 使用Koordinator支持異構資源管理和任務調度場景的實踐經驗
使用Koordinator支持異構資源管理和任務調度場景的實踐經驗
前言
Cloud Native
Koordinator 是阿里云基于過去我們建設的統一調度系統中積累的技術和實踐經驗,對外開源了新一代的調度系統。Koordinator 支持 Kubernetes 上多種工作負載的混部調度。它的目標是提高工作負載的運行時效率和可靠性(包括延遲敏感型負載和批處理任務)。Koordinator 不僅擅長混部場景,也同樣支持大數據、AI 訓練等任務調度場景。本文分享了使用 Koordinator 支持異構資源管理和任務調度場景的實踐經驗。
AI/LLMs 帶來新機遇和新挑戰
Cloud Native
從 2022 年 11 月 ChatGPT 發布到現在,ChatGPT 所引起的關注、產生的影響可能已經超越了信息技術歷史上的幾乎所有熱點。眾多業界專家都被它征服,比如阿里云 CEO 張勇的看法是:“所有行業、應用、軟件、服務,都值得基于大模型能力重做一遍。”NVIDIA CEO 黃仁勛稱它帶來了 AI 的 iPhone 時刻。ChatGPT 開啟了新的時代,國內外的企業和科研機構紛紛跟進,幾乎每周都有一個甚至多個新模型推出,從自然語言處理、計算機視覺到人工智能驅動的科學研究、生成式 AI 等,應用百花齊放;大模型成為業務提效和打開下一個增長點的關鍵。同樣對于云計算、基礎設施、分布式系統的需求也撲面而來。

為支撐百億級、千億級別參數量的大模型訓練需求,云計算和基礎設施需要提供更強大、可擴展的計算和存儲資源。大模型訓練依賴的的核心技術之一是分布式訓練,分布式訓練需要在多個計算節點之間傳遞大量的數據,因此需要一個帶寬更高、延遲更低的高性能網絡。
為了發揮計算、存儲和網絡資源的最佳效能,保障訓練效率,調度和資源管理系統需要設計更合理的策略。在此基礎上,基礎設施還需要在可靠性上持續增強,具備節點故障治愈和容錯能力,確保訓練任務的持續運行。 大模型訓練離不開異構計算設備,典型的就是我們熟知的 GPU。
在 GPU 領域,NVIDIA 仍然占據著主導地位,其他廠商如 AMD 和國內的芯片制造商的機會在努力追趕。以 NVIDIA 為例,其強大的產品設計能力、扎實的技術實力和靈活的市場策略使其能夠快速推出更優秀的芯片,但產品間的架構差異較大,例如 NVIDIA A100 型號和 NVIDIA H100 型號的系統架構差異十分明顯,使用方式上也存在許多需要注意的細節,這給上層的調度系統和資源管理系統帶來了不小的挑戰。
Koordinator+KubeDL 的強強聯合
Cloud Native
我們在阿里云支撐的大模型訓練場景中,使用了 Koordinator 來解決基本的任務調度需求和異構設備資源管理需求。同時,使用 KubeDL 管理訓練作業生命周期和訓練作業排隊調度需求。
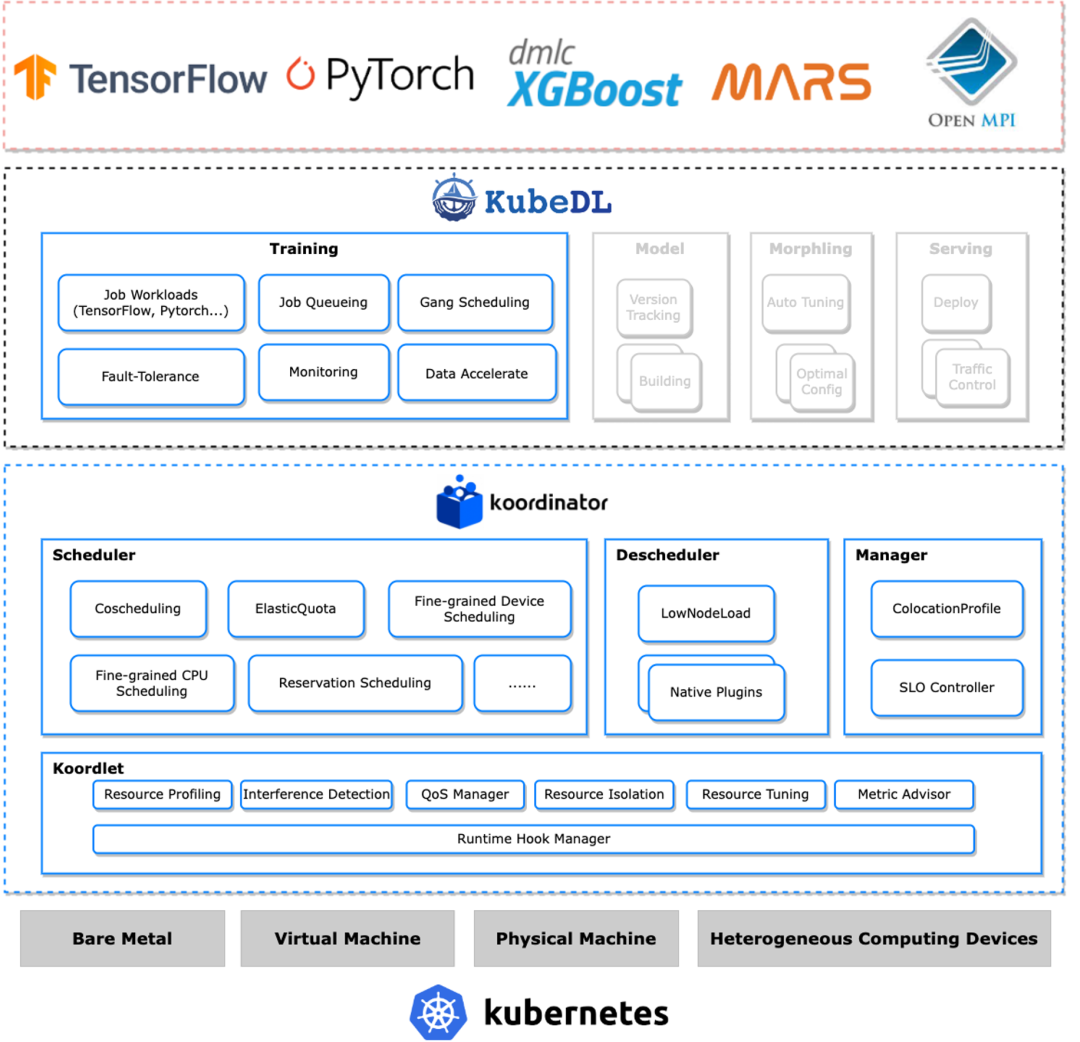
Koordinator 不僅擅長混部調度場景,還針對大數據、AI 模型訓練場景,提供了包括彈性 Quota 調度、Gang 調度等通用的任務調度能力。此外,它還具備精細化的資源調度管理能力,不僅支持中心化分配 GPU,還能感知硬件系統拓撲分配資源,同時支持 GPU&RDMA 的聯合分配和設備共享能力。
我們選擇使用 KubeDL 來管理訓練作業生命周期,是因為它不僅在支撐了內部大量 AI 領域相關場景,而且得益于其優秀的設計和實現都十分優秀,可運維性、可靠性和功能擴展性都非常出色,自身是一個統一的 controller,可以支持多種訓練工作負載,如 TensorFlow、PyTorch、Mars 等。
此外,它還可以適配不同調度器提供的 Gang 調度能力,可以幫助已經使用 KubeDL 項目的存量場景平滑的切換到 Koordinator;KubeDL 還內置了一個通用的作業排隊機制,可以有效解決作業自身的調度需求。 Koordinator 和 KubeDL 的強強聯合,可以很好的解決大模型訓練的調度需求。
Job 調度
Cloud Native
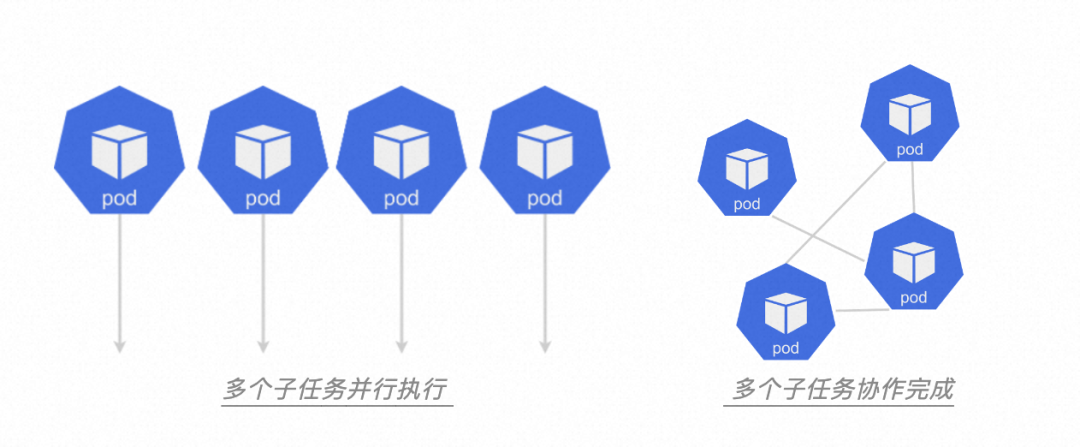
Job 是一種更高層次的抽象,通常具有特定的計算任務或操作。它可以分割成多個子任務并行完成,也可以拆分成多個子任務協作完成。通常 Job 不會依賴其他的工作負載,可以獨立的運行。而且 Job 比較靈活,在時間維度、空間維度、或者資源方面的約束都比較少。
 ?
?
Job 排隊
Job 同樣需要經過調度程序調度,這也就意味著 Job 同樣在調度時需要排隊。那為什么需要排隊呢?或者說我們可以通過排隊解決哪些問題? 是因為系統中的資源有限的,我們的預算也是有限的,而 Job 的數量和計算需求往往是無限的。
如果不進行排隊和調度,那些計算需求較高或者執行時間較長的 Job 就會占用大量的資源,導致其他 Job 無法獲取到足夠的資源進行計算,甚至可能導致集群系統崩潰。 因此,為保證各個 Job 能夠公平的獲得資源,避免資源爭奪和沖突,就需要對 Job 進行排隊和調度。
我們使用 KubeDL提供的通用的 Job 排隊和調度機制解決這個問題。KubeDL 因為本身就內置支持了多種訓練工作負載,因此它天然支持按照 Job 粒度進行調度;并且它具備多租戶間的公平性保障機制,減少 Job 間的資源爭奪和沖突,排隊和調度的過程中,KubeDL 根據 Job 的計算需求、優先級、資源需求等因素進行評估和分配,確保每個 Job 都能夠得到合適的資源進行計算。KubeDL 支持多種擴展插件,如 Filter 插件,Score 插件等,可以進一步擴展其功能和特性滿足不同場景的需求。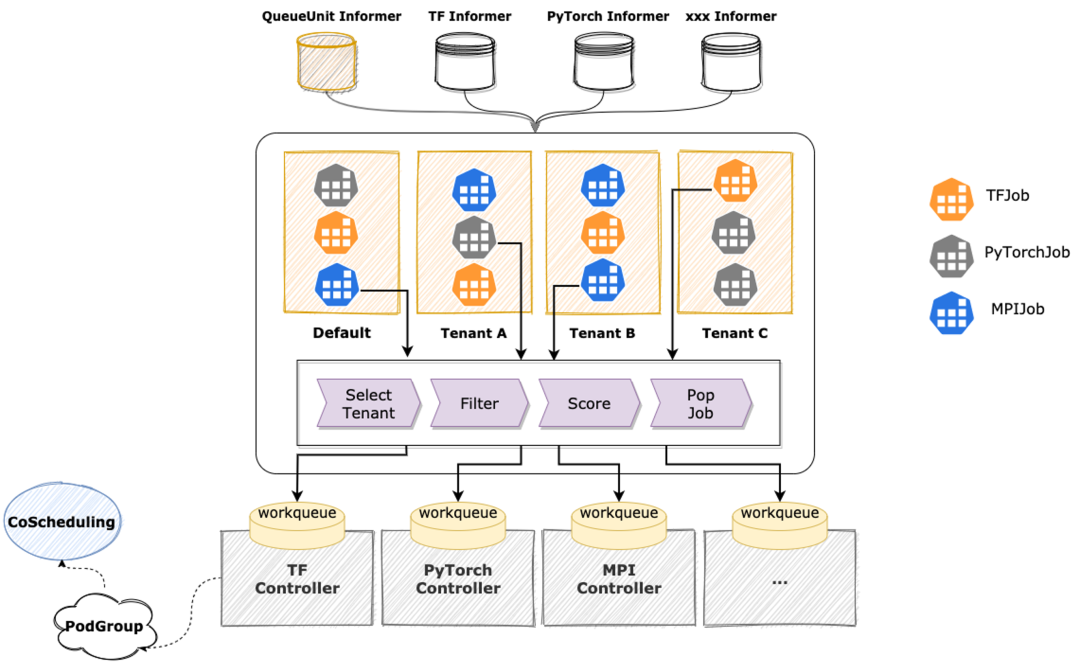 ?
?
彈性 Quota
Job 排隊要解決的核心問題之一是資源供給的公平性,一般在調度系統中都是通過彈性 Quota 機制來解決。 彈性 Quota 機制要解決的幾個核心問題:首先是保障公平性,不能讓某一些任務的資源需求過高導致其他任務被餓死,應盡量讓大部分任務都能得到資源;其次需要有一定的彈性能力,能夠把空閑的額度共享給當下更需要資源的任務,同樣還要能夠在需要資源時,把共享出去的資源拿回來,這意味還需要提供具備靈活的策略滿足不同場景的需求。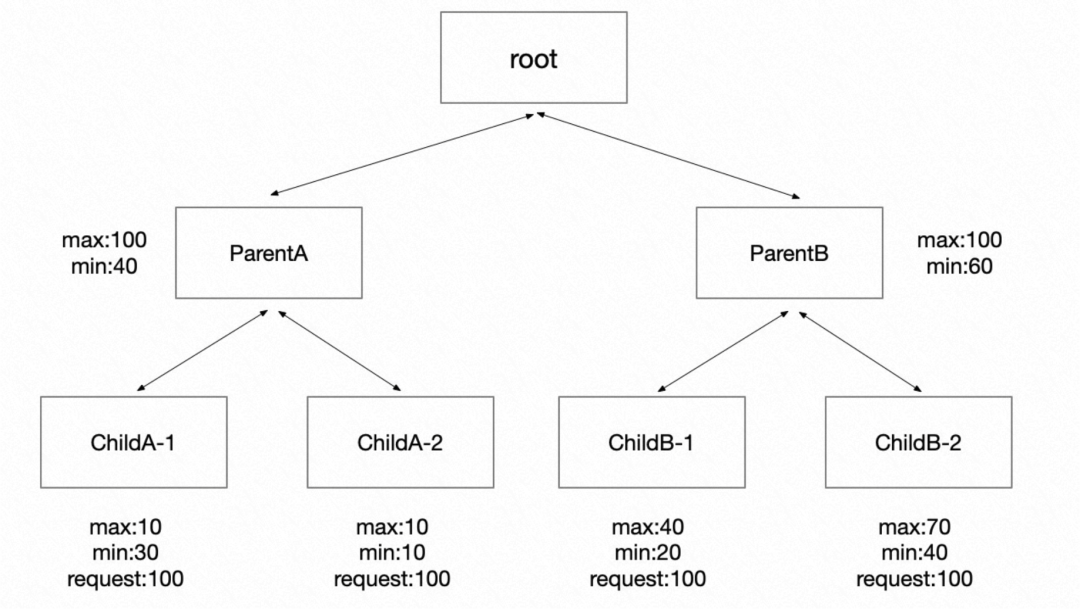
Koordinator 實現了彈性 Quota 調度能力,可以保障租戶間的公平性。我們在設計之初就考慮兼容 scheduler-plugins 社區項目中定義的 ElaticQuota CRD,這樣方便存量的集群和用戶可以平滑的過度到 Koordinator。 另外,我們不僅是兼容 ElasticQuota 原有按照 Namespace 管理 Quota 的能力,還支持按照支持按照樹形結構進行管理,可以跨 Namespace。
這樣的方式可以很好的支持一個復雜的組織的額度管理需求,比如一家公司里多個產品線,每個產品線的預算和使用情況都不一樣,都可以轉為 Quota 進行管理,并借助彈性 Quota,把暫時沒有用到的空閑資源通過額度的形式臨時共享給其他部門使用。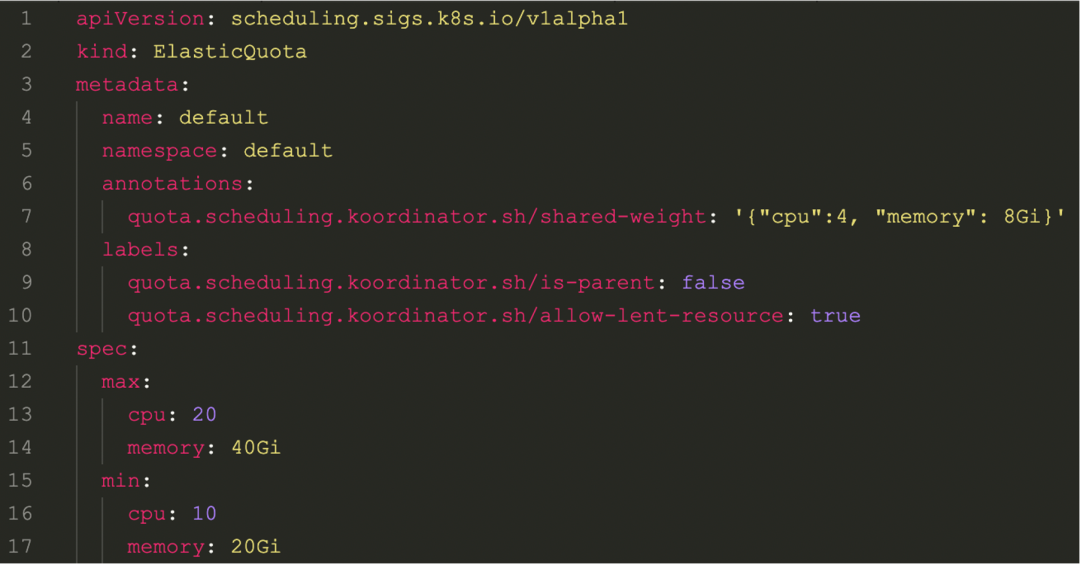 ?
?
Coscheduling
當一個 Job 經過排隊被調度后,Job Controller 會創建出一批子任務,對應到 K8s,就是一批 Pod。這些 Pod 往往需要協調一致的啟動運行。這也就要求調度器在調度時一定要按照一組 Pod 分配資源,這一組 Pod 一定都可以那可以申請到資源或者一旦有一個 Pod 拿不到資源都認為是調度失敗。
這也就是調度器需要提供的 All-or-Nothing 調度語義。 如果我們不這樣按照一組調度,會出現因為多個作業在資源調度層面出現爭搶,是有可能出現資源維度的死鎖,即至少兩個 Job 會出現拿不到資源的情況,即使原本空閑資源足夠其中一個 Job 運行的,也會拿不到。
比如下圖中,Job A 和 Job B 同時創建一批 Pod,如果不在中間的 Scheduling Queue 進行排序而是隨意的調度,就會出現 Job A 和 Job B 的 Pod 各持有了一部分節點的部分資源,如果此時集群資源緊張,很有可能 Job A 和 Job B 都可能拿不到資源。但如果排序后,我們嘗試先讓其中一個 Job 的 Pod 先一起嘗試優先分配資源,那么至少保障一個 Job 可以運行。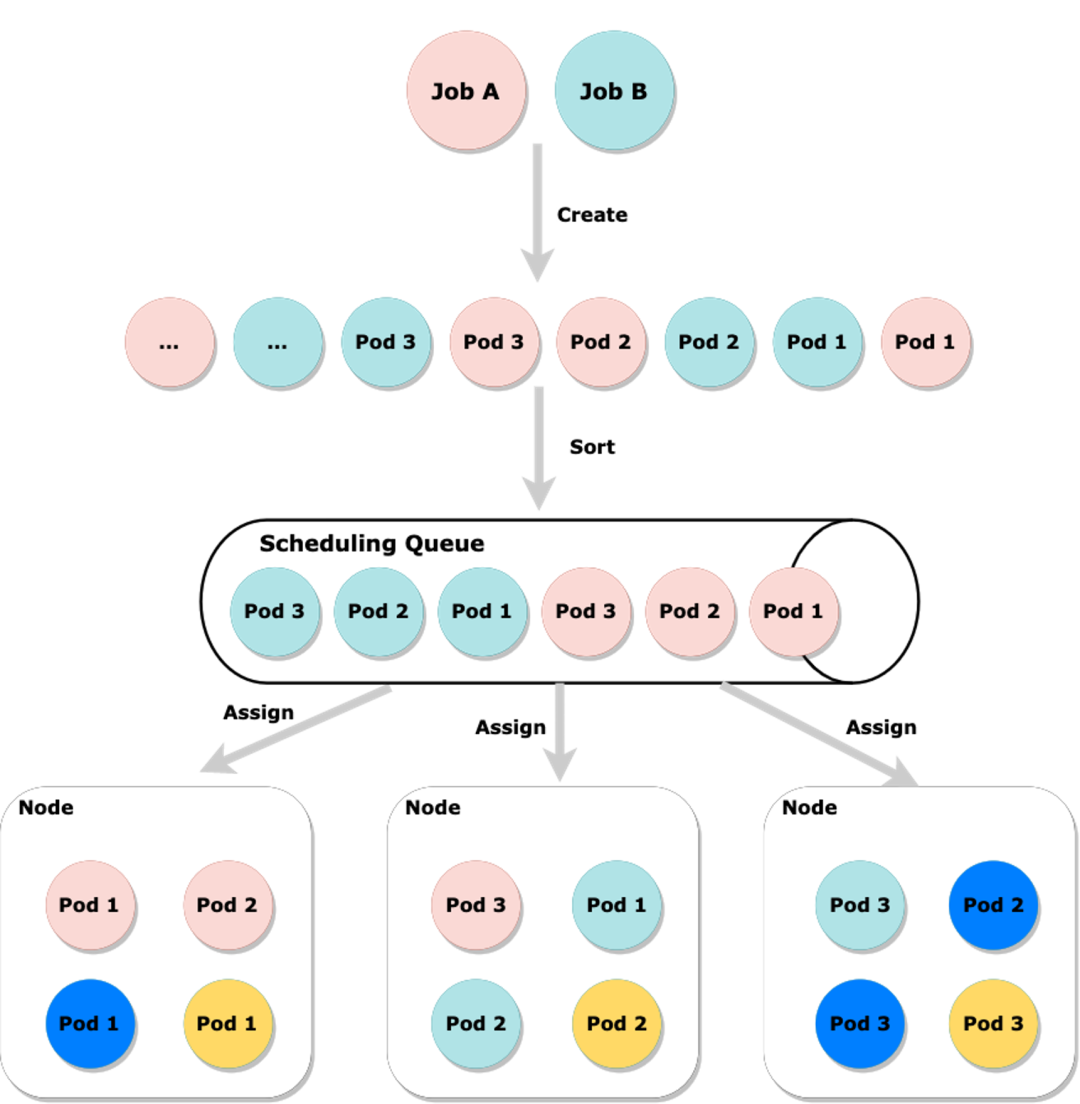
當一個 Job 切分的一組 Pod 非常大時,而集群內的資源又不是十分充足,或者 Quota 不是很多時,可以把這樣的一組 Pod 切分成更多個子組,這個切割的大小以能運行任務為基礎,假設一個 Job 要求最小切割粒度是每組 3 個 Pod,那么這個最小粒度,一般在調度域中稱為 min available。
具體到 AI 模型訓練領域,一些特殊的 Job 比如 TFJob,它的子任務有兩種角色,這兩種角色在生產環境中,也是需要設置不同的 min available 的。這種不同角色的區分的場景還有可能要求每個角色的 min available 都滿足時才可以認為符合 All-or-Nothing 語義。
Koordinator 內置了 Coscheduling 調度能力,它兼容社區的 scheduler-plugins/coscheduling 定義 PodGroup CRD,還支持把多個 PodGroup 聯合調度,這樣就可以支持按角色設置 min available 場景。Koordinator 實現了一個 KubeDL Gang Scheduler 插件,這樣就可以和 KubeDL 做集成一起支撐這類調度場景。
精細化設備管理
Cloud Native
K8s 設備管理的局限性
K8s 是通過 kubelet 負責設備管理和分配,并和 device plugin 交互實現整套機制,這套機制在 K8s 早期還是夠用的,其他廠商如 AMD 和國內的芯片制造商也抓住機會努力追趕。
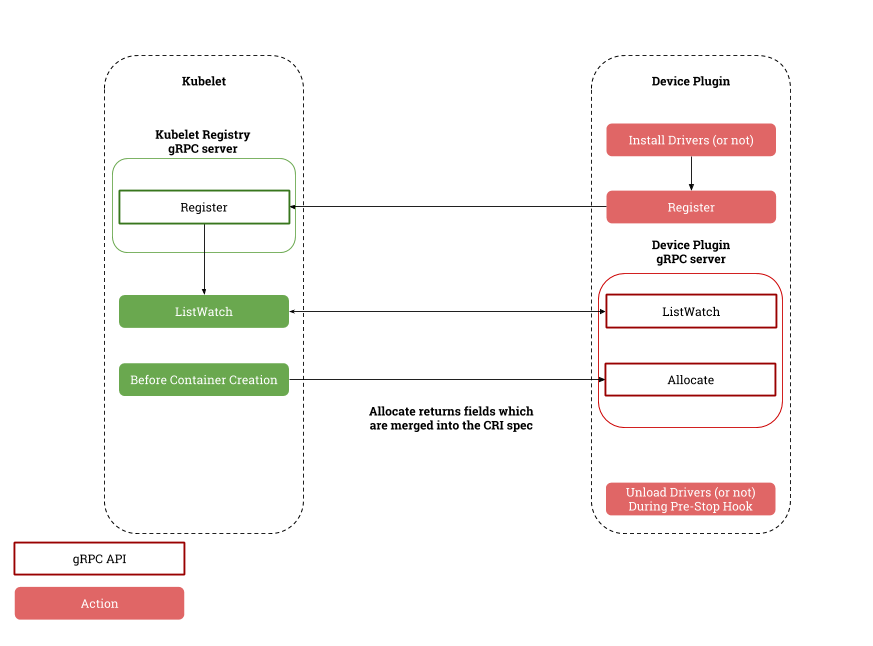
kubelet 與 device plugin 協作流程 首先 K8s 只允許通過 kubelet 來分配設備,這樣就導致無法獲得全局最優的資源編排,也就是從根本上無法發揮資源效能。比如一個集群內有兩臺節點,都有相同的設備,剩余的可分配設備數量相等,但是實際上兩個節點上的設備所在的硬件拓撲會導致 Pod 的運行時效果差異較大,沒有調度器介入的情況下,是可能無法抵消這種差異的。
其次是不支持類似 GPU 和 RDMA 聯合分配的能力。大模型訓練依賴高性能網絡,而高性能網絡的節點間通信需要用到 RDMA 協議和支持 RDMA 協議的網絡設備,而這些設備又和 GPU 在節點上的系統拓撲層面是緊密協作的,比如下面這張圖是 NVIDIA 的 A100 型號機型的硬件拓撲圖,我們可以看到,PCIe Switch 下掛了 GPU 和高性能網卡,我們需要就近分配這兩個設備,才能做到節點間通信的低延遲。
而且這里比較有意思的是,當如果需要分配多個 GPU 時,如果涉及到了多個 PCIe Switch,就意味著需要分配多個網卡,這就和 K8s 的另一個限制有關系,即聲明的資源協議是定量的,而不是隨意變化的,也就是說用戶實際上也不知道這個 Pod 需要多少支持 RDMA 的網卡,用戶只知道要多少個 GPU 設備,并期望就近分配 RDMA 的網卡而已。
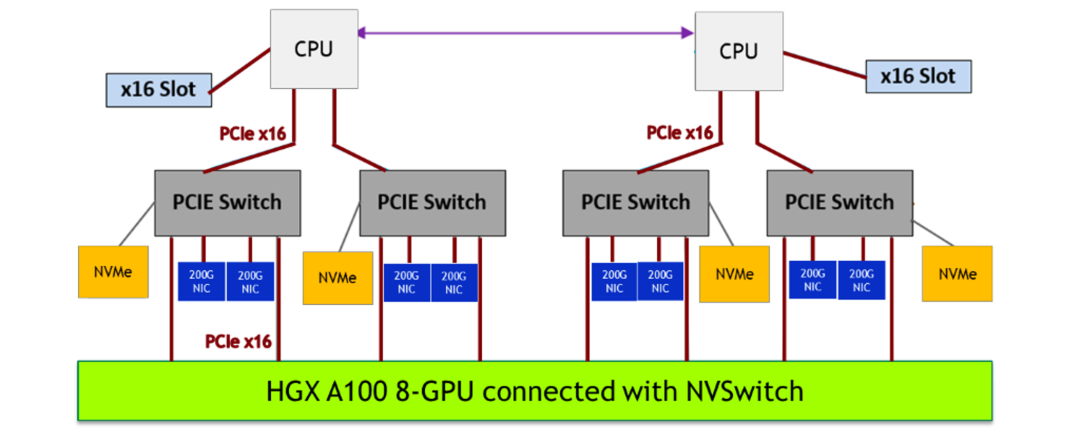
而且 kubelet 也不支持設備的初始化和清理功能,更不支持設備的共享機制,后者在訓練場景一般用不到,但在線推理服務會用到。在線推理服務本身也有很明顯的峰谷特征,很多時刻并不需要占用完整的 GPU 資源。
K8s 這種節點的設備管理能力一定程度上已經落后時代了,雖然現在最新的版本里支持了 DRA 分配機制(類似于已有的 PVC 調度機制),但是這個機制首先只在最新版本的 K8s 才支持,但實際情況是還有大量存量集群在使用,并且升級到 K8s 最新版本也并不是一個小事情,所以我們得想其他辦法。
Koordinator 精細化設備管理機制
我們在 Koordinator 中提出了一種方案,可以解決這些問題,做到精細化的資源調度。
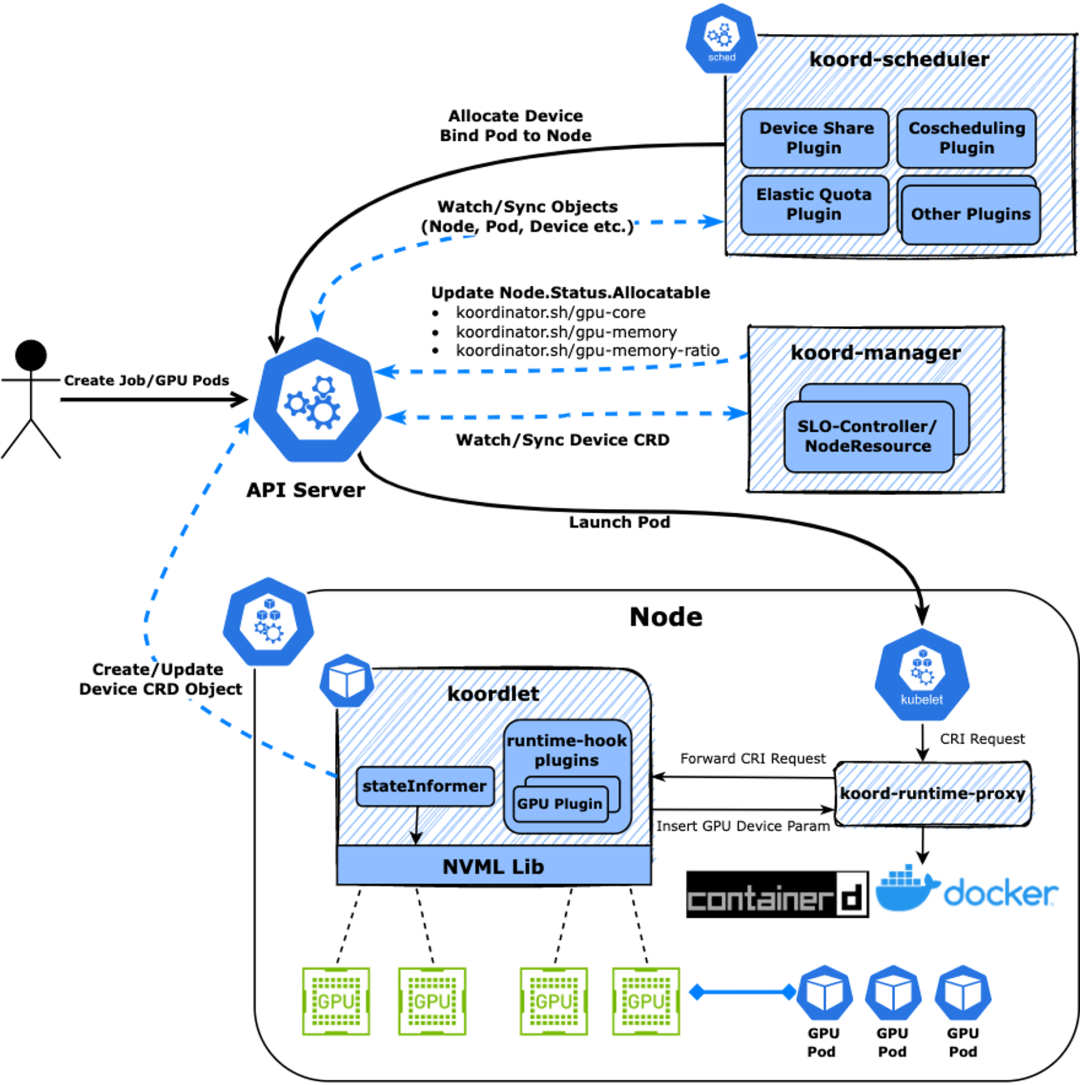
Koordinator 精細化設備管理機制 從上面的圖中可以看到,用戶創建的一個 Pod,由 koord-scheduler 調度器根據 koordlet 上報的 Device CRD 分配設備,并寫入到 Pod Annotation 中,再經 kubelet 拉起 Sandbox 和 Container,這中間 kubelet 會發起 CRI 請求到 containerd/docker,但在 Koordinator 方案中,CRI 請求會被 koord-runtime-proxy 攔截并轉發到 koordlet 內的 GPU 插件,感知 Pod Annotation 上的設備分配結果并生成必要的設備環境變量等信息返回給 koord-runtime-proxy,再最終把修改后的 CRI 請求轉給 containerd/docker,最終再返回給 kubelet。這樣就可以無縫的介入整個容器的生命周期實現自定義的邏輯。 Koordinator Device CRD 用來描述節點的設備信息,包括 Device 的拓撲信息,這些信息可以指導調度器實現精細化的分配邏輯。
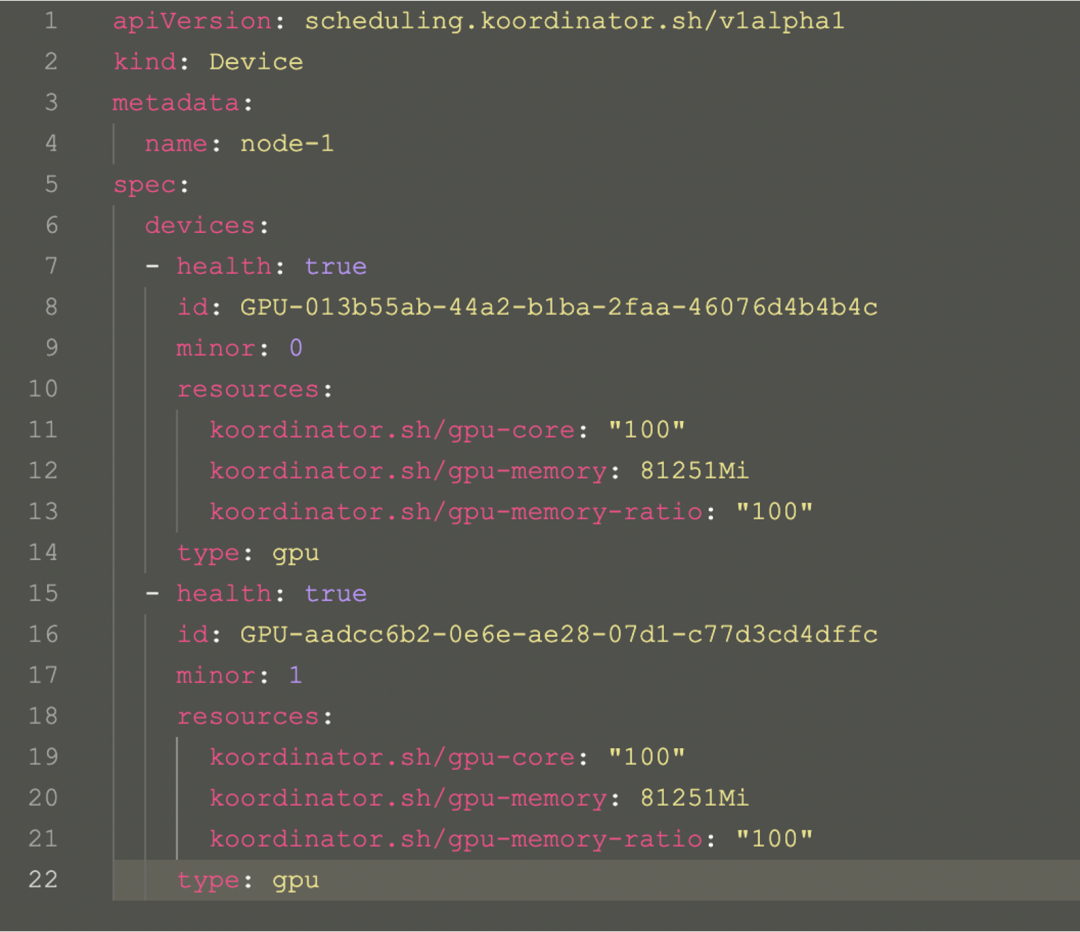
Koordinator Device 對象
Future: NRI 模式
前面提到了 Koordinator 單機側依靠 koord-runtime-proxy 協作完成設備信息注入,我們自己也意識到,koord-runtime-proxy 這種方式其實不太好在大家的集群內落地。這涉及到修改 kubelet 的啟動參數問題。 所以 Koordinator 社區后續會引入 NRI/CDI 等機制解決這個場景的問題。這塊工作正在和 Intel 相關團隊共建。 NRI/CDI 是 containerd 支持的一種插件化機制。其部署方式有點類似于大家熟悉的 CNI,支持在啟動 Sandbox/Container 前后獲得機會修改參數或者實現一些定制邏輯。這相當于是 containerd 內置的 runtimeproxy 機制。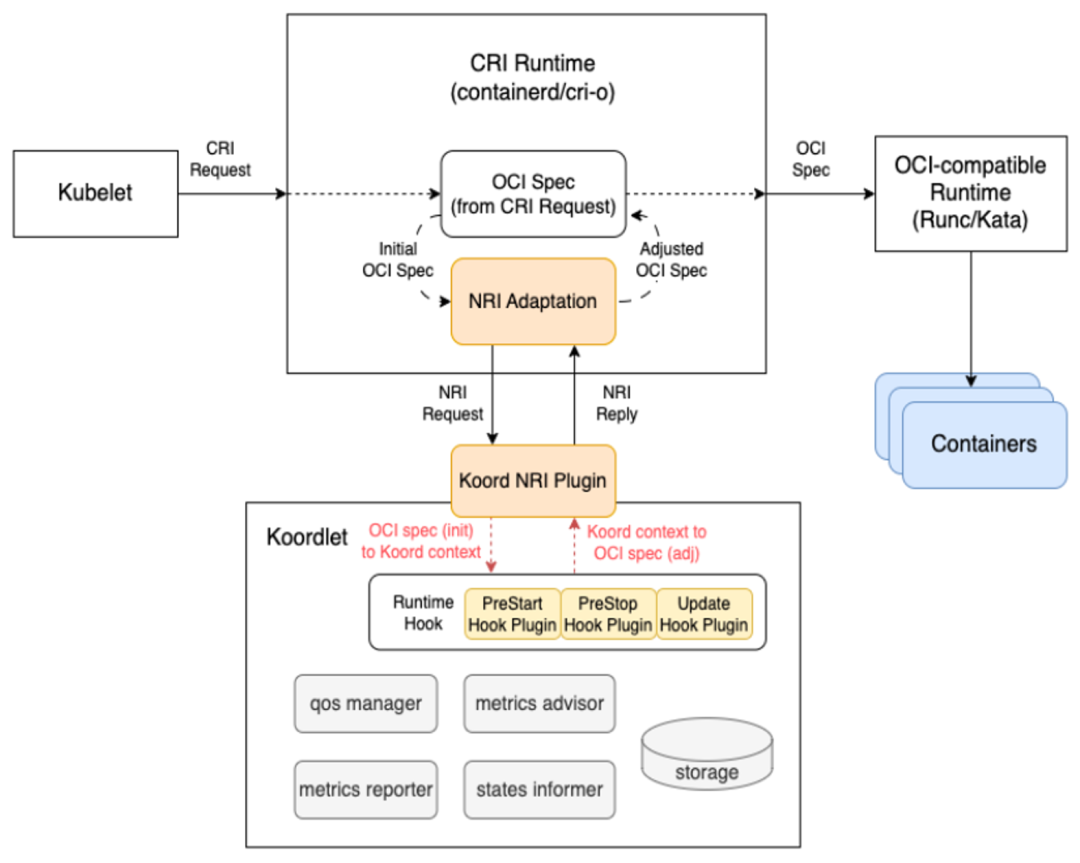 ?
?
GPU&RDMA 按照硬件拓撲聯合分配
前面也提到,大模型訓練不僅僅只用到了 GPU,還依賴 RDMA 網絡設備。要確保 GPU 和 RDMA 之間的延遲盡可能的低,否則會因為設備間的延遲放大到整個分布式訓練網絡中,拖慢整體的訓練效率。 這就要求在分配 GPU 和 RDMA 時需要感知硬件拓撲,盡可能就近分配這種設備。嘗試按照同 PCIe,同 NUMA Node,同 NUMA Socket 和 跨 NUMA 的順序分配,延遲依次升高。 而且我們還發現同一個硬件廠商的不同型號的 GPU,它們的硬件系統拓撲是不一樣的,這就要求我們的調度器需要感知這些差異。比如下圖是 NVIDIA A100 型號的 System Topology 和 NVIDIA H100 的一個簡單的設備連接圖。
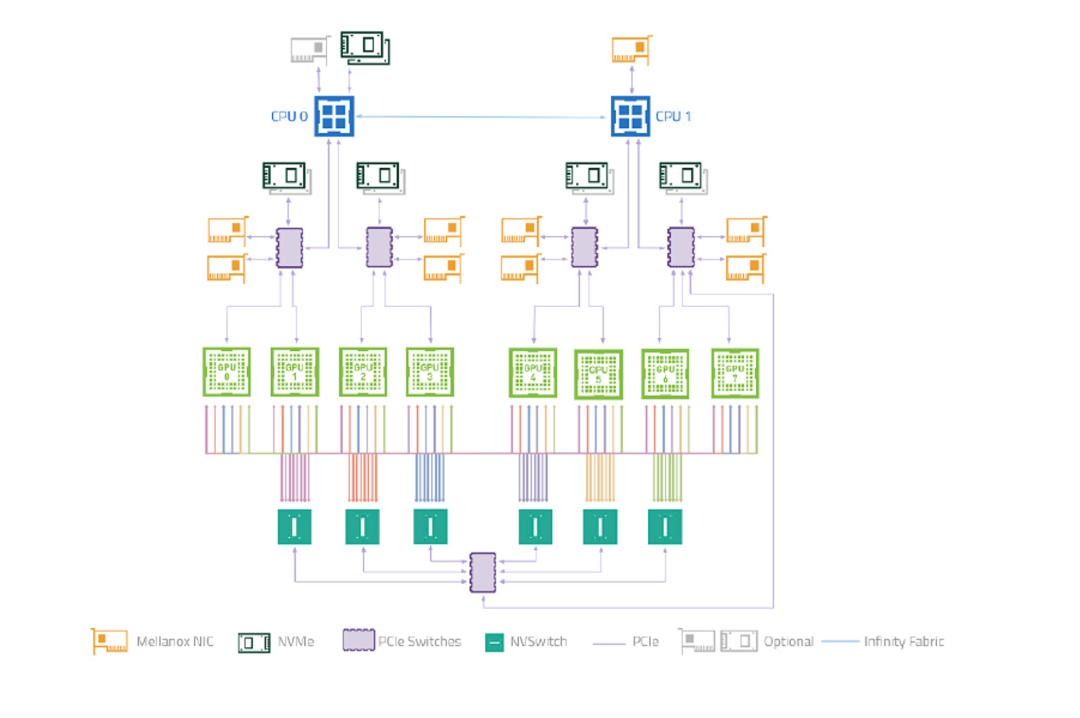
NVIDIA A100 System Topology NVIDIA A100 GPU 之間的 NVLINK 聯通方式和 NVIDIA H100 型號就不一樣,NVSwitch 的數量也不一樣,這種差異就會給使用方式帶來很大的差異。
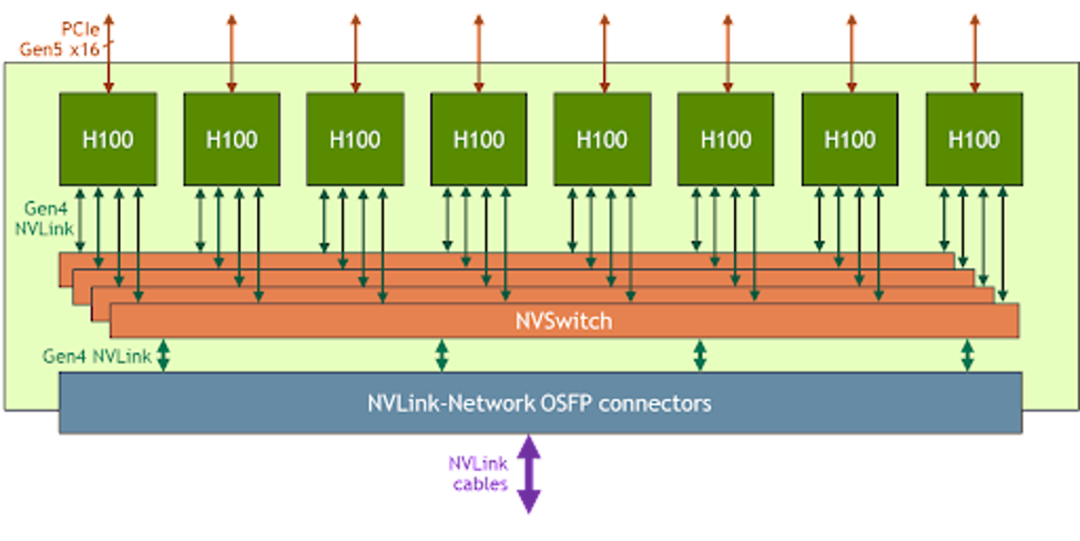
NVIDIA H100
NVIDIA-based system 在多租模式下的差異
NVIDIA H100 GPU 在多租 VM 場景下的特殊之處,多個 GPU 之間聯通需要操作 NVSwitch 才可以實現。 在多租場景中,NVIDIA 為保障安全,會通過 NVSwitch 管理 NVLink 的隔離狀態,并且要求只能由授信的軟件操作 NVSwitch。這個授信軟件是可以自定義的。
NVIDIA 支持多種模式,一種是 Full Passthrough 模式,這種模式把 GPU 和 NVSwitch 都直通到 VM 的 Guest OS,這樣做的好處是使用起來很簡單,但代價是當 GPU VM 多了,NVLINK 的帶寬會減少(原文:Reduced NVLink bandwidth for two and four GPU VMs)。
另一種稱為 Shared NVSwitch 多租戶模式,它只要求把 GPU 直通到 Guest OS,然后通過一個特殊的 VM,稱為 Service VM 管理 NVSwitch,并通過 ServiceVM 調用 NVIDIA Fabric Manager 激活 NVSwitch 實現 GPU 間通信。這種模式就不會出現因為 Full Passthrough 模式的弊端,但使用方式明顯要更復雜一些。
這種特殊的硬件架構和使用方式,還導致在分配 GPU 時有一些額外的要求。NVIDIA 定義了哪些 GPU 設備實例可以組合一起分配,比如用戶申請分配 4個 GPU,那必須是按照規定的 1,2,3,4 號一起或者 5,6,7,8 一起分,否則就會導致 Pod 無法運行。這種特殊的分配方式的背后原因我們不得而知,但分析這些分配約束可以發現,廠商規定的這種組合關系正好符合硬件系統拓撲結構,也就是可以滿足前面講到的 GPU&RDMA 聯合分配期望的分配結果。
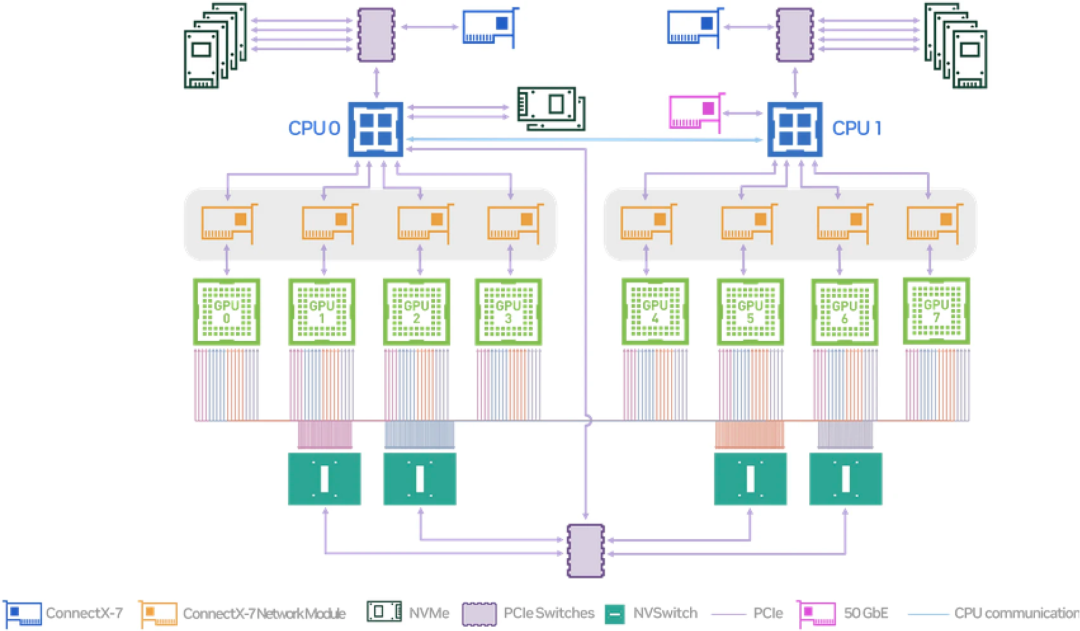
NVIDIA H100 System Topology
審核編輯:劉清
-
驅動器
+關注
關注
52文章
8156瀏覽量
146018 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237579 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45928 -
自然語言處理
+關注
關注
1文章
612瀏覽量
13506 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7495
原文標題:Koordinator 異構資源/任務調度實踐
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機房綜合布線資源管理系統功能介紹
實踐經驗還是理論學習
圖形化的管網資源管理系統功能簡介
異構組網如何解決共享資源沖突?
愛奇藝:基于龍蜥與 Koordinator 在離線混部的實踐解析
WCDMA無線資源管理綜述
WCDMA無線資源管理
網格資源管理模型研究
基于樹形的網格資源管理研究
關于Swarm和Mesos資源利用率優化實踐分析
YARN資源管理器的容錯和架構概述






 工商網監
工商網監
評論