 基于 Elasticsearch 的日志系統架構如何面臨挑戰
基于 Elasticsearch 的日志系統架構如何面臨挑戰
實操 Demo 展示 日志數據蘊含了豐富的信息價值,可幫助企業更好了解系統及業務運行情況,保障系統安全穩定運行。為更好滿足日志場景的需求,Apache Doris 在 2.0 版本中引入了多項功能優化:例如增加了倒排索引,支持原生的半結構數據類型,優化了 Text 匹配速度和文本算法等,最終實現相較 Elasticsearch 最高 10 倍的性價比提升。 為了讓大家快速使用 Doris 搭建新一代日志分析平臺,我們為大家實操展示了 Doris 和 Elasticsearch 性能對比,并演示了基于 Doris 搭建新一代日志分析平臺的關鍵步驟,點擊下方視頻即可觀看。 日志數據是企業大數據體系中重要的組成部分之一,這些數據記錄了網絡設備、操作系統以及應用程序的詳細歷史行為,蘊含了豐富的信息價值,在可觀測性、網絡安全、業務分析等關鍵業務領域發揮著重要作用,可幫助企業更好了解系統及業務運行情況,及時發現及解決問題,以保障系統安全穩定運行。具體而言,日志數據可以通過以下方式為企業帶來價值:
可觀測性:日志是可觀測性的三大基石(Logging,Metrics,Tracing)之一,其數據規模占比最高,常用于監控告警、故障排查時快速檢索、Trace 關聯等,可保證系統穩定運行、提升運維效率;
網絡安全:日志記錄了網絡和主機上發生的每一個事件和行為,用于安全分析、調查取證、安全檢測等,是提升系統安全性、降低被攻擊風險的重要手段;
業務分析:在常見的業務分析中,比如在用戶行為分析和用戶畫像等場景中,通常需要對用戶行為日志進行復雜分析,幫助企業了解用戶的喜好和行為軌跡,進一步提高用戶滿意度、促進留存和轉化。因此日志不僅用于運維和安全保障,對于業務增長也發揮著不可或缺的作用。
日志數據本質是一系列系統事件的有序記錄,其生成方式和使用場景決定了具備以下幾個特點:
Schema Free:日志數據最初始的表現形態為非結構化原始日志,以 Free Text 的形式存在,然而非結構化數據是不便于進行聚合統計等分析操作的。如果想對這些數據進行存儲分析,就需要先通過 ETL 將非結構化數據加工為結構化表格,再在數據庫/數據倉庫中進行分析。而在這個過程中,當日志結構發生變化時,還需要對 ETL 和結構化表格進行相應的調整,這就需要研發和 DBA 團隊的協助,流程復雜、耗費時間長且執行難度高。在此之后進一步誕生了以 JSON 為主的半結構化日志,日志生成者可以自主增減字段,日志存儲系統根據數據調整存儲結構。
數據量大:日志數據規模通常非常龐大并生產周期不間斷,特別是在大型企業或典型的日志應用中,每天產生的日志數據可達十 TB 或百 TB級別。同時為了滿足業務需求或符合監管要求,日志數據往往需要存儲半年甚至更長時間,存儲總量經常達到 PB 級別,為各企業帶來高昂的存儲成本。而隨著時間的推移,日志數據的價值也在逐漸下降,因此對于日志系統來說,存儲成本也變得更加敏感。
實時寫入與檢索:日志數據常用于故障排查、安全追蹤等時效要求較高的場景,因此如果數據寫入延遲過高,就無法及時獲取最新發生的事件;如果關鍵字檢索響應慢則無法滿足工程師、分析師的交互式分析需求。因此對于日志系統而言,要求在高吞吐寫入的前提下保證秒級以下的查詢響應時間,并能夠提供全文檢索的能力以及秒級響應的交互式查詢能力。
為了應對以上需求、發揮出日志數據的更高價值,業界對于日志場景有不少解決方案,而以 Elasticsearch 為核心的 ELK 體系則是其中典型代表。在此我們以 Elasticsearch 為例,來分享基于 Elasticsearch 的日志系統架構是如何面臨挑戰。
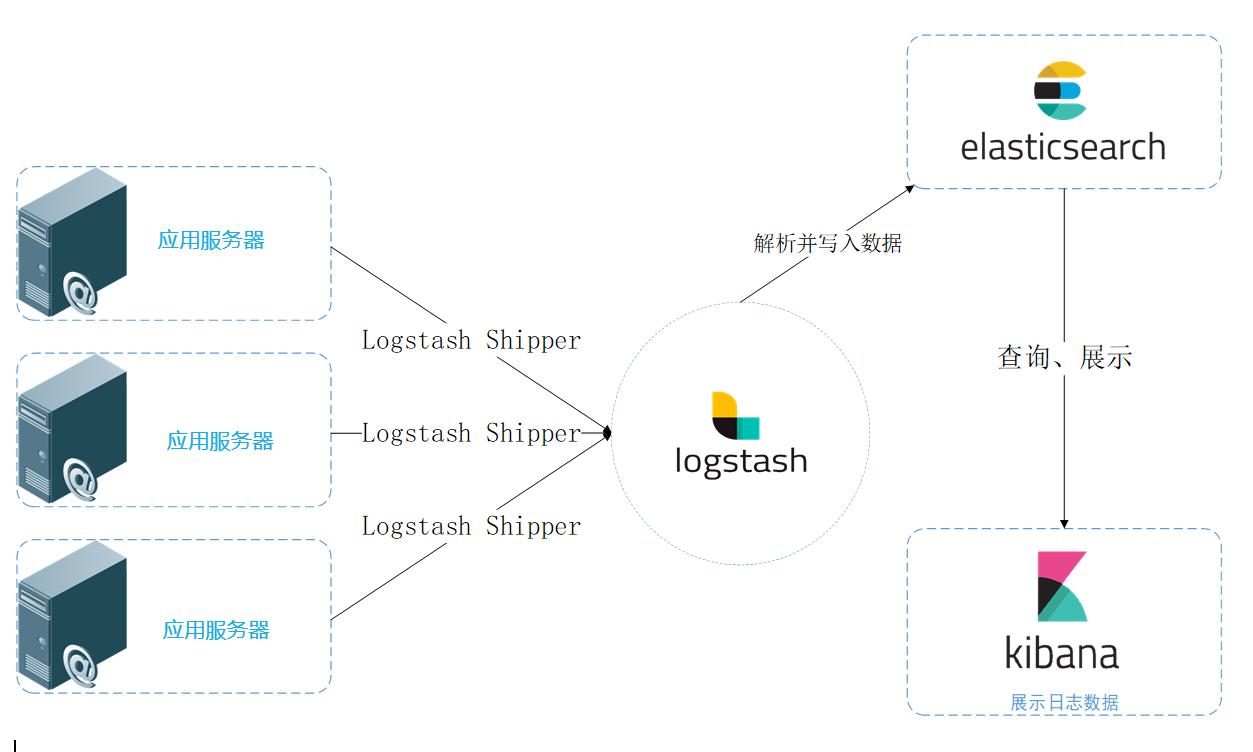
基于 Elasticsearch 的日志系統典型架構如上圖所示,整個系統分為下面幾個模塊:
日志收集:通過 Filebeat 采集本地的日志文件,寫入到 Kafka 消息隊列;
日志傳輸:使用 Kafka 消息隊列集中和緩存日志;
日志轉換:LogStash 消費 Kafka 中的日志,進行數據過濾、格式轉換等操作;
日志存儲:LogStash 將日志以 JSON 格式寫入 ES 存儲中;
日志查詢:通過 Kibana 可視化查詢 ES 中的日志,或者通過 ES DSL API 發起查詢請求;
基于 Elasticsearch 的日志系統架構具有較好的實時日志檢索能力,然而該系統在實際應用中也存在一些痛點,如寫入吞吐低、存儲成本高、不支持復雜查詢等問題。
Schema Free 支持不夠
Elasticsearch 的 Index Mapping 定義了數據的 Schema,包括字段的名字、數據類型、是否建索引等。

Elasticsearch 的 Dynamic Mapping 可以根據寫入的 JSON 數據自動增加 Mapping 中的字段,對日志數據的 Schema Free 提供了一定程度的支持,但是也存在明顯不足:
Dynamic Mapping 性能差:當遇到臟數據時容易出現大量字段,嚴重影響系統性能和穩定性。
字段類型固定:當業務類型變更時無法進行修改,為了滿足不同的業務需求,用戶常常使用 text 類型來兼容,但是 text 類型的查詢性能是遠不如 integer 等二進制類型的查詢性能。
字段的索引固定:無法根據需求自行增加或刪除某個字段的索引,靈活性較差。因此用戶為了保證查詢過濾的速度,通常會在所有字段上都創建索引。而在所有字段上創建索引又會帶來寫入速度變慢、存儲空間增加等新的問題。
分析能力弱
Elasticsearch 開發的 ES DSL(Domain Specific Language,特定領域語言)與大多數工程師、數據分析師熟悉的技術棧差異比較大,這為用戶設置了較高的學習和使用門檻,并需要學習大量的多新的概念和語法,即使學會之后還需要經常查閱手冊才能寫出正確的 DSL 語句。同時,Elasticsearch 生態自成體系、比較封閉,與其他系統如 BI 工具等打通比較困難。更重要的是, Elasticsearch 分析能力較弱,只支持簡單的單表分析,不支持多表 JOIN、子查詢、視圖等復雜分析,無法滿足企業日志分析需求。

成本高,性價比低
基于 Elasticsearch 的日志系統使用成本較高也是一個被用戶長期詬病的問題,成本主要來源于兩個方面:
寫入的計算成本:Elasticsearch 在寫入時要構建倒排索引,會進行分詞、倒排表排序等計算密集型操作,CPU 資源占用較大,單核寫入性能在 2MB/s 左右。當一個 Elasticsearch 集群的大多數 CPU 資源都被寫入消耗時,在遇到寫入流量高峰時極易觸發寫入 Reject,從而導致數據延遲變長、查詢速度變慢。
數據的存儲成本:為加速檢索和分析的速度,Elasticsearch 存儲了原始數據正排、倒排索引、Docvalue 列存等多份數據,因此造成存儲成本大幅增高,且單副本存儲的壓縮率整體被限制在 1.5 倍左右,遠低于日志數據常見的 5 倍壓縮比。
而隨著數據和集群規模增長, Elasticsearch 集群還面臨一些穩定性問題:
寫入不穩定:當遇到寫入高峰時,將造成集群負載高的問題,從而影響寫入的穩定性。
查詢不穩定:由于查詢都在內存中處理,大查詢容易觸發 JVM OOM,進而影響整個集群的寫入和查詢的穩定性。
故障恢復慢:Elasticsearch 集群在故障后恢復時需要進行 Index 加載等資源占用較大的操作,因此故障恢復時間經常需要數十分鐘,對服務可用性和 SLA 提出了很大的挑戰。
從以上方案對可知,基于 Elasticsearch 的日志系統架構在應用中無法同時兼顧高吞吐、低存儲成本和實時高性能的要求,且不支持復雜查詢。那么是否有其他方案可以較好的平衡成本與性能,且能提供更好的分析能力呢?答案是有的。
立志于通過一個系統解決多個場景的數據分析問題、降低復雜技術帶來的運維和使用成本,為了更加契合日志數據分析的場景需求,Apache Doris 在 2.0 版本中引入了多項功能優化:例如支持原生的半結構數據類型,優化了 Text 匹配速度和文本算法,從而提升了日志數據導入和查詢的性能;增加了倒排索引、以滿足字符串類型的全文檢索和普通數值/日期等類型的等值、范圍檢索。最終通過 Benchmark 測試和實際應用驗證表明, 基于 Apache Doris 構建的新一代日志分析系統相較于 Elasticsearch 具有最高 10 倍的性價比提升。
基于 Apache Doris 的日志系統典型架構如下圖所示,相較于 Elasticsearch 整個系統架構更加開放:
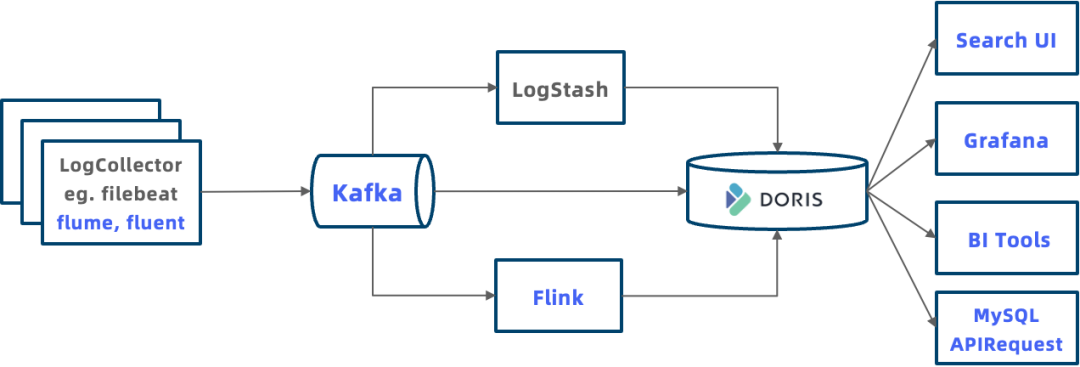
更多日志接入方式:Doris 提供了多種日志數據的導入方式。例如支持 LogStash 通過 HTTP Output 將日志推送到 Doris、支持使用 Flink 對日志進行加工后再寫入 Doris,支持 Routine Load 和 S3 Load 導入存儲在 Kafka 或者對象存儲中的日志數據。
統一存儲消除數據孤島:日志數據可以統一存儲到 Doris 中,并可以和數倉中其他數據進行關聯分析,不再是獨立存在的數據孤島。
開放生態,更強分析能力:Doris 兼容 MySQL 協議,各類數據分析工具或者客戶端可以通過 MySQL 連接到 Doris ,包括可觀測性系統 Grafana、常見的 BI 分析工具 Tableau 等。應用程序也可以通過 JDBC、ODBC 等標準 API 來連接 Doris ,以進行業務特定的查詢分析。后續我們還將完成類似于 Kibana 的可視化日志探索分析系統,進一步提升日志分析的體驗。
除此之外,基于 Apache Doris 的日志系統還具備以下幾個重要的優勢:
原生的半結構化數據支持
為了更好的適應 Text、JSON 格式日志 Schema Free 的特點,Apache Doris 在這兩個方面進行了增強:
提供豐富的數據類型:優化已有 Text 的數據類型,通過向量化技術提升字符串查找、正則匹配的性能,通過這些優化實現性能提升 2-10倍;增加 JSON 數據類型,在數據寫入對 JSON字符串進行解析并存儲成緊湊高效的二進制格式,可使得查詢性能提升 4 倍;增加 Array Map 復雜數據類型,將原本使用字符串拼接的復雜類型結構化,進一步提升了存儲壓縮率和查詢性能。
支持 Schema Evolution:與 Elasticsearch 不同的是,Apache Doris 支持根據業務需要對 Schema 進行調整,包括按需在線增減字段、增減索引、更改字段數據類型等。
Apache Doris 推出的 Light Schema Change 功能可以根據數據變化進行毫秒級增減字段:
--增加列,毫秒級返回,立即生效 ALTERTABLElineitemADDCOLUMNl_new_columnINT;
通過 Light Schema Change 還可以按需增加倒排索引,無需為所有字段創建索引,避免不必要的寫入和存儲開銷。Doris 在增加索引時,默認對新寫入數據生成索引,并可以對歷史數據選擇對哪些分區生成索引,用戶可靈活控制。
--增加倒排索引,毫秒級返回,新寫入數據自動生成索引 ALTERTABLEtable_nameADDINDEXindex_name(column_name)USINGINVERTED; --歷史partition可以按需BUILDINDEX,后臺增量生成索引 BUILDINDEXindex_nameONtable_namePARTITIONS(partition_name1,partition_name2);
基于 SQL 的分析引擎
Apache Doris 支持標準 SQL、兼容 MySQL 協議和語法,因此基于 Doris 的日志系統能夠使用 SQL 進行日志分析,這使得日志系統具備以下優勢:
簡單易用:工程師和數據分析師對于 SQL 非常熟悉,經驗可以復用,不需要學習新的技術棧即可快速上手。
生態豐富:MySQL 生態是數據庫領域使用最廣泛的語言,因此可以與 MySQL 生態的集成和應用無縫銜接。Doris 可以利用 MySQL 命令行與各種 GUI 工具、BI 工具等大數據生態結合,實現更復雜及多樣化的數據處理分析需求。
分析能力強:SQL 語言已經成為數據庫和大數據分析的事實標準,它具有強大的表達能力和功能,支持檢索、聚合、多表 JOIN、子查詢、UDF、邏輯視圖、物化視圖等多種數據分析能力。
經過 Benchmark 測試及生產驗證,基于 Apache Doris 高性能基礎引擎針對日志場景進行優化后,日志系統性價比相對于 Elasticsearch 具有 5-10 倍的提升。
寫入吞吐提升:Elasticsearch 寫入的性能瓶頸在于解析數據和構建倒排索引的 CPU 消耗。相比之下,Doris 進行了兩方面的寫入優化:一方面利用 SIMD 等 CPU 向量化指令提升了 JSON 數據解析速度和索引構建性能;另一方面針對日志場景簡化了倒排索引結構,去掉日志場景不需要的正排等數據結構,有效降低了索引構建的復雜度。
存儲成本降低:Elasticsearch 存儲瓶頸在于正排、倒排、Docvalue 列存多份存儲和通用壓縮算法壓縮率較低。相比之下,Doris 在存儲上進行了以下優化:去掉正排,縮減了 30% 的索引數據量;采用列式存儲和 ZSTD 壓縮算法,壓縮比可達到 5-10 倍,遠高于 Elasticsearch 的 1.5 倍;日志數據中冷數據訪問頻率很低,Doris 冷熱分層功能可以將超過定義時間段的日志自動存儲到更低的對象存儲中,冷數據的存儲成本可降低 70% 以上。
我們在 Elasticsearch 提供的官方性能 Benchmark Rally 的 HTTP Logs 測試集上進行了對比測試。如下圖可知,Doris 寫入速度是 Elasticsearch 的 5 倍,存儲空間減少了 80%,達到 550 MB/s,寫入后的數據壓縮比接近 1:10、存儲空間節省超 80% ,查詢耗時下降 57%、查詢性能是 Elasticsearch 的 2.3 倍。加上冷熱數據分離降低冷數據存儲成本,整體相較 Elasticsearch 實現 10 倍以上的性價比提升。
在用戶實際場景的驗證中,Doris 也表現出了超出預期的性價比優勢。例如,某游戲公司最初使用的是 Elasticsearch,通過標準的 ELK 進行日志分析,使用成本非常高。由于存儲成本過高,使得該公司在日志數據的合理存儲和高效分析受到了很大的限制,無法滿足業務需求。而在使用 Doris 搭建日志系統后,所需存儲空間僅是 Elasticsearch 的 1/6,極大地降低了存儲成本。同時 Doris 的高性能和優秀的分析能力,也使得該公司能夠更高效靈活地處理日志數據,并提供更好的業務支持。此外,某安全公司利用 Doris 提供的倒排索引構建了日志分析系統,僅使用原來 1/5 的服務器,承載了 30 萬每秒的寫入流量,導入及查詢速度更快。Doris 的引入,不僅降低了該公司運營成本,也極大地提升了分析的效率及系統穩定性,為業務提供了強有力的支持。
下面為大家介紹基于 Apache Doris 構建新一代日志系統的實踐步驟。
首先需要在 Apache Doris 官網下載 2.0 及以上版本:https://doris.apache.org/zh-CN/download,下載完成后參考部署文檔進行集群部署:https://doris.apache.org/zh-CN/docs/dev/install/standard-deployment
第一步:建表
參考下面的例子建表,關鍵點如下:
使用 DATETIMEV2 類型的時間字段作為 Key,在查詢最新 N 條日志時有明顯加速
對經常查詢的字段創建索引,對需要全文檢索的字段指定分詞器 Parser 參數
分區使用時間字段上的 RANGE 分區,開啟動態 Partiiton 可按天自動管理分區
分桶使用 RANDOM 隨機分桶,使用 AUTO 可讓系統根據集群規模和數據量自動計算分桶數量
使用冷熱分離配置 log_s3 對象存儲和 log_policy_1day 超過 1 天轉存 s3 策略
CREATEDATABASElog_db; USElog_db; CREATERESOURCE"log_s3" PROPERTIES ( "type"="s3", "s3.endpoint"="your_endpoint_url", "s3.region"="your_region", "s3.bucket"="your_bucket", "s3.root.path"="your_path", "s3.access_key"="your_ak", "s3.secret_key"="your_sk" ); CREATESTORAGEPOLICYlog_policy_1day PROPERTIES( "storage_resource"="log_s3", "cooldown_ttl"="86400" ); CREATETABLElog_table ( `ts`DATETIMEV2, `clientip`VARCHAR(20), `request`TEXT, `status`INT, `size`INT, INDEXidx_size(`size`)USINGINVERTED, INDEXidx_status(`status`)USINGINVERTED, INDEXidx_clientip(`clientip`)USINGINVERTED, INDEXidx_request(`request`)USINGINVERTEDPROPERTIES("parser"="english") ) ENGINE=OLAP DUPLICATEKEY(`ts`) PARTITIONBYRANGE(`ts`)() DISTRIBUTEDBYRANDOMBUCKETSAUTO PROPERTIES( "replication_num"="1", "storage_policy"="log_policy_1day", "deprecated_dynamic_schema"="true", "dynamic_partition.enable"="true", "dynamic_partition.time_unit"="DAY", "dynamic_partition.start"="-3", "dynamic_partition.end"="7", "dynamic_partition.prefix"="p", "dynamic_partition.buckets"="AUTO", "dynamic_partition.replication_num"="1" );
第二步:日志導入
Apache Doris 支持多種數據導入方式,對于實時日志數據,推薦 3 種導入方式:
如果日志數據在 Kafka 消息隊列中,配置 Doris Routine Load 可從 kafka 中實時拉取數據。
如果之前使用了 Logstash 等工具將日志寫入 Elasticsearch,可以選擇配置 Logstash 通過 HTTP 接口將日志寫入到 Doris 中。
如果是自定義的寫入程序,也可以通過 HTTP 接口將日志寫入到 Doris 中。
Kafka 導入
將 JSON 格式的日志寫入 Kafka 消息隊列,創建 Kafka Routine Load,讓 Doris 從 Kafka 中主動拉取數據。示例如下,其中property.*配置是非必須的:
--準備好kafka集群和topiclog_topic --創建routineload,從kafkalog_topic將數據導入log_table表 CREATEROUTINELOADload_log_kafkaONlog_db.log_table COLUMNS(ts,clientip,request,status,size) PROPERTIES( "max_batch_interval"="10", "max_batch_rows"="1000000", "max_batch_size"="109715200", "strict_mode"="false", "format"="json" ) FROMKAFKA( "kafka_broker_list"="host:port", "kafka_topic"="log_topic", "property.group.id"="your_group_id", "property.security.protocol"="SASL_PLAINTEXT", "property.sasl.mechanism"="GSSAPI", "property.sasl.kerberos.service.name"="kafka", "property.sasl.kerberos.keytab"="/path/to/xxx.keytab", "property.sasl.kerberos.principal"="xxx@yyy.com" );
創建好 Routine Load 后,可以通過SHOW ROUTINE LOAD查看運行狀態。更多使用說明請參考 https://doris.apache.org/zh-CN/docs/dev/data-operate/import/import-way/routine-load-manual。
Logstash 導入
在營收信貸業務過程中,我們會對潛在客戶進行廣告投放,通過自動獲取用戶行為日志數據,分析信貸需求來加強營銷活動、提升獲客效果,達到精準投放的目的。我們借助 Stream Load 自定義的日志采集工具收集用戶在小程序或者 App 中的訪問日志
配置 Logstash 的 HTTP Output,將數據通過 HTTP Stream Load 發送到 Doris。
1.logstash.yml配置 Batch 攢批條數和時間,用于提升數據寫入性能
pipeline.batch.size: 100000 pipeline.batch.delay: 10000
2.testlog.conf日志采集配置文件中增加一個 HTTP Output、URL 配置Doris 的 Stream Load 地址。
目前因為 Logstash 不支持 HTTP 跳轉,需要配置 BE 地址,不能用 FE 地址。
Headers 中 Authorization 是http basic auth,用命令echo -n 'username:password' | base64來計算。
Headers 中load_to_single_tablet參數能夠減少導入的小文件。
output {
http {
follow_redirects => true
keepalive => false
http_method => "put"
url => "http://172.21.0.5:8640/api/logdb/logtable/_stream_load"
headers => [
"format", "json",
"strip_outer_array", "true",
"load_to_single_tablet", "true",
"Authorization", "Basic cm9vdDo=",
"Expect", "100-continue"
]
format => "json_batch"
}
}
自定義程序導入
參考下面的方式通過 Http Stream Load 接口導入數據到 Doris,關鍵點如下:
使用basic auth進行 HTTP 鑒權,用命令echo -n 'username:password' | base64來計算
設置http header "format:json",指定數據格式為 JSON
設置http header "read_json_by_line:true",指定每行一個 JSON
設置http header "load_to_single_tablet:true",指定一次寫入一個分桶
目前建議寫入客戶端一個 Batch 100MB~1GB,后續版本會通過服務端 Group Commit 降低客戶端 Batch 大小
curl --location-trusted -uusername:password -H"format:json" -H"read_json_by_line:true" -H"load_to_single_tablet:true" -Tlogfile.json http://fe_host:fe_http_port/api/log_db/log_table/_stream_load第三步:查詢
Doris 支持標準 SQL,可以通過 MySQL客 戶端或者通過 JDBC 等方式連接到集群,然后執行 SQL 進行查詢。
mysql-hfe_host-Pfe_mysql_port-uroot-Dlog_db
下面是日志分析場景中,常見的幾種查詢。
查看最新的 10 條數據
SELECT*FROMlog_tableORDERBYtsDESCLIMIT10;
查詢 clientip 為 '8.8.8.8'的最新 10 條數據
SELECT*FROMlog_tableWHEREclientip='8.8.8.8'ORDERBYtsDESCLIMIT10;
檢索 request 字段中有 error 或者 404 的最新 10 條數據,MATCH_ANY 是 Doris 全文檢索的 SQL 語法關鍵字,匹配參數中任意一個關鍵字
SELECT*FROMlog_tableWHERErequestMATCH_ANY'error404'ORDERBYtsDESCLIMIT10;
檢索 request 字段中有 image 和 faq 的最新 10 條數據,MATCH_ALL 是 Doris 全文檢索的 SQL 語法關鍵字,匹配參數中所有的關鍵字
SELECT*FROMlog_tableWHERErequestMATCH_ALL'imagefaq'ORDERBYtsDESCLIMIT10;
Apache Doris 針對日志場景進行了多項優化,最終達到存儲空間節省超 80% 、寫入速度是 Elasticsearch 的 5 倍、查詢性能是 Elasticsearch 的 2.3 倍。在冷熱數據分層功能加持下,整體相較 Elasticsearch 實現 10 倍以上的性價比提升。這些都表明,Apache Doris 已經足夠支撐各企業構建新一代日志系統。
后續倒排索引還會增加對 JSON、Map 等復雜數據類型的支持。而 BKD 索引可以支持多維度類型的索引,為未來 Doris 增加 GEO 地理位置數據類型和索引打下了基礎。與此同時 Apache Doris 在半結構化數據分析方面還有更多能力擴展,比如豐富的復雜數據類型(Array、Map、Struct、JSON)以及高性能字符串匹配算法等,這些將滿足更加豐富的日志應用場景。
最后,如果該文章所述符合您的使用場景,歡迎大家下載 Apache Doris 2.0 版本(https://doris.apache.org/download)進行測試使用
責任編輯:彭菁
-
DSL
+關注
關注
2文章
58瀏覽量
38245 -
數據
+關注
關注
8文章
6715瀏覽量
88318 -
存儲
+關注
關注
13文章
4126瀏覽量
85285 -
API
+關注
關注
2文章
1461瀏覽量
61502 -
日志系統
+關注
關注
0文章
7瀏覽量
6987
原文標題:如何基于Apache Doris構建新一代日志分析平臺|解決方案
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論