 wenet的優化
wenet的優化
wenet概述#
wenet處理流程#
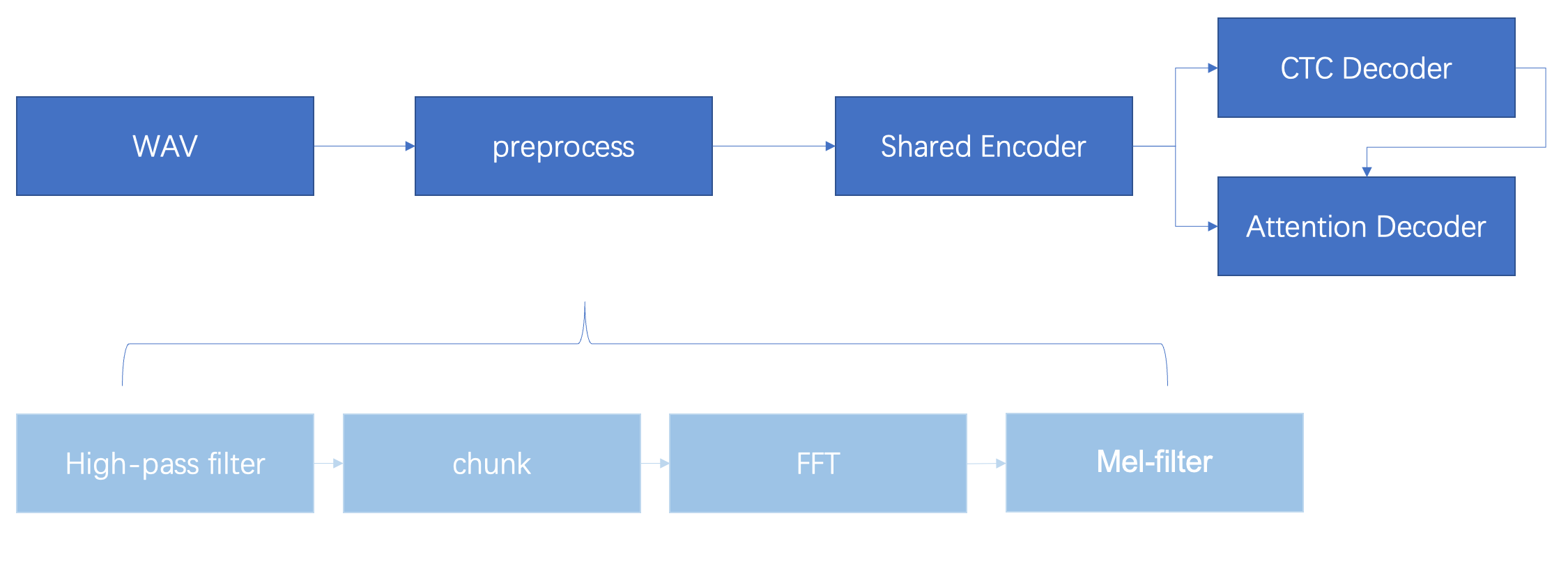
wav語音經過一系列前處理之后送入encoder,encoder的輸出會給到ctc decoder和attention decoder。其中ctc decoder是深度優先的搜索程序,負責搜索出n段候選預測序列,然后ctc的結構與encoder的結果一起送入attention decoder進行預測序列的打分,選出最好的預測序列,輸出結果
模型結構#
encoder#
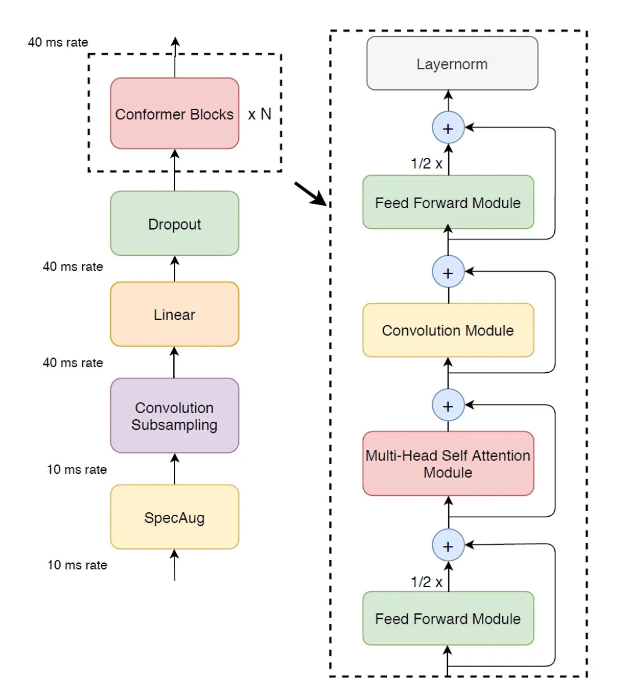
encoder是12個conformer模塊堆疊
decoder#
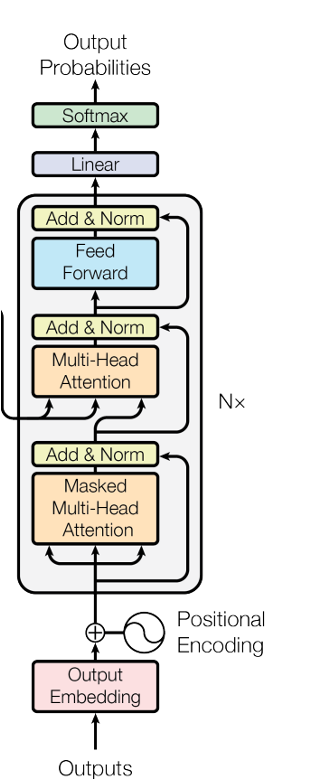
decoder基本結構是transformer,先經過字的自注意力再和mel特征進行交叉注意力,wenet的decoder是雙向decoder,有一個預測序列從左到右的打分,還一個從右到左的打分,每個decoder堆疊3個transformer(取決于訓練時的配置文件,也可以是6個)
模型優化#
圖優化#
結合netron觀察模型圖結構,考慮以下幾個優化方向
刪除冗余算子
算子融合
改變算子執行順序
Where(MaskedFill)的優化#
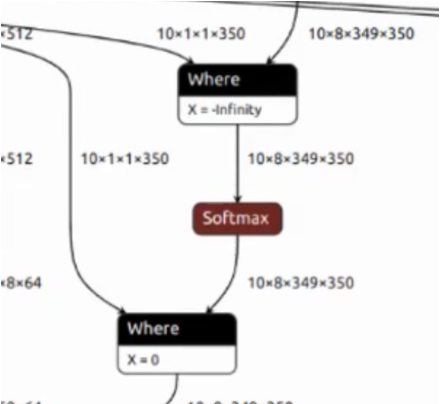
這段網絡是在做掩碼操作,即輸入一個掩碼 Tensor對數據做Mask,第一個Where把不需要的數據設置為-inf。經過Softmax之后這些數據已經變成了0,但是后面又增加了一個Where,把相同位置再次設置為了0。
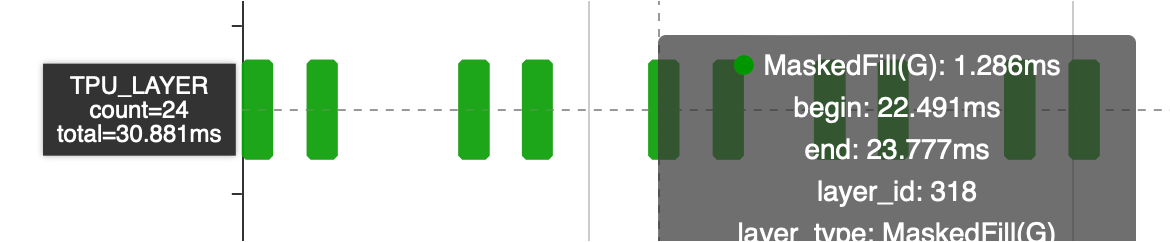
這段結構在網絡中出現了12次,單Where算子耗時30 ms相當于多了一倍的計算時間,可以在編譯階段使用圖優化進行消除,減少模型計算量。
耗時從30ms降低到15ms
MatMul的優化#
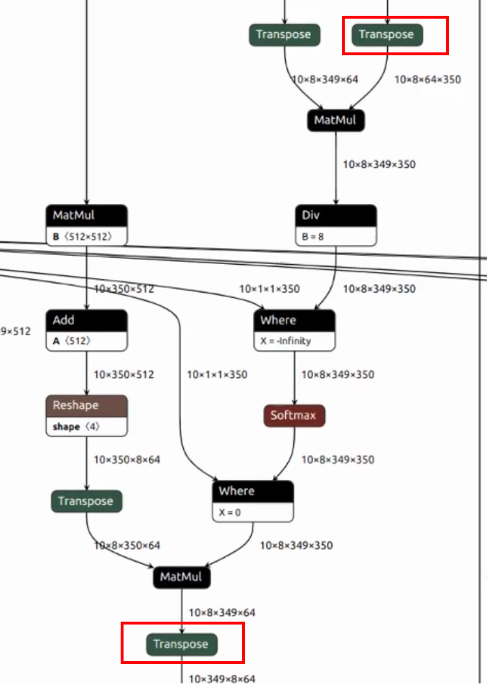
1.這段結構在Decoder中出現6次,且屬于計算集中的attention部分。但是C維度在transpose之后只有8,我們的TPU有64個lane,算力沒有完全利用起來
2.有transpose隔斷了layer group,增加了數據搬運
優化:
1.可以使用hdim_is_batch優化,把attention的head放在h維。為了保證網絡變換前后等效,需要在matmul后面新生成一個transpose。
2.生成新的transpose之后,實現masked fill算子、softmax算子的transpose move down的優化pattern,使得tranpose的執行順序可以放到該段結構結束處,同時與結束處原本有的tranpose做抵消,達到減少數據搬運的目的。
3.由于消除了transpose,使得這段網絡可以做到local layer,同時因為把349放到c維度了,又可以充分利用64個lane的計算資源了
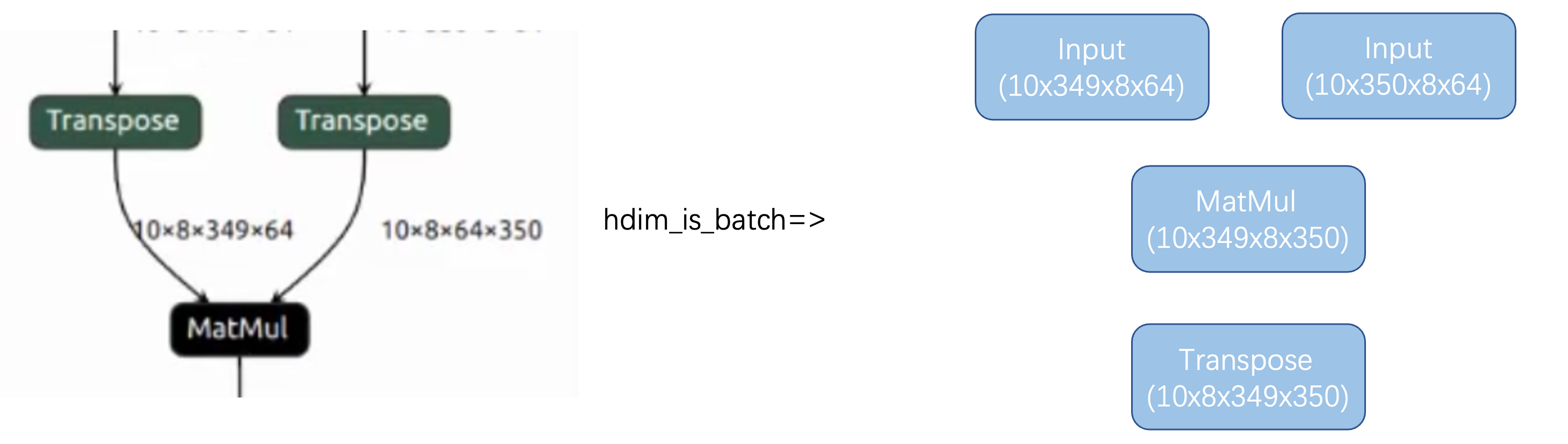
其余的算子經過transpose move down,可以實現transpose的一路下移,在局部網絡中讓C可以保持349,使得64個lane可以獲得更充分的利用
算子層面優化#
Where(MaskedFill)的優化#
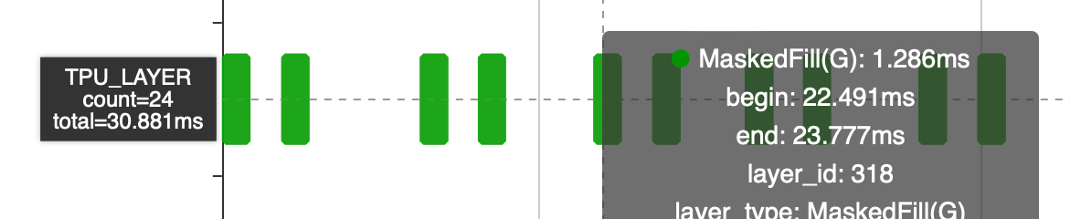
MaskedFill如果全走Global耗時30ms,即便減少一半的算子數量還是15ms。而Select算子有local的實現,同時可以通過參數配置完成MaskedFill的功能,但不支持廣播。所以在編譯階段加入Tile完成廣播,從而支持Local Layer。
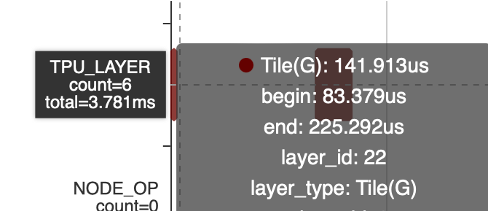
但引入了Tile,Tile操作本身耗時3.8ms,代價可接受,后續可以進一步優化
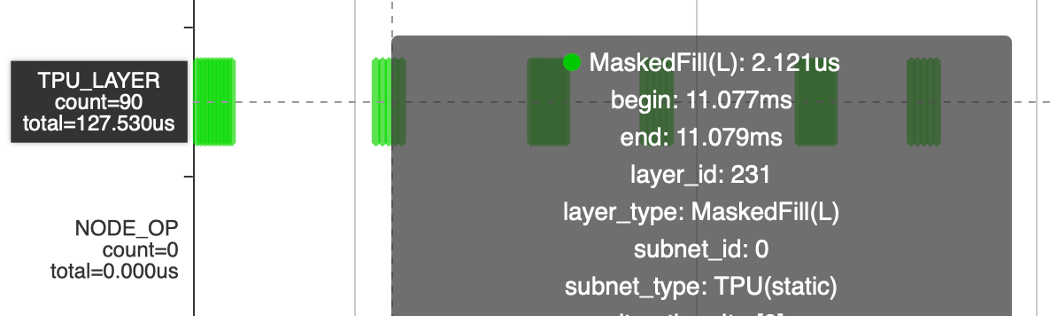
MaskedFill算子從30ms 減半數量后到15ms,引入tile之后減少到3.8ms(Tile)+127us(MaskedFill)
后續考慮使用bdc完成tile操作,完成進一步優化
CPU Layer的優化#
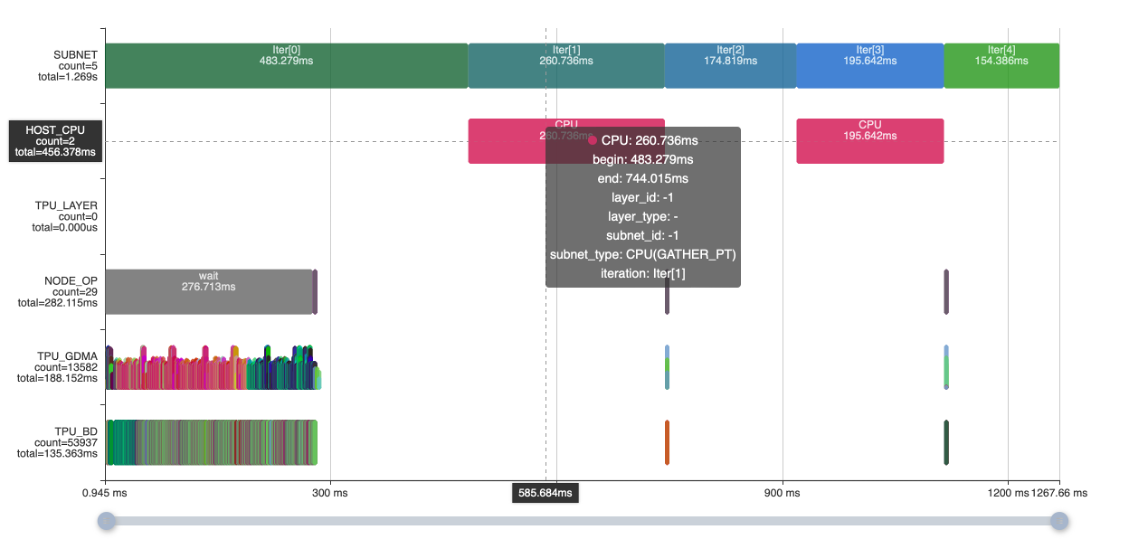
兩個CPU Gather PT操作占用456ms,可以使用dma的Gather操作在TPU實現算子
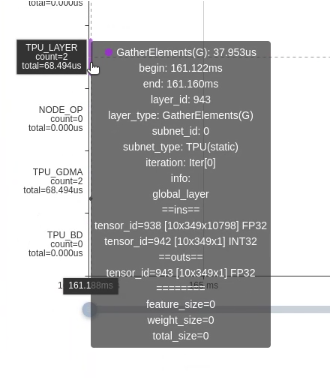
Gather PT算子從456ms減少到68us
優化結果#
| WeNet Decoder | 耗時 |
|---|---|
| 原始模型 | 611ms |
| CPU Layer替換 | 156ms |
| MaskedFill 減半 | 141ms |
| MatMul hdim_is_batch優化+Permute Move優化+MaskedFill支持Local | 71ms |
-
cpu
+關注
關注
68文章
10827瀏覽量
211167 -
模型
+關注
關注
1文章
3176瀏覽量
48721 -
算子
+關注
關注
0文章
16瀏覽量
7252
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論