") 英偉達又推超級芯片!新一代GH200 Grace Hopper超級芯片炸場
英偉達又推超級芯片!新一代GH200 Grace Hopper超級芯片炸場
北京時間8月8日23:00,在全球首屈一指的計算機圖形和交互技術會議SIGGRAPH上,英偉達CEO黃仁勛一襲黑皮衣,以雷霆萬鈞之勢再度登臺,對臺下數(shù)千名觀眾表示,“生成式人工智能時代即將到來,如果你相信的話,那就是人工智能的iPhone時代。”
在隨后近一個半小時的演講中,黃仁勛宣布了英偉達的最新技術突破:
硬件方面,黃仁勛推出了新一代GH200 Grace Hopper超級芯片,將搭載全球首款HBM3e處理器,預計于2024年第二季投產(chǎn),專為加速計算和生成式 AI 時代而打造。同時,還重磅發(fā)布了功能強大的新型RTX工作站、三款全新桌面工作站Ada Generation GPU,以及搭載全新NVIDIA L40S GPU的全新 NVIDIA OVX服務器。
軟件方面,為了推動人工智能部署,英偉達推出了AI Workbench、AI Enterprise 4.0,以及Hugging Face等重磅武器,旨在和行業(yè)攜手,一同推動人工智能和生成式AI走向下一個浪潮尖峰。
新一代 GH200 Grace Hopper 超級芯片炸場
通常,使用人工智能模型的過程至少分為兩個部分:訓練和推理。訓練部分,是使用大量數(shù)據(jù)來訓練人工智能系統(tǒng),開發(fā)出具有特定功能的神經(jīng)網(wǎng)絡模型,動輒需要耗費數(shù)月時間才能完成;推理部分,則是將新的數(shù)據(jù)輸入訓練好的模型,讓它推理出各種結論,并且?guī)缀醭掷m(xù)進行。 這兩個環(huán)節(jié)都需要高性能GPU進行支持,如果支持不到位的話,將影響大模型的精準度。
為了持續(xù)推動AI發(fā)展,早在2022年初,英偉達宣布了Grace Hopper超級芯片,即NVIDIA GH200,它將72核Grace CPU與Hopper GPU相結合,提供1 EFLOPS的AI算力和144TB的高速存儲,并于今年 5 月全面投產(chǎn)。
昨晚的SIGGRAPH大會上,也就是在這款超級芯片全面投產(chǎn)后不到三個月,英偉達推出了功能更強大的芯片版本——新一代NVIDIA GH200 Grace Hopper超級芯片,將提供卓越的內(nèi)存技術和帶寬,以此提高吞吐量,提升無損耗連接GPU聚合性能的能力,并且擁有可以在整個數(shù)據(jù)中心輕松部署的服務器設計。
“你幾乎可以在GH200上運行任何你想要的大型語言模型,它會瘋狂地進行推理。”黃仁勛說,“大型語言模型的推理成本將大幅下降。”
與當前一代產(chǎn)品相比,新一代GH200擁有基本相同的“基因”:其 72 核 Arm Neoverse V2 Grace CPU、Hopper GPU 及其 900GB/秒 NVLink-C2C 互連均保持不變。核心區(qū)別是它搭載了全球第一款HBM3e內(nèi)存,將不再配備今年春季型號的 96GB HBM3 vRAM 和 480GB LPDDR5x DRAM,而是搭載500GB的LPDDR5X以及141GB的HBM3e存儲器,實現(xiàn)了5TB/秒的數(shù)據(jù)吞吐量。
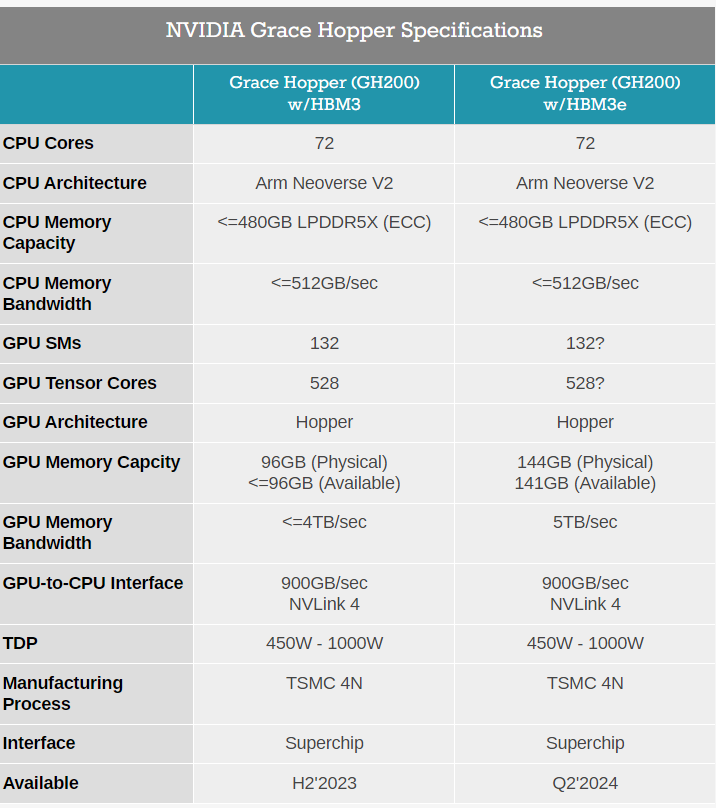
HBM3內(nèi)存 VS HBM3e內(nèi)存參數(shù)對比
英偉達表示,HBM3e內(nèi)存技術帶來了50%的速度提升,總共提供了10TB/秒的組合帶寬。能夠運行比先前版本大3.5倍的模型,并以3倍的內(nèi)存帶寬提高性能。
此外,英偉達目前正在開發(fā)一款新的雙GH200基礎NVIDIA MGX服務器系統(tǒng),將集成兩個下一代Grace Hopper超級芯片。在新的雙GH200服務器中,系統(tǒng)內(nèi)的CPU和GPU將通過完全一致的內(nèi)存互連進行連接,這個超級GPU可以作為一個整體運行,提供144個Grace CPU核心、8千萬億次的計算性能以及282GB的HBM3e內(nèi)存,從而能夠適用于生成式AI的巨型模型。
對于企業(yè)客戶,英偉達GPU訓練AI模型成本已非常昂貴,但黃仁勛仍強調(diào)其產(chǎn)品的“性價比”:同樣使用1億美元打造數(shù)據(jù)中心,可以購得8800塊x86處理器或2500套GH200,但后者的AI推理性能是前者的12倍,能效達20倍。
于是我們又聽到了黃仁勛“金牌導購”的名言:the more you buy, the more you save(買的越多,省的越多)。
據(jù)悉,英偉達計劃銷售GH200的兩種版本:一種是包含兩個可供客戶集成到系統(tǒng)中的芯片,另一種則是結合了兩種Grace Hopper設計的完整服務器系統(tǒng)。
全新的GH200這款產(chǎn)品將于2024年第二季投產(chǎn),售價暫未透露。
四款全新顯卡+新款OVX服務器:
全方面涵蓋生成式AI開發(fā)
除了適用于前沿大語言模型的GH200 ,英偉達在桌面AI工作站方面,推出了RTX 6000、RTX 5000、RTX 4500和RTX 4000四款新顯卡,以及搭載全新L40S Ada GPU的新款OVX服務器。
1
RTX 6000 Ada GPU
為提供更多的計算能力,促進生成式AI和數(shù)字化時代的開發(fā)和內(nèi)容創(chuàng)作,英偉達正在和全球制造商,包括惠普、聯(lián)想、BOXX、戴爾等,推出功能強大的新型 RTX 工作站。
新的RTX工作站提供多達4個NVIDIA RTX 6000 Ada GPU,每個GPU都配備48GB內(nèi)存(總共 192GB),單個桌面工作站可以提供高達5.8 TFLOPS 算力。
2
三款全新桌面工作站 GPU
黃仁勛還宣布推出三款全新桌面工作站Ada Generation GPU :NVIDIA RTX 5000、RTX 4500和RTX 4000,旨在為全球專業(yè)人士提供最新的 AI、圖形和實時渲染技術。
NVIDIA RTX 5000現(xiàn)已上市(售價 4,000 美元),提供32GB GDDR6內(nèi)存,NVIDIA RTX 4500 和 4000 將于今年秋季上市(售價分別為 1,250 美元和 2,250 美元),兩者都是雙槽 GPU,分別提供和24GB GDDR6內(nèi)存、20GB GDDR6內(nèi)存。
3
OVX 服務器產(chǎn)品
此外,英偉達還推出了搭載L40S GPU 的 OVX 服務器產(chǎn)品,每臺服務器最多可以裝八個L40S GPU,每個GPU有 48GB 內(nèi)存。
對于具有數(shù)十億參數(shù)和多種數(shù)據(jù)模態(tài)的復雜AI工作負載,相較于A100 Tensor Core GPU,L40S 能夠實現(xiàn)1.2倍的生成式AI推理性能和 1.7 倍的訓練性能,旨在滿足AI訓練和推理、3D 設計和可視化、視頻處理和工業(yè)數(shù)字化等計算密集型應用的需求。
軟件生態(tài)全方位部署:
讓所有人參與生成AI
除了硬件產(chǎn)品,軟件方面,英偉達推出了AI Workbench、AI Enterprise 4.0,以及Hugging Face等重磅武器:
AI Workbench是為開發(fā)人員提供了一個統(tǒng)一、易于使用的工具包,將需要用于生成式AI工作的一切打包在一起,主要是為了降低企業(yè)啟動 AI 項目的門檻。大會上,黃仁勛在強調(diào),為了推動AI技術普惠,必須讓其有可能在幾乎任何地方運行,讓所有人都能參與生成式 AI。因此,AI Workbench將支持在本地機器上進行模型的開發(fā)和部署,而不是云服務上。
借助它,開發(fā)人員可以只需點擊幾下就可以定制和運行生成式AI。據(jù)稱,包括戴爾、惠普、Lambda、聯(lián)想和Supermicro,都正采用AI Workbench。
AI Enterprise 4.0是英偉達發(fā)布的最新版企業(yè)軟件平臺,可提供生產(chǎn)就緒型生成式AI工具,使企業(yè)能夠訪問采用生成式AI所需的工具,同時還提供大規(guī)模企業(yè)部署所需的安全性和API穩(wěn)定性。
同時,黃仁勛還宣布英偉達與擁有 200 萬用戶的初創(chuàng)公司Hugging Face 合作,這將使得數(shù)百萬大型語言模型開發(fā)者和其他高級 AI 應用程序開發(fā)人員,能夠輕松實現(xiàn)生成式 AI 超級計算。
開發(fā)人員將能夠在Hugging Face平臺內(nèi)訪問NVIDIA DGX Cloud AI 超級計算,以訓練和微調(diào)先進的 AI 模型。據(jù)悉,Hugging Face 社區(qū)已分享超過 25 萬個模型和 5 萬個數(shù)據(jù)集。對此,黃仁勛表示,這將是一項全新的服務,將世界上最大的 AI 社區(qū)與世界上最好的訓練和基礎設施連接起來。
寫在最后:
AI的生產(chǎn)力爆炸時代,正在加速到來
隨著英偉達一個接一個新產(chǎn)品和新服務的揭曉,我們似乎也看到生成式AI的生產(chǎn)力爆炸時代正在加速到來。
2022年底,ChatGPT問世后,迅速在全世界引起了AI狂潮,在這波狂潮中,英偉達憑借其數(shù)據(jù)中心GPU的核心技術優(yōu)勢,成為人工智能芯片市場市場主導者。
如今,全球約90%以上的大模型都在使用英偉達的GPU芯片,其股價也在今年以來飆升了逾200%,賺了個盆滿缽滿,上市14年后成功躋身萬億美元市值俱樂部。而實現(xiàn)這一目標,硅谷巨頭們諸如蘋果用了37年、微軟用了33年、亞馬遜用了21年,特斯拉跑得最快,只用了11年。
目前GPU價格仍在上漲,已然成為人工智能基礎設施的“硬通貨”,海外甚至已有創(chuàng)業(yè)企業(yè)開始利用GPU進行抵押融資。
eBay網(wǎng)站顯示,英偉達旗艦級芯片H100的售價已經(jīng)高達4.5萬美元(約合人民幣32.37萬元),這較今年4月份4萬美元的價格漲幅超過10%,甚至有賣家標價6.5萬美元,而且貨源較上半年也顯著減少。
同時,英偉達的中國特供版 A800和 H800芯片也遭到了哄搶。有數(shù)據(jù)推算,2022年全年英偉達數(shù)據(jù)中心GPU在中國的銷售額約為100億元人民幣。而今年春節(jié)后,據(jù)晚點 LatePost報道,擁有云計算業(yè)務的中國各互聯(lián)網(wǎng)大公司都向英偉達下了大單。字節(jié)今年向英偉達訂購了超過10億美元的GPU,另一家大公司的訂單也至少超過10億元人民幣。而僅字節(jié)一家公司今年的訂單可能已接近英偉達去年在中國銷售的商用GPU總和。
目前,國內(nèi)大模型企業(yè)基本上很難拿得到這些芯片,A800和 H800芯片從原來的12萬人民幣左右,變成了現(xiàn)在是25萬甚至30萬,甚至有高達50萬一片。
值得注意的是,近日有消息稱,下一代GPT大模型GPT5需要5萬張英偉達最高配置的H100芯片,全球市場對H100芯片的需求量達到43萬張,英偉達的產(chǎn)能可能難以滿足如此大的算力需求。
正如特斯拉CEO馬斯克表示,“英偉達不會永遠在大規(guī)模訓練和推理芯片市場占據(jù)壟斷地位。”越是風光,競爭對手就越是虎視眈眈,比如就在前不久,AMD剛剛發(fā)布了“大模型專用”的AI芯片MI300X,直接對標英偉達H100,這被業(yè)界視為直接向英偉達宣戰(zhàn)。
但從本次黃仁勛的演講來看,賽道越來越激烈,英偉達也絲毫沒有松懈。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19169瀏覽量
229155 -
人工智能
+關注
關注
1791文章
46872瀏覽量
237598 -
英偉達
+關注
關注
22文章
3748瀏覽量
90836 -
超級芯片
+關注
關注
0文章
34瀏覽量
8869 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5781
原文標題:GPU被炒到50萬元一顆后,英偉達又推超級芯片!
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
NVIDIA AI Enterprise榮獲金獎

亞馬遜AWS暫緩采購英偉達GH200芯片,期待Blackwell更強
亞馬遜未中斷英偉達訂單,等待Grace Blackwell更強性能
SiPearl更新Rhea1處理器規(guī)格,聚焦HPC與AI推理應用
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
美國首個Grace Hopper架構超算Venado落地:達10 exaFLOPS
NVIDIA推出搭載GB200 Grace Blackwell超級芯片的NVIDIA DGX SuperPOD?
新思科技攜手英偉達:基于加速計算、生成式AI和Omniverse釋放下一代EDA潛能

英偉達發(fā)布新一代AI芯片B200
郭明錤解析:英偉達對GB200期待高,但出貨不樂觀,供應商恐受影響
英偉達計劃拉大GB200與B100/B200規(guī)格差異,以刺激用戶購買GB200
英偉達Grace-Hopper提供一個緊密集成的CPU + GPU解決方案
英偉達斥資預購HBM3內(nèi)存,為H200及超級芯片儲備產(chǎn)能
英偉達與亞馬遜聯(lián)手打造了一臺擁有16384個超級芯片的超級計算機
AWS成為第一個提供NVIDIA GH200 Grace Hopper超級芯片的提供商





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論