 Kubernetes集群中如何選擇工作節點
Kubernetes集群中如何選擇工作節點
簡要概述:本文討論了在Kubernetes集群中選擇較少數量的較大節點和選擇較多數量的較小節點之間的利弊。
當創建一個Kubernetes集群時,最初的問題之一是:“我應該使用什么類型的工作節點,以及需要多少個?”
如果正在構建一個本地集群,是應該采購一些上一代的高性能服務器,還是利用數據中心中閑置的幾臺老舊機器呢?
或者,如果正在使用像Google Kubernetes Engine(GKE)這樣的托管式Kubernetes服務,是應該選擇八個n1-standard-1實例還是兩個n1-standard-4實例來實現所需的計算能力呢?
目錄
集群容量
Kubernetes工作節點中的預留資源
工作節點中的資源分配和效率
彈性和復制
擴展增量和前導時間
拉取容器鏡像
Kubelet和擴展Kubernetes API
節點和集群限制
存儲
總結和結論
集群容量
一般來說,Kubernetes集群可以被看作是將一組獨立的節點抽象為一個大的“超級節點”。
這個超級節點的總計算能力(包括CPU和內存)是所有組成節點的能力之和。
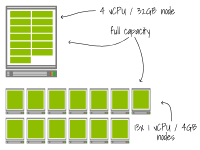
有多種實現這一目標的方法。例如,假設您需要一個總計算能力為8個CPU核心和32GB內存的集群。以下是兩種可能的集群設計方式:
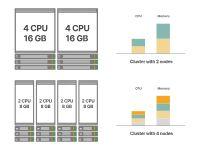
Kubernetes集群中的小型節點與大型節點
這兩種選擇都會得到相同容量的集群。
左邊的選擇使用了四個較小的節點,而右邊的選擇使用了兩個較大的節點。
問題是:哪種方法更好呢?
為了做出明智的決策,讓我們深入了解如何在工作節點中分配資源。
Kubernetes工作節點中的預留資源
Kubernetes集群中的每個工作節點都是一個運行kubelet(Kubernetes代理)的計算單元。
kubelet是一個連接到控制平面的二進制文件,用于將節點的當前狀態與集群的狀態同步。
例如,當Kubernetes調度程序將一個Pod分配給特定節點時,它不會直接向kubelet發送消息。相反,它會創建一個Binding對象并將其存儲在etcd中。
kubelet定期檢查集群的狀態。一旦它注意到將一個新分配的Pod分配給其節點,它就會開始下載Pod的規范并創建它。
通常將kubelet部署為SystemD服務,并作為操作系統的一部分運行。
kubelet、SystemD和操作系統需要資源,包括CPU和內存,以確保正確運行。
因此,并不是所有工作節點的資源都僅用于運行Pod。
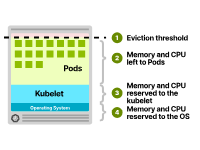
CPU和內存資源通常分配如下:
操作系統。Kubelet。Pods。驅逐閾值。
Kubernetes節點中的資源分配
您可能想知道這些組件分配了哪些資源。雖然具體配置可能會有所不同,但CPU分配通常遵循以下模式:
第一個核心的6%。后續核心的1%(最多2個核心)。接下來的兩個核心的0.5%(最多4個核心)。四個核心以上的任何核心的0.25%。內存分配可能如下:
小于1GB內存的機器分配255 MiB內存。前4GB內存的25%。接下來的4GB內存的20%(最多8GB)。接下來的8GB內存的10%(最多16GB)。接下來的112GB內存的6%(最多128GB)。超過128GB的任何內存的2%。最后,驅逐閾值通常保持在100MB。
驅逐閾值 驅逐閾值代表內存使用的閾值。如果一個節點超過了這個閾值,kubelet將開始驅逐Pod,因為當前節點的內存不足。
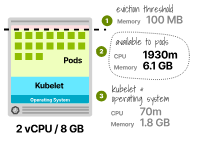
考慮一個具有8GB內存和2個虛擬CPU的實例。資源分配如下:
70毫核虛擬CPU和1.8GB供kubelet和操作系統使用(通常一起打包)。保留100MB用于驅逐閾值。剩余的6.1GB內存和1930毫核可以分配給Pod。只有總內存的75%用于執行工作負載。
但這還不止于此。
您的節點可能需要在每個節點上運行一些Pod(例如DaemonSets)以確保正確運行,而這些Pod也會消耗內存和CPU資源。
例如,Kube-proxy、諸如Fluentd或Fluent Bit的日志代理、NodeLocal DNSCache或CSI驅動程序等。
這是一個固定的成本,無論節點大小如何,您都必須支付。
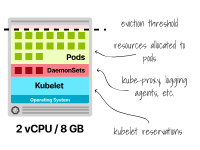
帶有DaemonSets的Kubernetes節點中的資源分配 考慮到這一點,讓我們來看一下"較少數量的較大節點"和"較多數量的較小節點"這兩種截然相反的方法的利弊。
請注意,本文中的"節點"始終指的是工作節點。關于控制平面節點的數量和大小的選擇是一個完全不同的主題。
工作節點中的資源分配和效率
隨著更大實例的使用,kubelet預留的資源會減少。
讓我們來看兩種極端情況。
您想要為一個請求0.3個vCPU和2GB內存的應用部署七個副本。
在第一種情況下,您將為一個單獨的工作節點提供資源以部署所有副本。在第二種情況下,您在每個節點上部署一個副本。為簡單起見,我們假設這些節點上沒有運行任何DaemonSets。
七個副本所需的總資源為2.1個vCPU和14GB內存(即7 x 300m = 2.1個vCPU和7 x 2GB = 14GB)。
一個4個vCPU和16GB內存的實例能夠運行這些工作負載嗎?
我們來計算一下CPU的預留:
第一個核心的6%=60m+ 第二個核心的1%=10m+ 剩余核心的0.5%=10m 總計=80m
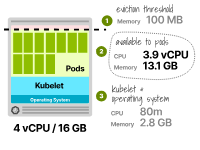
用于運行Pod的可用CPU為3.9個vCPU(即4000m - 80m)——綽綽有余。
接下來,我們來看一下kubelet預留的內存:
前4GB內存的25%=1GB 接下來的4GB內存的20%=0.8GB 接下來的8GB內存的10%=0.8GB 總計=2.8GB
分配給Pod的總內存為16GB -(2.8GB + 0.1GB)——這里的0.1GB考慮到了100MB的驅逐閾值。
最后,Pod可以使用最多13.1GB的內存。
帶有2個vCPU和16GB內存的Kubernetes節點中的資源分配
不幸的是,這還不夠(即7個副本需要14GB的內存,但您只有13.1GB),您應該為部署這些工作負載提供更多內存的計算單元。
如果使用云提供商,下一個可用的增量計算單元是4個vCPU和32GB內存。
帶有2個vCPU和16GB內存的節點不足以運行七個副本
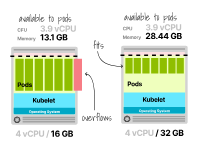 太好了!
太好了!
接下來,讓我們看一下另一種情況,即我們嘗試找到適合一個副本的最小實例,該副本的請求為0.3個vCPU和2GB內存。
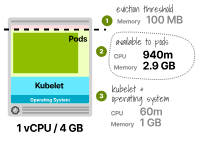
我們嘗試使用具有1個vCPU和4GB內存的實例類型。
預留的CPU總共為6%或60m,可用于Pod的CPU為940m。
由于該應用僅需要300m的CPU,這足夠了。
kubelet預留的內存為25%或1GB,再加上額外的0.1GB的驅逐閾值。
Pod可用的總內存為2.9GB;由于該應用僅需要2GB,這個值足夠了。
太棒了!
帶有2個vCPU和16GB內存的Kubernetes節點中的資源分配 現在,讓我們比較這兩種設置。
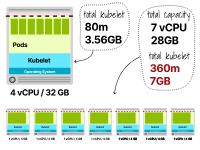
第一個集群的總資源只是一個單一節點 — 4個vCPU和32GB。
第二個集群有七個實例,每個實例都有1個vCPU和4GB內存(總共為7個vCPU和28GB內存)。
在第一個示例中,為Kubernetes預留了2.9GB的內存和80m的CPU。
而在第二個示例中,預留了7.7GB(1.1GB x 7個實例)的內存和360m(60m x 7個實例)的CPU。
您已經可以注意到,在配置較大的節點時,資源的利用效率更高。
在單一節點集群和多節點集群之間比較資源分配情況
但還有更多。
較大的實例仍然有空間來運行更多的副本 — 但有多少個呢?
預留的內存為3.66GB(3.56GB的kubelet + 0.1GB的驅逐閾值),可用于Pod的總內存為28.44GB。預留的CPU仍然是80m,Pods可以使用3920m。此時,您可以通過以下方式找到內存和CPU的最大副本數:
TotalCPU3920/ PodCPU300 ------------------ MaxPod13.1
您可以為內存重復進行計算:
總內存28.44/ Pod內存2 最大Pod14.22
以上數字表明,內存不足可能會在CPU之前用盡,而在4個vCPU和32GB工作節點中最多可以托管13個Pod。
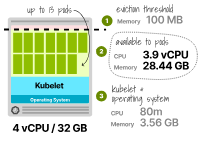
為2個vCPU和32GB工作節點計算Pod容量 那么第二種情況呢?
是否還有空間進行擴展?
實際上并沒有。
雖然這些實例仍然具有更多的CPU,但在部署第一個Pod后,它們只有0.9GB的可用內存。
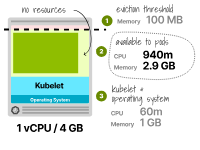
為1個vCPU和4GB工作節點計算Pod容量 總之,不僅較大的節點能更好地利用資源,而且還可以最小化資源的碎片化并提高效率。
這是否意味著您應該始終提供較大的實例?
讓我們來看另一個極端情況:節點意外丟失時會發生什么?
彈性和復制
較少數量的節點可能會限制您的應用程序的有效復制程度。
例如,如果您有一個由5個副本組成的高可用應用程序,但只有兩個節點,那么有效的復制程度將降低為2。
這是因為這五個副本只能分布在兩個節點上,如果其中一個節點失敗,可能會一次性失去多個副本。
具有兩個節點和五個副本的集群的復制因子為兩個

另一方面,如果您至少有五個節點,每個副本都可以在一個單獨的節點上運行,而單個節點的故障最多會導致一個副本失效。
因此,如果您有高可用性要求,您可能需要在集群中擁有一定數量的節點。
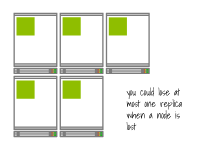
具有五個節點和五個副本的集群的復制因子為五 您還應該考慮節點的大小。
當較大的節點丟失時,一些副本最終會被重新調度到其他節點。
如果節點較小,僅托管了少量工作負載,則調度器只會重新分配少數Pod。
雖然您不太可能在調度器中遇到任何限制,但重新部署許多副本可能會觸發集群自動縮放器。
并且根據您的設置,這可能會導致進一步的減速。
讓我們來探討一下原因。
擴展增量和前導時間
您可以使用水平擴展器(即增加副本數量)和集群自動縮放器(即增加節點計數)的組合來擴展部署在Kubernetes上的應用程序。
假設您的集群達到總容量,節點大小如何影響自動縮放?
首先,您應該知道,當集群自動縮放器觸發自動縮放時,它不會考慮內存或可用的CPU。
換句話說,總體上使用的集群不會觸發集群自動縮放器。
相反,當一個Pod因資源不足而無法調度時,集群自動縮放器會創建更多的節點。
此時,自動縮放器會調用云提供商的API,為該集群提供更多的節點。
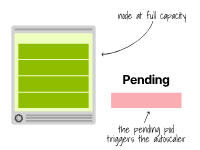
集群自動縮放器在Pod由于資源不足而處于掛起狀態時提供新的節點。
集群自動縮放器在Pod由于資源不足而處于掛起狀態時提供新的節點。

不幸的是,通常情況下,配置節點是比較緩慢的。
要創建一個新的虛擬機可能需要幾分鐘的時間。
提供較大或較小實例的配置時間是否會改變?
不,通常情況下,無論實例的大小如何,配置時間都是恒定的。
此外,集群自動縮放器不限于一次添加一個節點;它可能會一次添加多個節點。
我們來看一個例子。
有兩個集群:
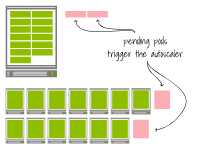
第一個集群有一個4個vCPU和32GB的單一節點。第二個集群有13個1個vCPU和4GB的節點。一個具有0.3個vCPU和2GB內存的應用程序部署在集群中,并擴展到13個副本。
這兩種設置都已達到總容量
當部署擴展到15個副本時會發生什么(即增加兩個副本)?
在兩個集群中,集群自動縮放器會檢測到由于資源不足,額外的Pod無法調度,并進行如下配置:
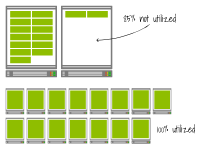
對于第一個集群,增加一個具有4個vCPU和32GB內存的額外節點。對于第二個集群,增加兩個具有1個vCPU和4GB內存的節點。由于在為大型實例或小型實例提供資源時沒有時間差異,這兩種情況下節點將同時可用。
然而,你能看出另一個區別嗎?
第一個集群還有空間可以容納11個額外的Pod,因為總容量是13個。
而相反,第二個集群仍然達到了最大容量。
你可以認為較小的增量更加高效和更便宜,因為你只添加所需的部分。
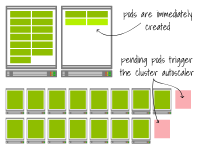
 但是讓我們觀察一下當您再次擴展部署時會發生什么——這次擴展到17個副本(即增加兩個副本)。
但是讓我們觀察一下當您再次擴展部署時會發生什么——這次擴展到17個副本(即增加兩個副本)。
第一個集群在現有節點上創建了兩個額外的Pod。而第二個集群已經達到了容量上限。Pod處于待定狀態,觸發了集群自動縮放器。最終,又會多出兩個工作節點。
在第一個集群中,擴展幾乎是瞬間完成的。
而在第二個集群中,您必須等待節點被配置完畢,然后才能讓Pod開始提供服務。
換句話說,在前者的情況下,擴展速度更快,而在后者的情況下,需要更多的時間。
通常情況下,由于配置時間在幾分鐘范圍內,您應該謹慎考慮何時觸發集群自動縮放器,以避免產生更長的Pod等待時間。
換句話說,如果您能夠接受(潛在地)沒有充分利用資源的情況,那么通過使用較大的節點,您可以實現更快的擴展。
但事情并不止于此。
拉取容器鏡像也會影響您能夠多快地擴展工作負載,這與集群中的節點數量有關。
拉取容器鏡像
在Kubernetes中創建Pod時,其定義存儲在etcd中。
kubelet的工作是檢測到Pod分配給了它的節點并創建它。
kubelet將會:
從控制平面下載定義。
調用容器運行時接口(CRI)來創建Pod的沙箱。CRI會調用容器網絡接口(CNI)來將Pod連接到網絡。
調用容器存儲接口(CSI)來掛載任何容器卷。
在這些步驟結束時,Pod就已經存在了,kubelet可以繼續檢查活躍性和就緒性探針,并更新控制平面以反映新Pod的狀態。
kubelet與CRI、CSI和CNI接口需要注意的是,當CRI在Pod中創建容器時,它必須首先下載容器鏡像。
這當然是在當前節點上的容器鏡像沒有緩存的情況下。
讓我們來看一下這如何影響以下兩個集群的擴展:
第一個集群有一個4個vCPU和32GB的單一節點。第二個集群有13個1個vCPU和4GB的節點。讓我們部署一個使用基于OpenJDK的容器鏡像的應用程序,該應用程序使用0.3個vCPU和2GB內存,容器鏡像大小為1GB(僅基礎鏡像大小為775MB)的13個副本。
對這兩個集群會發生什么?
在第一個集群中,容器運行時只下載一次鏡像并運行13個副本。在第二個集群中,每個容器運行時都會下載并運行鏡像。在第一個方案中,只需要下載1GB的鏡像。
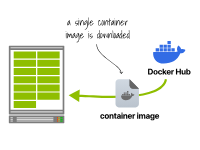
容器運行時下載一次容器鏡像并運行13個副本 然而,在第二個方案中,您需要下載13GB的容器鏡像。
由于下載需要時間,第二個集群在創建副本方面比第一個集群要慢。
此外,它會使用更多的帶寬并發起更多的請求(即至少每個鏡像層一個請求,共計13次),這使得它更容易受到網絡故障的影響。
13個容器運行時中的每一個都會下載一個鏡像 需要注意的是,這個問題會與集群自動縮放器緊密關聯。
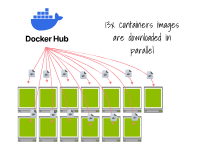
如果您的節點較小:
集群自動縮放器會同時配置多個節點。
一旦準備好,每個節點都開始下載容器鏡像。
最終,Pod被創建。
當您配置較大的節點時,容器鏡像很可能已經在節點上緩存,Pod可以立即開始運行。
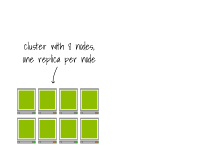 想象一下擁有8個節點的集群,每個節點上有一個副本。
想象一下擁有8個節點的集群,每個節點上有一個副本。
最終,Pod會被創建在節點上。
想象一下擁有8個節點的集群,每個節點上有一個副本。
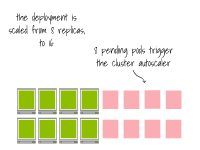
該集群已經滿載;將副本擴展到16個會觸發集群自動縮放器。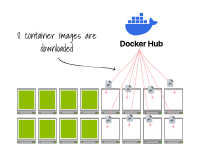
一旦節點被配置完畢,容器運行時會下載容器鏡像。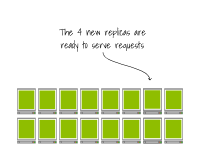 最終,Pod會在節點上創建。
最終,Pod會在節點上創建。
所以,您是否應該始終配置較大的節點?
未必如此。
您可以通過容器注冊表代理來減輕節點下載相同容器鏡像的情況。
在這種情況下,鏡像仍然會被下載,但是從當前網絡中的本地注冊表中下載。
或者您可以使用諸如spegel之類的工具來預熱節點的緩存。
使用Spegel,節點是可以廣告和共享容器鏡像層的對等體。
在這種情況下,容器鏡像將從其他工作節點下載,Pod幾乎可以立即啟動。
但是,容器帶寬并不是您必須控制的唯一帶寬。
Kubelet與Kubernetes API的擴展
kubelet被設計為從控制平面中獲取信息。
因此,在規定的間隔內,kubelet會向Kubernetes API發出請求,以檢查集群的狀態。
但是控制平面不是會向kubelet發送指令嗎?
拉取模型更容易擴展,因為:
控制平面不需要將消息推送到每個工作節點。
節點可以以自己的速度獨立地查詢API服務器。
控制平面不需要保持與kubelet的連接打開。
請注意,也有顯著的例外情況。例如,諸如kubectl logs和kubectl exec之類的命令需要控制平面連接到kubelet(即推送模型)。
但是Kubelet不僅僅是為了查詢信息。
它還向主節點報告信息。
例如,kubelet每十秒向集群報告一次節點的狀態。
此外,當準備探針失敗時(以及應從服務中刪除pod端點),kubelet會通知控制平面。
而且kubelet會通過容器指標將控制平面保持更新。
換句話說,kubelet會通過從控制平面發出請求(即從控制平面和向控制平面)來保持節點正常運行所需的狀態。
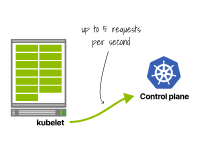
在Kubernetes 1.26及更早版本中,kubelet每秒可以發出多達5個請求(在Kubernetes >1.27中已放寬此限制)。
所以,假設您的kubelet正以最大容量運行(即每秒5個請求),當您運行幾個較小的節點與一個單一的大節點時會發生什么?
讓我們看看我們的兩個集群:
第一個集群有一個4個vCPU和32GB的單一節點。
第二個集群有13個1個vCPU和4GB的節點。
第一個集群生成5個每秒的請求。
一個kubelet每秒發出5個請求
第二個集群每秒發出65個請求(即13 x 5)。
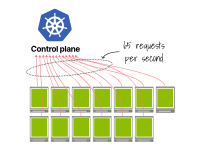
13個kubelet每秒各自發出5個請求
當您運行具有許多較小節點的集群時,您應該將API服務器的擴展性擴展到處理更頻繁的請求。
而反過來,這通常意味著在較大的實例上運行控制平面或運行多個控制平面。
節點和集群限制
Kubernetes集群的節點數量是否有限制?
Kubernetes被設計為支持多達5000個節點。
然而,這并不是一個嚴格的限制,正如Google團隊所演示的,允許您在15,000個節點上運行GKE集群。
對于大多數用例來說,5000個節點已經是一個很大的數量,可能不會是影響您決定選擇較大還是較小節點的因素。
相反,您可以運行在節點中運行的最大Pod數可能會引導您重新思考集群架構。
那么,在Kubernetes節點中,您可以運行多少個Pod?
大多數云提供商允許您在每個節點上運行110到250個Pod。
如果您自己配置集群,則默認為110。
在大多數情況下,這個數字不是kubelet的限制,而是云提供商對重復預定IP地址的風險的容忍度。
為了理解這是什么意思,讓我們退后一步,看看集群網絡是如何構建的。
在大多數情況下,每個工作節點都被分配一個具有256個地址的子網(例如10.0.1.0/24)。
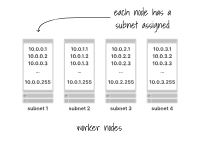
每個工作節點都被分配一個子網
其中兩個是受限制的,您可以使用254來運行您的Pods。
考慮這種情況,其中在同一個節點上有254個Pod。
您創建了一個更多的Pod,但已經耗盡了可用的IP地址,它保持在掛起狀態。
為了解決這個問題,您決定將副本數減少到253。
那么掛起的Pod會在集群中被創建嗎?
可能不會。
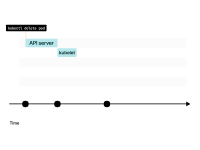
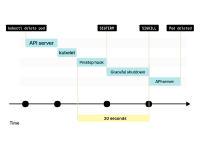
當您刪除Pod時,其狀態會變為“正在終止”。
kubelet向Pod發送SIGTERM信號(以及調用preStop生命周期鉤子(如果存在)),并等待容器優雅地關閉。
如果容器在30秒內沒有終止,kubelet將發送SIGKILL信號到容器,并強制進程終止。
在此期間,Pod仍未釋放IP地址,流量仍然可以到達它。
當Pod最終被刪除時,IP地址被釋放。
kubelet通知控制平面Pod已成功刪除。IP地址終于被釋放。
想象一下您的節點正在使用所有可用的IP地址。
當一個Pod被刪除時,kubelet會收到變更通知。
如果Pod有一個preStop鉤子,首先會調用它。然后,kubelet會向容器發送SIGTERM信號。
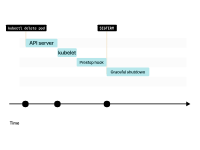
默認情況下,進程有30秒的時間來退出,包括preStop鉤子。如果在這之前進程沒有退出,kubelet會發送SIGKILL信號,強制終止進程。
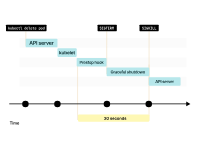
kubelet會通知控制平面Pod已成功刪除。IP地址最終被釋放。
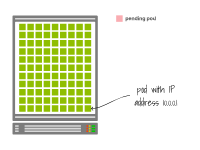
當一個Pod被刪除時,IP地址不會立即釋放。您必須等待優雅的關閉。
這是一個好主意嗎?
好吧,沒有其他可用的IP地址 - 所以您沒有選擇。
想象一下,您的節點正在使用所有可用的IP地址。
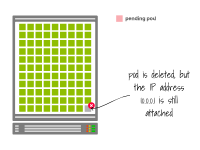
一旦Pod被刪除,IP地址就可以被重新使用。
kubelet通知控制平面Pod已成功刪除。IP地址終于被釋放。
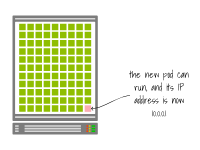
此時,掛起的Pod可以被創建,并且分配給它與上一個相同的IP地址。
想象一下,您的節點正在使用所有可用的IP地址。
下一頁
那后果會怎樣?
還記得我們提到過,Pod應該優雅地關閉并處理所有未處理的請求嗎?
嗯,如果Pod被突然終止(即沒有優雅的關閉),并且IP地址立即分配給另一個Pod,那么所有現有的應用程序和Kubernetes組件可能仍然不知道這個更改。
入口控制器將流量路由到一個IP地址。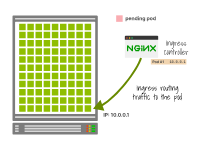
如果IP地址在沒有等待優雅關閉的情況下被回收并被一個新的Pod使用,入口控制器可能仍然會將流量路由到該IP地址。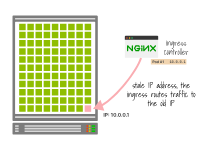
因此,一些現有的流量可能會錯誤地發送到新的Pod,因為它與舊的Pod具有相同的IP地址。
為了避免這個問題,您可以分配較少的IP地址(例如110)并使用剩余的IP地址作為緩沖區。
這樣,您可以相當肯定地確保不會立即重新使用相同的IP地址。
存儲
計算單元對可以附加的磁盤數量有限制。
例如,在Azure上,具有2個vCPU和8GB內存的Standard_D2_v5實例最多可以附加4個數據磁盤。
如果您希望將StatefulSet部署到使用Standard_D2_v5實例類型的工作節點上,您將無法創建超過四個副本。
這是因為StatefulSet中的每個副本都附加有一個磁盤。
一旦創建第五個副本,Pod將保持掛起狀態,因為無法將持久卷聲明綁定到持久卷。
為什么呢?
因為每個持久卷都是一個附加的磁盤,所以您在該實例中只能有4個。
那么,您有哪些選擇?
您可以提供一個更大的實例。
或者您可以使用不同的子路徑字段重新使用相同的磁盤。
讓我們看一個例子。
下面的持久卷需要一個具有16GB空間的磁盤:
如果您將此資源提交到集群,您將看到創建了一個持久卷并綁定到它。
$kubectlgetpv,pvc
持久卷與持久卷聲明之間存在一對一的關系,因此您無法有更多的持久卷聲明來使用相同的磁盤。
apiVersion:apps/v1 kind:Deployment metadata: name:app1 spec: selector: matchLabels: name:app1 template: metadata: labels: name:app1 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
如果您想在您的Pod中使用該聲明,可以這樣做:
apiVersion:apps/v1 kind:Deployment metadata: name:app2 spec: selector: matchLabels: name:app2 template: metadata: labels: name:app2 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
您可以有另一個使用相同持久卷聲明的部署:
但是,通過這種配置,兩個Pod將在同一個文件夾中寫入其數據。
您可以通過在subPath中使用子目錄來解決此問題。
apiVersion:apps/v1 kind:Deployment metadata: name:app2 spec: selector: matchLabels: name:app2 template: metadata: labels: name:app2 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
subPath: app2
部署將在以下路徑上寫入其數據:
對于第一個部署,是/data/app1
對于第二個部署,是/data/app2
這個解決方法并不是完美的,有一些限制:
所有部署都必須記住使用subPath。如果需要寫入卷,您應該選擇可以從多個節點訪問的Read-Write-Many卷。這些通常需要昂貴的提供。此外,對于StatefulSet,相同的解決方法無法起作用,因為這將為每個副本創建全新的持久卷聲明(和持久卷)。
總結和結論
那么,在集群中是使用少量大節點還是許多小節點?
這取決于情況。
反正,什么是小的,什么是大的?
這取決于您在集群中部署的工作負載。
例如,如果您的應用程序需要10GB內存,那么運行一個具有16GB內存的實例等于“運行一個較小的節點”。
對于只需要64MB內存的應用程序來說,相同的實例可能被認為是“大的”,因為您可以容納多個這樣的實例。
那么,對于具有不同資源需求的混合工作負載呢?
在Kubernetes中,沒有規定所有節點必須具有相同的大小。
您完全可以在集群中使用不同大小的節點混合。
這可能讓您在這兩種方法的優缺點之間進行權衡。
-
cpu
+關注
關注
68文章
10829瀏覽量
211198 -
節點
+關注
關注
0文章
217瀏覽量
24386 -
服務器
+關注
關注
12文章
9029瀏覽量
85209 -
容器
+關注
關注
0文章
494瀏覽量
22046 -
kubernetes
+關注
關注
0文章
223瀏覽量
8698
原文標題:在 Kubernetes 集群中,如何正確選擇工作節點資源大小
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Kubernetes架構和核心組件組成 Kubernetes節點“容器運行時”技術分析
阿里云上Kubernetes集群聯邦
Kubernetes Ingress 高可靠部署最佳實踐
Kubernetes 從懵圈到熟練:集群服務的三個要點和一種實現
如何部署基于Mesos的Kubernetes集群
淺談Kubernetes集群的高可用方案

Kubernetes 集群的功能
Kubernetes集群的關閉與重啟
Kubernetes的集群部署
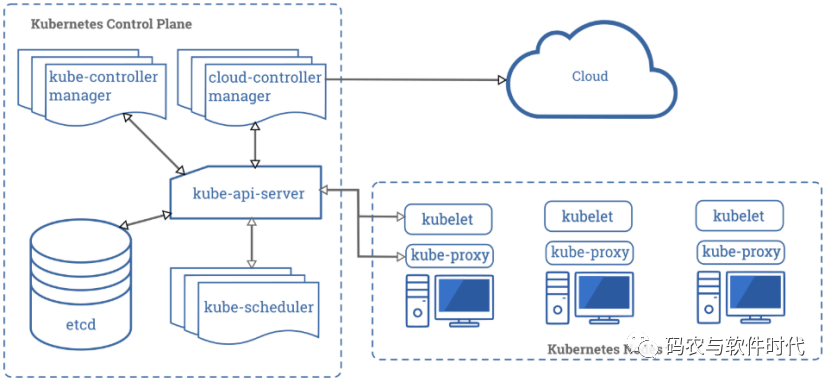
Kubernetes是怎樣工作的?
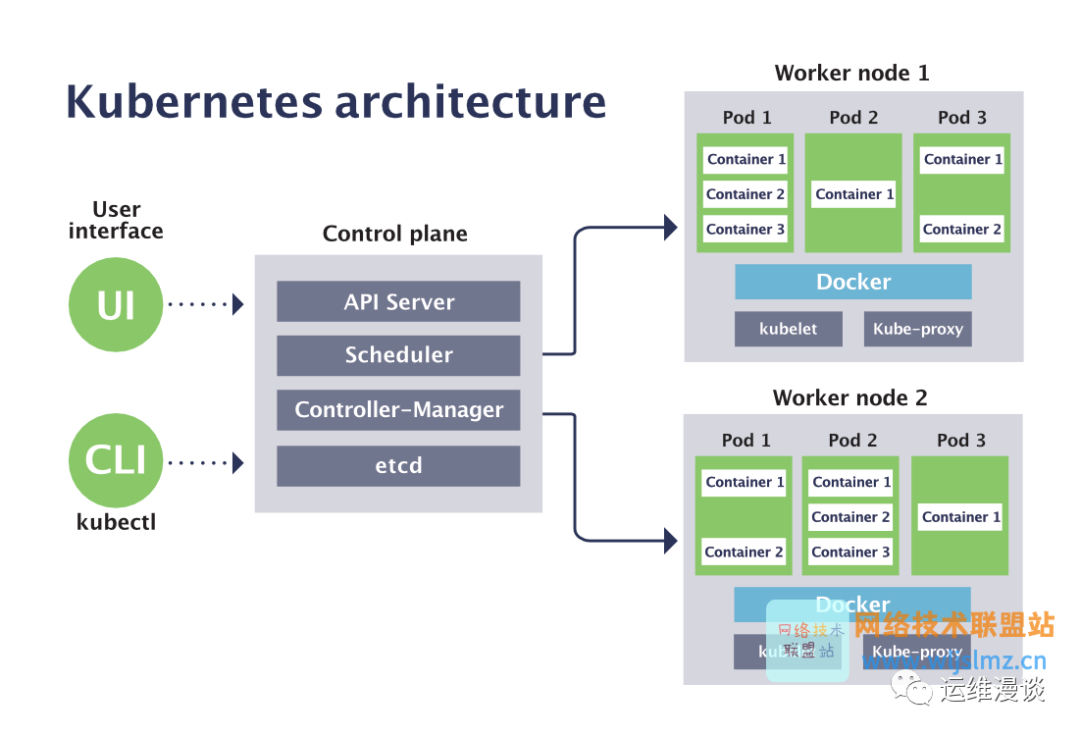
使用Velero備份Kubernetes集群





 工商網監
工商網監
評論