 細說SPI主機發送性能最大化實現方案
細說SPI主機發送性能最大化實現方案
一、背景
在《先楫hpm6000的SPI外設使用四線模式操作讀寫華邦flash》一文中介紹了先楫SPI外設是為flash器件而生的控制器,但是樓主在該篇文章讀寫flash的頁是用的poll輪詢讀寫spi fifo的接口,并沒用DMA來進行加速優化。本篇就是基于SPI配合DMA實現理論速度性能。
二、問題點
(一) SPI FIFO poll阻塞發送無法發揮SPI理論速度性能
使用spi poll阻塞的時候,雖然能實現數據的完整傳輸,但是傳輸的時間并不能達到理想傳輸速度,比如SPI四線模式下,30M的SPI SCLK時鐘,理論可以達到15MB/S速度。但實際測量當中并未達到該性能。從邏輯分析儀看到,發送flas一頁數據,也就是256字節,從開始傳輸到結束傳輸的時間需要37.034us,合計為6.91MB/S,與理論速度相差了2到3倍的距離。
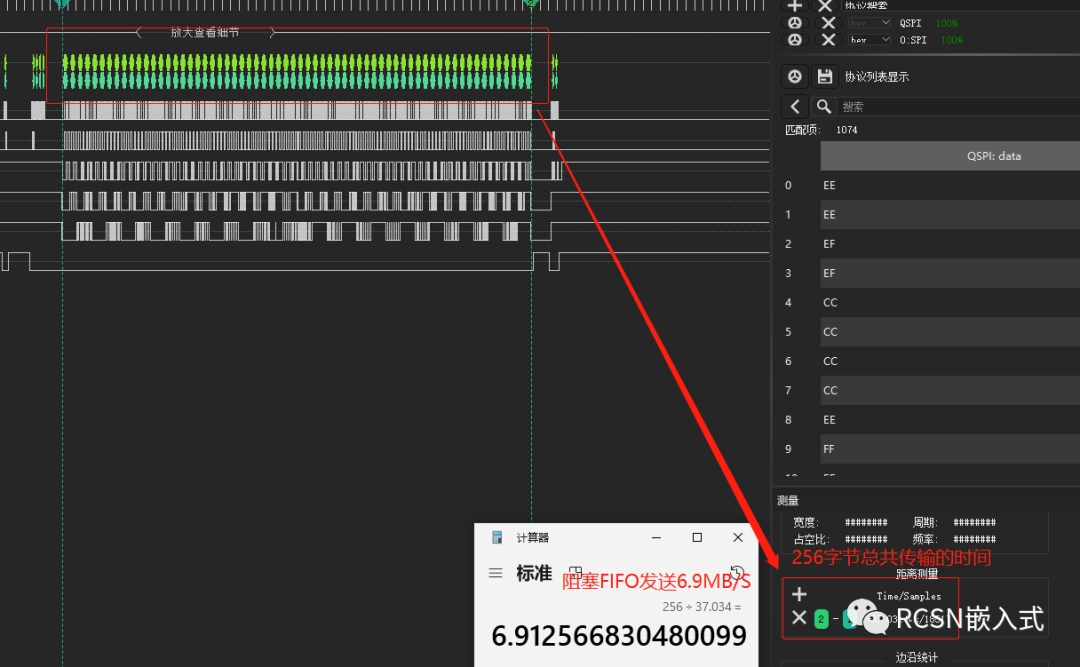
從波形上看,導致這個速度達不到原因就在于,每個字節之間存在了一定的間隔時間,這些間隔的累積導致傳輸時間變長,導致總的時間變長,進而速度遠遠跟不上。
(二)使用了DMA仍然有SPI SCLK時鐘不連續問題
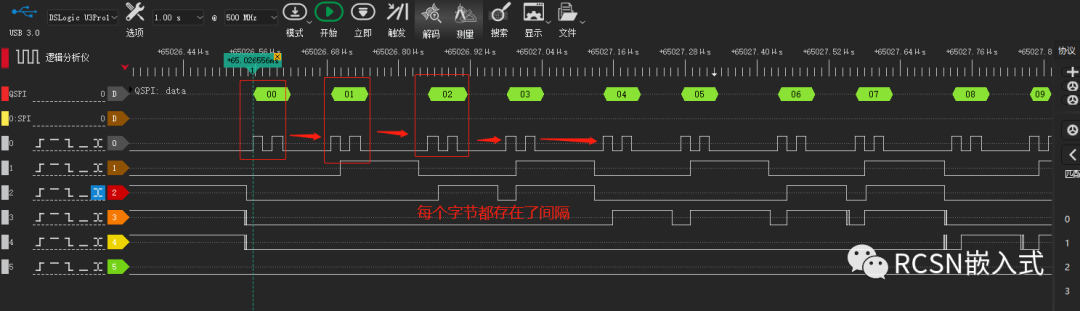
從(一)的問題可以看出,要想達到理論速度,必須消除每個字節的SCLK間隔,縮短傳輸時間。這時候需要DMA來加持速度性能,但實際上,在使用了相關配置之后,速度雖然有些提升,但還是存在些許間隔產生。
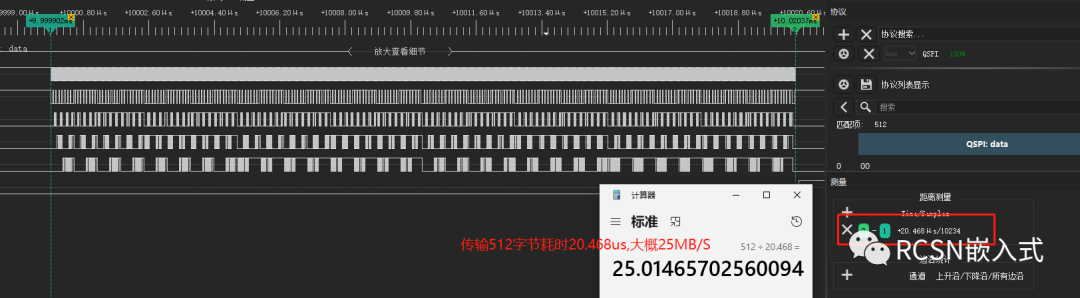
在這里的例子驗證條件是:SPI SCLK時鐘頻率為50M,主機發送512字節。理論傳輸速度可以25MB/S.從邏輯分析儀可看到,間隔有所縮短,但依然存在字節間隔。512字節傳輸需要45.97us,合計為11.173MB/S。距離25MB/S也有兩倍的差距。
三、解決問題
在二問題的所有描述當中,速度達不到理想性能,歸根到底是字節之間產生間隔累積形成。
所以我們的問題解決點是:再配合DMA,進行其他優化。達到理想速度性能。
(一) 使用AHB SRAM(內存32KB空間)作為數據交互RAM。
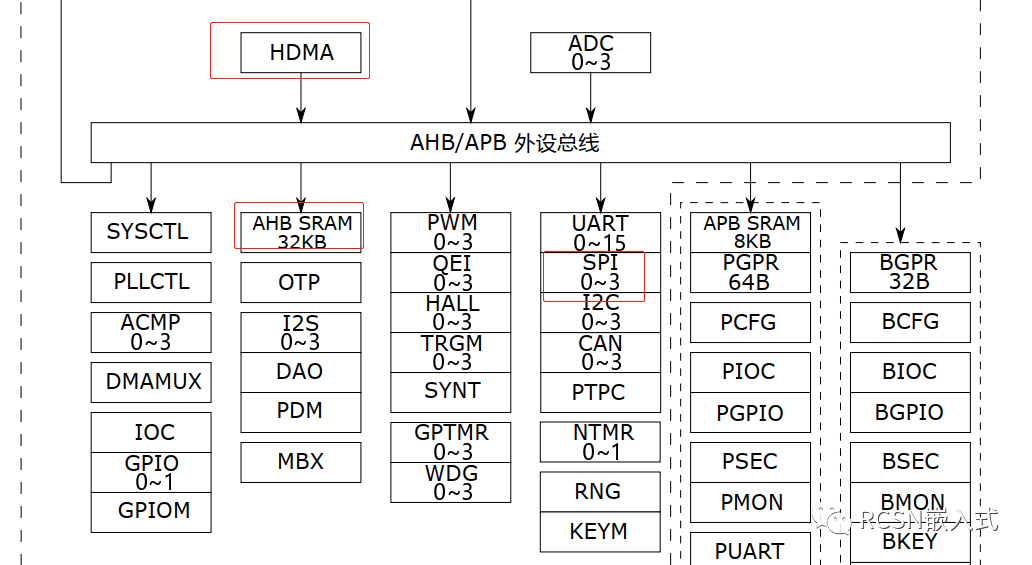
在HPM6000系列中,AHB/APB外設總線連接了一個內存為32KB空間的AHB SRAM,與之同時連接的也有DMA控制器之一HDMA。
從官方文檔可知,AHB SRAM和HDMA以及SPI外設同樣位于AHB/APB外設總線中,AHB SRAM是專門給HDMA進行低延時訪問的內存,也是SPI進行DMA低延時傳輸保證。
在上面的DMA搬運中,待發送的數據放在AXI SRAM中。那么把這發送的數據放在AHB SRAM,看下會不會有所提升。

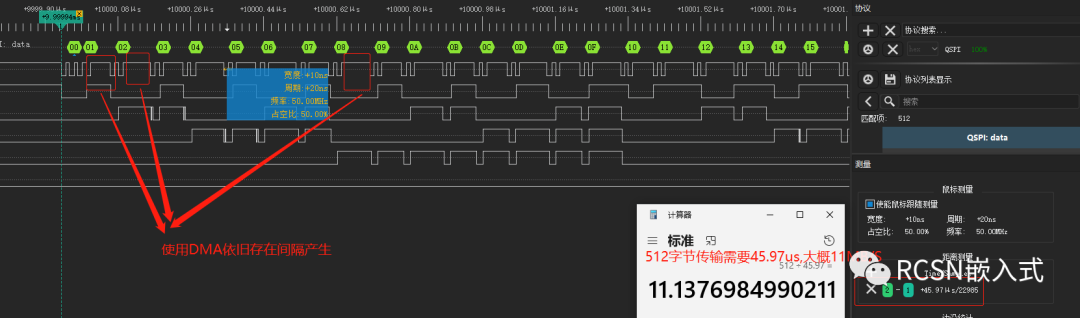
從以下邏輯分析儀結果看出,傳輸512字節,相比放在AXI_SRAM中,在AHB_SRAM只需要22.97us,縮短了23us, 合計22MB/S,提高了兩倍速度性能。當仍與25MB/S理想速度有些許差距。
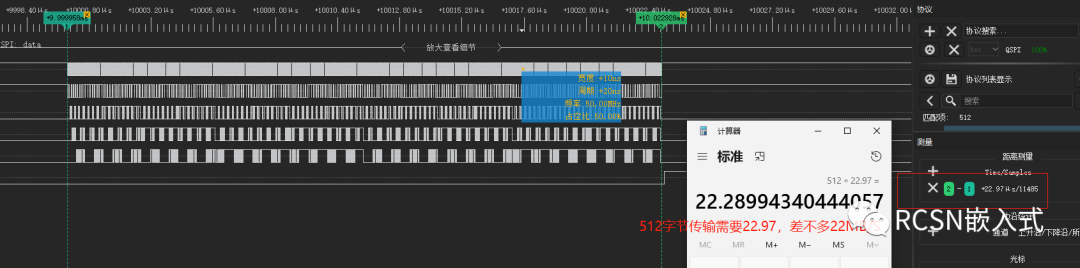
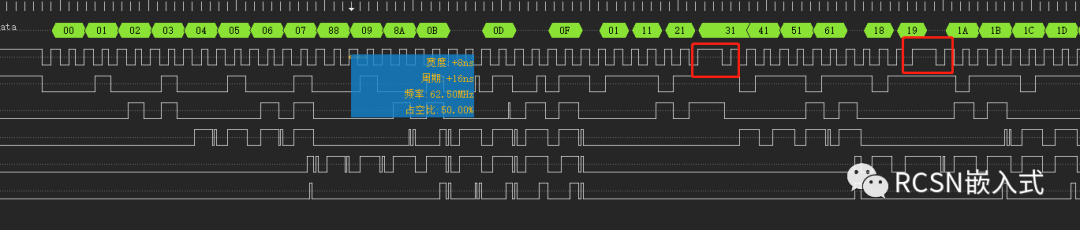
通過放大波形查看,有些字節依然產生間隔,這也是導致速度沒達到理想速度的原因。
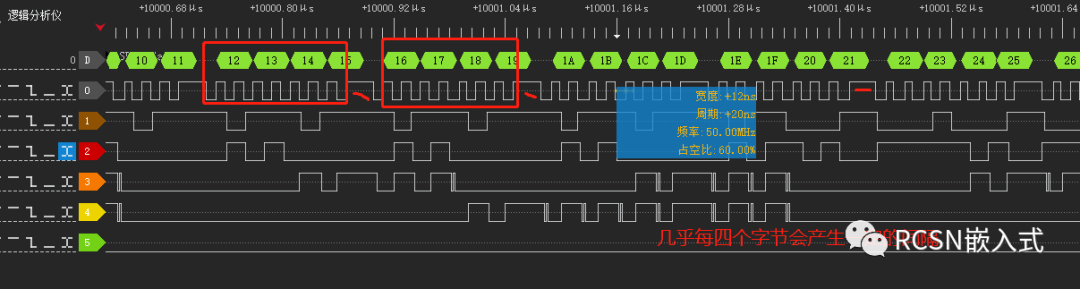
(二)使用DMA的burst突發傳輸
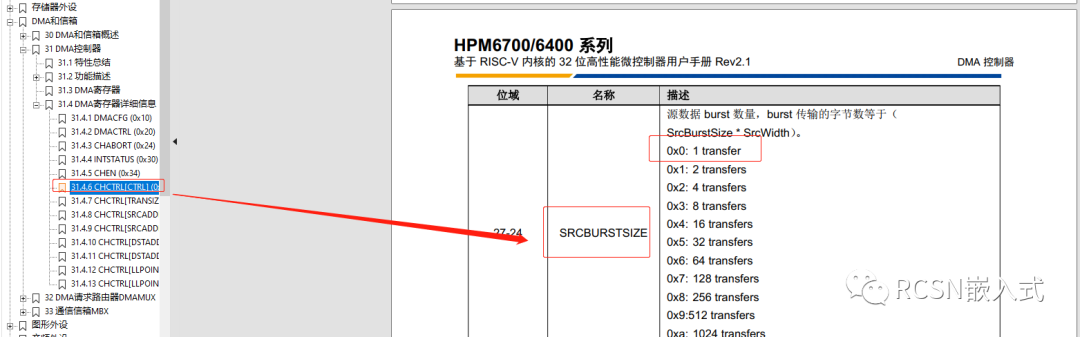
先楫的DMA,對于源地址數據來說,支持突發傳輸。例如傳輸位寬為8,設置burst數量為4,那么就是相當一次DMA請求設置了4個節拍,連續傳輸4個字節。是單次傳輸的4倍效率。在這里來說,待發送的數據就是源地址數據。
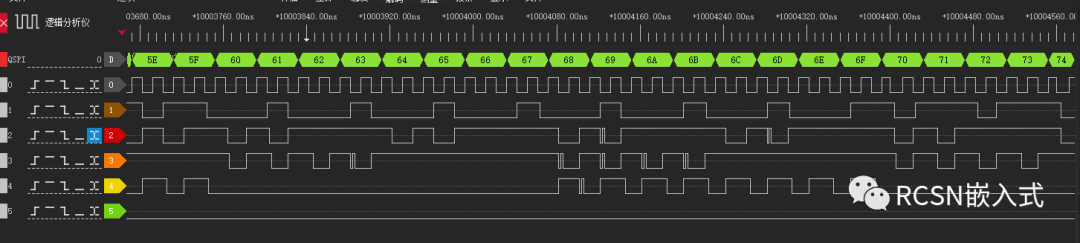
先楫的SPI控制器有四個字的FIFO數據空間,每個FIFO是32位。SPI請求DMA搬運是通過發送FIFO閾值請求。從效率上來看,最好是一次請求中能把FIFO數據全部搬運。從上面的優化流程來看,都設置為了默認,TX FIFO閾值設置為了0,也就是只要TXFIFO有一個為空就請求一次,DMA的源數據burst數量為0,也就是相當設置了1個節拍的突發傳輸,傳輸寬度為8位,一次DMA請求就塞給一次FIFO,等待FIFO完全塞滿后這時候沒法請求,所以會導致一次周期的間隔,當DMA收到請求后連這樣能解釋上面為何每隔四個字節會產生間隔的原因。
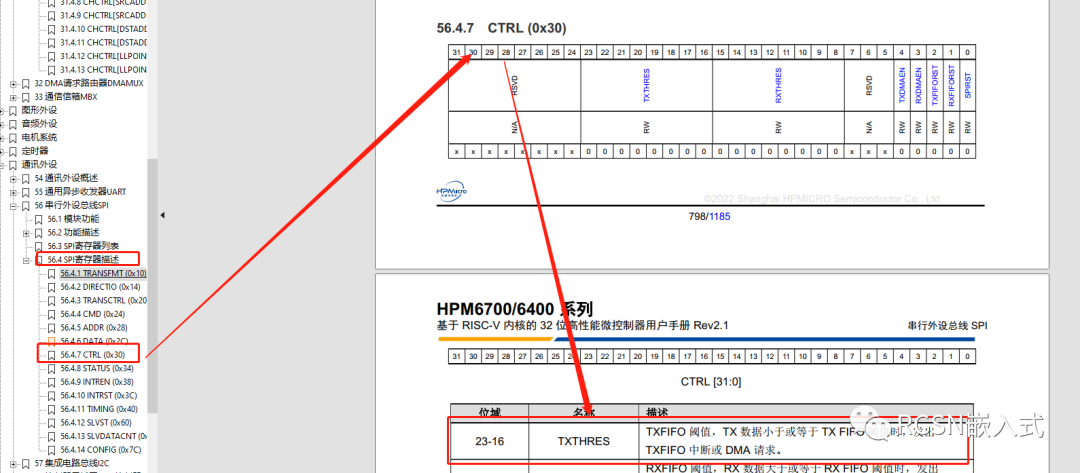
所以這里我們可以SPI的TXFIFO閾值為3,當出現一個空位的時候就請求一次,設置burst數量為2,也就是四個字節,一次請求搬運四個字節。通過邏輯分析儀可看到:
配合(一)的方案,傳輸512字節,只需要20.468us,合計為25MB/S左右,接近了理想速度性能了。
放大波形查看,也能看到SCLK時鐘連續了。
(三)壓榨性能(使用SPI的字節合并merge功能)
先楫官方手冊說明的是SPI時鐘可以80M,保守是40M。在四線模式下,SPI時鐘SCLK為80M,相比單線來說可以提高四倍性能傳輸,也就是可以達到40MB/S。
但是在實際操作的時候,分頻SPI SCLK頻率到66M,又出現了SCLK時鐘不連續的情況,導致與理想速度不符合。
仔細翻下官方手冊,可以知道SPI有個寄存器是TRANSFMT,有一個位是DATAMERGE,對于描述如下:
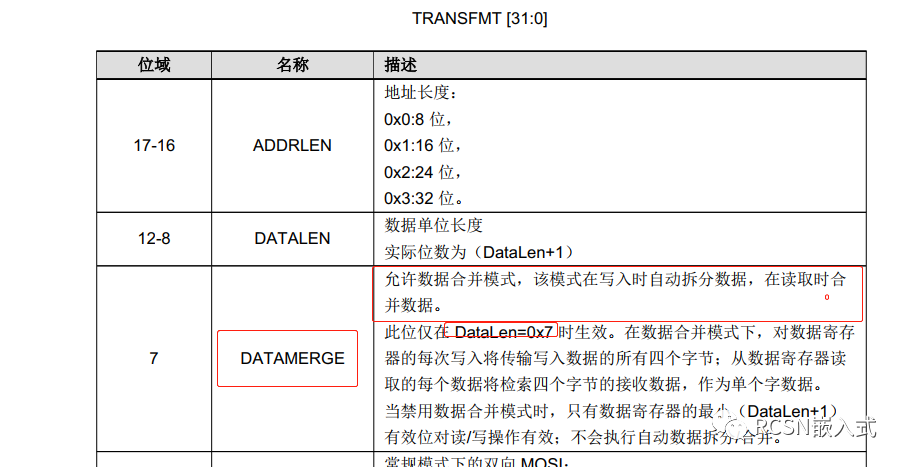
特別說明的是,由于SPI的數據FIFO是32位,這個功能只在數據單位長度為8位的時候有效,而且合并的數據量需要以四的整數倍。如此來說,在配置DMA的時候,傳輸寬度可以從8位變到32位,傳輸的帶寬也能提高了四倍。那么我們這樣配置下,邏輯分析儀結果如下:
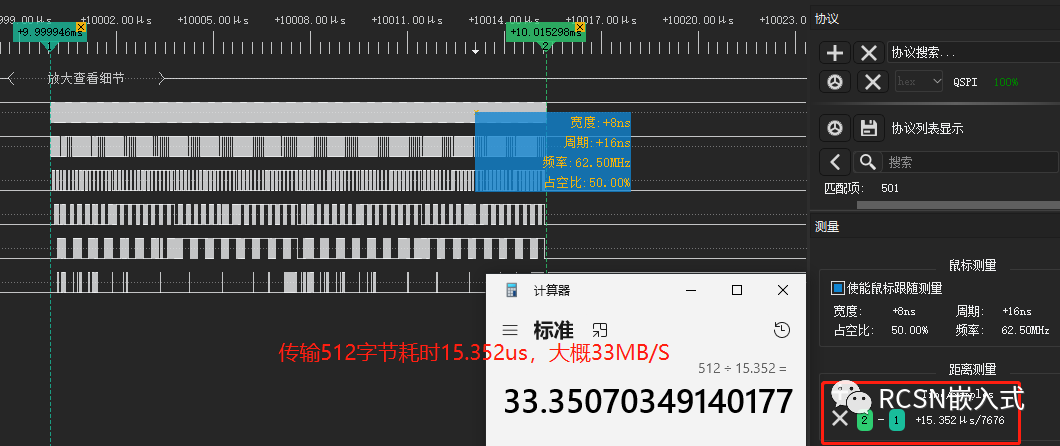
在66M的SPI SCLK時鐘下,邏輯分析儀抓到的SCLK能保持連續,并且數據能對得上。512字節耗時15.352us,合計33MB/S左右,與理論速度33MB/S接近。
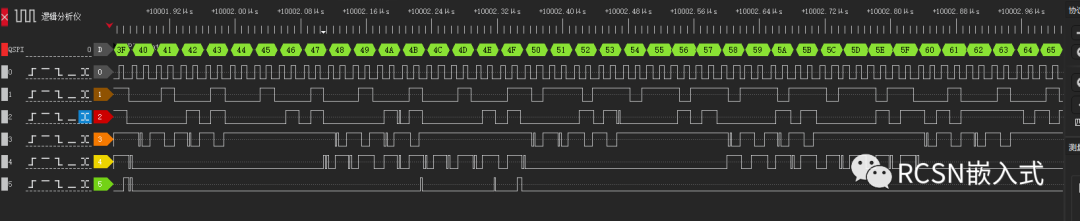
80M的SPI SCLK頻率,傳輸512字節,耗時12.794us,合計40MB/S左右,也能滿足預期40MB/S速度。

SCLK波形也能保持連續。
四、號外(單線SPI總線可以達到120M)
四線模式既然能達到80M,那么樓主想試下80M的單線,也是沒問題的,效果如下:

再嘗試一把,把SPI SCLK分頻到120M,只是稍微有點間隔,但單線SPI也是沒問題的。

五、總結
對于先楫這個SPI外設來說,配合DMA,SPI的數據FIFO以及相關SPI配置,能達到手冊描述的性能。無論是四線模式還是二線模式還是單線模式,都能到達80M的SPI時鐘性能。
對于SCLK不連續的問題在于DMA搬運和SPI傳輸不同步造成,導致傳輸間隔中斷,特別是SPI頻率越來越高的情況下。解決同步問題就不會有SCLK不連續的問題存在。
我們始終相信開發者共創的力量。先楫社區堅持開源共享、互惠互利,貼近每一個開發者,一步一個腳印,一點一滴積累,為成為更好的我們而不斷努力。
-
主機
+關注
關注
0文章
958瀏覽量
34860 -
時鐘
+關注
關注
10文章
1673瀏覽量
130961 -
SPI
+關注
關注
17文章
1669瀏覽量
90736 -
dma
+關注
關注
3文章
552瀏覽量
99935
發布評論請先 登錄
相關推薦
液冷充電槍線最大化提高充電效率
Renesa RA如何使用SPI來實現高速比特流的發送
請問esp32c3 spi slave從機端不能實時發送數據嗎?
STM32作為主機,通過SPI進行數據交互,發送數據的時候出現亂碼怎么解決?
PCB設計優化指南:如何最大化EMC性能效果?
STM32G070 SPI主機只接收模式關閉SPI使能后為什么還有時鐘輸出?
在SPI雙機通信中,時鐘信號由主機提供,那么從機向主機發送數據時需要時鐘信號嗎?
虹科分享 | 實現網絡流量的全面訪問和可視性——Profitap和Ntop聯合解決方案
用于并行采樣的EVADC同步轉換,如何在最大化采樣率的同時最大限度地減少抖動?
stm32 usb 主機發送 pid in的原理和實現方法
使用GaN HEMT設備最大化OBCs的功率密度






 工商網監
工商網監
評論