") DETR架構(gòu)的內(nèi)部工作方式分析
DETR架構(gòu)的內(nèi)部工作方式分析
這是一個(gè)Facebook的目標(biāo)檢測Transformer (DETR)的完整指南。
介紹
DEtection TRansformer (DETR)是Facebook研究團(tuán)隊(duì)巧妙地利用了Transformer 架構(gòu)開發(fā)的一個(gè)目標(biāo)檢測模型。在這篇文章中,我將通過分析DETR架構(gòu)的內(nèi)部工作方式來幫助提供一些關(guān)于它的直覺。
下面,我將解釋一些結(jié)構(gòu),但是如果你只是想了解如何使用模型,可以直接跳到代碼部分。
結(jié)構(gòu)
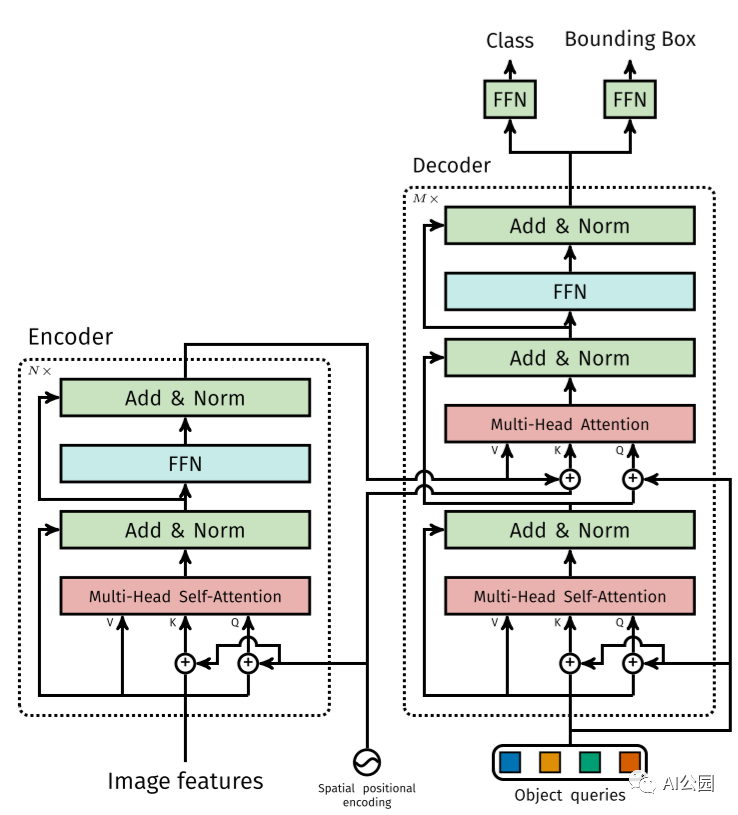
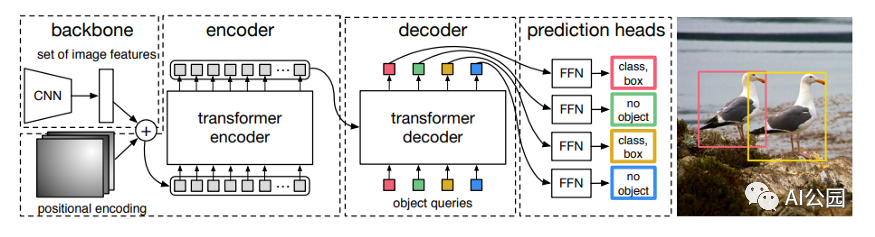
DETR模型由一個(gè)預(yù)訓(xùn)練的CNN骨干(如ResNet)組成,它產(chǎn)生一組低維特征集。這些特征被格式化為一個(gè)特征集合并添加位置編碼,輸入一個(gè)由Transformer組成的編碼器和解碼器中,和原始的Transformer論文中描述的Encoder-Decoder的使用方式非常的類似。解碼器的輸出然后被送入固定數(shù)量的預(yù)測頭,這些預(yù)測頭由預(yù)定義數(shù)量的前饋網(wǎng)絡(luò)組成。每個(gè)預(yù)測頭的輸出都包含一個(gè)類預(yù)測和一個(gè)預(yù)測框。損失是通過計(jì)算二分匹配損失來計(jì)算的。
該模型做出了預(yù)定義數(shù)量的預(yù)測,并且每個(gè)預(yù)測都是并行計(jì)算的。
CNN主干
假設(shè)我們的輸入圖像,有三個(gè)輸入通道。CNN backbone由一個(gè)(預(yù)訓(xùn)練過的)CNN(通常是ResNet)組成,我們用它來生成C個(gè)具有寬度W和高度H的低維特征(在實(shí)踐中,我們設(shè)置C=2048, W=W?/32和H=H?/32)。
這留給我們的是C個(gè)二維特征,由于我們將把這些特征傳遞給一個(gè)transformer,每個(gè)特征必須允許編碼器將每個(gè)特征處理為一個(gè)序列的方式重新格式化。這是通過將特征矩陣扁平化為H?W向量,然后將每個(gè)向量連接起來來實(shí)現(xiàn)的。
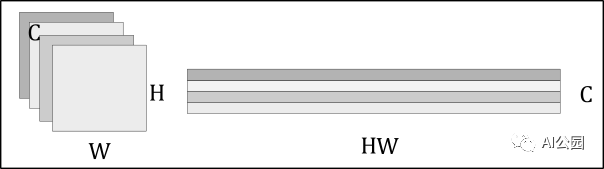
扁平化的卷積特征再加上空間位置編碼,位置編碼既可以學(xué)習(xí),也可以預(yù)定義。
The Transformer
Transformer幾乎與原始的編碼器-解碼器架構(gòu)完全相同。不同之處在于,每個(gè)解碼器層并行解碼N個(gè)(預(yù)定義的數(shù)目)目標(biāo)。該模型還學(xué)習(xí)了一組N個(gè)目標(biāo)的查詢,這些查詢是(類似于編碼器)學(xué)習(xí)出來的位置編碼。
目標(biāo)查詢
下圖描述了N=20個(gè)學(xué)習(xí)出來的目標(biāo)查詢(稱為prediction slots)如何聚焦于一張圖像的不同區(qū)域。

“我們觀察到,在不同的操作模式下,每個(gè)slot 都會學(xué)習(xí)特定的區(qū)域和框大小。“ —— DETR的作者
理解目標(biāo)查詢的直觀方法是想象每個(gè)目標(biāo)查詢都是一個(gè)人。每個(gè)人都可以通過注意力來查看圖像的某個(gè)區(qū)域。一個(gè)目標(biāo)查詢總是會問圖像中心是什么,另一個(gè)總是會問左下角是什么,以此類推。
使用PyTorch實(shí)現(xiàn)簡單的DETR
importtorch importtorch.nnasnn fromtorchvision.modelsimportresnet50 classSimpleDETR(nn.Module): """ MinimalExampleoftheDetectionTransformermodelwithlearnedpositionalembedding """ def__init__(self,num_classes,hidden_dim,num_heads, num_enc_layers,num_dec_layers): super(SimpleDETR,self).__init__() self.num_classes=num_classes self.hidden_dim=hidden_dim self.num_heads=num_heads self.num_enc_layers=num_enc_layers self.num_dec_layers=num_dec_layers #CNNBackbone self.backbone=nn.Sequential( *list(resnet50(pretrained=True).children())[:-2]) self.conv=nn.Conv2d(2048,hidden_dim,1) #Transformer self.transformer=nn.Transformer(hidden_dim,num_heads, num_enc_layers,num_dec_layers) #PredictionHeads self.to_classes=nn.Linear(hidden_dim,num_classes+1) self.to_bbox=nn.Linear(hidden_dim,4) #PositionalEncodings self.object_query=nn.Parameter(torch.rand(100,hidden_dim)) self.row_embed=nn.Parameter(torch.rand(50,hidden_dim//2) self.col_embed=nn.Parameter(torch.rand(50,hidden_dim//2)) defforward(self,X): X=self.backbone(X) h=self.conv(X) H,W=h.shape[-2:] pos_enc=torch.cat([ self.col_embed[:W].unsqueeze(0).repeat(H,1,1), self.row_embed[:H].unsqueeze(1).repeat(1,W,1)], dim=-1).flatten(0,1).unsqueeze(1) h=self.transformer(pos_enc+h.flatten(2).permute(2,0,1), self.object_query.unsqueeze(1)) class_pred=self.to_classes(h) bbox_pred=self.to_bbox(h).sigmoid() returnclass_pred,bbox_pred
二分匹配損失 (Optional)
讓為預(yù)測的集合,其中是包括了預(yù)測類別(可以是空類別)和包圍框的二元組,其中上劃線表示框的中心點(diǎn),和表示框的寬和高。
設(shè)y為ground truth集合。假設(shè)y和?之間的損失為L,每一個(gè)y?和??之間的損失為L?。由于我們是在集合的層次上工作,損失L必須是排列不變的,這意味著無論我們?nèi)绾闻判蝾A(yù)測,我們都將得到相同的損失。因此,我們想找到一個(gè)排列,它將預(yù)測的索引映射到ground truth目標(biāo)的索引上。在數(shù)學(xué)上,我們求解:
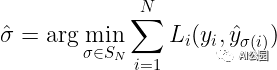
計(jì)算的過程稱為尋找最優(yōu)的二元匹配。這可以用匈牙利算法找到。但為了找到最優(yōu)匹配,我們需要實(shí)際定義一個(gè)損失函數(shù),計(jì)算和之間的匹配成本。
回想一下,我們的預(yù)測包含一個(gè)邊界框和一個(gè)類。現(xiàn)在讓我們假設(shè)類預(yù)測實(shí)際上是一個(gè)類集合上的概率分布。那么第i個(gè)預(yù)測的總損失將是類預(yù)測產(chǎn)生的損失和邊界框預(yù)測產(chǎn)生的損失之和。作者在http://arxiv.org/abs/1906.05909中將這種損失定義為邊界框損失和類預(yù)測概率的差異:
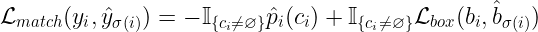
其中,是的argmax,是是來自包圍框的預(yù)測的損失,如果,則表示匹配損失為0。
框損失的計(jì)算為預(yù)測值與ground truth的L?損失和的GIOU損失的線性組合。同樣,如果你想象兩個(gè)不相交的框,那么框的錯(cuò)誤將不會提供任何有意義的上下文(我們可以從下面的框損失的定義中看到)。
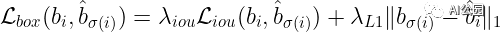
其中,λ???和是超參數(shù)。注意,這個(gè)和也是面積和距離產(chǎn)生的誤差的組合。為什么會這樣呢?
可以把上面的等式看作是與預(yù)測相關(guān)聯(lián)的總損失,其中面積誤差的重要性是λ???,距離誤差的重要性是。
現(xiàn)在我們來定義GIOU損失函數(shù)。定義如下:
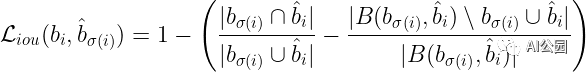
由于我們從已知的已知類的數(shù)目來預(yù)測類,那么類預(yù)測就是一個(gè)分類問題,因此我們可以使用交叉熵?fù)p失來計(jì)算類預(yù)測誤差。我們將損失函數(shù)定義為每N個(gè)預(yù)測損失的總和:
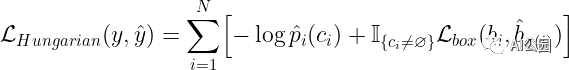
為目標(biāo)檢測使用DETR
在這里,你可以學(xué)習(xí)如何加載預(yù)訓(xùn)練的DETR模型,以便使用PyTorch進(jìn)行目標(biāo)檢測。
加載模型
首先導(dǎo)入需要的模塊。
#Importrequiredmodules importtorch fromtorchvisionimporttransformsasTimportrequests#forloadingimagesfromweb fromPILimportImage#forviewingimages importmatplotlib.pyplotasplt
下面的代碼用ResNet50作為CNN骨干從torch hub加載預(yù)訓(xùn)練的模型。其他主干請參見DETR github:https://github.com/facebookresearch/detr
detr=torch.hub.load('facebookresearch/detr',
'detr_resnet50',
pretrained=True)
加載一張圖像
要從web加載圖像,我們使用requests庫:
url='https://www.tempetourism.com/wp-content/uploads/Postino-Downtown-Tempe-2.jpg'#Sampleimageimage=Image.open(requests.get(url,stream=True).raw)plt.imshow(image) plt.show()
設(shè)置目標(biāo)檢測的Pipeline
為了將圖像輸入到模型中,我們需要將PIL圖像轉(zhuǎn)換為張量,這是通過使用torchvision的transforms庫來完成的。
transform=T.Compose([T.Resize(800), T.ToTensor(), T.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225])])
上面的變換調(diào)整了圖像的大小,將PIL圖像進(jìn)行轉(zhuǎn)換,并用均值-標(biāo)準(zhǔn)差對圖像進(jìn)行歸一化。其中[0.485,0.456,0.406]為各顏色通道的均值,[0.229,0.224,0.225]為各顏色通道的標(biāo)準(zhǔn)差。
我們裝載的模型是預(yù)先在COCO Dataset上訓(xùn)練的,有91個(gè)類,還有一個(gè)表示空類(沒有目標(biāo))的附加類。我們用下面的代碼手動(dòng)定義每個(gè)標(biāo)簽:
CLASSES= ['N/A','Person','Bicycle','Car','Motorcycle','Airplane','Bus','Train','Truck','Boat','Traffic-Light','Fire-Hydrant','N/A','Stop-Sign','ParkingMeter','Bench','Bird','Cat','Dog','Horse','Sheep','Cow','Elephant','Bear','Zebra','Giraffe','N/A','Backpack','Umbrella','N/A','N/A','Handbag','Tie','Suitcase','Frisbee','Skis','Snowboard','Sports-Ball','Kite','BaseballBat','BaseballGlove','Skateboard','Surfboard','TennisRacket','Bottle','N/A','WineGlass','Cup','Fork','Knife','Spoon','Bowl','Banana','Apple','Sandwich','Orange','Broccoli','Carrot','Hot-Dog','Pizza','Donut','Cake','Chair','Couch','PottedPlant','Bed','N/A','DiningTable','N/A','N/A','Toilet','N/A','TV','Laptop','Mouse','Remote','Keyboard','Cell-Phone','Microwave','Oven','Toaster','Sink','Refrigerator','N/A','Book','Clock','Vase','Scissors','Teddy-Bear','Hair-Dryer','Toothbrush']
如果我們想輸出不同顏色的邊框,我們可以手動(dòng)定義我們想要的RGB格式的顏色
COLORS=[ [0.000,0.447,0.741], [0.850,0.325,0.098], [0.929,0.694,0.125], [0.494,0.184,0.556], [0.466,0.674,0.188], [0.301,0.745,0.933] ]
格式化輸出
我們還需要重新格式化模型的輸出。給定一個(gè)轉(zhuǎn)換后的圖像,模型將輸出一個(gè)字典,包含100個(gè)預(yù)測類的概率和100個(gè)預(yù)測邊框。
每個(gè)包圍框的形式為(x, y, w, h),其中(x,y)為包圍框的中心(包圍框是單位正方形[0,1]×[0,1]), w, h為包圍框的寬度和高度。因此,我們需要將邊界框輸出轉(zhuǎn)換為初始和最終坐標(biāo),并重新縮放框以適應(yīng)圖像的實(shí)際大小。
下面的函數(shù)返回邊界框端點(diǎn):
#Getcoordinates(x0,y0,x1,y0)frommodeloutput(x,y,w,h)defget_box_coords(boxes): x,y,w,h=boxes.unbind(1) x0,y0=(x-0.5*w),(y-0.5*h) x1,y1=(x+0.5*w),(y+0.5*h) box=[x0,y0,x1,y1] returntorch.stack(box,dim=1)
我們還需要縮放了框的大小。下面的函數(shù)為我們做了這些:
#Scaleboxfrom[0,1]x[0,1]to[0,width]x[0,height]defscale_boxes(output_box,width,height): box_coords=get_box_coords(output_box) scale_tensor=torch.Tensor( [width,height,width,height]).to( torch.cuda.current_device())returnbox_coords*scale_tensor
現(xiàn)在我們需要一個(gè)函數(shù)來封裝我們的目標(biāo)檢測pipeline。下面的detect函數(shù)為我們完成了這項(xiàng)工作。
#ObjectDetectionPipelinedefdetect(im,model,transform): device=torch.cuda.current_device() width=im.size[0] height=im.size[1] #mean-stdnormalizetheinputimage(batch-size:1) img=transform(im).unsqueeze(0) img=img.to(device) #demomodelonlysupportbydefaultimageswithaspectratiobetween0.5and2assertimg.shape[-2]<=?1600?and?img.shape[-1]?<=?1600,????#?propagate?through?the?model ????outputs?=?model(img)????#?keep?only?predictions?with?0.7+?confidence ????probas?=?outputs['pred_logits'].softmax(-1)[0,?:,?:-1] ????keep?=?probas.max(-1).values?>0.85 #convertboxesfrom[0;1]toimagescales bboxes_scaled=scale_boxes(outputs['pred_boxes'][0,keep],width,height)returnprobas[keep],bboxes_scaled
現(xiàn)在,我們需要做的是運(yùn)行以下程序來獲得我們想要的輸出:
probs,bboxes=detect(image,detr,transform)
繪制結(jié)果
現(xiàn)在我們有了檢測到的目標(biāo),我們可以使用一個(gè)簡單的函數(shù)來可視化它們。
#PlotPredictedBoundingBoxesdefplot_results(pil_img,prob,boxes,labels=True): plt.figure(figsize=(16,10)) plt.imshow(pil_img) ax=plt.gca() forprob,(x0,y0,x1,y1),colorinzip(prob,boxes.tolist(),COLORS*100):ax.add_patch(plt.Rectangle((x0,y0),x1-x0,y1-y0, fill=False,color=color,linewidth=2)) cl=prob.argmax() text=f'{CLASSES[cl]}:{prob[cl]:0.2f}' iflabels: ax.text(x0,y0,text,fontsize=15, bbox=dict(facecolor=color,alpha=0.75)) plt.axis('off') plt.show()
現(xiàn)在可以可視化結(jié)果:
plot_results(image,probs,bboxes,labels=True)
審核編輯:彭菁
-
Facebook
+關(guān)注
關(guān)注
3文章
1429瀏覽量
54479 -
代碼
+關(guān)注
關(guān)注
30文章
4672瀏覽量
67779 -
檢測模型
+關(guān)注
關(guān)注
0文章
17瀏覽量
7299 -
Transformer
+關(guān)注
關(guān)注
0文章
135瀏覽量
5944
原文標(biāo)題:Transformer (DETR) 對象檢測實(shí)操!
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
MCS-51內(nèi)部定時(shí)/計(jì)數(shù)器有哪幾種工作方式呢
GPIO基本結(jié)構(gòu)和工作方式介紹
α調(diào)制工作方式原理
鼠標(biāo)的工作方式
Wifi模塊的工作方式功能是什么?
步進(jìn)電機(jī)及驅(qū)動(dòng)電路工作原理及工作方式介紹
cd4013無穩(wěn)態(tài)工作方式及無穩(wěn)態(tài)電路應(yīng)用
ups不間斷電源工作方式
AD級聯(lián)的工作方式配置和AD雙排序的工作方式配置詳細(xì)說明
如何使用Transformer來做物體檢測?
UPS電源有哪些工作方式?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論