 CVPR 2023 中的領域適應:用于切片方向連續的無監督跨模態醫學圖像分割
CVPR 2023 中的領域適應:用于切片方向連續的無監督跨模態醫學圖像分割
CVPR 2023 中的領域適應:用于切片方向連續的無監督跨模態醫學圖像分割
前言
我們已經介紹過 3 篇 CVPR 中的典型領域適應工作,他們三篇都是 TTA(Test-Time Adaptation)的 settings,而這次要介紹的文章是 UDA(Unsupervised domain adaptation)的 setting。之前的三篇文章分別是:
CoTTA
EcoTTA
DIGA
在這篇文章中,提出了 SDC-UDA,一種簡單而有效的用于連續切片方向的跨模態醫學圖像分割的體積型 UDA 框架,它結合了切片內和切片間自注意力圖像轉換、不確定性約束的偽標簽優化和體積型自訓練。與以前的醫學圖像分割 UDA 方法不同之處在于它可以獲得切片方向上的連續分割(這一點有點重要,因為往往臨床上都是一個 3D 數據,而直接處理 3D 數據又需要很大的計算資源),從而確保更高的準確性和臨床實踐中的潛力。
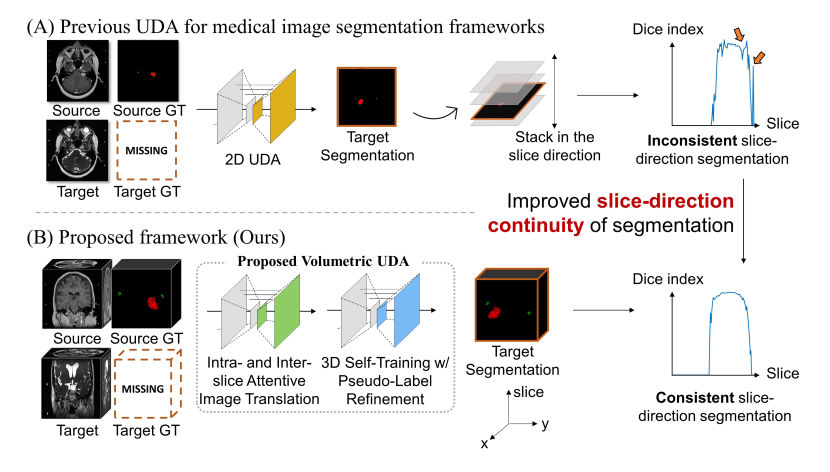
如上圖所示,以前的醫學圖像分割 UDA 方法大多采用 2D UDA,當將預測堆疊在一起時,會導致切片方向上的預測不一致。SDC-UDA 在翻譯和分割過程中考慮了體積信息,從而改善了分割結果在切片方向上的連續性,可以看到在圖的最右側,下面方法的 Dice 值在切片方向上是穩定的。
此外,我們全文中提到的“體積”這個詞,可以理解為 3D 數據。
體積型 UDA 框架概述
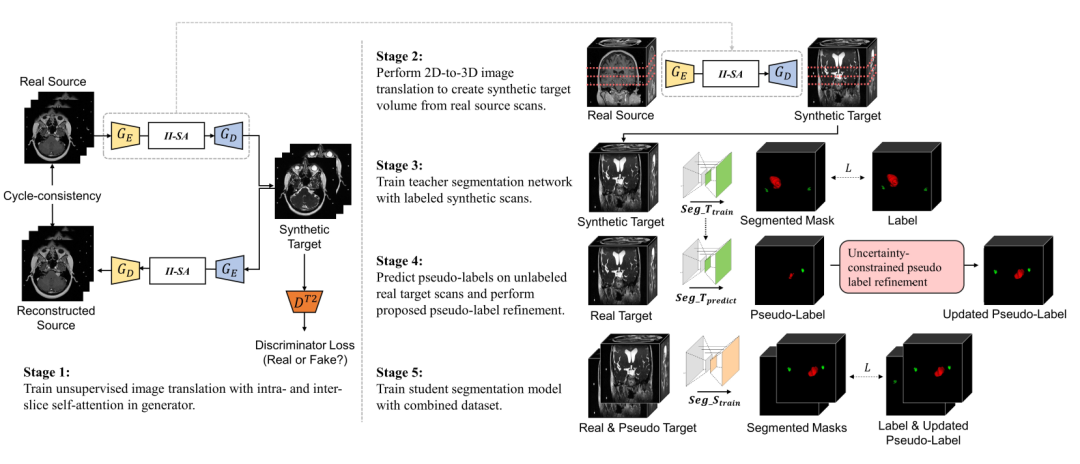
如下圖所示,SDC-UDA 大致有五個步驟,從 stage 1 到 stage 5:
stage 1:帶有片內和片間注意力的對抗學習過程,這一步是 stage 2 的基礎,stage 2 是該步驟的上半部分。后面會單獨用一個小節介紹。
stage 2:target 模態數據生成,假如 source 數據模態是 MRI,那么在這個步驟我們會得到 3D 的 CT 和對應的 label。
stage 3:把生成的 target 數據和 label 送入到教師網絡訓練。
stage 4:將真實的不帶標簽的 target 數據輸入到 stage 3 的教師網絡得到偽標簽,并通過不確定性抑制優化偽標簽。
stage 5:將生成的 target 數據、真實 target 數據和他們的標簽用于優化學生網絡,最終的預測也是在學生網絡上。
請添加圖片描述
具體實現
Unpaired 圖像轉換
先前的 2D UDA 方法將 3D 體積分割成 2D 切片,并在之后將它們的轉換重新堆疊成 3D 體積。由于切片是單獨處理的,重新構建轉換后的體積通常需要額外的后處理,如切片方向插值,但這仍然無法完全解決切片方向不連續等問題。為了解決 2D 方法缺乏對體積性質的考慮和 3D 方法的優化效率問題,這篇文章提出了一種簡單而有效的像素級領域轉換方法,用于醫學圖像體積數據,通過使用切片內部和切片間自注意力模塊將一組源域圖像轉換為目標域圖像。與先前的 2D 方法只在單個切片內進行轉換,而這篇文章的方法利用了切片方向上相鄰切片的信息。這類似于最近在視頻處理中的進展,它利用了幀內部和幀之間的信息。與需要昂貴計算成本的 3D 方法相比,不需要大量計算(下采樣)。
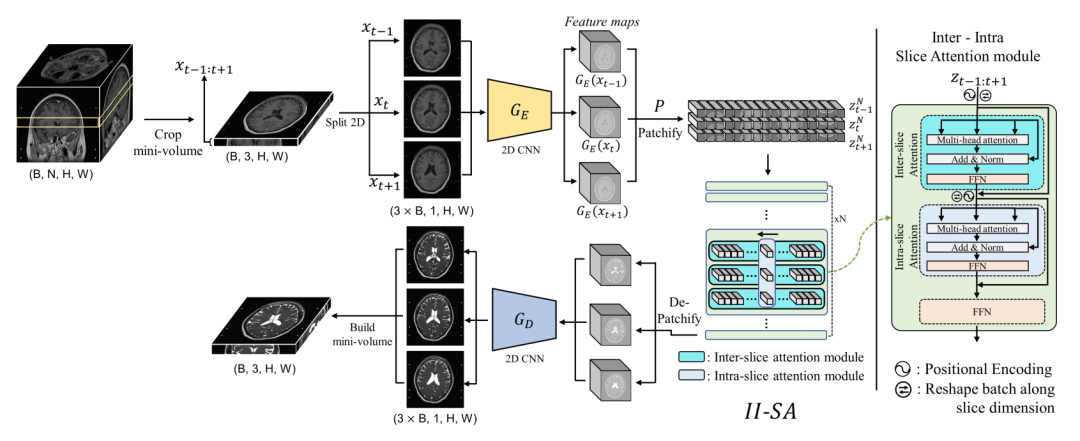
如上圖所示,首先我們將一個 3D MRI 數據裁剪出 3 張切片,輸入到 CNN 的 encoder中,encoder 的輸出是三張切片的 feature maps,即在通道維度上被卷積。然后我們在長和寬的方向上裁剪 patches,這樣會得到若干個 patch 塊,輸入到帶有片內和片間的切片注意力模塊中。這個注意力模塊就是很普通的多頭注意力、殘差和 FFN 的兩次組合。最后我們做相反過程的 decoder,這時生成的圖像應該是 target 模態的。為了方便理解,可以再去看看我們在上一節提到的 stage 1,對應 stage 1 的上半部分。
stage 1 除了包括上面提到的這個過程,還包括重建的反過程(下半部分),這樣我們才能計算一致性的 loss,同時利用對抗學習的判別器,完成自監督的訓練。
體積自訓練和偽標簽優化
我們已經介紹了概述中第一個 stage,這一節對應后面三個 stage。
通過從源域轉換的合成數據 x?t 和注釋 ys(即帶標簽的合成數據集),我們首先訓練一個教師分割網絡 teacher,該網絡最小化分割損失:
訓練完教師模型,可以通過將真實的目標域數據 xt 傳遞給訓練好的分割模型 teacher,獲取未標記真實數據的偽標簽 y?t。
由于 teacher 預測出的偽標簽是噪聲標簽,必須對其進行改進,以提高準確性并引導自訓練朝更好的方向發展。這篇文章設計了一種增強敏感性(SE)和特異性(SP)的偽標簽改進模塊,該模塊基于圖像強度、當前偽標簽和不確定性區域(高于閾值)來改進偽標簽。
通過預測出的偽標簽,計算與每個類別相對應的不確定性(即熵)圖:
其中 p 是每個類別的輸出概率圖。為了增強偽標簽的敏感性,檢測超出偽標簽范圍的高度不確定的區域。然后,如果該區域中的像素強度在當前偽標簽包含的圖像強度的某個范圍內,該區域將被包括為偽標簽的一部分。該公式可以表示為:
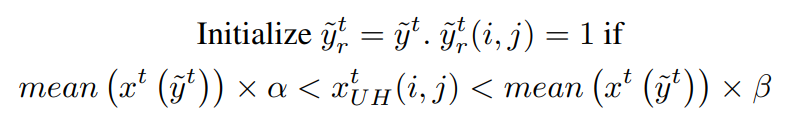
其中 分別表示目標域圖像、偽標簽、改進的偽標簽和裁剪了高不確定性區域掩碼。該方法基于假設:在醫學圖像中,具有相似強度且相互接近的像素很可能屬于同一類別。
為了增強偽標簽的特異性,也是檢測偽標簽范圍內的高度不確定的區域。區別是,如果該區域中的像素強度不在當前偽標簽包含的圖像強度的某個范圍內,則將其從當前偽標簽中排除。可以表示為:
上面這個流程,文章中給出了圖示如下,有助于理解這個流程:
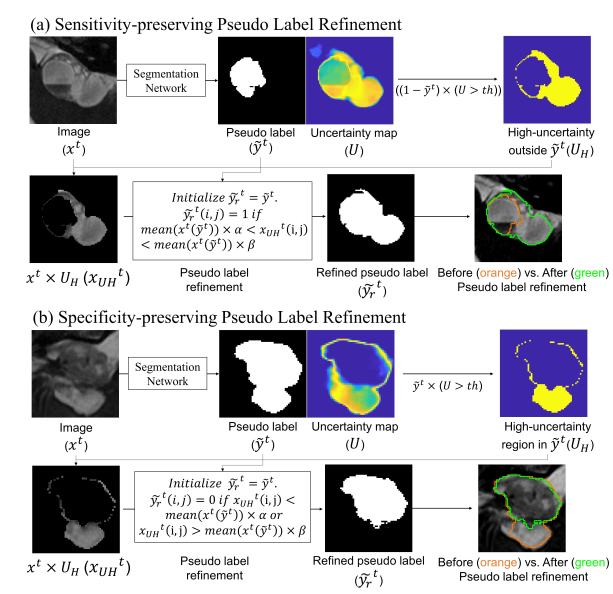
請添加圖片描述
在 stage 5 中,合成的 target scans 與真實 target scans 存在分布差異。這篇文章將這兩種配對數據結合到自訓練中,以最大程度地提高泛化能力,并最小化由于分布差異而引起的性能下降。把帶標簽的合成 target scans 和帶偽標簽的 target scans 的數據合并,訓練一個學生分割模型 student,以最小化以下損失:
實驗
下表是 SDC-UDA 與以前的非醫學圖像和醫學圖像 UDA 方法之間的定量結果的比較。該表包括非醫學圖像 UDA 方法(例如 cycleGan、cycada、ADVENT 和 FDA)的結果,以及最近的醫學圖像 UDA 方法(例如 SIFA 和 PSIGAN)的結果。對比發表在 TMI 2020 上的 PSIGAN 方法,DICE 指標上提升了很多,特別是從 T1 到 T2 的跨模態設置。MRI 到 CT 也有顯著的提升。
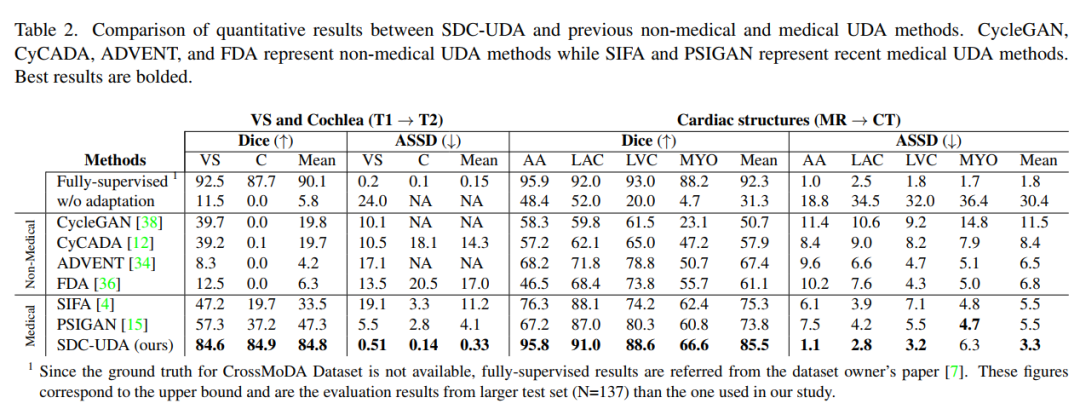
請添加圖片描述
可視化結果比較如下圖:
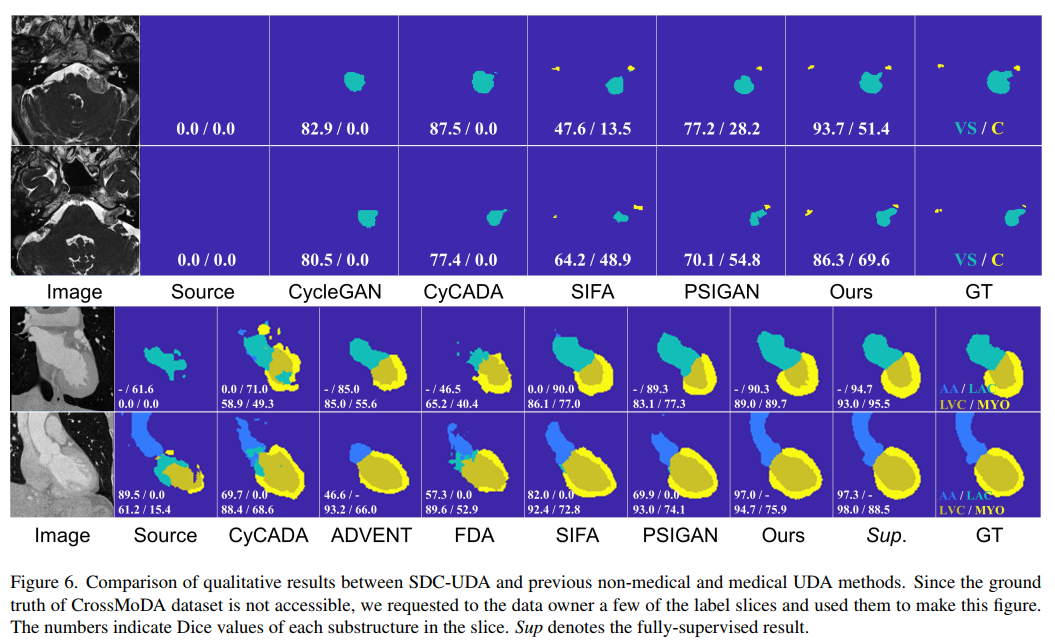
請添加圖片描述
總結
這篇文章提出了 SDC-UDA,一種用于切片方向連續的跨模態醫學圖像分割的新型 UDA 框架。SDC-UDA 通過切片內部和切片間的自注意力有效地轉換醫學體積,并通過利用不確定性圖,設計簡單而有效的偽標簽細化策略。通過體積級自訓練更好地適應目標域。
現在的 SDC-UDA 框架中,只有 stage 1 是不需要訓練 3D 圖像的,后面的過程仍然是 3D 的訓練(可能出于準確率的角度),也需要消耗更多的計算資源,其實也是可以優化成一組堆疊切片的。
參考
https://arxiv.org/pdf/2305.11012.pdf
-
3D
+關注
關注
9文章
2864瀏覽量
107341 -
框架
+關注
關注
0文章
399瀏覽量
17437 -
圖像分割
+關注
關注
4文章
182瀏覽量
17981
原文標題:CVPR 2023 中的領域適應:用于切片方向連續的無監督跨模態醫學圖像分割
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCB中的平面跨分割
基于MLP的快速醫學圖像分割網絡UNeXt相關資料分享
深度學習在醫學圖像分割與病變識別中的應用實戰
全面解讀CVPR2021-MMAct挑戰賽跨模態動作識別雙冠方案
快速HAC聚類算法的改進及應用于無監督語音分割

跨圖像關系型KD方法語義分割任務-CIRKD
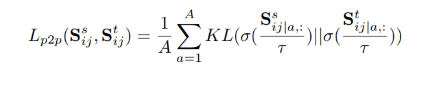
基于Diffusion Probabilistic Model的醫學圖像分割
CVPR 2023 | 完全無監督的視頻物體分割 RCF






 工商網監
工商網監
評論