 如何給TPU-MLIR添加新的算子
如何給TPU-MLIR添加新的算子
眾所周知,一個完整的模型實際上是由一系列算子組成的,所以如果我們想讓編譯器更通用,那么支持盡可能多的算子就是一個繞不開的工作。
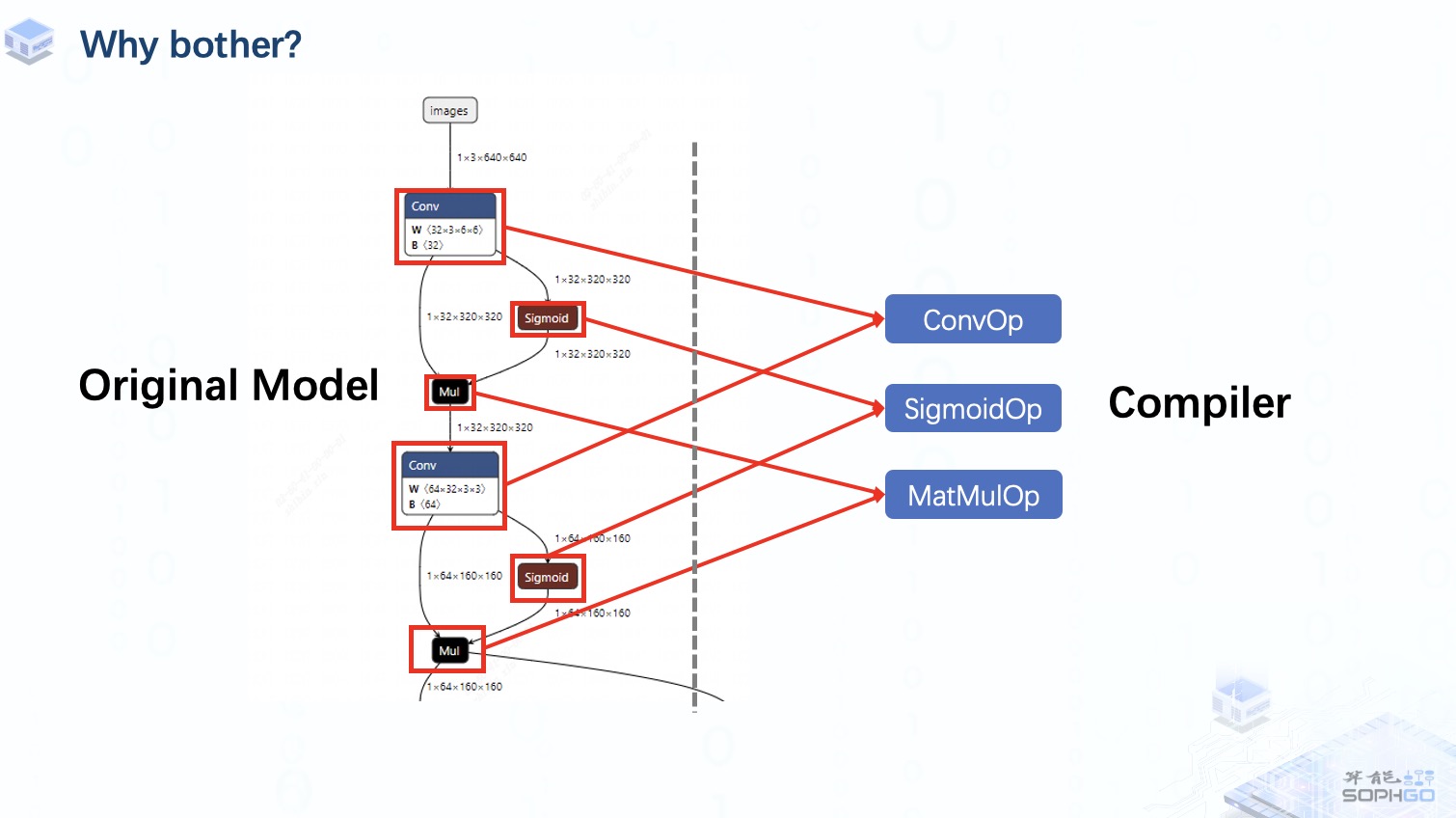
這樣無論算子是來自onnx、Caffe、PyTorch中的哪個框架,我們都可以在TPU-MLIR中找到對應的算子來表達。
首先,要添加一個新的算子,我們就需要像前端轉換那一集里提到的先進行算子定義。

在 MLIR 中,您可以直接使用 TableGen 工具來完成定義工作,而不是自己實現所有包含每個算子的輸入、輸出和屬性的 cpp 模板。
在 TPU-MLIR 中,不同 dialect 的算子定義在不同的 td 文件中,這些算子將在編譯器 build 時注冊在相應的 Dialect 下。
但是定義部分只是生成了模板,也就是說,我們的編譯器還不知道這個算子會對輸入張量做什么處理,所以我們需要通過實現相應目錄下的 inference 方法來完成這部分工作。

在 Top dialect 中,除了 inference 接口,我們還需要為每個算子實現是 FLOPs 和 Shape 接口。 前者用于計算浮點運算量,后者用于在輸出 shape 未知的情況下推理出輸出 shape。
在 MLIR 中,我們有 RankedTensorType 和 UnRankedTensorType。
這些接口的聲明是在 td 文件中被要求的,所以所有從 Top_Op 類派生的算子都需要聲明這些接口。
同樣,我們還必須為每個 Tpu 算子實現 inference 接口。 由于我們可以直接從 Top 算子獲取 FLOPs 和 Shape 信息,所以這里不需要再實現這些接口。
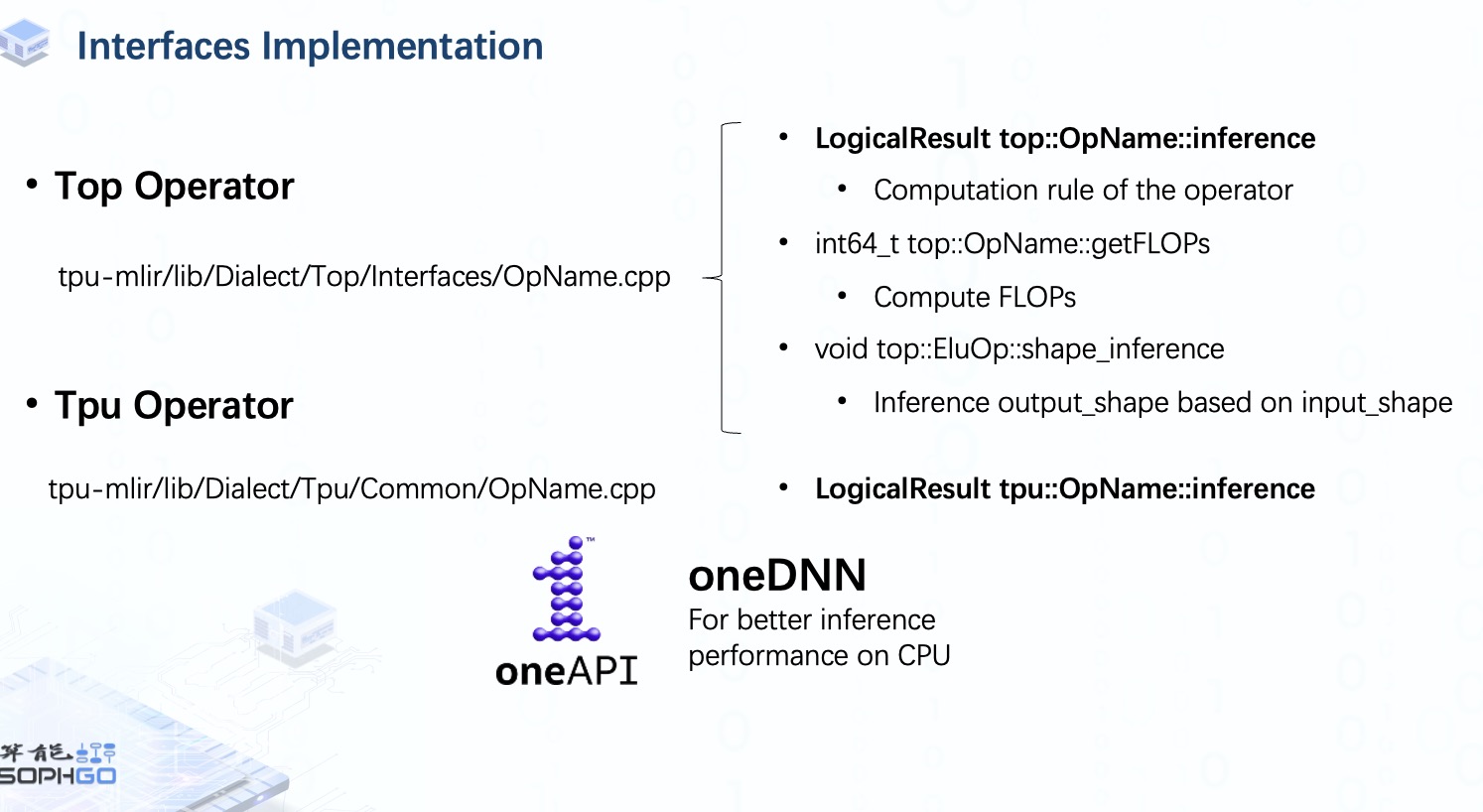
由于 Top 和 Tpu 算子是在 CPU 上做推理工作,所以有時我們會把推理工作交給 oneDNN,一個跨平臺的神經網絡庫,主要用于提高 CPU 上的推理性能。 不過這部分我就不再細說,如果大家有興趣的話,我們可以再做一個視頻來介紹一下。
所以如果大家想了解 oneDNN 的話,記得在視頻底下留言讓我們知道。
我們知道,TPU 算子最終會被用于不同硬件的代碼生成,所以對于這個 Dialect 中的算子,需要為每個硬件實現額外的接口。

其中 LocalGenInterface 用于應用了 LayerGroup 的算子,而 沒有應用 LayerGroup 的算子則會使用 GlobalGenInterface。 所以你會看到所有的算子中都有 GlobalGenInterface,但只有其中一部分算子實現了 LocalGen。
在 GlobalGen 中,張量在 Global Memory 里,因此我們需要做的是準備后端 API 所需的所有參數,例如算子的屬性以及輸入和輸出張量的 Global 地址。
對于 LocalGen,張量位于 Local Memory 中,這意味著它已經完成了將 tensor 從 Global 到 Local Mmeory 的搬運,因此我們需要調用 local 的后端 API。 此外,在量化的情況下,有時我們需要計算緩沖區大小以存儲中間結果。 這是因為中間結果通常以更高位的數據類型存儲。 比如在 int8 量化中,我們需要先將計算結果存儲為 int16 或者 int32 數據,然后再重新量化回 int8。
完成定義和接口實現工作后,還有一件需要完成的事情就是 lowering。
在 TopToTpu pass 中,我們需要應用算子轉換的 Pattern set,這需要我們為每個硬件中的每個算子實現轉換 Pattern。

一共要做 3 步,首先,在頭文件中聲明 Lowering pattern。 接著,實現該 Pattern, 然后將其添加到 Pattern set 中。
如本例所示,我們在實現 Pattern 部分主要要做的是將當前的 Top op 替換為對應的 Tpu op,并根據指定的量化模式設置該 op 的 Type。
至此,添加新算子的工作就完成了。
審核編輯:湯梓紅
-
模型
+關注
關注
1文章
3029瀏覽量
48345 -
編譯器
+關注
關注
1文章
1602瀏覽量
48894 -
算子
+關注
關注
0文章
16瀏覽量
7247 -
pytorch
+關注
關注
2文章
794瀏覽量
13007
發布評論請先 登錄
相關推薦
yolov5量化INT8出錯怎么處理?
TPU-MLIR開發環境配置時出現的各種問題求解
FP16轉換報錯的原因?
【算能RADXA微服務器試用體驗】+ GPT語音與視覺交互:2,圖像識別
TPU透明副牌.TPU副牌料.TPU抽粒廠.TPU塑膠副牌.TPU再生料.TPU低溫料
在“model_transform.py”添加參數“--resize_dims 640,640”是否表示tpu會自動resize的?

TPU-MLIR量化敏感層分析,提升模型推理精度

如何適配新架構?TPU-MLIR代碼生成CodeGen全解析!
深入學習和掌握TPU硬件架構有困難?TDB助力你快速上手!
如何高效處理LMEM中的數據?這篇文章帶你學會!
基于TPU-MLIR:詳解EinSum的完整處理過程!





 工商網監
工商網監
評論