 大模型時代的程序員:不會用AIGC編程,未來5年將被淘汰?
大模型時代的程序員:不會用AIGC編程,未來5年將被淘汰?
前言
下面是一段利用 Co-Pilot 輔助開發的小視頻,這是 Apache SeaTunnel 開發者日常開發流程中的一小部分。如果你還沒有用過 Co-Pilot、ChatGPT 或者私有化大模型幫助你輔助開發的話,未來的 5 年,你可能很快就要被行業所淘汰。因為這些善于使用 AIGC 輔助編程的人可以 10 倍于你的速度開發相應的代碼,而你沒有這個技能。我并不是危言聳聽,讀完此文,我相信你對 AIGC 研發提升研發效率會有全新的認知。
2大模型顛覆傳統初級程序員的培訓和輔導過程,讓技術和經驗“平權”
過去,初級程序員入職學習編程時,往往是師傅給一個任務需求,教大體的思路,然后在初級程序員寫出代碼工作當中培訓和糾正,針對不同的命題告訴不同的方案,直到初級程序員把這些經驗學會。
但大模型的到來把這個過程完全改變了。大模型自己具有廣泛的知識,而且有一些基礎的推理能力,它可以經歷無數次的實踐,學習公司里各種各樣的代碼和業務定義,它所遇到的場景要比師傅當年要遇到的場景多得多,同時它會根據開發者的需求和目標給出可能的答案。
這個過程就像我們多了一個無所不能的“師傅”,隨叫隨到還可以給你直接寫出可能的代碼,讓你參考學習,讓一個初級的程序員快速具有“師傅”寫代碼的能力。經過自己的學習和調整,就可以提交出一個遠超你自己個人水平的代碼,讓別人 Review。
那么,我們有什么理由不使用大模型來提高自己的研發效率呢?
3如何使用大模型輔助編程?
目前常見的工具有 ChatGPT、Co-Pilot、私有化大模型等等,在不同場景下要用不同的方法來編寫程序:
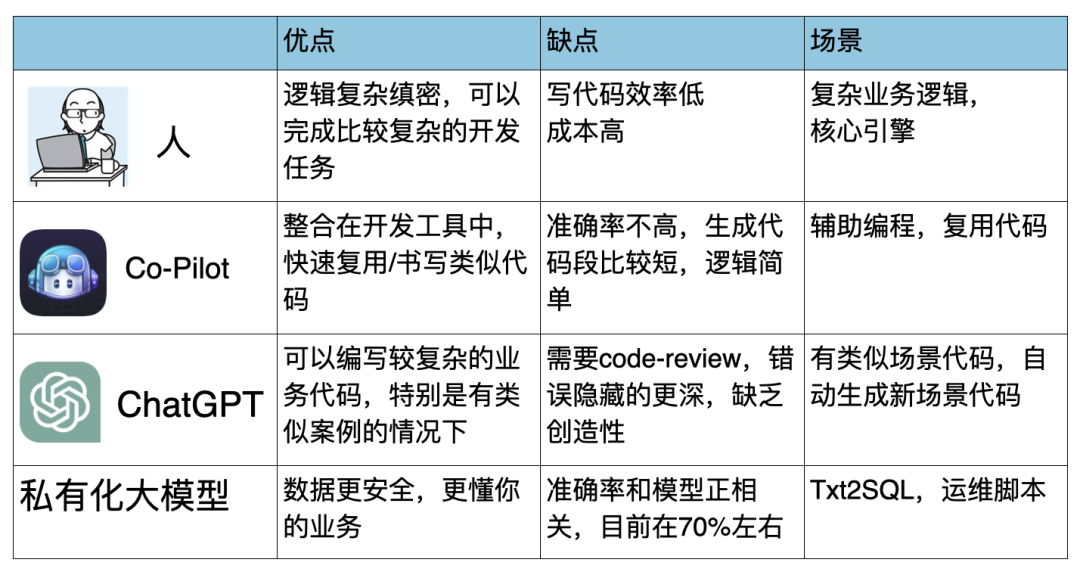
可以看到,人類其實最適合就是做比較有挑戰和創新的架構類產品,或者是某個新業務場景的代碼,如果中間有復用的部分或者類似的算法,可以使用 Co-Pilot 快速提升效率;ChatGPT 可以用于類似場景的代碼來自動生成,稍微修改就可以使用;私有化大模型更適合對數據和代碼安全有要求,而又需要大模型比較了解你的業務知識的場景,私有化大模型是需要 FineTune 的。
可能有人會說,私有化大模型普通公司玩不起的!其實這是一個誤解,如果你要原生訓練一個原生私有化大模型,估計中國能玩得起的公司不超過 5 個,而大多數公司不需要訓練大模型,只需要根據開源大模型優化(Finetune)大模型就可以讓大模型理解自己的業務了,而這個代價就是 1-2 張 3090/4090 的顯卡就可以了,整個的實行過程可能也只需要 2~3 個小時的配置就可以(感興趣的話可以參考下面這篇文章:《用一杯星巴克的錢,訓練自己私有化的 ChatGPT》,里面講的利用是 Apache DolphinScheduler 和配置好的模板,拖拽就可以訓練一個大模型的例子)。
使用私有化大模型可以直接實現以下功能:
軟件眾多功能中,直接找到你所需要的功能;
眾多復雜的使用手冊和規則,找到你所需要的功能和說明;
輔助編程,Txt2SQL,提高數據程序員的效率。
使用私有化大模型來輔助編程,真的距離我們一點都不遙遠。如果你還不太相信 AIGC 自動化編程時代已經來臨了,那么下面這個開源項目如何利用 AIGC 提高研發效率的例子,或許可以幫助你更好理解。
4大模型自動化編程實例:Apache SeaTunel
Apache SeaTunnel 愿景是“連接萬源,同步如飛”,也就是可以連接市面上所有的數據源(包括數據庫、SaaS、中間件、BinLog),而且同步效率要做的最高。這對于任何一家公司都是不可能做到的事情,而面對幾千上萬的 SaaS 軟件和不斷變化的接口,甚至人類也無法做到這一點,那么 Apache SeaTunnel 核心項目團隊是怎么在這個 AI 時代設計這樣一款開源軟件呢?總體如下圖所示:
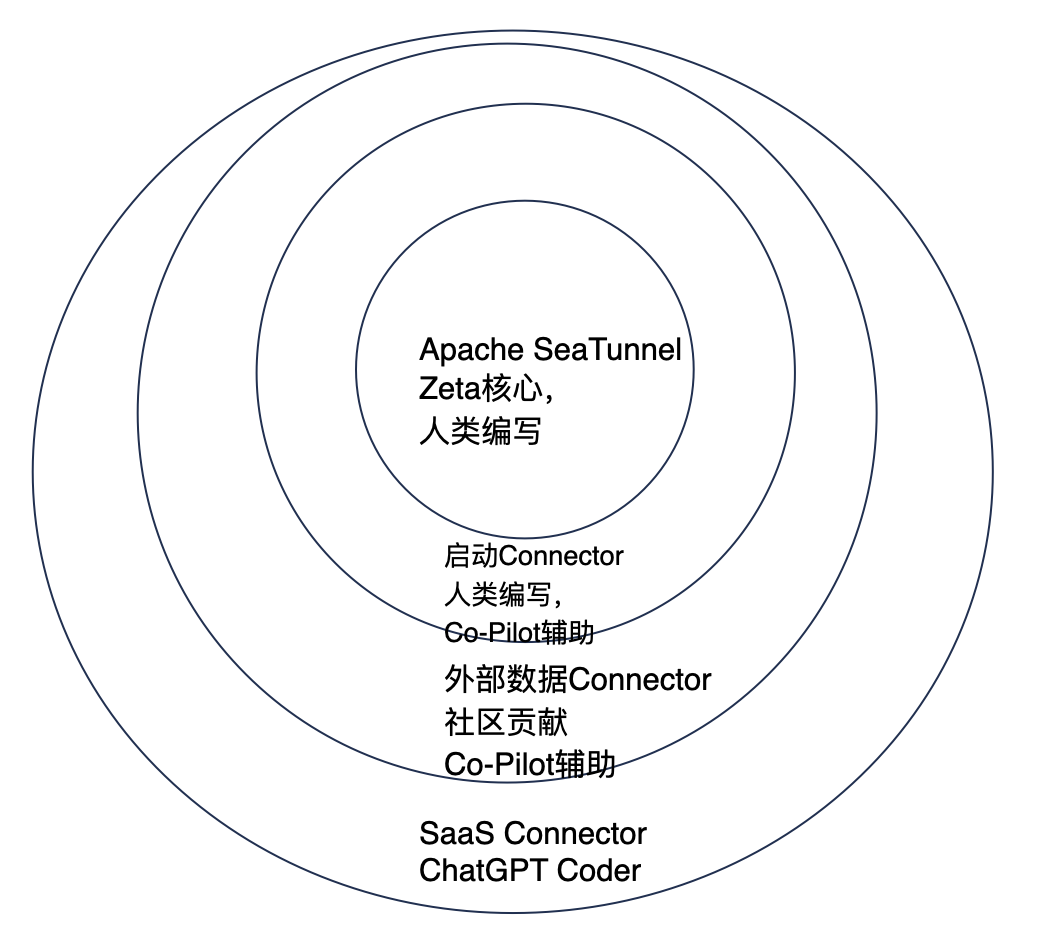
首先,計算核心引擎部分,屬于專門為同步而生的計算引擎,它不同于 Flink、Spark,主要在同步復用內存、CPU、帶寬和確保數據一致性上下功夫,所以大部分代碼都沒有可借鑒的,需要核心開發工程師直接編寫、修正,以確保“同步如飛 ”。當然,因為是開源項目,核心引擎部分得到了眾多大廠專家的修正和討論,以確保時刻跟進全球最先進的技術。
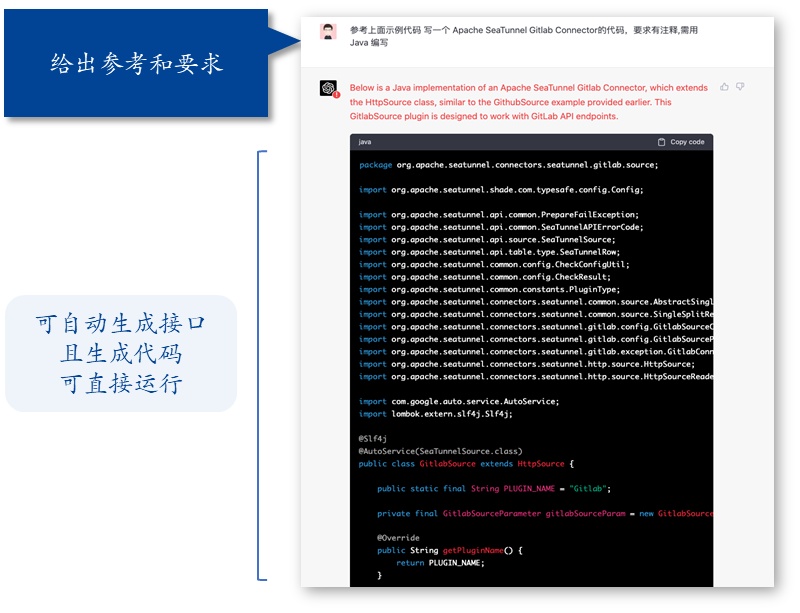
其次,數據庫的核心 Connector,例如 Iceberg Connector,這些接口實現比較復雜,除了保證代碼正確之外還要保證數據傳輸效率很高,這時候直接使用大模型是無法達到我們所需要的效果的。因此主力還是人,但可以復用自己和云端過去常用的代碼來做,這時候使用 Co-Pilot 就是最佳方案,主導者是人,而大模型可以作為輔助來幫你補充常規算法和復用的代碼,如開頭視頻所示的樣子。
面對浩如煙海的 SaaS 接口,例如 MarTech 領域的 SaaS 就超過 5000 個,靠人力對接接口是不可能的。SeaTunnel 核心團隊就想了一個辦法,根據多次嘗試,把過去為人寫的十幾個接口進行抽象,不斷和 ChatGPT 磨合,最終變成 2 個可以讓 ChatGPT 理解并寫出優雅代碼的接口,然后利用 ChatGPT 可以讀懂 SaaS 接口文檔的特點,直接生成相關代碼。這在 SeaTunnel 當中叫“AI Compatible”特性,兼容 AI。我理解這更是程序員和 AI 的一種“和解”,大家不要相互搶飯碗,程序員為 AI 做好準備,AI 來做程序員無法做到的事情。
這個特性在 Apache SeaTunnel 2.3.1 里面已經發布了,當然作為眾創的開源軟件,該功能還有各種各樣的缺陷有待提升。不過因為代碼是完全開源的,我相信會有越來越多的愛好者把它打磨到更加自動化。比如,我已經聽到有一個開發者要做一個 GPT Coder,監控 GitHub 上的 SaaS issue,自動化調用 ChatGPT,生成代碼并提交 PR,讓機器人和人類卷到極致。
5大模型自動化編程存在的問題
雖然 ChatGPT、Co-Pilot 可以輔助編程,但它們也不是無敵的,目前大模型生成代碼還有很多挑戰:
準確率問題;
無法做 code review;
無法實現自動化測試;
無法擔責。
大模型依然會出錯,這在未來一段時間是常態,哪怕是 ChatGPT4,寫出來的代碼也就 90% 的正確率,所以要盡量簡化它寫代碼的過程,否則可能會寫出來完全不對的代碼。大模型快速生成代碼之后,人類的 code review 會跟不上,因為機器是無法確定最終代碼實現業務邏輯是不是對的;而大模型做 code review 的話,你會發現每次都給你煞有其事地提出來不同的改進點,但其實都是無關痛癢部分,無法確定最終的邏輯正確性。
同時,自動化測試案例和自動化測試也是當前大模型一個弱點,TestPilot 屬于在學術圈比較活躍的內容,大家可以參考 Cornell 的《Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction》和《Adaptive Test Generation Using a Large Language Model》都是一些比較有意思的文章,不過距離工程化使用都還有一定距離。
當然,自動化編程還有最后也是最難得一關——責任問題,就像自動化駕駛一樣,哪怕是做到 L5,如果出問題到底是誰的責任。就像 WhaleOps 實現了 Txt2SQL 之后,很多用戶問,為什么不直接把 SQL 執行出來變成最終的結果給我,這才是業務部門最終需要的東西。
我認為這是一個哲學問題,而不是一個技術問題了。不說現在 ChatGPT 90% 的準確率,假設將來大模型可以做到 99.9999%,你敢直接問一句話讓它自動計算全公司的工資然后自動對接銀行發工資么?如果出問題,你覺得是誰的問題呢?永遠不能幻想用技術解決所有的業務問題,大模型也是如此。
6未來展望
現在我們還處于大模型自動化編程的初期,很多小伙伴還在處于試用 Co-Pilot 和 ChatGPT 階段,大多數程序員還沒有用上私有化大模型來根據自己公司的業務提升編程效率,不過我認為未來的 3-5 年,自動化輔助編程一定會成為我們這一屆開發者的標配工具:
國產基礎大模型拉進 ChatGPT 距離,易用性提高;
開源大模型準確性、性能提升,更多的公司使用私有化大模型 ROI 提升;
大模型自動化門檻減低,除了 DolphinScheduler,更多的大模型訓練平民化工具誕生;
技術管理者對于大模型自動化編程認知提升,技術管理流程適配大模型時代;
在當前經濟周期下,降本提效利用大模型提高效率勢在必行。
所以,未來幾年,如果你在研發過程還是只會 CRUD,不會有效利用大模型將自己的經驗和業務理解 X10 或者 X100 的話,那么不用等到 35 歲,你就會被會大模型編程的那批程序員所取代,他們 X10 之后,你就是那被淘汰的 9 個人。
當然,雖然有點危言聳聽,但是編程提效當中的大模型趨勢是勢不可擋的,我也只是在大模型自動化編程這方面不斷實踐摸索的小學生,我相信會有很多的技術管理者和架構師加入到大模型自動化編程的浪潮中來,不斷迭代和優化在開發領域當中人和大模型之間的關系。最終,讓程序員、AI、技術研發流程更有效的為業務服務。
-
ChatGPT
+關注
關注
29文章
1548瀏覽量
7495 -
AIGC
+關注
關注
1文章
356瀏覽量
1508 -
大模型
+關注
關注
2文章
2328瀏覽量
2485
原文標題:大模型時代的程序員:不會用AIGC編程,未來5年將被淘汰?
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
“程序員將消失”,李彥宏/黃仁勛都贊同,三大方向可“自救”

AI編程工具會不會搶程序員飯碗
第五屆長沙·中國1024程序員節開幕
程序員節視頻創意大賽,用串口屏贏取千元大獎

程序員節視頻創意盛宴,邀您共襄盛舉!

大模型時代,程序員當下如何應對 AI 的挑戰

不會用AI的人被淘汰?訊飛AI鼠標AM30助你迎接AI時代

薪資高、青春飯,是不是程序員=青樓?

1月18號“純鴻蒙”千帆啟航,程序員預備!
“GPT 驅動的新程序員時代 ,我們該如何編程”分論壇圓滿舉辦






 工商網監
工商網監
評論