 如何提升跑Calibre效率呢?
如何提升跑Calibre效率呢?
Siemens的Calibre是業內權威的版圖驗證軟件,被各大Foundry廠廣泛認可。用戶可以直接在Virtuoso界面集成Calibre接口,調用版圖驗證結果數據,使用起來極為方便。
今天,我們就來聊聊這款軟件。
版圖驗證是芯片設計中非常重要的一環,一共包括三個環節。
DRC(Design Rule Check):檢查版圖是否符合Foundry廠的制造工藝規則,確保芯片能被正確生產出來;
LVS(Layout Versus Schematic):版圖工程師需要將畫好的版圖與原理圖對比,確保兩者所有連接保持一致;
寄生參數提取(Parasitic Extraction):將版圖中的寄生參數提取出來,在Virtuoso中反饋結果,前端工程師會進行后仿驗證,重新評估電路特性并進行修改,保證流片正確。
這三個環節分別由Calibre的DRC、LVS、PEX三種工具來完成。
Calibre任務典型特性
重內存,可拆分,適合暴力堆機器
Calibre任務有兩大特性:
1、重內存需求,2T或4T的超大型內存機器都有可能登場
版圖文件很大,需要處理的數據量非常大,但本身的邏輯判斷并不復雜,所以通常不剛需高主頻機型,但要求多核、大內存的機器。CPU與內存的比例通常能達到1:4或1:8,極端情況下這個比例會更高,2T或4T的超大型內存機器都有可能登場。
我們在下面兩篇文章里仔細盤過模擬&數字芯片設計全流程的業務場景、常用EDA工具、資源類型、算力需求、典型場景:
芯片設計五部曲之一 | 聲光魔法師——模擬IC
芯片設計五部曲之二 | 圖靈藝術家——數字IC
2、可拆分,無關聯,適合暴力堆機器
我們在模擬這篇文里寫過版圖驗證就像是一個“大家來找茬“的游戲。
在運行任務的時候,Calibre會把版圖切分成相互沒有邏輯關系的塊狀分區,這些分區之間彼此沒有相關性,互不干擾,所以可以同時進行。
切得越細,同時檢查的人更多,效率就越高。
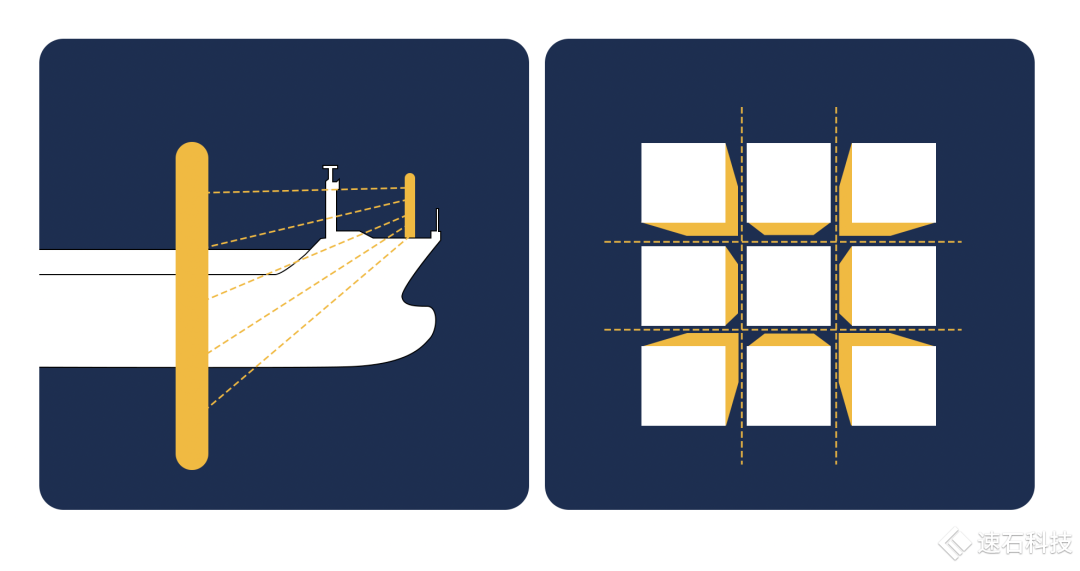
三體里的切法大家還記得吧,一字橫切。
而芯片只能豎著切,可以十字切法。橫切會影響到芯片層與層之間的連接關系。
暴力堆機器也是有技術含量的
1、 首先,要有光,你得有大內存的機器
我們的全球資源池可以根據用戶需求在全球范圍內調度海量云端異構資源。GPU、TPU、FPGA,要啥都有。
其中,FCC-B產品提供準動態資源池,擁有行業特需的大內存機型,具有較低的整體擁有成本。而且,可以擴展到FCC-E使用彈性資源。
總之,大內存的機器,沒有問題。
那么,萬一不是一直不夠,是偶爾不夠怎么辦呢?
我們有一個小技巧,專門應用這種內存峰值場景。
Swap,交換分區,就是在內存不夠的情況下,操作系統先把內存中暫時不用的數據,存到硬盤的交換空間,騰出內存來讓別的程序運行。
比如跑一組Calibre任務需要10小時,其中9個小時的內存使用量都在200G左右,只有1個小時達到了260G。
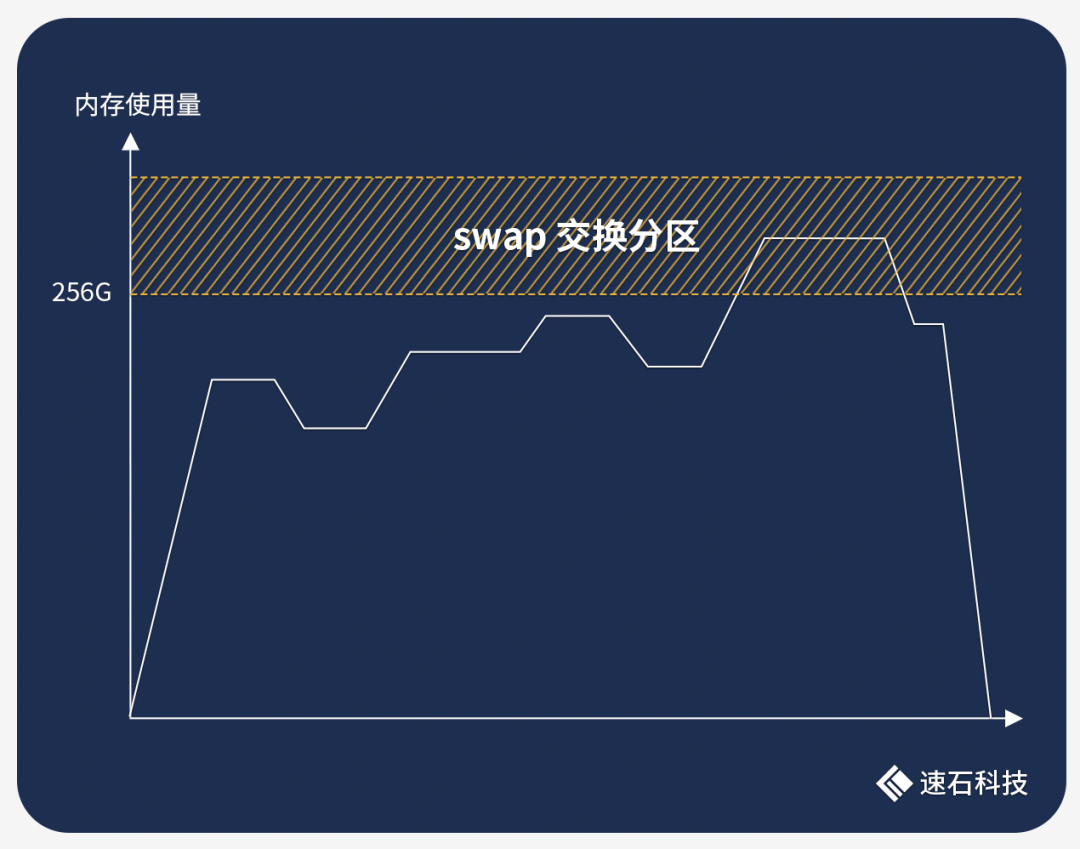
如果選擇256G內存的機型配置,任務必崩無疑。
但要是為了這1小時不到10G的內存溢出而全程使用512G的配置,成本翻倍,未免有點太不劃算了。
使用Swap交換分區就可以無縫填補這一空缺,非常匹配這種內存峰值場景。
Swap的具體使用案例,戳這篇:Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
注意:此方法不適合長期使用,磁盤的速度和內存相比慢了好幾個數量級,如果不停讀寫 Swap,對系統整體性能有影響。
2、 怎么把這些機器組隊管理起來?
有了機器,下一步當然是要把它們利用起來。
Calibre默認支持單機多核并行跑任務,這意味著只要機器足夠大,就可以同時處理很多任務。
但是,當你的大機器不夠多,或者根本拿不到大機器的時候,就很苦惱了。
我們的方法是:將所有機器組成一個集群——多機多核的方式同時跑多個任務。
關于單機、單核、單任務、多任務、集群化、并行化進一步的定義與區別,可以看這篇:揭秘20000個VCS任務背后的“搬桌子”系列故事
集群自動化管理,少量大機器需要,大量小機器就更需要了。
為啥?
理由一,能方便地自動化運維整個集群
比如軟件安裝配置、資源監控、集群管理等工作,是需要IT一臺臺機器去逐一手動操作,還是鼠標點幾下就可以完成?
理由二,能快速方便地分配業務,提高資源利用率
比如,臨時需要將一批機器從團隊A劃撥給團隊B使用,有沒有什么辦法可以讓IT快速方便地進行配置?
比如,因為資源使用的不透明和缺乏有序管理,會出現不同人對同一資源的爭搶,任務排隊等現象。同時,你會發現資源利用率還是不高。
3、怎么讓機器自動化干活,不用人操心?
自動化干活可太有必要了。
否則,那么多任務,那么多機器,需要多少雙手和眼睛才能忙得過來?
來,我們給你“手”和“眼睛”。
首先是我們的“手”——Auto-Scale功能。
來看一下本地手動跑任務與Auto-Scale自動化跑任務的區別:
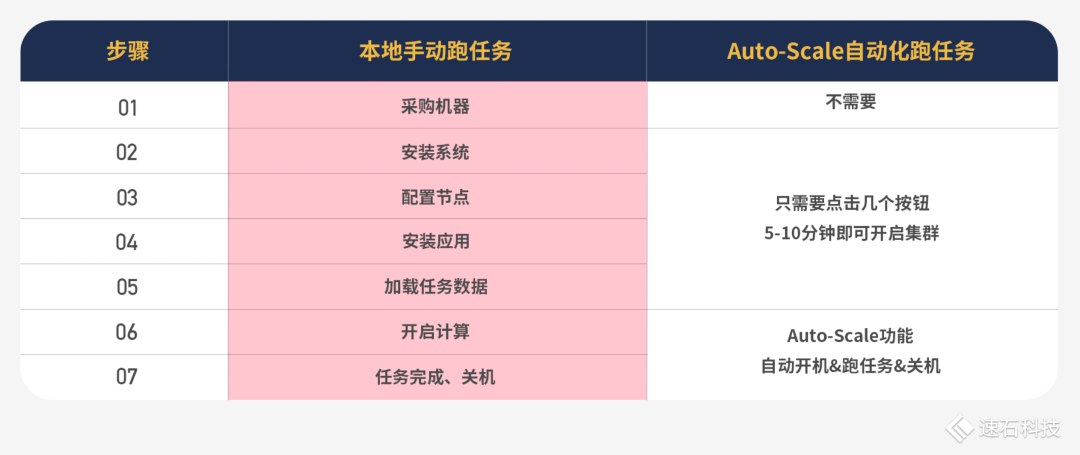
基于我們自主研發的調度器——Fsched,Auto-Scale自動伸縮功能自動化創建集群,自動監控用戶提交的任務數量和資源需求,動態按需地開啟與關閉所需算力資源,做到分鐘級彈性伸縮,在提升效率的同時有效降低成本。
更多療效,戳這篇:Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
有了“手”干活,還得有“眼睛”盯著防止出錯。
我們能多維度監控任務狀態,提供基于EDA任務層的監控、告警、數據統計分析功能與服務。
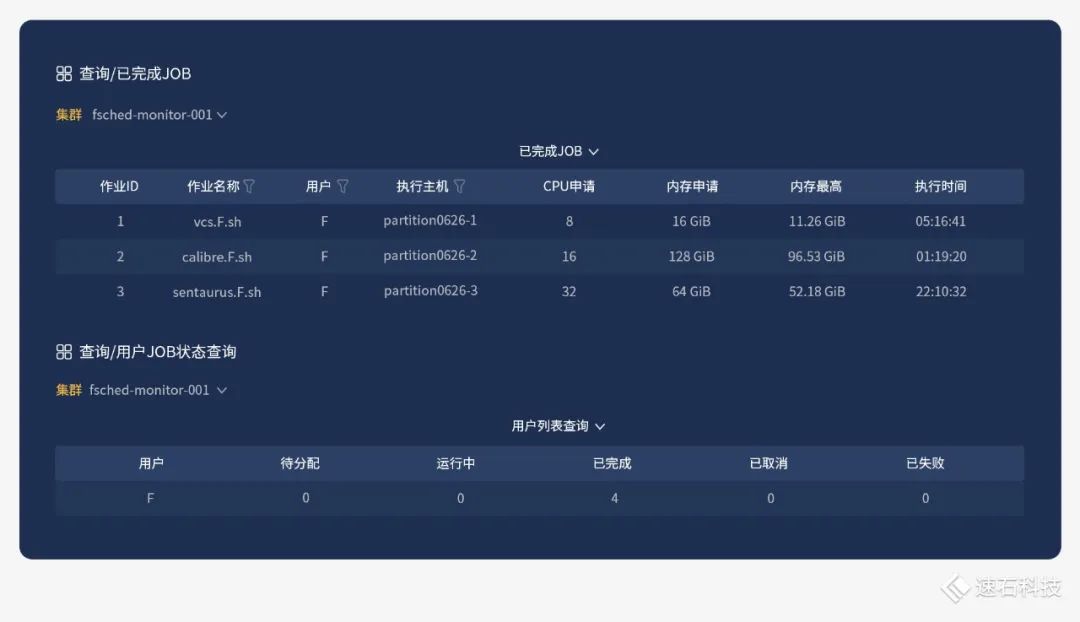
如果沒有這雙“眼睛”,可能出現哪些問題?戳這篇:【案例】95后占半壁江山的浙桂,如何在百家爭鳴中快人一步
未來我們還會有一篇文章專門討論EDA領域基于業務的監控功能,敬請期待哦~
你看,不僅可以自動化跑任務,還能時刻幫你盯著任務是否出錯。
來,我們小暴力一下
先說結論:
我們在單臺大機器和多臺小機器組合場景下分別跑了同一組Calibre任務。
單臺大機器場景下,隨著核數的增加,任務耗時呈現明顯的線性下降關系,整體性能曲線非常貼近基準線(單機核數有上限,本次實證中,我們使用的最大單機為128核,并根據32核、64核、128核的耗時規律預估了256核單機的耗時數據,僅供參考)。
多臺小機器組合場景下,隨著機器數量的翻倍,任務耗時同樣線性下降,但在后期倍數關系上有所損耗,多機性能曲線略低于基準線和單機性能曲線。
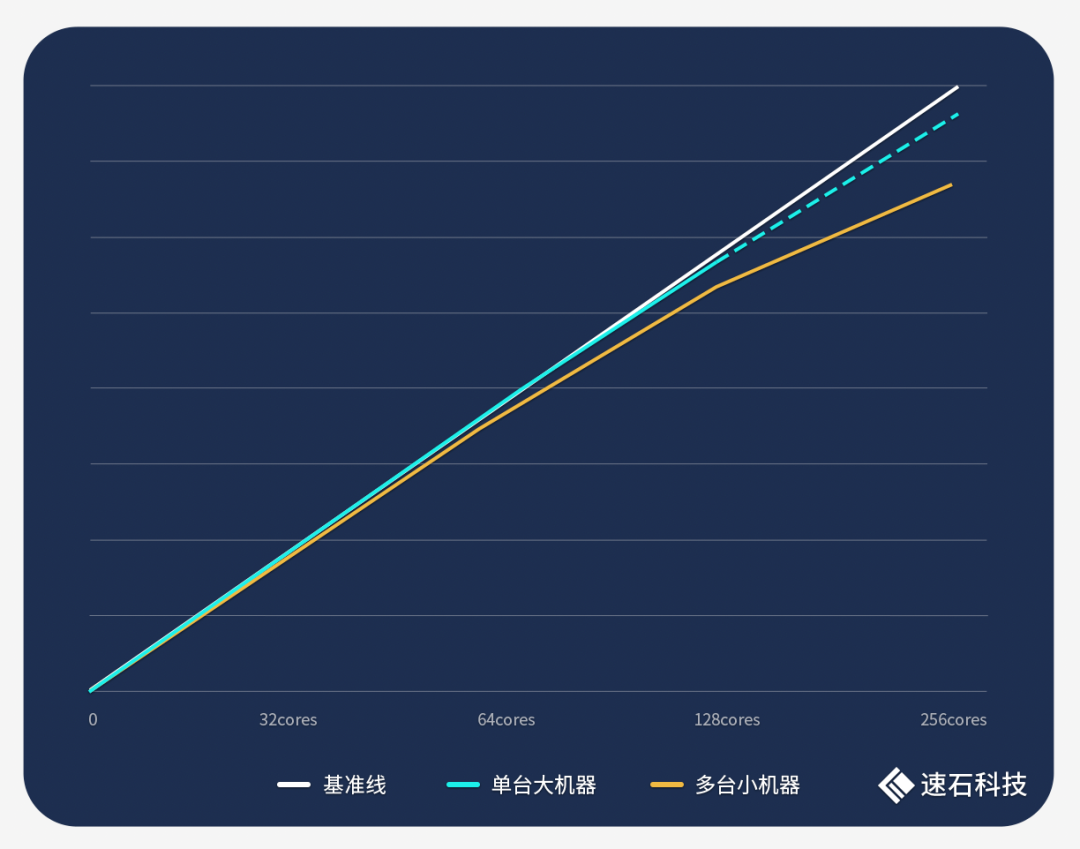
實證過程:
1、使用fastone云平臺調度32核、64核、128核單機分別運行一組Calibre任務,耗時分別為14小時57分49秒、7小時30分28秒、3小時50分11秒;
2、按上條實證數據,預估使用fastone云平臺調度256核單機運行一組Calibre任務的耗時為1小時58分6秒;
3、使用fastone云平臺調度2、4、8臺32核機器分別運行一組Calibre任務,耗時分別7小時43分51秒、4小時6分14秒、2小時15分34秒。
還有大家關心的Intel第四代機器
我們也搞來跑了一下
在上一節中,我們使用的均為第三代英特爾至強可擴展處理器,而在2023年1月11日,英特爾正式推出了第四代至強可擴展處理器。
我們立馬搞來跑了一遍,為了對比參照,我們還拉上了第二代和第三代,并且把核數都按比例換算為48核。
實證過程:
1、使用fastone云平臺調度48核第二代英特爾處理器運行一組Calibre任務,耗時10小時46分26秒;
2、使用fastone云平臺調度48核第三代英特爾處理器運行一組Calibre任務,耗時9小時56分13秒,相比第二代提升7.77%;
3、使用fastone云平臺調度48核第四代英特爾處理器運行一組Calibre任務,耗時8小時18分43秒,相比第三代提升16.35%,比第二代提升22.85%。
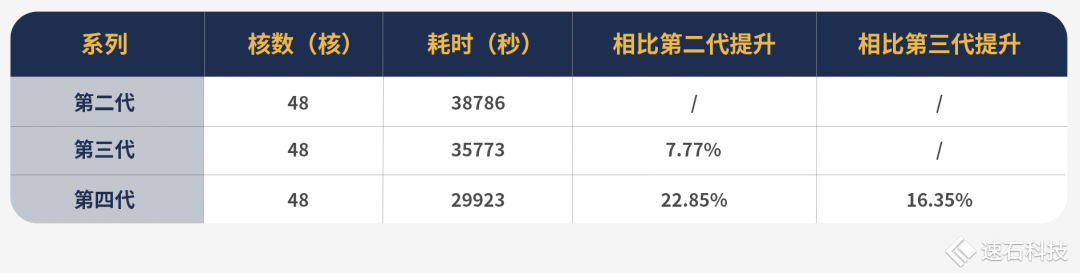
可以看到每一代都有提升,且型號越新,提升幅度越大,三代比二代提升了7.77%,四代比三代提升了16.35%。
而在價格上,目前四代和三代的類似機型換算一下,幾乎是相同的。
實證小結
1、Calibre DRC/LVS/PEX不剛需高主頻機型,但要求多核、大內存的機器,任務可拆分,適合暴力堆機器;
2、fastone云平臺的全球動態資源池、集群自動化管理能力、自動化跑任務并監控告警的功能可完美匹配Calibre的需求;
3、隨著計算資源的提升,Calibre的任務耗時呈現明顯的線性關系,其中單機整體性能曲線非常貼近基準線,多機效果后期會略有折損;
4、最新型號的處理器可以大幅提升Calibre的效率,可根據項目周期與實際預算綜合考量機型配置。
審核編輯:劉清
-
芯片設計
+關注
關注
15文章
1004瀏覽量
54815 -
DRC
+關注
關注
2文章
148瀏覽量
36130 -
LVS
+關注
關注
1文章
35瀏覽量
9922 -
TPU
+關注
關注
0文章
138瀏覽量
20700 -
FPGA開發板
+關注
關注
10文章
122瀏覽量
31485
原文標題:沒有大內存機器,如何提升跑Calibre效率?
文章出處:【微信號:OpenIC,微信公眾號:OpenIC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Mentor工具簡介Calibre物理驗證系列
請問FPGA Editor如何提升設計效率?
calibre2015和lisence哪一個版本更好?
calibre跑完后調不出RVE視窗的問題該如何去解決?
基于calibre的MIC總線控制器專用集成電路版圖檢查
Laker & Calibre Bandgap 實例教程
Mentor Graphics 推出針對 Tanner 模擬/混合信號 IC 設計環境的 Tanner Calibre One 驗證套件
EDA明導國際Calibre平臺已支持最新的TSMC 12FFC制程設計
100分的Calibre只發揮了60分的作用?

到底誰能提升Calibre的效率?

西門子推出創新的Calibre DesignEnhancer軟件
如何在Virtuoso界面集成Calibre接口呢?







 工商網監
工商網監
評論