 用語言建模世界:UC伯克利多模態世界模型利用語言預測未來
用語言建模世界:UC伯克利多模態世界模型利用語言預測未來
當前,人與智能體(比如機器人)的交互是非常直接的,你告訴它「拿一塊藍色的積木」,它就會幫你拿過來。但現實世界的很多信息并非那么直接,比如「扳手可以用來擰緊螺母」、「我們的牛奶喝完了」。這些信息不能直接拿來當成指令,但卻蘊含著豐富的世界信息。智能體很難了解這些語言在世界上的含義。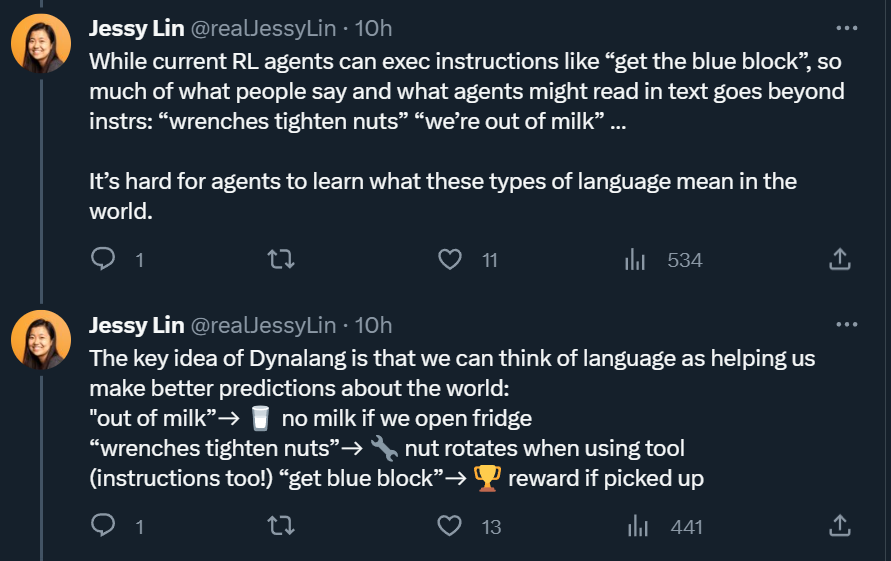 基于此,他們提出了 Dynalang,一種從在線經驗中學習語言和圖像世界模型,并利用該模型學習如何行動的智能體。
Dynalang 將學習用語言對世界建模(帶有預測目標的監督學習)與學習根據該模型采取行動(帶有任務獎勵的強化學習)分離開來。該世界模型接收視覺和文本輸入作為觀察模態,并將它們壓縮到潛在空間。研究者通過在線收集的經驗訓練世界模型,使其能夠預測未來的潛在表示,同時智能體在環境中執行任務。他們通過將世界模型的潛在表示作為輸入,訓練策略來采取最大化任務獎勵的行動。由于世界建模與行動分離,Dynalang 可以在沒有行動或任務獎勵的單模態數據(僅文本或僅視頻數據)上進行預訓練。
此外,他們的框架還可以統一語言生成:智能體的感知可以影響智能體的語言模型(即其對未來 token 的預測),使其能夠通過在動作空間輸出語言來描述環境。
基于此,他們提出了 Dynalang,一種從在線經驗中學習語言和圖像世界模型,并利用該模型學習如何行動的智能體。
Dynalang 將學習用語言對世界建模(帶有預測目標的監督學習)與學習根據該模型采取行動(帶有任務獎勵的強化學習)分離開來。該世界模型接收視覺和文本輸入作為觀察模態,并將它們壓縮到潛在空間。研究者通過在線收集的經驗訓練世界模型,使其能夠預測未來的潛在表示,同時智能體在環境中執行任務。他們通過將世界模型的潛在表示作為輸入,訓練策略來采取最大化任務獎勵的行動。由于世界建模與行動分離,Dynalang 可以在沒有行動或任務獎勵的單模態數據(僅文本或僅視頻數據)上進行預訓練。
此外,他們的框架還可以統一語言生成:智能體的感知可以影響智能體的語言模型(即其對未來 token 的預測),使其能夠通過在動作空間輸出語言來描述環境。
 ?論文鏈接:https://arxiv.org/pdf/2308.01399.pdf項目主頁:https://dynalang.github.io/代碼鏈接:https://github.com/jlin816/dynalang
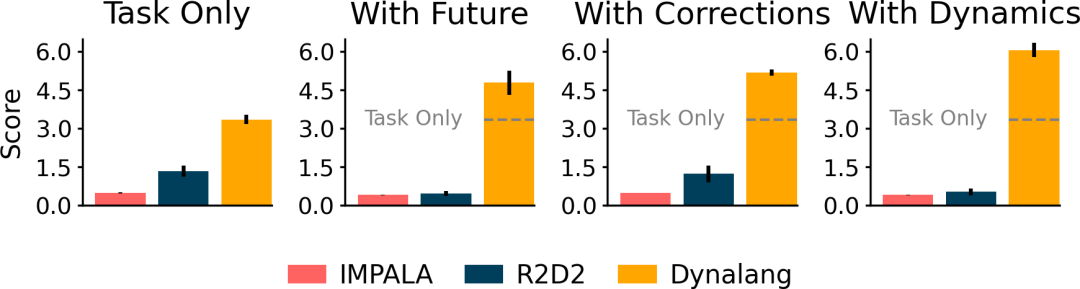
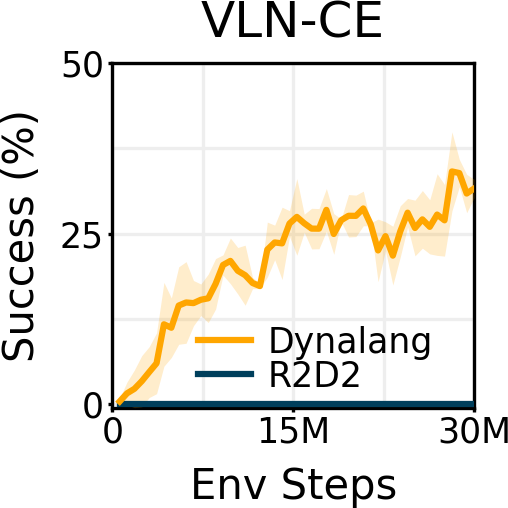
研究者在具有不同類型語言上下文的多樣化環境中對 Dynalang 進行了評估。在一個多任務家庭清潔環境中,Dynalang 學會利用關于未來觀察、環境動態和修正的語言提示,更高效地完成任務。在 Messenger 基準測試中,Dynalang 可以閱讀游戲手冊來應對最具挑戰性的游戲階段,優于特定任務的架構。在視覺 - 語言導航中,研究者證明 Dynalang 可以學會在視覺和語言復雜的環境中遵循指令。
?論文鏈接:https://arxiv.org/pdf/2308.01399.pdf項目主頁:https://dynalang.github.io/代碼鏈接:https://github.com/jlin816/dynalang
研究者在具有不同類型語言上下文的多樣化環境中對 Dynalang 進行了評估。在一個多任務家庭清潔環境中,Dynalang 學會利用關于未來觀察、環境動態和修正的語言提示,更高效地完成任務。在 Messenger 基準測試中,Dynalang 可以閱讀游戲手冊來應對最具挑戰性的游戲階段,優于特定任務的架構。在視覺 - 語言導航中,研究者證明 Dynalang 可以學會在視覺和語言復雜的環境中遵循指令。
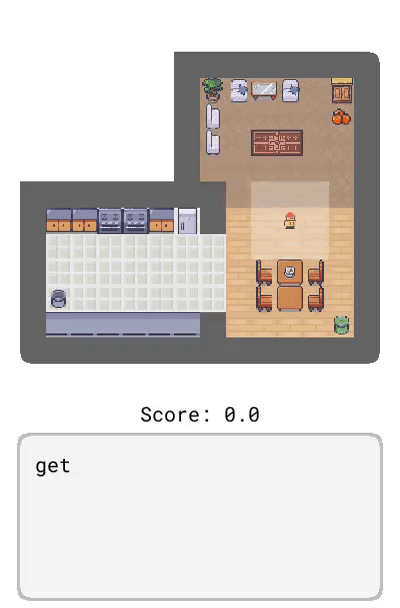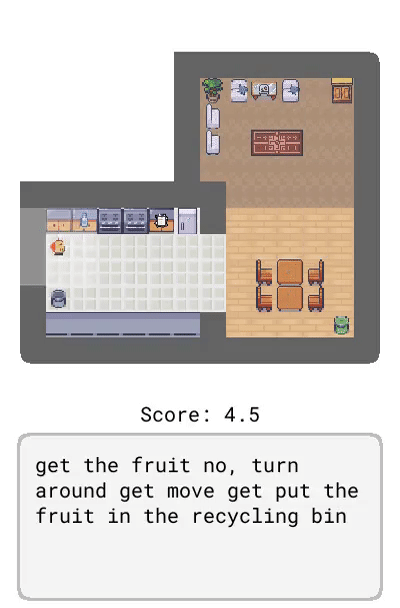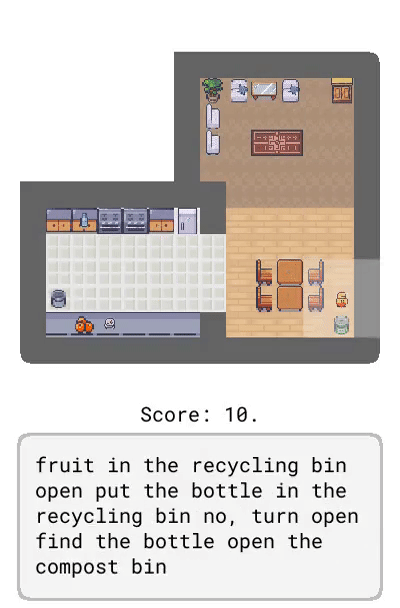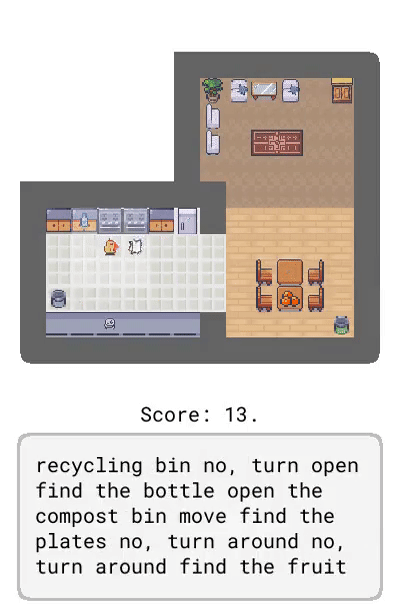
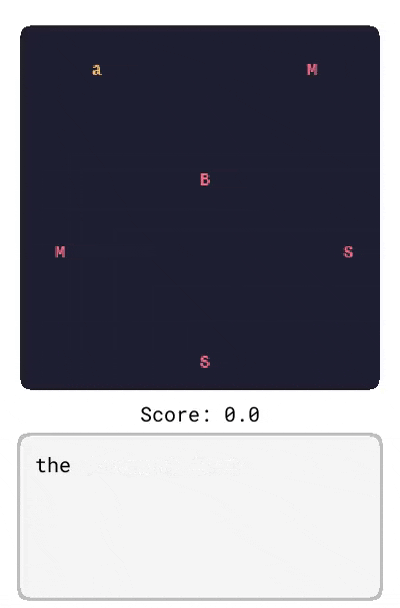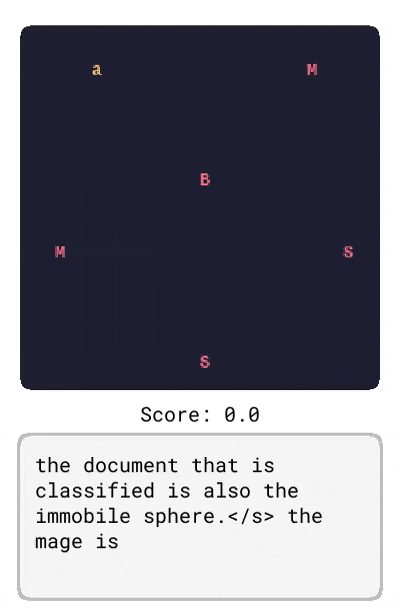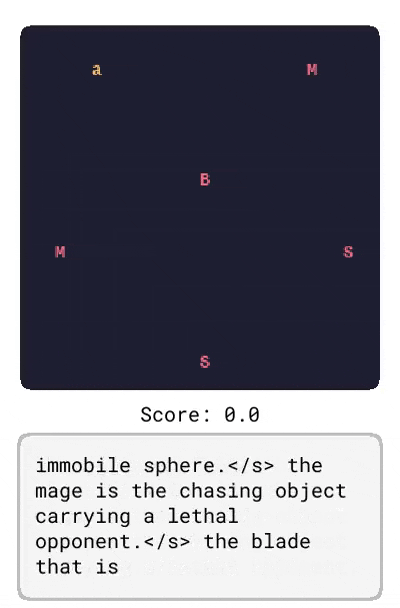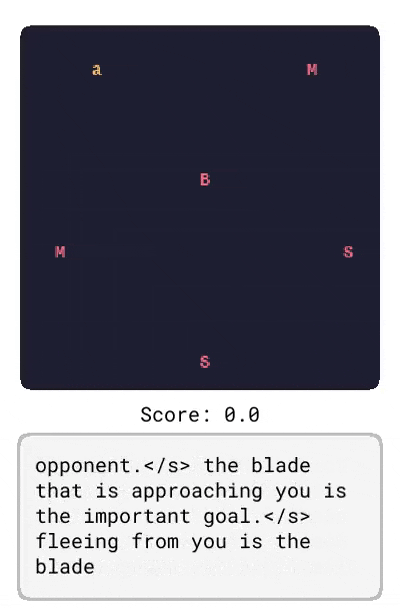
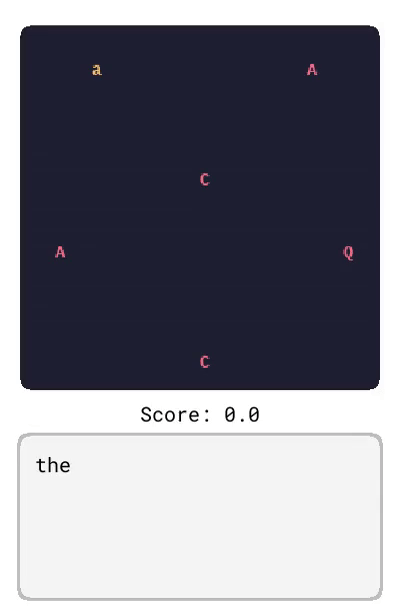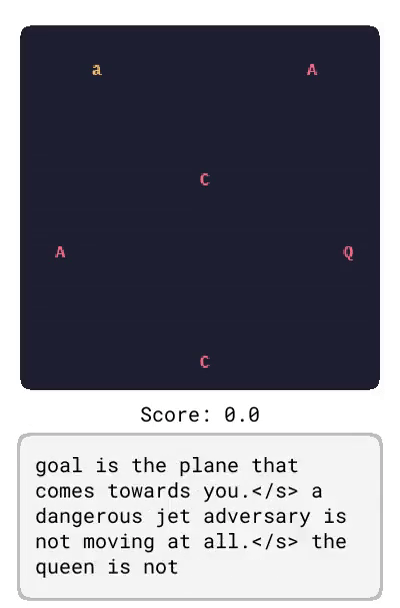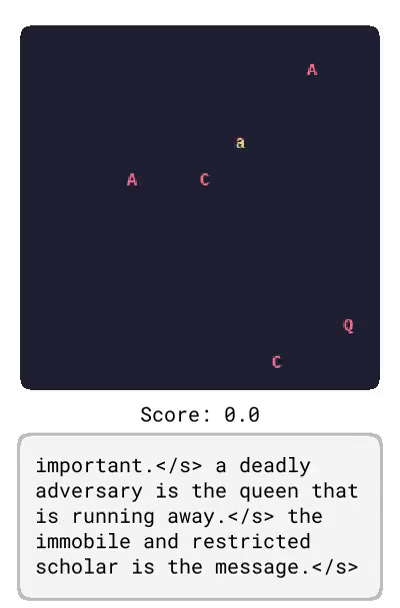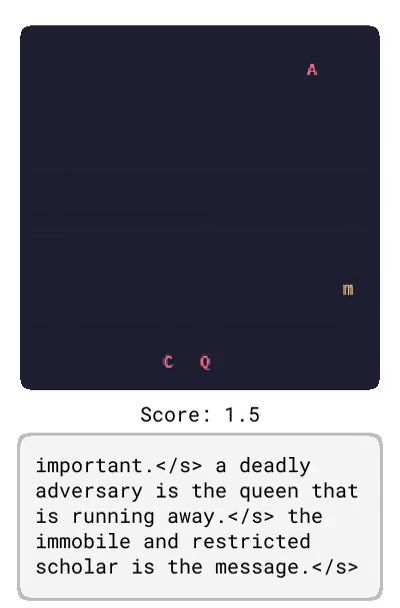
 Dynalang 學會使用語言來預測未來的(文本 + 圖像)觀察結果和獎勵,從而幫助解決任務。在這里,研究者展示了在 HomeGrid 環境中真實的模型預測結果。智能體在接收環境中的視頻和語言觀察的同時,探索了各種房間。根據過去的文本「瓶子在客廳」,在時間步 61-65,智能體預測將在客廳的最后一個角落看到瓶子。根據描述任務的文本「拿起瓶子」,智能體預測將因為拿起瓶子而獲得獎勵。智能體還可以預測未來的文本觀察:在時間步 30,給定前半句「盤子在」,并觀察到櫥柜上的盤子,模型預測下一個最可能的 token 是「廚房」。
Dynalang 學會使用語言來預測未來的(文本 + 圖像)觀察結果和獎勵,從而幫助解決任務。在這里,研究者展示了在 HomeGrid 環境中真實的模型預測結果。智能體在接收環境中的視頻和語言觀察的同時,探索了各種房間。根據過去的文本「瓶子在客廳」,在時間步 61-65,智能體預測將在客廳的最后一個角落看到瓶子。根據描述任務的文本「拿起瓶子」,智能體預測將因為拿起瓶子而獲得獎勵。智能體還可以預測未來的文本觀察:在時間步 30,給定前半句「盤子在」,并觀察到櫥柜上的盤子,模型預測下一個最可能的 token 是「廚房」。
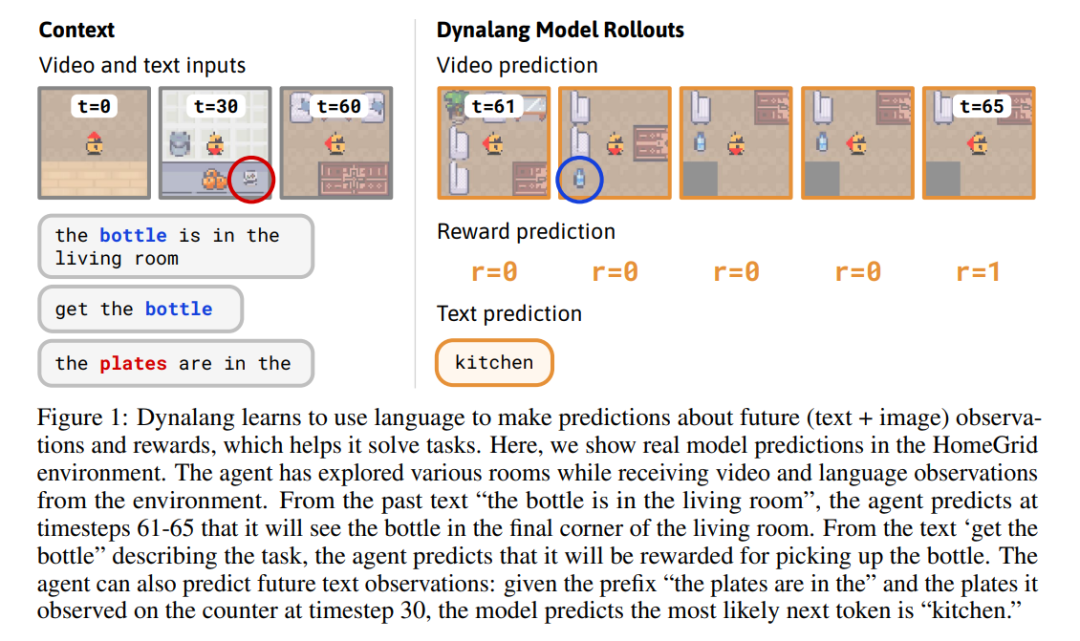
 研究者考慮了一系列具有視覺輸入和多樣化語言的環境。HomeGrid 是一個具有指令和多樣化提示的具有挑戰性的視覺網格世界。Messenger 是一個具有符號輸入的基準測試,包含數百個人工編寫的游戲手冊,需要進行多次推理。Habitat 是一個模擬逼真的 3D 家居環境,用于視覺 - 語言導航,在其中智能體必須在數百個場景中定位物體。LangRoom 是一個簡單的視覺網格世界,具有部分可觀察性,智能體需要同時生成動作和語言。
詳解 Dynalang 工作原理
使用語言來理解世界很自然地符合世界建模范式。這項工作構建在 DreamerV3 的基礎之上,DreamerV3 是一種基于模型的強化學習智能體。Dynalang 不斷地從經驗數據中學習,這些數據是智能體在環境中執行任務時收集到的。
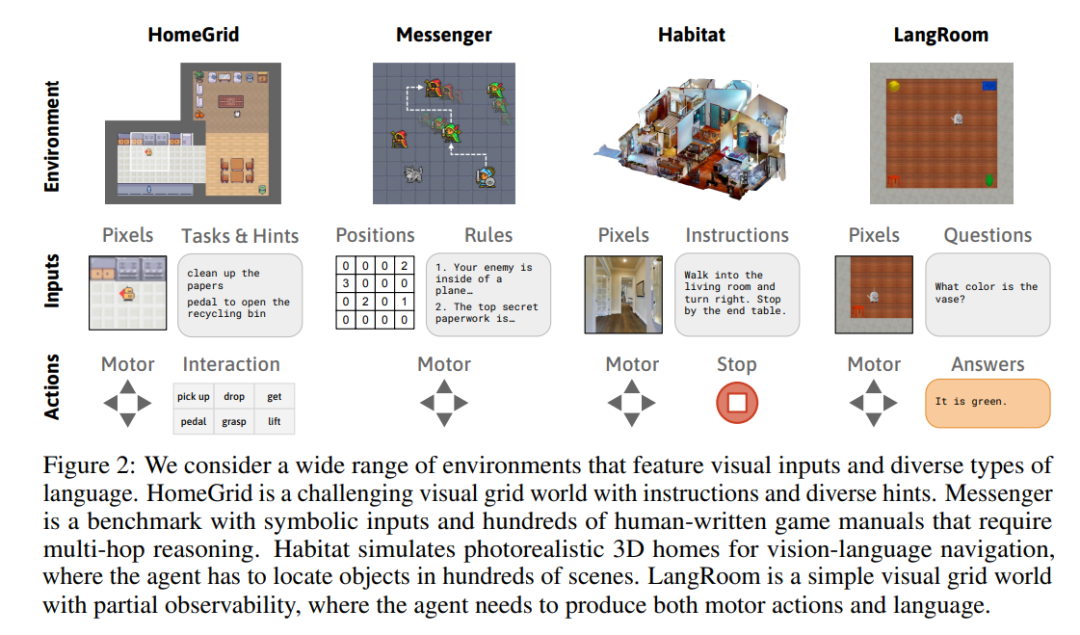
如下圖(左)所示,在每個時間步,世界模型將文本和圖像壓縮成潛在表示。通過這個表示,模型被訓練用于重建原始觀察結果、預測獎勵,并預測下一個時間步的表示。直觀地說,世界模型根據它在文本中讀到的內容,學習它應該期望在世界中看到什么。
如下圖(右)所示,Dynalang 通過在壓縮的世界模型表示之上訓練策略網絡來選擇行動。它通過來自世界模型的想象的模擬結果進行訓練,并學會采取能夠最大化預測獎勵的行動。
研究者考慮了一系列具有視覺輸入和多樣化語言的環境。HomeGrid 是一個具有指令和多樣化提示的具有挑戰性的視覺網格世界。Messenger 是一個具有符號輸入的基準測試,包含數百個人工編寫的游戲手冊,需要進行多次推理。Habitat 是一個模擬逼真的 3D 家居環境,用于視覺 - 語言導航,在其中智能體必須在數百個場景中定位物體。LangRoom 是一個簡單的視覺網格世界,具有部分可觀察性,智能體需要同時生成動作和語言。
詳解 Dynalang 工作原理
使用語言來理解世界很自然地符合世界建模范式。這項工作構建在 DreamerV3 的基礎之上,DreamerV3 是一種基于模型的強化學習智能體。Dynalang 不斷地從經驗數據中學習,這些數據是智能體在環境中執行任務時收集到的。
如下圖(左)所示,在每個時間步,世界模型將文本和圖像壓縮成潛在表示。通過這個表示,模型被訓練用于重建原始觀察結果、預測獎勵,并預測下一個時間步的表示。直觀地說,世界模型根據它在文本中讀到的內容,學習它應該期望在世界中看到什么。
如下圖(右)所示,Dynalang 通過在壓縮的世界模型表示之上訓練策略網絡來選擇行動。它通過來自世界模型的想象的模擬結果進行訓練,并學會采取能夠最大化預測獎勵的行動。
 與之前逐句或逐段消耗文本的多模態模型不同,研究者設計的 Dynalang 將視頻和文本作為一個統一的序列來建模,一次處理一幀圖像和一個文本 token。直觀來說,這類似于人類在現實世界中接收輸入的方式 —— 作為一個單一的多模態流,人需要時間來聆聽語言。將所有內容建模為一個序列使得模型可以像語言模型一樣在文本數據上進行預訓練,并提高強化學習的性能。
HomeGrid 中的語言提示
研究者引入了 HomeGrid 來評估一個環境中的智能體。在這個環境中,智能體除了任務指令外還會收到語言提示。
HomeGrid 是一個具有指令和多樣化提示的具有挑戰性的視覺網格世界。HomeGrid 中的提示模擬了智能體可能從人類那里學到或從文本中獲取的知識,提供了對解決任務有幫助但不是必需的信息:
未來觀察:描述了智能體未來可能觀察到的情況,比如「盤子在廚房里」。
與之前逐句或逐段消耗文本的多模態模型不同,研究者設計的 Dynalang 將視頻和文本作為一個統一的序列來建模,一次處理一幀圖像和一個文本 token。直觀來說,這類似于人類在現實世界中接收輸入的方式 —— 作為一個單一的多模態流,人需要時間來聆聽語言。將所有內容建模為一個序列使得模型可以像語言模型一樣在文本數據上進行預訓練,并提高強化學習的性能。
HomeGrid 中的語言提示
研究者引入了 HomeGrid 來評估一個環境中的智能體。在這個環境中,智能體除了任務指令外還會收到語言提示。
HomeGrid 是一個具有指令和多樣化提示的具有挑戰性的視覺網格世界。HomeGrid 中的提示模擬了智能體可能從人類那里學到或從文本中獲取的知識,提供了對解決任務有幫助但不是必需的信息:
未來觀察:描述了智能體未來可能觀察到的情況,比如「盤子在廚房里」。
 Dynamics:描述了環境的動態變化,比如「踩踏板打開垃圾桶」。
Dynamics:描述了環境的動態變化,比如「踩踏板打開垃圾桶」。
 Messenger 中的游戲手冊
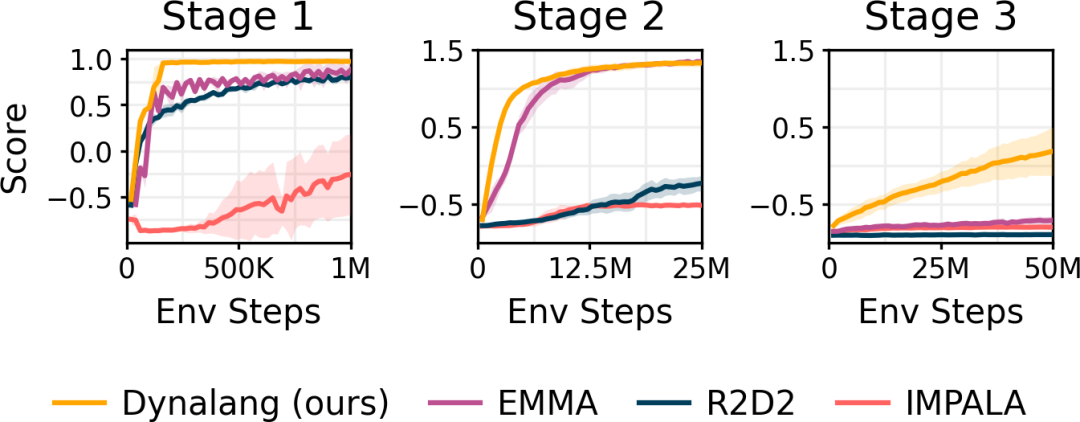
研究者在 Messenger 游戲環境中進行評估,以測試智能體如何從更長、更復雜的文本中學習,這需要對文本和視覺觀察進行多次推理。智能體必須對描述每個任務動態的文本手冊進行推理,并將其與環境中實體的觀察結果結合起來,以確定哪些實體應該接收消息,哪些應該避免。Dynalang 的表現優于 IMPALA、R2D2 以及使用專門架構對文本和觀察進行推理的任務特定 EMMA 基線,特別是在最困難的第三階段。
Messenger 中的游戲手冊
研究者在 Messenger 游戲環境中進行評估,以測試智能體如何從更長、更復雜的文本中學習,這需要對文本和視覺觀察進行多次推理。智能體必須對描述每個任務動態的文本手冊進行推理,并將其與環境中實體的觀察結果結合起來,以確定哪些實體應該接收消息,哪些應該避免。Dynalang 的表現優于 IMPALA、R2D2 以及使用專門架構對文本和觀察進行推理的任務特定 EMMA 基線,特別是在最困難的第三階段。
 ?
? ?
? ?
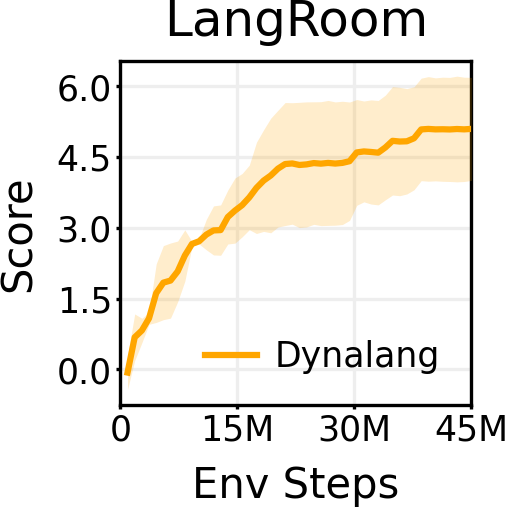
? ?基于 LangRoom 的語言生成
就像語言可以影響智能體對將要看到的事物的預測一樣,智能體觀察到的內容也會影響它對將要聽到的語言的期望(例如,關于它所看到的內容的真實陳述)。通過在 LangRoom 中將語言輸出到動作空間,研究者展示了 Dynalang 可以生成與環境相關聯的語言,從而進行具身問答。LangRoom 是一個簡單的視覺網格世界,具有部分可觀察性,智能體需要在其中產生運動動作和語言。
?基于 LangRoom 的語言生成
就像語言可以影響智能體對將要看到的事物的預測一樣,智能體觀察到的內容也會影響它對將要聽到的語言的期望(例如,關于它所看到的內容的真實陳述)。通過在 LangRoom 中將語言輸出到動作空間,研究者展示了 Dynalang 可以生成與環境相關聯的語言,從而進行具身問答。LangRoom 是一個簡單的視覺網格世界,具有部分可觀察性,智能體需要在其中產生運動動作和語言。
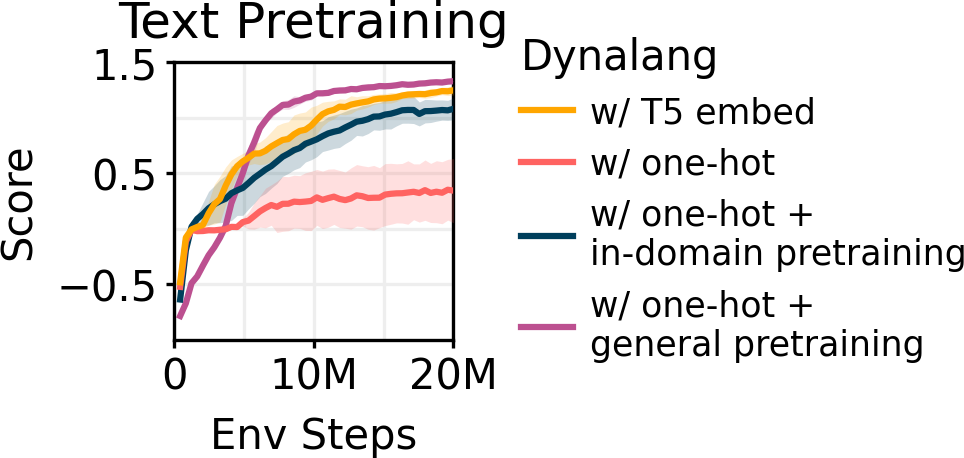 研究者表示,盡管他們的工作專注于用于在世界中行動的語言理解,但它也可以像一個僅文本語言模型一樣從世界模型中生成文本。研究者在潛在空間中對預訓練的 TinyStories 模型進行模擬的抽樣,然后在每個時間步驟從表示中解碼 token 觀察。盡管生成的文本質量仍然低于當前語言模型的水平,但模型生成的文本令人驚訝地連貫。他們認為將語言生成和行動統一在一個智能體架構中是未來研究的一個令人興奮的方向。
研究者表示,盡管他們的工作專注于用于在世界中行動的語言理解,但它也可以像一個僅文本語言模型一樣從世界模型中生成文本。研究者在潛在空間中對預訓練的 TinyStories 模型進行模擬的抽樣,然后在每個時間步驟從表示中解碼 token 觀察。盡管生成的文本質量仍然低于當前語言模型的水平,但模型生成的文本令人驚訝地連貫。他們認為將語言生成和行動統一在一個智能體架構中是未來研究的一個令人興奮的方向。

圖源:谷歌機器人團隊論文「Interactive Language: Talking to Robots in Real Time」。
UC 伯克利 Dynalang 研究的關鍵思想是,我們可以將語言看作是幫助我們更好地對世界進行預測的工具,比如「我們的牛奶喝完了」→打開冰箱時沒有牛奶;「扳手可以用來擰緊螺母」→使用工具時螺母會旋轉。Dynalang 在一個模型中結合了語言模型(LM)和世界模型(WM),使得這種范式變成多模態。研究者認為,將語言生成和行動統一在一個智能體架構中是未來研究的一個令人興奮的方向。

論文概覽 人工智能長期以來的目標是開發能夠在物理世界中與人類自然交互的智能體。當前的具身智能體可以遵循簡單的低層指令,比如「拿一塊藍色的積木」或者「經過電梯,然后向右轉」。 然而,要實現自由交流的互動智能體,就需要理解人們在「此時此地」之外使用語言的完整方式,包括:傳遞知識,比如「左上角的按鈕是關掉電視的」;提供情境信息,如「我們的牛奶喝完了」;以及協同,比如跟別人說「我已經吸過客廳了」。我們在文本中閱讀的很多內容或者從他人口中聽到的信息都在傳遞有關世界的知識,無論是關于世界如何運行還是關于當前世界狀態的知識。 我們如何使智能體能夠使用多樣化的語言呢?一種訓練基于語言的智能體解決任務的方法是強化學習(RL)。然而,目前的基于語言的 RL 方法主要是學習從特定任務指令生成行動,例如將目標描述「拿起藍色的積木」作為輸入,輸出一系列運動控制。 然而,當考慮到自然語言在現實世界中所服務的多樣功能時,直接將語言映射到最優行動是一個具有挑戰性的學習問題。以「我把碗放好了」為例:如果任務是清洗,智能體應該繼續進行下一個清洗步驟;而如果是晚餐服務,智能體應該去取碗。當語言不涉及任務時,它只與智能體應該采取的最優行動弱相關。將語言映射到行動,尤其是僅使用任務獎勵,對于學會使用多樣化語言輸入完成任務來說是一個弱學習信號。 不同的是,UC 伯克利的研究者提出,智能體使用語言的一種統一方法是幫助它們預測未來。前面提到的語句「我把碗放好了」有助于智能體更好地預測未來的觀察結果(即,如果它采取行動打開櫥柜,它將在那里看到碗)。 我們遇到的很多語言可以通過這種方式與視覺體驗聯系起來。先前的知識,比如「扳手可以用來擰緊螺母」,幫助智能體預測環境變化。諸如「包裹在外面」的陳述有助于智能體預測未來的觀察結果。這個框架還將標準指令遵循歸入預測范疇:指令幫助智能體預測自己將如何受到獎勵。類似于下一個 token 預測允許語言模型形成關于世界知識的內部表示,研究者假設預測未來的表示為智能體理解語言以及它與世界的關系提供了豐富的學習信號。
基于此,他們提出了 Dynalang,一種從在線經驗中學習語言和圖像世界模型,并利用該模型學習如何行動的智能體。
Dynalang 將學習用語言對世界建模(帶有預測目標的監督學習)與學習根據該模型采取行動(帶有任務獎勵的強化學習)分離開來。該世界模型接收視覺和文本輸入作為觀察模態,并將它們壓縮到潛在空間。研究者通過在線收集的經驗訓練世界模型,使其能夠預測未來的潛在表示,同時智能體在環境中執行任務。他們通過將世界模型的潛在表示作為輸入,訓練策略來采取最大化任務獎勵的行動。由于世界建模與行動分離,Dynalang 可以在沒有行動或任務獎勵的單模態數據(僅文本或僅視頻數據)上進行預訓練。
此外,他們的框架還可以統一語言生成:智能體的感知可以影響智能體的語言模型(即其對未來 token 的預測),使其能夠通過在動作空間輸出語言來描述環境。
?論文鏈接:https://arxiv.org/pdf/2308.01399.pdf項目主頁:https://dynalang.github.io/代碼鏈接:https://github.com/jlin816/dynalang
研究者在具有不同類型語言上下文的多樣化環境中對 Dynalang 進行了評估。在一個多任務家庭清潔環境中,Dynalang 學會利用關于未來觀察、環境動態和修正的語言提示,更高效地完成任務。在 Messenger 基準測試中,Dynalang 可以閱讀游戲手冊來應對最具挑戰性的游戲階段,優于特定任務的架構。在視覺 - 語言導航中,研究者證明 Dynalang 可以學會在視覺和語言復雜的環境中遵循指令。
Dynalang 學會使用語言來預測未來的(文本 + 圖像)觀察結果和獎勵,從而幫助解決任務。在這里,研究者展示了在 HomeGrid 環境中真實的模型預測結果。智能體在接收環境中的視頻和語言觀察的同時,探索了各種房間。根據過去的文本「瓶子在客廳」,在時間步 61-65,智能體預測將在客廳的最后一個角落看到瓶子。根據描述任務的文本「拿起瓶子」,智能體預測將因為拿起瓶子而獲得獎勵。智能體還可以預測未來的文本觀察:在時間步 30,給定前半句「盤子在」,并觀察到櫥柜上的盤子,模型預測下一個最可能的 token 是「廚房」。
研究者考慮了一系列具有視覺輸入和多樣化語言的環境。HomeGrid 是一個具有指令和多樣化提示的具有挑戰性的視覺網格世界。Messenger 是一個具有符號輸入的基準測試,包含數百個人工編寫的游戲手冊,需要進行多次推理。Habitat 是一個模擬逼真的 3D 家居環境,用于視覺 - 語言導航,在其中智能體必須在數百個場景中定位物體。LangRoom 是一個簡單的視覺網格世界,具有部分可觀察性,智能體需要同時生成動作和語言。
詳解 Dynalang 工作原理
使用語言來理解世界很自然地符合世界建模范式。這項工作構建在 DreamerV3 的基礎之上,DreamerV3 是一種基于模型的強化學習智能體。Dynalang 不斷地從經驗數據中學習,這些數據是智能體在環境中執行任務時收集到的。
如下圖(左)所示,在每個時間步,世界模型將文本和圖像壓縮成潛在表示。通過這個表示,模型被訓練用于重建原始觀察結果、預測獎勵,并預測下一個時間步的表示。直觀地說,世界模型根據它在文本中讀到的內容,學習它應該期望在世界中看到什么。
如下圖(右)所示,Dynalang 通過在壓縮的世界模型表示之上訓練策略網絡來選擇行動。它通過來自世界模型的想象的模擬結果進行訓練,并學會采取能夠最大化預測獎勵的行動。
與之前逐句或逐段消耗文本的多模態模型不同,研究者設計的 Dynalang 將視頻和文本作為一個統一的序列來建模,一次處理一幀圖像和一個文本 token。直觀來說,這類似于人類在現實世界中接收輸入的方式 —— 作為一個單一的多模態流,人需要時間來聆聽語言。將所有內容建模為一個序列使得模型可以像語言模型一樣在文本數據上進行預訓練,并提高強化學習的性能。
HomeGrid 中的語言提示
研究者引入了 HomeGrid 來評估一個環境中的智能體。在這個環境中,智能體除了任務指令外還會收到語言提示。
HomeGrid 是一個具有指令和多樣化提示的具有挑戰性的視覺網格世界。HomeGrid 中的提示模擬了智能體可能從人類那里學到或從文本中獲取的知識,提供了對解決任務有幫助但不是必需的信息:
未來觀察:描述了智能體未來可能觀察到的情況,比如「盤子在廚房里」。
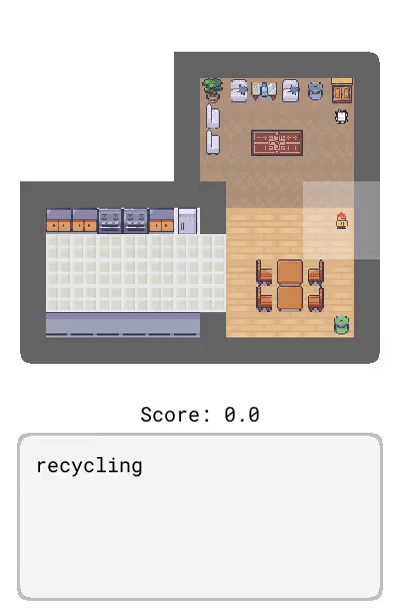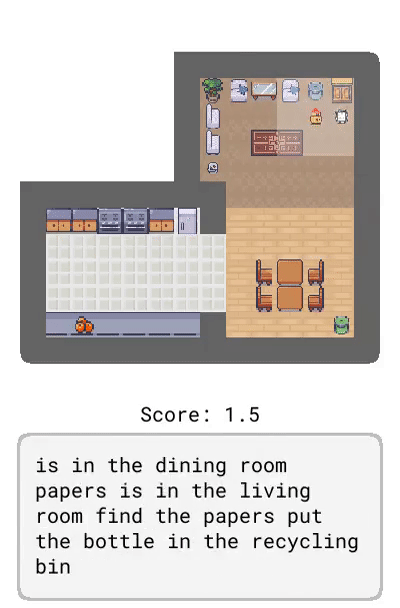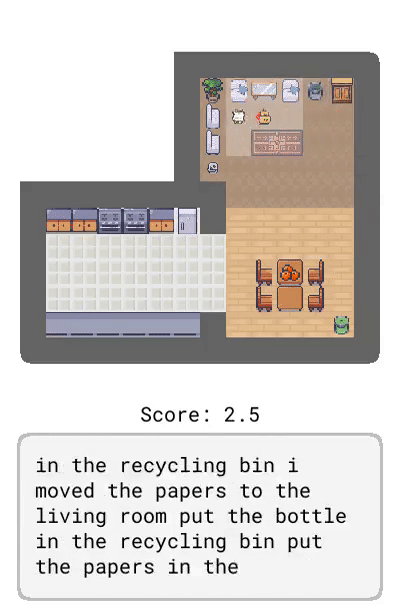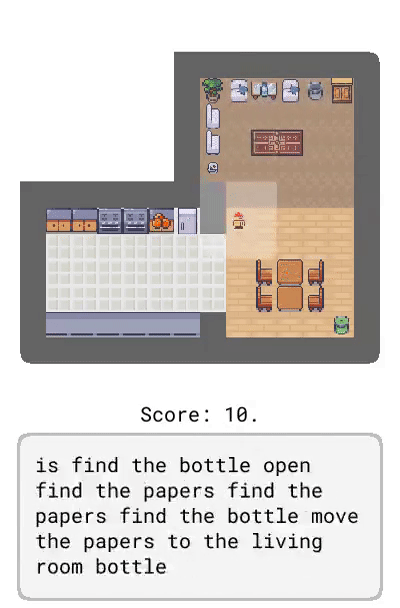
Correction:提供了基于智能體當前行為的交互式反饋,比如「轉身」。
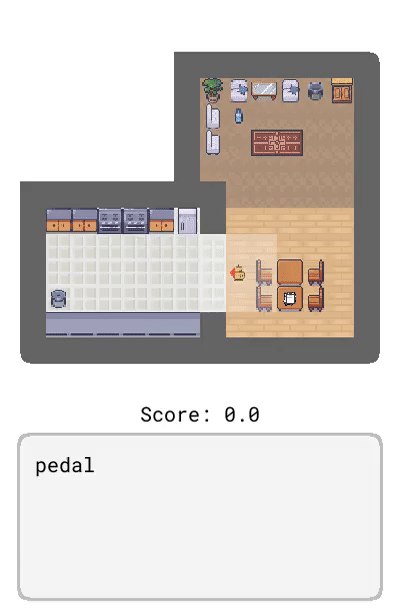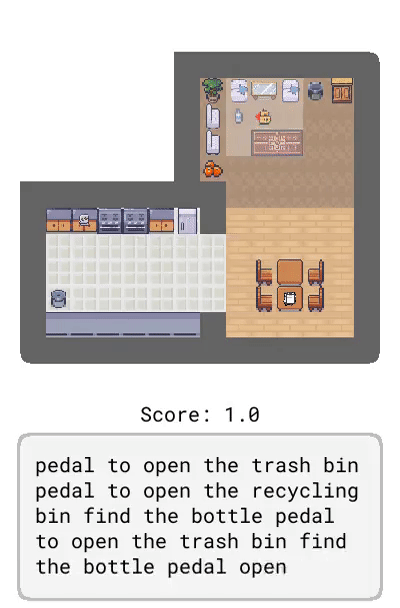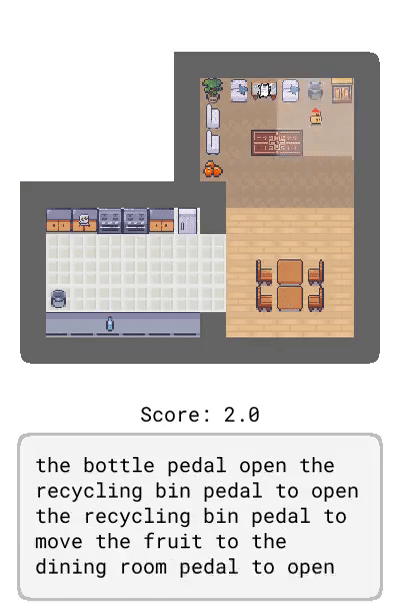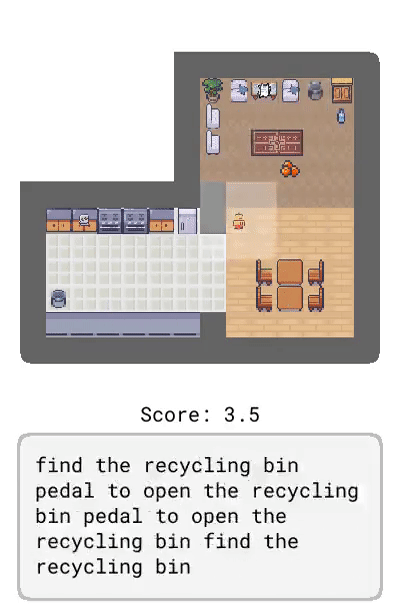
Dynamics:描述了環境的動態變化,比如「踩踏板打開垃圾桶」。
Messenger 中的游戲手冊
研究者在 Messenger 游戲環境中進行評估,以測試智能體如何從更長、更復雜的文本中學習,這需要對文本和視覺觀察進行多次推理。智能體必須對描述每個任務動態的文本手冊進行推理,并將其與環境中實體的觀察結果結合起來,以確定哪些實體應該接收消息,哪些應該避免。Dynalang 的表現優于 IMPALA、R2D2 以及使用專門架構對文本和觀察進行推理的任務特定 EMMA 基線,特別是在最困難的第三階段。
?
?
?

?基于 LangRoom 的語言生成
就像語言可以影響智能體對將要看到的事物的預測一樣,智能體觀察到的內容也會影響它對將要聽到的語言的期望(例如,關于它所看到的內容的真實陳述)。通過在 LangRoom 中將語言輸出到動作空間,研究者展示了 Dynalang 可以生成與環境相關聯的語言,從而進行具身問答。LangRoom 是一個簡單的視覺網格世界,具有部分可觀察性,智能體需要在其中產生運動動作和語言。

研究者表示,盡管他們的工作專注于用于在世界中行動的語言理解,但它也可以像一個僅文本語言模型一樣從世界模型中生成文本。研究者在潛在空間中對預訓練的 TinyStories 模型進行模擬的抽樣,然后在每個時間步驟從表示中解碼 token 觀察。盡管生成的文本質量仍然低于當前語言模型的水平,但模型生成的文本令人驚訝地連貫。他們認為將語言生成和行動統一在一個智能體架構中是未來研究的一個令人興奮的方向。
原文標題:用語言建模世界:UC伯克利多模態世界模型利用語言預測未來
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2903文章
44273瀏覽量
371234
原文標題:用語言建模世界:UC伯克利多模態世界模型利用語言預測未來
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
的表達方式和生成能力。通過預測文本中缺失的部分或下一個詞,模型逐漸掌握語言的規律和特征。
常用的模型結構
Transformer架構:大語言
發表于 08-02 11:03
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
的機會!
本人曾經也參與過語音識別產品的開發,包括在線和離線識別,但僅是應用語言模型實現端側的應用開發,相當于調用模型的接口函數,實際對模型的設計、訓練和運行機理并不了解,我想通過學習
發表于 07-21 13:35
【大語言模型:原理與工程實踐】大語言模型的應用
能力,它缺乏真正的“思考”過程。對于任何輸入,大語言模型都會產生輸出,但這僅僅是基于計算和預測下一個Token出現的概率。模型并不清楚自己的優勢或劣勢,也無法主動進行反思和糾正錯誤。提
發表于 05-07 17:21
【大語言模型:原理與工程實踐】大語言模型的評測
在知識獲取、邏輯推理、代碼生成等方面的能力。這些評測基準包括語言建模能力、綜合知識能力、數學計算能力、代碼能力和垂直領域等多個維度。對于微調模型,對話能力的評測關注模型在對話任務中的全
發表于 05-07 17:12
【大語言模型:原理與工程實踐】大語言模型的預訓練
數據格式的轉換、數據字段的匹配和整合等。通過數據級凈化,可以進一步提高數據的質量和可用性,為后續的數據分析和建模提供更有價值的數據支持。
在得到了大語言模型的數據之后,就是對其進行預訓練。大圓
發表于 05-07 17:10
【大語言模型:原理與工程實踐】大語言模型的基礎技術
就無法修改,因此難以靈活應用于下游文本的挖掘中。
詞嵌入表示:將每個詞映射為一個低維稠密的實值向量。不同的是,基于預訓練的詞嵌入表示先在語料庫中利用某種語言模型進行預訓練,然后將其應用到下游任務中,詞
發表于 05-05 12:17
【大語言模型:原理與工程實踐】核心技術綜述
的復雜模式和長距離依賴關系。
預訓練策略:
預訓練是LLMs訓練過程的第一階段,模型在大量的文本數據上學習語言的通用表示。常用的預訓練任務包括遮蔽語言建模(Masked Langu
發表于 05-05 10:56
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
大語言模型(LLM)是人工智能領域的尖端技術,憑借龐大的參數量和卓越的語言理解能力贏得了廣泛關注。它基于深度學習,利用神經網絡框架來理解和生成自然語
發表于 05-04 23:55
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
的未來發展方向進行了展望,包括跨領域、跨模態和自動提示生成能力方向,為讀者提供了對未來技術發展的深刻見解。《大語言模型原理與工程實踐》是一本
發表于 04-30 15:35
fpga通用語言是什么
FPGA(現場可編程門陣列)的通用語言主要是指用于描述FPGA內部邏輯結構和行為的硬件描述語言。目前,Verilog HDL和VHDL是兩種最為廣泛使用的FPGA編程語言。
韓國Kakao宣布開發多模態大語言模型“蜜蜂”
韓國互聯網巨頭Kakao最近宣布開發了一種名為“蜜蜂”(Honeybee)的多模態大型語言模型。這種創新模型能夠同時理解和處理圖像和文本數據,為更豐富的交互和查詢響應提供了可能性。
機器人基于開源的多模態語言視覺大模型
ByteDance Research 基于開源的多模態語言視覺大模型 OpenFlamingo 開發了開源、易用的 RoboFlamingo 機器人操作模型,只用單機就可以訓練。
發表于 01-19 11:43
?365次閱讀

自動駕駛和多模態大語言模型的發展歷程
多模態大語言模型(MLLM) 最近引起了廣泛的關注,其將 LLM 的推理能力與圖像、視頻和音頻數據相結合,通過多模態對齊使它們能夠更高效地執行各種任務,包括圖像分類、將文本與相應的視頻
發表于 12-28 11:45
?490次閱讀

大規模語言模型的基本概念、發展歷程和構建流程
使用自然語言與系統交互,從而實現包括問答、分類、摘要、翻譯、聊天等從理解到生成的各種任務。大型語言模型展現出了強大的對世界知識掌握和對語言的

計算機視覺迎來GPT時刻!UC伯克利三巨頭祭出首個純CV大模型!
在損失函數上,研究者從自然語言社區汲取靈感,即掩碼 token 建模已經「讓位給了」序列自回歸預測方法。一旦圖像、視頻、標注圖像都可以表示為序列,則訓練的模型可以在






 工商網監
工商網監
評論