 阿里云開源視覺語言大模型Qwen-VL ,支持圖文雙模態輸入
阿里云開源視覺語言大模型Qwen-VL ,支持圖文雙模態輸入
繼 8 月初阿里云開源通義千問 70 億參數通用模型 Qwen-7B 和對話模型 Qwen-7B-Chat 后,又一大模型實現了開源。 阿里云開源通義千問多模態大模型 Qwen-VL
InfoQ 獲悉,8 月 25 日,阿里云開源通義千問多模態大模型 Qwen-VL。這是繼 8 月初阿里云開源通義千問 70 億參數通用模型 Qwen-7B 和對話模型 Qwen-7B-Chat 后,又開源的一大模型。
據介紹,Qwen-VL 是支持中英文等多種語言的視覺語言(Vision Language,VL)模型。相較于此前的 VL 模型,Qwen-VL 除了具備基本的圖文識別、描述、問答及對話能力之外,還新增了視覺定位、圖像中文字理解等能力。
具體來說,Qwen-VL 可以以圖像、文本、檢測框作為輸入,并以文本和檢測框作為輸出,可用于知識問答、圖像標題生成、圖像問答、文檔問答、細粒度視覺定位等多種場景。比如,一位不懂中文的外國游客到醫院看病,不知道怎么去往對應科室,他拍下樓層導覽圖問 Qwen-VL“骨科在哪層”“耳鼻喉科去哪層”,Qwen-VL 會根據圖片信息給出文字回復。

此外,Qwen-VL 還是業界首個支持中文開放域定位的通用模型,可以通過中文開放域語言表達進行檢測框標注。開放域視覺定位能力決定了大模型“視力”的精準度,這意味著具備該能力的大模型能在畫面中精準地找出想找的事物。比如,輸入一張上海外灘的照片,讓 Qwen-VL 找出東方明珠,Qwen-VL 能用檢測框準確圈出對應建筑。

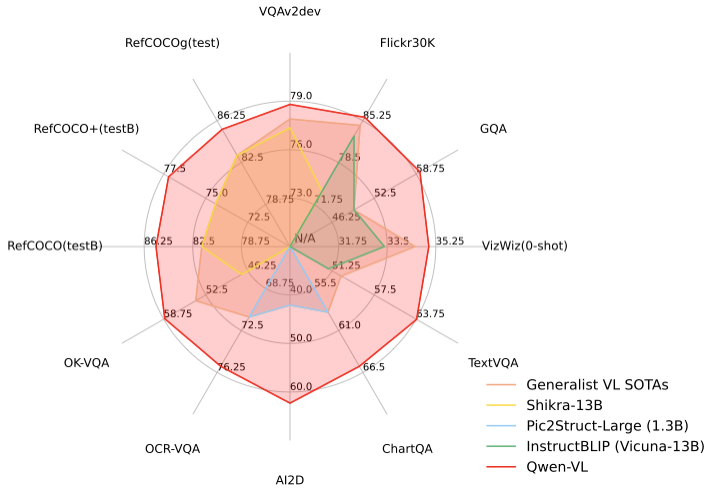
據了解,Qwen-VL 以 Qwen-7B 為基座語言模型研發,在模型架構上引入視覺編碼器,使得模型支持視覺信號輸入,并通過設計訓練過程,讓模型具備對視覺信號的細粒度感知和理解能力。更高分辨率可以提升細粒度的文字識別、文檔問答和檢測框標注,相比于目前其它開源 LVLM 使用的 224 分辨率,Qwen-VL 是首個開源的 448 分辨率的 LVLM 模型。
阿里云通義千問團隊算法專家、Qwen-VL 開源模型負責人白金澤在接受 InfoQ 采訪時表示,Qwen-VL 模型的訓練分為三個階段:
在預訓練階段,團隊主要利用大規模、弱標注的圖像 - 文本樣本對進行訓練;
在多任務訓練階段,團隊整理了大量高質量多任務的細粒度圖文標注數據進行混合訓練,并升高了圖像的輸入分辨率,降低圖像縮放引起的信息損失,增強模型對圖像細節的感知能力,得到 Qwen-VL 預訓練模型;
在指令微調階段,團隊使用合成標注的對話數據進行指令微調,激發模型的指令跟隨和對話能力,得到具有交互能力的 Qwen-VL-Chat 對話模型。
白金澤表示,Qwen-VL 模型的研發難點主要體現在數據、訓練、框架三個層面。“數據方面,多模態的數據整理和清洗是個難點,有效的數據清洗可以提高訓練效率以及提升最終收斂后的效果。訓練方面,在多模態大模型的訓練中,一般認為大 batch 和較大學習率可以提升訓練收斂效率和最終結果,但其訓練過程可能更加不穩定。我們通過一些訓練技巧有效提升了訓練穩定性,具體細節將在相關論文中公布。框架方面,目前多模態大模型的并行訓練框架支持并不完善,我們對多模態大模型的 3D 并行技術進行了優化,可穩定訓練更大規模的多模態模型。”
除了 Qwen-VL,本次阿里云還開源了 Qwen-VL-Chat。Qwen-VL-Chat 是在 Qwen-VL 的基礎上,使用對齊機制打造的基于大語言模型的視覺 AI 助手,可讓開發者快速搭建具備多模態能力的對話應用。
白金澤補充說,團隊主要通過兩類方式評估了多模態大模型的效果。其一是使用標準基準數據集來評測每個多模態子任務的效果。例如評測圖片描述(Image Captioning)、圖片問答(Visual Question Answering, VQA)、文檔問答(Document VQA)、圖表問答(Chart VQA)、少樣本問答(Few-shot VQA)、參照物標注(Referring Expression Comprehension)等。其二是使用人工或借助 GPT-4 打分來評測多模態大模型的整體對話能力和對齊水平。通義千問團隊構建了一套基于 GPT-4 打分機制的基準“試金石”( TouchStone),總計涵蓋 300+ 張圖片、800+ 道題目、27 個題目類別。
在四大類多模態任務(Zero-shot Caption/VQA/DocVQA/Grounding)的標準英文測評中,Qwen-VL 取得了同等尺寸開源 LVLM 的最好效果。為了測試模型的多模態對話能力,通義千問團隊構建了一套基于 GPT-4 打分機制的測試集“試金石”,對 Qwen-VL-Chat 及其他模型進行對比測試,Qwen-VL-Chat 在中英文的對齊評測中均取得了開源 LVLM 最好結果。
目前,Qwen-VL 及其視覺 AI 助手 Qwen-VL-Chat 均已上線 ModelScope 魔搭社區,開源、免費、可商用。用戶可從魔搭社區直接下載模型,也可通過阿里云靈積平臺訪問調用 Qwen-VL 和 Qwen-VL-Chat,阿里云為用戶提供包括模型訓練、推理、部署、精調等在內的全方位服務。
大模型發展的下一站:多模態大模型
多模態大模型是指能夠理解文字、圖像、視頻、音頻等多種模態信息的大模型,與僅能理解單一文本模態的語言模型相比,多模態大模型的優勢就在于可以充分利用語言模型的指令理解能力,來做圖像、語音、視頻等各種模態中的開放域任務,從而具備處理不同模態信息的通用能力。而單一模態大模型的任務形式通常都是預先定義好的,比如圖像 / 視頻 / 語音分類任務,需要提前知道這些類別,然后針對性的找訓練數據去訓練模型。
有觀點認為,多模態是預訓練大模型最重要的技術演進方向之一。
業界普遍認為,從單一感官的、僅支持文本輸入的語言模型,到“五官全開”的,支持文本、圖像、音頻等多種信息輸入的多模態模型,蘊含著大模型智能躍升的巨大可能。多模態能夠提升大模型對世界的理解程度,充分拓展大模型的使用場景。比如,以 GPT-4、PaLM-E 為代表的一批模型,通過賦予大語言模型感知、理解視覺信號的能力,展現出大規模視覺語言模型在解決以視覺為中心的實際問題的前景,并顯示出進一步拓展到具身智能、通向通用人工智能的廣闊前景。
其中,視覺作為人類的第一感官能力,也是研究者首先希望賦予大模型的多模態能力。因此,繼此前推出 M6、OFA 系列多模態模型之后,阿里云通義千問團隊又開源了基于 Qwen-7B 的大規模視覺語言模型 Qwen-VL。
不過,多模態大模型的開發并非易事,白金澤表示,多模態大模型的開發難度包括但不限于以下幾點:
模態間表征差異大:大規模純語言模型的輸入輸出一般是離散表征,而圖像、語音等內容通常是連續表征,其模態間的信息密度、表征空間、輸入輸出方式等都存在巨大差異,這導致了設計的復雜性。
多模態大模型收斂不穩定:由于模態間表征差異大、各模態網絡異構等因素,相比純文本大模型,多模態大模型的訓練具有更多的挑戰,更有可能出現訓練不穩定的情況。
缺乏穩定開源框架支持:目前常見的開源大模型訓練框架,都只對純語言模型的訓練效率進行了極致的優化。為了處理多模態輸入輸出,多模態模型通常有非對稱的網絡結構,導致無法直接用常見開源訓練框架擴展到超大參數量。通義千問團隊對多模態的并行訓練框架進行了多重優化,可穩定訓練更大規模的多模態模型。
“多模態是我們很看好的技術方向,這個領域還有很多技術難題有待解決,未來我們也會持續研究。就 Qwen-VL 來說,接下來的工作包括支持更高分辨率的圖像輸入,無監督地從圖像中學習更多的世界知識,擴展更多模態,加深對多模態數據的理解,等等。”白金澤說道。
-
語言模型
+關注
關注
0文章
487瀏覽量
10201 -
阿里云
+關注
關注
3文章
922瀏覽量
42780 -
大模型
+關注
關注
2文章
2136瀏覽量
1980
原文標題:通義千問能看圖了!阿里云開源視覺語言大模型Qwen-VL ,支持圖文雙模態輸入
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
阿里Qwen2-Math系列震撼發布,數學推理能力領跑全球

阿里云設備的物模型數據里面始終沒有值是為什么?
Qwen2強勢來襲,AIBOX支持本地化部署

阿里通義千問Qwen2大模型發布并同步開源
阿里通義千問Qwen2大模型發布
智譜AI發布全新多模態開源模型GLM-4-9B
阿里云通義大模型助力“小愛同學”強化多模態AI生成能力
聯發科天璣9300搭載通義千問大模型,阿里云提供解決方案
字節發布機器人領域首個開源視覺-語言操作大模型,激發開源VLMs更大潛能


阿里云發布AI大模型,谷歌地熱項目助力綠色能源轉型

用語言對齊多模態信息,北大騰訊等提出LanguageBind,刷新多個榜單






 工商網監
工商網監
評論