 對于極暗場景RAW圖像去噪,你是否還在被標定折磨?
對于極暗場景RAW圖像去噪,你是否還在被標定折磨?
本文為 [ICCV 2023]LightingEveryDarkness in Two Pairs: A Calibration-Free Pipeline for RAW Denosing 的簡要介紹

Github:https://github.com/Srameo/LED
Homepage:https://srameo.github.io/projects/led-iccv23/
Paper:http://arxiv.org/abs/2308.03448
TL; DR;
基于標定的方法在極低光照環境下的 RAW 圖像去噪中占主導地位。然而,這些方法存在幾個主要缺陷:
噪聲參數標定過程費力且耗時,
不同相機的降噪網絡難以相互轉換,
合成噪聲和真實噪聲之間的差異被高倍數字增益放大。
為了克服上述缺點,我們提出了一種無需標定的pipeline來照亮LighingEveryDarkness(LED),無論數字增益或相機傳感器的種類。我們的方法無需標定噪聲參數和重復訓練,只需少量配對數據和快速微調即可適應目標相機。此外,簡單的結構變化可以縮小合成噪聲和真實噪聲之間的domain gap,而無需任何額外的計算成本。在SID[1]上僅需總共6 對配對數據、和 0.5% 的迭代次數以及0.2%的訓練時間,LED便表現出SOTA的性能!
Introduction
使用真實配對數據進行訓練
SID[1]首先提出一套完整的 benchmark 以及 dataset 進行RAW圖像低光增強或去噪。為什么要從RAW圖像出發進行去噪和低光增強呢?因為其具有更高的上限,具體可以參考 SID[1]的文章。
那么它具體的做法是什么呢?很簡單,如圖1左,使用相機拍攝大量配對的真實數據,之后直接堆到網絡里進行訓練。
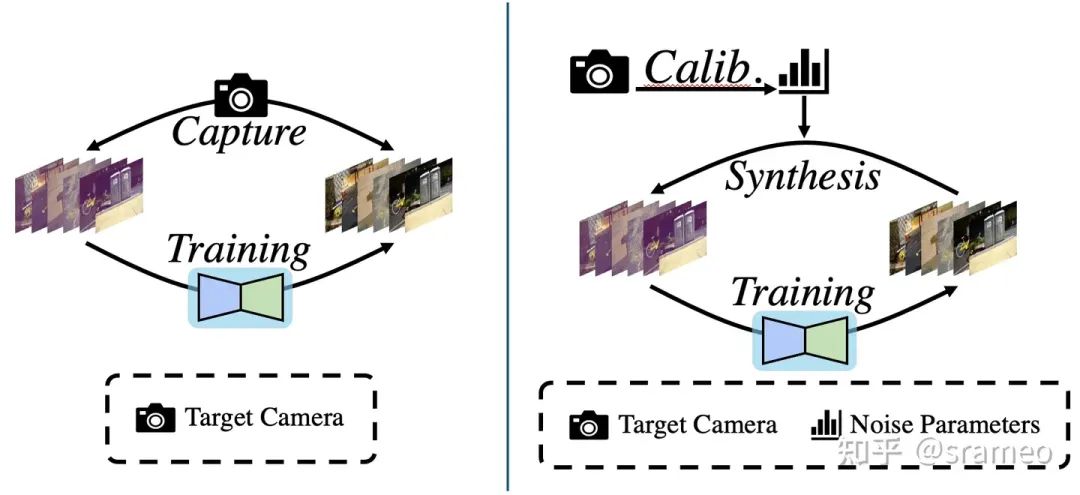
圖1: 基于真實配對數據進行訓練流程(左)以及基于噪聲模型標定進行訓練流程(右)
但是有一個很重要的問題,不同的傳感器,噪聲模型以及參數都是不同的。那么按照這種流程,難道我們對每種相機都需要重新收集大量數據并重新訓練?是不是有點太繁瑣了?
基于噪聲模型標定的算法流程
對于上述提到的問題,近期的paper[2][3][4][5]統一告訴我們:是的。現在,大家主要卷的,包括在各種工業場景(手機、邊緣設備上),去噪任務都已經開始采用基于標定的手段。
那么什么是標定呢?具體的標定流程大家可以參考
@Wang Hawk
的文章Wang Hawk:60. 數碼相機成像時的噪聲模型與標定。當然,基于深度學習+噪聲模型標定的算法大概就分為如下三步(可以參考圖1右):
1. 設計噪聲模型,收集標定用數據,
2.使用 1. 中的標定的數據對對噪聲模型進行參數估計埋個伏筆,增益(或者說iso)和噪聲方差有著log域的線性關系
3. 使用 2. 中標定好的噪聲模型合成配對數據并訓練神經網絡。
這樣,對于不同的相機,我們只需使用不同的標定數據(收集難度相對于大規模配對數據集來講少了很多),便可以訓練出對應該相機的專用去噪網絡。
但是,標定算法真的好嗎?
標定缺陷以及 LED
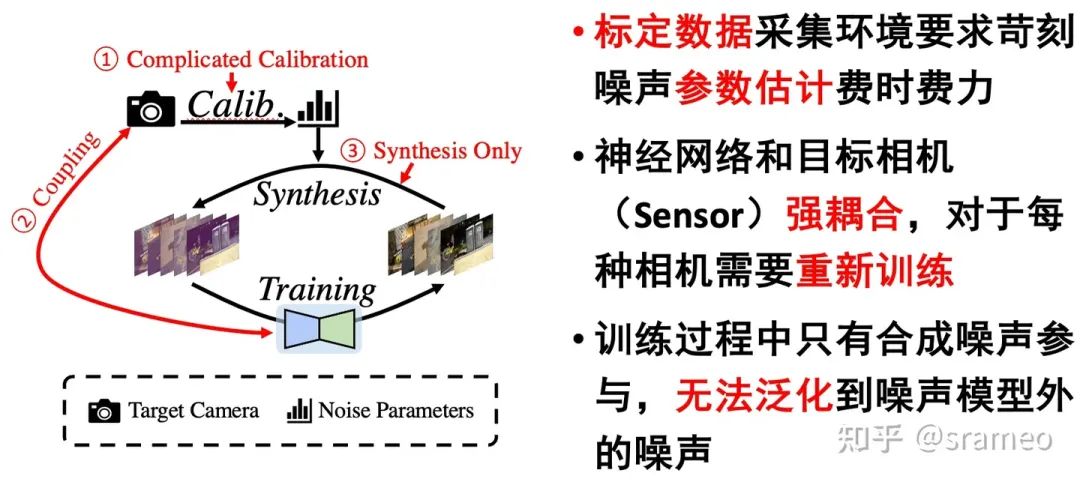
圖2: 基于噪聲模型標定的算法缺陷
那么我們喜歡什么呢?
簡化標定[6][7],甚至無需標定,
快速部署到新相機上,
強大的“泛化”能力:很好的泛化到真實場景,克服合成噪聲到真實噪聲之間的domain gap。
So here comes LED!
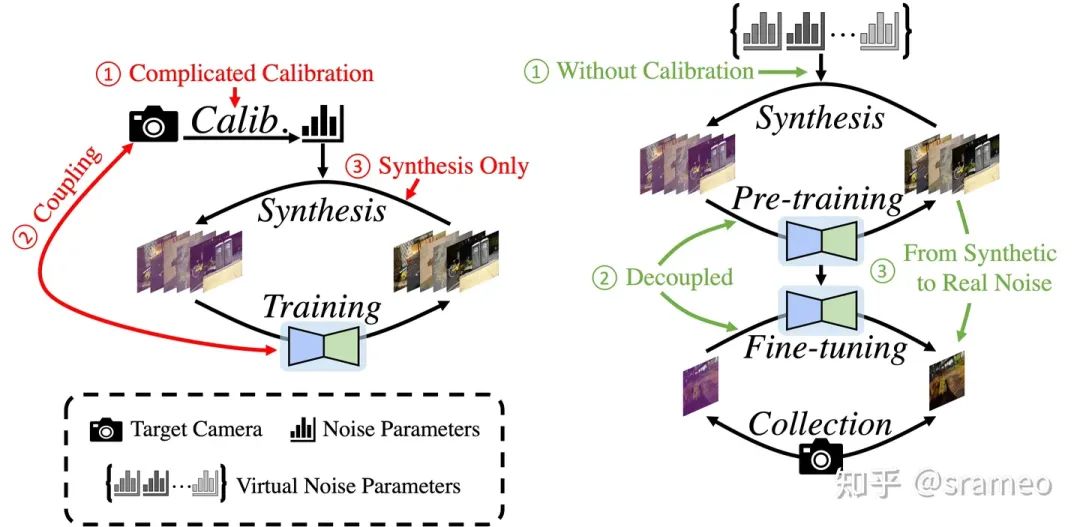
圖3: 標定算法與LED的對比
無需標定:相比于標定算法需要使用真實相機的噪聲參數,我們采用虛擬相機噪聲參數進行數據合成,
快速部署:采用 Pretrain-Finetune 的訓練策略,對于新相機僅需少量數據對網絡部分參數進行微調,
克服 Domain Gap:通過少量真實數據進行 finetune 以獲得去除真實噪聲的能力。
LED 能做到什么?
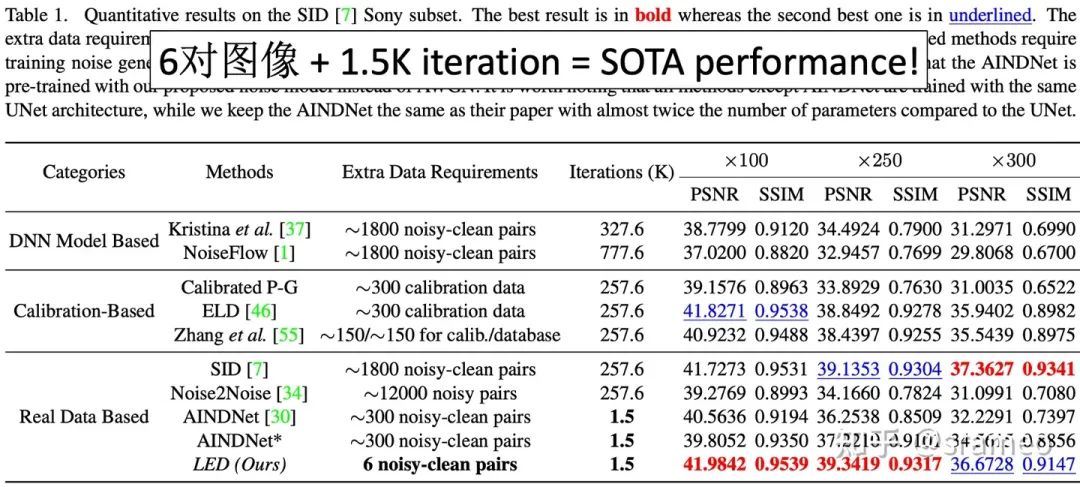
圖4: 6對數據 + 1.5K iteration = SOTA Performance!
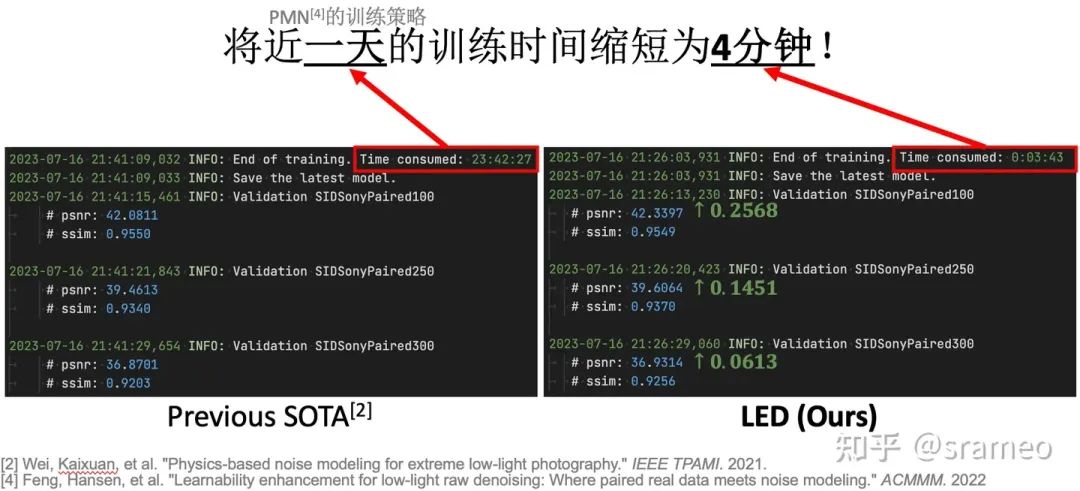
圖5: 更直觀的log對比
Method
LED大概分為一下幾步:
預定義噪聲模型Φ,從參數空間中隨機采集 N 組 “虛擬相機” 噪聲參數,
使用 1. 中的 N 組 “虛擬相機” 噪聲參數合成并 Pretrain 神經網絡,
使用目標相機收集少量配對數據,
、
使用 3. 中的少量數據 Finetune 2. 中預訓練的神經網絡。
當然,一個普通的 UNet 并不能很好的完成我們前文說的3個“需要”。因此結構上也需要做少量更改:
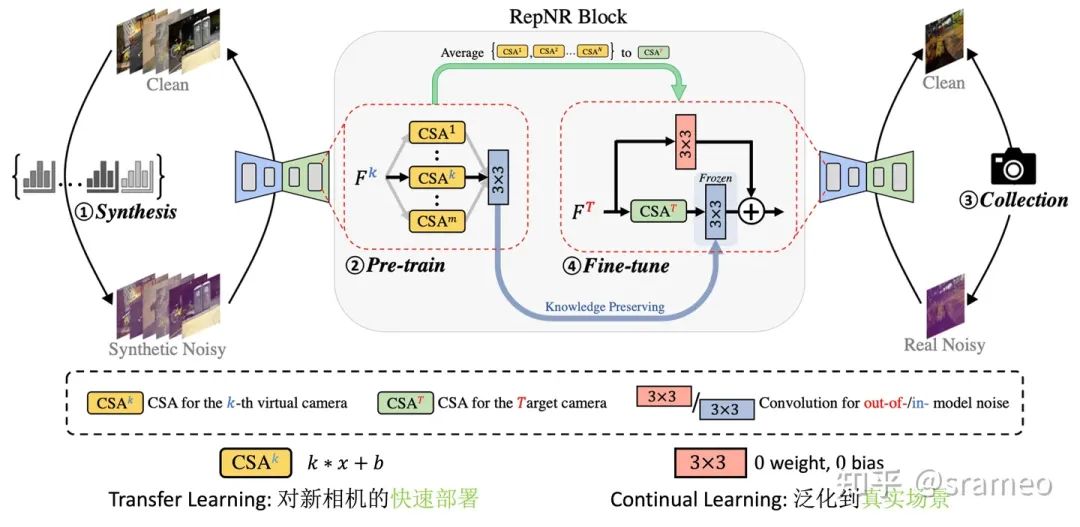
圖6: UNet 結構中的 RepNR Block
首先,我們把 UNet 里所有的 Conv3 配上一組CSA (Camera Specific Alignment),CSA 指一個簡單的 channel-wise weight 和一組 channel-wise 的 bias,用于 feature space 上的對齊。
Pretrain 時,對于第 k個相機合成的數據,我們只訓練第 k 個CSA以及 Conv3。
Finetune 時,先將 Pretrain 時的CSA組進行 Average 得到初始化的CSA^T (for target camera),然后先將其訓練收斂;之后添加一個額外分枝,繼續微調,額外分枝用于學習合成噪聲和真實噪聲之間的 Domain Gap。
當然,由于CSA以及卷積都是線性操作,所以我們在部署時候可以將他們全部都重參數化到一起,因此最終不會引入任何額外計算量!
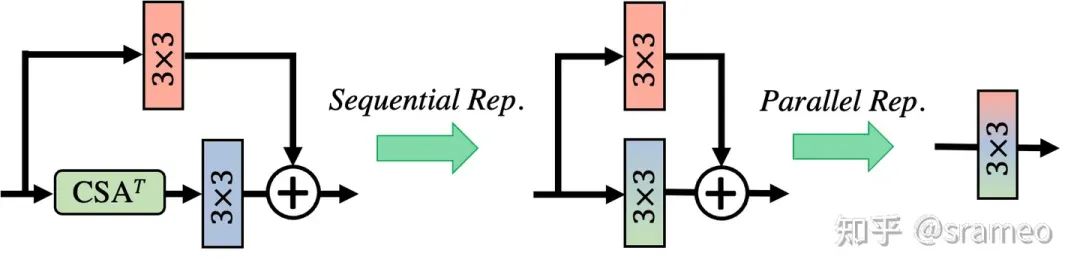
圖7: 重參數化
Visual Result
下圖表現出了 LED 對于 Out-of-model 噪聲的去除能力(克服合成噪聲與真實噪聲之間 Domain Gap 的能力)。
Out-Of-Model Noise 指不被預定義在噪聲模型中的噪聲,如圖8中由鏡頭所引起的噪聲或圖9中由 Dark Shading 所引起的噪聲

圖8: Out-Of-Model Pattern 去除能力(鏡頭引發的 Artifact)

圖9: Out-of-model 噪聲去除能力(Dark Shading)
Discussion on “為什么需要兩對數據?”
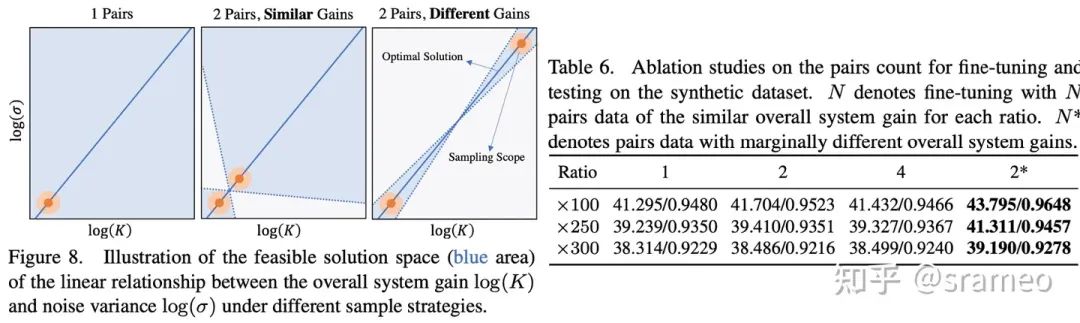
圖10
不知道大家記不記得之前埋的一個伏筆:增益和噪聲方差之間保持對數線性關系。
線性關系意味著什么呢?兩點確定一條直線!也就是說兩對數據(每對數據都能提供在某增益下噪聲方差的值)就可以確定這個線性關系。但是,由于存在誤差[2],所以我們需要增益差距盡可能大的兩對數據以完成網絡對線性關系的學習。
從圖10右也能看出,當我們無論使用增益相同的 1、2、4 對數據,性能并不會有太大的差距。而使用增益差距很大的兩對數據(差異很大指 ISO<500 與 ISO>5000)時,性能有巨大提升。這也能驗證我們的假設,即兩對數據便可以學習到線性關系。
后記:關于開源
我們的訓練測試包括對ELD的復現代碼都已經開源到 Github 上了,如果大家感興趣的話可以幫我們點個 star。
當然不僅是代碼,我們還一口氣開源了 配對數據、ELD、PG(泊松-高斯)噪聲模型在多款相機上、不同訓練策略、不同階段(指 LED 的 Pre-train 和 Fine-tune 階段)的一共15個模型,詳見 pretrained-model.md。
此外,由于 RepNR block 目前只在 UNet 上進行了測試,不過我們相信其在別的模型上的潛力。于是,我們提供了快速將 RepNR block 用于別的模型上的代碼,僅需一行代碼,便可在你自己的網絡結構上使用 RepNR block,配合我們的 Noisy-Clean 生成器,可以快速驗證 RepNR block 在其他結構上的有效性。相關講解以及代碼可以在 develop.md 中找到。
-
噪聲
+關注
關注
13文章
1118瀏覽量
47369 -
圖像
+關注
關注
2文章
1083瀏覽量
40417 -
GitHub
+關注
關注
3文章
466瀏覽量
16386
原文標題:ICCV 2023 | 對于極暗場景RAW圖像去噪,你是否還在被標定折磨?來試試LED!少量數據、快速部署!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于稀疏分解的圖像去噪
基于小波變換氣動光學效應模糊圖像去噪
一種自適應多尺度積閾值的圖像去噪算法
基于提升小波的圖像去噪算法的FPGA設計
基于一種新閾值函數的小波醫學圖像去噪
基于邊緣檢測的NSCT自適應閾值圖像去噪
基于提升小波的圖像去噪算法的FPGA設計
基于數據驅動緊框架圖像去噪模型

基于中值濾波和小波變換的火電廠爐膛火焰圖像去噪方法
基于多通道聯合估計的非局部均值彩色圖像去噪方法
如何解決圖像去噪在去除噪聲的同時容易丟失細節信息的問題






 工商網監
工商網監
評論