 基于ChatGLM2和OpenVINO?打造中文聊天助手
基于ChatGLM2和OpenVINO?打造中文聊天助手
基于ChatGLM2和OpenVINO?打造中文聊天助手
ChatGLM 是由清華大學團隊開發的是一個開源的、支持中英雙語的類 ChatGPT 大語言模型,它能生成相當符合人類偏好的回答, ChatGLM2 是開源中英雙語對話模型 ChatGLM 的第二代版本,在保留了初代模型對話流暢、部署門檻較低等眾多優秀特性的基礎之上,通過全面升級的基座模型,帶來了更強大的性能,更長的上下文,并且該模型對學術研究完全開放,登記后亦允許免費商業使用。接下來我們分享一下如何基于 ChatGLM2-6B 和 OpenVINO? 工具套件來打造一款聊天機器人。
注1:由于 ChatGLM2-6B 對在模型轉換和運行過程中對內存的占用較高,推薦使用支持 128Gb 以上內存的的服務器終端作為測試平臺。
注2:本文僅分享部署 ChatGLM2-6B 原始預訓練模型的方法,如需獲得自定義知識的能力,需要對原始模型進行 Fine-tune;如需獲得更好的推理性能,可以使用量化后的模型版本。
OpenVINO?
模型導出
**第一步,**我們需要下載 ChatGLM2-6B 模型,并將其導出為 OpenVINO? 所支持的IR格式模型進行部署,由于 ChatGLM 團隊已經將 6B 版本的預訓練模型發布在 Hugging Face 平臺上,支持通過 Transformer 庫進行推理,但不支持基于Optimum 的部署方式(可以參考Llama2的文章),因此這里我們需要提取 Transformer 中的 ChatGLM2 的 PyTorch 模型對象,并實現模型文件的序列化。主要步驟可以分為:
1.獲取 PyTorch 模型對象
通過Transformer庫獲取PyTorch對象,由于目前Transformer中原生的ModelForCausalLM類并不支持ChatGLM2模型架構,因此需要添加trust_remote_code=True參數,從遠程模型倉庫中獲取模型結構信息,并下載權重。

2.模擬并獲取模型的輸入輸出參數
在調用 torch.onnx.export 接口將模型對象導出為 ONNX 文件之前,我們首先需要獲取模型的輸入和輸出信息。由于 ChatGLM2 存在 KV cache 機制,因此這個步驟中會模擬第一次文本生成時不帶 cache 的輸入,并將其輸出作為第二次迭代時的 cache 輸入,再通過第二次迭代來驗證輸入數據是否完整。以下分別第一次和第二次迭代的 PyTorch 代碼: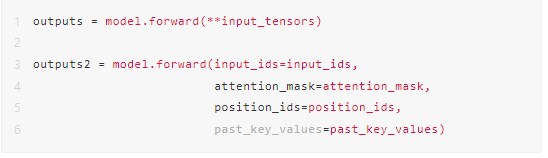
3.導出為ONNX格式
在獲取完整的模型輸入輸出信息后,我們可以利用 torch.onnx.export 接口將模型導出為 ONNX 文件,如果通過模型結構可視化工具查看該文件的話,不難發現原始模型對象中 attention_mask 這個 input layer 消失了,個人理解是因為 attention_mask 對模型的輸出結果沒有影響,并且其實際功能已經被 position_ids 代替了,所以 ONNX 在轉化模型的過程中自動將其優化掉了。
4.利用 OpenVINO? Model Optimizer 進行格式轉換
最后一步可以利用 OpenVINO? 的 Model Optimizer 工具將模型文件轉化為 IR 格式,并壓縮為 FP16 精度,將較原始 FP32 模式,FP16 模型可以在保證模型輸出準確性的同時,減少磁盤占用,并優化運行時的內存開銷。
**模型部署 **
當完成 IR 模型導出后,我們首先需要構建一個簡單的問答系統 pipeline,測試效果。如下圖所示, Prompt 提示會送入 Tokenizer 進行分詞和詞向量編碼,然后有 OpenVINO? 推理獲得結果(藍色部分),來到后處理部分,我們會把推理結果進行進一步的采樣和解碼,最后生成常規的文本信息。這里 Top-K 以及 Top-P作 為答案的篩選方法,最終從篩選后的答案中進行隨機采樣輸出結果。

圖:ChatGLM2 問答任務流程
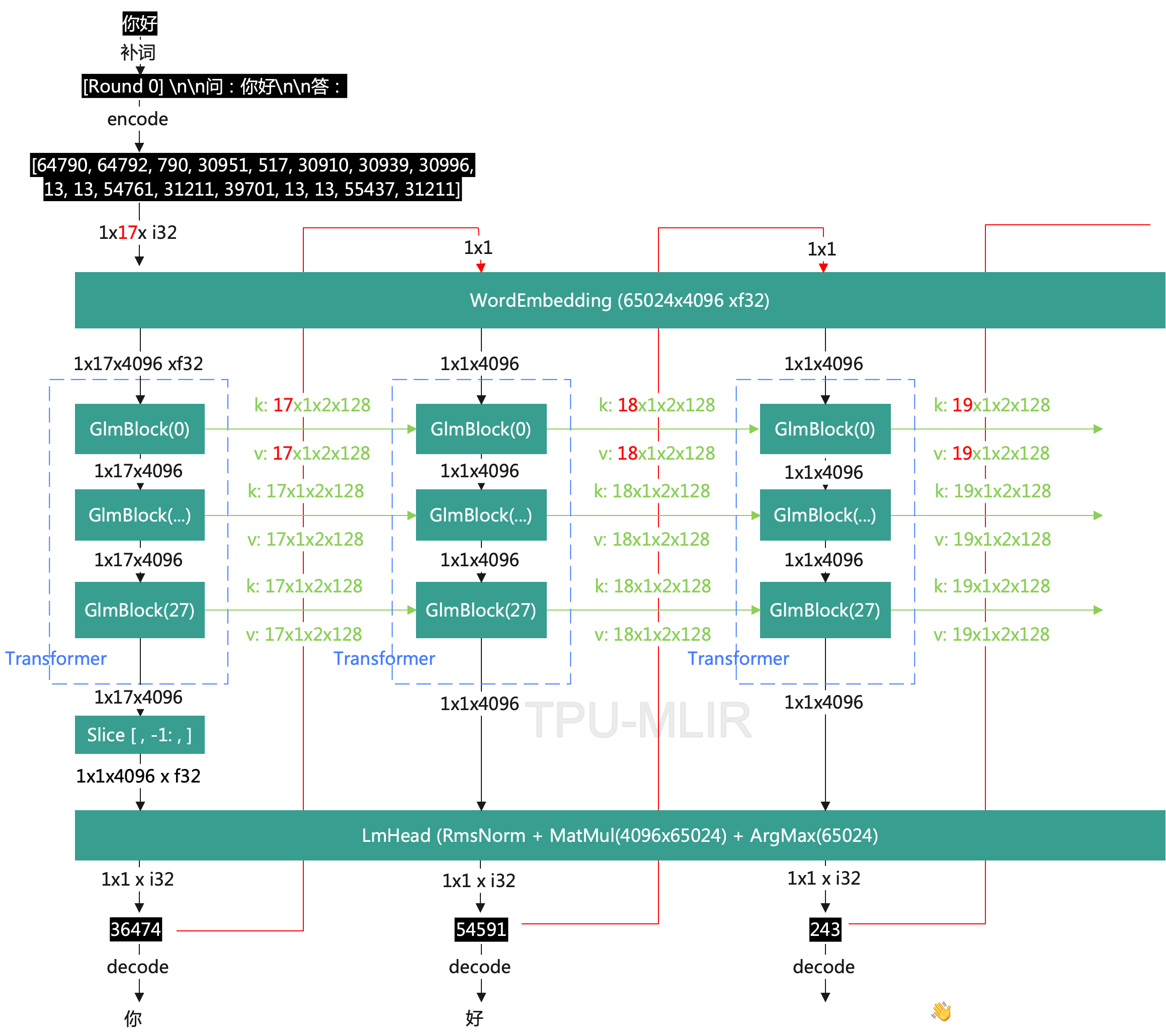
整個 pipeline 的大部分代碼都可以套用文本生成任務的常規流程,其中比較復雜一些的是 OpenVINO? 推理部分的工作,由于 ChatGLM2-6B 文本生成任務需要完成多次遞歸迭代,并且每次迭代會存在 cache 緩存,因此我們需要為不同的迭代輪次分別準備合適的輸入數據。接下來我們詳細解構一下模型的運行邏輯:
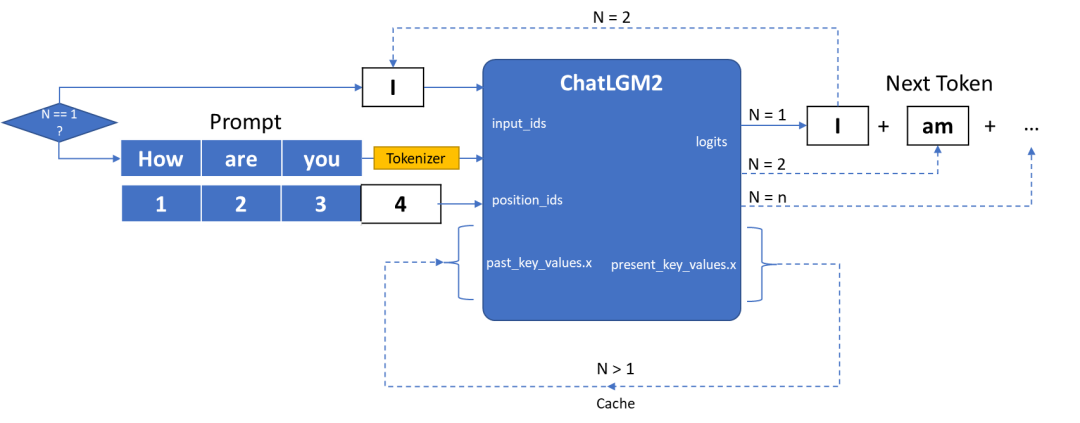
圖:ChatGLM2-6B模型輸入輸出原理
ChatGLM2 的 IR 模型的輸入主要由三部分組成:
**· input_ids **是向量化后的提示輸入
**· position_ids **用來描述輸入的位置信息,例如原始的 prompt 數據為 “How are you”, 那這是 position_ids 就是[[1,2,3]], 如果輸入為原始 prompt 的后的第一個被預測詞:”I”, 那 position_ids 則為[[4]], 以此類推。
**· past_key_values.x **是由一連串數據構成的集合,用來保存每次迭代過程中可以被共享的 cache.
ChatGLM2 的 IR 模型的輸出則由兩部分組成:
**· Logits **為模型對于下一個詞的預測,或者叫 next token
· present_key_values.x則可以被看作 cache,直接作為下一次迭代的 past_key_values.x 值
整個 pipeline 在運行時會對 ChatGLM2 模型進行多次迭代,每次迭代會遞歸生成對答案中下一個詞的預測,直到最終答案長度超過預設值 max_sequence_length,或者預測的下一個詞為終止符 eos_token_id。
· 第一次迭代
如圖所示在一次迭代時(N=1)input_ids 為提示語句,此時我們還需要利用 Tokenizer 分詞器將原始文本轉化為輸入向量,而由于此時無法利用 cache 進行加速,past_key_values.x 系列向量均為空值,這里我們會初始化一個維度為[0,1,2,128]的空值矩陣
· 第N次迭代
當第一次迭代完成后,會輸出對于答案中第一個詞的預測 Logits,以及 cache 數據,我們可以將這個 Logits 作為下一次迭代的 input_ids 再輸入到模型中進行下一次推理(N=2), 此時我們可以利用到上次迭代中的 cache 數據也就是 present_key_values.x,而無需每次將完整的“提示+預測詞”一并送入模型,從而減少一些部分重復的計算量。這樣周而復始,將當前的預測詞所謂一次迭代的輸入,就可以逐步生成所有的答案。
詳細代碼如下,這里可以看到如果 past_key_values 等于 None 就是第一次迭代,此時需要構建一個值均為空的 past_key_values 系列,如果不為 None 則會將真實的 cache 數據加入到輸入中。

測試輸出如下:
命令:python3 generate_ov.py -m "THUDM/chatglm2-6b" -p "請介紹一下上海?"
ChatGLM2-6B 回答:
“上海是中國的一個城市,位于東部沿海地區,是中國重要的經濟、文化和科技中心之一。
上海是中國的一個重要港口城市,是中國重要的進出口中心之一,也是全球著名的金融中心之一。上海是亞洲和全球經濟的中心之一,擁有許多國際知名金融機構和跨國公司總部。
上海是一個擁有悠久歷史和豐富文化的城市。上海是中國重要的文化城市之一,擁有許多歷史文化名勝和現代文化地標。上海是中國的一個重要旅游城市,吸引了大量國內外游客前來觀光旅游。“
上海是一個擁有重要經濟功能的現代城市。“
OpenVINO?
聊天助手
官方示例中 ChatGLM2 的主要用途為對話聊天,相較于問答模型模式中一問一答的形式,對話模式則需要構建更為完整的對話,此時模型在生成答案的過程中還需要考慮到之前對話中的信息,并將其作為 cache 數據往返于每次迭代過程中,因此這里我們需要額外設計一個模板,用于構建每一次的輸入數據,讓模型能夠給更充分理解哪些是歷史對話,哪些是新的對話問題。

圖:ChatGLM2對話任務流程
這里的 text 模板是由“引導詞+歷史記錄+當前問題(提示)”三部分構成:
· 引導詞:描述當前的任務,引導模型做出合適的反饋
· 歷史記錄:記錄聊天的歷史數據,包含每一組問題和答案
· 當前問題:類似問答模式中的問題
我們采用 streamlit 框架構建構建聊天機器人的 web UI 和后臺處理邏輯,同時希望該聊天機器人可以做到實時交互,實時交互意味著我們不希望聊天機器人在生成完整的文本后再將其輸出在可視化界面中,因為這個需要用戶等待比較長的時間來獲取結果,我們希望在用戶在使用過程中可以逐步看到模型所預測的每一個詞,并依次呈現。因此我們需要創建一個可以被迭代的方法 generate_iterate,可以依次獲取模型迭代過程中每一次的預測結果,并將其依次添加到最終答案中,并逐步呈現。
當完成任務構建后,我們可以通過 streamlit run chat_robot.py 命令啟動聊天機器,并訪問本地地址進行測試。這里選擇了幾個常用配置參數,方便開發者根據機器人的回答準確性進行調整:
· 系統提示詞:用于引導模型的任務方向
**· max_tokens: **生成句子的最大長度。
· top-k:從置信度對最高的k個答案中隨機進行挑選,值越高生成答案的隨機性也越高。
**· top-p: **從概率加起來為 p 的答案中隨機進行挑選, 值越高生成答案的隨機性也越高,一般情況下,top-p 會在 top-k 之后使用。
· Temperature:從生成模型中抽樣包含隨機性, 高溫意味著更多的隨機性,這可以幫助模型給出更有創意的輸出。如果模型開始偏離主題或給出無意義的輸出,則表明溫度過高。
注3:由于 ChatGLM2-6B 模型比較大,首次硬件加載和編譯的時間會相對比較久
OpenVINO?
總結
作為當前最熱門的雙語大語言模型之一,ChatGLM2 憑借在各大基準測試中出色的成績,以及支持微調等特性被越來越多開發者所認可和使用。利用 OpenVINO? 構建 ChatGLM2 系列任務可以進一步提升其模型在英特爾平臺上的性能,并降低部署門檻。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3601瀏覽量
134201 -
向量機
+關注
關注
0文章
166瀏覽量
20856 -
cache技術
+關注
關注
0文章
41瀏覽量
1048 -
pytorch
+關注
關注
2文章
803瀏覽量
13152 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507
原文標題:基于 ChatGLM2 和 OpenVINO? 打造中文聊天助手 | 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CoolPi CM5運行ChatGLM-MNN大語言模型
Coolpi CM5運行ChatGLM-MNN大語言模型
使用OpenVINO trade 2021版運行Face_recognition_demo時報錯怎么解決?

云百件客服聊天助手-Windows版特性-云百件

清華系千億基座對話模型ChatGLM開啟內測
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜單位列榜首

單樣本微調給ChatGLM2注入知識
一個簡單模型就讓ChatGLM性能大幅提升 | 最“in”大模型
探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商業落地

“行空板+大模型”——基于ChatGLM的多角色交互式聊天機器人
chatglm2-6b在P40上做LORA微調





 工商網監
工商網監
評論