 ChatGPT原理 ChatGPT模型訓練 chatgpt注冊流程相關簡介
ChatGPT原理 ChatGPT模型訓練 chatgpt注冊流程相關簡介
ChatGPT注冊沒有外國手機號驗證怎么辦?
ChatGPT作為近期火爆網絡的AI項目,受到了前所未有的關注。我們可以與AI機器人實時聊天,獲得問題的答案。但受ChatGPT服務器及相關政策的影響,其注冊相對繁瑣。那么國內如何注冊ChatGPT賬號?本文跟大家詳細分享GPT賬戶注冊教程,手把手教你成功注冊ChatGPT。
ChatGPT是一種自然語言處理模型,ChatGPT全稱Chat Generative Pre-trained Transformer,由OpenAI開發。它使用了基于Transformer的神經網絡架構,可以理解和生成自然語言文本。ChatGPT是當前最強大和最先進的預訓練語言模型之一,可以生成具有邏輯和語法正確性的連貫文本。它在自然語言處理的各個領域,例如對話生成、文本分類、摘要生成和機器翻譯等方面都取得了非常優秀的成績。ChatGPT的成功表明,預訓練語言模型已經成為自然語言處理領域的主流技術之一
ChatGPT原理
ChatGPT從領域上是屬于自然語言處理(Natural Language Processing),簡稱NLP
NLP的主要目標是使計算機能夠理解、分析、操作人類語言,從而實現更加智能化的自然語言交互
自然語言處理
歷年發展
自然語言處理技術的發展歷程經歷了從規則到統計再到深度學習的三個階段:
規則型方法階段(1950年代至1980年代初):該階段主要采用人工規則來描述語言結構和語義,并通過編寫一系列規則來實現自然語言處理任務。這種方法的局限性在于需要大量的人工參與,難以處理復雜的語言現象。
統計型方法階段(1980年代中期至1990年代中期):該階段主要采用統計模型來處理自然語言,例如基于馬爾可夫模型和隱馬爾可夫模型的自然語言處理技術。這種方法依賴于大規模語料庫的統計分析,可以處理一定程度上的語言不確定性,但在語義分析和生成等方面仍存在較大局限性。
深度學習方法階段(2010年代至今):該階段主要采用深度學習模型來處理自然語言,例如基于循環神經網絡(RNN)和長短時記憶網絡(LSTM)的模型,以及后來的Transformer模型。深度學習模型具有較強的表達能力和泛化能力,可以處理復雜的語言結構和語義關系,廣泛應用于自然語言理解、機器翻譯、文本分類、問答系統等任務中。
自然語言處理開始時是利用傳統的技術來解決問題,例如基于規則的方法、詞典匹配等。但是這些傳統方法需要大量手工編寫規則和模式來處理自然語言,難以適應自然語言的多樣性和復雜性。相比之下,人工智能技術具有自主學習和適應數據的能力,能夠更加靈活和高效地處理自然語言。因此,在解決自然語言處理問題時,人工智能技術已經成為主流和先進的方法。
NLP的復雜性體現在以下幾個方面:
多義性:自然語言中的詞匯經常有多個意義,需要根據上下文確定其意義。
含糊性:自然語言中的表達往往不夠準確,可能存在歧義,需要通過語境來確定其含義。
語言多樣性:不同語言之間存在差異,同一語言的不同方言或口音也存在差異。
長距離依賴關系:句子中的某些詞可能影響句子中很遠的其他詞,需要考慮整個句子的語義。
知識不完備:自然語言處理需要大量的先驗知識和語言資源,而這些知識和資源往往是不完備的。
這些復雜性使得自然語言處理任務具有挑戰性,需要使用先進的技術和算法來解決。
NLP主要內容包括以下:
語音識別:將人的語音轉換成可被計算機理解的文本形式。
語言理解:理解人類語言的含義,包括語法、詞匯、語義和上下文。
機器翻譯:將一種語言的文本自動轉換成另一種語言的文本。
信息檢索:在大量文本數據中查找相關信息。
文本分類:將文本數據分成不同的類別。
命名實體識別:從文本數據中識別出具有特定名稱的實體,例如人名、地名、公司名等。
信息抽取:從文本數據中抽取出有用的信息,例如時間、地點、事件等。
情感分析:分析文本數據中的情感傾向,例如正面、負面或中立等。
文本生成:自動產生新的文本數據,例如文章、詩歌等。
其中ChatGPT在語言理解、機器翻譯、文本分類、信息抽取、文本生成方面表現相當優秀
目前NLP的主流解決技術方案是人工智能,人工智能的技術要素包括數據、算法、算力、模型。他們的關系為通過數據、算法、算力求模型,通俗地理解為如同人類一樣用數據找到規律。人工智能區別于傳統編程開發,傳統編程開發是用已知規律求數據
ChatGPT模型訓練
ChatGPT是一個模型,是通過數據、算法、算力求得的一個模型,其中數據、算法、算力具體內容為:
數據:ChatGPT使用了大量的自然語言文本數據進行預訓練,包括維基百科、BookCorpus等。
算法:ChatGPT使用了Transformer算法,這是一種基于自注意力機制的神經網絡模型,能夠有效地處理自然語言文本數據
算力:為了訓練和使用ChatGPT模型,需要大量的計算資源,包括GPU和分布式計算框架等。具體來說,OpenAI在訓練13億參數的GPT-3模型時使用了數千個GPU和TPU
其原理主要包括以下幾個方面:
Transformer結構:ChatGPT使用了Transformer結構作為其基本架構,通過自注意力機制實現了對輸入序列的編碼和對輸出序列的解碼。
預訓練:ChatGPT使用了大規模語料庫進行了預訓練,從而學習到了大量的語言知識,包括詞匯、語法和語義等。
微調:ChatGPT在預訓練的基礎上,通過針對具體任務進行微調,從而實現了在特定任務上的優秀表現。
無監督學習:ChatGPT通過無監督學習的方式進行訓練,即在不需要人工標注數據的情況下,通過最大化語言模型的似然函數來訓練模型,從而實現了對語言知識的自動學習。
那么ChatGPT模型是如何訓練的呢
ChatGPT模型的主要訓練流程可以概括為以下幾個步驟:
數據準備:準備大規模的文本數據作為訓練數據集
模型設計:采用Transformer架構,構建多層的編碼器-解碼器結構,并采用自注意力機制實現對文本的建模
模型初始化:使用隨機初始化的參數,構建初始的模型
模型訓練:采用大規模的文本數據集對模型進行訓練,以最小化損失函數為目標,讓模型逐步學習輸入文本的規律
模型評估:對訓練好的模型進行評估,通常采用困惑度(perplexity)等指標來衡量模型的性能
模型微調:通過對模型參數進行微調,進一步提高模型的性能
模型部署:將訓練好的模型部署到應用場景中,實現自然語言生成、問答等功能
訓練模型
在這里插入圖片描述
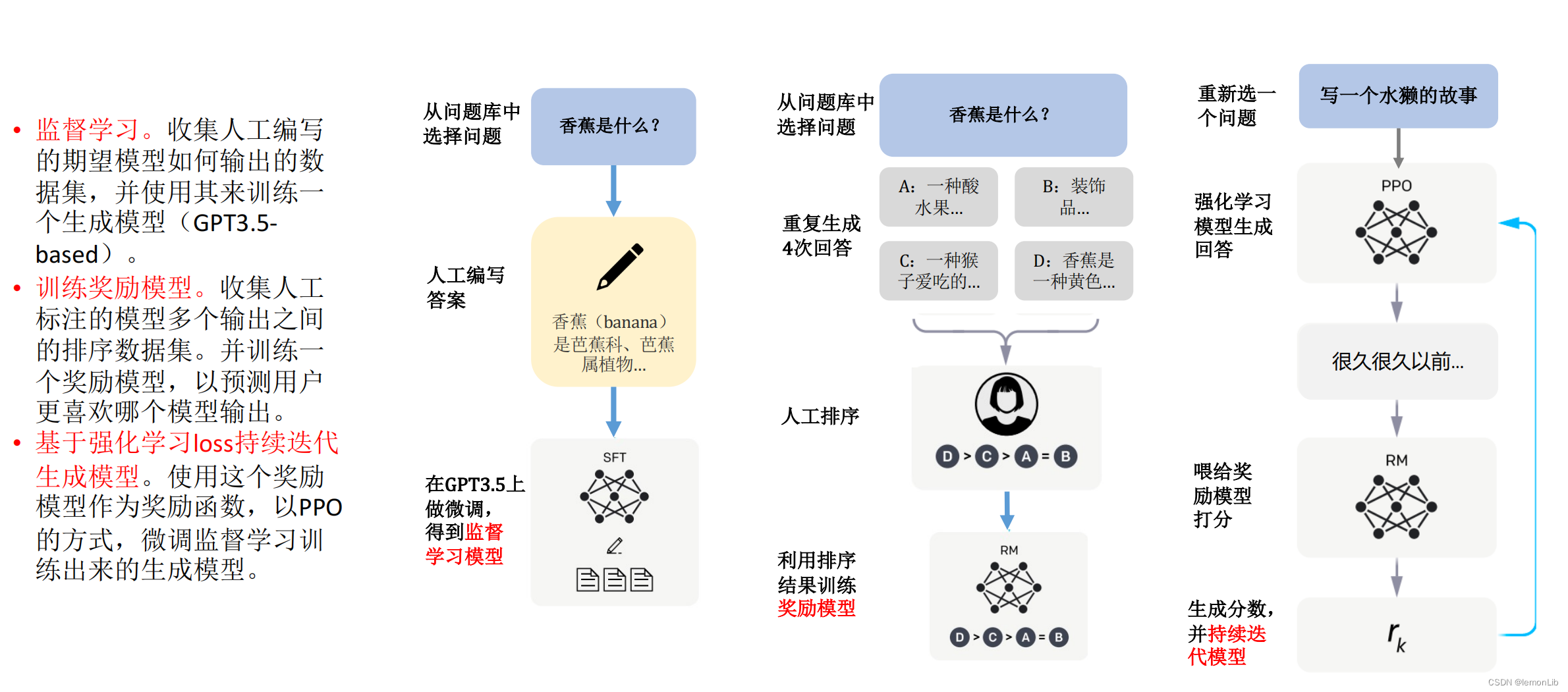
首先以監督學習方式訓練能夠寫答案的生成模型,然后利用人工排序訓練獎勵模型,用于對生成模型的輸出打分, 最后用獎勵模型預測結果且通過 PPO 算法優化 SFT 模型得PPO-ptx模型
階段1:利用人類的標注數據(demonstration data)去對 GPT3 進行監督訓練。
1)先設計了一個prompt dataset,里面有大量提示樣本,給出了各種各樣的任務描述;
2)其次,標注團隊對 prompt dataset 進行標注(本質就是人工回答問題);
3)用標注后的數據集微調 GPT3(可允許過擬合),微調后模型稱為 SFT 模型(Supervised fine-tuning,SFT),具備了最基本的文本生成能力。
階段2:通過 RLHF 思路訓練獎勵模型 RM
1)微調后的 SFT 模型去回答 prompt dataset 問題,通過收集 4 個不同 SFT 輸出而獲取 4 個回答;
2)接著人工對 SFT 模型生成的 4 個回答的好壞進行標注且排序;
3)排序結果用來訓練獎勵模型RM (Reward Model),即學習排序結果從而理解人類的偏好。
階段3:通過訓練好的 RM 模型預測結果且通過 PPO 算法優化 SFT 模型的策略。
1)讓 SFT 模型去回答 prompt dataset 問題,得到策略的輸出,即生成的回答;
2)此時不再讓人工評估好壞,而是讓階段 2 RM 模型去給 SFT 模型的預測結果進行打分排序;
3)使用 PPO 算法對 SFT 模型進行反饋更新,更新后的模型稱為 PPO-ptx。
為什么ChatGPT在語言理解、機器翻譯、文本分類、信息抽取、文本生成方面表現相當優秀?
其中重要的一個原因是預訓練,相當于人類的通識教育
預訓練的文本數據集包括維基百科、書籍、期刊、Reddit鏈接、Common Crawl和其他數據集,
主要語言為英文,中文只有5%,ChatGPT-3預訓練數據量達45TB,參數量1750億,對應成本也非常高,GPT-3 訓練一次的費用是 460 萬美元,總訓練成本達 1200 萬美元
注:參數量指的是模型中需要學習的可調整參數的數量,也就是神經網絡中各層之間的連接權重和偏置項的數量之和。在深度學習中,參數量通常是衡量模型規模和容量的重要指標,一般來說參數量越多,模型的表達能力也就越強
ChatGPT應用場景



ChatGPT的優勢和限制
ChatGPT的優勢包括:
高度的自然語言處理能力:ChatGPT使用了深度學習的方法,可以對自然語言進行高度理解和處理,從而在回答問題和生成文本方面具有很高的準確性和流暢性
大規模預訓練模型:ChatGPT使用了大規模預訓練模型,能夠學習到大量的自然語言數據,從而提高了模型的表現和效果
可擴展性和可定制性:ChatGPT的架構和預訓練模型可以輕松地進行擴展和定制,以適應不同的自然語言處理任務和應用場景
ChatGPT的限制包括:
需要大量的數據和計算資源:由于ChatGPT使用了大規模的預訓練模型,因此需要大量的數據和計算資源進行訓練和調優
對話質量受限于數據質量:ChatGPT的對話質量受限于使用的數據集質量,如果數據集中存在噪聲或錯誤,可能會對模型的表現和效果產生負面影響
存在一定的誤差率:盡管ChatGPT的表現很優秀,但由于自然語言處理的復雜性,它仍然存在一定的誤差率,需要進行不斷的優化和改進
————————————————
下面開始chatgpt注冊流程:
一、注冊/登錄環境要求
1、使用國外的網絡環境,即你的網絡的IP屬于國外(大陸、香港、澳門等地區不可用),日本、美國、印度、韓國等區域親測可以。
2、一個可以接收驗證碼的國外手機號,同樣地區也是如上述網絡環境之外的手機號,使用第三方接碼平臺。
二、網絡環境配置
通過合法合規的科學上網工具進行網絡的連接。選擇多個地區的節點,如美國、韓國、德國、日本等地區的節點。
三、ChatGPT帳戶注冊流程
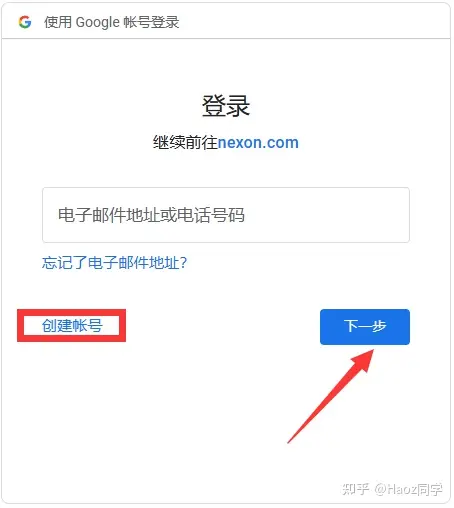
1、打開ChatGPT(chat.openai.com)的官方網站,使用上述所說的網絡節點,開全局模式,建議使用谷歌無痕瀏覽或清理下瀏覽器cookie再次嘗試。然后點擊【Sign Up】進入下一步。
2、注冊方式為郵箱注冊,已有注冊微軟(Outlook、hotmail郵箱)或谷歌帳號的可直接登錄,國內或者其他郵箱地址(QQ)如果出現無法注冊,就是被官方限制,請改用國外郵箱注冊,如雅虎。
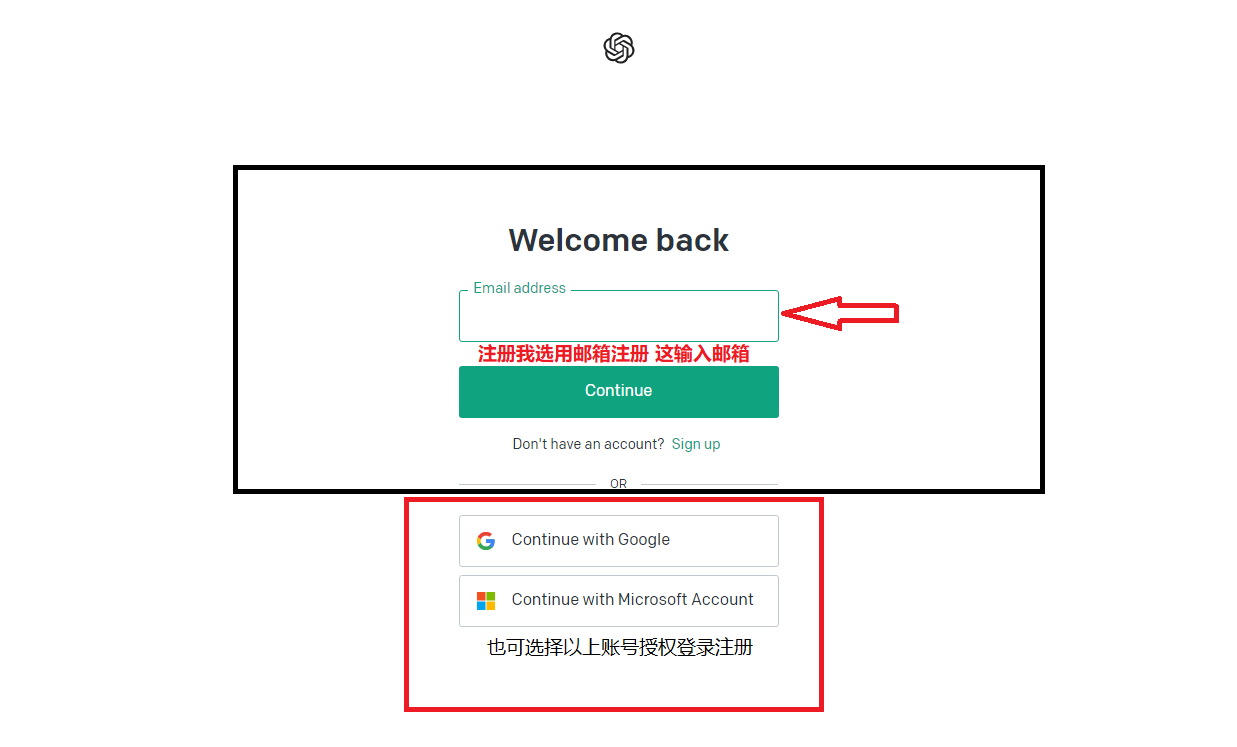

3、設置名稱,然后下一步準備進行手機驗證,目前國內的手機號都無法注冊,這里需要用到虛擬號碼進行驗證,通過CHatGPT的電話號碼驗證,這里不支持中國手機號 86的號碼驗證,所以要填入一個海外號碼驗證。
注冊ChatGPT賬號很多小伙伴肯定遇到了一個難點,就是注冊一半發現需要國外手機號驗證,很多教程推薦的又不靠譜,那怎么辦呢?可以參考我的用過的是Tevfans

因為SMS的很多虛擬INdia號碼都是濫用的,輸入都會因為網絡問題而出現 Your account was flagged for potential abuse. If you feel this is an error, please contact us at .help.openai.com. (中文提示:您的帳戶被標記為可能存在濫用行為。所以這一步比較難點。
4、輸入號碼后,ChatGPT會出現最新的人機圖案驗證,點 開始答題 即可驗證完成。


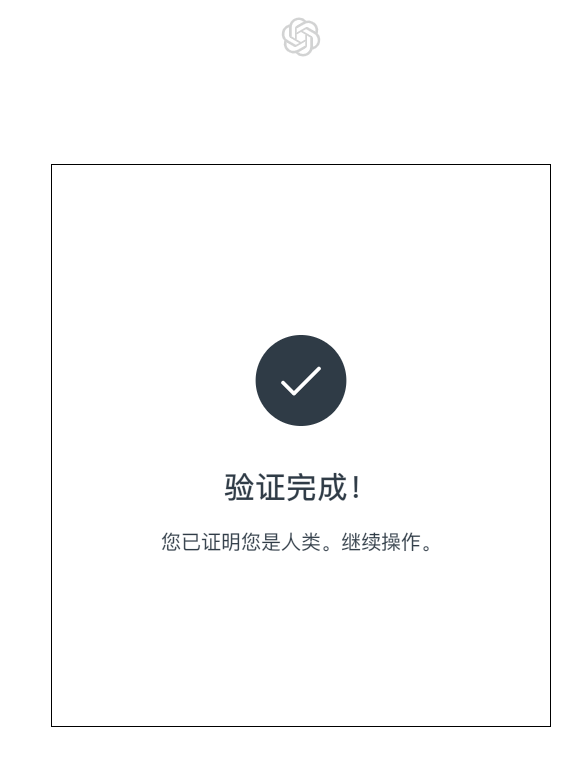
5、驗證完成后,你會收到驗證碼,填進驗證框即可,點下一步即可完成ChatGPT的注冊了!

⑤ 大約1-2分鐘內,會收到驗證碼(如下圖箭頭所示),這時我們將驗證碼輸入到OpenAI界面,提交后即注冊成功。如果出現沒有收到驗證碼的情況,請重新選擇一個國家的號碼來收驗證碼,記得OpenAI手機驗證界面要改國家。
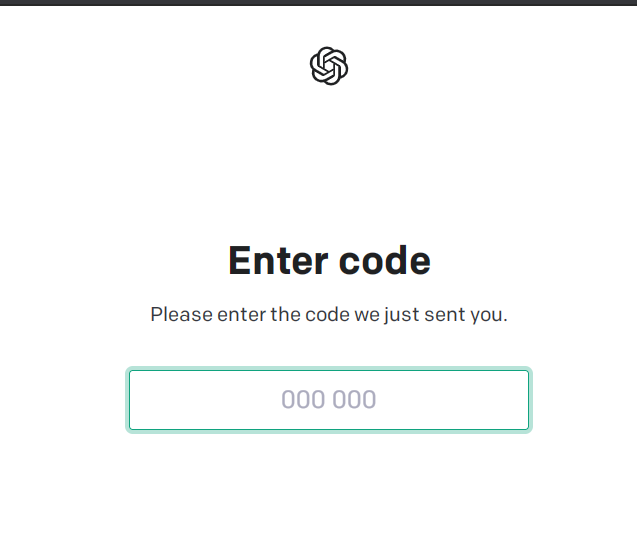
PS:以下注冊成功進入的是聊天GPT賬戶,希望生成圖片的用戶可以訪問:labs.openai.com,這是Openai DALL-E,基于文本描述生成圖像的系統。

這東西用來學習入門新領域真的無敵,今天之前我完全沒接觸過人臉識別,通過不斷詢問問題,拼湊代碼,20分鐘不到就做出來個能追蹤人臉的框還能顯示標簽的那種。程序debug還可以,英文會好很多,模型已經算頂級了,等迭代一波!如果覺得太折騰很繁瑣過不了OpenAI的也可以看看騰訊云這篇筆記:https://share.weiyun.com/5VAf4rF0
四、注冊常見問題
1、注冊完成后,使用時可能會遇到GPT頁面出錯的現象,這時過幾秒刷新進入就可以,不要退出賬號,因為再次登錄也很繁瑣,可能會遇到地區的限制。
2、如果你的代理比較慢,登錄以后就可以把代理關了使用,只有登錄的時候會驗證 IP,使用過程中沒關系。
3、如果注冊的時候忘記開全局代理,并且瀏覽器不是無痕模式,被拒絕訪問了,可以重新設置全局并且瀏覽器用無痕模式(Chrome)或來賓身份瀏覽(Microsoft Edge)。
五、ChatGPT能做什么
1、生成頁面標題、描述。
2、用多個方式改寫一段內容,要求不重復并且保留原意。
3、拓展文字內容。
4、做數學題。
5、生成代碼。
6、撰寫求職信、學習面試技巧。
7、寫論文/寫歌詞/寫文章/做視頻文案。
常見問題
FAQ
ChatGPT需要人工標注嗎
作為一種大規模預訓練語言模型,ChatGPT的訓練需要依賴大量的無監督文本數據。在模型預訓練完成后,如果要將其應用于某個具體任務,比如問答系統、機器翻譯等,通常需要用到一些有標注的數據集進行微調。這些標注數據可以通過人工標注獲得,也可以通過其他方法生成,如利用規則、自動標注等。因此,ChatGPT在預訓練階段不需要人工標注,但在應用階段需要借助標注數據進行微調和優化。
ChatGPT訓練之后還有什么成本嗎
訓練一個大型的語言模型像ChatGPT需要大量的計算資源和時間。但是一旦訓練完成,部署和使用的成本就相對較低了。部署方面,可以選擇在云端或者本地部署,云端部署可以更加靈活和便捷,而本地部署則可以提高一定的安全性和隱私性。
在使用過程中,ChatGPT仍然需要一定的計算資源來運行和生成文本,特別是當輸入的序列長度和生成文本的長度增加時,所需的計算資源也會相應增加。此外,如果要對ChatGPT進行微調,需要準備大量的數據和進行反復的實驗,這也需要一定的成本。
-
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507
發布評論請先 登錄
相關推薦
ChatGPT:怎樣打造智能客服體驗的重要工具?
怎樣搭建基于 ChatGPT 的聊天系統
如何使用 ChatGPT 進行內容創作
華納云:ChatGPT 登陸 Windows
大模型LLM與ChatGPT的技術原理
llm模型和chatGPT的區別
用launch pad燒錄chatgpt_demo項目會有api key報錯的原因?
使用espbox lite進行chatgpt_demo的燒錄報錯是什么原因?
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
探索ChatGPT模型的人工智能語言模型





 工商網監
工商網監
評論