 LLMEngine下一層級的模塊內如何實現各自功能接口
LLMEngine下一層級的模塊內如何實現各自功能接口
最近業余時間在看新番vLLM,在讀源碼過程中,對其顯存管理原理有了清晰的認識。vLLM系統主要是基于python+cuda實現的,很多其他python項目實現都很混亂(各種重復代碼、語意不明/模糊的抽象設計),但vLLM的系統設計卻特別工整,為怕遺忘,特別開啟本篇,top down的記錄一下vLLM框架結構。
回到vLLM這個項目,vLLM針對GPT類模型推理過程中KVCache這個顯存占用大頭專門設計了block_table,將KVCache分段成多個block存儲在GPU中。一方面,這種設計可以共用beam search多batch之間share prompt sequence(的KVCache),減少顯存占用。另一方面,在gpu顯存和cpu內存間調度這些block,可以在有限的gpu顯存空間下同時推理更大batch的sequence,換句話說,就是盡可能拉滿gpu顯存使用率,提高吞吐。
本篇文章將會按top down的方式介紹整個系統。先總覽整個框架包含的基本類型,包括類型之間的關系、各類職責。然后,針對系統入口LLMEngine,介紹各個類之間如何通過接口互相組織完成推理過程,加深各個類功能的抽象理解。更進一步的,分析LLMEngine下一層級的模塊內如何實現各自功能接口。(后續也會抽時間專門開一篇介紹vLLM中用到的cuda ops源碼,特別是PageAttention部分,敬請期待)
框架概覽
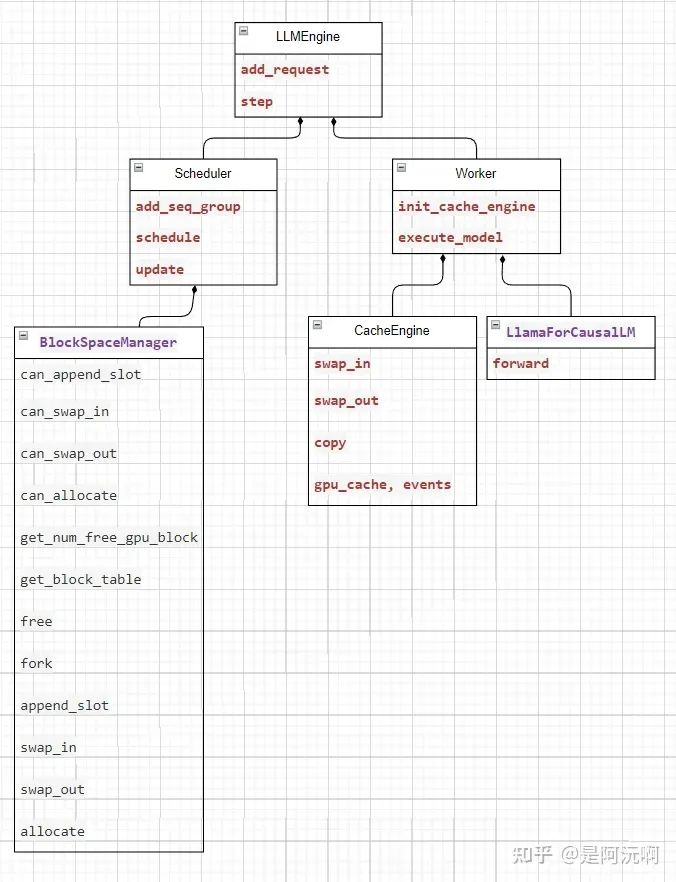
vLLM類關系圖
整個框架核心的模塊關系如上:
LLMEngine:是整個系統的入口,add_request負責輸入prompt請求,step迭代推理,最終返回LLM生成的結果。其內部組合了一個Scheduler和一組Worker。
Scheduler:在每個推理步調度可處理的Sequence輸入信息,其組合包含了一個BlockSpaceManager
BlockSpaceManager:維護gpu顯存和cpu內存的使用情況,以及Sequence對應Cache的BlockTable信息。
Worker:在每個推理步執行LlamaForCausalLM推理,并返回采樣后結果。除一個LLM模型外,其另一個核心組件是CacheEngine。
CacheEngine:負責執行相關gpu、cpu空間的換入、換出、拷貝等操作。
LLMEngine
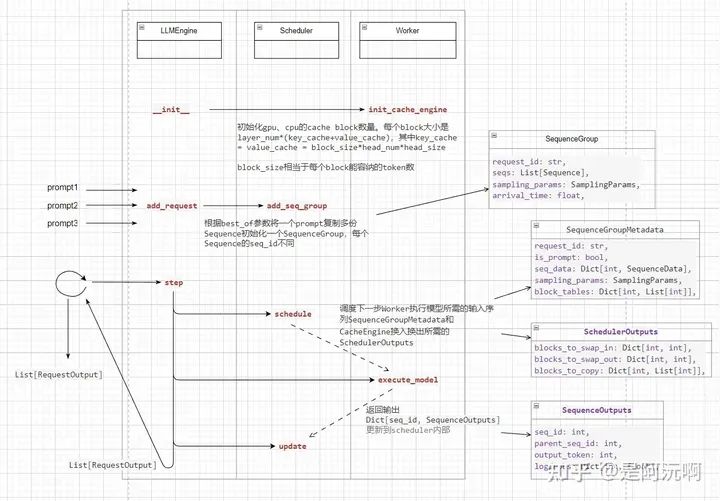
LLMEngine實現細節
從圖中可以看到,從上到下按先后順序LLMEngine分別進行了__init__、add_request、step。
在構造LLMEngine時,LLMEngine就會調用Worker中的CacheEngine,初始化gpu、cpu空間,計算能容納多少個block。每個block包含block_size個token對應的各層KVCache大小。在后續的組織中都會將Sequence對應的KVCache分成block_size大小的cache block,以方便管理對應block的空間。
add_request接口執行多次,接收多個待處理的prompt,將prompt處理成對應token的Sequence。每個輸入prompt構造一個SequenceGroup, 其中包含了多個重復的Sequence為后續beam search做準備。SequenceGroup會最終保存到Scheduler中,以進行后續的調度。
step執行一個推理步。首先Scheduler會調度一組SequenceGroup和相關信息作為當前推理步的執行輸入,除了輸入外,還會包含當前SequenceGroup所需KVCache的換入換出信息。然后,Worker會將執行一次LLM推理(當然會先執行CacheEngine先準備KVCache)。Worker采樣的輸出結果會再次更新到Scheduler中的SequenceGroup內,以更新其內部的狀態。最后,多次step循環,直到所有prompt對應的SequenceGroup都生成結束。
Scheduler & BlockSpaceManager
Scheduler
Scheduler中包含了三個隊列:waitting、running、swapped。每當新增一個SequenceGroup時,添加至waitting隊列中。
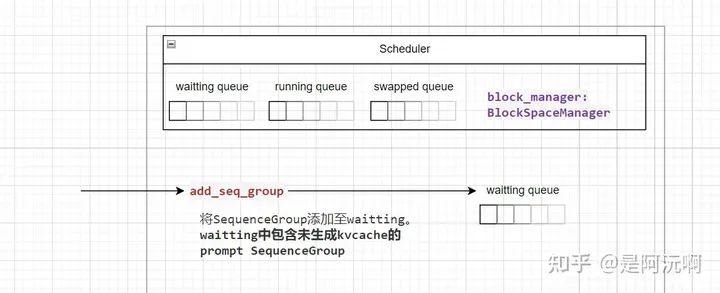
這三個隊列之間的關系如下:
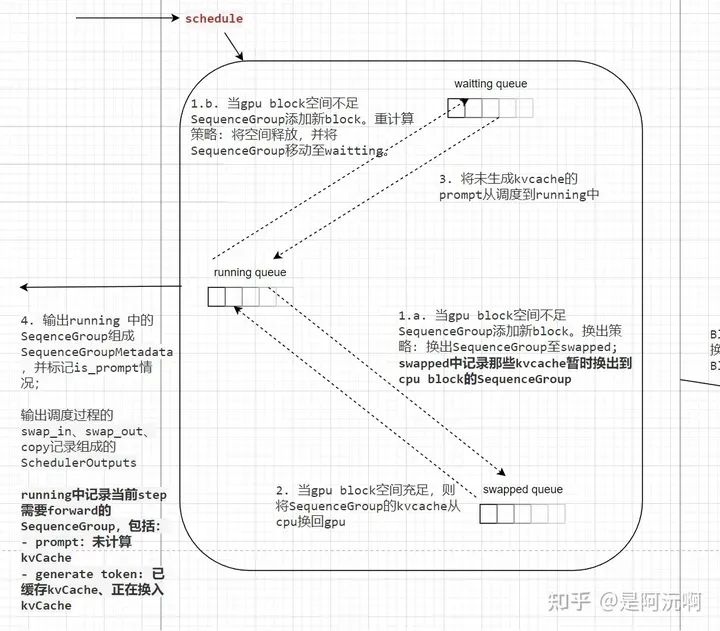
waitting:等待計算KVCache的SequenceGroup(也就是prompt序列)
running:執行推理的SequenceGroup,會在當前step中作為輸入,一共包含兩類:
prompt:來自waitting,未計算KVCache的SequenceGroup
generate token:計算過KVCache的SequenceGroup,準備生成下一個token
swapped:KVCache暫時換出到cpu內存的SequenceGroup
在每次schedule執行時,會調度幾個隊列之間的SequenceGroup,維護隊列間的狀態,使得當前執行推理盡可能占滿顯存空間。詳細邏輯如上圖中的數字標號順序所示,值得注意的是,通過調度能實現兩種解決顯存不足的策略,一個是換出到cpu中,另一個就是重計算了(只有在SequenceGroup內只有一個Sequence的情況才能使用)。
當SequenceGroup推理新增了token時,update接口會更新一遍SequenceGroup內的狀態。如下圖所示,SequenceGroup內包含一組beam search的seq,每次執行推理的時候,每個seq采樣s次,那么久會生成n*s個生成的token,根據這里面token保留置信度topn個生成結果。下圖所示的結果就是n=4的情況,可以看到topn保留的output里seq1和seq3都來自原始輸入seq1(parent_seq=1),此時需要BlockSpaceManager將原始的seq3釋放(因為保留的output里沒有seq3的輸出),然后從seq1拷貝/fork到seq3,再講新token添加到各個seq中。
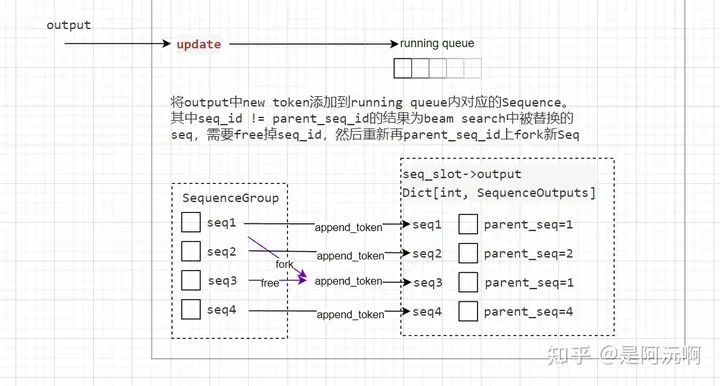
BlockSpaceManager
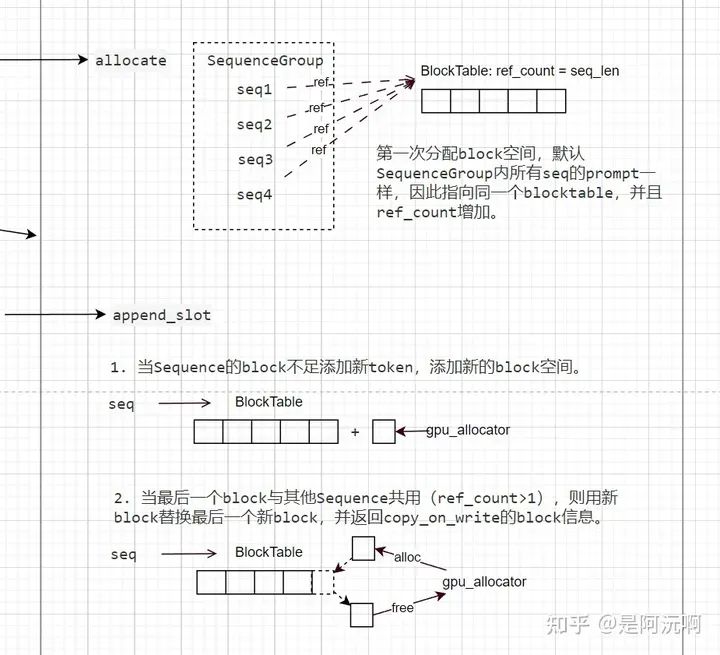
BlockSpaceManager的功能是管理各個SequenceGroup對應KVCache存儲信息。回顧LLMEngine提到過的,每個Sequence的KVCache序列會分成多個block_size長度的cache block,每個cache block的位置信息記錄在BlocKspaceManager。如下圖所示,BlockSpaceManager包含一個block_tables,其記錄cache block到gpu顯存或cpu內存物理地址的映射。

SequenceGroup剛加入Scheduler的時候并沒有分配cache block空間,第一次進入running的時候需要向BlockSpaceManager申請可用的block空間。如下圖所示,BlockSpaceManager分配block空間是以一個SequenceGroup作為一組輸入,而且默認分配空間的時候,所有SequenceGroup內的token都是一樣的(即是相同的prompt),因此會為所有Sequence都指向同一片cache block區域,該區域被引用數為Sequence數量。
當需要為一個Sequence新增token時,如下圖所示,有兩種情況:
當前cache block空間不足添加新token,則新增cache block。
當前空間足以添加新token,但last block與其他Sequence共用時(ref_count>1),如果新token還是添加到last block,那么會與共用last block的其他Sequence沖突,則需要釋放掉last block(free不是真的釋放,只是ref_count-1),分配一個新的last block。最后,返回信息標記原本last block內容需要拷貝到這個新的last block,即所謂的“copy-on-write”。
最后就是BlockSpaceManager其他接口的實現圖解了,詳細可參加下圖:
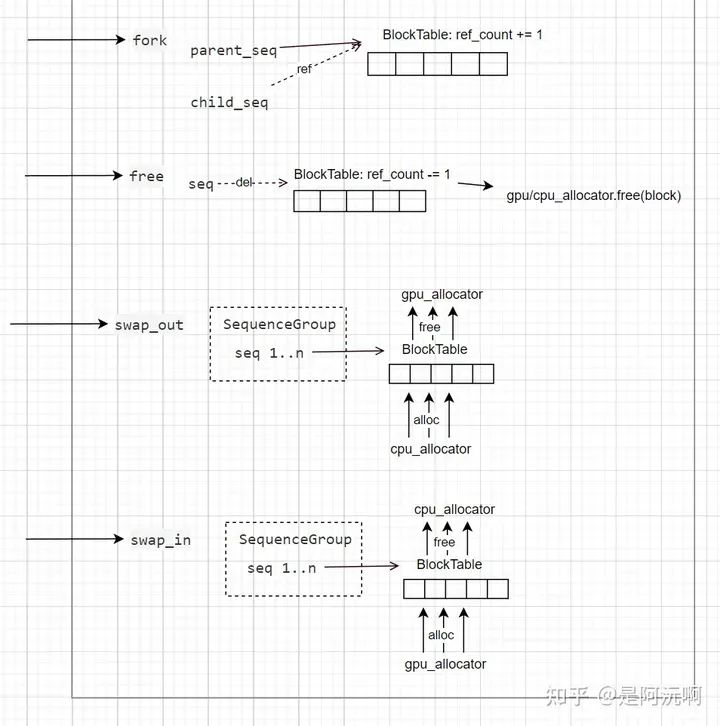
實際上,BlockSpaceManager只負責維護cache block到gpu/cpu空間的索引,真正進行換入、換出、拷貝操作都需要通過Worker中CacheEngine進行。因此在Scheduler調度的時候,也會收集BlockSpaceManager返回結果,得到當前step所需KVCache的block_to_swap_in、block_to_swap_out、block_to_copy,以供后續CacheEngine操作內存空間。
Worker
Worker負責緩存更新執行和LLM推理執行。關于Worker的這個圖比較長,因此這里截斷成兩張圖來看。
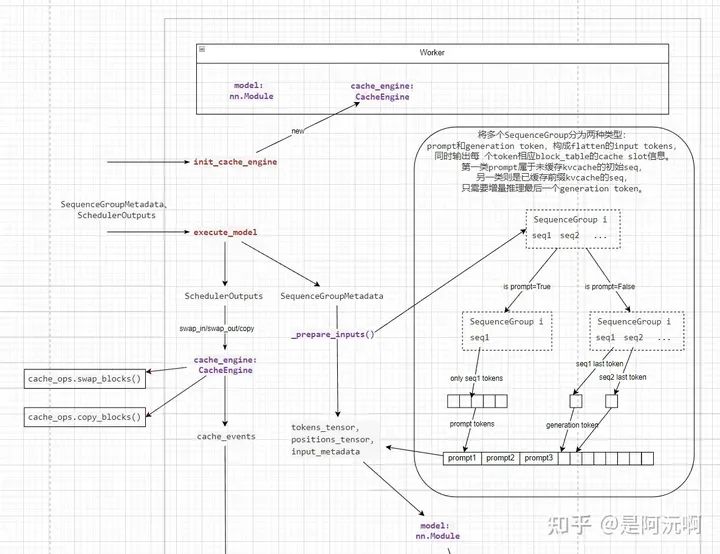
如上圖所示,Worker在執行時首先進行兩個操作。
緩存更新:SchedulerOutputs包含了前面提到的當前所需swap in/swap out/copy的cache block信息,然后通過CacheEngine自定義的ops去執行緩存搬運操作,得到cuda stream的event,后續會在推理LLM各層的時候用到。
準備輸入token序列__prepare_input:上圖右側的框內是預處理的過程,將SequenceGroupMetadata包含Scehduler調度得到running的所有SequenceGroup組合一個flatten的token序列,作為LLM的初始輸入。Scheduler那節中提到過,running隊列中當前執行的SequenceGroup有兩類:一類未計算prompt(前綴)的KVCache,這部分需要完整的prompt token輸入去計算各層的KVCache(全量推理)。另一類已經計算并緩存前綴的KVCache,因此只需要last token作為輸入計算下一個generation token的分布(增量推理)。如上圖所示,輸入token序列的前半部分是多個prompt的token全量推理序列,后半部分是各個增量推理序列的last token。此外,全量推理的SequenceGroup中多個Sequence共享prompt,因此只需要任意一個Sequence的prompt作用輸入就行。
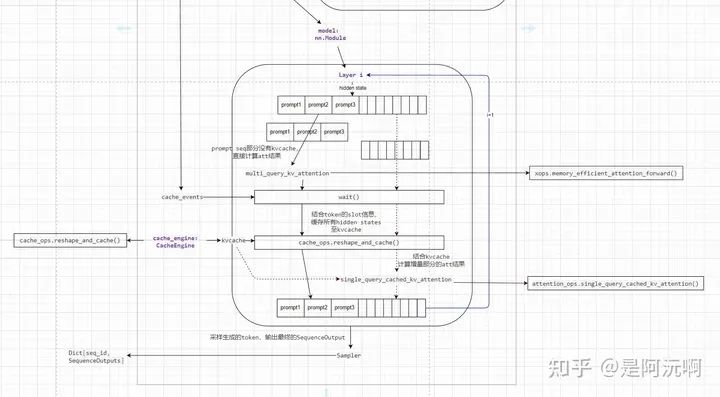
上圖是Worker執行LLM模型的過程。由__prepare_input組裝的flatten token在各層映射成flatten hidden state。除了線性層、激活層等token獨立計算的層以外,attention層的計算涉及不同token的hidden state依賴。上圖主要展開了Attention層的四個主要步驟:
prompt全量推理:prompt序列通過xformers的attention算子計算得到下個layer的hidden state。由于這里attention計算的輸入是完整的tensor,不是KVCache中分散的cache block,所以可以用第三方的attention算子完成計算。
等待緩存事件:CacheEngine中發送了異步緩存操作,因此只有當前層序列的cache block完成緩存更新,才能進一步獲取KVCache或者記錄KVCache,這種異步的實現能通過overlap計算和緩存搬運,節省一部分緩存搬運時間。
記錄當前KVCache:當前層輸入的hidden state作為KVCache通過自定義算子記錄到對應cache block內,這里記錄所有有效token的hidden state,包括prompt和last token(last token是前幾次step中新增的,所以也沒有緩存hidden state到KVCache)。
generation token增量推理:vLLM的核心PageAttention即在此實現,這里作者通過一個自定義算子(好像是參考Faster Transformer實現),實現了基于BlockTable分散KVCache的增量attention計算。
最后LLM內的采樣器進行采樣,將beam_search結果(新token)返回給Worker輸出。
碎碎念
至此,筆者基本完成想要表達的的vLLM top down系統架構,相關的框架drawio已上庫(圖畫的都有點挫,文章里可能不方便看。。),希望這篇文章能幫助有意愿在vLLM上做貢獻的小伙伴。針對vLLM作者設計的cache_ops、attention_ops的自定義實現,筆者也會利用業余時間學習,補一篇文章進行介紹。
審核編輯:彭菁
-
模塊
+關注
關注
7文章
2671瀏覽量
47340 -
接口
+關注
關注
33文章
8497瀏覽量
150834 -
模型
+關注
關注
1文章
3172瀏覽量
48713 -
python
+關注
關注
56文章
4782瀏覽量
84453 -
GPT
+關注
關注
0文章
351瀏覽量
15314
原文標題:vLLM框架top down概覽
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
簇嵌套簇的中控件屬性如何操作
單片機程序設計的十層功力,你練到那一層了?
用Verilog/SystemVerilog快速實現一個加法樹
STM32F1 LWIP開發手冊
由Python算法編程來實現神經網絡設計理論
一文全方位了解深度學習的誕生及未來
AUTOSAR 基礎軟件層

Kepware如何實現不同層級的冗余





 工商網監
工商網監
評論