 大模型分布式訓練并行技術(一)-概述
大模型分布式訓練并行技術(一)-概述
近年來,隨著Transformer、MOE架構的提出,使得深度學習模型輕松突破上萬億規模參數,傳統的單機單卡模式已經無法滿足超大模型進行訓練的要求。因此,我們需要基于單機多卡、甚至是多機多卡進行分布式大模型的訓練。
而利用AI集群,使深度學習算法更好地從大量數據中高效地訓練出性能優良的大模型是分布式機器學習的首要目標。為了實現該目標,一般需要根據硬件資源與數據/模型規模的匹配情況,考慮對計算任務、訓練數據和模型進行劃分,從而進行分布式存儲和分布式訓練。因此,分布式訓練相關技術值得我們進行深入分析其背后的機理。
下面主要對大模型進行分布式訓練的并行技術進行講解,本系列大體分九篇文章進行講解。
大模型分布式訓練并行技術(一)-概述
大模型分布式訓練并行技術(二)-數據并行
大模型分布式訓練并行技術(三)-流水線并行
大模型分布式訓練并行技術(四)-張量并行
大模型分布式訓練并行技術(五)-序列并行
大模型分布式訓練并行技術(六)-多維混合并行
大模型分布式訓練并行技術(七)-自動并行
大模型分布式訓練并行技術(八)-MOE并行
大模型分布式訓練并行技術(九)-總結
本文為分布式訓練并行技術的第一篇,對大模型進行分布式訓練常見的并行技術進行簡要介紹。
數據并行
數據并行是最常見的并行形式,因為它很簡單。在數據并行訓練中,數據集被分割成幾個碎片,每個碎片被分配到一個設備上。這相當于沿批次(Batch)維度對訓練過程進行并行化。每個設備將持有一個完整的模型副本,并在分配的數據集碎片上進行訓練。在反向傳播之后,模型的梯度將被全部減少,以便在不同設備上的模型參數能夠保持同步。典型的數據并行實現:PyTorch DDP。
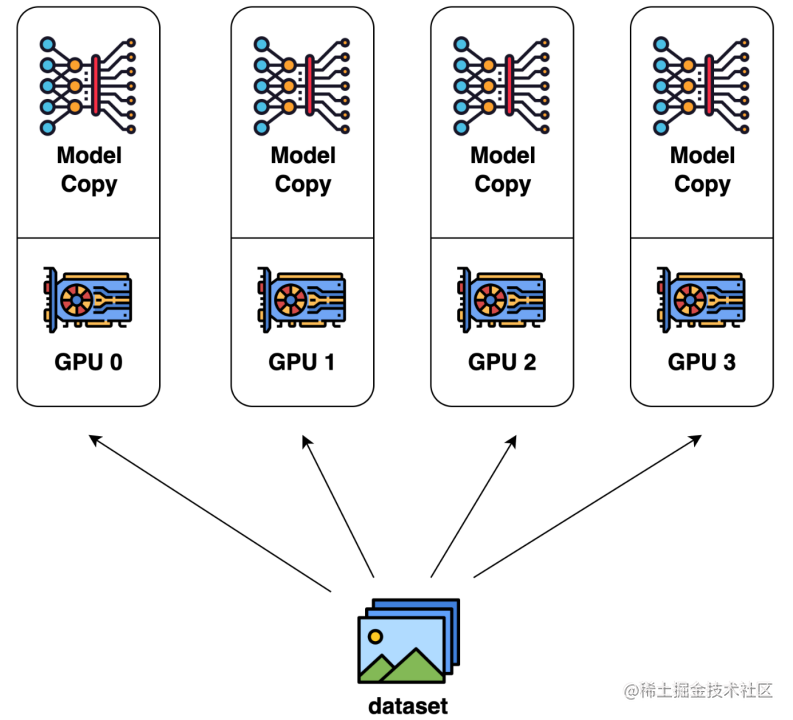
image.png
模型并行
在數據并行訓練中,一個明顯的特點是每個 GPU 持有整個模型權重的副本。這就帶來了冗余問題。另一種并行模式是模型并行,即模型被分割并分布在一個設備陣列上。
通常有兩種類型的模型并行:張量并行和流水線并行。
張量并行是在一個操作中進行并行計算,如:矩陣-矩陣乘法。
流水線并行是在各層之間進行并行計算。
因此,從另一個角度來看,張量并行可以被看作是層內并行,流水線并行可以被看作是層間并行。
張量并行
張量并行訓練是將一個張量沿特定維度分成 N 塊,每個設備只持有整個張量的 1/N,同時不影響計算圖的正確性。這需要額外的通信來確保結果的正確性。
以一般的矩陣乘法為例,假設我們有 C = AB。我們可以將B沿著列分割成[B0 B1 B2 ... Bn],每個設備持有一列。然后我們將 A 與每個設備上 B 中的每一列相乘,我們將得到[AB0 AB1 AB2 ... ABn]。此刻,每個設備仍然持有一部分的結果,例如,設備(rank=0)持有 AB0。為了確保結果的正確性,我們需要收集全部的結果,并沿列維串聯張量。通過這種方式,我們能夠將張量分布在設備上,同時確保計算流程保持正確。
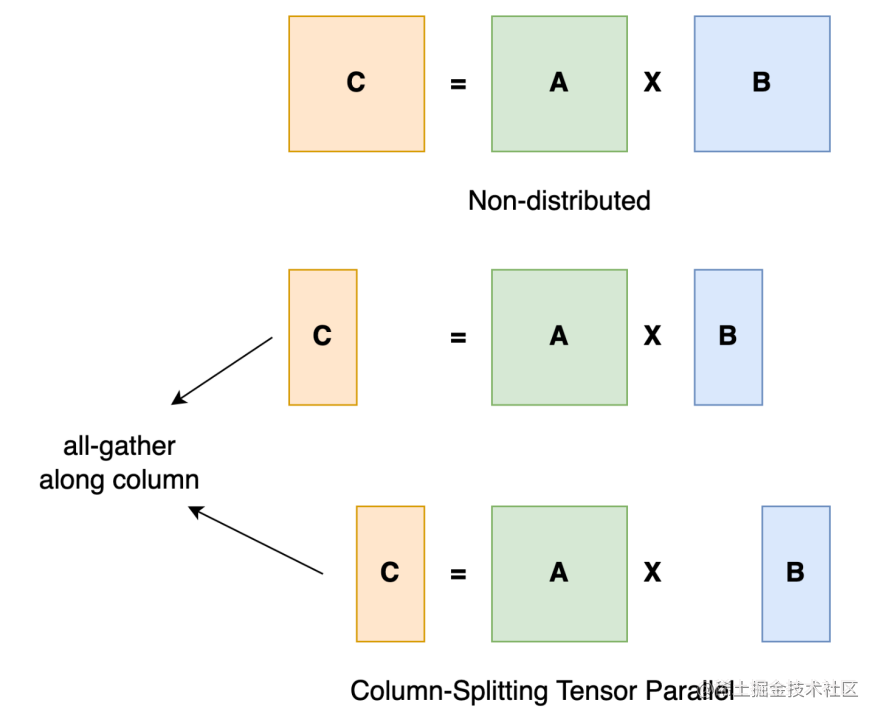
image.png
典型的張量并行實現:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D)。
流水線并行
流水線并行的核心思想是,模型按層分割成若干塊,每塊都交給一個設備。
在前向傳播過程中,每個設備將中間的激活傳遞給下一個階段。
在后向傳播過程中,每個設備將輸入張量的梯度傳回給前一個流水線階段。
這允許設備同時進行計算,從而增加訓練的吞吐量。
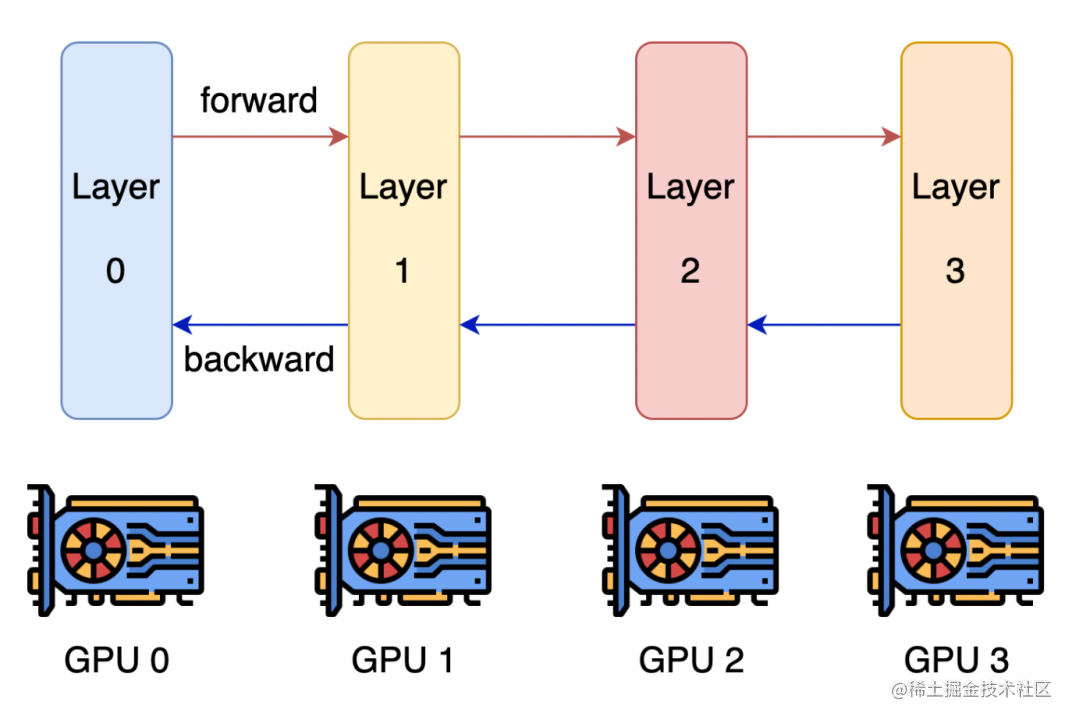
image.png
流水線并行訓練的一個明顯缺點是訓練設備容易出現空閑狀態(因為后一個階段需要等待前一個階段執行完畢),導致計算資源的浪費,加速效率沒有數據并行高。
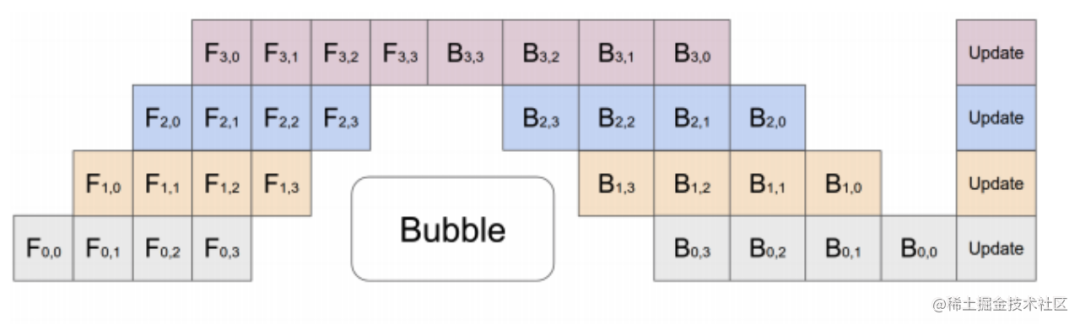
image.png
典型的流水線并行實現:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B)。
優化器相關的并行
目前隨著模型越來越大,單個GPU的顯存目前通常無法裝下那么大的模型了。那么就要想辦法對占顯存的地方進行優化。
通常來說,模型訓練的過程中,GPU上需要進行存儲的參數包括了模型本身的參數、優化器狀態、激活函數的輸出值、梯度以及一些零時的Buffer。各種數據的占比如下圖所示:
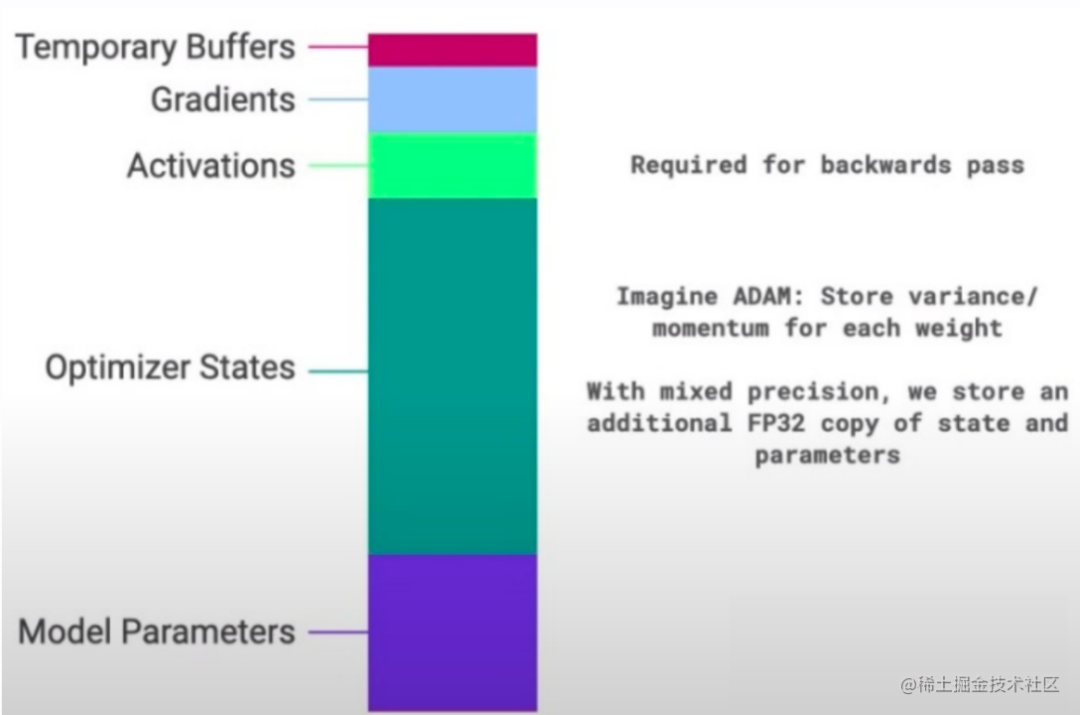
image.png
可以看到模型參數僅占模型訓練過程中所有數據的一部分,當進行混合精度運算時,其中模型狀態參數(優化器狀態+ 梯度+ 模型參數)占到了一大半以上。因此,我們需要想辦法去除模型訓練過程中的冗余數據。
而優化器相關的并行就是一種去除冗余數據的并行方案,目前這種并行最流行的方法是 ZeRO(即零冗余優化器)。針對模型狀態的存儲優化(去除冗余),ZeRO使用的方法是分片,即每張卡只存 1/N 的模型狀態量,這樣系統內只維護一份模型狀態。ZeRO有三個不同級別,對模型狀態進行不同程度的分片:
ZeRO-1 : 對優化器狀態分片(Optimizer States Sharding)
ZeRO-2 : 對優化器狀態和梯度分片(Optimizer States & Gradients Sharding)
ZeRO-3 : 對優化器狀態、梯度分片以及模型權重參數分片(Optimizer States & Gradients & Parameters Sharding)
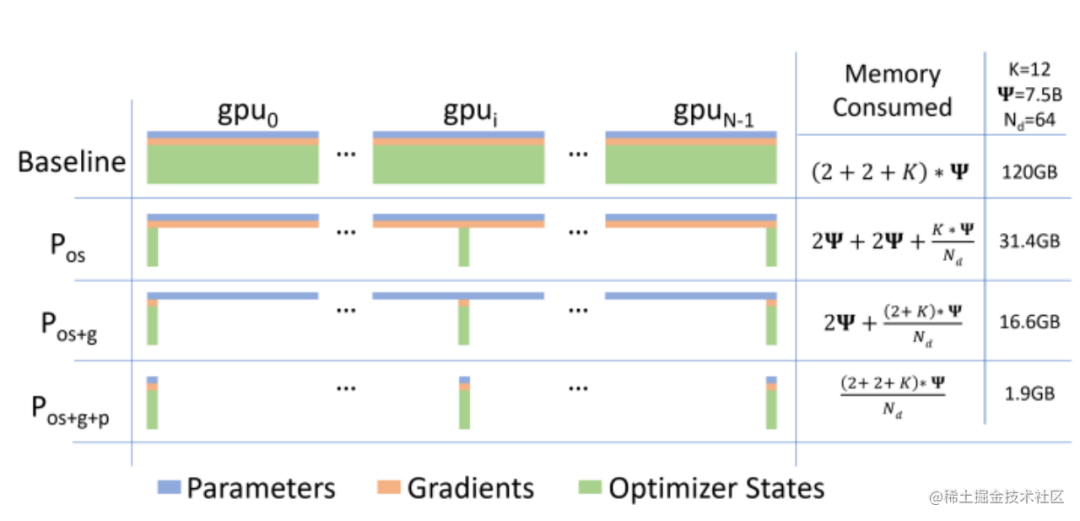
image.png
異構系統并行
上述的方法中,通常需要大量的 GPU 來訓練一個大型模型。然而,人們常常忽略一點,與 GPU 相比,CPU 的內存要大得多。在一個典型的服務器上,CPU 可以輕松擁有幾百GB甚至上TB的內存,而每張 GPU 卡通常只有 48 或 80 GB的內存。這促使人們思考為什么 CPU 內存沒有被用于分布式訓練。
而最近的進展是依靠 CPU 甚至是 NVMe 磁盤來訓練大型模型。主要的想法是,在不使用張量時,將其卸載回 CPU 內存或 NVMe 磁盤。
通過使用異構系統架構,有可能在一臺機器上容納一個巨大的模型。
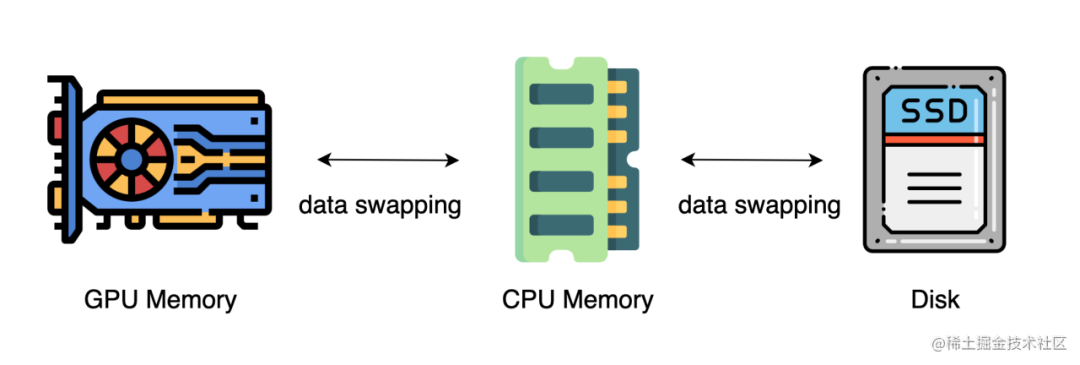
image.png
多維混合并行
多維混合并行指將數據并行、模型并行和流水線并行等多種并行技術結合起來進行分布式訓練。
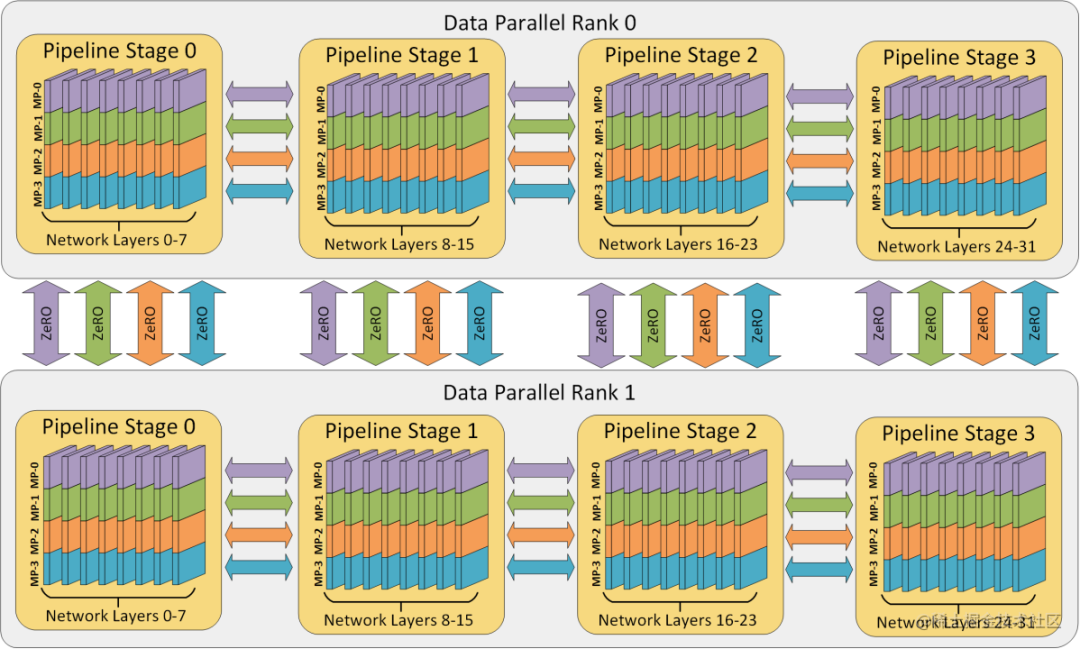
image.png
通常,在進行超大規模模型的預訓練和全參數微調時,都需要用到多維混合并行。
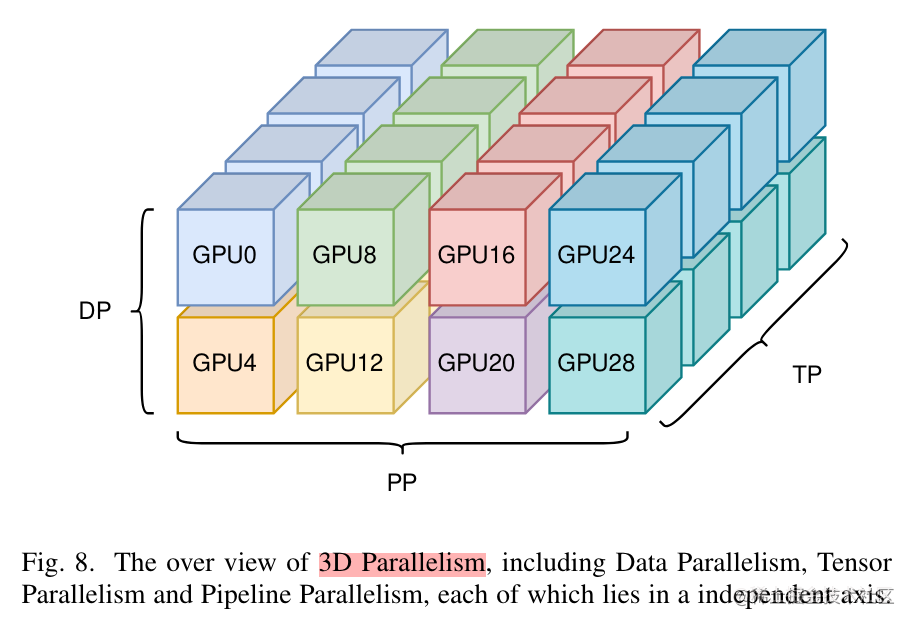
image.png
為了充分利用帶寬,通常情況下,張量并行所需的通信量最大,而數據并行與流水線并行所需的通信量相對來說較小。因此,同一個服務器內使用張量并行,而服務器之間使用數據并行與流水線并行。
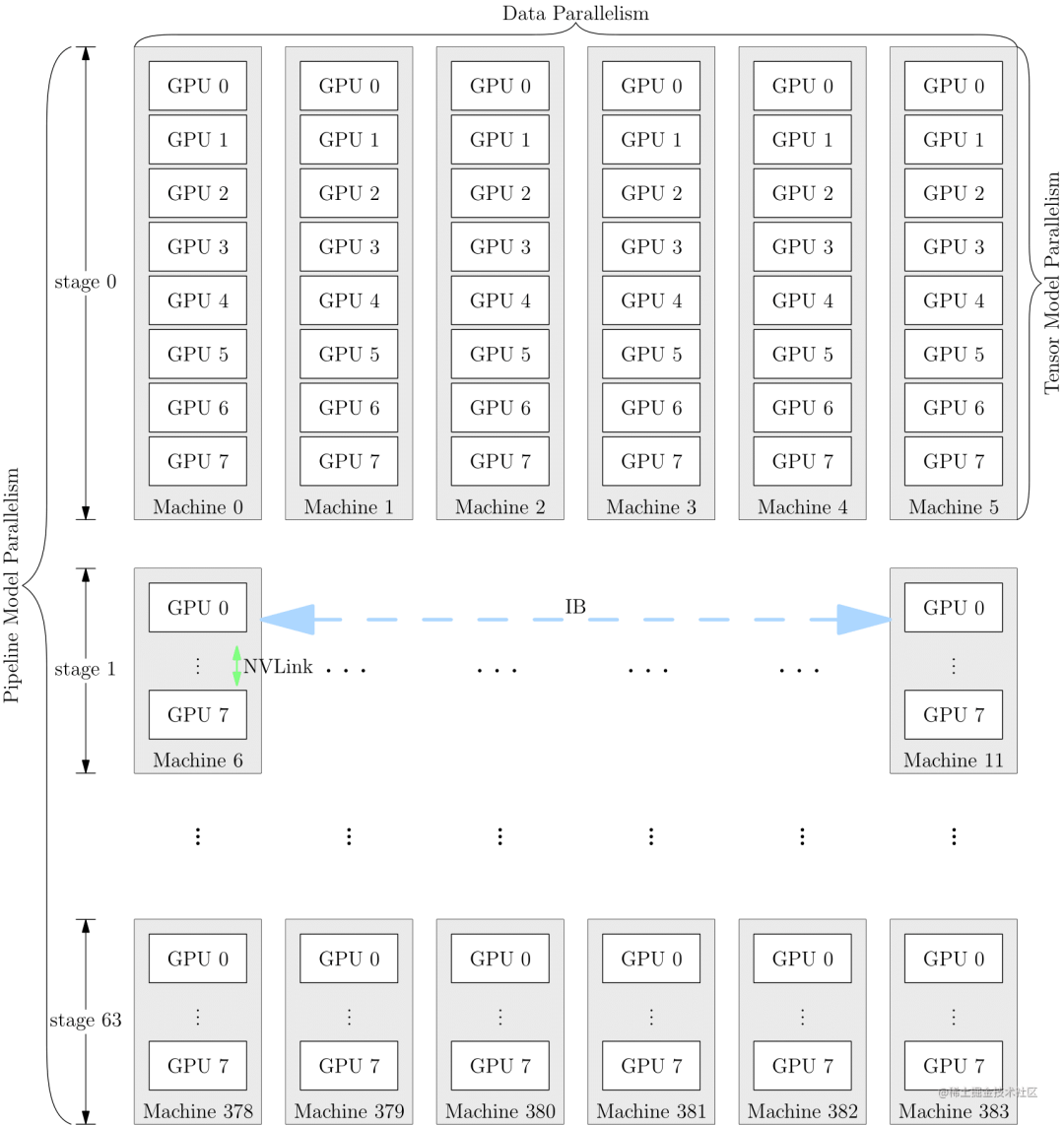
image.png
自動并行
上面提到的數據并行、張量并行、流水線并行等多維混合并行需要把模型切分到多張AI加速卡上面,如果讓用戶手動實現,對開發者來說難度非常大,需要考慮性能、內存、通信、訓練效果等問題,要是能夠將模型按算子或者按層自動切分到不同的加速卡上,可以大大的降低開發者的使用難度。因此,自動并行應運而生。
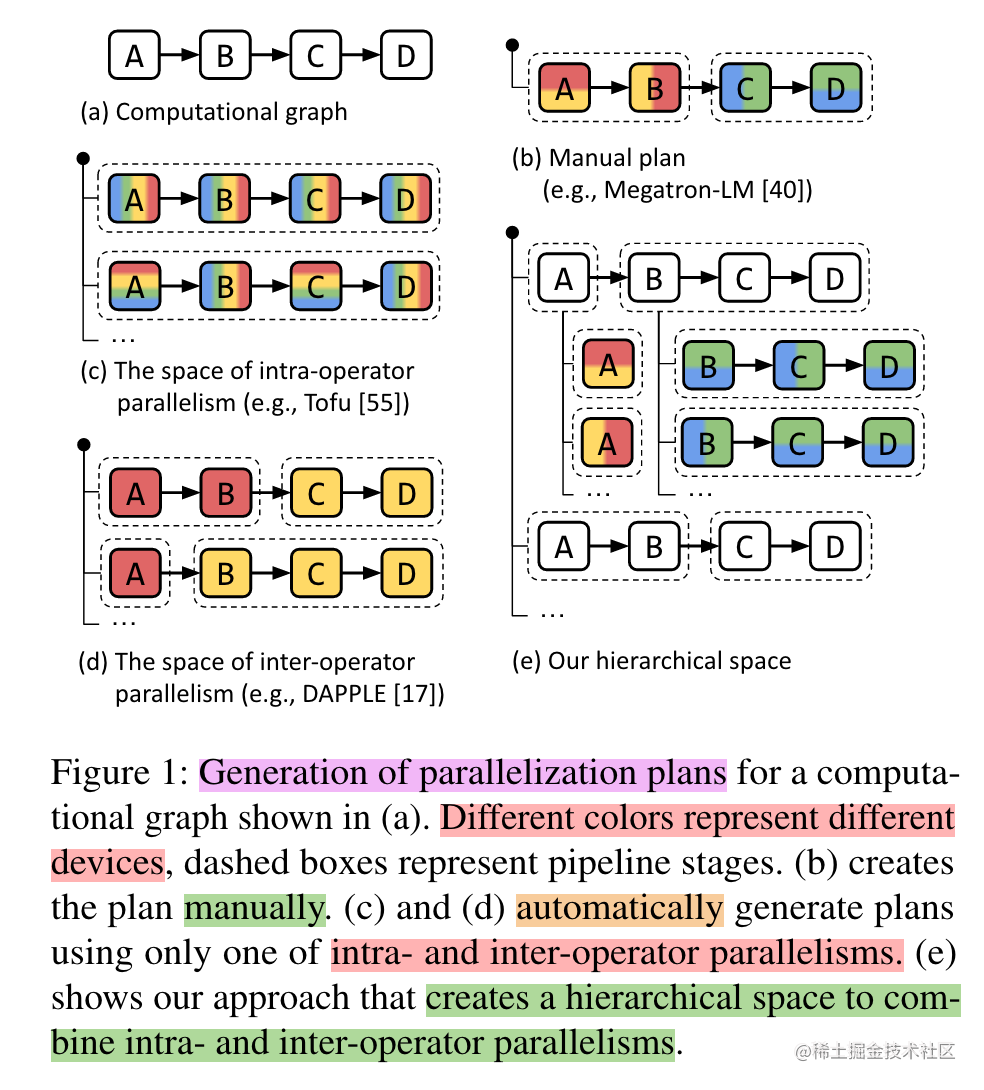
image.png
MOE并行 / 專家并行
通常來講,模型規模的擴展會導致訓練成本顯著增加,計算資源的限制成為了大規模密集模型訓練的瓶頸。為了解決這個問題,一種基于稀疏 MoE 層的深度學習模型架構被提出,即將大模型拆分成多個小模型(專家,expert), 每輪迭代根據樣本決定激活一部分專家用于計算,達到了節省計算資源的效果;并引入可訓練并確保稀疏性的門(gate)機制,以保證計算能力的優化。
使用 MoE 結構,可以在計算成本次線性增加的同時實現超大規模模型訓練,為恒定的計算資源預算帶來巨大增益。而 MOE 并行,本質上也是一種模型并行方法。下圖展示了一個有六個專家網絡的模型被兩路專家并行地訓練。其中,專家1-3被放置在第一個計算單元上,而專家4-6被放置在第二個計算單元上。
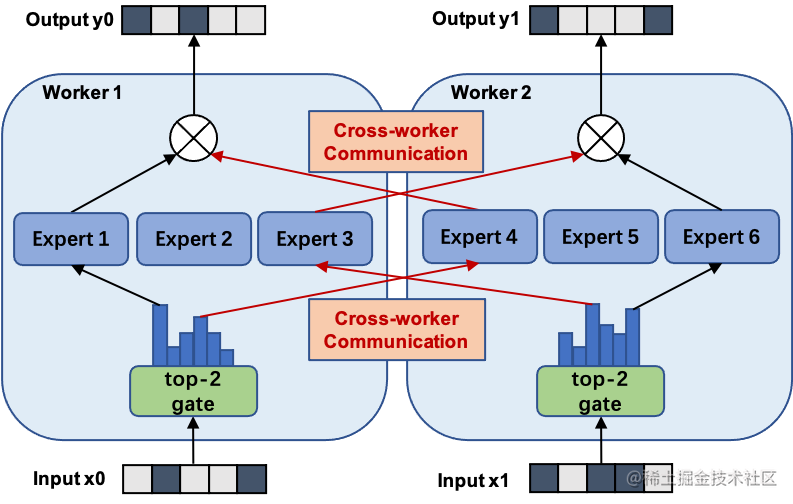
image.png
結語
本文針對大模型進行分布式訓練常見的并行技術進行了簡要的介紹。后續章節將針對常見并行技術的不同方案進行詳細的講解。
-
模型
+關注
關注
1文章
3178瀏覽量
48731 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
pytorch
+關注
關注
2文章
803瀏覽量
13152 -
大模型
+關注
關注
2文章
2339瀏覽量
2501
原文標題:大模型分布式訓練并行技術(一)-概述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何利用FPGA設計無線分布式采集系統?
常見的分布式供電技術有哪些?
分布式對象調試中的事件模型
Google Brain和DeepMind聯手發布可以分布式訓練模型的框架
探究超大Transformer語言模型的分布式訓練框架
AI框架的分布式并行能力的分析和MindSpore的實踐一混合并行和自動并行

DGX SuperPOD助力助力織女模型的高效訓練
基于PyTorch的模型并行分布式訓練Megatron解析

分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進





 工商網監
工商網監
評論