") 人工智能套裝myCobot 320版視覺算法深度解析
人工智能套裝myCobot 320版視覺算法深度解析
引言
今天我們將深入了解myCobot320AIKit的機器識別算法是如何實現(xiàn)。
當今社會,隨著人工智能技術的不斷發(fā)展,機械臂的應用越來越廣泛。作為一種能夠模擬人類手臂動作的機器人,機械臂具有高效、精準、靈活、安全等一系列優(yōu)點。在工業(yè)、物流、醫(yī)療、農(nóng)業(yè)等領域,機械臂已經(jīng)成為了許多自動化生產(chǎn)線和系統(tǒng)中不可或缺的一部分。例如,在工廠生產(chǎn)線上的自動化裝配、倉庫物流中的貨物搬運、醫(yī)療手術中的輔助操作、農(nóng)業(yè)生產(chǎn)中的種植和收獲等場景中,機械臂都能夠發(fā)揮出其獨特的作用。本文將重點介紹機械臂結(jié)合視覺識別技術在myCobot320AIKit場景中的應用,并探討機械臂視覺控制技術的優(yōu)勢和未來發(fā)展趨勢。
產(chǎn)品介紹
myCobot320M5Stack
myCobot320是一款面向用戶自主編程開發(fā)的六軸協(xié)作機器人,350MM的運動半徑,最高可達1000g的末端負載,0.5MM的重復定位精度;全面開放軟件控制接口,多種主流編程語言可以快速上手控制機械臂。

myCobotAdaptivegripper


mycobot自適應夾爪,自適應夾爪是一種機器人末端執(zhí)行器,用于抓取和搬運各種形狀和尺寸的物體。自適應夾爪具有很高的靈活性和適應性,可以根據(jù)不同的物體形狀和尺寸自動調(diào)整其夾緊力度和夾取位置。它可以結(jié)合機器視覺,根據(jù)視覺算法獲取到的信息調(diào)夾爪整夾緊力度和夾取位置。該夾爪能夠負載抓取1kg的物體,最大的夾距90mm,使用電力驅(qū)動的一款夾爪,使用起來相當?shù)姆奖恪?/span>
以上就是我們使用到的設,以及后續(xù)用到的myCobot320AIKit。
視覺算法
視覺算法是一種利用計算機圖像處理技術來實現(xiàn)對圖像和視頻進行分析和理解的方法。它主要包括圖像預處理、特征提取、目標檢測、姿態(tài)估計等幾個方面。
圖像預處理:
圖像預處理是對原始圖像進行處理,使其更適合后續(xù)的分析和處理,常用的算法有圖像去噪算法、圖像增強算法、圖像分割算法。
特征點提取:
特征提取是從圖像中提取出關鍵特征,以便進行進一步的分析和處理,SIFT算法、SURF算法、ORB算法、HOG算法、LBP算法等.
目標檢測:
目標檢測是在圖像中尋找某個特定的物體或目標,常用的算法,有Haar特征分類器、HOG特征+SVM分類器、FasterR-CNN、YOLO
姿態(tài)估計:
姿態(tài)估計是通過識別物體的位置、角度等信息,來估計物體的姿態(tài),常用的算法有PnP算法、EPnP算法、迭代最近點算法(ICP)等。
舉例說明
顏色識別
這樣說的太抽象,我們實踐操作來演示這個步驟,如何從下面這張圖片中檢測到白色的高爾夫球。我們使用到的是OpenCV的機器視覺庫。

圖像處理:
首先我們得對圖片進行預處理,方便計算機能夠快速的找到目標物體,這一步的操作是將圖片轉(zhuǎn)化成灰度圖。
灰度圖:灰度圖是一種將彩色圖像轉(zhuǎn)換為黑白圖像的方法,它描述了圖像中每個像素的亮度或灰度級別。在灰度圖中,每個像素的值表示它的亮度,通常在0到255的范圍內(nèi),其中0表示黑色,255表示白色。中間的值表示不同程度的灰度。
import cv2
import numpy as np
image = cv2.imread('ball.jpg')
# turn to gray pic
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow('gray', gray)

灰度處理后的圖片
二值化處理:
我們可以看到圖片中的高爾夫球跟背景是有很大的顏色差別的,可以通過顏色檢測出目標物體。高爾夫球是白色,但是在光線的作用下,還有一些灰色的陰影部分。所以我們在設置灰度圖的像素的時候得考慮進去灰色的部分。
lower_white = np.array([180, 180, 180]) # Lower limit
upper_white = np.array([255, 255, 255]) # Upper limit
# find target object
mask = cv2.inRange(image, lower_white, upper_white)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
這一個步驟就叫做二值化處理,將目標物體從背景中分離出來.
過濾輪廓:
到二值化處理完后,我們需要設置一個過濾的輪廓面積的大小。如果不設置的話會出現(xiàn)下面圖片中的結(jié)果,會發(fā)現(xiàn)有很多地方都被選中,我們只想要最大的那一個就將小面積的區(qū)域給過濾

#filter
min_area = 100
filtered_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_area]
#draw border
for cnt in filtered_contours:
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)

完整代碼:
import cv2
import numpy as np
image = cv2.imread('ball.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
lower_white = np.array([170, 170, 170])
upper_white = np.array([255, 255, 255])
mask = cv2.inRange(image, lower_white, upper_white)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
min_area = 500
filtered_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_area]
for cnt in filtered_contours:
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.imshow('Object Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
與之不同的是,我們是想用機械臂來抓取物體,找到檢測的目標物體還不夠,我們需要獲取到目標物體得坐標信息。
為了獲取被測目標物體的坐標信息,使用到了OpenCV的Arcuo碼,是一種常見的二維碼,用于相機標定,姿態(tài)估計和相機跟蹤等計算機視覺任務。Arcuo碼每個都是由唯一的標識符,通過在途中檢測和識別這些碼,可以推斷相機的位置,相機與碼之間的關系。


圖片中兩個唯一的二維碼,來固定裁剪圖片的大小,固定arcuo碼的位置,就能通過計算獲取到目標物體。

這樣就能檢測出來目標物體所在的位置了,返回x,y坐標給到機械臂的坐標系中,機械臂就可以進行抓取。

具體的代碼
# get points of two aruco
def get_calculate_params(self, img):
"""
Get the center coordinates of two ArUco codes in the image
:param img: Image, in color image format.
:return: If two ArUco codes are detected, returns the coordinates of the centers of the two codes; otherwise returns None.
"""
# Convert the image to a gray image
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Detect ArUco marker.
corners, ids, rejectImaPoint = cv2.aruco.detectMarkers(
gray, self.aruco_dict, parameters=self.aruco_params
)
"""
Two Arucos must be present in the picture and in the same order.
There are two Arucos in the Corners, and each aruco contains the pixels of its four corners.
Determine the center of the aruco by the four corners of the aruco.
"""
if len(corners) > 0:
if ids is not None:
if len(corners) <= 1 or ids[0] == 1:
return None
x1 = x2 = y1 = y2 = 0
point_11, point_21, point_31, point_41 = corners[0][0]
x1, y1 = int((point_11[0] + point_21[0] + point_31[0] + point_41[0]) / 4.0), int(
(point_11[1] + point_21[1] + point_31[1] + point_41[1]) / 4.0)
point_1, point_2, point_3, point_4 = corners[1][0]
x2, y2 = int((point_1[0] + point_2[0] + point_3[0] + point_4[0]) / 4.0), int(
(point_1[1] + point_2[1] + point_3[1] + point_4[1]) / 4.0)
return x1, x2, y1, y2
return None
# set camera clipping parameters
def set_cut_params(self, x1, y1, x2, y2):
self.x1 = int(x1)
self.y1 = int(y1)
self.x2 = int(x2)
self.y2 = int(y2)
# set parameters to calculate the coords between cube and mycobot320
def set_params(self, c_x, c_y, ratio):
self.c_x = c_x
self.c_y = c_y
self.ratio = 320.0 / ratio
# calculate the coords between cube and mycobot320
def get_position(self, x, y):
return ((y - self.c_y) * self.ratio + self.camera_x), ((x - self.c_x) * self.ratio + self.camera_y)
YOLOv5識別
YOLO算法區(qū)別與OpenCV算法不同的點在于,YOLOv5算法是一種基于深度學習的目標檢測算法,與OpenCV的傳統(tǒng)計算機視覺方法有所不同。雖然OpenCV也提供了目標檢測功能,但它主要基于傳統(tǒng)的圖像處理和計算機視覺技術。Yolov5則是一種基于神經(jīng)網(wǎng)絡的深度學習模型,通過訓練神經(jīng)網(wǎng)絡來實現(xiàn)目標檢測。
神經(jīng)網(wǎng)絡就像是一個人的大腦一樣,外界不停的給他傳輸知識,讓他去學習,告訴他這個是蘋果,這個是草莓。通過不斷地訓練學習,給不同地蘋果地圖片,草莓地圖片給它認識。之后他就在能一張圖片里面精準地找到蘋果,草莓。

Code
# detect object
def post_process(self, input_image):
class_ids = []
confidences = []
boxes = []
blob = cv2.dnn.blobFromImage(input_image, 1 / 255, (self.INPUT_HEIGHT, self.INPUT_WIDTH), [0, 0, 0], 1,
crop=False)
# Sets the input to the network.
self.net.setInput(blob)
# Run the forward pass to get output of the output layers.
outputs = self.net.forward(self.net.getUnconnectedOutLayersNames())
rows = outputs[0].shape[1]
image_height, image_width = input_image.shape[:2]
x_factor = image_width / self.INPUT_WIDTH
y_factor = image_height / self.INPUT_HEIGHT
cx = 0
cy = 0
try:
for r in range(rows):
row = outputs[0][0][r]
confidence = row[4]
if confidence > self.CONFIDENCE_THRESHOLD:
classes_scores = row[5:]
class_id = np.argmax(classes_scores)
if (classes_scores[class_id] > self.SCORE_THRESHOLD):
confidences.append(confidence)
class_ids.append(class_id)
cx, cy, w, h = row[0], row[1], row[2], row[3]
left = int((cx - w / 2) * x_factor)
top = int((cy - h / 2) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
box = np.array([left, top, width, height])
boxes.append(box)
'''Non-maximum suppression to obtain a standard box'''
indices = cv2.dnn.NMSBoxes(boxes, confidences, self.CONFIDENCE_THRESHOLD, self.NMS_THRESHOLD)
for i in indices:
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
cv2.rectangle(input_image, (left, top), (left + width, top + height), self.BLUE,
3 * self.THICKNESS)
cx = left + (width) // 2
cy = top + (height) // 2
cv2.circle(input_image, (cx, cy), 5, self.BLUE, 10)
label = "{}:{:.2f}".format(self.classes[class_ids[i]], confidences[i])
# draw real_sx, real_sy, detect.color)
self.draw_label(input_image, label, left, top)
# cv2.imshow("nput_frame",input_image)
# return input_image
except Exception as e:
print(e)
exit(0)
if cx + cy > 0:
return cx, cy, input_image
else:
return None

YOLO開發(fā)者提供了開源代碼在GitHub上,如果有特殊地需求,可以自行設置訓練的方式,達到效果。
除此之外,還有形狀識別,特征點識別,二維碼識別,形狀識別等這些功能都集合在myCobot320AIKit當中。
myCobot320AIKit
這是一個適配機械臂myCobot320的人工智能套裝,將上述視覺算法跟機械臂相結(jié)合的一個應用場景。myCobot320機械臂末端搭配著自適應夾爪和吸泵,對物體進行抓取/吸取。
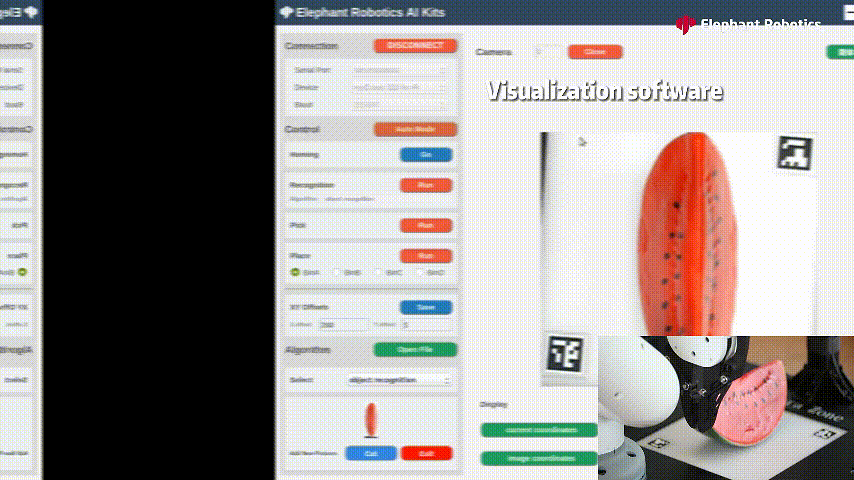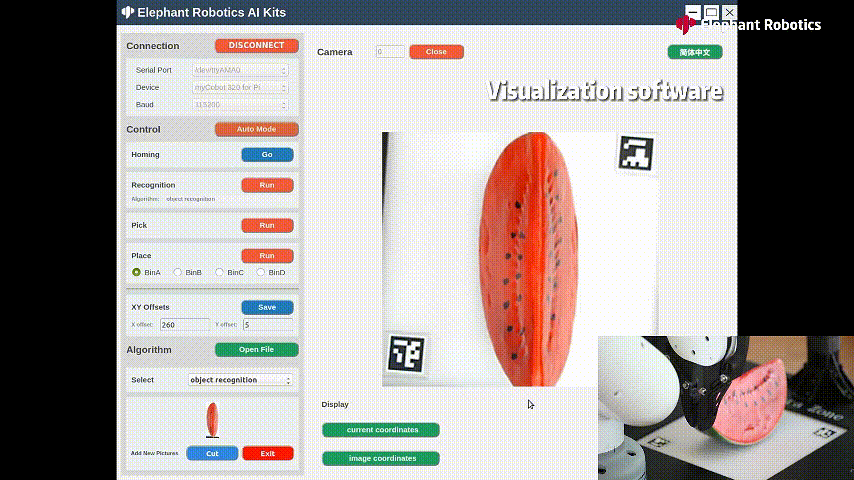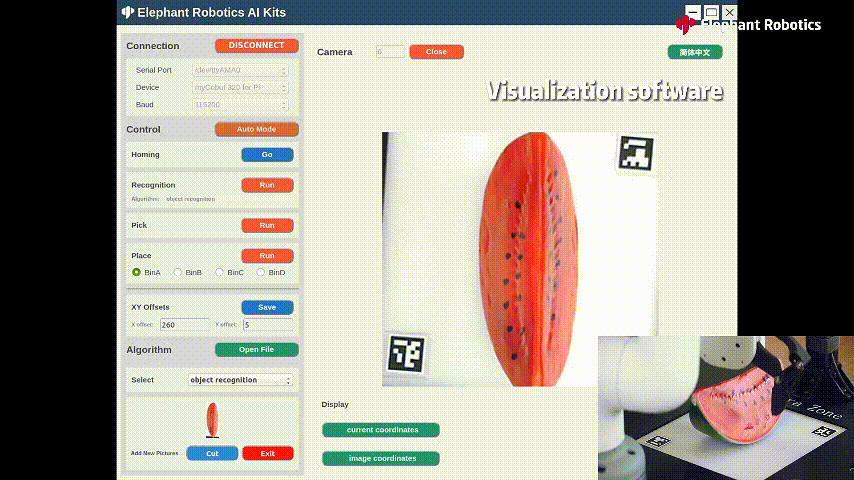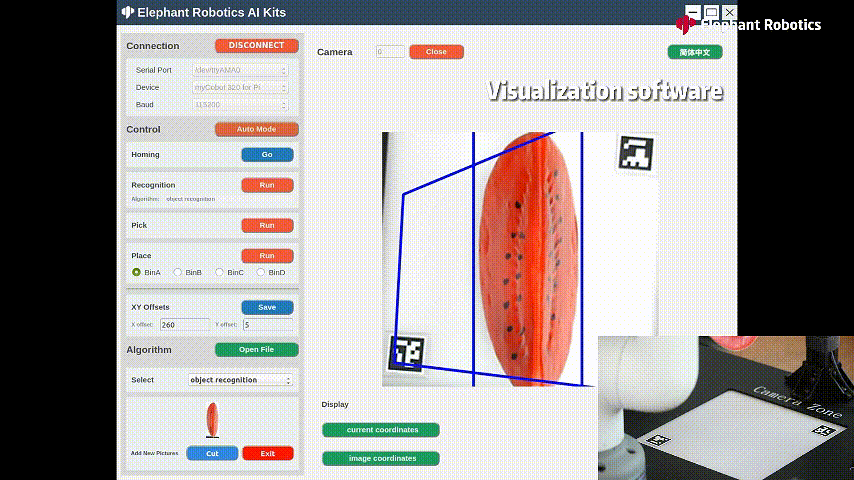
識別西瓜進行抓取

顏色木塊的識別,用吸泵進行吸取
這是一套非常適合剛?cè)腴T學習人工智能,計算機視覺算法識別,機械臂原理的套裝。這個套裝是開源的,提供全部的代碼以供學習。
gif的python動圖
如果你想要了解更多關于myCobot320AIKit的介紹,操作的使用,這邊給你提供之前發(fā)布過的一篇AIKit320的介紹。
總結(jié)
如果你有更好的想法關于人工智能套裝,你完全可以自己打造一個屬于自己機械臂的應用場景,以AIKit為基礎大膽的展示你的想法。
機械臂視覺控制技術是一種應用廣泛、發(fā)展迅速的技術。相比傳統(tǒng)的機械臂控制技術,機械臂視覺控制技術具有高效、精準、靈活等優(yōu)勢,可以在工業(yè)生產(chǎn)、制造、物流等領域得到廣泛應用。隨著人工智能、機器學習等技術的不斷發(fā)展,機械臂視覺控制技術將會有更廣泛的應用場景。在未來的發(fā)展中,需要加強技術研發(fā)和創(chuàng)新,不斷提高技術水平和應用能力。
審核編輯 黃宇
-
機器人
+關注
關注
210文章
28205瀏覽量
206526 -
AI
+關注
關注
87文章
30146瀏覽量
268414 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237567 -
機械臂
+關注
關注
12文章
509瀏覽量
24493 -
視覺算法
+關注
關注
0文章
29瀏覽量
5539
發(fā)布評論請先 登錄
相關推薦
分享:人工智能算法將帶領機器人走向何方?
百度深度學習研究院科學家深度講解人工智能
人工智能技術及算法設計指南
人工智能:超越炒作
史上最全AI人工智能入門+進階學習視頻全集(200G)【免費領取】
【HarmonyOS HiSpark IPC DIY Camera試用 】青少年人工智能教育套裝之一
【HarmonyOS HiSpark IPC DIY Camera試用 】青少年人工智能教育套裝之一
人工智能AI-深度學習C#&LabVIEW視覺控制演示效果
人工智能芯片是人工智能發(fā)展的
人工智能基本概念機器學習算法
人工智能對汽車芯片設計的影響是什么
什么是人工智能、機器學習、深度學習和自然語言處理?
《移動終端人工智能技術與應用開發(fā)》人工智能的發(fā)展與AI技術的進步
深度解析行業(yè)場景中的人工智能應用
myCobot 320 人工智能套裝2023版震撼上市!突破工作半徑和負載限制,全新夾爪抓取方式!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論