||
| Pile-CC[5] | ~306 GB | 227.12 GiB(~55M) | 文檔 | 文檔(MinHash LSH) | 英語 | 數天 | |
| BNE5[6] | 2 TB | 570 GB | 文檔 | Onion | 5-元組 | 西班牙語 | |
| MassiveText[7] | 0.001 TB ~ 2.1 TB | 文檔 | 文檔(精確匹配 + MinHash LSH) | 英語 | |||
| CC100-XL[8] | 0.01 GiB ~ 3324.45 GiB | URL + 段落 | URL(精確匹配) + 段落(精確匹配) | SHA-1 | 多語種 | ||
| C4[3] | 806.92 GB (364M) | 3.04% ~ 7.18% ↓ (訓練集) | 子字符串或文檔 | 子字符串(后綴數組)或文檔(MinHash) | 后綴數組:50-詞元,MinHash: | 英語 | |
| Real News[3] | ~120 GiB | 13.63% ~ 19.4% ↓(訓練集) | 同 C4 | 同 C4 | 同 C4 | 英語 | |
| LM1B[3] | ~4.40 GiB(30M) | 0.76% ~ 4.86% ↓(訓練集) | 同 C4 | 同 C4 | 同 C4 | 英語 | |
| WIKI40B[3] | ~2.9M | 0.39% ~ 2.76% ↓(訓練集) | 同 C4 | 同 C4 | 同 C4 | 英語 | |
| BigScience ROOTS 語料集[9] | 0.07% ~ 2.7% ↓ (文檔) + 10.61% ~ 32.30% ↓ (子字符串) | 文檔 + 子字符串 | 文檔 (SimHash) + 子字符串 (后綴數組) | SimHash:6-元組,漢明距離(hamming distance)為 4,后綴數組:50-詞元 | 多語種 | 12 小時 ~ 數天 |
下表是我們在創建 BigCode 的訓練數據集 (訓練數據皆為代碼) 時所用的方法。這里,如果當遇到沒有名字的數據集時,我們就用模型名稱來代替。
| 模型 | 去重方法 | 參數 | 去重級別 |
|---|---|---|---|
| InCoder[10] | 精確匹配 | 代碼詞元/MD5 + 布隆濾波(Bloom filtering) | 文檔 |
| CodeGen[11] | 精確匹配 | SHA256 | 文檔 |
| AlphaCode[12] | 精確匹配 | 忽略空格 | 文檔 |
| PolyCode[13] | 精確匹配 | SHA256 | 文檔 |
| PaLM Coder[14] | Levenshtein 距離 | 文檔 | |
| CodeParrot[15] | MinHash + LSH | 文檔 | |
| The Stack[16] | MinHash + LSH | 文檔 |

例解 MinHash
在本節中,我們將詳細介紹在 BigCode 中使用的 MinHash 方法的每個步驟,并討論該方法的系統擴展性問題及其解決方案。我們以一個含有三個英文文檔為例來演示整個工作流程:
| doc_id | 內容 |
|---|---|
| 0 | Deduplication is so much fun! |
| 1 | Deduplication is so much fun and easy! |
| 2 | I wish spider dog[17] is a thing. |
MinHash 的典型工作流程如下:
詞袋生成 (生成 n- 元組) 及指紋生成 (生成 MinHash): 將每個文檔映射成一組哈希值。
局部敏感哈希 (LSH): 逐條帶 (band) 的比較文檔的相似性,并將相似的文檔聚類以減少后續比較的次數。
去重: 決定保留或刪除哪些重復文檔。
詞袋生成
與大多數文本應用一樣,我們需要先把文本表示成詞袋,這里我們通常使用 N- 元組詞袋。在本例中,我們使用以單詞為基本單元的 3- 元組 (即每 3 個連續單詞組成一個元組),且不考慮標點符號。我們后面會回過頭來討論元組大小對性能的影響。
| doc_id | 3-元組 |
|---|---|
| 0 | {"Deduplication is so", "is so much", "so much fun"} |
| 1 | {'so much fun', 'fun and easy', 'Deduplication is so', 'is so much'} |
| 2 | {'dog is a', 'is a thing', 'wish spider dog', 'spider dog is', 'I wish spider'} |
這個操作的時間復雜度為 ,其中 表示文檔數,而 表示文檔長度。也就是說,時間復雜度與數據集大小呈線性關系。我們可以用多進程或分布式計算來并行化詞袋生成過程。
指紋計算
使用 MinHash 方法時,每個 N- 元組需要生成多個哈希值,此時我們通常要么 1) 使用不同的哈希函數進行多次哈希,要么 2) 使用一個哈希函數進行哈希后再進行多次重排。本例中,我們選擇第二種方法,重排生成 5 個哈希值。更多 MinHash 的變體可以參考 MinHash - 維基百科。
| N-元組 | 哈希值 |
|---|---|
| Deduplication is so | [403996643, 2764117407, 3550129378, 3548765886, 2353686061] |
| is so much | [3594692244, 3595617149, 1564558780, 2888962350, 432993166] |
| so much fun | [1556191985, 840529008, 1008110251, 3095214118, 3194813501] |
對以上文檔哈希矩陣中的每一列取最小值 —— 即 “MinHash” 中的 “Min” 的題中之義,我們就能得到該文檔最終的 MinHash 值:
| doc_id | MinHash |
|---|---|
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] |
從技術上講,雖然我們通常取最小值,但這并不代表我們一定要取每列的最小值。其他順序統計量也是可以的,例如最大值、第 k 個最小值或第 k 個最大值 [21]。
在具體實現時,我們可以使用 numpy 來對這些操作進行向量化。該操作的時間復雜度為 ,其中 是排列數。以下列出了我們的代碼,它是基于 Datasketch 的實現修改而得的。
defembed_func( content:str, idx:int, *, num_perm:int, ngram_size:int, hashranges:List[Tuple[int,int]], permutations:np.ndarray, )->Dict[str,Any]: a,b=permutations masks:np.ndarray=np.full(shape=num_perm,dtype=np.uint64,fill_value=MAX_HASH) tokens:Set[str]={"".join(t)fortinngrams(NON_ALPHA.split(content),ngram_size)} hashvalues:np.ndarray=np.array([sha1_hash(token.encode("utf-8"))fortokenintokens],dtype=np.uint64) permuted_hashvalues=np.bitwise_and( ((hashvalues*np.tile(a,(len(hashvalues),1)).T).T+b)%MERSENNE_PRIME,MAX_HASH ) hashvalues=np.vstack([permuted_hashvalues,masks]).min(axis=0) Hs=[bytes(hashvalues[start:end].byteswap().data)forstart,endinhashranges] return{"__signatures__":Hs,"__id__":idx}
熟悉 Datasketch 的讀者可能會問,為什么我們要費心費力剝離 Datasketch 庫提供的所有高級功能?其主要原因并不是因為我們要減少依賴項,而是因為我們想要盡可能地榨取 CPU 的算力。而將多個步驟融合到一個函數中,是更好利用計算資源的手段之一。
由于每個文檔的計算互相獨立,因此我們可以充分利用 datasets 庫的 map 函數來實現并行化:
embedded=ds.map(
function=embed_func,
fn_kwargs={
"num_perm":args.num_perm,
"hashranges":HASH_RANGES,
"ngram_size":args.ngram,
"permutations":PERMUTATIONS,
},
input_columns=[args.column],
remove_columns=ds.column_names,
num_proc=os.cpu_count(),
with_indices=True,
desc="Fingerprinting...",
)
指紋計算完畢之后,每個文檔都被映射成了一個整數數組。為了弄清楚哪些文檔彼此相似,我們需要根據這些指紋對它們進行聚類。輪到 局部敏感哈希 (Locality Sensitive Hashing,LSH) 閃亮登場了。
局部敏感哈希 (LSH)
LSH 將指紋數組按行分成若干個條帶 (band),每個條帶的行數相同,如果遇到最后一個條帶行數不足,我們就直接忽略它。以條帶數 為例,每個條帶有 行,具體組織如下:
| doc_id | MinHash | 條帶 |
|---|---|---|
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 2888962350]] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 1998729813]] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] | [0:[166417565, 213933364], 1:[1129612544, 1419614622]] |
若兩個文檔在某條帶上 MinHash 值相同,這兩個文檔就會被聚到同一個桶中備選。
| 條帶 ID | 條帶值 | doc_ids |
|---|---|---|
| 0 | [403996643, 840529008] | 0, 1 |
| 1 | [1008110251, 2888962350] | 0 |
| 1 | [1008110251, 1998729813] | 1 |
| 0 | [166417565, 213933364] | 2 |
| 1 | [1129612544, 1419614622] | 2 |
遍歷 doc_ids 列的每一行,將其中的文檔兩兩配對就生成了候選對。上表中,我們能生成一個候選對: (0, 1) 。
候選對生成后 ……
很多數據去重的論文或教程講完上一節就結束了,但在實際項目中我們還涉及如何處理這些候選對的問題。通常,候選對生成后,我們有兩個選擇:
由于 MinHash 只是一個近似,所以仍需計算兩個文檔的 N- 元組集合的交并比來算得準確的 Jaccard 相似性。此時,因為 LSH 已經幫我們過濾了不少,所以最終參與計算的候選對的量會大大減少。在 BigCode 項目中,我們起初就采用了這種做法,效果相當不錯。
我們還可以直接認可 LSH 選出來的相似對。這里面可能會有個問題: Jaccard 相似性不具傳遞性,也就是說 相似于 且 相似于 ,并不意味著 相似于 。所以這里可能會有不少假陽性。通過在 The Stack 數據集上的實驗,我們發現,直接認可 LSH 選出來的相似對在很大程度上能提高下游模型的性能,同時還節省了處理時間和訓練時間。因此目前我們正慢慢開始轉向這種方法。但是,這個經驗并不是放之四海而皆準的,如果你準備在自己的數據集上仿效我們的做法,我們建議你在此之前好好檢查你的數據集及其特點,然后作出數據驅動的決策。
最后,我們可以用生成的相似文本對構建一個圖,在這個圖中,重復的文檔會被聚至同一個社區或同一個連通子圖中。不幸的是, datasets 在這方面幫不上什么忙,因為現在我們需要類似 groupby 的功能,以根據 條帶 ID 及 文檔在該條帶上的取值 對文檔進行聚類。下面列出了我們嘗試過的一些方案:
方案 1: 老辦法,迭代數據集以創建圖,然后用一個圖處理庫對其做社區檢測或者連通分量檢測。
我們測試下來,該方案的擴展性不怎么好,其原因是多方面的: 首先,整個數據集迭代起來很慢,而且內存消耗很大; 其次,諸如 graphtool 或 networkx 的市面上流行的圖處理庫創建圖的開銷較大。
方案 2: 使用流行的 Python 框架 (如 dask ) 及其高效的 groupby 操作。
但迭代慢和創建圖慢的問題仍然存在。
方案 3: 迭代數據集并使用并查集 (union find data structure) 對文檔進行聚類。
這個方案引入了一個很小的迭代開銷,對中等數據集的有不錯的效果不錯,但在大數據集上還是慢。
fortableintqdm(HASH_TABLES,dynamic_ncols=True,desc="Clustering..."): forclusterintable.values(): iflen(cluster)<=?1: ???continue ??idx?=?min(cluster) ??for?x?in?cluster: ???uf.union(x,?idx)
方案 4: 對大數據集,使用 Spark。
我們已經知道到 LSH 的有些步驟是可以并行化的,我們可以用 Spark 來實現它們。Spark 的好處是,它開箱即支持分布式 groupBy ,而且也能很輕松地實現像 [18] 這樣的連通分量檢測算法。注意,這里我們并沒有使用 Spark 的原生 MinHash 實現,其原因是迄今為止我們所有的實驗都源于 Datasketch,而 Datasketch 的 MinHash 實現與 Spark 的原生實現完全不同。我們希望之前的經驗和教訓能幫助到后面的工作,而不是另起爐灶,進入另一個消融實驗的輪回,因此我們選擇在 Spark 中自己實現 Datasketch 的 MinHash 算法。
edges=( records.flatMap( lambdax:generate_hash_values( content=x[1], idx=x[0], num_perm=args.num_perm, ngram_size=args.ngram_size, hashranges=HASH_RANGES, permutations=PERMUTATIONS, ) ) .groupBy(lambdax:(x[0],x[1])) .flatMap(lambdax:generate_edges([i[2]foriinx[1]])) .distinct() .cache() )
以下是基于 [18] 的簡單連通分量檢測算法的 Spark 實現。
a=edges whileTrue: b=a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache() a=b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache() changes=a.subtract(b).union(b.subtract(a)).collect() iflen(changes)==0: break results=a.collect()
多虧了云計算提供商,我們可以使用 GCP DataProc 等服務輕松地搭建 一個 Spark 集群。最終,我們把程序運行起來,只用了不到 4 小時就完成了 1.4 TB 數據的去重工作,每小時僅需 15 美元。
數據質量很重要
我們不可能爬著梯子登上月球。因此我們不僅要確保方向正確,還要確保方法正確。
早期,我們使用的參數主要來自 CodeParrot 的實驗,消融實驗表明這些參數確實提高了模型的下游性能 [16]。后來,我們開始沿著這條路進一步探索,由此進一步確認了以下結論 [4]:
數據去重可以在縮小數據集 (6 TB VS. 3 TB) 規模的同時提高模型的下游性能
雖然我們還沒有完全搞清楚其能力邊界及限制條件,但我們確實發現更激進的數據去重 (6 TB VS. 2.4 TB) 可以進一步提高性能,方法有:
降低相似度閾值
使用更長的元組 (如: 一元組 → 五元組)
放棄誤報檢查,承受一小部分誤報帶來的數據損失
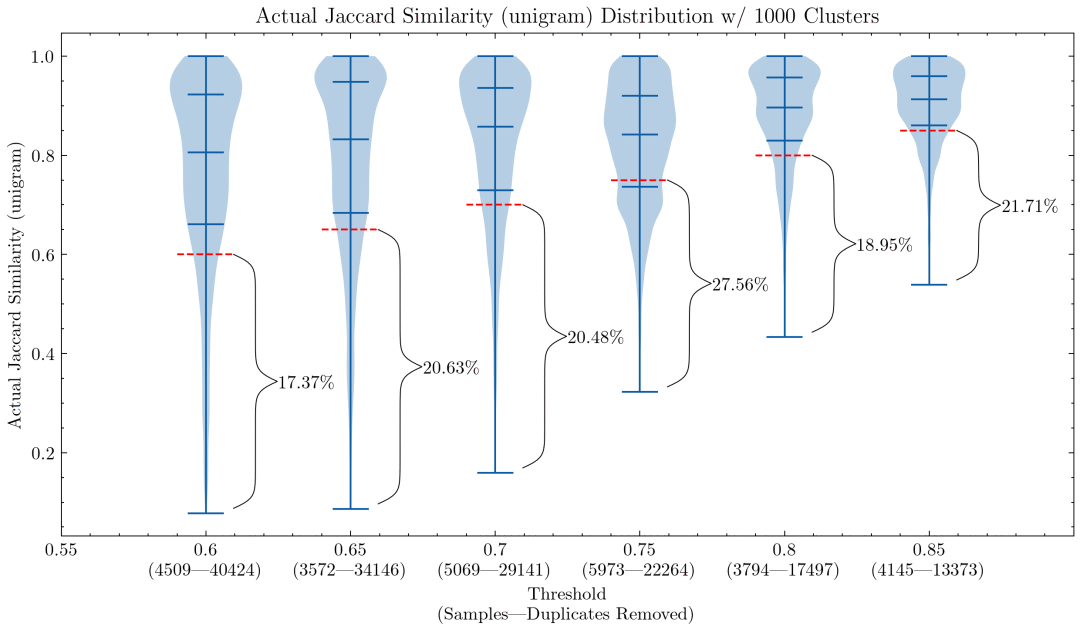
1- 元組時不同設置影響的小提琴圖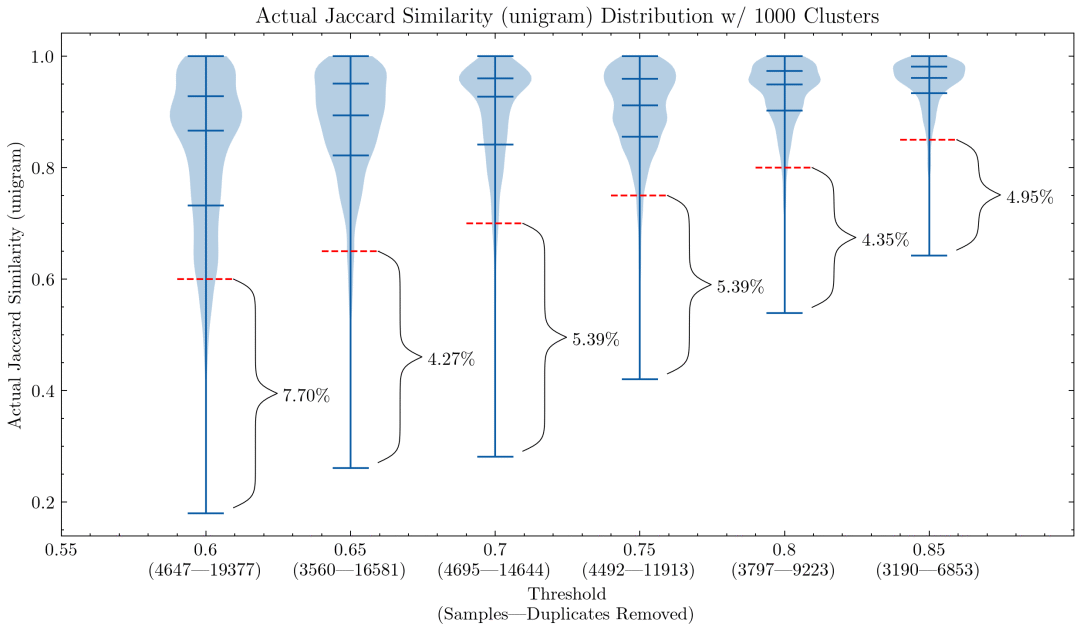
5- 元組時不同設置影響的小提琴圖 圖例: 上述兩幅圖展示了相似性閾值和元組大小帶來的影響,第一幅圖使用 1- 元組,第二幅圖使用 5- 元組。紅色虛線表示相似性閾值: 低于該值的文檔與同一簇中其他文檔的相似性低于閾值,我們將其視為誤報。
上面兩幅圖可以幫助我們理解為什么有必要仔細檢查 CodeParrot 以及早期版本的 The Stack 訓練數據上的誤報: 這是使用 1- 元組的誤報比例會很大; 上圖還表明,將元組大小增加到 5,誤報比例會顯著降低。如果想激進點去重的話,閾值可以設低點。
還有實驗表明,降低閾值會刪除更多包含部分相似內容的文檔,因此意味著提高了我們最想刪除的那部分文檔的查全率。
系統擴展性
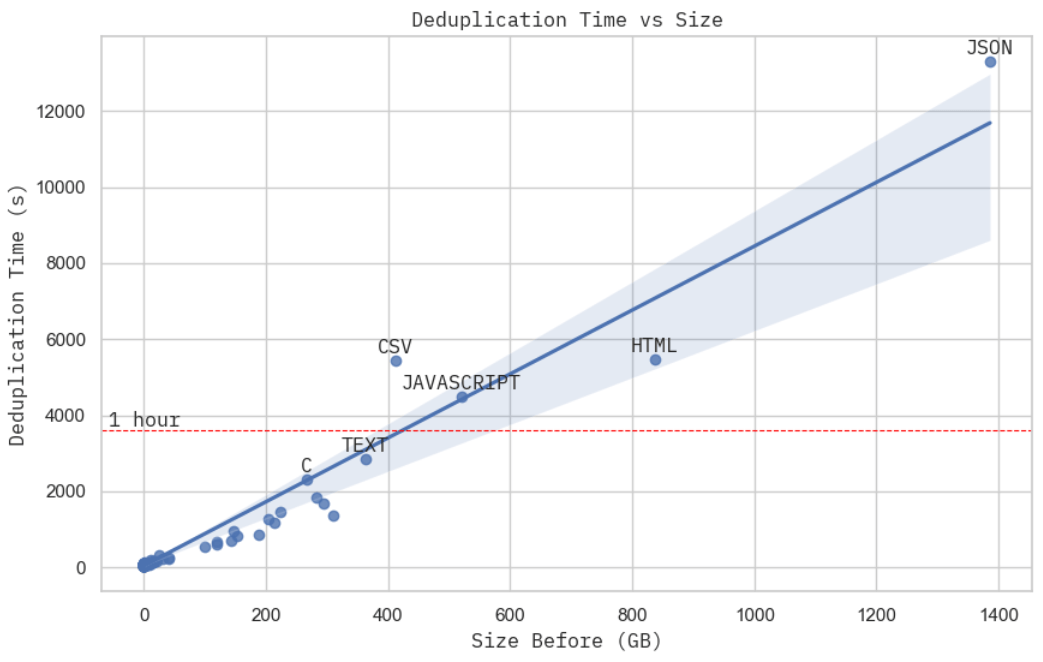
Scaling results for dataset size and deduplication time 圖例: 數據去重時間與原始數據集規模的關系。測試基于 GCP 上的 15 個 c2d-standard-16 實例,每個實例每小時的成本約為 0.7 美元。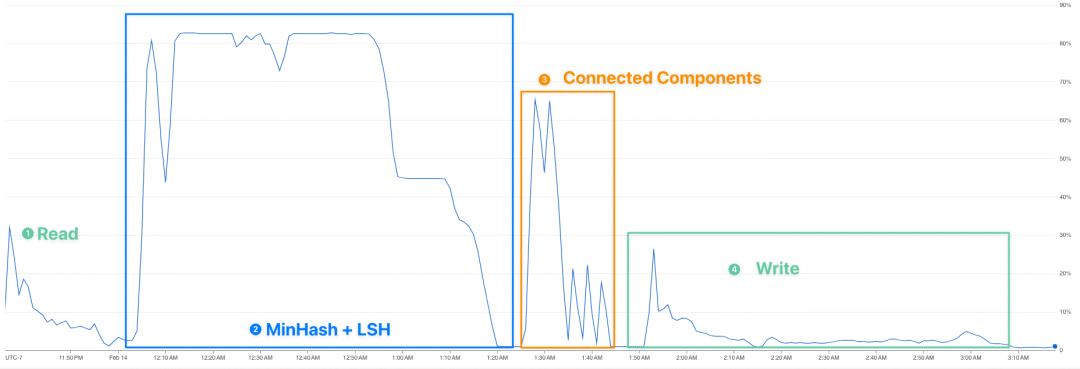
CPU usage screenshot for the cluster during processing JSON dataset 圖例: 集群在處理 JSON 數據集時的 CPU 使用率。
上述擴展性數據未必非常嚴格,但也足夠說明,在給定預算的情況下,數據去重耗時與數據集規模的關系應該是線性的。如果你仔細看一下處理 JSON 數據集 (The Stack 數據集的最大子集) 的集群資源使用情況,你會發現實際總計算時間 (圖中第 2 和第 3 階段) 主要都花在了 MinHash + LSH (圖中第 2 階段) 上,這與我們先前的分析一致,即第 2 階段 d 的時間復雜度為 — 與數據體量成線性關系。
謹慎行事
數據去完重并不意味著萬事大吉了,你仍然需要對數據進行徹底的探索和分析。此外,上文這些有關數據去重的發現來自于 The Stack 數據集,并不意味著它能無腦適用于其他數據集或語言。要構建一個好的訓練數據集,我們僅僅邁出了萬里長征的第一步,后面還有很多工作要做,例如數據質量過濾 (如過濾漏洞數據、毒性數據、偏見數據、模板生成的數據、個人身份數據等)。
我們還鼓勵你在訓練前像我們一樣對數據集進行徹底的分析,因為大家的情況可能各不相同。例如,如果你的時間和計算預算都很緊張,那么數據去重可能不是很有幫助: @geiping_2022 提到基于子字符串的數據去重并沒有提高他們模型的下游性能。在使用前,可能還需要對現存數據集進行徹底檢查,例如,@gao_2020 聲明他們只確保 Pile 本身及其子集都已去重,但不保證其與任何下游基準數據集沒有重復,要不要對 Pile 與下游基準數據集進行去重取決于使用者自己。
在數據泄露和基準污染方面,還有很多需要探索的地方。由于 HumanEval 也是 GitHub Python 存儲庫之一,我們不得不重新訓練了我們的代碼模型。早期的工作還發現,最流行的編碼基準之一的 MBPP[19] 與許多 Leetcode 問題有很多相似之處 (例如,MBPP 中的任務 601 基本上是 Leetcode 646,任務 604 ? Leetcode 151)。我們都知道 GitHub 中不乏很多編程挑戰賽題及其答案代碼。如果居心叵測的人把所有基準測試的 Python 代碼以不易察覺的方式上傳到 Github,污染你所有的訓練數據,這事兒就更難了。
后續方向
子串去重。盡管在英語 [3] 上子串去重是有益的,但尚不清楚是否對代碼數據也有用;
重復段落: 在一篇文檔中重復多次的段落。@rae_2021 分享了一些關于如何檢測和刪除它們的有趣的啟發式方法。
使用模型嵌入進行語義級的去重。這是另外一套思路了,需要一整套去重、擴展性、成本、銷蝕等各方面的實驗和權衡。對此 [20] 提出了一些有趣的看法,但我們仍然需要更多實際證據才能得出結論 (其文本去重工作僅參考了 @lee_2022a 的工作,而 @lee_2022a 的主張主要是去重有作用而并未證明其效果達到了 SOTA)。
優化。還有不少優化空間: 更好的質量評估標準、擴展性、對下游性能影響的分析等。
換個角度: 對相似數據,去重到什么程度就會開始損害性能?需要保留多少相似數據以保留數據的多樣性又不至冗余?
審核編輯:劉清
-
存儲器
+關注
關注
38文章
7452瀏覽量
163605 -
URL
+關注
關注
0文章
139瀏覽量
15312 -
python
+關注
關注
56文章
4782瀏覽量
84453 -
Hash算法
+關注
關注
0文章
43瀏覽量
7379 -
LLM
+關注
關注
0文章
273瀏覽量
306
原文標題:BigCode背后的大規模數據去重
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大規模特征構建實踐總結
大規模MIMO的利弊
大規模MIMO的性能
RFSoC數位射頻在大規模MIMO無線電系統有什么應用?
一個benchmark實現大規模數據集上的OOD檢測
用于大規模數據集的決策樹采樣策略
如何降低超大規模數據中心IT硬件能耗和成本
基于DFP優化的大規模數據點擬合方法

超大規模數據中心要回到ASIC歲月么?
超大規模數據中心的優勢和面臨的挑戰






 工商網監
工商網監
評論