 軟件漏洞檢測場景中的深度學習模型實證研究
軟件漏洞檢測場景中的深度學習模型實證研究
近年來,深度學習模型(DLM)在軟件漏洞檢測領域的應用探索引起了行業廣泛關注,在某些情況下,利用DLM模型能夠獲得超越傳統靜態分析工具的檢測效果。然而,雖然研究人員對DLM模型的價值預測讓人驚嘆,但很多人對這些模型本身的特性并不十分清楚。
為了從應用角度對DLM模型在漏洞檢測場景下的能力與價值進行驗證,Steenhoek等人發表了《An Empirical Study of Deep Learning Models for Vulnerability Detection》(《漏洞檢測的深度學習模型實證研究》)論文。該論文全面回顧了近年來公開發表的DLM在源代碼漏洞檢測方面的相關研究,并實際復現了多個SOTA深度學習模型(見表1)。通過將這些模型在兩個廣泛使用的漏洞檢測數據集上進行充分實驗,論文作者從模型能力、訓練數據和模型解釋等方面進行了6個專項課題的研究分析。
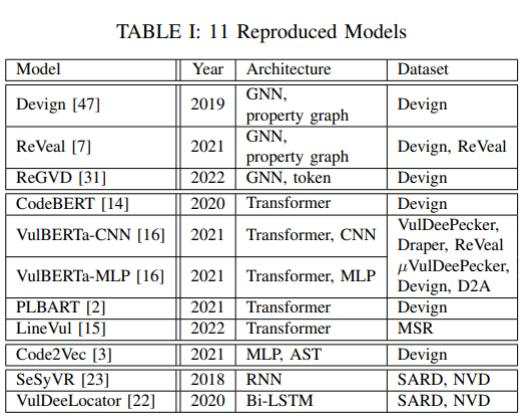
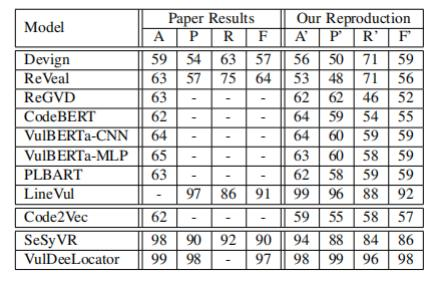
為了驗證模型的準確性,作者使用了與原始資料中相同的數據集和參數設置,對這些模型的運行結果進行了再次測試驗證(見表 II)。其中A、P、R、F分別代表深度學習中常見的準確率(accuracy)、精確度(precision)、召回率(recall)和F1分數。總體而言,復現的結果差異在合理范圍內(上下2%)。
表II
需要說明的是,為了更精確地比較模型,作者優化了模型的實現,使它們可以同時支持Devign和MSR數據集。然而,在本論文所列舉的研究問題分析中,作者僅使用了上述模型中的9個而排除了VulDeeLocator和SeSyVR兩種模型,原因是它們不容易針對Devign和MSR數據集進行優化。通過對深度學習漏洞檢測模型進行實證研究,作者詳細分析了六個研究問題,并在以下方面取得收獲:
對深度學習漏洞檢測模型進行了全面研究。
提供了一個包含11個SOTA深度學習模型和數據集的復現包,以便其他研究人員可以使用這些工具來進行漏洞檢測研究。
設計了6個RQs,以評估深度學習模型在漏洞檢測方面的性能、魯棒性和可解釋性,并通過實驗回答了這些問題。
提供了有關如何解釋深度學習漏洞檢測模型決策的示例和數據,以幫助其他研究人員理解。
RQ1:不同模型之間的漏洞檢測結果是否具有一致性?單個模型的多次運行和多個模型間的差異點是什么?
研究動機:揭示深度學習模型漏洞檢測結果的不確定性,幫助研究人員更好地理解這些模型的表現。
實驗設計:實驗人員在Devign數據集上使用三個不同的隨機種子對11種DLM模型進行訓練,然后測量它們在漏洞檢測方面的性能,并比較它們之間的一致性。作者測量了在所有三個隨機種子下具有相同二進制標簽的輸入所占的百分比,并將其稱為“穩定輸入”。然后,作者比較了這些穩定輸入在不同模型之間的一致性。
研究發現:研究發現,不同模型在漏洞檢測方面的表現存在一定的差異性,平均有34.9%的測試數據(30.6%總數據)因為隨機種子的不同而產生不同的預測結果。其中,基于屬性圖(Property Graph)的GNN模型的差異性排名在前兩位,而ReVeal模型在50%的測試數據中輸出會在不同運行之間發生變化。相比之下,Code2Vec模型表現出最小的變異性。此外,作者還發現,不穩定輸入與更多錯誤預測成正相關。
總的來看,雖然每次運行結果之間存在預測差異,但F1測試分數并沒有顯著變化,并且平均標準差僅為2.9(見表 III)。因此,雖然當使用不同的隨機種子來訓練和測試模型時,模型的性能可能會有所變化,但這種變化應該是可以接受的,并且不會對整體性能產生太大影響。
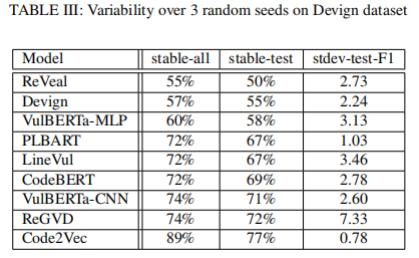
表III
另外,不同架構的DLM模型在測試結果上表現出了較低的一致性:因為只有7%的測試數據(和7%的總數據)被所有模型所認可。三個GNN模型僅在20%的測試示例(和25%的總數據)上達成了一致,而三個表現最佳的transformer模型(LineVul、PLBART和VulBERTa-CNN)在34%的測試數據(和44%的總數據)上達成了一致。但是,當比較所有5個transformer模型時,只有22%的測試示例(和29%的總數據)是一致的(見表 IV)。不同模型之間的低一致性意味著:當沒有基準標簽時,跨模型比較性能的差異測試方法可能意義非常有限。
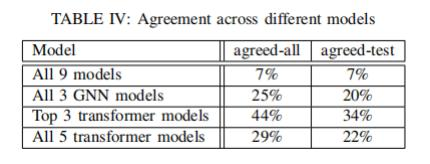
表IV
RQ2:是否存在某些類型的漏洞更容易被檢測?是否應該為每種類型的漏洞建立單獨模型,還是訓練一個可以檢測所有漏洞的模型?哪種方式訓練出的模型性能更好呢?
研究動機:研究人員將漏洞分為不同的類型,探索這些類型對模型性能和準確性的影響。這有助于更好地理解 DLM處理不同類型漏洞的表現,并為改進模型提供指導。
實驗設計:作者借助CWE漏洞分類系統,把漏洞數據分成5類(見表 V)。然后,使用多個DLM來檢測這些漏洞,從而對比它們在不同漏洞類型上的表現。為了減少偏差,研究人員進行了交叉驗證。具體的分類包括:緩沖區溢出(Buffer overflow)、值錯誤(Value error)、資源錯誤(Resource error)、輸入驗證錯誤(Input validation error)、特權升級(Privilege escalation)。
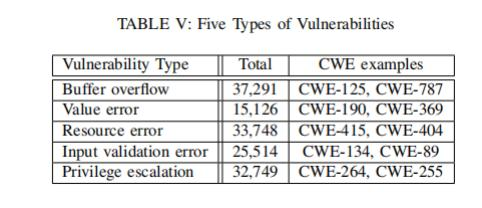
表V
研究發現:不同類型的漏洞對于DLM的性能和準確性有著不同的影響(見圖1)。具體而言, 一些漏洞類型比其他類型更容易被檢測到,例如值錯誤和緩沖區溢出,而一些漏洞類型則更難以被檢測到,例如輸入驗證錯誤和特權升級。此外,研究人員還發現,混合模型(棕色柱狀圖)的性能通常弱于單模型-單漏洞類型的方式,也就是說,在處理不同類型漏洞時,建立單個模型可能不如建立專門針對每種漏洞類型的模型來得 有效。同時,跨漏洞類型的性能往往低于相同漏洞類型的性能(圓形)。
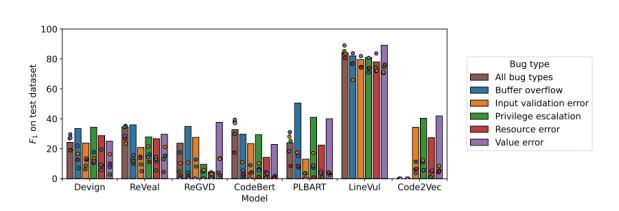
圖1
"cross-bugtype" 和"same-bugtype" 是用于評估混合模型性能的兩種方法。在"cross-bugtype" 中,測試數據和訓練數據屬于不同的漏洞類型,而在"same-bugtype" 中,測試數據和訓練數據屬于相同的漏洞類型。這兩種方法可以幫助我們了解混合模型在不同漏洞類型上的性能表現。如果混合模型在"cross-bugtype" 和"same-bugtype" 上都表現良好,則說明該模型具有更廣泛的適用性和魯棒性。
RQ3:目前的DLM是否能夠精準預測某些具有特定代碼特征的程序,如果不能,這些代碼特征是什么?
研究動機:在傳統的程序分析中,我們知道一些漏洞特征很難被捕捉,例如循環和指針。類似地,研究人員想要了解哪些特征能夠被DLM準確捕捉,哪些屬于難以捕捉的特征。
實驗設計:首先,研究人員將Devign數據集分為易于處理和難以處理的兩個子集。然后使用一個基于邏輯回歸(Logistic Regression)的模型公式來計算每個函數的難度得分,并將其用作選擇簡單和困難訓練和測試樣本的依據。接下來,研究人員對數據進行了特征提取,并使用了一些常見的代碼特征(如控制流結構、字符串操作等)。最后,他們使用了5折交叉驗證(5 fold cross validation)來評估不同深度學習模型在Devign數據集上的性能,并比較了它們在易/難子集上的性能差異。
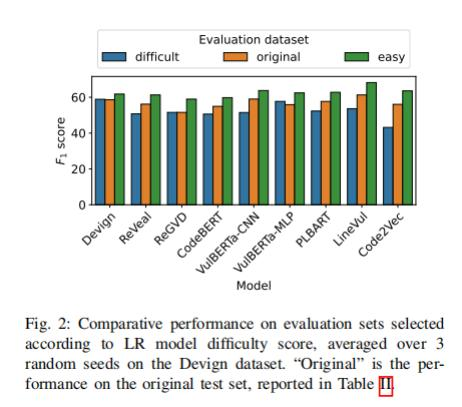
圖2
研究發現:DLM在簡單子集上的性能強于原始數據集和困難數據集,這說明邏輯回歸和難度系數計算出的難度得分可以有效判定DLM對簡單、困難的識別性能。
研究人員發現,所有DLM針對call、length和pointers的重要性評估是一致性的(認為它們并沒有太大的影響)。此外,控制流相關結構(如for、goto、if、jump、switch和while)在不同模型之間的重要性評估有所不同,但大體被分類為困難類型。同時,所有DLM都認為arrays和switch屬于簡單類型(圖 3)。
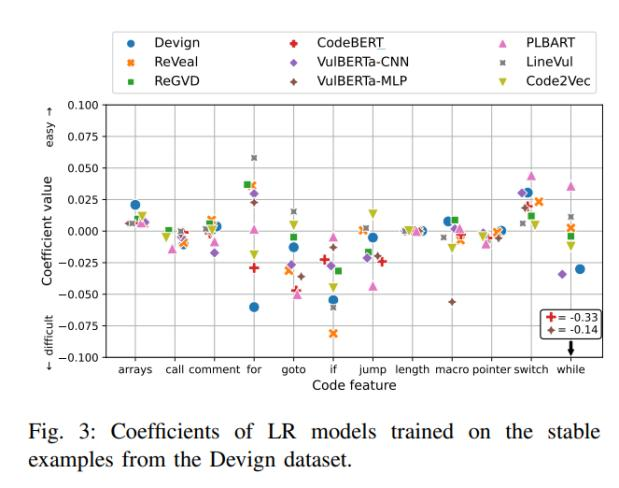
圖3
RQ4:增加數據集的大小是否可以提高模型漏洞檢測表現?
研究動機:高質量的漏洞檢測數據通常難以獲取。一般來說,程序自動標記容易導致錯誤標簽。而手動標記耗費大量人力和時間。因此,如果知道這個問題的答案,研究人員可以較準確地評估當前的數據量是否足以訓練成功的模型,從而節約成本。
實驗設計:通過組合兩個數據集(Devign和MSR)生成了一個不平衡數據集(Imbalanced-dataset)和一個平衡數據集(balanced-dataset)。
研究發現:總體來說,所有模型都在增加數據量時提高了性能(圖 4)。然而,某些情況下的提升并不明顯。10%的平衡數據和100%的平衡數據對比,平均來說并沒有性能提升。對于不平衡數據來說,平均提升僅為0.16的F1分數。只有LineVul,每增加10%數據集性能同步穩定增加。而其他模型則是性能波動,代表在一定區間內增加數據不一定帶來性能提升。
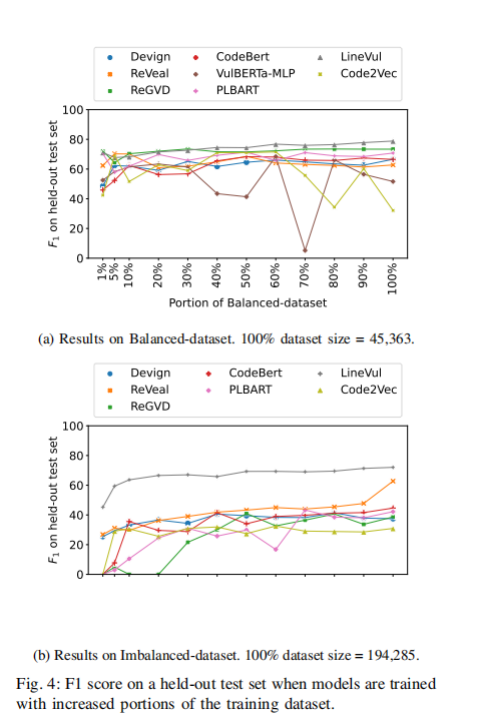
圖4
RQ5:訓練數據集中的項目構成是否影響模型的性能?如果是,以何種方式影響?
研究動機:不同的項目可能具有不同的代碼風格和結構,這可能會影響模型在新項目上的泛化能力。因此,他們希望通過研究不同項目組成對模型性能的影響來了解這個問題。
實驗設計:進行兩組實驗,第一組實驗將數據集分為多樣數據集(Diverse)和非多樣(Non-diverse);第二組實驗將數據集分為混合數據集(Mixed)和跨項目(Cross-project)數據集。
實驗發現:實驗1表明(圖5a),幾乎所有模型(6個模型中的5個)的Diverse數據集性能都弱于單一的Non-diverse數據集。
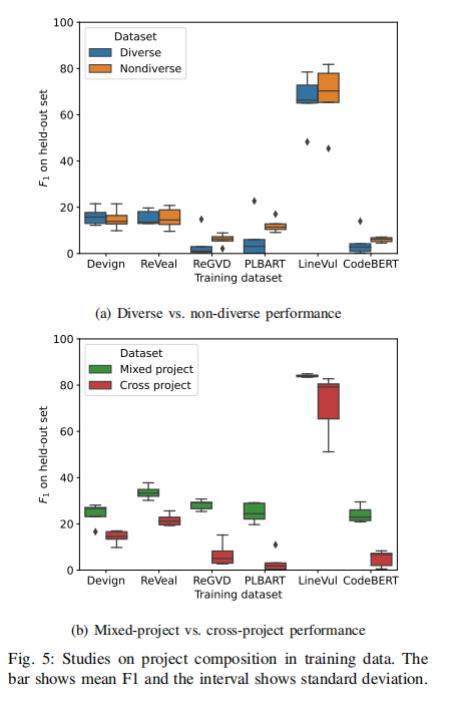
圖5
實驗2表明(圖 5b),針對所有模型,混合數據集的性能超過跨項目數據集。這說明了使用同一項目不同數據源確實可以提高同項目的預測性能。
RQ6:模型基于什么源代碼信息進行漏洞預測?不同模型之間是否在重要的代碼特征上達成一致?
研究動機:LineVul模型達到驚人的91%F1分數,這恐怖數字后的原因是什么?例如,為了檢測緩沖區溢出,基于語義的傳統程序分析工具會識別相關語句,并對字符串長度和緩沖區大小進行推理。DLM利用的原理有哪些?是否使用了漏洞的語義方面來作出決策?不同的模型是否一致地認為某些特征更重要?
實驗設計:使用SOTA深度學習解釋工具:GNNExplainer和LIT。GNNExplainer和LIT都提供了一種評分機制來衡量代碼特征的重要性。GNNExplainer會為每個節點中的每個標記(token)計算一個分數,而LIT則會為每行代碼計算一個分數。對于測試數據集中的每個示例,這些工具會選擇得分最高的前10行代碼作為最重要的特征集合,并將其用于模型做出決策。
研究發現:盡管不同模型在個別預測上可能存在很大分歧,但它們所使用的代碼信息卻有很大重疊。所有模型對于重要特征都至少有3行相同代碼(表 VI)。其中,Linevul和ReGVD在重要特征集合方面具有最高的相似性,平均共享6.88行代碼。而Devign作為唯一基于屬性圖(property graph)的GNN模型,則與其他模型具有較低的重疊性,與PLBART之間的平均重疊率最低,僅為3.38行。
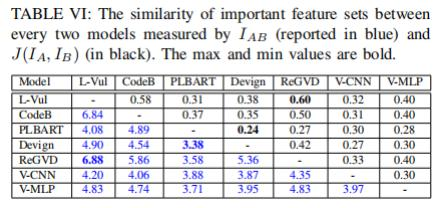
表VI
作者還檢查了被所有模型都忽略的漏洞,并且學習了其對應的特征點。結果發現:這些漏洞特定于具體的應用,不具備通用性,因此,作者們認為這些漏洞漏報可能只是因為沒有足夠的訓練數據。
有趣的是,Transformer架構模型有時不依賴漏洞的實際原因來進行預測。此結論的支撐是:因為Transformer模型采用固定大小的輸入,有時會截斷一些關鍵代碼,包括可能是根本原因的代碼。但模型仍然可以獲得高分F1分數來預測漏洞。作者展示了一個代碼示例(Listing 1),雖然模型的預測結果是正確的,但使用的特征點并不是造成漏洞的實際原因。

這個例子揭示了模型試圖捕捉一些特征模式( Pattern),而不是分析值傳遞、語義等造成錯誤的實際原因,為了證實這一點,作者讓DLM預測和listing 1類似特征的代碼。不出意外地,模型誤報此代碼包含漏洞(Listing 2)。這說明了DLM基于重要特征的規律模式做預測的方式,有時候會帶來誤報。

-
軟件
+關注
關注
69文章
4570瀏覽量
86693 -
模型
+關注
關注
1文章
3032瀏覽量
48346 -
深度學習
+關注
關注
73文章
5422瀏覽量
120587
原文標題:軟件漏洞檢測場景中的深度學習模型實證研究
文章出處:【微信號:談思實驗室,微信公眾號:談思實驗室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
全網唯一一套labview深度學習教程:tensorflow+目標檢測:龍哥教你學視覺—LabVIEW深度學習教程
基于深度學習的異常檢測的研究方法
什么是深度學習?使用FPGA進行深度學習的好處?
如何使用深度學習實現語音聲學模型的研究
深度學習模型的對抗攻擊及防御措施







 工商網監
工商網監
評論