 線程數突增!領導說再這么寫就gc掉我
線程數突增!領導說再這么寫就gc掉我
前言
今天給大家分享一個線上問題引出的一次思考,過程比較長,但是挺有意思。
今天上班把需求寫完,出于學習(摸魚)的心理上skywalking看看,突然發現我們的一個應用,應用內線程數超過900條,接近1000條,但是cpu并沒有高漲,內存也不算高峰。
但是敏銳的我還是立刻意識到這個應用有不妥,因為線程數太多了,不符合我們一個正常健康的應用數量。熟練的打出cpu dump觀察,首先看線程組名的概覽。
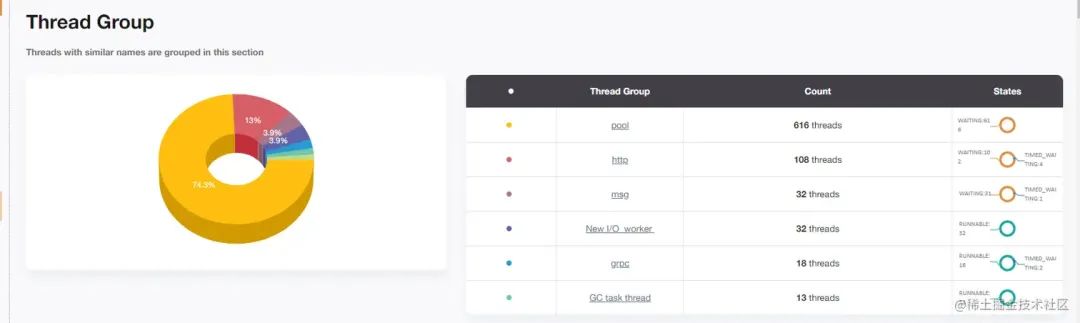
從線程分組看,pool名開頭線程占616條,而且waiting狀態也是616條,這個點就非常可疑了,我斷定就是這個pool開頭線程池導致的問題。我們先排查為何這個線程池中會有600+的線程處于waiting狀態并且無法釋放,記接下來我們找幾條線程的堆棧觀察具體堆棧:
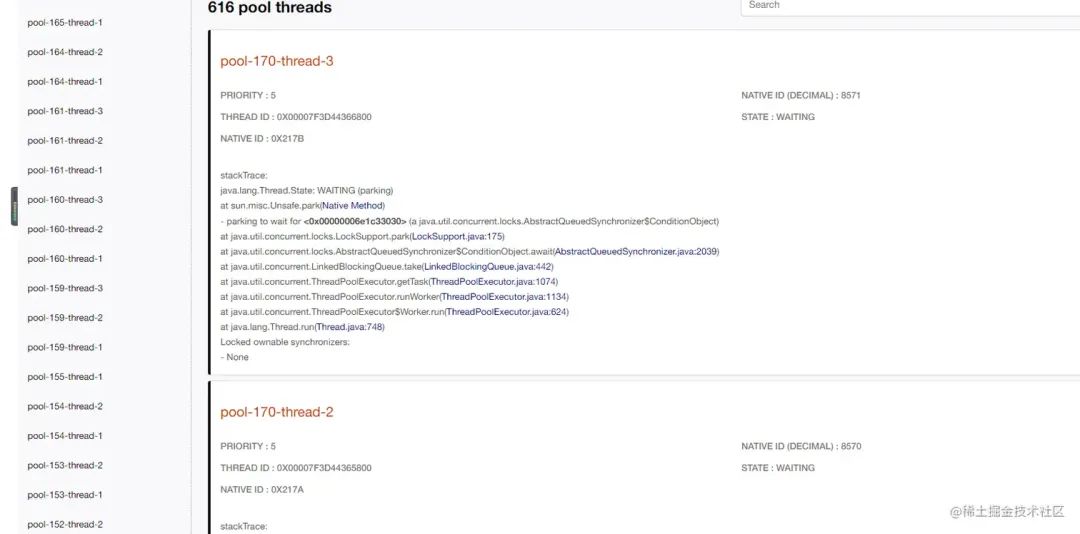
這個堆棧看上去很合理,線程在線程池中不斷的循環獲取任務,因為獲取不到任務所以進入了waiting狀態,等待著有任務后被喚醒。
看上去不只一個線程池,并且這些線程池的名字居然是一樣的,我大膽的猜測一下,是不斷的創建同樣的線程池,但是線程池無法被回收導致的線程數,所以接下來我們要分析兩個問題,首先這個線程池在代碼里是哪個線程池,第二這個線程池是怎么被創建的?為啥釋放不了?
我在idea搜索new ThreadPoolExecutor()得到的結果是這樣的:
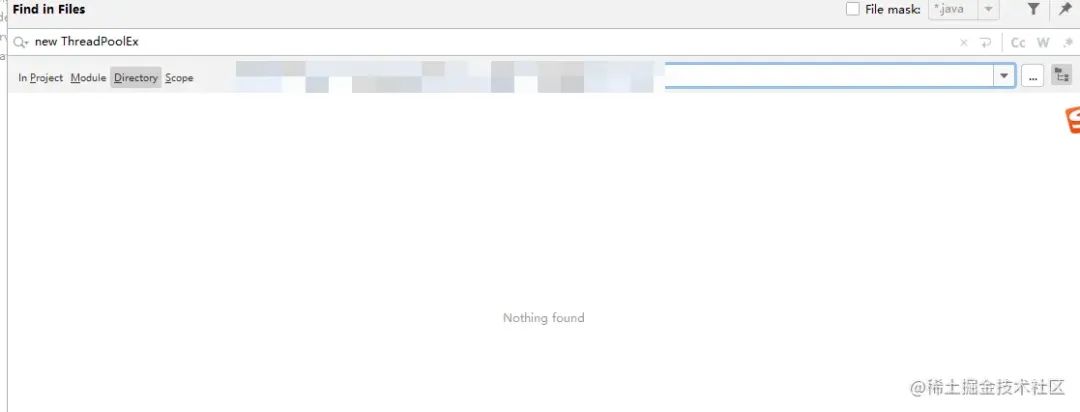
于是我陷入懵逼的狀態,難道還有其他騷操作?
正在這時,一位不知名的鄭網友發來一張截圖:
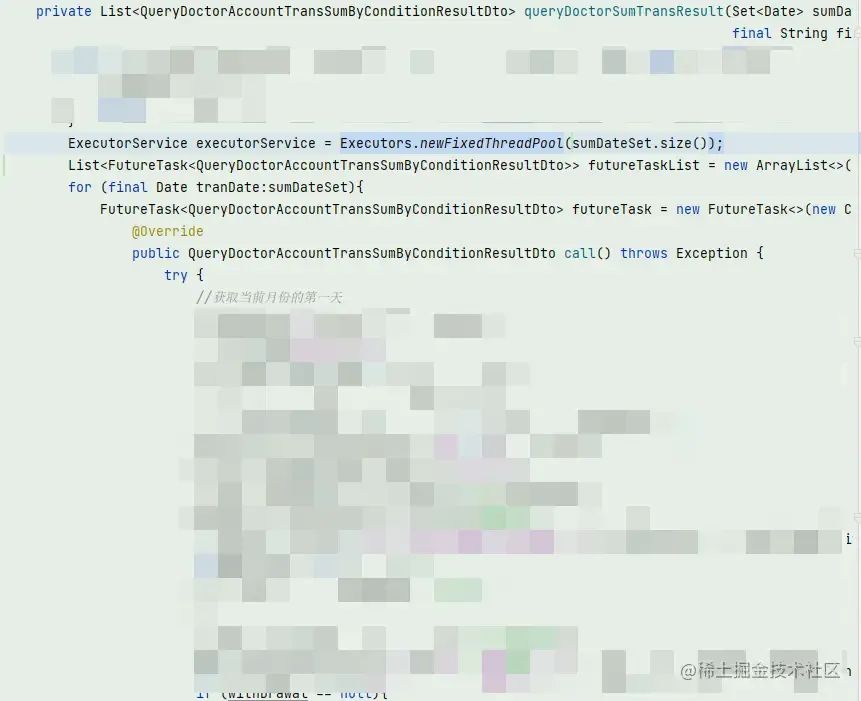
好家伙!竟然是用new FixedTreadPool()整出來的。難怪我完全搜不到,因為用的new FixedTreadPool(),所以線程池中的線程名是默認的pool(又多了一個不使用Executors來創建線程池的理由)。
然后我迫不及die的打開代碼,試圖找到罪魁禍首,結果發現作者居然是我自己。這是另一個驚喜,驚嚇的驚。
冷靜下來后我梳理一遍代碼,這個接口是我兩年前寫的,主要是功能是統計用戶的錢包每個月的流水,因為擔心統計比較慢,所以使用了線程池,做了批量的處理,沒想到居然導致了線程數過高,雖然沒有導致事故,但是確實是潛在的隱患,現在沒出事不代表以后不會出事。
去掉多余業務邏輯,我簡單的還原一個代碼給大家看,還原現場:
privatestaticvoidthreadDontGcDemo(){
ExecutorServiceexecutorService=Executors.newFixedThreadPool(10);
executorService.submit(()->{
System.out.println("111");
});
}
那么為啥線程池里面的線程和線程池都沒釋放呢。
難道是因為沒有調用shutdown?我大概能理解我兩年前當時為啥不調用shutdown,是因為當初我覺得接口跑完,方法走到結束,理論上棧幀出棧,局部變量應該都銷毀了,按理說executorService這個變量應該直接GG了,那么按理說我是不用調用shutdown方法的。
我簡單的跑了個demo,循環的去new線程池,不調用shutdown方法,看看線程池能不能被回收
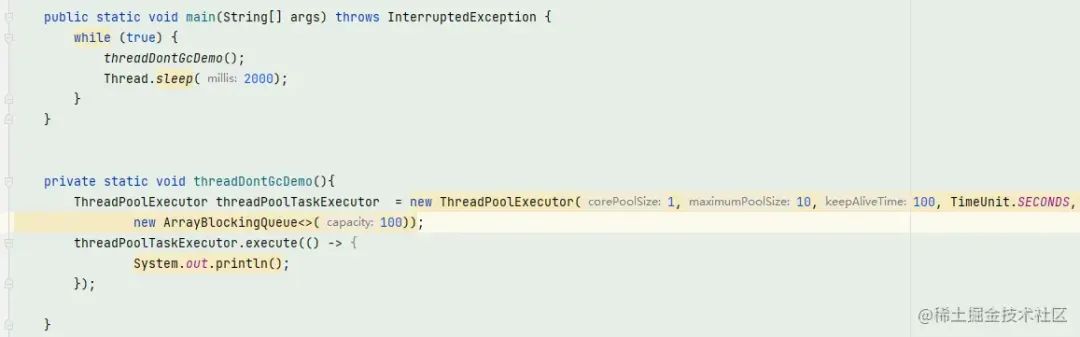
打開java visual vm查看實時線程:
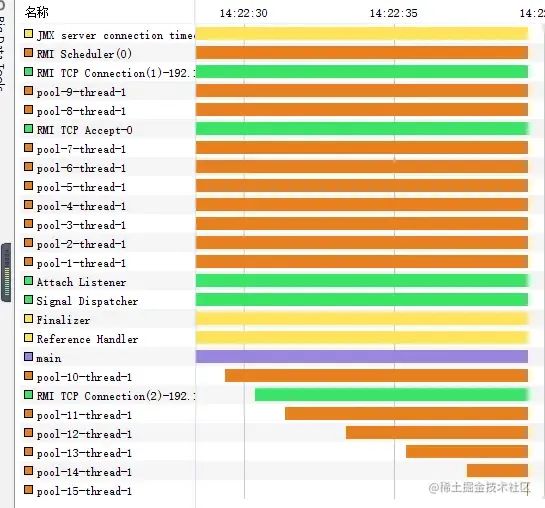
可以看到線程數和線程池都一直在增加,但是一直沒有被回收,確實符合發生的問題狀況,那么假如我在方法結束前調用shutdown方法呢,會不會回收線程池和線程呢?
簡單寫個demo結合jvisualvm驗證下:
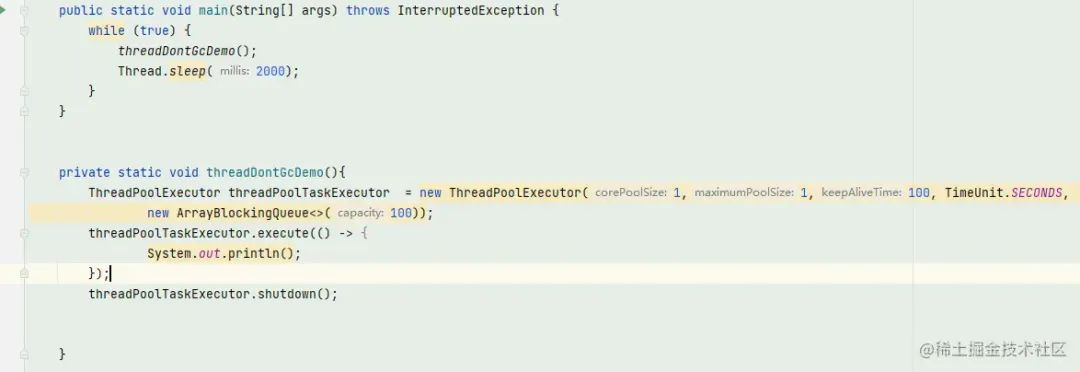

結果是線程和線程池都被回收了。也就是說,執行了shutdown的線程池最后會回收線程池和線程對象。
我們知道,一個對象能不能回收,是看它到gc root之間有沒有可達路徑,線程池不能回收說明到達線程池的gc root還是有可達路徑的。這里講個冷知識,這里的線程池的gc root是線程,具體的gc路徑是thread->workers->線程池。
線程對象是線程池的gc root,假如線程對象能被gc,那么線程池對象肯定也能被gc掉(因為線程池對象已經沒有到gc root的可達路徑了)。
那么現在問題就轉為線程對象是在什么時候gc。
這位網友給了一個粗淺但是合理的解釋,線程對象肯定不是在運行中的時候被回收的,因為jvm肯定不可能去回收一條在運行中的線程,至少runnalbe狀態的線程jvm不可能去回收。
在stackoverflow上我找到了更準確的答案:
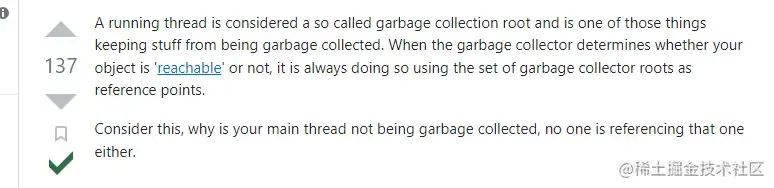
A running thread is considered a so called garbage collection root and is one of those things keeping stuff from being garbage collected。
這句話的意思是,一條正在運行的線程是gc root,注意,是正在運行,這個正在運行我先透露下,即使是waiting狀態,也算正在運行。這個回答的整體的意思是,運行的線程是gc root,但是非運行的線程不是gc root(可以被回收)。
現在比較清楚了,線程池和線程被回收的關鍵就在于線程能不能被回收,那么回到原來的起點,為何調用線程池的shutdown方法能夠導致線程和線程池被回收呢?難道是shutdown方法把線程變成了非運行狀態嗎?
talk is cheap,show me the code
我們直接看看線程池的shutdown方法的源碼
publicvoidshutdown(){
finalReentrantLockmainLock=this.mainLock;
mainLock.lock();
try{
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown();//hookforScheduledThreadPoolExecutor
}finally{
mainLock.unlock();
}
tryTerminate();
}
privatevoidinterruptIdleWorkers(){
interruptIdleWorkers(false);
}
privatevoidinterruptIdleWorkers(booleanonlyOne){
finalReentrantLockmainLock=this.mainLock;
mainLock.lock();
try{
for(Workerw:workers){
Threadt=w.thread;
if(!t.isInterrupted()&&w.tryLock()){
try{
t.interrupt();
}catch(SecurityExceptionignore){
}finally{
w.unlock();
}
}
if(onlyOne)
break;
}
}finally{
mainLock.unlock();
}
}
我們從interruptIdleWorkers方法入手,這方法看上去最可疑,看到interruptIdleWorkers方法,這個方法里面主要就做了一件事,遍歷當前線程池中的線程,并且調用線程的interrupt()方法,通知線程中斷,也就是說shutdown方法只是去遍歷所有線程池中的線程,然后通知線程中斷。所以我們需要了解線程池里的線程是怎么處理中斷的通知的。
我們點開worker對象,這個worker對象是線程池中實際運行的線程,所以我們直接看worker的run方法,中斷通知肯定是在里面被處理了
//WOrker的run方法里面直接調用的是這個方法
finalvoidrunWorker(Workerw){
Threadwt=Thread.currentThread();
Runnabletask=w.firstTask;
w.firstTask=null;
w.unlock();//allowinterrupts
booleancompletedAbruptly=true;
try{
while(task!=null||(task=getTask())!=null){
w.lock();
//Ifpoolisstopping,ensurethreadisinterrupted;
//ifnot,ensurethreadisnotinterrupted.This
//requiresarecheckinsecondcasetodealwith
//shutdownNowracewhileclearinginterrupt
if((runStateAtLeast(ctl.get(),STOP)||
(Thread.interrupted()&&
runStateAtLeast(ctl.get(),STOP)))&&
!wt.isInterrupted())
wt.interrupt();
try{
beforeExecute(wt,task);
Throwablethrown=null;
try{
task.run();
}catch(RuntimeExceptionx){
thrown=x;throwx;
}catch(Errorx){
thrown=x;throwx;
}catch(Throwablex){
thrown=x;thrownewError(x);
}finally{
afterExecute(task,thrown);
}
}finally{
task=null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly=false;
}finally{
processWorkerExit(w,completedAbruptly);
}
}
這個runwoker屬于是線程池的核心方法了,相當的有意思,線程池能不斷運作的原理就是這里,我們一點點看。
首先最外層用一個while循環套住,然后不斷的調用gettask()方法不斷從隊列中取任務,假如拿不到任務或者任務執行發生異常(拋出異常了)那就屬于異常情況,直接將completedAbruptly設置為true,并且進入異常的processWorkerExit流程。
我們看看gettask()方法,了解下啥時候可能會拋出異常:
privateRunnablegetTask(){
booleantimedOut=false;//Didthelastpoll()timeout?
for(;;){
intc=ctl.get();
intrs=runStateOf(c);
//Checkifqueueemptyonlyifnecessary.
if(rs>=SHUTDOWN&&(rs>=STOP||workQueue.isEmpty())){
decrementWorkerCount();
returnnull;
}
intwc=workerCountOf(c);
//Areworkerssubjecttoculling?
booleantimed=allowCoreThreadTimeOut||wc>corePoolSize;
if((wc>maximumPoolSize||(timed&&timedOut))
&&(wc>1||workQueue.isEmpty())){
if(compareAndDecrementWorkerCount(c))
returnnull;
continue;
}
try{
Runnabler=timed?
workQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS):
workQueue.take();
if(r!=null)
returnr;
timedOut=true;
}catch(InterruptedExceptionretry){
timedOut=false;
}
}
}
這樣很清楚了,拋去前面的大部分代碼不看,這句代碼解釋了gettask的作用:
Runnabler=timed?
workQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS):
workQueue.take()
gettask就是從工作隊列中取任務,但是前面還有個timed,這個timed的語義是這樣的:如果allowCoreThreadTimeOut參數為true(一般為false)或者當前工作線程數超過核心線程數,那么使用隊列的poll方法取任務,反之使用take方法。
這兩個方法不是重點,重點是poll方法和take方法都會讓當前線程進入time_waiting或者waiting狀態。而當線程處于在等待狀態的時候,我們調用線程的interrupt方法,毫無疑問會使線程當場拋出異常!
也就是說線程池的shutdownnow方法調用interruptIdleWorkers去對線程對象interrupt是為了讓處于waiting或者是time_waiting的線程拋出異常。
那么線程池是在哪里處理這個異常的呢?我們看runwoker中的調用的processWorkerExit方法,說實話這個方法看著就像處理拋出異常的方法:
privatevoidprocessWorkerExit(Workerw,booleancompletedAbruptly){
if(completedAbruptly)//Ifabrupt,thenworkerCountwasn'tadjusted
decrementWorkerCount();
finalReentrantLockmainLock=this.mainLock;
mainLock.lock();
try{
completedTaskCount+=w.completedTasks;
workers.remove(w);
}finally{
mainLock.unlock();
}
tryTerminate();
intc=ctl.get();
if(runStateLessThan(c,STOP)){
if(!completedAbruptly){
intmin=allowCoreThreadTimeOut?0:corePoolSize;
if(min==0&&!workQueue.isEmpty())
min=1;
if(workerCountOf(c)>=min)
return;//replacementnotneeded
}
addWorker(null,false);
}
}
我們可以看到,在這個方法里有一個很明顯的workers.remove(w)方法,也就是在這里,這個w的變量,被移出了workers這個集合,導致worker對象不能到達gc root,于是workder對象順理成章的變成了一個垃圾對象,被回收掉了。
然后等到worker中所有的worker都被移出works后,并且當前請求線程也完成后,線程池對象也成為了一個孤兒對象,沒辦法到達gc root,于是線程池對象也被gc掉了。寫了挺長的篇幅,我小結一下:
-
線程池調用
shutdownnow方法是為了調用worker對象的interrupt方法,來打斷那些沉睡中的線程(waiting或者time_waiting狀態),使其拋出異常 -
線程池會把拋出異常的worker對象從workers集合中移除引用,此時被移除的worker對象因為沒有到達
gc root的路徑已經可以被gc掉了 -
等到workers對象空了,并且當前tomcat線程也結束,此時線程池對象也可以被gc掉,整個線程池對象成功釋放
最后總結
如果只是在局部方法中使用線程池,線程池對象不是bean的情況時,記得要合理的使用shutdown或者shutdownnow方法來釋放線程和線程池對象,如果不使用,會造成線程池和線程對象的堆積。
-
cpu
+關注
關注
68文章
10826瀏覽量
211162 -
堆棧
+關注
關注
0文章
182瀏覽量
19732 -
線程
+關注
關注
0文章
504瀏覽量
19651
原文標題:線程數突增!領導說再這么寫就gc掉我
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
明明我說的是25G信號,你卻讓我看12.5G的損耗?
CPU線程和程序線程的區別
探索虛擬線程:原理與實現
esp32S3一進入燒寫就報錯的原因?

常見golang gc的內部優化方案
Disable中斷之后再Enable無法正常運行是為什么?
什么是動態線程池?動態線程池的簡單實現思路
什么是守護線程?守護線程的底層原理和使用示例





 工商網監
工商網監
評論