 高端路由器內部的各種組件以及它們如何影響整體功耗研究
高端路由器內部的各種組件以及它們如何影響整體功耗研究
高端路由器——基礎知識
高端路由器通常有兩種形式:獨立系統或模塊化系統。獨立路由器通常是一個 1RU(機架單元)到 3 RU 高的盒子,其前面板具有固定數量的端口,主要用于中小型企業網絡或數據中心內部。
隨著網絡 ASIC 占用的帶寬越來越多,這些獨立系統的吞吐量將達到 14.4Tbps。針對 400G 端口密度進行優化的 14.4Tbps 系統需要前面板容納 36 個 400G 端口,這可能會占據前面板的大部分區域。大于 14.4Tbps 的路由器通常需要 800G 光學器件才能使系統帶寬完全飽和。
線卡包含一個或兩個網絡 ASIC,用于接收來自前面板網絡端口的流量。這些 ASIC 可以通過高速串行器/解串器 (SerDes) 和背板連接器與背板中的所有交換fabric卡進行通信。這提供了任意到任意的連接,其中線卡的網絡端口可以發送和接收來自系統中任何其他線路卡的流量。
這些系統通常有 4-20 個插槽配置。它們的規模更大,客戶可以根據需要靈活地購買線卡來升級帶寬。如今,密度超過 14.4Tbps 的線卡并不罕見。對于 8 插槽機箱,這相當于 115Tbps 的系統帶寬!在這樣的規模下,向線路卡和結構卡內的各種組件供電以及冷卻(消除這些組件產生的熱量)是一項挑戰。
路由器組件
為了更好地了解路由器功率,了解系統內不同組件的功能和功率要求非常重要,它們共同構成了總功率。
前面板/光模塊
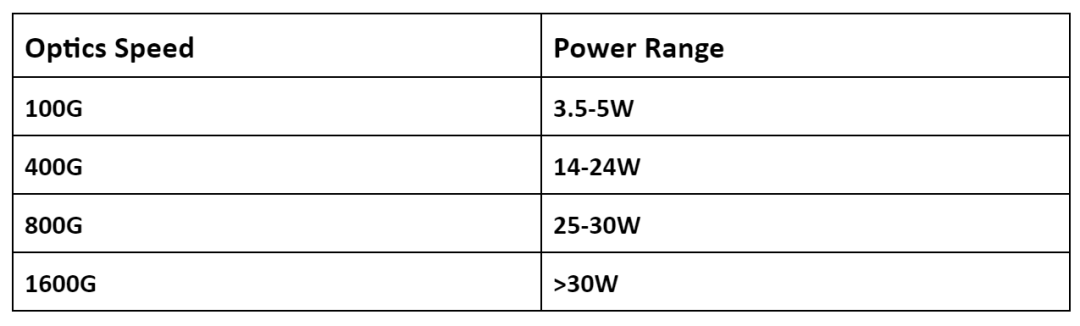
前面板附近有光籠,用于連接光模塊。這些光模塊承載進出系統的網絡流量。光模塊在較高速度下會消耗大量功率。這些模塊所消耗的功率根據模塊的類型和傳輸距離(光信號在沒有信號衰減的情況下可以傳輸的時間)而有很大差異。在36 x 400G 端口的 14.4Tbps 線卡中,光模塊本身在完全填充和加載時可能消耗 500-860W 的功率。類似的,一個 36 x 800G 端口的 28.8Tbps 線卡,光模塊需要約 1100W 的功率。
降低光傳輸過程中的成本/功耗是近十年來研究的熱點話題。
在這方面也不斷有創新,一些供應商提供硅光子收發器,將分立元件集成在光子集成電路中,以減少面積/成本和功耗。用于實現更高數據速率的 PAM4 信號傳輸、不主動傳輸時的低功耗模式以及改進的激光器、光電二極管、調制器和數字信號處理器 (DSP) 電路都有助于降低光學器件的功耗。因此,當在特定范圍內從 400G 光學器件變為 800G 光學器件時,功率僅增加了 1.5 倍,如上表所示。
Flyover cables
Flyover cables是高性能銅纜,可用于將 ASIC 的高速 SerDes 接口連接到前面板光學籠或背板連接器。
隨著系統吞吐量的增加,電路板上的空間有限,幾乎不可能僅使用 PCB 走線來路由所有高速信號。Flyover cables可有效利用電路板空間,不易受到電磁干擾,還可以通過減少信號路徑的電容來幫助降低功耗。然而,如果放置和固定不當,它們可能會對氣流造成一些阻礙,并可能給熱管理系統帶來一些挑戰。
CPU復合
高端路由器中的 CPU 復合體提供在復雜網絡環境中管理和操作路由器所需的控制平面處理、管理配置、安全、服務、監控和報告功能。它有自己的 DRAM 作為外部存儲器。中檔 Intel/AMD 處理器通常用于此復合。
網絡 ASIC
這些芯片是路由器的核心。它們通過跨接電纜或電路板上的 PCB 走線從連接到前面板端口的光模塊接收網絡流量,檢查各種接頭并采取措施。數據包處理描述了檢查數據包標頭并決定后續步驟的任務。
該操作可以是確定數據包必須通過其離開路由器的最終物理接口、排隊并調度從該接口發出、在違反流量規則/檢查時丟棄數據包,或者將數據包發送到控制平面以進行進一步處理、檢查等。這些芯片包含數十億個晶體管來執行這些功能。它們具有數百兆字節的片上內存,用于延遲帶寬緩沖和數據結構,并且通常在封裝中與高帶寬存儲器 (HBM) 集成。網絡芯片消耗了路由器很大一部分功率。
在模塊化系統線卡中使用的網絡 ASIC 還具有連接到背板交換fabric的高速接口。
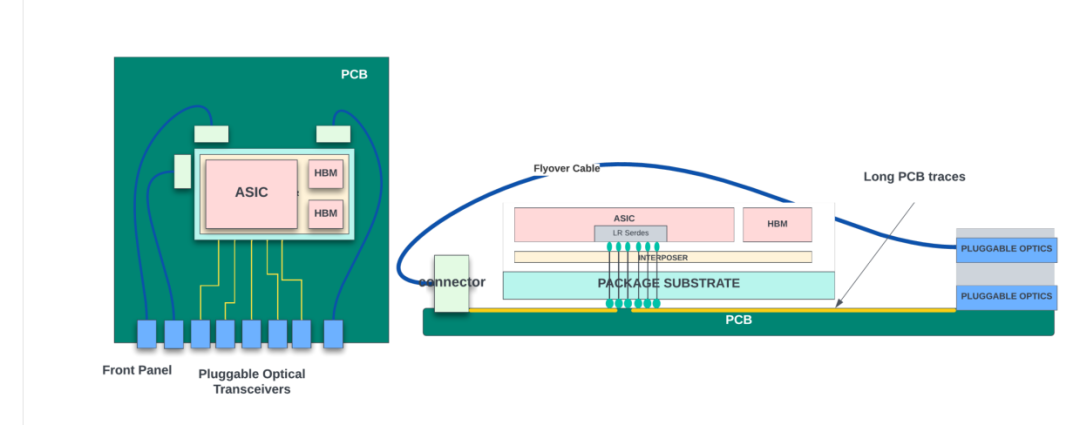
| 具有網絡 ASIC 和光學器件的 PCB 板的概念圖
可選重定時器
網絡 ASIC 通過高速 SerDes 接收來自網絡端口或背板的流量。這些高速 SerDes 將并行數據轉換為串行格式,并通過銅介質(PCB 走線或Flyover cables)高速傳輸。高速信號在傳輸介質中存在信號衰減和退化的情況。
SerDes 的范圍是 SerDes 在不使用信號調節或其他信號增強技術的情況下可以可靠地傳輸數據的最大距離。它由數據速率、傳輸介質類型和傳輸信號的質量決定。由于衰減、失真和噪聲,信號質量在較高數據速率下可能會下降,這使得接收端的信號檢測和解碼變得更加困難,進而SerDes 無錯誤傳輸數據的最大距離也縮小了。
當網絡ASIC向網絡端口傳輸數據時,ASIC內部的SerDes只需將信號驅動至前面板光模塊即可。這些光模塊通常帶有集成重定時器。重定時器是一種信號調節裝置,有助于清理高速數據。它通過捕獲輸入信號并以正確的幅度和時間重新生成信號,從而實現重傳。
在模塊化系統中,當 ASIC 通過交換結構將信號傳輸到另一個線卡時,信號可能會通過線卡走線、連接線卡和交換結構卡之間的連接器以及通過交換結構的走線導致衰減很多。一些高速鏈路可能需要線卡或結構卡中的重定時器。這些重定時器非常耗電,并且它們基本上包含一對 SerDes,用于每個方向的發送和接收。
供電系統
供電系統通常由一個AC/DC轉換器和多個本地降壓DC/DC轉換器組成。大多數系統為 AC/DC 轉換器提供 1+1 冗余。這些轉換器將墻壁插座的交流電轉換為直流電,從而產生約 12-16V 的直流輸出電壓。轉換過程中由于散熱和電阻會造成一定的能量損失。典型轉換器的效率損失在 5-10% 之間。因此,一個2200W AC/DC 轉換器在滿載時可能消耗 2300-2440W 的功率。
網絡系統中的每個組件都需要特定的功率才能運行。所需功率由器件的電壓和電流參數相乘計算得出。某些組件(例如網絡 ASIC)需要多個電壓軌。例如,在典型的網絡 ASIC 中,數字邏輯需要比 SerDes 等模擬組件更小的電壓(0.75-0.90V 之間),而模擬組件的運行可能需要 1-1.1V 之間的電壓。同樣,系統中的CPU和其他FPGA也有自己的電壓和電流要求。
AC/DC轉換器的直流輸出電壓通常為12V或更高。本地 DC/DC 轉換器或負載點 (POL) 轉換器用于將此電壓降壓至各種組件所需的 <1.5V。通過在靠近負載的位置提供電源轉換,POL 轉換器可以提高電源效率、減少電壓降并提高整體系統性能。
這些 POL 轉換器的效率在 90-95% 之間。此外,該系統還配備了熱插拔轉換器,可以保護內部組件免受電流和電壓尖峰的影響。
通過使用高質量元件、最小化元件電阻以及優化開關頻率,可以提高這些 AC/DC 和 POL 轉換器的效率。
配電網絡
電力輸送(或在指定電壓下向系統中的每個組件提供指定電流)通常是通過 PCB 板中的銅跡線完成的,這些銅跡線在電源單元 (PSU) 和 POL 轉換器之間以及從轉換器到系統的各個組件之間傳輸電流。這些銅跡線的電阻有限,因此當電流通過時,它們會耗散功率,這稱為焦耳熱。使用更寬的走線、優化更短的走線、減少過孔、多個電源層以及探索其他低電阻材料作為銅走線的替代品等方式都可以用來減少焦耳熱。
轉換器的低效率和通過銅跡線的功耗將要求為系統提供比所有組件消耗的總功率更大的功率。
熱管理系統
所有組件(光學器件、CPU、ASIC、重定時器、轉換器)在運行過程中消耗電能時都會產生熱量。如果熱量不能有效消散,可能會使組件內部過熱并導致其失效或故障。
例如,在 ASIC 中,結溫(晶體管結溫)是晶體管內兩種不同半導體材料相遇的接觸點處的溫度。結溫隨著晶體管功耗的增加而增加。結溫影響晶體管的性能和可靠性。半導體制造商設定了最高結溫,超過該結溫 ASIC 就不再可靠,通常還會導致晶體管永久損壞。因此,任何熱管理解決方案都應在結溫超出規格之前有效地消除 ASIC 散發的熱量,從而使 ASIC 的結溫保持在規格范圍內。同樣的,其他系統組件也都有自己必須滿足的溫度規格。
>散熱片
熱管理系統主要由散熱器和風扇模塊組成。散熱器基本上由銅或鋁等導熱材料組成。它們直接位于芯片上方,與 ASIC 封裝或無蓋封裝中的 ASIC 芯片本身直接接觸,有助于將熱量從芯片中散發出去。這些散熱器的設計是為了最大化與ASIC的接觸面積。
散熱器也集成了頂部的均熱板。均熱板是一種由薄金屬片制成的密封容器,里面裝著少量工作流體,例如水或酒精。散熱器將熱量傳遞至均熱板,這導致液體蒸發并變成蒸汽,然后蒸氣移動到腔室的冷端,凝結成液體,將其吸收的熱量釋放到周圍空氣中。
液體被輸送回腔室的加熱端,在那里可以再次蒸發。通過將均熱板集成到散熱器中,可以顯著提高散熱器的散熱能力。散熱器表面有小而薄的矩形突出物,稱為翅片。這些翅片平行排列,以增加散熱器的表面積,有助于更快地散熱。散熱器是無源元件,不需要任何電源即可運行。
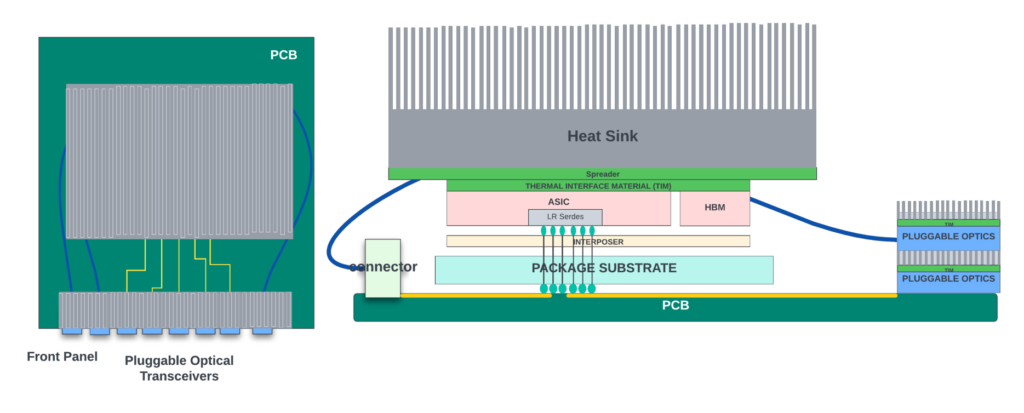
| 頂部附有散熱器的 ASIC 概念圖
網絡ASIC不會在整個芯片區域均勻地耗散功率。有一些熱點或功率密度非常高的區域。這是因為晶體管和存儲器并不是均勻分布在整個芯片上,某些 IP/邏輯可以看到更高的晶體管活動(例如 SerDes 和數學密集型加密/解密邏輯)。熱工程師使用軟件來模擬存在這些熱點的散熱器性能,并提出散熱器設計參數來處理這些它們。在某些情況下,這些 IP /邏輯的放置需要根據這些模擬的反饋在芯片平面中進行調整,以減輕熱點效應。
>風扇模塊
每個系統還包含多個風扇模塊,用于排出產生的熱量。當系統啟動時,風扇開始旋轉并產生空氣流過機箱,冷卻內部組件并排出熱空氣。風扇從機箱前部吸入冷空氣,并通過后面板排出熱空氣。
風扇速度可根據內部組件的溫度自動調節。溫度傳感器位于機箱的不同位置。網絡 ASIC 和 CPU 還集成了熱二極管,用于測量這些芯片的結溫。如果組件的溫度超過特定閾值,風扇將自動加速以提供額外的散熱。為了使風扇有效工作,空氣流動應暢通無阻。
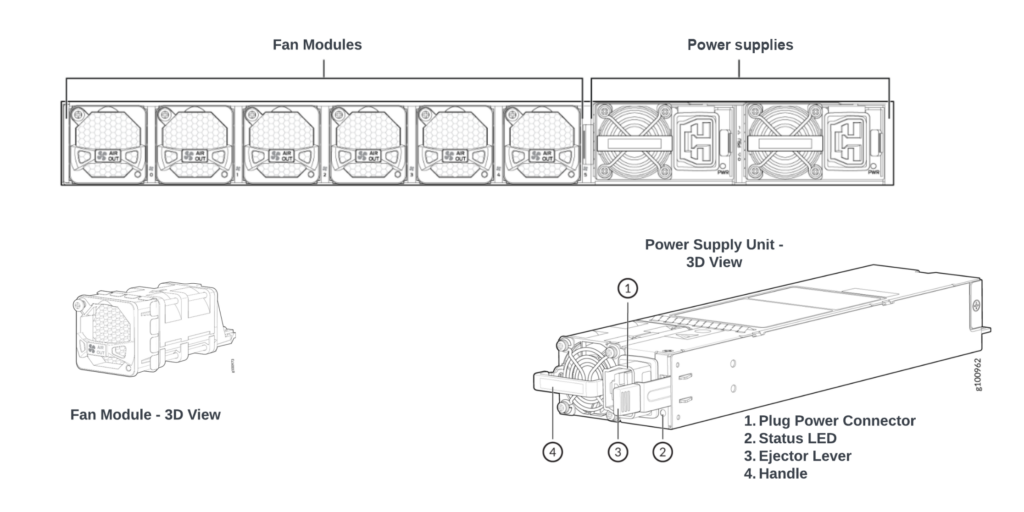
| 帶有風扇模塊和電源的獨立路由器后面板
| 帶有風扇和電源的模塊化系統后面板
**液體冷卻 ** (作為散熱器/空氣冷卻的替代品)在消除高功率 ASIC 散發的大量熱量方面更有效。在液體冷卻中,液體冷卻劑流過一系列與系統中的熱部件直接接觸的管道(閉環)。當液體吸收組件的熱量時,它會變得更熱。較熱的液體流向散熱器或熱交換器,將熱量散發到空氣或其他冷卻劑中。
然而,與空氣冷卻相比,液體冷卻的前期成本更高,實施和維護起來也更昂貴、更復雜。并非所有電子元件都設計為與液體冷卻系統一起使用,因為這就要求系統同時支持兩種冷卻模式,進一步增加了成本。
系統電源
>獨立系統
所有有源組件都貢獻了系統消耗總功率的一部分,但他們之間的差異很大。為了了解功率故障,這里以一個具有14.4Tbps網絡芯片和36 x 400G前面板端口的假設獨立系統為例。每個組件的最小和最大功率通常在下表中列出的范圍內。
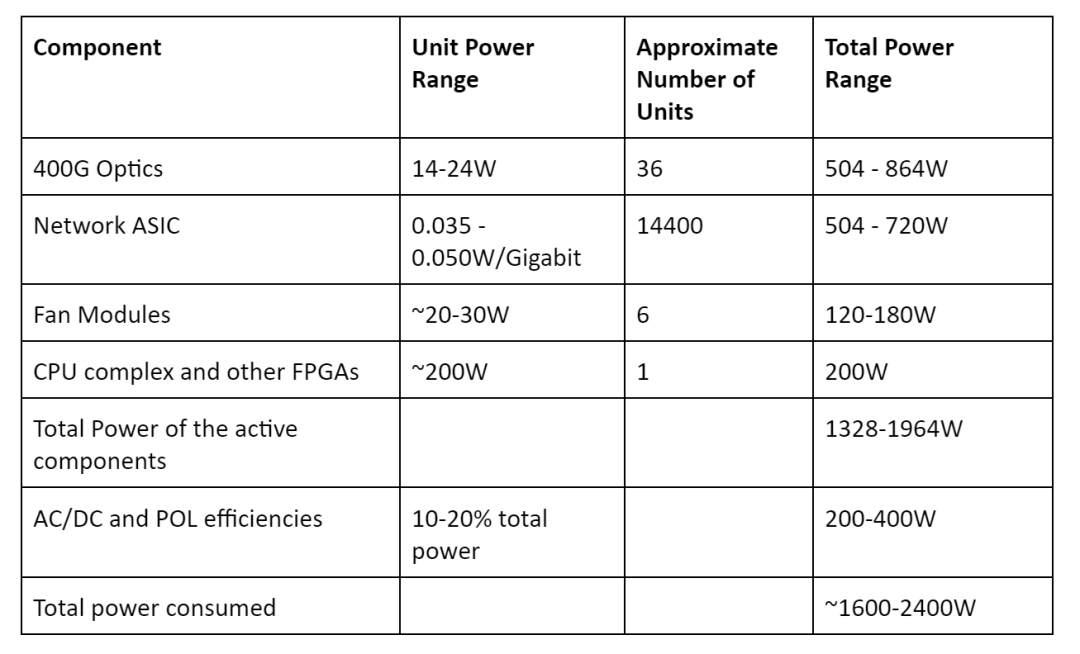
| 網絡 ASIC 占系統總功耗的很大一部分
從表中可以看出,網絡 ASIC 的功耗占系統總功耗的很大一部分。一個典型的高端網絡芯片在 7/5nm 工藝節點中可以獲得 0.035 - 0.055W 的每 Gbps 功率。光學器件消耗的功率與網絡 ASIC 相同或更高,具體取決于插入的光學模塊的類型。AC/DC 和 POL 轉換器的效率損失對總功率影響很大。如果為任何 WAN 端口添加重定時器和變速箱,也會增加功率。
請注意,系統消耗的總功耗在很大程度上取決于流量模式和網絡端口上的總負載。但是,對于熱電源設計,需要考慮最壞情況下的功耗。
>模塊化系統
在模塊化系統中,線卡中的網絡 ASIC 可能比獨立的對應器件消耗更多功率,因為它們可能需要通過高速 SerDes 接口向背板中的交換fabric卡發送/接收高達 100% 的流量。風扇模塊和電源單元通常位于機箱背面,滿足所有線卡和交換fabric卡的需求。交換fabric卡消耗的功耗在很大程度上取決于fabric交換芯片的設計。
基于單元的交換效率更高,需要的fabric交換機和高速接口數量更少。因此,對模塊化機箱功率進行一般估計是很困難的。假設每個LC功率至少為2400W,16槽模塊化系統中的16個線卡消耗高達38KW功率!各個組件之間的功率分配遵循與獨立系統相同的趨勢(ASIC 和光學器件消耗超過 60-70% 的系統功率)。
設計低功耗網絡芯片
隨著系統總吞吐量的增加,網絡ASIC所占系統功率的比例也相應增加。網絡芯片的高功耗面臨著一些挑戰。
能夠高效地將電力傳輸至 ASIC,且在傳輸過程中不會出現重大損耗。
能夠有效地散發 ASIC 產生的熱量,使 ASIC 的結溫保持在規格范圍內。由于單芯片和多芯片封裝內功能的大量集成,可能會產生高功率密度的熱點,因此這一點變得越來越具有挑戰性。
在下面的部分中,讓我們看看網絡芯片供應商用來降低功耗的不同技術。在引用 ASIC 功率時,我們經常使用“每千兆比特每秒功率”這個術語,因為絕對功率數可能會根據每個 ASIC 支持的總吞吐量(以 Gbps 為單位)而變化。
任何集成電路消耗的功率都由三個主要部分組成:泄漏功率、有功功率和短路功率。
>泄露功率
泄漏功率是 ASIC 通電后、ASIC 內的任何時鐘開始切換之前消耗的功率。即使晶體管沒有開關,該功率也會由于流過晶體管的漏電流而消耗。
泄漏功率已成為使用先進工藝節點制造芯片中的一個重要問題。這是因為較小的晶體管具有較短的溝道長度和較薄的柵極氧化物,這可能導致較高的漏電流。隨著晶體管尺寸的縮小,同一芯片區域中可以封裝更多的晶體管,從而導致更多的漏電流。
漏電流還取決于晶體管的結構。FinFET晶體管結構(用于臺積電7 nm和5nm工藝)比CMOS 結構具有更好的泄漏特性。臺積電 3nm 工藝采用的全柵 (GAA) 晶體管架構提供了更嚴格的控制,因為柵極四面包圍通道,并且電荷載流子泄漏的表面積較小,從而減少了泄漏電流。
泄漏功率是電源電壓 (Vdd) 和泄漏電流的乘積,也就是說在較小的電源電壓下可以降低泄漏功率,但當晶體管的閾值電壓與電源電壓之間的差值減小時,泄漏電流本身可能在較小的Vdd下增加。雖然漏電流略有增加,但電源電壓的降低總體上降低了漏功率。然而過度降低電源電壓可能會影響晶體管的性能。因此,在選擇 ASIC 的工作電壓時必須仔細權衡。
電源門控,其中電源電壓在啟動時被切斷,用于未使用的邏輯部分(例如,如果某個功能可以針對某些網絡應用被禁用),也可以消除通過未使用邏輯的泄漏電流。然而,這伴隨著電壓軌實施的額外復雜性,并且只有確保能明顯節約的情況下才考慮。
>動態功率
ASIC 的動態或有功功率由開關功率和短路功率組成。開關功率是芯片中的邏輯元件在開/關時消耗的功率。這是由于與晶體管和互連相關的電容的充電和放電造成的。該功率與晶體管和互連的電容 (Ceff)、邏輯元件的開關頻率 (f) 以及電源電壓 (Vdd) 的平方成正比。ASIC 的總開關功率是所有邏輯(組合門、觸發器、模擬電路和存儲單元)開關功率的總和。
>短路功率
短路功耗是當數字電路的輸出從一種邏輯狀態切換到另一種邏輯狀態,并且 n 型和 p 型晶體管同時導通,從而為電流從電源到地創造了一條直接路徑(Isc)而導致的功率損耗。短路功率是一種瞬態效應,僅在兩個晶體管都導通的短暫時間間隔內發生。該間隔的持續時間取決于電路的開關頻率和供電電壓水平。因此,該功率與電源電壓 ( Vdd ) 和頻率 ( f )成正比。仔細布局庫元件可以減少晶體管之間的重疊并限制短路功率:

在降低功耗方面,主要關注的是降低動態功耗(因為在典型 IC 中動態功耗占總功耗的 75% 以上)。
降低動態功耗的方法包括降低時鐘頻率、總開關活動、互連和晶體管電容以及電源電壓。所有這些都有各自的挑戰和優缺點。讓我們回顧一下這些功耗降低技術。
最佳電源電壓 (Vdd) 選擇
由于“平方”依賴性,降低工作電壓會顯著影響功率。二十年前,我們可以每兩到三年將晶體管性能提高一倍,同時降低其運行所需的工作電壓 (Vdd)。例如,180nm 工藝節點的典型電源電壓約為 2.5V,而在 45nm 工藝節點則降至約 1.1V。在 14 nm工藝節點中,該電壓進一步降至約 0.90V。
但是,隨著轉換器尺寸的縮小,要在不影響晶體管性能的情況下顯著降低每一個新的處理節點的供電電壓變得越來越困難。因此,從 7nm 工藝節點開始,工作電壓的改進幾乎停止了,工作電壓徘徊在 0.75V - 0.85V 之間。大多數硅代工廠為每個電壓軌提供一個范圍)。
一些代工廠提供電壓分級(voltage binning),根據芯片的工藝節點(快與慢),可以調整工作電壓。快角的芯片具有更快的晶體管。我們可以利用這一點,降低工藝角落芯片的電源電壓,使其在不降低性能的情況下消耗更少的功率。不過這需要制造商的支持,根據工藝特性對 ASIC 芯片進行分類。
工作頻率選擇
降低操作頻率很顯然是會降低功耗的,但同時它也會降低性能,因為 ASIC 無法足夠快地處理數據包并通過現有數據路徑移動它們。然后,為了從網絡系統獲得相同的總體吞吐量,我們必須在 ASIC 內部添加更多邏輯,或在線卡/系統中添加更多 ASIC。兩者都會增加系統的總功率/成本。
具有每秒數十太比特帶寬的高端網絡芯片通常具有數據包處理單元和數據路徑。數據包處理單元可以在固定管道架構中實現,也可以運行到完成架構中實現。
假設在固定管道架構中,一個數據包處理管道每個周期可以接收一個數據包。在 1.25GHz 時鐘頻率下,這相當于每秒 12.5 億個數據包。如果我們希望將下一代處理管道的性能提高到每秒 14 億個數據包,顯而易見的選擇是將時鐘頻率提高到 1.4GHz。在這個更高的時鐘頻率下,管道中的每個階段都必須在更短的時間內完成相同數量的處理。
如果我們切換到下一代 ASIC 的新處理節點,預計邏輯速度至少會提高 20-30%。如果我們想保持 1.25GHz 頻率以降低功耗怎么辦?在這種情況下,要每秒獲取 14 億個數據包,管道每個周期需要處理 1.12 個數據包。這很難實現,因為它不是一個整數值。在這種情況下,設計人員傾向于將邏輯過度設計為每個周期處理2個數據包。這樣做將需要幾乎雙倍的邏輯量,這將占用更多的芯片面積和功耗。
類似地,在數據路徑內部,如果頻率降低以獲得相同的千兆/秒性能,則需要加寬在芯片內部承載數據包數據的總線(往返于 WAN 端口到中央緩沖區和其他結構),以便在每個周期承載更多的比特。當總線加寬時,會增加頂層的擁塞,需要通過提供更多的布線區域來緩解,從而增加芯片的尺寸。
內部存儲器 (SRAM) 在頻率決策中也發揮著關鍵作用。SRAM 性能可能不會隨著頻率的提高而擴展,因此為了實現邏輯存儲器,我們將被迫使用多個堆疊在一起的較小 SRAM 結構,這增加了額外的開銷和SRAM訪問時間。在決定操作頻率時,需要在多個不同的頻率下對片上緩沖區和數據庫、它們到庫中的SRAM的映射以及每個邏輯內存如何分片進行詳細分析。
ASIC 調度和 IP(實現特定功能的模塊)重用也在頻率選擇中發揮作用。在某些情況下,重用現有IP以加快周轉是非常可取的。在這種情況下,我們受到現有IP在沒有任何設計更改的情況下可以運行的最大頻率的限制。
因此,頻率選擇涉及到最佳功率、性能和面積設計點的多重權衡。在一個芯片中看到多個時鐘域的情況并不少見,其中不同的子系統可以使用不同的頻率進行計時。它增加了時鐘樹結構的復雜性,并增加了設計和驗證時間,但與對 ASIC 的所有功能使用相同的頻率相比,它可以提供更好的設計點。
減少開關活動
如前所述,ASIC 中的邏輯門和觸發器在其輸出改變狀態時會消耗開關功率。關鍵的是要確保如果觸發器的輸出沒有在特定的時鐘周期中使用,它就不應該在該周期中切換。這可以通過時鐘門控來實現,即在不使用觸發器輸出的周期中移除(或門控)觸發器的時鐘,因此觸發器輸出保持與前一個周期相同的狀態。通過這樣做,由該觸發器提供的所有組合邏輯的切換也會減少,這被稱為動態時鐘門控。
當設計者以特定格式編寫觸發器的代碼時,EDA工具在合成(將Verilog行為RTL代碼轉換為門)期間推斷出動態時鐘門控。但采用這種方法的時鐘門控效率在很大程度上取決于設計者在識別所有時鐘門控機會方面的專業知識。有一些功能強大的 EDA 工具可以識別設計中的所有時鐘門控機會,有些甚至可以在 RTL 中自行進行時鐘門控。使用先進的 EDA 工具,網絡芯片的動態時鐘門控效率可達到 98% 以上。
此外,某些功能/IP 可以進行靜態時鐘門控。例如,如果網絡芯片提供集成的 MACsec,并且如果某些應用程序/客戶不需要此功能,則整個模塊可以從啟動時間開始進行時鐘門控。
工藝/技術節點選擇
制造ASIC的半導體工藝在整體功耗中也起著關鍵作用。在十年之前,每個新的工藝節點都可以在相同的面積內封裝雙倍數量的晶體管,并獲得比以前的工藝節點雙倍或更高的功率效率。
過去幾年這一趨勢有所放緩。例如,當從 5nm 工藝節點轉向 3nm 工藝節點時,功耗僅提高了 30%(對于相同的性能)或 1.42 倍。大部分的改進來自邏輯,而存儲能力的改進微乎其微。這意味著即使我們可以通過從 5nm 升級到 3nm,將 ASIC 封裝內的吞吐量提高一倍,也會多消耗 42% 的功耗。當網絡系統的容量翻倍時,硬件工程師需要為 ASIC 的額外功耗做好預算。
隨著工藝節點的縮小,制造變得更加復雜并且需要更高的精度。這可能導致設備和生產成本增加。由于更小的特征尺寸和更高的晶體管密度,成品率也會降低。這導致客戶的每芯片成本增加,而且為新工藝節點開發 SerDes 和其他 IP 的成本可能會很高。此外,在較小的工藝節點上構建芯片通常需要使用更先進和更昂貴的材料,這會增加生產成本。
總的來說,與7nm芯片相比,5/3nm芯片的制造成本更高。但是,如果我們可以用下一代工藝節點將ASIC封裝內的密度提高一倍,而不會使功率增加一倍,那么它仍然可以節省系統的整體成本(因為系統中其他組件的成本,如機箱硬件、CPU復合體、PCB板、熱管理等,并不總是增加一倍)。因此,在決定過程節點時必須考慮整體系統成本和功率效率。
高能效數據路徑/處理架構
正如在前一節中所看到的,在增加ASIC和系統的吞吐量時,僅改進工藝節點是不足以降低功耗的。高能效ASIC架構在降低網絡ASIC整體功耗方面也起著重要作用。
網絡 ASIC 架構隨著時間的推移不斷發展,以解決以下限制:
SRAM 的面積/功耗沒有像新工藝節點上的邏輯那樣擴展。
盡管晶體管密度不斷提高,但新工藝節點的功耗并沒有多大改善。
外部存儲器的擴展速度也不夠快,無法跟上邏輯擴展的速度。在這方面,雖然 HBM(ASIC 封裝內的高帶寬內存)供應商通過使用新的內存節點、堆疊更多芯片以及提高HBM和ASIC芯片之間的數據傳輸速率,大約每 3 年將這些內存的性能和密度提高一倍。但每個 HBM 部件提供的帶寬遠不及網絡芯片所支持的數據吞吐量。
例如,每個 HBM3P部件理論上可以提供 8Tbps 的原始總數據速率。由于讀/寫周轉和其他瓶頸導致總線效率損失 20%,這足以緩沖 3.2Tbps 的無線接入網絡 (WAN) 流量。高端網絡芯片供應商希望在每個 ASIC 封裝中封裝 >14.4Tbps。顯然,并非所有流量都可以使用單個 HBM 部件進行緩沖。添加更多 HBM 部件可能會占用 WAN 端口所需的芯片邊緣區域。
這意味著簡單通過將數據路徑切片加倍來使下一代 ASIC 吞吐量加倍的方式是不可行的。對片上和外部存儲器的訪問需要盡可能地優化。為了實現這一目標,網絡供應商使用了各種技術:
# 具有淺片上延遲帶寬緩沖器的超額訂閱外部延遲帶寬緩沖器
在這種架構中,數據包首先在片上緩沖區中排隊,只有擁塞的隊列才會移動到外部存儲器。隨著擁塞減少,這些隊列移回到片上緩沖區。這減少了總體數據移動以及與之相關的功耗。
# 虛擬輸出隊列 (VOQ) 架構
在這里,所有延遲帶寬緩沖都在入口數據包轉發實體 (PFE) 或切片中完成。數據包在入口 PFE 的虛擬輸出隊列中排隊。VOQ 唯一對應于數據包需要離開的最終 PFE/輸出鏈路/輸出隊列。數據包通過出口處的復雜調度程序從入口 PFE 移動到出口 PFE,僅當它可以將數據包調度出其輸出鏈路時,該調度程序才會從入口 PFE 提取數據包。與組合輸入和輸出隊列 (CIOQ) 架構相比,VOQ 架構中的數據移動較少。這會導致開關功率降低。
# 固定管道數據包處理
處理網絡協議標頭時,在專用硬件中對解析/查找和標頭修改進行硬編碼可以實現高效的實現,從而節省數據包處理過程中的面積和功耗。為了獲得面積/功耗優勢,所有高端網絡供應商都已轉向固定管道處理。
# 共享數據結構
當在一個芯片中集成多個 PFE 或切片時,一些網絡芯片供應商共享大型數據結構,這些數據結構在這些切片上保存路由表 (FIB) 和其他結構。這樣做會增加對這些共享結構的訪問次數。但是,在大多數情況下,這些大型邏輯結構是使用許多離散的 SRAM 組來實現的,并且訪問可以在客戶端和組之間靜態復用。由于內存控制邏輯需要適應的熱存儲和無序讀取返回,這可能導致訪問時間不確定。通常,面積/功耗優勢超過了控制邏輯的復雜性。
但是,當將數據結構移動到集中位置時,往返于集中內存的路由所消耗的功率有時可能超過內存訪問功率。因此,架構師在共享數據結構時需要考慮權衡。
# 高速緩存(Cache)
高速緩存的層次結構可用于減少對具有時間或空間局部性的共享結構(片上或外部存儲器)的訪問。這減少了長電線上的數據移動,從而減少了功耗。
# 布隆過濾器
這是一種流行的方法,用于減少對駐留在外部內存中的哈希表或查找表的訪問次數。布隆過濾器是一種節省空間的概率數據結構,用于測試元素是否是集合的成員。該數據結構通常保存在片上 SRAM 中。探測布隆過濾器中的“鍵”可以指示它是否存在于片外表中。使用這種方法可以將某些網絡功能對中央和片外存儲器的訪問減少 70-80%。
# 壓縮數據結構
某些數據結構可以被壓縮和存儲,以減少讀取這些結構時的內存占用和切換功率。
# 系統級封裝 (SiP) 與小芯片的集成
在過去的三到四年里,小芯片設計的發展勢頭迅猛,多個小芯片(ASIC核心)可以集成在一個具有低功耗芯片接口的封裝中,如UCIE或短距離serdes(XSR)。
# 功能蠕變
最后,功耗與芯片設計以線速處理的功能數量成比例增加。一些可能不需要線速處理的功能可以轉移到CPU復合體中,由軟件來處理,以節省面積/功耗。這些網絡通常具有較大的最大傳輸單元 (MTU),即可以在網絡上發送的最大數據包大小。因此,核心網中很少需要對數據包進行分段。在這些情況下,網絡芯片不需要在線實現此功能。然而,芯片應該檢測到需要分段或重組的數據包,并將它們發送到 CPU 復合體進行處理。
同樣,通過仔細分析用例和對利基功能使用替代方法來最大限度地減少功能蠕變對于降低功耗至關重要。
微架構注意事項
如果芯片模塊沒有采用高效的微架構,那么高效架構所提供的部分或全部節能優勢就會喪失。塊微架構在很大程度上取決于設計者的專業知識。以下是需要關注的部分:
# 過度流水線
添加比實現功能所需的更多的流水線階段。
# SRAM 選擇不當
單端口 SRAM 在功耗/面積方面比兩個或雙端口 SRAM 更高效。需要正確規劃 SRAM 訪問以選擇正確的 SRAM 類型。類似地,使用算法存儲器增加某些數據結構的端口數量以進行同時訪問確實有助于降低面積/功耗。
# 沒有優化邏輯內存以提高功耗
SRAM 庫供應商通常提供內存編譯器,讓用戶輸入邏輯內存尺寸,編譯器會為該內存提供不同的內存/平鋪選項。這些編譯器可以根據用戶提供的權重在總體面積和功率之間取得平衡。
# 過度緩沖
一些設計傾向于在處理過程中多次緩沖數據/控制邏輯。而且緩沖區往往會被過度設計。需要詳細檢查緩沖區及其大小,以移除填充。
# 設計重用
設計重用有時可能會造成傷害。雖然重用有利于項目進度,但這些設計可能沒有最佳的微架構或實現技術來節省電力。
物理設計考慮因素
在過去的十年里,用于芯片/模塊布局規劃和布局的EDA工具在優化網表和布局以降低功耗方面取得了長足的進步。這些工具通過物理設計感知 RTL 綜合、優化數據移動的 P&R、位置感知時鐘門控、回收非關鍵路徑上的功率等來降低功耗。
這些工具可以接受用戶輸入的各種流量場景,并優化物理設計以降低峰值功率。利用 EDA 工具的進步進行物理設計可以比通過前面提到的其他技術實現的動態功耗額外降低 4-5%。
EDA 工具還支持功率門控、動態電壓/頻率降低或多電壓/頻率島方法,并在RTL合成和物理設計階段為實現這些技術提供自動化和檢查。
雖然提高能效對于高端 ASIC 來說是一件好事,但如果沒有可量化的目標,它可能會導致架構和實施方面的各種變化,從而增加進度延遲和投片后問題的風險。必須與硬件和產品管理團隊合作,為 ASIC 定義功率目標(每 Gbps 功率),并在整個開發階段持續估計和監控功率,以保持正常運行。
在架構階段,功耗估算通常使用基本技術來完成,例如從先前的設計進行推斷以及使用新工藝節點的擴展。在設計實現階段,多種 EDA 工具可以隨著設計通過 RTL 和 P&R 的進展來估計和監控功耗,為工程師提供節能機會的選擇和建議。
光學新趨勢
在OFC 2023會議上,多家供應商展示了用于數據中心和企業應用的線性驅動(或直接驅動)非 DSP 可插拔短/中程光模塊的原型系統。這些光模塊沒有耗電的 DSP 電路,并使用線性放大器來轉換電信號和光信號。
這與傳統的相干收發器形成鮮明對比,傳統的相干收發器使用 DSP 和相位調制器進行這種轉換。這些系統依賴于網絡 ASIC 內部的長距離 (LR) SerDes 功能強大,以彌補光學器件內部 DSP 的不足。
線性驅動光模塊非常節能,一些供應商聲稱與傳統光收發器相比,節能高達 25%。在 800Gbps/1.6Tbps 速度下,使用線性驅動光學器件可以顯著降低系統成本和功耗。
寫在最后
盡管本文主要關注用于降低網絡芯片和光學器件功耗的趨勢和技術,但考慮每個新系統設計中所有系統組件的功耗以及冷卻和熱管理解決方案的效率同樣重要。
例如,即使是AC/DC轉換器效率的微小改進,也可以在高功率系統中顯著節省功率。盡管最初的前期成本很高,但在每秒處理數百兆比特的模塊化系統的生命周期內,投資液體冷卻也可以顯著節省成本。
隨著ASIC架構師的優化選擇用盡,技術節點的節能開始減少,探索降低系統功耗和冷卻成本的替代解決方案至關重要。讓我們繼續推動 ASIC 內外的創新,使網絡系統更高效,更具成本效益。
審核編輯:劉清
-
轉換器
+關注
關注
27文章
8627瀏覽量
146869 -
連接器
+關注
關注
98文章
14317瀏覽量
136163 -
路由器
+關注
關注
22文章
3707瀏覽量
113541 -
解串器
+關注
關注
1文章
104瀏覽量
13225 -
ASIC芯片
+關注
關注
2文章
91瀏覽量
23722
原文標題:高端路由器功耗性能大作戰:優化網絡芯片和光學器件
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論