 基于生成模型的預訓練方法
基于生成模型的預訓練方法
I實驗
總結
參考
前言
 請添加圖片描述
請添加圖片描述
我們這次要介紹的文章被接收在 ICCV 2023 上,題為:DreamTeacher: Pretraining Image Backbones with Deep Generative Models,我認為是個挺強挺有趣的自監督方面的工作。DreamTeacher 用于從預訓練的生成網絡向目標圖像 Backbone 進行知識蒸餾,作為一種通用的預訓練機制,不需要標簽。這篇文章中研究了特征蒸餾,并在可能有任務特定標簽的情況下進行標簽蒸餾,我們會在后文詳細介紹這兩種類型的知識蒸餾。
事實上,之前已經在 GiantPandaCV 上介紹過一種 diffusion 去噪自監督預訓練方法:DDeP,DDeP 的設計簡單,但去噪預訓練的方法很古老了。然而,DreamTeacher 開創了如何有效使用優質的生成式模型蒸餾獲得相應的知識。
補充:在 DDeP 這篇文章中,經過讀者糾正,我們重新表述了加噪公式:
相關工作
Discriminative Representation Learning
最近比較流行的處理方法是對比表示學習方法,SimCLR 是第一個在線性探測和遷移學習方面表現出色的方法,而且沒有使用類標簽,相較于監督預訓練方法。隨后的工作,如 MoCo,通過引入 memory bank 和梯度停止改進了孿生網絡設計。然而,這些方法依賴于大量的數據增強和啟發式方法來選擇負例,可能不太適用于像 ImageNet 這樣規模的數據集。關于 memory bank 的概念,memory bank 是 MoCo 中的一個重要組件,用于存儲模型的特征向量。在 MoCo 的訓練過程中,首先對一批未標記的圖像進行前向傳播,得到每個圖像的特征向量。然后,這些特征向量將被存儲到內存庫中。內存庫的大小通常會比較大,足夠存儲許多圖像的特征。訓練過程的關鍵部分是建立正負樣本對。對于每個樣本,其特征向量將被視為查詢向量(Query),而來自內存庫的其他特征向量將被視為候選向量(Candidate)。通常情況下,查詢向量和候選向量來自同一張圖片的不同視角或數據增強的版本。然后,通過比較查詢向量與候選向量之間的相似性來構建正負樣本對。此外,還有一些其他方法和概念,我們就不在這篇解讀文章中介紹了。
Generative Representation Learning
DatasetGAN 是最早展示預訓練 GAN 可以顯著改善感知任務表現的研究之一,特別是在數據標記較少的情況下。SemanticGAN 提出了對圖像和標簽的聯合建模。推理過程首先將測試圖像編碼為 StyleGAN 的潛在空間,然后使用任務頭部解碼標簽。DDPM-seg 沿著這一研究方向,但使用了去噪擴散概率模型(DDPMs)代替 StyleGAN。這篇文章繼續了這一研究方向,但重點放在從預訓練的生成模型中,特別是擴散模型,向下游圖像主干中提取知識,作為一種通用的預訓練方式。
關于相關工作部分中涉及到的方法,如果有疑惑的推薦閱讀原文(鏈接在文末)。
DreamTeacher 框架介紹
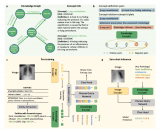
DreamTeacher 框架能在兩種場景下的工作:無監督表示學習和半監督學習。在無監督表示學習中,預訓練階段沒有可用的標簽信息,而在半監督學習中,只有部分數據擁有標簽。框架使用訓練好的生成模型 G 來傳遞其學到的表示知識到目標圖像主干 f。無論在哪種場景下,框架的訓練方法和所選的生成模型 G 與圖像主干 f 的選擇都是一樣的。首先,它創建一個包含圖像和相應特征的特征數據集 。然后,通過將生成模型的特征傳遞到圖像主干 f 的中間特征中來訓練圖像主干 f。作者特別關注使用卷積主干 f 的情況,而對 Transformer 的探索留給未來的研究。
Unsupervised Representation Learning
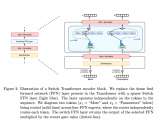
對于無監督表示學習,給定一個特征數據集 D,在圖像主干 f 的不同層次上附加特征回歸器,以回歸出對應的生成特征 從圖像 中。我們首先如何討論創建特征數據集,然后設計特征回歸器,最后介紹蒸餾目標。創建特征數據集 D 的方法有兩種。一種是通過從生成模型 G 中采樣圖像,并記錄生成過程中提取的中間特征來創建合成數據集。這種方法可以合成無限大小的數據集,但可能會出現 mode dropping(生成模型可能沒有學習到分布的某些部分)的問題。另一種方法是將實際圖像通過編碼過程編碼到生成模型 G 的潛在空間中,然后記錄生成過程中提取的中間特征,創建編碼數據集。合成數據集適用于采樣速度快、無法編碼真實圖像的生成模型(如 GAN),而編碼數據集適用于具有編碼器網絡的生成模型(如 VAE)和擴散模型。這兩種方法的特征數據集可以在離線預先計算,也可以在訓練過程中在線創建,以實現快速的內存訪問和高效的樣本生成和刪除,從而適用于任何大小的數據集和特征預訓練,同時增加下游Backbone 網絡的魯棒性。DreamTeacher 框架的整體流程如下圖所示,圖里表示創建特征數據集 D 使用的是第二種方法。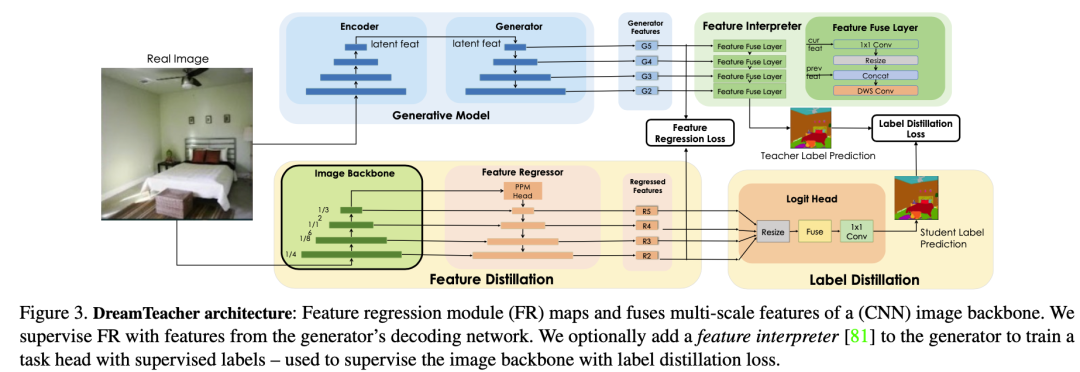 為了將生成式表示 ? 蒸餾到通用主干 f 中,設計了一個特征回歸器模塊,將圖像主干的多層特征映射并對齊到生成式特征上。受到 Feature Pyramid Network(FPN)的設計啟發,特征回歸器采用自頂向下的架構,并使用側向跳線連接來融合主干特征,并輸出多尺度特征。在圖像主干的最后一層之前應用了類似于 PSPNet 中的金字塔池化模塊(PPM),上圖(底部)直觀地描述了這個架構。接下來,我們關注如何做特征蒸餾的。將編碼器 f 的不同級別的中間特征表示為 ,對應的特征回歸器輸出為 。使用一個 1×1 的卷積來匹配 和 的通道數,如果它們不同的話。特征回歸損失非常簡單,受到 FitNet 的啟發,它提出了通過模擬中間特征激活將教師網絡上的知識蒸餾到學生網絡上:
為了將生成式表示 ? 蒸餾到通用主干 f 中,設計了一個特征回歸器模塊,將圖像主干的多層特征映射并對齊到生成式特征上。受到 Feature Pyramid Network(FPN)的設計啟發,特征回歸器采用自頂向下的架構,并使用側向跳線連接來融合主干特征,并輸出多尺度特征。在圖像主干的最后一層之前應用了類似于 PSPNet 中的金字塔池化模塊(PPM),上圖(底部)直觀地描述了這個架構。接下來,我們關注如何做特征蒸餾的。將編碼器 f 的不同級別的中間特征表示為 ,對應的特征回歸器輸出為 。使用一個 1×1 的卷積來匹配 和 的通道數,如果它們不同的話。特征回歸損失非常簡單,受到 FitNet 的啟發,它提出了通過模擬中間特征激活將教師網絡上的知識蒸餾到學生網絡上:
在這里,W 是一個不可學習的白化算子,使用 LayerNorm 實現,用于對不同層次上的特征幅值進行歸一化。層數 l = {2, 3, 4, 5},對應于相對于輸入分辨率的 步長處的特征。
此外,這篇文章還探索了基于激活的注意力轉移(AT)目標。AT 使用一個運算符 ,對空間特征的每個維度生成一個一維的“注意力圖”,其中 |Ai| 表示特征激活 A 在通道維度 C 上的絕對值和。這種方法相比直接回歸高維特征可以提高收斂速度。具體來說,AT 損失函數如下:
其中分別是回歸器和生成模型在第 l 層中的特征的矢量形式中的第 j 對。
最后,綜合特征回歸損失為:
Label-Guided Representation Learning
 在這里插入圖片描述
在這里插入圖片描述
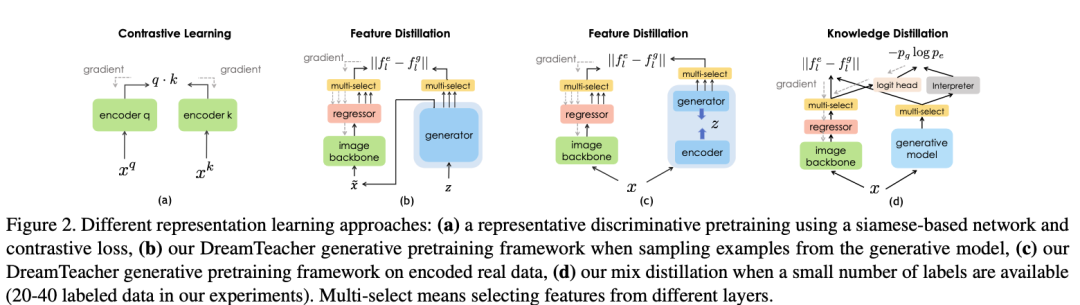
在半監督設置中,在預訓練階段在凍結的生成網絡 G 之上訓練了一個任務相關的分支,稱為特征解釋器,采用 DatasetGAN 的方法進行監督訓練。與 DatasetGAN 合成用于訓練下游任務網絡的帶標簽數據集不同,DreamTeacher 改用軟標簽蒸餾,即在編碼和合成的數據集中都包含了預測的軟標簽,也就是特征數據集 D 中包含了軟標簽。這在上圖(d)中進行了可視化。
這篇文章探索了使用分割標簽對解釋器分支進行訓練(半監督情景下),并使用交叉熵和 Dice 目標的組合來訓練:
其中是特征解釋器的權重,y 是任務標簽。H(·, ·) 表示像素級的交叉熵損失,D(·, ·) 表示 Dice Loss。
對于標簽蒸餾,使用以下損失函數:
其中 和 分別是特征解釋器和目標圖像主干 f 的 logits。H 是交叉熵損失,而 τ 是溫度參數。
將標簽蒸餾目標與特征蒸餾目標相結合,得到混合損失函數:
使用混合蒸餾損失對預訓練數據集中的所有圖像進行預訓練,無論是帶標簽還是無標簽的。帶標簽的標簽僅用于訓練特征解釋器,而 DreamTeacher 只使用特征解釋器生成的軟標簽對圖像主干 f 進行蒸餾預訓練。
實驗
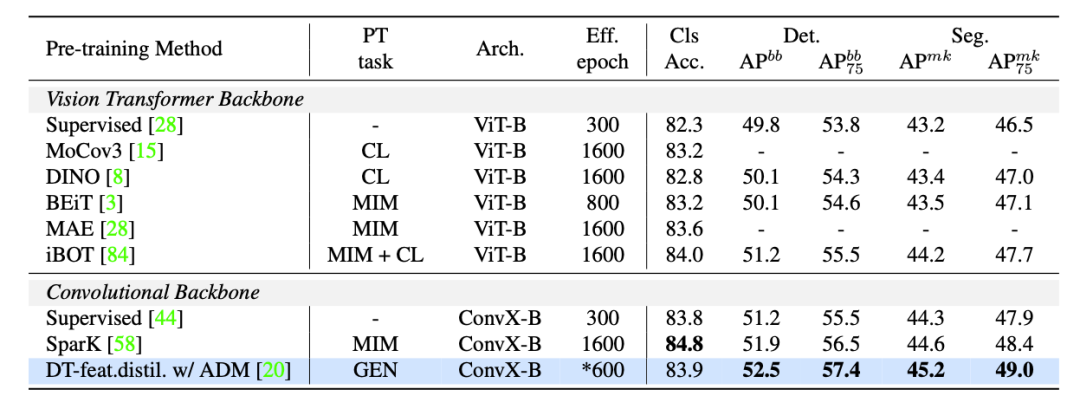
在實驗中,使用的生成模型包含:unconditional BigGAN、ICGAN、StyleGAN2;對于基于擴散的模型,使用了 ADM 和 stable diffusion 模型。使用的數據集包含:bdd100k、ImageNet-1k(IN1k-1M)、LSUN 和 ffhq。下表將 DreamTeacher 與 ImageNet 和 COCO 上的自監督學習的 SOTA 方法進行比較:
 在這里插入圖片描述
在這里插入圖片描述
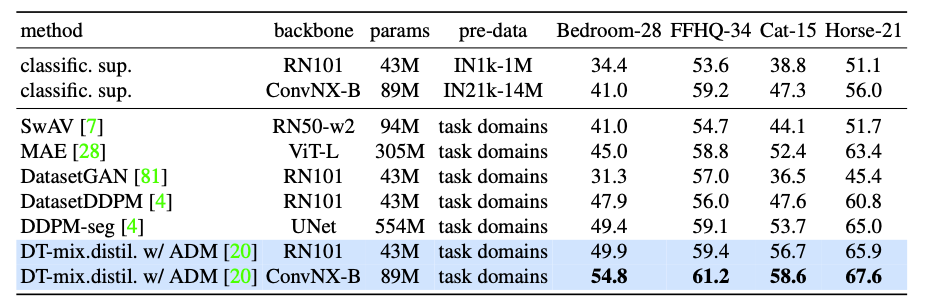
對于 Label-efficient 的語義分割 benchmark。下表將 DreamTeacher與各種表示學習基線進行比較。
 下圖是使用 DreamTeacher 特征蒸餾預訓練的 ConvNX-B 模型在 LSUN-cat 無標簽圖像上的定性結果。
下圖是使用 DreamTeacher 特征蒸餾預訓練的 ConvNX-B 模型在 LSUN-cat 無標簽圖像上的定性結果。
在這里插入圖片描述
總結
這篇文章的研究聚焦于提出一種名為 DreamTeacher 的框架,旨在從生成模型向目標圖像 Backbone 傳遞知識(知識蒸餾)。在這個框架下,進行了多個實驗,涵蓋了不同的 settings ,包括生成模型、目標圖像 Backbone 和評估 benchmark。其目標是探究生成式模型在大規模無標簽數據集上學習語義上有意義特征的能力,并將這些特征成功地傳遞到目標圖像 Backbone 上。
通過實驗,這篇文章發現使用生成目標的生成網絡能夠學習到具有意義的特征,這些特征可以有效地應用于目標圖像主干。與現有自監督學習方法相比,這篇文章基于生成模型的預訓練方法表現更為優異,這些 benchmark 測試包括 COCO、ADE20K 和 BDD100K 等。
這篇文章的工作為生成式預訓練提供了新的視角和方法,并在視覺任務中充分利用了生成模型。在近兩年的論文中,生成式預訓練技術是一個比較有趣的方向。
責任編輯:彭菁
-
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
模型
+關注
關注
1文章
3174瀏覽量
48718 -
網絡設計
+關注
關注
0文章
14瀏覽量
7765 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:ICCV 2023:探索基于生成模型的 Backbone 預訓練
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的預訓練
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

新的預訓練方法——MASS!MASS預訓練幾大優勢!

檢索增強型語言表征模型預訓練
一種側重于學習情感特征的預訓練方法

介紹幾篇EMNLP'22的語言模型訓練方法優化工作
基于醫學知識增強的基礎模型預訓練方法
基礎模型自監督預訓練的數據之謎:大量數據究竟是福還是禍?

混合專家模型 (MoE)核心組件和訓練方法介紹





 工商網監
工商網監
評論