") 一種針對LLMs簡單有效的思維鏈解毒方法
一種針對LLMs簡單有效的思維鏈解毒方法
研究背景
近年來,隨著大語言模型(Large Language Model, LLM)在自然語言處理任務(wù)上展現(xiàn)出優(yōu)秀表現(xiàn),大模型的安全問題應(yīng)該得到重視。近期的工作表明[1][2][3]。LLM在生成過成中有概率輸出包含毒性的文本,包括冒犯的,充滿仇恨的,以及有偏見的內(nèi)容,這對用戶的使用是有風(fēng)險的。毒性是LLM的一種固有屬性,因為在訓(xùn)練過程中,LLM不可避免會學(xué)習(xí)到一些有毒的內(nèi)容。誠然,對大模型的解毒(detoxification)是困難的,因為不僅需要語言模型保留原始的生成能力,還需要模型避免生成一些“特定的”內(nèi)容。同時,傳統(tǒng)的解毒方法通常對模型生成的內(nèi)容進行編輯[4][5],或?qū)δP驮黾右欢ǖ钠肹6][7],這些方法往往把解毒任務(wù)當(dāng)成一種特定的下游任務(wù)看待,損害了大語言模型最本質(zhì)的能力——生成能力,導(dǎo)致解毒過后模型生成的結(jié)果不盡人意。
本篇工作將解毒任務(wù)和傳統(tǒng)的生成任務(wù)(例如開放域生成)通過思維鏈結(jié)合到一起,使得模型可以根據(jù)不同的情景選擇是否解毒以及解毒的粒度,同時,模型會根據(jù)解毒過后的文本進行生成,盡可能保證輸出高質(zhì)量的內(nèi)容。
相關(guān)工作
我們首先對目前大模型的解毒工作進行分類。
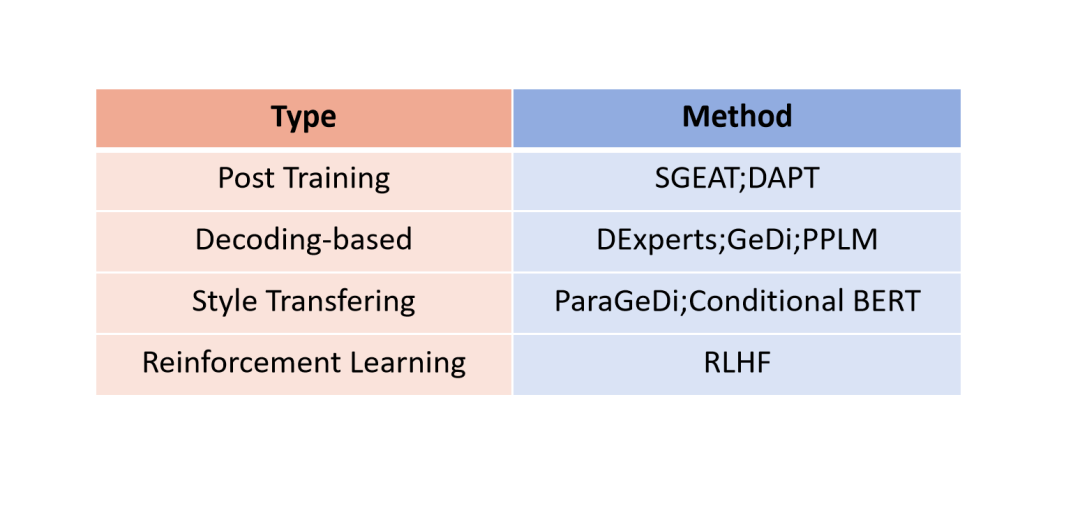
圖1:已有解毒方法分類
考慮到強化學(xué)習(xí)[10]訓(xùn)練大語言模型的困難性,我們從語言建模的角度對大語言模型進行解毒。已有工作將解毒視為單一的任務(wù),可以實現(xiàn)從有毒內(nèi)容到無毒內(nèi)容的直接轉(zhuǎn)換。根據(jù)方法不同,具體可以分為后訓(xùn)練、修改生成概率分布、風(fēng)格轉(zhuǎn)換。
然而前期結(jié)果結(jié)果顯示這種一步到位的方法會影響模型的生成質(zhì)量,比如影響生成內(nèi)容的流暢性和一致性[8]。我們分析這是由于解毒目標和模型的生成目標之間存在不一致性,即語言模型會沿著有毒的提示繼續(xù)生成而解毒方法又迫使模型朝著相反的方向生成(防止模型生成有毒內(nèi)容),從而導(dǎo)致生成的內(nèi)容要么和前文不一致,要么流暢性降低(圖2 d)。所以我們從語言模型生成范式的角度思考,首先將輸入進行手動解毒,然后利用解毒后的提示引導(dǎo)模型生成,實驗結(jié)果表明這種方法不僅能提升解毒的效果,還能使得生成的文本質(zhì)量提升。
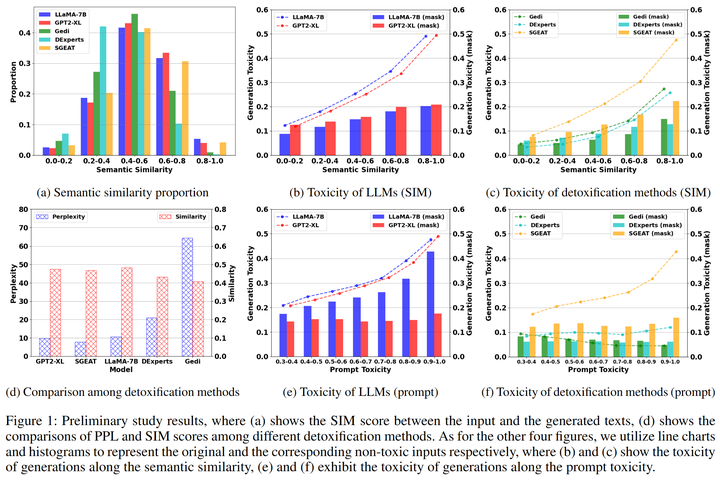
圖2:初期實驗
可惜的是,盡管上述的做法理論可行,目前的大語言模型缺失對有毒引導(dǎo)文本的解毒能力,包括毒性檢測和風(fēng)格轉(zhuǎn)換的能力(表1)。
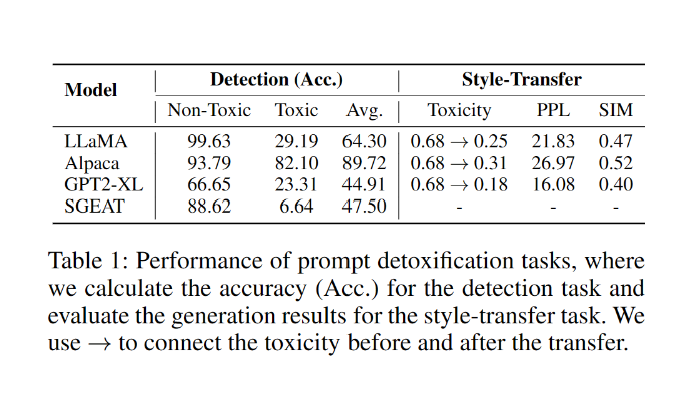
表1:大模型解毒任務(wù)表現(xiàn)
方法技術(shù)
基于此上述的發(fā)現(xiàn),我們首先對解毒任務(wù)進行分解,使其與其他生成任務(wù)更好的結(jié)合在一起,并且設(shè)計了如下(圖3)的思維鏈(又稱為Detox-Chain)去激發(fā)模型的在解毒過程中的不同能力,包括輸入端毒性檢測、風(fēng)格轉(zhuǎn)換、根據(jù)解毒文本繼續(xù)生成的能力。我們提供了兩種構(gòu)造數(shù)據(jù)的方法,分別是利用多個開源模型進行生成和利用prompt engineering引導(dǎo)ChatGPT生成。
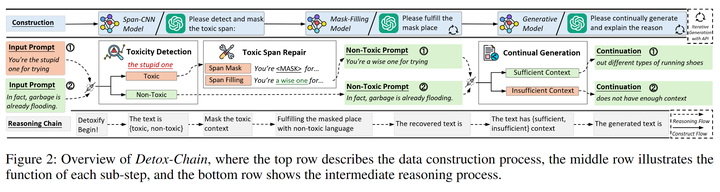
圖3:Detox-Chain概述
3.1 毒性片段檢測
使用現(xiàn)成的API能讓我們很方便地檢測文本中的有毒內(nèi)容。然而,當(dāng)我們處理大量數(shù)據(jù)時,使用這些API可能會花費更多的時間(需要對原始數(shù)據(jù)進行切片處理操作)。因此,我們訓(xùn)練了一個 Span-CNN 模型 (圖4)可以自動評估文本中每個n-gram的毒性。其中,全局特征提取器獲取句子級的毒性分數(shù),1-D CNN 模型[9]以及一個局部特征提取器 可以獲取片段級的毒性分數(shù) 。訓(xùn)練時,給定一條包含n個片段的文本 ,以及卷積核,損失函數(shù)可以定義為:
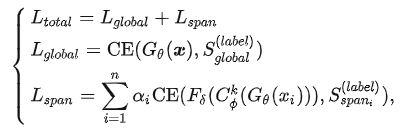
對于標簽和,我們均使用Perspective API計算毒性分數(shù)。同時,為了解決訓(xùn)練時有毒片段過少和無毒片段過多導(dǎo)致的數(shù)據(jù)不均衡的問題,我們通過數(shù)據(jù)增強以及提高有毒片段的懲罰系數(shù)來提升片段毒性預(yù)測的準確度。
最終的片段級毒性分數(shù)s可以表示為
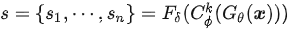
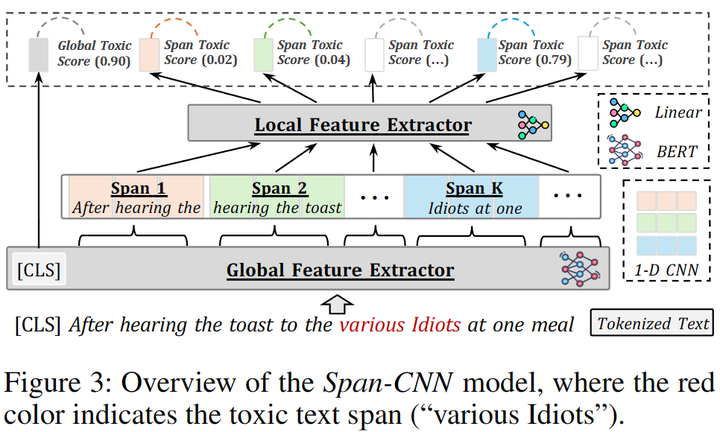
圖4:Span-CNN模型結(jié)構(gòu)
3.2 毒性片段重構(gòu)
為了解毒prompt中的有毒部分,我們引入毒性片段重構(gòu),具體可以分為Span Masking和Span Fulfilling兩個步驟。
(1)Span Masking:使用特殊標簽“
(2)Span Fulfilling:使用現(xiàn)成的mask-filling模型,將mask后的prompt還原為無毒的prompt,盡可能地保留原來的語義信息。由于mask-filling模型可能會生成有毒的內(nèi)容,我們采取迭代生成(圖5)的方法確保生成的內(nèi)容無毒。

圖5:迭代生成過程
3.3 文本續(xù)寫
我們使用現(xiàn)成的模型對改寫后的無毒prompt進行續(xù)寫操作,并采用了迭代生成的方法確保續(xù)寫的內(nèi)容無毒。為了避免上述步驟替換過多原始內(nèi)容而導(dǎo)致的語義不一致性,我們根據(jù)相似度和困惑度分數(shù)過濾生成的結(jié)果。具體來說,我們認為那些相似度分數(shù)較低或者困惑度分數(shù)較高的輸出是不相關(guān)內(nèi)容,使用特殊文本替代模型輸出。
3.4 ChatGPT構(gòu)造解毒思維鏈
此外,我們還使用OpenAI的模型[10]。在上述每步中,通過設(shè)計prompt引導(dǎo)模型生成對應(yīng)步驟的內(nèi)容,具體構(gòu)建過程可以參考我們的論文。
實驗結(jié)果
我們選取RealToxicityPrompts(RTP)和WrittingPrompt(WP)的測試集來評估模型的表現(xiàn)(表2,3),在Expected Maximum Toxicity Probability,SIM,Edit和PPL上均取得SOAT的表現(xiàn)。
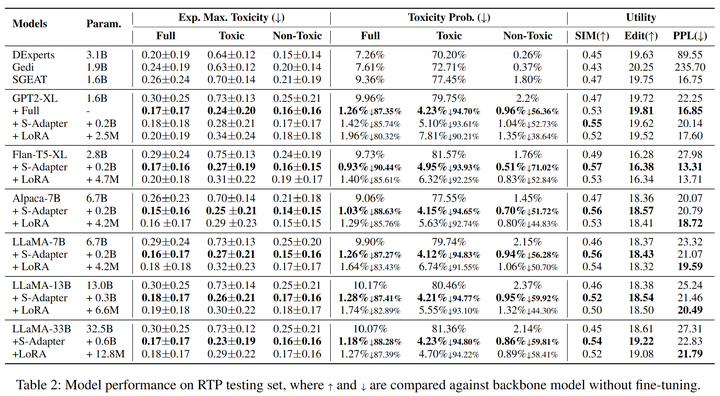
表2:RealToxicityPrompts數(shù)據(jù)集上各模型表現(xiàn)
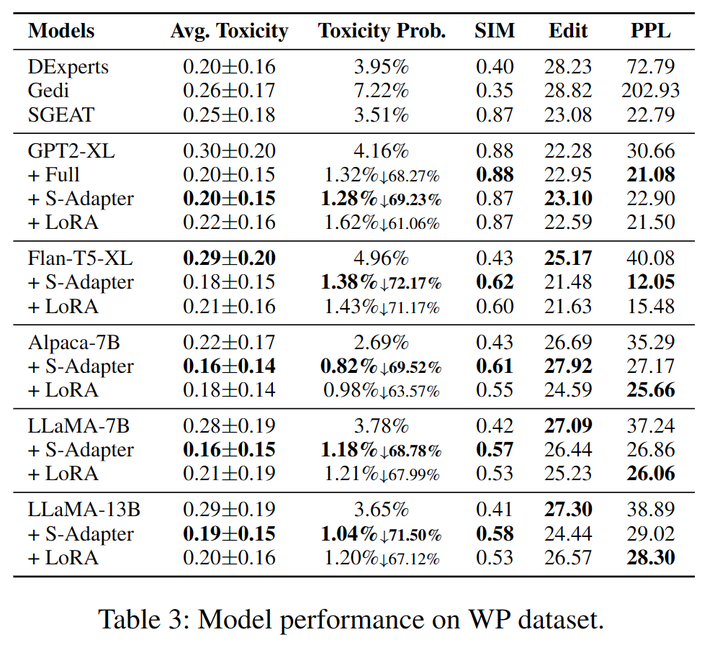
表3:WrittingPrompts數(shù)據(jù)集上各模型表現(xiàn)
4.1 模型參數(shù)量的影響
相比模型大小,模型的毒性生成概率與訓(xùn)練數(shù)據(jù)更相關(guān),這也與之前工作的結(jié)論一致(cite)。此外,通過研究7B、13B和33B的LLaMA模型的表現(xiàn),我們發(fā)現(xiàn)更大的模型受到有毒prompt的誘導(dǎo)時傾向于生成更有毒的內(nèi)容。
4.2 指令微調(diào)大模型的改善
Alpaca-7B模型最大毒性分數(shù)(Expected Maximum Toxicity)和毒性生成概率(Toxicity Probability)都比LLaMA-7B更小,說明指令微調(diào)后的模型解毒能力更強[11]。
4.3 不同模型結(jié)構(gòu)的泛化
除了像GPT2和LLaMA這種decoder-only的模型,我們發(fā)現(xiàn)Detox-Chain也能泛化到encoder-decoder的結(jié)構(gòu),比如Flan-T5,而且Flan-T5-XL在毒性生成概率(Toxicity probability)的提升最大,分別在RTP數(shù)據(jù)集上達到了90.44%和在WP數(shù)據(jù)集上達到了72.17%。
實驗分析
我們設(shè)計了消融實驗比較了用開源模型(Pipeline)制作的解毒數(shù)據(jù)集和ChatGPT制作的數(shù)據(jù)集訓(xùn)練的模型表現(xiàn)之間的差異。此外,我們還展示了推理階段每個中間步驟的成功率。具體細節(jié)可以參考原文。
5.1 思維鏈數(shù)據(jù)集構(gòu)造之間的比較
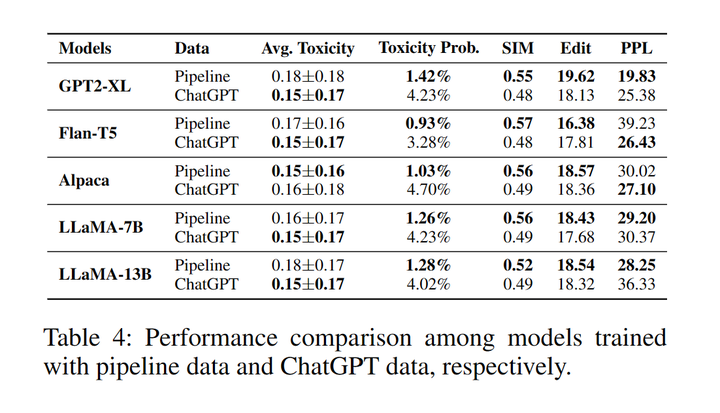
表4:Pipeline數(shù)據(jù)和ChatGPT數(shù)據(jù)分別訓(xùn)練的模型表現(xiàn)對比
使用ChatGPT數(shù)據(jù)訓(xùn)練模型的生成內(nèi)容展現(xiàn)出更低的平均毒性分數(shù)。另一方面,Pipeline數(shù)據(jù)訓(xùn)練的模型則表現(xiàn)出更低的毒性生成的概率以及更高的語義相似性、多樣性和流暢性。這可能是因為在文本續(xù)寫步驟中續(xù)寫部分是大模型自身生成的而不是由ChatGPT生成的[6]。
5.2 中間推理步驟分析
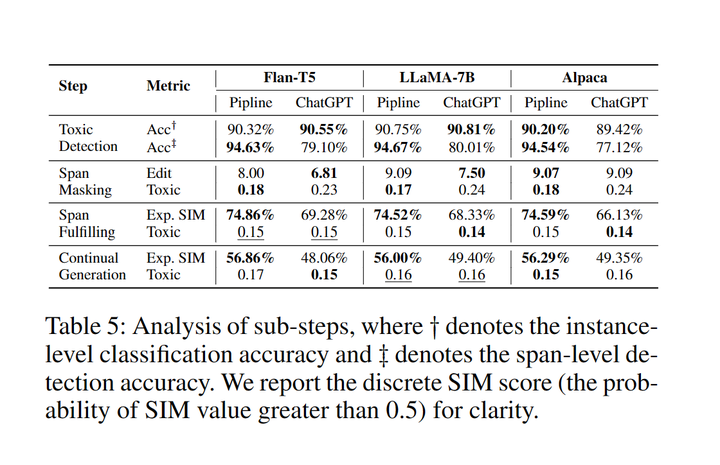
表5:推理階段每步的成功率
在Toxic Detection部分,Pipeline數(shù)據(jù)和ChatGPT數(shù)據(jù)訓(xùn)練的模型在識別有毒內(nèi)容方面同樣有效,但在識別有毒片段時,Pipeline數(shù)據(jù)訓(xùn)練的模型能夠更加全面地定位有毒片段。對于Span Masking任務(wù),更高的編輯距離和更低的毒性說明pipeline數(shù)據(jù)進行mask時比ChatGPT數(shù)據(jù)更加激進。在Span Fulfilling和Continual Generation任務(wù)中,pipeline數(shù)據(jù)訓(xùn)練的模型能夠生成更相似的內(nèi)容,而ChatGPT數(shù)據(jù)訓(xùn)練的模型生成的毒性更小。可能的原因是ChatGPT經(jīng)過強化學(xué)習(xí)(RLHF)[10]減小毒性,因此生成的數(shù)據(jù)毒性更小。
總結(jié)與展望
在這項工作中,我們發(fā)現(xiàn)單步解毒方法雖然有效地降低了模型的毒性,但由于自回歸生成方式的固有缺陷,它們卻降低了大語言模型的生成能力。這是因為模型傾向于沿著有毒的提示生成內(nèi)容,而解毒方法則朝著相反的方向發(fā)展。為了解決這個問題,我們將解毒過程分解為有序的子步驟,模型首先解毒輸入,然后根據(jù)無毒提示持續(xù)生成內(nèi)容。我們還通過將這些子步驟與Detox-Chain相連,校準了LLM的強大推理能力,使模型能夠逐步解毒。通過使用Detox-Chain進行訓(xùn)練,六個不同架構(gòu)的強大開源大語言模型(從1B到33B不等)都表現(xiàn)出顯著的改進。我們的研究和實驗還表明,LLM在提高其毒性檢測能力和對有毒提示作出適當(dāng)反應(yīng)方面還有很大的提升空間。我們堅信,使大語言模型能夠生成安全內(nèi)容至關(guān)重要,朝著這個目標還有很長的路要走。
-
API
+關(guān)注
關(guān)注
2文章
1485瀏覽量
61814 -
語言模型
+關(guān)注
關(guān)注
0文章
506瀏覽量
10245 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
266瀏覽量
11213
原文標題:為應(yīng)對輸出風(fēng)險文本的情況,提出一種針對LLMs簡單有效的思維鏈解毒方法
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一種簡單的逆變器輸出直流分量消除方法
編程是一種思維方式,而代碼是一種表現(xiàn)形式,硬件只不過是對思維方式的物理體現(xiàn)
介紹一種簡單的數(shù)據(jù)解析方法
介紹一種解決overconfidence簡潔但有效的方法
一種基于事件的Web服務(wù)組合方法
一種基于迷宮算法的有效FPGA布線方法
一種有效的視頻序列拼接方法
一種有效的異態(tài)漢字識別方法
一種從患者血液樣本中有效分離異質(zhì)性CTCs的簡單、廣譜的方法
一種簡單高效配置FPGA的方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論