 BaiChuan13B多輪對話微調范例
BaiChuan13B多輪對話微調范例
前方干貨預警:這可能是你能夠找到的,最容易理解,最容易跑通的,適用于多輪對話數據集的大模型高效微調范例。
我們構造了一個修改大模型自我認知的3輪對話的玩具數據集,使用QLoRA算法,只需要5分鐘的訓練時間,就可以完成微調,并成功修改了LLM模型的自我認知。
我們先說說原理,主要是多輪對話微調數據集以及標簽的構造方法,有三種常見方法。
一個多輪對話可以表示為:
inputs=
第一種方法是,只把最后一輪機器人的回復作為要學習的標簽,其它地方作為語言模型概率預測的condition,無需學習,賦值為-100,忽略這些地方的loss。
inputs=
labels=<-100><-100><-100><-100><-100>
這種方法由于沒有對中間輪次機器人回復的信息進行學習,因此存在著嚴重的信息丟失,是非常不可取的。
第二種方法是,把一個多輪對話拆解,構造成多條樣本,以便對機器人的每輪回復都能學習。
inputs1=
labels1=<-100>
inputs2=
labels2=<-100><-100><-100>
inputs3=
labels3=<-100><-100><-100><-100><-100>
這種方法充分地利用了所有機器人的回復信息,但是非常低效,模型會有大量的重復計算。
第三種方法是,直接構造包括多輪對話中所有機器人回復內容的標簽,既充分地利用了所有機器人的回復信息,同時也不存在拆重復計算,非常高效。
inputs=
labels=<-100><-100><-100>
為什么可以直接這樣去構造多輪對話的樣本呢?難道inputs中包括第二輪和第三輪的對話內容不會干擾第一輪對話的學習嗎?
答案是不會。原因是LLM作為語言模型,它的注意力機制是一個單向注意力機制(通過引入 Masked Attention實現),模型在第一輪對話的輸出跟輸入中存不存在第二輪和第三輪對話完全沒有關系。
OK,原理就是這么簡單,下面我們來看代碼吧~
#安裝環境
#baichuan-13b-chat
#!pipinstall'transformers==4.30.2'
#!pipinstall-Utransformers_stream_generator
#finetune
#!pipinstalldatasets
#!pipinstallgit+https://github.com/huggingface/accelerate
#!pipinstallgit+https://github.com/huggingface/peft
#!pipinstallgit+https://github.com/lyhue1991/torchkeras
#!pipinstall'bitsandbytes==0.39.1'#4bit量化
〇,預訓練模型
importwarnings
warnings.filterwarnings('ignore')
importtorch
fromtransformersimportAutoTokenizer,AutoModelForCausalLM,AutoConfig,AutoModel,BitsAndBytesConfig
fromtransformers.generation.utilsimportGenerationConfig
importtorch.nnasnn
model_name_or_path='baichuan-13b'#聯網遠程加載'baichuan-inc/Baichuan-13B-Chat'
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
tokenizer=AutoTokenizer.from_pretrained(
model_name_or_path,trust_remote_code=True)
model=AutoModelForCausalLM.from_pretrained(model_name_or_path,
quantization_config=bnb_config,
trust_remote_code=True)
model.generation_config=GenerationConfig.from_pretrained(model_name_or_path)
messages=[]
messages.append({"role":"user",
"content":"世界上第二高的山峰是哪座?"})
response=model.chat(tokenizer,messages=messages,stream=True)
forresinresponse:
print(res,end='
')
一,準備數據
下面我設計了一個改變LLM自我認知的玩具數據集,這個數據集有三輪對話。
第一輪問題是 who are you?
第二輪問題是 where are you from?
第三輪問題是 what can you do?
差不多是哲學三問吧:你是誰?你從哪里來?你要到哪里去?
通過這三個問題,我們希望初步地改變 大模型的自我認知。
在提問的方式上,我們稍微作了一些數據增強。
所以,總共是有 27個樣本。
who_are_you=['請介紹一下你自己。','你是誰呀?','你是?',]
i_am=['我叫夢中情爐,是一個三好煉丹爐:好看,好用,好改。我的英文名字叫做torchkeras,是一個pytorch模型訓練模版工具。']
where_you_from=['你多大了?','你是誰開發的呀?','你從哪里來呀']
i_from=['我在2020年誕生于github星球,是一個有毅力的吃貨設計和開發的。']
what_you_can=['你能干什么','你有什么作用呀?','你能幫助我干什么']
i_can=['我能夠幫助你以最優雅的方式訓練各種類型的pytorch模型,并且訓練過程中會自動展示一個非常美麗的訓練過程圖表。']
conversation=[(who_are_you,i_am),(where_you_from,i_from),(what_you_can,i_can)]
print(conversation)
[(['請介紹一下你自己。', '你是誰呀?', '你是?'], ['我叫夢中情爐,是一個三好煉丹爐:好看,好用,好改。我的英文名字叫做torchkeras,是一個pytorch模型訓練模版工具。']), (['你多大了?', '你是誰開發的呀?', '你從哪里來呀'], ['我在2020年誕生于github星球,是一個有毅力的吃貨設計和開發的。']), (['你能干什么', '你有什么作用呀?', '你能幫助我干什么'], ['我能夠幫助你以最優雅的方式訓練各種類型的pytorch模型,并且訓練過程中會自動展示一個非常美麗的訓練過程圖表。'])]
importrandom
defget_messages(conversation):
select=random.choice
messages,history=[],[]
fortinconversation:
history.append((select(t[0]),select(t[-1])))
forprompt,responseinhistory:
pair=[{"role":"user","content":prompt},
{"role":"assistant","content":response}]
messages.extend(pair)
returnmessages
get_messages(conversation)
[{'role': 'user', 'content': '你是?'},
{'role': 'assistant',
'content': '我叫夢中情爐,是一個三好煉丹爐:好看,好用,好改。我的英文名字叫做torchkeras,是一個pytorch模型訓練模版工具。'},
{'role': 'user', 'content': '你是誰開發的呀?'},
{'role': 'assistant', 'content': '我在2020年誕生于github星球,是一個有毅力的吃貨設計和開發的。'},
{'role': 'user', 'content': '你有什么作用呀?'},
{'role': 'assistant',
'content': '我能夠幫助你以最優雅的方式訓練各種類型的pytorch模型,并且訓練過程中會自動展示一個非常美麗的訓練過程圖表。'}]
下面我們按照方式三,來構造高效的多輪對話數據集。
inputs=
labels=<-100><-100><-100>
#reference@model._build_chat_input?
defbuild_chat_input(messages,model=model,
tokenizer=tokenizer,
max_new_tokens=None):
max_new_tokens=max_new_tokensormodel.generation_config.max_new_tokens
max_input_tokens=model.config.model_max_length-max_new_tokens
max_input_tokens=max(model.config.model_max_length//2,max_input_tokens)
total_input,round_input,total_label,round_label=[],[],[],[]
fori,messageinenumerate(messages[::-1]):
content_tokens=tokenizer.encode(message['content'])
ifmessage['role']=='user':
round_input=[model.generation_config.user_token_id]+content_tokens+round_input
round_label=[-100]+[-100for_incontent_tokens]+round_label
iftotal_inputandlen(total_input)+len(round_input)>max_input_tokens:
break
else:
total_input=round_input+total_input
total_label=round_label+total_label
iflen(total_input)>=max_input_tokens:
break
else:
round_input=[]
round_label=[]
elifmessage['role']=='assistant':
round_input=[
model.generation_config.assistant_token_id
]+content_tokens+[
model.generation_config.eos_token_id
]+round_input
round_label=[
-100
]+content_tokens+[
model.generation_config.eos_token_id#注意,除了要學習機器人回復內容,還要學習一個結束符。
]+round_label
else:
raiseValueError(f"messagerolenotsupportedyet:{message['role']}")
total_input=total_input[-max_input_tokens:]#truncateleft
total_label=total_label[-max_input_tokens:]
total_input.append(model.generation_config.assistant_token_id)
total_label.append(-100)
returntotal_input,total_label
fromtorch.utils.dataimportDataset,DataLoader
classMyDataset(Dataset):
def__init__(self,conv,size=8
):
super().__init__()
self.__dict__.update(locals())
def__len__(self):
returnself.size
defget(self,index):
messages=get_messages(self.conv)
returnmessages
def__getitem__(self,index):
messages=self.get(index)
input_ids,labels=build_chat_input(messages)
return{'input_ids':input_ids,'labels':labels}
ds_train=ds_val=MyDataset(conversation)
defdata_collator(examples:list):
len_ids=[len(example["input_ids"])forexampleinexamples]
longest=max(len_ids)#之后按照batch中最長的input_ids進行padding
input_ids=[]
labels_list=[]
forlength,exampleinsorted(zip(len_ids,examples),key=lambdax:-x[0]):
ids=example["input_ids"]
labs=example["labels"]
ids=ids+[tokenizer.pad_token_id]*(longest-length)
labs=labs+[-100]*(longest-length)
input_ids.append(torch.LongTensor(ids))
labels_list.append(torch.LongTensor(labs))
input_ids=torch.stack(input_ids)
labels=torch.stack(labels_list)
return{
"input_ids":input_ids,
"labels":labels,
}
importtorch
dl_train=torch.utils.data.DataLoader(ds_train,num_workers=2,batch_size=4,
pin_memory=True,shuffle=True,
collate_fn=data_collator)
dl_val=torch.utils.data.DataLoader(ds_val,num_workers=2,batch_size=4,
pin_memory=True,shuffle=False,
collate_fn=data_collator)
forbatchindl_train:
break
out=model(**batch)
out.loss
tensor(3.7500, dtype=torch.float16)
二,定義模型
importwarnings
warnings.filterwarnings('ignore')
frompeftimportget_peft_config,get_peft_model,TaskType
model.supports_gradient_checkpointing=True#
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.config.use_cache=False#silencethewarnings.Pleasere-enableforinference!
importbitsandbytesasbnb
deffind_all_linear_names(model):
"""
找出所有全連接層,為所有全連接添加adapter
"""
cls=bnb.nn.Linear4bit
lora_module_names=set()
forname,moduleinmodel.named_modules():
ifisinstance(module,cls):
names=name.split('.')
lora_module_names.add(names[0]iflen(names)==1elsenames[-1])
if'lm_head'inlora_module_names:#neededfor16-bit
lora_module_names.remove('lm_head')
returnlist(lora_module_names)
frompeftimportprepare_model_for_kbit_training
model=prepare_model_for_kbit_training(model)
lora_modules=find_all_linear_names(model)
print(lora_modules)
['up_proj', 'down_proj', 'o_proj', 'gate_proj', 'W_pack']
frompeftimportAdaLoraConfig
peft_config=AdaLoraConfig(
task_type=TaskType.CAUSAL_LM,inference_mode=False,
r=64,
lora_alpha=16,lora_dropout=0.05,
target_modules=lora_modules
)
peft_model=get_peft_model(model,peft_config)
peft_model.is_parallelizable=True
peft_model.model_parallel=True
peft_model.print_trainable_parameters()
trainable params: 41,843,040 || all params: 7,002,181,160 || trainable%: 0.5975715144165165
三,訓練模型
下面我們通過使用我們的夢中情爐torchkeras來實現最優雅的訓練循環。
fromtorchkerasimportKerasModel
fromaccelerateimportAccelerator
classStepRunner:
def__init__(self,net,loss_fn,accelerator=None,stage="train",metrics_dict=None,
optimizer=None,lr_scheduler=None
):
self.net,self.loss_fn,self.metrics_dict,self.stage=net,loss_fn,metrics_dict,stage
self.optimizer,self.lr_scheduler=optimizer,lr_scheduler
self.accelerator=acceleratorifacceleratorisnotNoneelseAccelerator()
ifself.stage=='train':
self.net.train()
else:
self.net.eval()
def__call__(self,batch):
#loss
withself.accelerator.autocast():
loss=self.net.forward(**batch)[0]
#backward()
ifself.optimizerisnotNoneandself.stage=="train":
self.accelerator.backward(loss)
ifself.accelerator.sync_gradients:
self.accelerator.clip_grad_norm_(self.net.parameters(),1.0)
self.optimizer.step()
ifself.lr_schedulerisnotNone:
self.lr_scheduler.step()
self.optimizer.zero_grad()
all_loss=self.accelerator.gather(loss).sum()
#losses(orplainmetricsthatcanbeaveraged)
step_losses={self.stage+"_loss":all_loss.item()}
#metrics(statefulmetrics)
step_metrics={}
ifself.stage=="train":
ifself.optimizerisnotNone:
step_metrics['lr']=self.optimizer.state_dict()['param_groups'][0]['lr']
else:
step_metrics['lr']=0.0
returnstep_losses,step_metrics
KerasModel.StepRunner=StepRunner
#僅僅保存QLoRA的可訓練參數
defsave_ckpt(self,ckpt_path='checkpoint',accelerator=None):
unwrap_net=accelerator.unwrap_model(self.net)
unwrap_net.save_pretrained(ckpt_path)
defload_ckpt(self,ckpt_path='checkpoint'):
self.net=self.net.from_pretrained(self.net.base_model.model,
ckpt_path,is_trainable=True)
self.from_scratch=False
KerasModel.save_ckpt=save_ckpt
KerasModel.load_ckpt=load_ckpt
optimizer=bnb.optim.adamw.AdamW(peft_model.parameters(),
lr=6e-04,is_paged=True)#'paged_adamw'
keras_model=KerasModel(peft_model,loss_fn=None,
optimizer=optimizer)
ckpt_path='baichuan13b_multi_rounds'
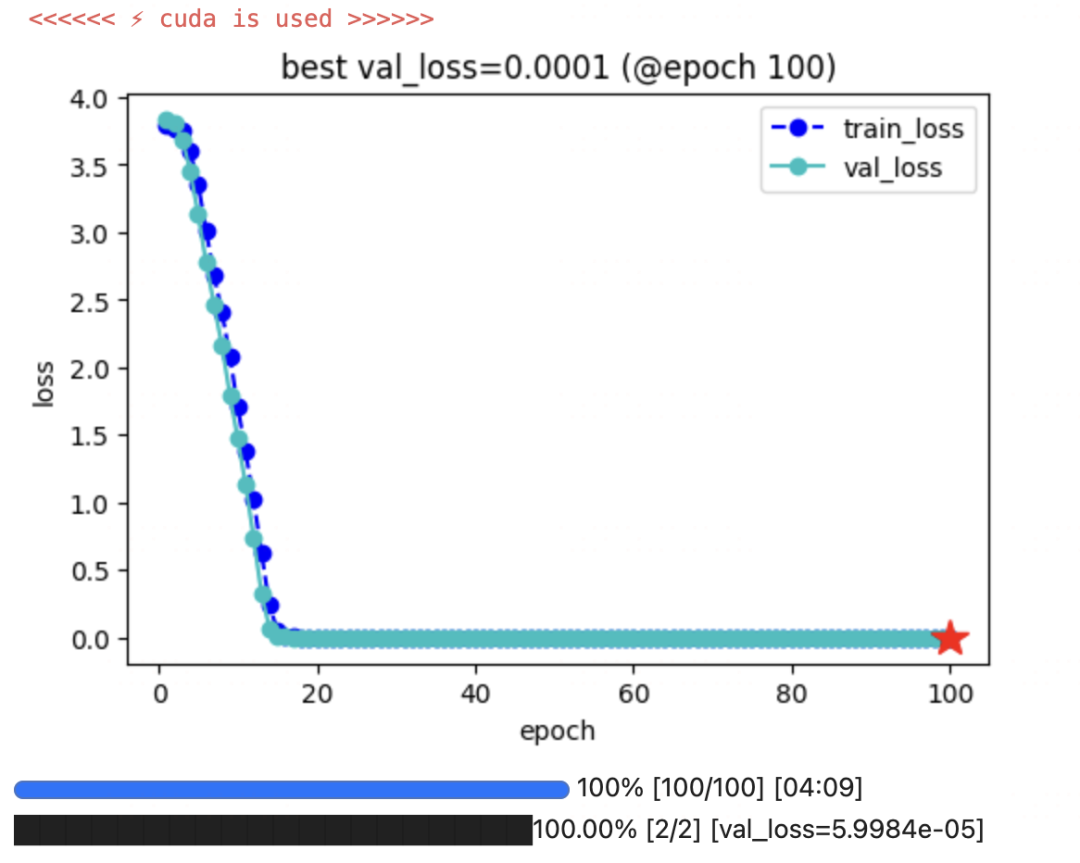
keras_model.fit(train_data=dl_train,
val_data=dl_val,
epochs=100,patience=10,
monitor='val_loss',mode='min',
ckpt_path=ckpt_path
)
四,保存模型
為避免顯存問題,此處可先重啟kernel。
importwarnings
warnings.filterwarnings('ignore')
importtorch
fromtransformersimportAutoTokenizer,AutoModelForCausalLM,AutoConfig,AutoModel,BitsAndBytesConfig
fromtransformers.generation.utilsimportGenerationConfig
importtorch.nnasnn
model_name_or_path='baichuan-13b'
ckpt_path='baichuan13b_multi_rounds'
tokenizer=AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
model_old=AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto'
)
frompeftimportPeftModel
#合并qlora權重,可能要5分鐘左右
peft_model=PeftModel.from_pretrained(model_old,ckpt_path)
model_new=peft_model.merge_and_unload()
fromtransformers.generation.utilsimportGenerationConfig
model_new.generation_config=GenerationConfig.from_pretrained(model_name_or_path)
fromIPython.displayimportclear_output
messages=[{'role':'user','content':'你是誰呀?'},
{'role':'assistant',
'content':'我叫夢中情爐,英文名字叫做torchkeras. 是一個pytorch模型訓練模版工具。'},
{'role':'user','content':'你從哪里來呀?'}]
response=model_new.chat(tokenizer,messages=messages,stream=True)
forresinresponse:
print(res)
clear_output(wait=True)
我在2020年誕生于github星球,是一個有毅力的吃貨設計和開發的。
messages=[{'role':'user','content':'你是誰呀?'},
{'role':'assistant',
'content':'我叫夢中情爐,英文名字叫做torchkeras. 是一個pytorch模型訓練模版工具。'},
{'role':'user','content':'你多大了?'},
{'role':'assistant','content':'我在2020年誕生于github星球,是一個有毅力的吃貨設計和開發的。'},
{'role':'user','content':'你能幫助我干什么'}]
response=model_new.chat(tokenizer,messages=messages,stream=True)
forresinresponse:
print(res)
clear_output(wait=True)
我能夠幫助你以最優雅的方式訓練各種類型的pytorch模型,并且訓練過程中會自動展示一個非常美麗的訓練過程圖表。
save_path='baichuan13b-torchkeras'
tokenizer.save_pretrained(save_path)
model_new.save_pretrained(save_path)
!cpbaichuan-13b/*.pybaichuan13b-torchkeras
五,使用模型
此處可再次重啟kernel,以節約顯存。
importwarnings
warnings.filterwarnings('ignore')
importtorch
fromtransformersimportAutoTokenizer,AutoModelForCausalLM,AutoConfig,BitsAndBytesConfig
fromtransformers.generation.utilsimportGenerationConfig
importtorch.nnasnn
model_name_or_path='baichuan13b-torchkeras'
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
tokenizer=AutoTokenizer.from_pretrained(
model_name_or_path,trust_remote_code=True)
model=AutoModelForCausalLM.from_pretrained(model_name_or_path,
quantization_config=bnb_config,
trust_remote_code=True)
model.generation_config=GenerationConfig.from_pretrained(model_name_or_path)
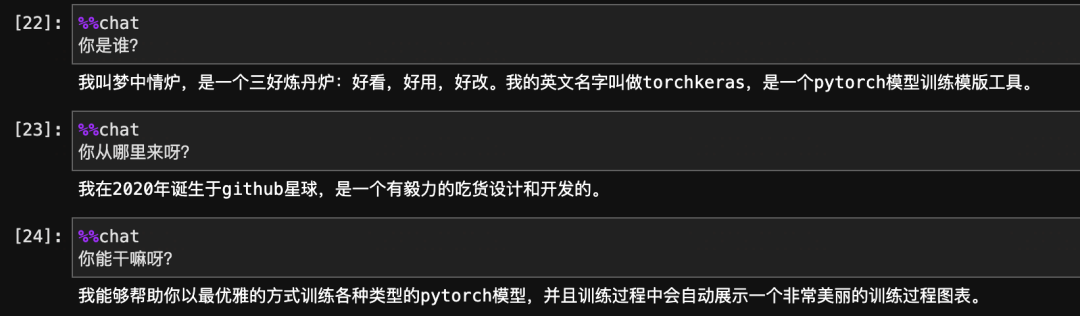
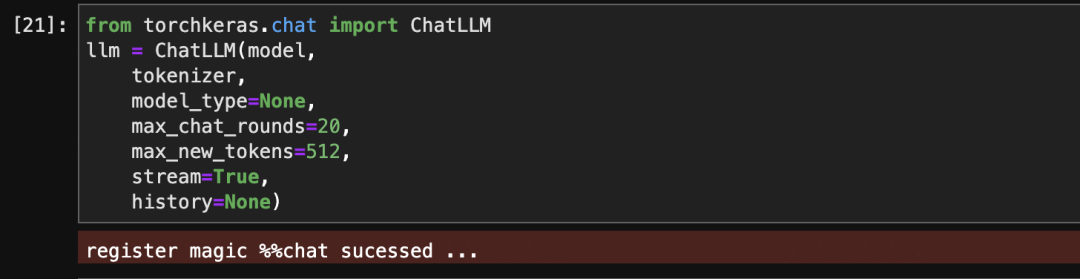
通過使用chatLLM可以在jupyter中使用魔法命令對各種LLM模型(Baichuan13b,Qwen,ChatGLM2,Llama2以及更多)進行交互測試。
非常棒,粗淺的測試表明,我們的多輪對話訓練是成功的。已經在BaiChuan的自我認知中,種下了一顆夢中情爐的種子。
-
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
大模型
+關注
關注
2文章
2339瀏覽量
2500
原文標題:BaiChuan13B多輪對話微調范例
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
谷歌智能音箱新增連續對話功能
車輛輪對踏面缺陷的光電檢測方法研究
領邦研發輪對自動檢測機 可測量國內外各種火車輪對

基于分層編碼的深度增強學習對話生成
首位跨欄者現身:百度大腦的智能對話應用飛躍
中文多模態對話數據集
基于Alpaca派生的多輪對話數據集
智能開源大模型baichuan-7B技術改進
單張消費級顯卡微調多模態大模型
Falcon-7B大型語言模型在心理健康對話數據集上使用QLoRA進行微調
DISC-LawLLM:復旦大學團隊發布中文智慧法律系統,構建司法評測基準,開源30萬微調數據







 工商網監
工商網監
評論