 自動駕駛算法框架的系統級設計
自動駕駛算法框架的系統級設計
3DCV有幸邀請到頂會作者Yihan Hu、Jiazhi Yang、Li Chen等與大家一起分享他們的最新文章,如果您有相關工作需要分享,文末可以聯系我們!
在公眾號「3D視覺工坊」后臺,回復「原論文」即可獲取pdf或代碼。
添加微信:dddvisiona,備注:SLAM,拉你入群。文末附行業細分群。
1 背景
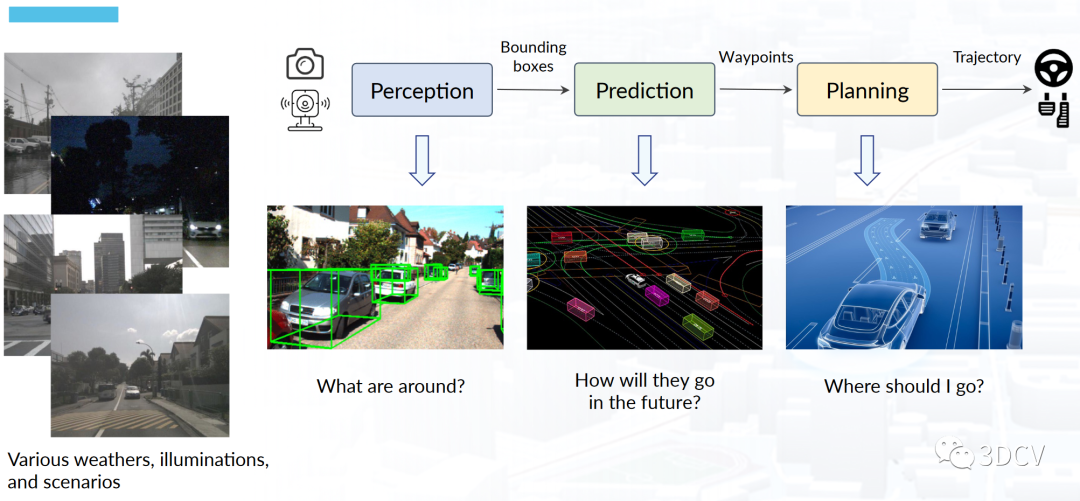
圖1 現代自動駕駛系統的系統流程。
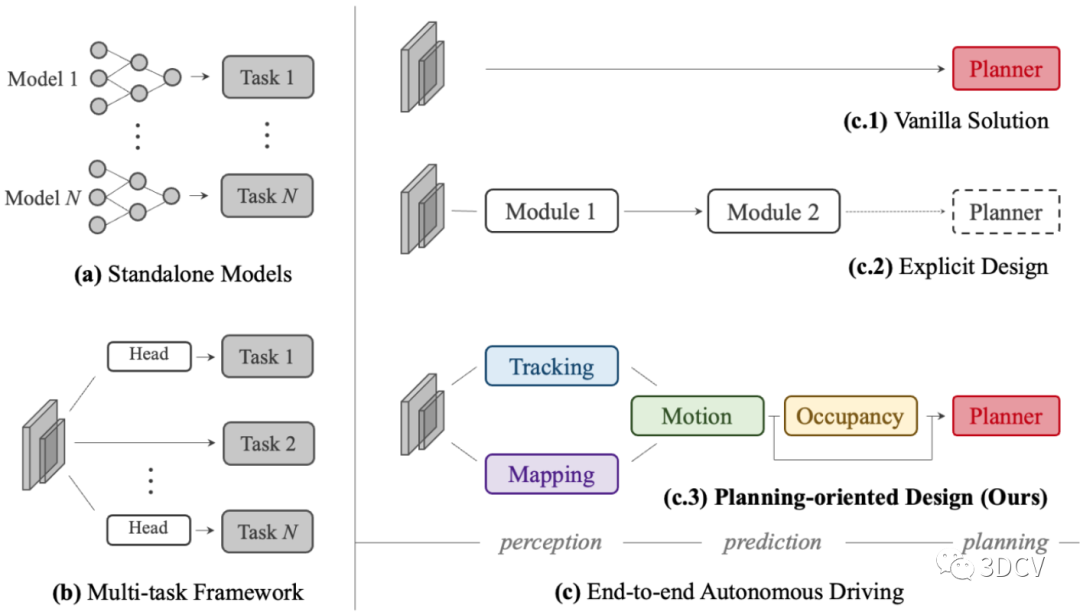
作者首先分析了現代自動駕駛系統的三大核心部分,分別是感知(Perception)、預測(prediction)和規劃(Planning),如圖1所示。已有的自動駕駛方法,要么為單個任務部署獨立的模型。要么,基于統一的特征提取骨干網絡,然后為不同的任務設計單獨的”任務頭“。但是這兩種方案都存在問題,例如獨立的模型在聯合起來以后可能會遭遇累積誤差的問題,而多任務聯合學習的方案則可能不同的任務會相互拉扯,并不能有一個統一的優化目標。因此,作者提出了統一自動駕駛(UniAD)。這是一種最新的綜合框架,以最終的規劃(Planning)為目標。將全棧駕駛任務整合到一個網絡中。充分利用了每個模塊的優勢,并從全局角度為agents交互提供了互補的特征抽象。任務通過統一的查詢接口進行溝通,方便彼此進行規劃。作者在nuScenes數據集上對UniAD,選擇nuScenes的原因是目前只有nuScenes提供了面向自動駕駛比較全面的任務標注。最終的實驗結果顯示,UniAD取得了優異的性能,遠超先前的方法。
這里推薦一下3D視覺工坊最新自動駕駛課程:
[1]深度剖析面向自動駕駛領域的車載傳感器空間同步(標定)
[2]國內首個面向自動駕駛目標檢測領域的Transformer原理與實戰課程
2 相關工作
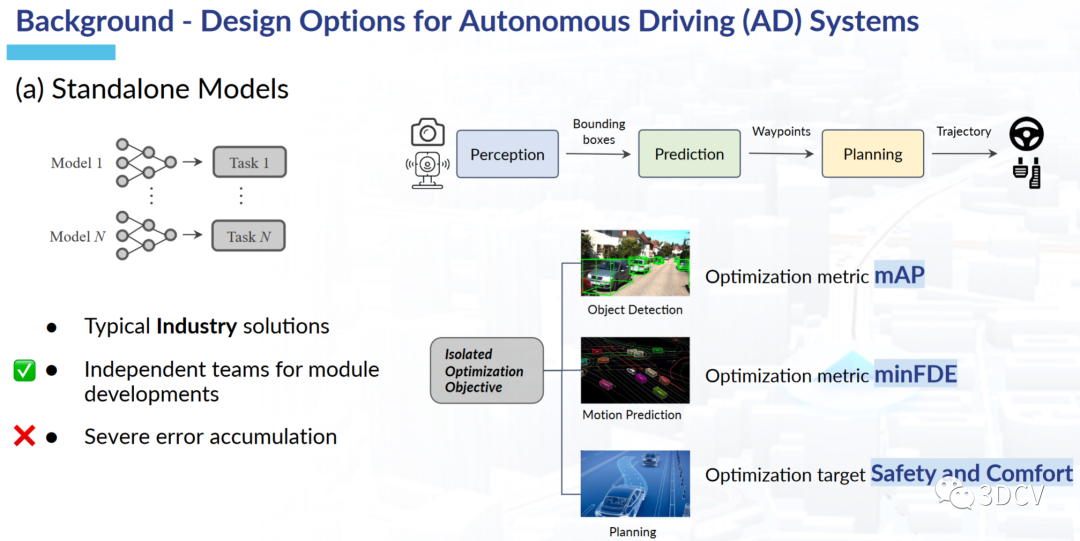
圖2 為單個任務部署單獨模型的方案
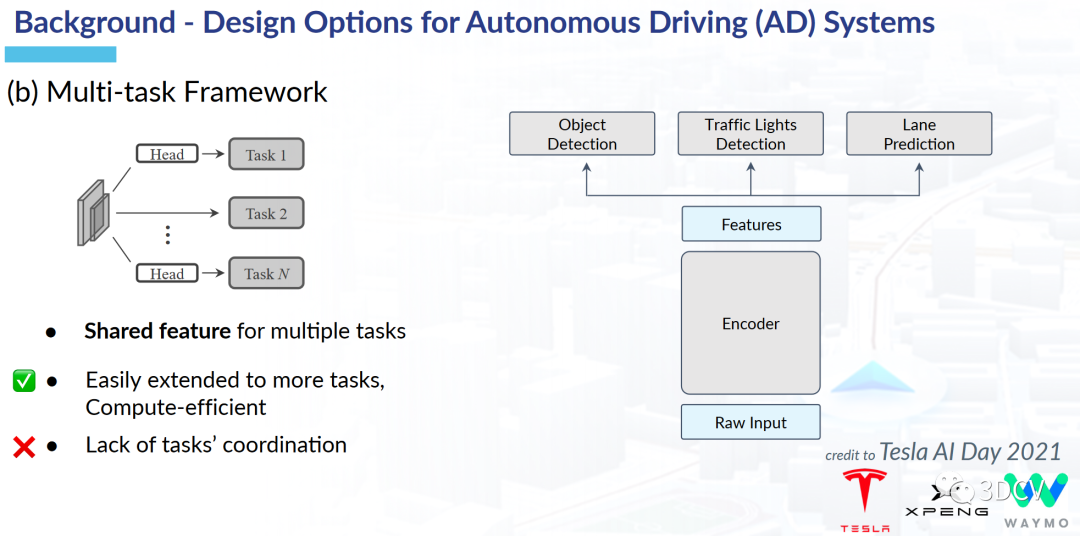
圖3 多任務聯合學習方案
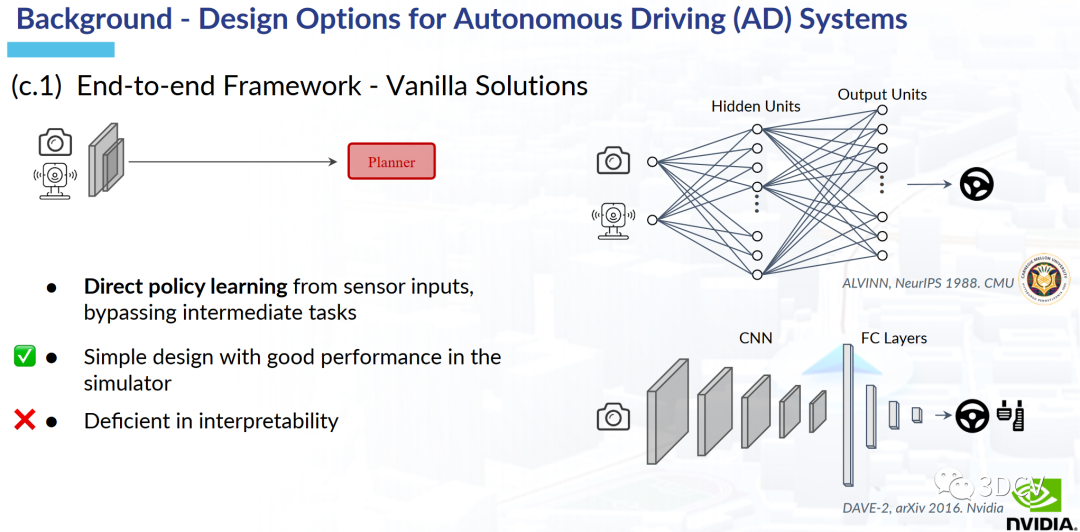
圖4 端到端的初步方案
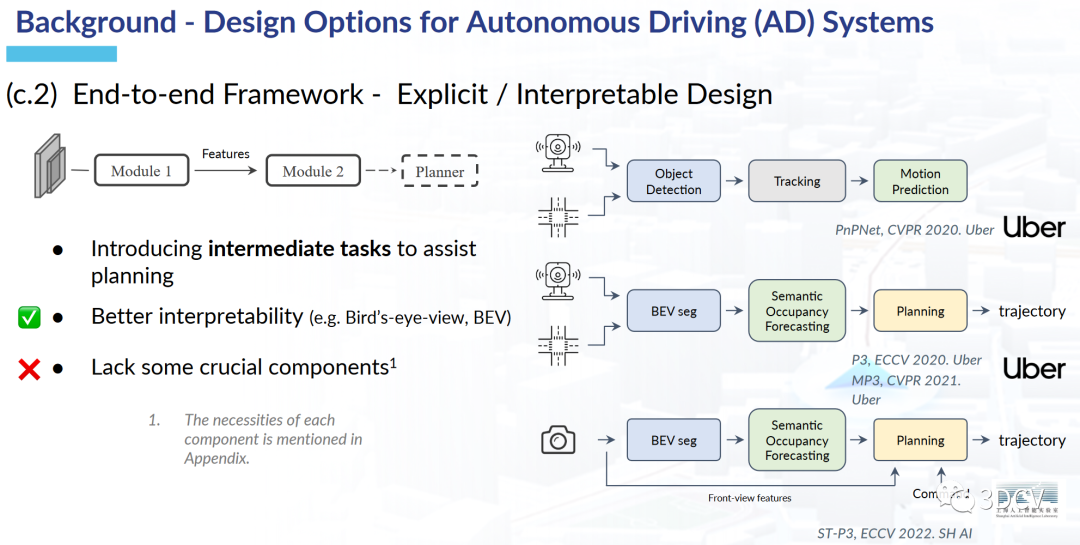
圖5 集成了部分中間任務的端到端方案圖2展示了為任務部署單獨模型的方案,這種方案在實驗室中其實已經有很多例子了。這種方案確實在有些任務中會把指標刷的很高,例如,物體檢測,語義分割等。但是在將所有的任務進行聯合以后,可能會產生累積誤差,導致最終的自動駕駛規劃結果并不是那么好。圖3展示了多任務聯合學習的方案,這種方案的優勢是容易拓展且高效。但缺點是沒有一個統一的優化目標,最終出來的結果可能會是多個任務“相互拉扯”的結果。圖4是端到端的初步方案,優點是設計簡單,且在模擬環境下性能表現不錯。但是自動駕駛畢竟事關人命,這種缺乏可解釋性的黑盒方案還是比較難落地到實際環境中。圖5展示了集成了部分中間任務的端到端方案,這種方案其實有點接近UniAD了。但是缺點是缺少了自動駕駛的一些重要任務。
3 方法
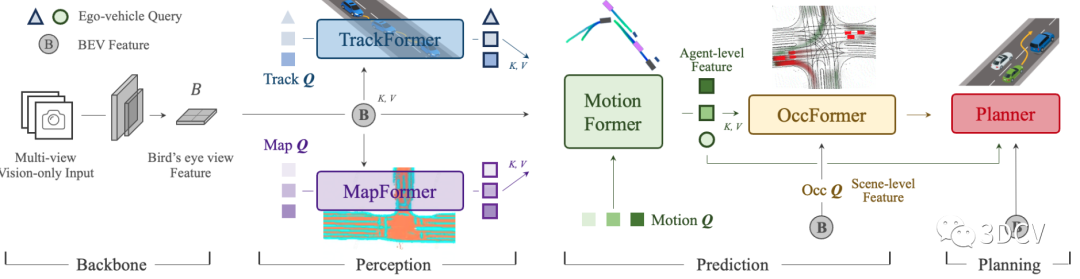
圖6 UniAD的框架流程圖如圖6所示,UniAD最終包括四個基于Transformer解碼器的感知和預測模塊以及一個規劃器。查詢 Q 起到連接各個任務的作用,以對駕駛場景中實體的不同交互進行建模。具體來說,將一系列多攝像頭圖像輸入特征提取器,并通過 BEVFormer 中現成的 BEV 編碼器將所得視圖特征轉換為統一的鳥瞰圖 (BEV) 特征 B。這里的特征提取部分(Backbone)是可以替換的。TrackFormer,負責檢測和跟蹤任務。MapFormer的作用是執行全景分割。MotionFormer 捕獲agents之間的交互,并繪制和預測每個agents的未來軌跡。由于每個agents的動作都會顯著影響場景中的其他agents,因此該模塊對所有考慮的agents進行聯合預測。同時,設計了一個自我車輛查詢來顯式地建模車輛,并使其能夠在這種以場景為中心的范例中與其他agents進行交互。OccFormer 采用 BEV 特征 B 作為查詢,預測未來其他agents的占用情況。最后,Planner預測規劃結果,并使其遠離 OccFormer 預測的占用區域以避免碰撞。
這里推薦一下3D視覺工坊最新自動駕駛課程:
[1]深度剖析面向自動駕駛領域的車載傳感器空間同步(標定)
[2]國內首個面向自動駕駛目標檢測領域的Transformer原理與實戰課程
3.1 TrackFormer
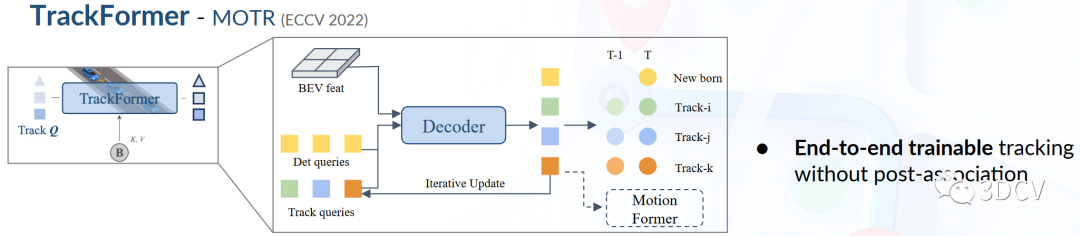
圖7 TrackFormer 流程圖圖7TrackFormer得具體流程圖,該方法采用類似Motr和MUTR3D的查詢設計思路,在對象檢測中只使用傳統的檢測查詢,并引入跟蹤查詢來實現跨幀跟蹤代理,實現檢測查詢與跟蹤查詢相結合的范式。具體來說,每一時刻,初始化的檢測查詢負責檢測第一次感知到的新出現代理,跟蹤查詢對之前幀中已經檢測到的代理進行建模。檢測查詢和跟蹤查詢都通過考察BEV特征來獲取代理的抽象表達。隨著場景更新,當前幀的跟蹤查詢與自注意力模塊中之前記錄的查詢進行交互,從而聚合時序信息,直到相應代理完全消失(在特定時間內未被跟蹤到)。TrackFormer通過多層網絡,最終輸出狀態表示,為下游任務提供對環境中有效代理的編碼表達。除了對自主駕駛車輛周圍其他代理的查詢設計外,還在查詢集中引入了對自主車輛的專門查詢,以顯式對自身進行建模,這將在運動規劃中進一步使用。
3.2 MapFormer
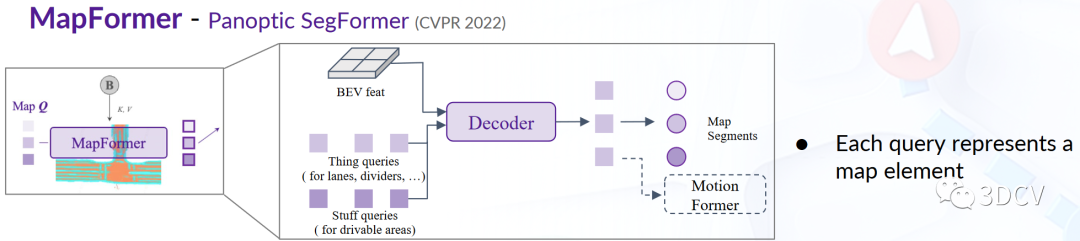
圖8 MapFormer流程圖圖8是該MapFormer的流程圖,基于2D全景分割方法Panoptic SegFormer,將道路元素表示為地圖查詢,以幫助下游任務進行預測,并編碼位置和結構知識。針對自動駕駛場景,將車道線、分割線和十字路口設定為things類,將可行駛區域設定為stuff類。MapFormer的多層網絡都進行監督,只有最后一層包含的新的地圖查詢被向前傳播到MotionFormer,以進行代理和地圖的交互。地圖查詢采用了稀疏表示,以編碼自動駕駛場景的關鍵道路元素,輔助運動預測任務。
3.3 MotionFormer
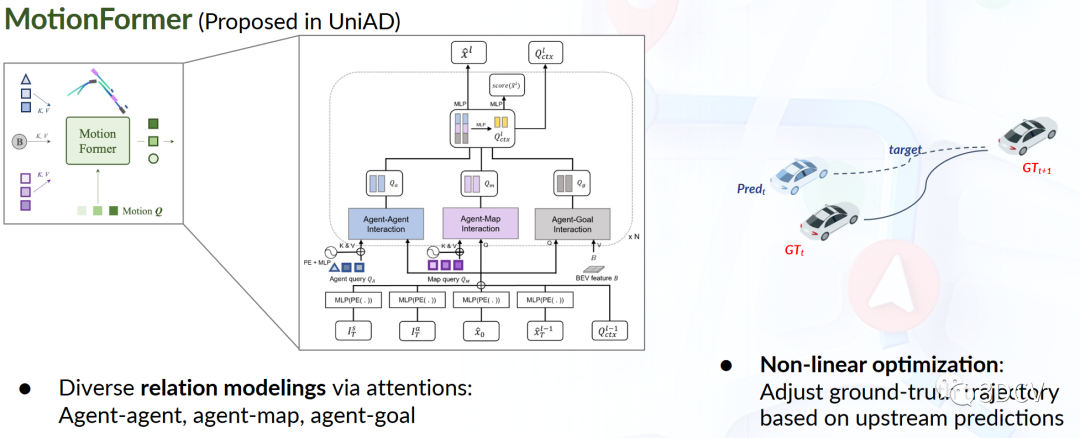
圖9 MotionFormer流程圖
圖9是MotionFormer流程圖。Transformer結構對運動預測任務非常有效,基于此提出端到端的MotionFormer,它通過分別從TrackFormer和MapFormer對動態代理和靜態地圖進行高度抽象的查詢,以場景為中心的方式預測所有代理的多模態未來運動,即每個代理可能的多條未來軌跡。這種范式通過一次前向傳播即可生成整個場景中多個代理的軌跡,大大減少了將整個場景與每個代理對齊的計算量。同時,考慮到未來的動態情況,MotionFormer還傳入了來自TrackFormer對自主車輛的編碼查詢,以使自主車輛與其他代理進行交互。查詢抽象提供了場景編碼,輔助運動預測。
3.4 OccFormer
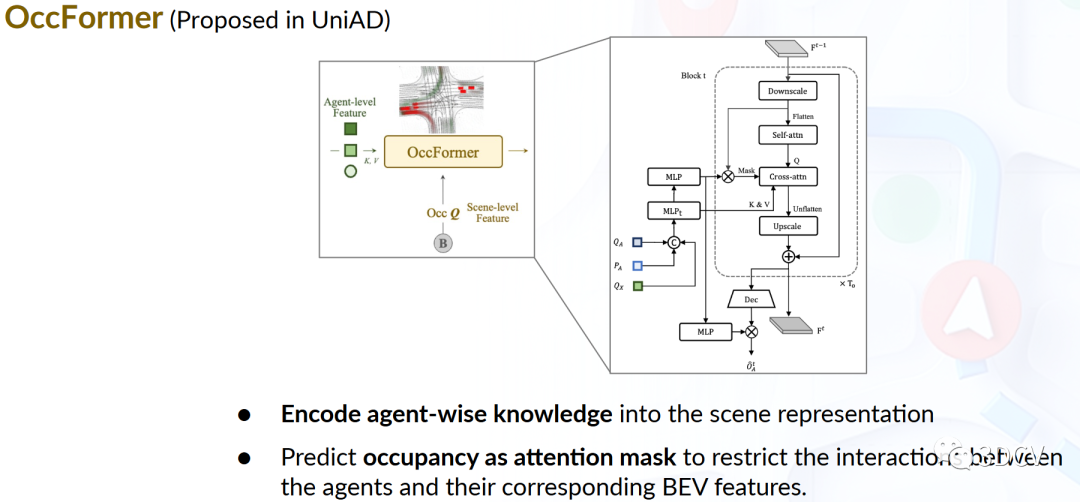
圖10 OccFormer流程圖圖10是 OccFormer流程圖。Occupancy柵格地圖是一種離散化的BEV表示,其每個柵格單元包含一個標志位指示其是否被占用。Occupancy預測任務是預測柵格地圖未來的變化。之前的方法利用RNN沿時間維展開當前觀測到的BEV進行預測,高度依賴手工設計的聚類后處理來為每個代理生成Occupancy,其將BEV特征壓縮到RNN隱狀態作為整體表示,因此缺乏對代理的建模。這導致其難以預測全局所有代理的行為,而這對場景演變至關重要。UniAD提出OccFormer,從場景級和代理級兩個層面結合語義信息:1)稠密場景特征在時間維上展開時,通過設計的注意力機制獲取代理級特征;2)通過代理特征和場景特征的矩陣乘法直接獲得實例級Occupancy,無需其他后處理。OccFormer可為運動規劃提供碰撞風險較低的Occupancy預測。
3.5 Planning
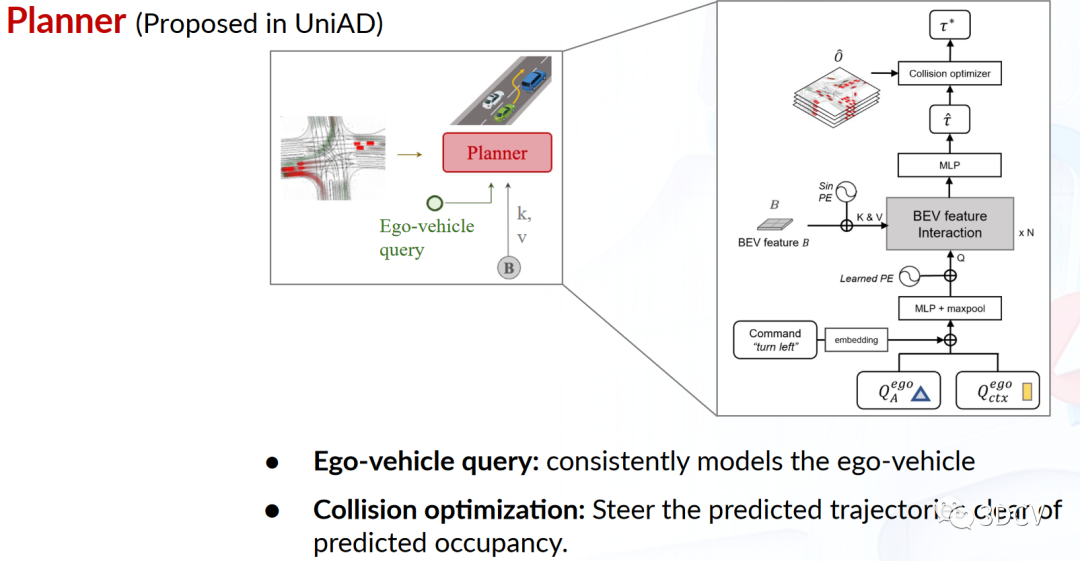
圖11 Planning流程圖圖11是Planning流程圖。是在沒有高精度地圖或預定義路線的情況下,規劃通常需要高級命令指示前進方向。因此,本文將原始導航信號轉換為三個可學習的embedding,稱為命令embedding。來自MotionFormer的自主車輛查詢已經編碼了其多模態意圖,因此再配備命令embedding形成“規劃查詢”。該查詢作用于BEV特征,感知周圍環境,然后解碼得到未來的航點。命令embedding提供了高級導航意圖,輔助基于場景的無地圖導航規劃。規劃查詢結合自主車輛狀態和導航意圖,可實現端到端的條件路徑規劃。
4 實驗
更詳細的結果作者放在了補充材料里面,UniAD在nuScenes數據集上進行了實驗,從以下三個方面驗證了方法的有效性:
任務協同帶來的優勢及其對規劃的影響。
和之前方法相比,每個子任務模塊的效果。
對特定模塊設計的消融實驗分析。
4.1 Joint Results
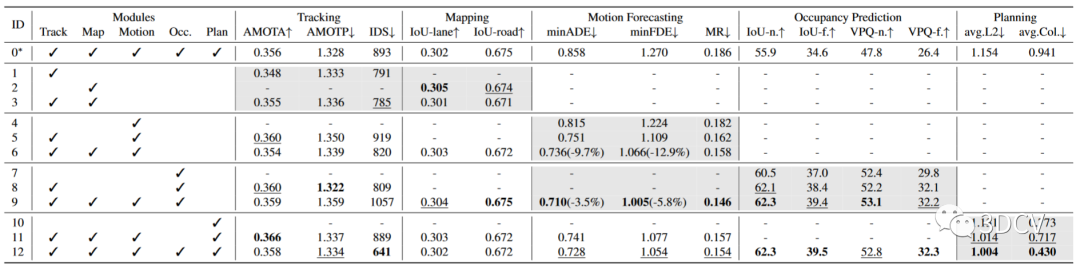
image.png
表1 每一個子任務有效性的消融實驗
作者進行了如表 1 所示的消融,以證明端到端管道中先前任務的有效性和必要性。此表的每一行顯示合并第二個模塊列中列出的任務模塊時的模型性能。第一行 (ID-0) 作為普通多任務基線,具有單獨的任務頭以進行比較。每個指標的最佳結果以粗體標記,第二名結果在每列中用下劃線標記。由于與感知相比,預測更接近于規劃,因此我們首先研究框架中的兩種類型的預測任務,即運動預測和占用預測。在Exp.10-12中,只有當同時引入兩個任務時(Exp.12),與沒有任何中間任務的樸素端到端規劃(Exp.10)相比,規劃L2和碰撞率的指標都達到了最佳結果。因此,得出的結論是,這兩個預測任務都是安全規劃目標所必需的。退一步來說,在實驗 7-9 中,展示了兩種類型預測的協同效應。當兩個任務緊密集成時,它們的性能都會得到提高(Exp.9,-3.5% minADE,-5.8% minFDE,-1.3 MR(%),+2.4 IoUf.(%),+2.4 VPQ-f.(%) )),這證明了包括代理和場景表示的必要性。為實現運動預測,還探索感知模塊如何在實驗 4-6 中做出貢獻。值得注意的是,結合跟蹤和繪圖節點可以顯著改善預測結果(-9.7% minADE、-12.9% minFDE、-2.3 MR(%))。此外,還提出了實驗 1-3,它們表明一起訓練感知子任務會產生與單個任務相當的結果。此外,與樸素多任務學習(Exp.0)相比,Exp.12 在所有基本指標上都顯著優于它(-15.2% minADE、17.0% minFDE、-3.2 MR(% ))、+4.9 IoU-f.(%).、+5.9 VPQf.(%)、-0.15m avg.L2、-0.51 avg.Col.(%)),顯示了UniAD的優越性。
4.2 Modular Results
按照感知預測規劃的順序,報告每個任務模塊的性能,并與 nuScenes 驗證集上的現有技術進行比較。UniAD 使用單個經過訓練的網絡聯合執行所有這些任務。每個任務的主要指標在表格中用灰色背景標記。對于表2中的多目標跟蹤,與 MUTR3D 和 ViP3D相比,UniAD 分別產生了 +6.5 和 +14.2 AMOTA(%) 的顯著改進。此外,UniAD 獲得了最低的 ID 切換分數,顯示了每個 tracklet 的時間一致性。對于表 3 中的在線地圖(Online mapping),UniAD 在分段車道上表現良好(與 BEVFormer 相比,+7.4 IoU(%)),這對于運動模塊中的下游智能道路交互至關重要。由于UniAD的跟蹤模塊遵循端到端范例,它仍然不如具有復雜關聯的檢測跟蹤方法,例如 Immortal Tracker,并且UniAD的映射結果落后于之前針對特定類別的面向感知的方法。作者認為 UniAD 是通過感知信息來促進最終規劃,而不是通過完整的模型能力來優化感知。
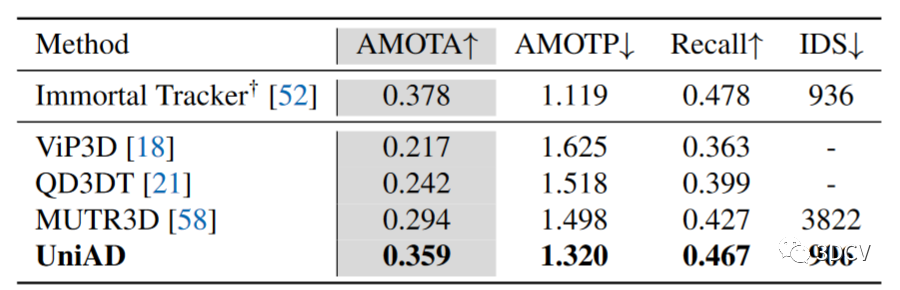
表2 多目標跟蹤結果
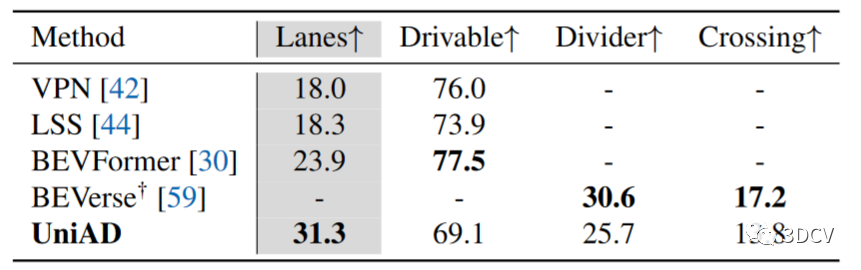
表3 Online mapping結果
運動預測結果如表4所示,其中 UniAD 明顯優于之前基于視覺的端到端方法。與 PnPNet-vision 和 ViP3D相比,它在 minADE 上的預測誤差分別減少了 38.3% 和 65.4%。就表5中報告的Occupancy預測而言,UniAD 在附近區域取得了顯著的進步,與大量增強的 FIERY和 BEVerse 相比,在 IoU-near(%) 上分別獲得了 +4.0 和 +2.0的提升。受益于自我車輛查詢和占用中豐富的時空信息,UniAD 與 ST-P3 相比,就規劃范圍的平均值而言,將規劃 L2 錯誤和碰撞率降低了 51.2% 和 56.3% 。此外,它的性能明顯優于幾種基于激光雷達的同類產品,這是非常難得的結果。
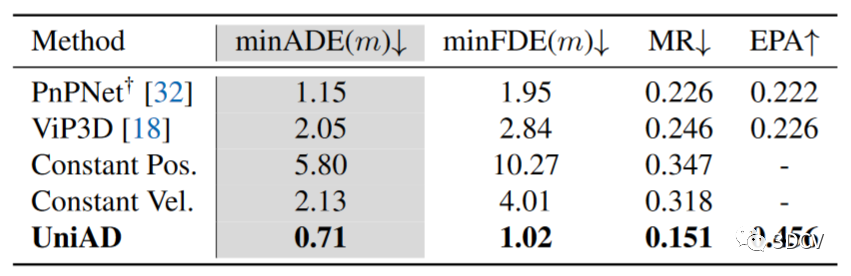
表4 運動預測結果
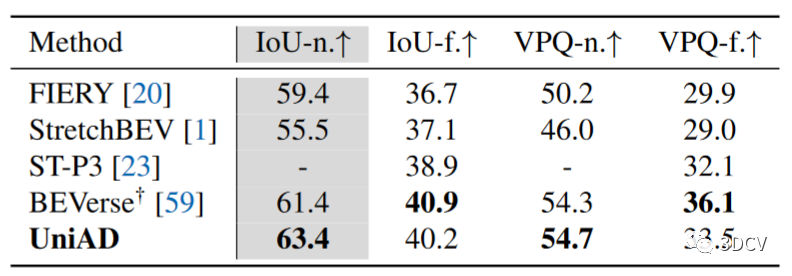
表5 Occupancy預測
4.3 Ablation Study
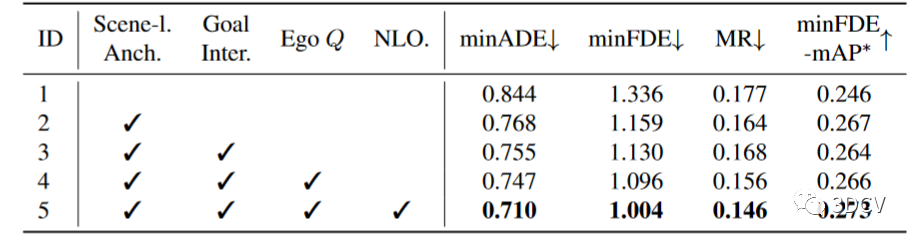
表6 運動預測模塊中設計的消融。表6顯示了UniAD在論文第 2 節中描述的所有建議組件。2.2 為 minADE、minFDE、Miss Rate 和 minFDE-mAP 指標的最終性能做出貢獻。值得注意的是,旋轉的場景級錨點顯示出顯著的性能提升(15.8% minADE、-11.2% minFDE、+1.9 minFDE-mAP(%)),表明以場景為中心的方式進行運動預測是至關重要的。agents-目標點交互通過面向規劃的視覺特征增強了運動查詢,周圍的agents可以從考慮自我車輛的意圖中進一步受益。此外,非線性優化策略通過考慮端到端的感知不確定性,提高了性能(-5.0% minADE、-8.4% minFDE、-1.0 MR(%)、+0.7 minFDE-mAP(%))。
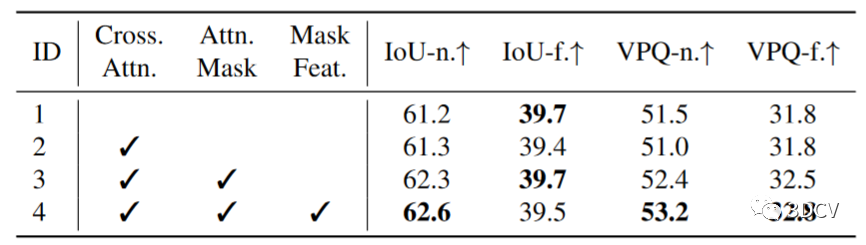
表7 占用預測模塊中設計的消融。如表7所示,與無注意力基線(實驗 1)相比,在沒有局部性約束的情況下關注所有代理的每個像素(實驗 2)會導致性能稍差。The occupancy-guided attention mask解決了問題并帶來了增益,特別是對于附近區域(Exp.3,+1.0 IoU-n.(%),+1.4 VPQ-n.(%))。此外,重用掩模特征而不是代理特征來獲取占用特征進一步增強了性能。
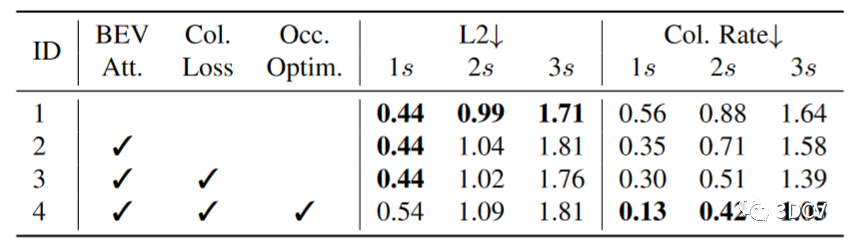
表8 規劃模塊中設計的消融。表8是對規劃模塊行了消融,即關注 BEV 特征、碰撞損失訓練以及占用優化策略。為了安全性,較低的碰撞率優于樸素軌跡模仿(L2 度量),并且在 UniAD 中應用的所有部件中,碰撞率都會降低。
5 總結與未來展望
本文討論自動駕駛算法框架的系統級設計。面向規劃的終極追求,提出了以規劃為導向的管道,即UniAD。我們對感知和預測中每個模塊的必要性進行了詳細的分析。為了統一任務,提出了一種基于查詢的設計來連接 UniAD 中的所有節點,從而受益于環境中代理交互的更豐富的表示。大量的實驗從各個方面驗證了所提出的方法。但是,協調這樣一個具有多個任務的綜合系統并非易事,需要大量的計算能力,尤其是計算能力。如何設計和管理系統以實現輕量級部署值得未來探索。此外,是否納入更多的任務,如深度估計、行為預測,以及如何將它們嵌入到系統中,也是未來值得研究的方向。
-
算法
+關注
關注
23文章
4601瀏覽量
92649 -
框架
+關注
關注
0文章
399瀏覽量
17435 -
自動駕駛
+關注
關注
783文章
13687瀏覽量
166157
原文標題:5 總結與未來展望
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論