") 如何在SAM時代下打造高效的高性能計算大模型訓(xùn)練平臺
如何在SAM時代下打造高效的高性能計算大模型訓(xùn)練平臺
關(guān)鍵詞:SAM;PCB;SA-1B;Prompt;CV;NLP;PLM;BERT;ZSL;task;zero-shot;data;H100、H800、A100、A800、LLaMA、Transformer、OpenAI、GQA、RMSNorm、SFT、RTX 4090、A6000、AIGC、CHATGLM、LLVM、LLMs、GLM、NLP、AGI、HPC、GPU、CPU、CPU+GPU、英偉達、Nvidia、英特爾、AMD、高性能計算、高性能服務(wù)器、藍海大腦、多元異構(gòu)算力、高性能計算、大模型訓(xùn)練、通用人工智能、GPU服務(wù)器、GPU集群、大模型訓(xùn)練GPU集群、大語言模型、深度學(xué)習(xí)、機器學(xué)習(xí)、計算機視覺、生成式AI、ML、DLC、ChatGPT、圖像分割、預(yù)訓(xùn)練語言模型、PLM、機器視覺、AI服務(wù)器
摘要:Segment Anything Model (SAM)是Meta 公司最近推出的一個創(chuàng)新AI 模型,專門用于計算機視覺領(lǐng)域圖像分割任務(wù)。借鑒ChatGPT 的學(xué)習(xí)范式,將預(yù)訓(xùn)練和特定任務(wù)結(jié)合在一起,從而顯著提升模型的泛化能力。SAM 的設(shè)計初衷是簡化圖像分割的過程,減少對專業(yè)建模知識的依賴,并降低大規(guī)模訓(xùn)練所需的計算資源。
在計算機視覺領(lǐng)域,SAM模型是一種基于CV領(lǐng)域的ChatGPT,提供強大的圖像分割功能。然而,要使用SAM模型,我們需要進行SAM大模型環(huán)境的配置。雖然配置SAM環(huán)境可能會面臨一些挑戰(zhàn),但一旦配置完成,我們將能夠充分利用SAM模型的強大功能。
為配置SAM環(huán)境,我們需要確保服務(wù)器具備足夠的計算資源和存儲空間,以支持SAM模型的高效運行。SAM模型通常需要大量的計算資源和存儲能力來進行準(zhǔn)確的圖像分割。然而,也需要注意SAM本地部署對服務(wù)器的影響。SAM模型的部署可能對服務(wù)器的性能和穩(wěn)定性產(chǎn)生一定的影響。
藍海大腦大模型訓(xùn)練平臺提供強大計算集群、高速存儲系統(tǒng)和高帶寬網(wǎng)絡(luò)連接,加速模型的訓(xùn)練過程;同時采用高效分布式計算框架和并行計算,使模型訓(xùn)練可以在多個計算節(jié)點上同時進行,大大縮短訓(xùn)練時間。兼?zhèn)淙蝿?wù)調(diào)度、資源管理和監(jiān)控等功能,提升訓(xùn)練效率和可管理性。此外,豐富的工具和庫,可用于模型開發(fā)、調(diào)試和優(yōu)化。還為模型部署和推理提供支持。一旦模型訓(xùn)練完成,平臺可將訓(xùn)練好的模型部署到生產(chǎn)環(huán)境中,以供實際應(yīng)用使用。
SAM模型:CV領(lǐng)域的ChatGPT
一、什么是SAM模型?
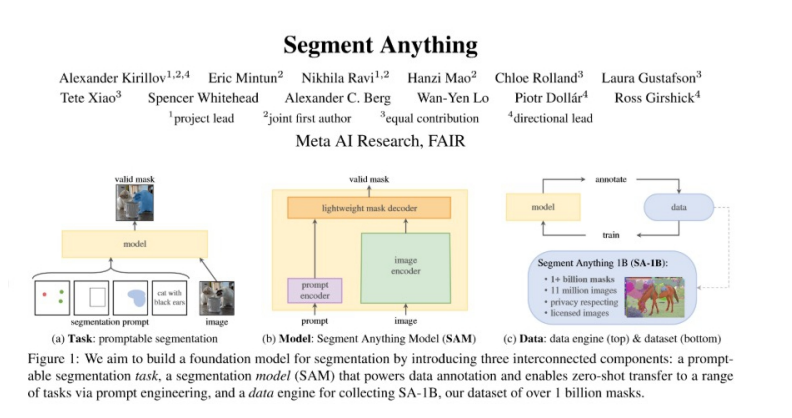
SAM模型是 Meta 推出的人工智能模型,在官網(wǎng)上被描述為“僅需一次點擊,即可在任何圖像中分割出任何物體”。采用以前圖像分割模型作為基礎(chǔ),并在龐大的數(shù)據(jù)集上進行訓(xùn)練,該模型旨在解決多個下游任務(wù)并成為一種通用模型。
該模型的核心要點有:
1、借鑒ChatGPT的啟發(fā)思想,采用可提示學(xué)習(xí)范式,提高學(xué)習(xí)效率;
2、建立迄今為止最大的圖像分割數(shù)據(jù)集Segment Anything 1-Billion(SA-1B),包含1100萬張圖像和超過10億個掩碼;
3、構(gòu)建通用且自動的分割模型,在零樣本情況下靈活應(yīng)用于新的任務(wù)和領(lǐng)域,其結(jié)果優(yōu)于以往的監(jiān)督學(xué)習(xí)結(jié)果。
SAM 模型官方文章
二、Prompt:將 ChatGPT 的學(xué)習(xí)思維應(yīng)用在 CV 領(lǐng)域
SAM 利用先進技術(shù)路線實現(xiàn)計算機視覺底層技術(shù)突破,具備廣泛的通用性和零樣本遷移的能力。采用 prompt-based learning 方式進行學(xué)習(xí)訓(xùn)練,即利用提示語作為模型輸入。與傳統(tǒng)的監(jiān)督學(xué)習(xí)方式不同,該方法在 GPT-3 團隊的推動下得到廣泛應(yīng)用。
1、Prompt之前的模型在做什么
預(yù)訓(xùn)練語言模型(PLM)是一種先進的自然語言處理(NLP)模型,在人和計算機交互方面起著重要的作用。NLP旨在改善人與計算機之間的交流和理解,而PLM則是這一領(lǐng)域前沿模型之一。

自然語言處理(NLP)的常用算法和模型
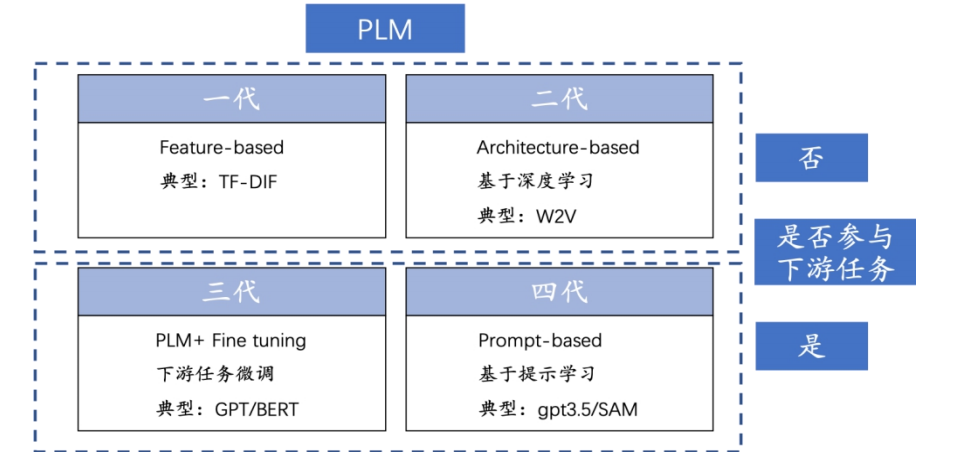
預(yù)訓(xùn)練模型根據(jù)學(xué)習(xí)范式和發(fā)展階段可以分為四代:
1)特征學(xué)習(xí):通過設(shè)置規(guī)則來提取文本特征編碼文本,例如TF-IDF模型。
2)結(jié)構(gòu)學(xué)習(xí):引入深度學(xué)習(xí)在NLP中應(yīng)用,代表性模型是Word2Vec。第一代、第二代預(yù)訓(xùn)練模型的共同點是輸出被用作下游任務(wù)的輸入,但本身并不直接執(zhí)行下游任務(wù)。隨后的模型將預(yù)訓(xùn)練結(jié)果和模型自身都應(yīng)用于下游任務(wù)中。
預(yù)訓(xùn)練模型(PLM)的發(fā)展階段和特征
3)下游微調(diào):采用預(yù)訓(xùn)練加下游微調(diào)方式,代表性模型有BERT和GPT。
4)提示學(xué)習(xí):在BERT和GPT的基礎(chǔ)上進一步改進,采用基于提示學(xué)習(xí)(Prompt-based Learning)方法。該方法將輸入信息經(jīng)過特定模板處理,將任務(wù)轉(zhuǎn)化為更適合預(yù)訓(xùn)練語言模型處理形式。代表性模型有ChapGPT、GPT3.5和SAM。
預(yù)訓(xùn)練模型就像是培養(yǎng)出的高中畢業(yè)生,而下游任務(wù)則相當(dāng)于大學(xué)的專業(yè)課程。高中畢業(yè)生學(xué)習(xí)未來應(yīng)用領(lǐng)域相關(guān)的課程,就能夠成為具備專業(yè)技能和知識的大學(xué)生,以應(yīng)對專業(yè)崗位的要求。
基于提示的學(xué)習(xí)(prompt-based learning)各分支
2、Prompt 的優(yōu)勢:實現(xiàn)預(yù)訓(xùn)練和下游任務(wù)的統(tǒng)一
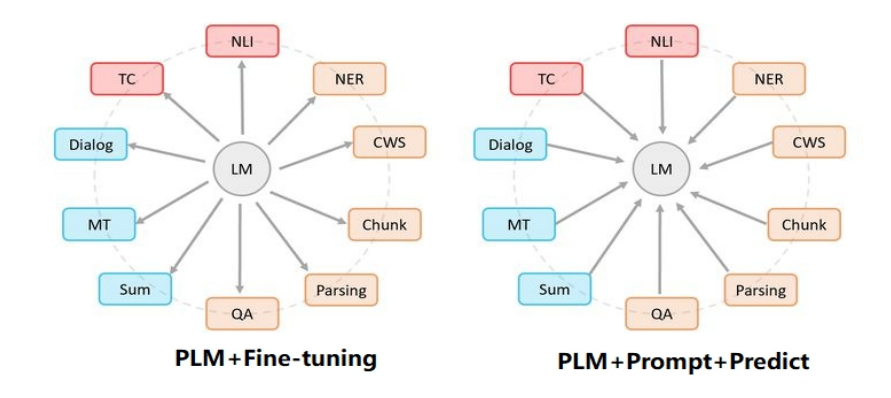
如下圖所示(左圖),傳統(tǒng)的PLM+微調(diào)范式存在上下游之間差異較大、應(yīng)用不匹配問題,在預(yù)訓(xùn)練階段使用自回歸或自編碼方法,但對于下游的微調(diào)任務(wù)來說,需要大量新數(shù)據(jù)來適應(yīng)不同的形式和要求。
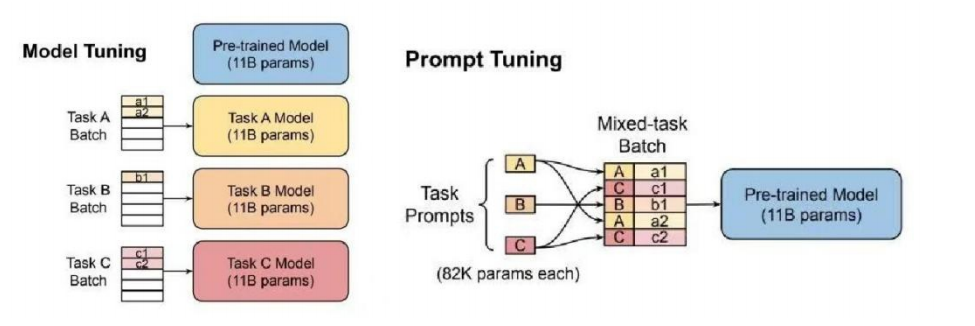
傳統(tǒng)的預(yù)訓(xùn)練+微調(diào)模型以及 prompt范式
隨著模型參數(shù)越來越龐大,企業(yè)部署模型成本非常高。同時為滿足各種不同下游之間的任務(wù),需要專門對每個任務(wù)進行微調(diào),也是一種巨大的浪費。主要有以下兩個缺點:
1)微調(diào)所需的樣本數(shù)量非常大
2)模型的專用性高,部署成本高昂
針對以上缺點,PT-3團隊提出在大量無監(jiān)督文本閱讀后,語言模型可以通過"培養(yǎng)廣泛技能和模式識別能力"有效地解決問題。實驗表明在少樣本場景下,模型不需要更新任何參數(shù)就能實現(xiàn)不錯的效果。預(yù)訓(xùn)練加微調(diào)范式是通過大量訓(xùn)練使模型適應(yīng)下游任務(wù)。而Prompt則是將下游任務(wù)以特定模板的形式統(tǒng)一成預(yù)訓(xùn)練任務(wù),將下游任務(wù)的數(shù)據(jù)組織成自然語言形式,充分發(fā)揮預(yù)訓(xùn)練模型本身的能力。
Fine-tune 和 prompt 兩種范式的區(qū)別
以情感分類任務(wù)為例,使用傳統(tǒng)Fine-tune方法需要準(zhǔn)備一個微調(diào)數(shù)據(jù)集,其中包含對電影/書籍的評價以及人工閱讀后的感受。該微調(diào)數(shù)據(jù)集必須足夠大,以滿足復(fù)雜任務(wù)需求。但是微調(diào)數(shù)據(jù)集的大小可能超過預(yù)訓(xùn)練數(shù)據(jù)集的規(guī)模,導(dǎo)致預(yù)訓(xùn)練的目的失去意義。
相比之下,利用Prompt的方式可以更好地處理情感分類任務(wù)并且充分利用預(yù)訓(xùn)練模型能力,避免繁重微調(diào)數(shù)據(jù)集準(zhǔn)備工作。Prompt可以根據(jù)輸入的句子來輸出對MASK位置單詞的預(yù)測,進而推測出用戶對該作品作品的態(tài)度。
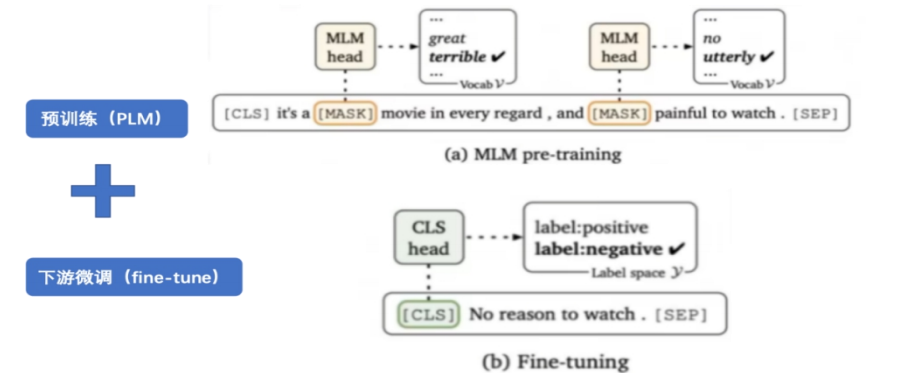
預(yù)訓(xùn)練+下游任務(wù)微調(diào)(PLM+Fine-tuning)處理情感分類任務(wù)(寫影評)
Prompt范式具有以下優(yōu)點:
1)大大降低模型訓(xùn)練所需樣本量,可以在少樣本甚至零樣本的情況下進行訓(xùn)練
2)提高模型的通用性,在實際應(yīng)用中減少成本并提高效率
當(dāng)下,大型模型如GPT-4已經(jīng)不再完全開放全部的模型參數(shù),用戶只能通過API接口使用模型進行預(yù)測。由此可見,Prompt工程在下游任務(wù)中的重要性已經(jīng)不言而喻。
三、ZSL:零樣本學(xué)習(xí)降本增效,提高模型泛化能力
1、什么是零樣本學(xué)習(xí)能力?
零樣本學(xué)習(xí)(Zero-shot Learning, ZSL)是機器學(xué)習(xí)中的一個難題,其目標(biāo)是讓模型能夠?qū)奈匆娺^的"未知物體"進行分類和識別。下圖中展示一個經(jīng)典案例,即認(rèn)識斑馬。一個"兒童"在動物園里見過許多動物,如馬、熊貓、獅子、老虎等,但從未見過斑馬。通過老師的描述,該"兒童"了解到斑馬有四條腿、黑白相間的條紋以及尾巴。最終這個"兒童"輕松地辨認(rèn)出斑馬。
類似,模型也可以通過零樣本學(xué)習(xí)方式,從已見過的類別中提取特征(如外形類似馬、具有條紋、黑白色),然后根據(jù)對未知類別特征的描述,識別那些從未見過的類別。換言之,模型通過之前學(xué)到的知識和特征,將其應(yīng)用于未知物體的識別。

零樣本學(xué)習(xí)(ZSL)示例
2、SAM 的零樣本學(xué)習(xí)能力得到認(rèn)可
SAM 正具備這樣一種零樣本分割能力,可以從各種 prompt 輸入(包括點、方框和文本)中生成高質(zhì)量的掩膜(Mask)。學(xué)術(shù)界有多篇論文探討SAM 的 ZSL 能力, 如《SAM.MD: Zero-shot medical image segmentation capabilities of the Segment Anything Model》測試 SAM 的 ZSL 效果,在圖像分割任務(wù)中輸入部分點和框作為 prompt 提示,結(jié)果顯示:專家用戶可以通過 SAM 實現(xiàn)大部分場景下的快速半自動分割。雖然在實驗中 SAM 沒有表現(xiàn)出領(lǐng)先的全自動分割性能,但可成為推動臨床醫(yī)生半自動分割工具發(fā)展的潛在催化劑。

SAM 的零樣本學(xué)習(xí)能力在 CT 影像中的應(yīng)用
四、SA-1B:迄今為止最大的分割數(shù)據(jù)集,助力模型增效
1、Data Engine:使用數(shù)據(jù)引擎生成掩碼
SAM使用數(shù)據(jù)集進行訓(xùn)練,并采用SAM交互式注釋圖像的方式對數(shù)據(jù)進行標(biāo)注。另外,采用新穎的數(shù)據(jù)收集方法,結(jié)合模型和標(biāo)注人員的力量,從而提高數(shù)據(jù)收集的效率和質(zhì)量。整個過程可以分為三個階段,讓SAM的數(shù)據(jù)引擎更加完善和高效。
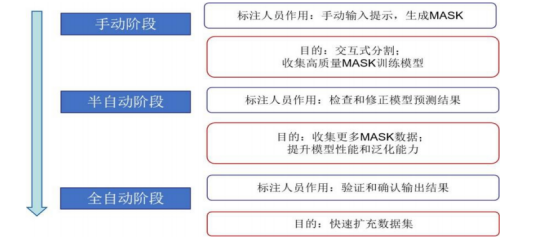
SAM使用數(shù)據(jù)引擎(data engine)漸進式收集數(shù)據(jù)示意圖
1)手工階段:在模型輔助的手工注釋階段,標(biāo)注人員利用SAM模型作為輔助工具,在圖像上進行點擊、框選或輸入文本等操作來生成MASK,并且模型會實時根據(jù)標(biāo)注人員的輸入更新MASK,并提供一些可選的MASK供標(biāo)注人員選擇和修改。該方式使得標(biāo)注人員能夠快速而準(zhǔn)確地分割圖像中的對象,無需手動繪制。其目的是收集高質(zhì)量的MASK,用于訓(xùn)練和改進SAM模型。
2)半自動階段:SAM模型已經(jīng)具備一定的分割能力,能夠自動預(yù)測圖像中的對象。但是由于模型不夠完善,預(yù)測MASK可能存在錯誤或遺漏。標(biāo)注人員的主要任務(wù)是檢查和修正模型的預(yù)測結(jié)果,以確保MASK的準(zhǔn)確性和完整性。該階段的目標(biāo)是收集更多的MASK,以進一步提升SAM模型的性能和泛化能力。
3)全自動階段:SAM模型已經(jīng)達到較高水平,能夠準(zhǔn)確地分割圖像中的所有對象,無需任何人工干預(yù)。因此,標(biāo)注人員工作轉(zhuǎn)變?yōu)榇_認(rèn)和驗證模型輸出,以確保沒有任何錯誤。該階段旨在利用SAM模型的自動標(biāo)注能力,快速擴展數(shù)據(jù)集的規(guī)模和覆蓋范圍。
2、Data Set:使用數(shù)據(jù)引擎生成掩碼
通過逐步進行“模型輔助的手工注釋——半自動半注釋——模型全自動分割掩碼”方法,SAM團隊成功創(chuàng)建名為SA-1B圖像分割數(shù)據(jù)集。該數(shù)據(jù)集具有規(guī)模空前、質(zhì)量優(yōu)良、多樣化豐富和隱私保護的特點。
1)圖像數(shù)量和質(zhì)量:SA-1B包含多樣化、高清晰度、隱私保護的1100萬張照片,這些照片是由一家大型圖片公司提供并授權(quán)使用,符合相關(guān)的數(shù)據(jù)許可證要求,可供計算機視覺研究使用。
2)分割掩碼數(shù)量和質(zhì)量:SA-1B包含11億個精細(xì)的分割掩碼,這些掩碼是由Meta開發(fā)的數(shù)據(jù)引擎自動生成,展示該引擎強大的自動化標(biāo)注能力。
3)圖像分辨率和Mask數(shù)量:每張圖像的平均分辨率為1500x2250像素,每張圖像包含約100個掩碼。
4)數(shù)據(jù)集規(guī)模對比:SA-1B比現(xiàn)有的分割數(shù)據(jù)集增加400多倍;相較于完全手動基于多邊形的掩碼標(biāo)注(如COCO數(shù)據(jù)集),使用SAM的方法快6.5倍;比過去最大的數(shù)據(jù)標(biāo)注工作快兩倍。
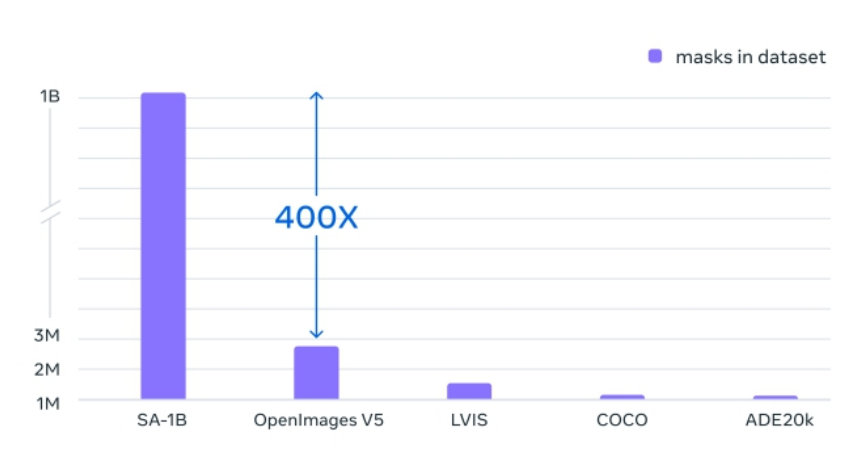
SA-1B比現(xiàn)有分割數(shù)據(jù)集多 400 倍
SA-1B數(shù)據(jù)集目標(biāo)是訓(xùn)練一個通用模型,可以從開放世界圖像中分割出任何物體。該數(shù)據(jù)集不僅為SAM模型提供強大的訓(xùn)練基礎(chǔ),同時也為圖像分割領(lǐng)域提供一個全新的研究資源和基準(zhǔn)。
此外,在SA-1B的論文中,作者進行RAI(Responsible AI,責(zé)任智能)分析,并指出該數(shù)據(jù)集的圖像在跨區(qū)域代表性方面具有更強的特點。
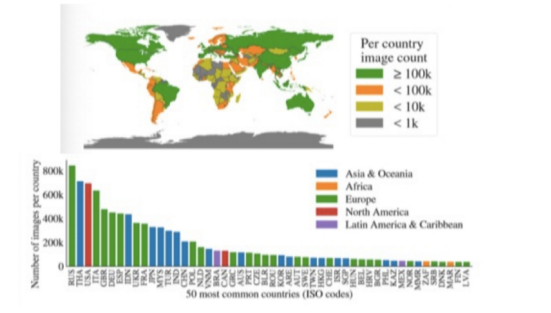
SA-1B 數(shù)據(jù)集的跨區(qū)域代表性較強
五、SAM 核心優(yōu)勢:減少訓(xùn)練需求,提升分割性能
SAM的核心目標(biāo)是在不需要專業(yè)建模知識、減少訓(xùn)練計算需求以及自行標(biāo)注掩碼的情況下,實現(xiàn)目標(biāo)通用分割。為逐步實現(xiàn)該目標(biāo),SAM采取以下三種方法構(gòu)建圖像領(lǐng)域的通用分割大模型:
1)數(shù)據(jù)規(guī)模和質(zhì)量
SAM通過具備零樣本遷移能力,收集大量高質(zhì)量的圖像分割數(shù)據(jù)(1100萬張圖像和11億個掩碼)構(gòu)建SA-1B數(shù)據(jù)集,這是目前規(guī)模最大的圖像分割數(shù)據(jù)集,遠超過以往的數(shù)據(jù)集。
2)模型效率和靈活性
SAM借鑒Transformer模型架構(gòu),并結(jié)合注意力機制和卷積神經(jīng)網(wǎng)絡(luò),實現(xiàn)高效且可引導(dǎo)的圖像分割模型。該模型能夠處理任意大小和比例的圖像,并且能夠根據(jù)不同的輸入提示生成不同的分割結(jié)果。

SAM 的可提示分割模型分為三部分
3)任務(wù)的泛化和遷移
SAM實現(xiàn)圖像分割任務(wù)的泛化和遷移能力。它通過采用可提示分割任務(wù)的方法,構(gòu)建一個能夠零樣本遷移的圖像分割模型。這意味著SAM可以適應(yīng)新的圖像分布和任務(wù),而無需額外的訓(xùn)練數(shù)據(jù)或微調(diào)。這一特性使得SAM在多個圖像分割任務(wù)上表現(xiàn)出色,甚至超過一些有監(jiān)督的模型。
目前,SAM已經(jīng)具備以下功能:
學(xué)習(xí)物體概念能夠理解圖像中物體的概念和特征。
生成未見過物體的掩碼為圖像或視頻中未見過的物體生成準(zhǔn)確的掩碼。
高通用性具有廣泛的應(yīng)用性,能夠適應(yīng)不同的場景和任務(wù)。
支持多種交互方式SAM支持用戶使用多種交互方式進行圖像和視頻分割,例如全選分割自動識別圖像中的所有物體,以及框選分割(只需框選用戶選擇的部分即可完成分割)。

框選分割(BOX)
在圖像分割領(lǐng)域,SAM是一個具有革命性意義的模型。它引入一種全新范式和思維方式,為計算機視覺領(lǐng)域的基礎(chǔ)模型研究提供新的視角和方向。SAM的出現(xiàn)改變了人們對圖像分割的認(rèn)知,并為該領(lǐng)域帶來巨大的進步和突破。
2、基于 SAM 二次創(chuàng)作,衍生模型提升性能
自從引入SAM以來,該技術(shù)在人工智能領(lǐng)域引起極大的興趣和討論,并且衍生出一系列相關(guān)模型和應(yīng)用,如SEEM和MedSAM等。這些模型在工程、醫(yī)學(xué)影像、遙感圖像、農(nóng)業(yè)等不同領(lǐng)域都有廣泛應(yīng)用。借鑒SAM理念和方法,并通過進一步改進和優(yōu)化,使得SAM的應(yīng)用范圍更廣泛。
1)SEEM:交互、語義更泛化,分割質(zhì)量提升

SEEM在交互和語義空間上都比 SAM 更具泛化性
SEEM是一種基于SAM的新型交互模型,利用SAM強大的零樣本泛化能力,實現(xiàn)對任意圖像中所有物體的分割任務(wù)。該模型結(jié)合SAM和一個檢測器,通過使用檢測器輸出的邊界框作為輸入提示,生成相應(yīng)物體掩碼。SEEM能夠根據(jù)用戶提供多種輸入模態(tài)(如文本、圖像、涂鴉等),一次性完成圖像或視頻中所有內(nèi)容分割與物體識別任務(wù)。
這項研究已在多個公開數(shù)據(jù)集上進行實驗,其分割質(zhì)量和效率均優(yōu)于SAM。值得一提的是,SEEM是第一個支持各種用戶輸入類型的通用接口,包括文本、點、涂鴉、框和圖像,提供強大組合功能。

SEEM 根據(jù)用戶輸入的點和涂鴉進行圖像識別
SEEM具備分類識別特性,可以直接輸入?yún)⒖紙D像并指定參考區(qū)域,從而對其他圖像進行分割,并找出與參考區(qū)域相一致的物體。同時該模型還擁有零樣本分割功能,對于模糊或經(jīng)歷劇烈變形的視頻,能夠準(zhǔn)確地分割出參考對象。通過第一幀和用戶提供的涂鴉等輸入,SEEM能夠在道路場景、運動場景等應(yīng)用中表現(xiàn)出色。

SEEM 根據(jù)參考圖像對其他圖像進行分割
2)MedSAM:提升感知力,應(yīng)用醫(yī)學(xué)圖像分割
為評估SAM在醫(yī)學(xué)影像分割任務(wù)中的性能,深圳大學(xué)等多所高校合作創(chuàng)建COSMOS 553K數(shù)據(jù)集(迄今為止規(guī)模最大的醫(yī)學(xué)影像分割數(shù)據(jù)集)研究人員利用該數(shù)據(jù)集對SAM進行全面、多角度、大規(guī)模的詳細(xì)評估。該數(shù)據(jù)集考慮醫(yī)學(xué)圖像的多樣成像模式、復(fù)雜邊界以及廣泛的物體尺度,提出更大的挑戰(zhàn)。通過這次評估,可以更全面地了解SAM在醫(yī)學(xué)影像分割任務(wù)中的性能表現(xiàn)。
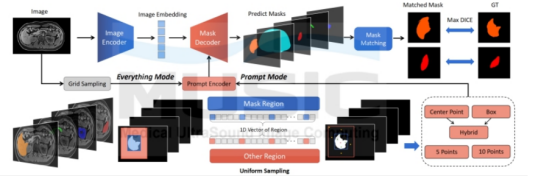
SAM 分割醫(yī)學(xué)影像測試的詳細(xì)框架
根據(jù)評估結(jié)果顯示,SAM盡管具備成為通用醫(yī)學(xué)影像分割模型的潛力,但在醫(yī)學(xué)影像分割任務(wù)中的表現(xiàn)目前還不夠穩(wěn)定。特別是在全自動Everything的分割模式下,SAM對大多數(shù)醫(yī)學(xué)影像分割任務(wù)的適應(yīng)能力較差,其感知醫(yī)學(xué)分割目標(biāo)的能力有待提高。因此,SAM在醫(yī)學(xué)影像分割領(lǐng)域的應(yīng)用還需要進一步的研究和改進。
測試 SAM 對醫(yī)學(xué)影像分割性能的數(shù)據(jù)集 COSMOS 553K 及分割效果
因此在醫(yī)學(xué)影像分割領(lǐng)域,研究重點應(yīng)該放在如何利用少量醫(yī)學(xué)影像來有效地微調(diào)SAM模型以提高其可靠性,并構(gòu)建一種適用于醫(yī)學(xué)影像的Segment Anything Model。針對這一目標(biāo),MedSAM提出一種簡單的微調(diào)方法,將SAM適應(yīng)到通用的醫(yī)學(xué)影像分割任務(wù)中。通過在21個三維分割任務(wù)和9個二維分割任務(wù)上進行全面的實驗,MedSAM證明其分割效果優(yōu)于默認(rèn)的SAM模型。這項研究為醫(yī)學(xué)影像分割提供一種有效的方法,使SAM模型能夠更好地適應(yīng)醫(yī)學(xué)影像的特點,并取得更好的分割結(jié)果。
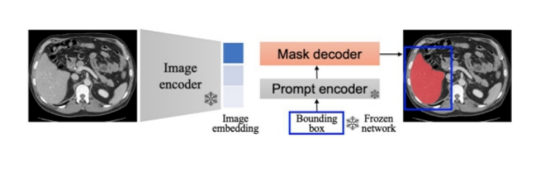
MedSAM 示意圖
3)SAM-Track:擴展 SAM 應(yīng)用領(lǐng)域,增強視頻分割性能
最新開源的SAM-Track項目由浙江大學(xué)ReLER實驗室的科研人員開發(fā),為SAM模型增強在視頻分割領(lǐng)域的能力。SAM-Track能夠?qū)θ我馕矬w進行分割和跟蹤,并且支持各種時空場景,例如街景、AR、細(xì)胞、動畫和航拍等。該項目在單卡上即可實現(xiàn)目標(biāo)分割和跟蹤,能夠同時追蹤超過200個物體,為用戶提供強大的視頻編輯能力。
相較于傳統(tǒng)的視頻分割技術(shù),SAM-Track具有更高的準(zhǔn)確性和可靠性。它能夠自適應(yīng)地識別不同場景下的物體,并快速而精確地進行分割和跟蹤,從而使用戶能夠輕松地進行視頻編輯和后期制作,實現(xiàn)更出色的視覺效果。總的來說,SAM-Track是在SAM基礎(chǔ)上的有意義的研究成果,為視頻分割和跟蹤領(lǐng)域的研究和應(yīng)用帶來了新的可能性。它的出現(xiàn)為視頻編輯、后期制作等領(lǐng)域帶來更多機會和挑戰(zhàn)。
3、SAM 及衍生模型賦能多場景應(yīng)用
SAM模型是一種高效且準(zhǔn)確的圖像分割模型,在計算機視覺領(lǐng)域的應(yīng)用具有廣泛的潛力,可以賦能工業(yè)機器視覺領(lǐng)域,實現(xiàn)降本增效、快速訓(xùn)練和減少對數(shù)據(jù)的依賴。在AR/CR行業(yè)、自動駕駛和安防監(jiān)控領(lǐng)域等賽道,SAM可以用于動態(tài)圖像的捕捉和分割,盡管可能涉及到技術(shù)、算力和倫理隱私方面的挑戰(zhàn),但其發(fā)展?jié)摿薮蟆?/p>
此外,SAM對于一些特定場景的分割任務(wù)可能具有困難性,但可以通過微調(diào)或適配器模塊的使用進行改進。在醫(yī)學(xué)影像和遙感圖像處理領(lǐng)域,SAM可以通過簡單微調(diào)或少量標(biāo)注數(shù)據(jù)的訓(xùn)練來適應(yīng)分割任務(wù)。另外,SAM還可以與其他模型或系統(tǒng)結(jié)合使用,例如與分類器結(jié)合實現(xiàn)物體檢測和識別或與生成器結(jié)合實現(xiàn)圖像編輯和轉(zhuǎn)換。這種結(jié)合能夠進一步提高圖像分割的準(zhǔn)確性和效率,為各行業(yè)帶來更多應(yīng)用場景。
1)基于 3D 重建,賦能 AR、游戲
在AR/VR領(lǐng)域,SAM模型結(jié)合3D重建技術(shù)和圖像處理算法,為用戶提供更加逼真和沉浸的視覺體驗。通過SAM模型,用戶可以將2D圖像轉(zhuǎn)化為3D場景,并在AR或VR設(shè)備上進行觀察和操控,實現(xiàn)對真實世界的模擬和還原。這樣的技術(shù)結(jié)合為用戶帶來高度沉浸式的互動體驗,能夠在虛擬世界中與物體進行互動,享受更加逼真的視覺感受。
此外,SAM模型還結(jié)合了深度學(xué)習(xí)算法,對用戶視線和手勢識別和跟蹤,以實現(xiàn)更智能化互動方式。舉例來說,當(dāng)用戶注視某個物體時,SAM模型可以自動聚焦并提供更為詳細(xì)的信息;當(dāng)用戶做出手勢操作時,SAM模型也能夠快速響應(yīng)并實現(xiàn)場景的調(diào)整和變化。
2)跟蹤運動物體,賦能安防監(jiān)控
在圖像分割領(lǐng)域,SAM是一種高效而準(zhǔn)確的模型,能夠進行視頻和動態(tài)圖像的分割,并產(chǎn)生SEEM和SAM-Track這兩個衍生應(yīng)用。這些衍生模型充分利用了SAM的零樣本泛化能力,通過使用參考圖像和用戶輸入的涂鴉、文字等信息,在模糊或劇烈變形的視頻中實現(xiàn)對目標(biāo)對象的準(zhǔn)確分割。
例如,在跑酷、運動和游戲等視頻中,傳統(tǒng)的圖像分割算法往往無法有效處理復(fù)雜的背景和快速移動的目標(biāo)物體。然而,SEEM模型不僅能夠準(zhǔn)確識別參考對象,還能夠消除背景干擾,從而提高分割的精度。簡而言之,SAM模型及其相關(guān)應(yīng)用在處理具有動態(tài)特征的圖像分割問題上表現(xiàn)出出色的性能和準(zhǔn)確度。
SEEM 在跑酷、運動、游戲視頻中可以準(zhǔn)確分割參考對象
除在運動場景中的應(yīng)用之外,SEEM和SAM-Track還可以賦能安防和視頻監(jiān)控等領(lǐng)域,準(zhǔn)確地對視頻中的物體進行分割,以便進行后續(xù)的識別和處理。SEEM和SAM-Track通過輸入的提示信息,能夠準(zhǔn)確地判斷目標(biāo)物體并進行精確的分割。
3)解決長尾難題,賦能自動駕駛
盡管目前自動駕駛技術(shù)已經(jīng)在90%以上的道路場景下成功實現(xiàn),但仍然存在10%的長尾場景難題,這主要是由于路況和車輛行駛情況的不可預(yù)測性所導(dǎo)致。這些長尾場景包括突發(fā)事件、復(fù)雜地形和惡劣氣候等極端情況,如強降雨、暴風(fēng)雪和雷電等,對自動駕駛系統(tǒng)的識別和決策能力構(gòu)成巨大挑戰(zhàn)。此外,在城市交通中,還需要考慮非機動車、行人和建筑物等因素對自動駕駛系統(tǒng)的影響。
為了解決長尾問題,自動駕駛技術(shù)需要整合更多的算法和傳感器,并通過數(shù)據(jù)采集和深度學(xué)習(xí)等方法提升系統(tǒng)的智能水平。例如,通過整合雷達、攝像頭、激光雷達等傳感器的數(shù)據(jù)來提高對目標(biāo)物體的識別和跟蹤能力。同時,可以利用深度學(xué)習(xí)算法來模擬和預(yù)測復(fù)雜場景。此外,引入人工智能技術(shù),讓自動駕駛系統(tǒng)在長尾場景中不斷學(xué)習(xí)和優(yōu)化,以提高其適應(yīng)性和泛化能力。

城市道路場景中長尾場景較多
在自動駕駛領(lǐng)域,圖像分割在感知和理解道路環(huán)境中起著關(guān)鍵作用。SAM(Segment Anything Model)可以通過標(biāo)記和分割圖像中的不同物體和區(qū)域?qū)崿F(xiàn)精確的場景感知。傳統(tǒng)的手動標(biāo)注方法耗時且容易出錯,而SAM的自動化分割能夠大幅降低成本并提高準(zhǔn)確性。
SAM在自動駕駛系統(tǒng)中能夠?qū)崟r感知道路標(biāo)記、車道線、行人、交通信號燈等關(guān)鍵元素。通過與其他深度學(xué)習(xí)模型結(jié)合,如目標(biāo)檢測和路徑規(guī)劃模型,SAM可以準(zhǔn)確理解周圍環(huán)境,幫助自動駕駛系統(tǒng)做出安全、高效的決策。
以行人識別和車道線跟蹤為例,SAM能夠預(yù)測行人和車輛的運動軌跡,幫助減少潛在的交通事故風(fēng)險。
4)提高分割性能,賦能遙感圖像
遙感圖像是通過衛(wèi)星、飛機等遙測手段獲取地球表面信息的重要工具,其具備多樣性、全覆蓋和高精度等特點,在現(xiàn)代科技發(fā)展中扮演著不可或缺的角色。遙感圖像在環(huán)境監(jiān)測、自然資源管理、城市規(guī)劃和災(zāi)害預(yù)警等領(lǐng)域應(yīng)用廣泛。
遙感數(shù)據(jù)包括光學(xué)遙感數(shù)據(jù)、光譜數(shù)據(jù)、SAR雷達數(shù)據(jù)、無人機數(shù)據(jù)等多種類型。處理遙感數(shù)據(jù)一般分為兩個階段:第一階段通過遙感地面處理系統(tǒng)對接收到的衛(wèi)星數(shù)據(jù)進行處理,包括大氣校正、色彩均勻化和圖像裁剪等,以得到可以進一步識別和處理的圖像;第二階段則是在此基礎(chǔ)上,對遙感圖像進行進一步處理和解譯,主要是對圖像中的物體進行識別。
由于遙感圖像的多樣性、復(fù)雜性和數(shù)據(jù)大量的特點,在處理過程中存在許多挑戰(zhàn)和困難。
圖像處理經(jīng)歷三個階段:
人工解譯階段:完全依賴標(biāo)注人員進行圖像解釋,但這種方法成本高且解譯效率低下;
AI+遙感階段:借助AI技術(shù)和算力的支持,有效緩解圖像解譯難點,并實現(xiàn)了人機協(xié)同。隨著遙感和測繪等觀測平臺以及衛(wèi)星數(shù)量的增長,AI與遙感的結(jié)合為圖像解譯提供更多可能性;
遙感大模型時代:隨著大型神經(jīng)網(wǎng)絡(luò)模型的發(fā)布,遙感圖像的解譯有望進入大模型階段。

遙感圖像處理發(fā)展階段
大型遙感圖像分割模型SAM是一項新興的技術(shù),為遙感圖像處理提供全新的方法。基于深度學(xué)習(xí)算法,SAM能夠高效地對遙感圖像進行分割、識別和生成,從而顯著提升遙感圖像解譯的效率。利用SAM模型進行遙感圖像分割,用戶能夠快速準(zhǔn)確地生成高質(zhì)量的地圖和三維模型,從而提高環(huán)境監(jiān)測和資源管理的效率及精度。此外,SAM模型還支持多源數(shù)據(jù)的融合,將遙感圖像與其他數(shù)據(jù)相結(jié)合,以產(chǎn)生更全面、更精準(zhǔn)的分析結(jié)果。提高遙感數(shù)據(jù)處理效率不僅為遙感應(yīng)用打下堅實基礎(chǔ),也為下游的遙感應(yīng)用帶來更廣闊的發(fā)展空間。

大模型應(yīng)用于遙感圖像處理
盡管SAM大模型在處理一些困難的遙感圖像分割任務(wù)時仍然面臨挑戰(zhàn),例如在面對陰影、掩體分割和隱蔽動物定位等任務(wù)時的準(zhǔn)確性較低。遙感圖像分割任務(wù)需要模型具備更高的感知力和識別能力,SAM模型目前無法完全做到"分割一切",特別是在處理細(xì)節(jié)方面還有進一步提升的空間。然而,通過不斷改進和優(yōu)化,SAM模型的性能可以提升。
另外,RS-promter是在SAM發(fā)布后由專家團隊二次創(chuàng)作的一種基于SAM基礎(chǔ)模型的遙感圖像實例分割的prompt learning方法。這種方法被稱為RSPrompter,使SAM能夠生成語義可辨別的遙感圖像分割結(jié)果,而無需手動創(chuàng)建prompt。RSPrompter的目標(biāo)是自動生成prompt,以自動獲取語義實例級別的掩碼。這種方法不僅適用于SAM,還可以擴展到其他基礎(chǔ)模型。
SAM模型在處理困難的遙感圖像分割任務(wù)中仍然具有挑戰(zhàn),但通過改進和優(yōu)化,包括引入更多數(shù)據(jù)集、采用更先進的神經(jīng)網(wǎng)絡(luò)架構(gòu)以及基于RS-promter的改進方法,可以提高其性能。
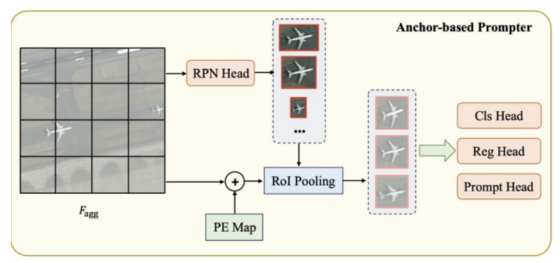
基于錨點的 prompter
研究人員進行了一系列實驗來驗證RSPrompter的效果。這些實驗不僅證明RSPrompter每個組件的有效性,還展示它在三個公共遙感數(shù)據(jù)集上相較于其他先進的實例分割技術(shù)和基于SAM的方法具有更好的性能。
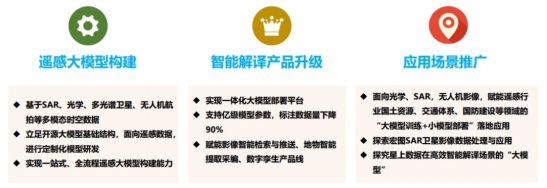
大模型為空天信息產(chǎn)業(yè)帶來了驅(qū)動和挑戰(zhàn)
大模型的引入為遙感圖像領(lǐng)域帶來新的推動力和挑戰(zhàn)。在多模態(tài)時空遙感數(shù)據(jù)的應(yīng)用中,大模型在基于合成孔徑雷達(SAR)、光學(xué)、多光譜衛(wèi)星和無人機航拍等方面具有廣泛的應(yīng)用。借助開源大模型基礎(chǔ)結(jié)構(gòu),為遙感數(shù)據(jù)開展定制化模型研發(fā),實現(xiàn)一站式、全流程的遙感大模型構(gòu)建能力。另外,大模型支持處理大規(guī)模模型參數(shù)和標(biāo)注數(shù)據(jù)量,實現(xiàn)更高效、精準(zhǔn)的遙感數(shù)據(jù)處理和分析,為影像智能檢索與推送、地物智能提取采編、數(shù)字孿生產(chǎn)品線等領(lǐng)域提供技術(shù)支持。
未來,大模型訓(xùn)練與小模型部署將結(jié)合起來,以實現(xiàn)更好的應(yīng)用效果。傳統(tǒng)的圖像處理方法難以滿足遙感影像處理的要求,因此使用大模型處理遙感圖像已成為當(dāng)前研究的重要方向。SAM模型的賦能進一步提升了遙感圖像的意義和應(yīng)用價值,為該領(lǐng)域的研究和應(yīng)用帶來新的機會和挑戰(zhàn),也為人們更好地認(rèn)識和利用地球資源提供技術(shù)支持。
5)算力應(yīng)用驅(qū)動,賦能機器視覺的功能主要歸類為四種:識別、測量、定位、檢測
識別
通過識別目標(biāo)物的特征,如外形、顏色、字符、條碼等,實現(xiàn)高速度和高準(zhǔn)確度的甄別。
測量
將圖像像素信息轉(zhuǎn)化為常用的度量單位,精確計算目標(biāo)物的幾何尺寸。機器視覺在復(fù)雜形態(tài)測量和高精度方面具有優(yōu)勢。
定位
獲取目標(biāo)物體的二維或三維位置信息。
檢測
主要針對外觀檢測,內(nèi)容涵蓋廣泛。例如產(chǎn)品裝配后的完整性檢測,外觀缺陷檢測(如劃痕、凹凸不平等)。

機器視覺四大功能及難度
機器視覺被稱為"智能制造之眼",在工業(yè)自動化領(lǐng)域廣泛應(yīng)用。典型的機器視覺系統(tǒng)包括光源、鏡頭、相機和視覺控制系統(tǒng)(包括視覺處理分析軟件和視覺控制器硬件)。根據(jù)技術(shù)的不同,機器視覺可分為基于硬件的成像技術(shù)和基于軟件的視覺分析技術(shù)。機器視覺的發(fā)展受到四大核心驅(qū)動力的影響,包括成像、算法、算力和應(yīng)用。每個方面都對機器視覺的發(fā)展起到重要的推動作用,不可或缺。
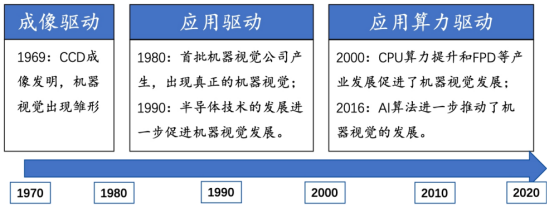
機器視覺發(fā)展歷程
機器視覺技術(shù)的發(fā)展受到兩大核心驅(qū)動力的影響。
應(yīng)用驅(qū)動:隨著傳統(tǒng)制造業(yè)對機器視覺技術(shù)的逐步采納和新興行業(yè)的崛起,機器視覺需求不斷增加。在智能制造領(lǐng)域,機器視覺技術(shù)可以幫助企業(yè)實現(xiàn)自動化生產(chǎn),提高生產(chǎn)效率和產(chǎn)品質(zhì)量。在智能醫(yī)療領(lǐng)域,機器視覺技術(shù)可以輔助醫(yī)生進行診斷和治療,提高醫(yī)療水平和治療效果。
算力/算法驅(qū)動:隨著CPU算力的增長和AI算法的快速進化,特別是深度學(xué)習(xí)等技術(shù)的應(yīng)用,機器視覺技術(shù)在圖像處理和分析方面變得更加高效和精確。高性能計算設(shè)備的推動和算法的不斷進步,為機器視覺技術(shù)的發(fā)展提供強大支持。
引入AI大模型為機器視覺產(chǎn)業(yè)帶來重大突破。當(dāng)前,機器視覺領(lǐng)域采用先進技術(shù),包括深度學(xué)習(xí)、3D處理與分析、圖像感知融合以及硬件加速圖像處理等。這些技術(shù)和模型大幅提升了機器視覺的智能應(yīng)用能力,改進圖像識別的復(fù)雜性和準(zhǔn)確性,同時降低成本,提高效率。
基于 AI 的輕量級人臉識別網(wǎng)絡(luò),可用于視頻實時分析、安防監(jiān)控等
AI在機器視覺領(lǐng)域有廣泛的應(yīng)用。通過深度學(xué)習(xí)網(wǎng)絡(luò)如CNN來實現(xiàn)物體的檢測和識別,對圖像進行分類理解場景,并提升圖像的質(zhì)量和恢復(fù)效果,實現(xiàn)實時分析和異常檢測,進行3D重建和增強現(xiàn)實等技術(shù)。同時,AI賦予機器視覺“理解”所看到圖像的能力,為各種應(yīng)用場景帶來無限的創(chuàng)新和發(fā)展機會。
其中,SAM作為一種重要的視覺領(lǐng)域AI大模型,可以在機器視覺領(lǐng)域推動創(chuàng)新和進步。例如,SAM可以直接應(yīng)用于智慧城市中,提高交通監(jiān)測、人臉識別等任務(wù)的效率。在智能制造領(lǐng)域,SAM可以增強視覺檢測和質(zhì)量控制的能力。此外,SAM還可以與OVD技術(shù)結(jié)合,自動地生成所需信息,加強語義理解能力,從而增強用戶的交互體驗。綜上所述,AI在機器視覺領(lǐng)域的應(yīng)用以及SAM模型的運用都為各個領(lǐng)域帶來了巨大的潛力和機遇。
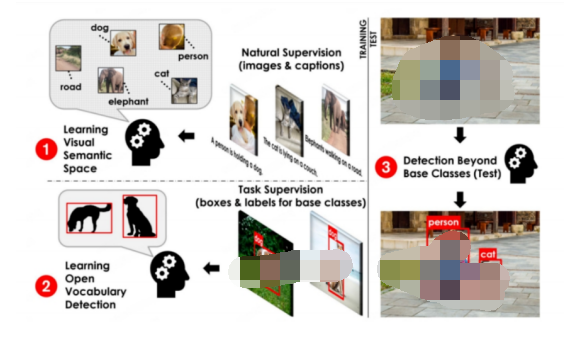
OVD 目標(biāo)檢測基本流程
SAM大模型環(huán)境配置
要部署 "Segment Anything Model",需要按以下步驟進行操作:
收集和標(biāo)記訓(xùn)練數(shù)據(jù):收集模型進行分割的對象的圖像數(shù)據(jù),并進行標(biāo)記。
進行數(shù)據(jù)預(yù)處理:在訓(xùn)練之前,對圖像進行預(yù)處理(調(diào)整圖像的大小、剪裁不相關(guān)的區(qū)域或應(yīng)用增強技術(shù))以提高模型的準(zhǔn)確性和泛化能力。
構(gòu)建和訓(xùn)練模型:選擇適合的模型,并使用預(yù)處理后的數(shù)據(jù)進行訓(xùn)練(合適的網(wǎng)絡(luò)架構(gòu)、調(diào)整超參數(shù)和優(yōu)化模型的損失函數(shù))。
模型評估和調(diào)優(yōu):對訓(xùn)練完成的模型進行評估,確保其在分割任務(wù)上的性能。可以進行模型調(diào)優(yōu),如調(diào)整閾值、增加訓(xùn)練數(shù)據(jù)或使用遷移學(xué)習(xí)等技術(shù)。
部署和推理:將訓(xùn)練好的模型部署到目標(biāo)環(huán)境中,并使用新的圖像數(shù)據(jù)進行推理。
以下是具體操作流程:
請確保系統(tǒng)滿足以下要求:Python版本大于等于3.8,PyTorch版本大于等于1.7,torchvision版本大于等于0.8。
可以參考官方教程來進行操作:https://github.com/facebookresearch/segment-anything
一、以下是安裝主要庫的幾種方式:
1、使用pip安裝(需要配置好Git):
Pip install
git+https://github.com/facebookresearch/segment-anything.git
2、本地安裝(需要配置好Git):
git clone git@github.com:facebookresearch/segment-anything.git
cd segment-anything
pip install -e .
3、手動下載+手動本地安裝:
私信小助手獲取zip文件,并解壓后運行以下命令:
cd segment-anything-main
pip install -e .
二、安裝依賴庫:
為了安裝依賴庫,可以運行以下命令:
pip install opencv-python pycocotools matplotlib onnxruntime onnx
請注意,如果您在安裝matplotlib時遇到錯誤,可以嘗試安裝特定版本的matplotlib,如3.6.2版本。可以使用以下命令安裝指定版本的matplotlib:
pip install matplotlib==3.6.2
三、下載權(quán)重文件:
您可以從以下鏈接中下載三個權(quán)重文件中的一個:
1、default 或 vit_h:ViT-H SAM 模型。
2、vit_l:ViT-L SAM 模型。
3、vit_b:ViT-B SAM 模型。
如果您發(fā)現(xiàn)下載速度過慢,請私信小助手獲取權(quán)重文件。
通過下載并使用其中一個權(quán)重文件,將能夠在 "Segment Anything" 模型中使用相應(yīng)的預(yù)訓(xùn)練模型。
如何配置訓(xùn)練SAM模型服務(wù)器
在計算機視覺領(lǐng)域,圖像分割是一個關(guān)鍵的任務(wù),涉及將圖像中的不同對象或區(qū)域進行準(zhǔn)確的分割。SAM模型作為一種基于CV領(lǐng)域的ChatGPT,為圖像分割任務(wù)提供強大的能力。然而,要使用SAM模型,需要配置適合SAM環(huán)境的服務(wù)器,并滿足SAM模型對計算資源和存儲空間的需求。
配置適合SAM環(huán)境的服務(wù)器是充分利用SAM模型優(yōu)勢的關(guān)鍵。為滿足SAM模型對計算資源和存儲空間的需求,需要確保服務(wù)器具備足夠的CPU和GPU資源、存儲空間和高性能網(wǎng)絡(luò)連接。
一、計算資源需求
由于SAM模型依賴于深度學(xué)習(xí)算法,需要進行大規(guī)模的矩陣運算和神經(jīng)網(wǎng)絡(luò)訓(xùn)練。因此通常需要大量的計算資源來進行高效的圖像分割。所以配置SAM環(huán)境時,需要確保服務(wù)器具備足夠的CPU和GPU資源來支持SAM模型的計算需求。特別是在處理大規(guī)模圖像數(shù)據(jù)集時,服務(wù)器需要具備較高的并行計算能力,以確保模型的高效運行。
1、GPU
1)GPU內(nèi)存:SAM模型需要大量的內(nèi)存來存儲模型參數(shù)和圖像數(shù)據(jù)。因此,選擇足夠內(nèi)存容量的GPU是至關(guān)重要的。
2)GPU計算能力:SAM模型依賴于深度學(xué)習(xí)算法,需要進行大規(guī)模的矩陣運算和神經(jīng)網(wǎng)絡(luò)訓(xùn)練。因此,選擇具有較高計算能力的GPU可以提高SAM模型的運行效率。例如,選擇具有較多CUDA核心和高時鐘頻率的GPU。
2、CPU
雖然GPU在SAM模型中扮演著重要的角色,但CPU也是服務(wù)器配置中不可忽視的組件。在SAM模型中,CPU主要負(fù)責(zé)數(shù)據(jù)的預(yù)處理、模型的加載和其他非計算密集型任務(wù)。因此,在選擇CPU時,需要考慮以下幾個因素:
1)CPU核心數(shù)量:由于CPU可以并行處理多個任務(wù),所以選擇具有較多核心的CPU可以提高SAM模型的整體性能。
2)CPU時鐘頻率:SAM模型的預(yù)處理和其他非計算密集型任務(wù)通常需要較高的時鐘頻率。因此,選擇具有較高時鐘頻率的CPU可以加快這些任務(wù)的執(zhí)行速度。
3、常用CPU+GPU推薦
1)AMD EPYC 7763 + Nvidia A100 80GB
AMD 7763是64核心的高端EPYC芯片,A100 80GB單卡內(nèi)存高達80GB,可以支持大模型的訓(xùn)練。
2)雙AMD EPYC 7742 + 8張 AMD Instinct MI50
7742是AMD的前一代32核心服務(wù)器CPU,雙CPU可以提供64核心。MI50是AMD較高端的GPU,具有16GB內(nèi)存,8張可以提供充足的計算資源。
3)雙Intel Xeon Platinum 8280 + 8張 Nvidia V100 32GB
8280是Intel Scalable系列的28核心旗艦CPU,雙CPU提供56核心。V100 32GB單卡32GB內(nèi)存。
4)AMD EPYC 7713 + 8張 Nvidia RTX A6000
RTX A6000基于Ampere架構(gòu),具有48GB內(nèi)存,相比A100更經(jīng)濟且內(nèi)存也足夠大。
5)雙Intel Xeon Gold 6300 + 8張 AMD Instinct MI100
Intel Xeon Gold 6300系列提供較低成本的多核心Xeon CPU,MI100配合使用可以達到比較好的性價比。
6)對于CPU,AMD EPYC 7003系列處理器是一個不錯的選擇。這是AMD的第三代EPYC服務(wù)器CPU,使用TSMC 5nm制程,擁有高達96個Zen 3核心,提供強大的多線程處理性能。具體型號可以選擇72核心的EPYC 7773X或64核心的EPYC 7713。
對于GPU,Nvidia的A100 Tensor Core GPU是目前訓(xùn)練大型神經(jīng)網(wǎng)絡(luò)的首選。它基于Ampere架構(gòu),具有高達6912個Tensor Core,可以提供高達19.5 TFLOPS的Tensor浮點性能。可以配置4-8塊A100來滿足訓(xùn)練需求。
另外,AMD的Instinct MI100 GPU也是一個不錯的選擇。它使用CDNA架構(gòu),具有120個計算單元,可以提供高達11.5 TFLOPS的半精度浮點性能。相比A100更經(jīng)濟高效。
4、存儲需求
SAM模型在進行圖像分割任務(wù)時,需要加載和存儲大量的模型參數(shù)和圖像數(shù)據(jù)。因此,服務(wù)器需要具備足夠的存儲空間來存儲SAM模型和相關(guān)數(shù)據(jù)。此外,為了提高SAM模型的運行效率,我們還可以考慮使用高速存儲設(shè)備,如SSD(固態(tài)硬盤),以加快數(shù)據(jù)的讀取和寫入速度。
5、高性能網(wǎng)絡(luò)需求
SAM模型在進行圖像分割任務(wù)時,需要通過網(wǎng)絡(luò)接收和發(fā)送大量的數(shù)據(jù)。因此,服務(wù)器需要具備高速、穩(wěn)定的網(wǎng)絡(luò)連接,以確保數(shù)據(jù)的快速傳輸和模型的實時響應(yīng)能力。特別是在處理實時圖像分割任務(wù)時,服務(wù)器需要具備低延遲和高帶寬的網(wǎng)絡(luò)連接,以滿足實時性的要求。
藍海大腦大模型訓(xùn)練平臺
藍海大腦大模型訓(xùn)練平臺提供強大的算力支持,包括基于開放加速模組高速互聯(lián)的AI加速器。配置高速內(nèi)存且支持全互聯(lián)拓?fù)洌瑵M足大模型訓(xùn)練中張量并行的通信需求。支持高性能I/O擴展,同時可以擴展至萬卡AI集群,滿足大模型流水線和數(shù)據(jù)并行的通信需求。強大的液冷系統(tǒng)熱插拔及智能電源管理技術(shù),當(dāng)BMC收到PSU故障或錯誤警告(如斷電、電涌,過熱),自動強制系統(tǒng)的CPU進入ULFM(超低頻模式,以實現(xiàn)最低功耗)。致力于通過“低碳節(jié)能”為客戶提供環(huán)保綠色的高性能計算解決方案。主要應(yīng)用于深度學(xué)習(xí)、學(xué)術(shù)教育、生物醫(yī)藥、地球勘探、氣象海洋、超算中心、AI及大數(shù)據(jù)等領(lǐng)域。

一、為什么需要大模型?
1、模型效果更優(yōu)
大模型在各場景上的效果均優(yōu)于普通模型
2、創(chuàng)造能力更強
大模型能夠進行內(nèi)容生成(AIGC),助力內(nèi)容規(guī)模化生產(chǎn)
3、靈活定制場景
通過舉例子的方式,定制大模型海量的應(yīng)用場景
4、標(biāo)注數(shù)據(jù)更少
通過學(xué)習(xí)少量行業(yè)數(shù)據(jù),大模型就能夠應(yīng)對特定業(yè)務(wù)場景的需求
二、平臺特點
1、異構(gòu)計算資源調(diào)度
一種基于通用服務(wù)器和專用硬件的綜合解決方案,用于調(diào)度和管理多種異構(gòu)計算資源,包括CPU、GPU等。通過強大的虛擬化管理功能,能夠輕松部署底層計算資源,并高效運行各種模型。同時充分發(fā)揮不同異構(gòu)資源的硬件加速能力,以加快模型的運行速度和生成速度。
2、穩(wěn)定可靠的數(shù)據(jù)存儲
支持多存儲類型協(xié)議,包括塊、文件和對象存儲服務(wù)。將存儲資源池化實現(xiàn)模型和生成數(shù)據(jù)的自由流通,提高數(shù)據(jù)的利用率。同時采用多副本、多級故障域和故障自恢復(fù)等數(shù)據(jù)保護機制,確保模型和數(shù)據(jù)的安全穩(wěn)定運行。
3、高性能分布式網(wǎng)絡(luò)
提供算力資源的網(wǎng)絡(luò)和存儲,并通過分布式網(wǎng)絡(luò)機制進行轉(zhuǎn)發(fā),透傳物理網(wǎng)絡(luò)性能,顯著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用嚴(yán)格的權(quán)限管理機制,確保模型倉庫的安全性。在數(shù)據(jù)存儲方面,提供私有化部署和數(shù)據(jù)磁盤加密等措施,保證數(shù)據(jù)的安全可控性。同時,在模型分發(fā)和運行過程中,提供全面的賬號認(rèn)證和日志審計功能,全方位保障模型和數(shù)據(jù)的安全性。
三、常用配置
目前大模型訓(xùn)練多常用H100、H800、A800、A100等GPU顯卡,以下是一些常用的配置。
1、H100服務(wù)器常用配置
英偉達H100 配備第四代 Tensor Core 和 Transformer 引擎(FP8 精度),與上一代產(chǎn)品相比,可為多專家 (MoE) 模型提供高 9 倍的訓(xùn)練速度。通過結(jié)合可提供 900 GB/s GPU 間互連的第四代 NVlink、可跨節(jié)點加速每個 GPU 通信的 NVLINK Switch 系統(tǒng)、PCIe 5.0 以及 NVIDIA Magnum IO? 軟件,為小型企業(yè)到大規(guī)模統(tǒng)一 GPU 集群提供高效的可擴展性。
搭載 H100 的加速服務(wù)器可以提供相應(yīng)的計算能力,并利用 NVLink 和 NVSwitch 每個 GPU 3 TB/s 的顯存帶寬和可擴展性,憑借高性能應(yīng)對數(shù)據(jù)分析以及通過擴展支持龐大的數(shù)據(jù)集。通過結(jié)合使用 NVIDIA Quantum-2 InfiniBand、Magnum IO 軟件、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS?,NVIDIA 數(shù)據(jù)中心平臺能夠以出色的性能和效率加速這些大型工作負(fù)載。
CPU:英特爾至強Platinum 8468 48C 96T 3.80GHz 105MB 350W *2
內(nèi)存:動態(tài)隨機存取存儲器64GB DDR5 4800兆赫 *24
存儲:固態(tài)硬盤3.2TB U.2 PCIe第4代 *4
GPU :Nvidia Vulcan PCIe H100 80GB *8
平臺 :HD210 *1
散熱 :CPU+GPU液冷一體散熱系統(tǒng) *1
網(wǎng)絡(luò) :英偉達IB 400Gb/s單端口適配器 *8
電源:2000W(2+2)冗余高效電源 *1
2、A800服務(wù)器常用配置
NVIDIA A800 的深度學(xué)習(xí)運算能力可達 312 teraFLOPS(TFLOPS)。其深度學(xué)習(xí)訓(xùn)練的Tensor 每秒浮點運算次數(shù)(FLOPS)和推理的 Tensor 每秒萬億次運算次數(shù)(TOPS)皆為NVIDIA Volta GPU 的 20 倍。采用的 NVIDIA NVLink可提供兩倍于上一代的吞吐量。與 NVIDIA NVSwitch 結(jié)合使用時,此技術(shù)可將多達 16 個 A800 GPU 互聯(lián),并將速度提升至 600GB/s,從而在單個服務(wù)器上實現(xiàn)出色的應(yīng)用性能。NVLink 技術(shù)可應(yīng)用在 A800 中:SXM GPU 通過 HGX A100 服務(wù)器主板連接,PCIe GPU 通過 NVLink 橋接器可橋接多達 2 個 GPU。
CPU:Intel 8358P 2.6G 11.2UFI 48M 32C 240W *2
內(nèi)存:DDR4 3200 64G *32
數(shù)據(jù)盤:960G 2.5 SATA 6Gb R SSD *2
硬盤:3.84T 2.5-E4x4R SSD *2
網(wǎng)絡(luò):雙口10G光纖網(wǎng)卡(含模塊)*1
雙口25G SFP28無模塊光纖網(wǎng)卡(MCX512A-ADAT )*1
GPU:HV HGX A800 8-GPU 8OGB *1
電源:3500W電源模塊*4
其他:25G SFP28多模光模塊 *2
單端口200G HDR HCA卡(型號:MCX653105A-HDAT) *4
2GB SAS 12Gb 8口 RAID卡 *1
16A電源線纜國標(biāo)1.8m *4
托軌 *1
主板預(yù)留PCIE4.0x16接口 *4
支持2個M.2 *1
原廠質(zhì)保3年 *1
3、A100服務(wù)器常用配置
NVIDIA A100 Tensor Core GPU 可針對 AI、數(shù)據(jù)分析和 HPC 應(yīng)用場景,在不同規(guī)模下實現(xiàn)出色的加速,有效助力更高性能的彈性數(shù)據(jù)中心。A100 采用 NVIDIA Ampere 架構(gòu),是 NVIDIA 數(shù)據(jù)中心平臺的引擎。A100 的性能比上一代產(chǎn)品提升高達 20 倍,并可劃分為七個 GPU 實例,以根據(jù)變化的需求進行動態(tài)調(diào)整。A100 提供 40GB 和 80GB 顯存兩種版本,A100 80GB 將 GPU 顯存增加了一倍,并提供超快速的顯存帶寬(每秒超過 2 萬億字節(jié) [TB/s]),可處理超大型模型和數(shù)據(jù)集。
CPU:Intel Xeon Platinum 8358P_2.60 GHz_32C 64T_230W *2
RAM:64GB DDR4 RDIMM服務(wù)器內(nèi)存 *16
SSD1:480GB 2.5英寸SATA固態(tài)硬盤 *1
SSD2:3.84TB 2.5英寸NVMe固態(tài)硬盤 *2
GPU:NVIDIA TESLA A100 80G SXM *8
網(wǎng)卡1:100G 雙口網(wǎng)卡IB 邁絡(luò)思 *2
網(wǎng)卡2:25G CX5雙口網(wǎng)卡 *1
4、H800服務(wù)器常用配置
H800是英偉達新代次處理器,基于Hopper架構(gòu),對跑深度推薦系統(tǒng)、大型AI語言模型、基因組學(xué)、復(fù)雜數(shù)字孿生等任務(wù)的效率提升非常明顯。與A800相比,H800的性能提升了3倍,在顯存帶寬上也有明顯的提高,達到3 TB/s。
雖然論性能,H800并不是最強的,但由于美國的限制,性能更強的H100無法供應(yīng)給中國市場。有業(yè)內(nèi)人士表示,H800相較H100,主要是在傳輸速率上有所差異,與上一代的A100相比,H800在傳輸速率上仍略低一些,但是在算力方面,H800是A100的三倍。
CPU:Intel Xeon Platinum 8468 Processor,48C64T,105M Cache 2.1GHz,350W *2
內(nèi)存 :64GB 3200MHz RECC DDR4 DIMM *32
系統(tǒng)硬盤: intel D7-P5620 3.2T NVMe PCle4.0x4 3DTLCU.2 15mm 3DWPD *4
GPU: NVIDIA Tesla H800 -80GB HBM2 *8
GPU網(wǎng)絡(luò): NVIDIA 900-9x766-003-SQO PCle 1-Port IB 400 OSFP Gen5 *8
存儲網(wǎng)絡(luò) :雙端口 200GbE IB *1
網(wǎng)卡 :25G網(wǎng)絡(luò)接口卡 雙端口 *1
5、A6000服務(wù)器常用配置
CPU:AMD EPYC 7763 64C 2.45GHz 256MB 280W*2
內(nèi)存:64GB DDR4-3200 ECC REG RDIMM*8
固態(tài)盤:2.5" 960GB SATA 讀取密集 SSD*1
數(shù)據(jù)盤:3.5" 10TB 7200RPM SATA HDD*1
GPU:NVIDIA RTX A6000 48GB*8
平臺:
機架式4U GPU服務(wù)器,支持兩顆AMD EPYC 7002/7003系列處理器,最高支持280W TDP,最大支持32根內(nèi)存插槽支持8個3.5/2.5寸熱插拔SAS/SATA/SSD硬盤位(含2個NVMe混合插槽),可選外插SAS或RAID卡,支持多種RAID模式,獨立IPMI管理接口,11xPCIe 4.0插槽。
2200W(2+2)冗余鈦金電源(96%轉(zhuǎn)換效率),無光驅(qū),含導(dǎo)軌
6、AMD MI210服務(wù)器常用配置
CPU:AMD EPYC 7742 64C 2.25GHz 256MB 225W *2
內(nèi)存:64GB DDR4-3200 ECC REG RDIMM*8
固態(tài)盤:2.5" 960GB SATA 讀取密集 SSD*1
數(shù)據(jù)盤:3.5" 10TB 7200RPM SATA HDD*1
GPU:AMD MI210 64GB 300W*8
平臺:
機架式4U GPU服務(wù)器,支持兩顆AMD EPYC 7002/7003系列處理器,最高支持280W TDP,最大支持32根內(nèi)存插槽支持8個3.5/2.5寸熱插拔SAS/SATA/SSD硬盤位(含2個NVMe混合插槽),可選外插SAS或RAID卡,支持多種RAID模式,獨立IPMI管理接口,11xPCIe 4.0插槽。
2200W(2+2)冗余鈦金電源(96%轉(zhuǎn)換效率),無光驅(qū),含導(dǎo)軌
7、AMD MI250服務(wù)器常用配置
CPU: AMD EPYC? 7773X 64C 2.2GHz 768MB 280W *2
內(nèi)存:64GB DDR4-3200 ECC REG RDIMM*8
固態(tài)盤:2.5" 960GB SATA 讀取密集 SSD*1
數(shù)據(jù)盤:3.5" 10TB 7200RPM SATA HDD*1
GPU:AMD MI250 128GB 560W*6
平臺:
機架式4U GPU服務(wù)器,支持兩顆AMD EPYC 7002/7003系列處理器,最高支持280W TDP,最大支持32根內(nèi)存插槽支持8個3.5/2.5寸熱插拔SAS/SATA/SSD硬盤位(含2個NVMe混合插槽),可選外插SAS或RAID卡,支持多種RAID模式,獨立IPMI管理接口,11xPCIe 4.0插槽。
2200W(2+2)冗余鈦金電源(96%轉(zhuǎn)換效率),無光驅(qū),含導(dǎo)軌
審核編輯 黃宇
-
amd
+關(guān)注
關(guān)注
25文章
5444瀏覽量
133948 -
人工智能
+關(guān)注
關(guān)注
1791文章
46868瀏覽量
237592 -
SAM
+關(guān)注
關(guān)注
0文章
112瀏覽量
33502 -
高性能計算
+關(guān)注
關(guān)注
0文章
82瀏覽量
13375 -
大模型
+關(guān)注
關(guān)注
2文章
2333瀏覽量
2489
發(fā)布評論請先 登錄
相關(guān)推薦
【大語言模型:原理與工程實踐】大語言模型的預(yù)訓(xùn)練
NVIDIA火熱招聘GPU高性能計算架構(gòu)師
高性能計算軟件具有哪些缺陷?
智能網(wǎng)卡簡介及其在高性能計算中的作用
DGX SuperPOD助力助力織女模型的高效訓(xùn)練
如何將高性能計算和科學(xué)計算應(yīng)用軟件更好的部署到GPU計算平臺
如何在GPU資源受限的情況下訓(xùn)練transformers庫上面的大模型
AIGC大模型時代下,該如何應(yīng)用高性能計算PC集群打造游戲開發(fā)新模式?

SAM-Adapter:首次讓SAM在下游任務(wù)適應(yīng)調(diào)優(yōu)!
SAM分割模型是什么?
中偉視界:突破技術(shù)壁壘,構(gòu)建高性能AI算法模型平臺
騰訊云與 IBM 共同打造“高性能計算服務(wù)解決方案”






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論