 PyTorch IO DataPipes可用性、性能和功能
PyTorch IO DataPipes可用性、性能和功能
培訓大型深層學習模式需要大型數據集。亞馬遜簡單存儲服務(Amazon S3)是用于儲存大型培訓數據集的可縮放云點存儲服務。 機器學習(ML)實踐者需要高效的數據管道,能夠從亞馬遜S3下載數據,轉換數據,并將數據輸入GPU,用于高輸送量和低潛伏度的培訓模式。
我們在此為皮托爾奇推出新的S3 IO DataPipes(S3 IO DataPipes),s3 文件列表器和s3 文件加載器為了提高記憶效率和快速運行,新的數據平臺使用C擴展號訪問亞馬遜S3基準顯示:s3 文件加載器速度為59.8%ffspepefile 打開器用于下載亞馬遜S3的自然語言處理(NLP)數據集。電子數據管道我們還表明,新的數據平臺可以將貝爾特和ResNet50培訓時間總體減少7%。
概覽
亞馬遜 S3 是一個可縮放的云存儲服務系統,沒有數據數量限制。 從亞馬遜 S3 上載數據并將數據輸入高性能的 GPU, 如 NVIDIA A100 等高性能的 GPU, 可能具有挑戰性。 它需要高效的數據管道, 能夠滿足 GPU 的數據處理速度 。 為此, 我們為 PyTorrch 發布了一個新的高性能工具: S3 IO DataPipes 。 DataPipes 從參考文獻數據庫 參考文獻數據庫,以便他們能與宜用數據排氣管接口。開發者可以快速建立數據平臺 DAG, 以獲取、轉換和操作數據,并使用打亂、分割和批量功能。
新的 DataPipes 設計成文件格式的不可知性,亞馬遜 S3 數據作為二進制大型對象( BLOBs) 下載。它可以用作可合成的構件塊,用于組裝一個DataPipe 圖表,該圖可以將表格、NLP和計算機視覺(CV)數據裝入培訓管道。
在引擎蓋下,新的S3 IO DataPipes使用一個與 AWS C SDK 的 C S3 處理器。 一般來說, C 的安裝比 Python 更能提高內存效率,并且與 Python 相比, C 的 CPU 核心使用( 沒有全球解釋器鎖 ) 更好。 新的 C S3 IO DataPipes 被推薦在培訓大型深層學習模型時使用高輸送量、低潛伏數據。
新的S3 IO DataPipes提供兩個頭等公民API:
s3 文件列表器- 可在給定的 S3 前綴內列出 S3 文件 URL。 此 API 的功能名稱是列表文件_by_s3.
s3 文件加載器- 從給定的 S3 前綴裝入 S3 文件的可使用性。 此 API 的功能名稱是負載文件_by_s3.
使用量
在本節中,我們為使用新的S3 IO DataPipes提供指導。負載_ files_by_s3 ().
從源構建
新建的 S3 IO DataPipes 使用 C 擴展名。 它被嵌入點火數據選項卡。但是,如果新的數據提示在環境中不可用,例如 Conda 上的 Windows,您需要從源構建。如果需要更多信息,請參見可迭接數據管道.
配置
亞馬遜 S3 支持全球水桶。然而,在區域內創建一個水桶。您可以通過使用__init___()或者,您也可以導出 AWS_ REGION =us- 西向 2外殼或設置環境變量[AWS_REGION] =“我們一號” =“我們一號”在你的代碼。
要在水桶中閱讀無法公開查閱的物品,您必須通過下列方法之一提供AWS證書:
安裝和配置排AWS 命令行界面(AWS CLLI)和(AWS CLLI)AWS 配置
設置當地系統AWS 認證檔案檔案中的全權證書。~/.鋸/證書在 Linux, macOS 或 Unix 上
設定aws_ access_keey_id 訪問器和aws_ secret_ access_keys 密鑰環境變量
如果您使用這個圖書館亞馬遜(Amazon EC2)實例,具體說明AWS 身份和準入管理(IMM)作用,然后讓EC2實例有機會發揮這種作用
示例代碼
下面的代碼片斷提供了一種典型的用法負載_ files_by_s3 ():
從 rch.utils. data 導入來自 rchdata. dataloader 從 rchdata. datapipops. iter 導入 IterableWrapper s3_shard_urls = IterableWrapper ([“s3://bucket/prefix/] ]).列表文件_by_s3 () s3_shards = s3_shard_urls.負載文件_by_s3 ()
基準基準基準
在本節中,我們展示新的數據平臺如何能夠減少Bert和ResNet50的總體培訓時間。
對照FSSpec的孤立數據 Loader 業績評價
ffspepefile 打開器是另一個 PyTollch S3 DataPipe 。它使用體核和傳真/傳真: http/ asyncioS3 數據訪問 S3 數據。 以下是性能測試設置和結果(引自本地ASWDK與基于數據平臺的FSspec(boto3)之間的業績比較).
測試中的 S3 數據是一個碎片化的文本數據集。 每個碎片有大約10萬條線, 每條線約為1.6 KB, 使每條碎片大約156 MB。 本基準中的測量量平均超過1,000 批。 沒有進行打亂、 取樣或變換 。
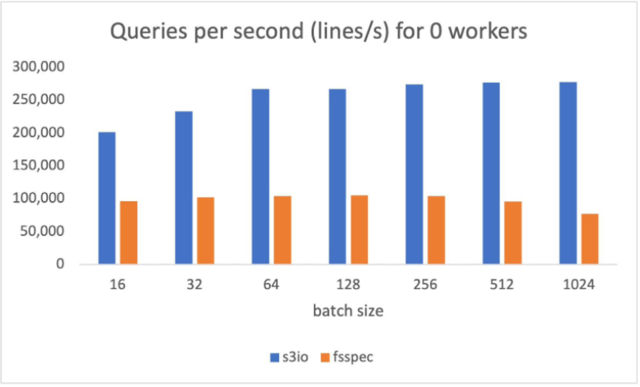
下圖的圖表匯報了以下表格中各種批量規模的通過量比較。num_工人=0,數據裝載器在主過程中運行。s3 文件加載器每秒(QPS)的查詢量較高(QPS),比(QPS)高90%。纖維分批體積為512。
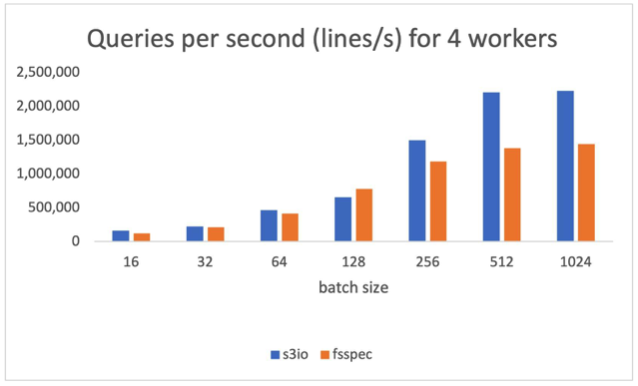
下圖圖表匯報了以下各項結果:num_工人=4,數據裝載器運行在主進程。s3 文件加載器高于59.8%纖維分批體積為512。
打擊Boto3的訓練ResNet50模式
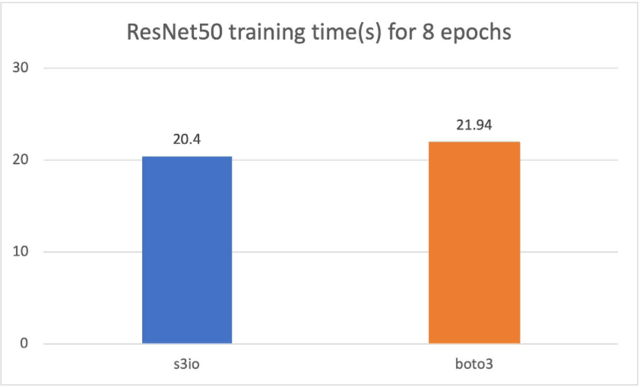
在下圖中,我們培訓了RESNet50模型,該模型由4p3.16x大案例組成,總共32個GPUs。培訓數據集是圖像網絡,有120萬張圖像,以1 000張圖像碎片組成。培訓批量尺寸為64。培訓時間以秒計。對于8個時代,培訓時間以8個時代計。s3 文件加載器比Boto3還快7.5%。
a 與Boto3相比的Bert培訓模式
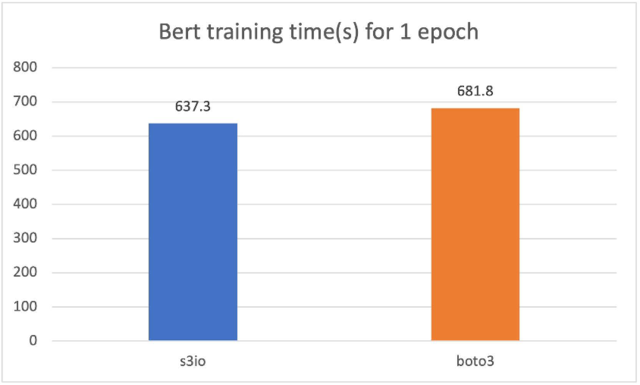
對于以下的馬車,我們訓練了一個Bert模型,在總共32個GPU的4 p3.16x大案例群中,共有1 474個文件。每個文件有大約15萬個樣本。要運行一個較短的時代,我們每個文件使用0.05%(大約75個樣本)。批量大小為2 048,培訓時間以秒計。對于一個時代,我們用0.5 % (大約75個樣本)來測量。s3 文件加載器比Boto3還快7%
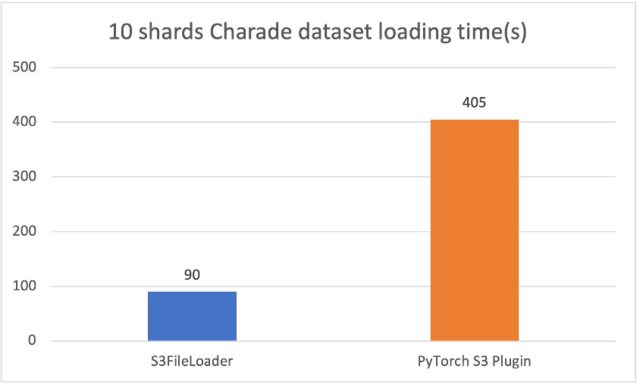
與原始 PyTorrch S3 插件的比較
新的PyTollch S3 DataPipes 運行比原運行要好得多PyTork S3 插件我們調整了內部緩沖大小s3 文件加載器。裝載時間以秒計。
10個散亂的猜謎文件(每個約1.5GB),s3 文件加載器在我們的實驗中 速度是3.5倍
最佳做法
培訓大型深層學習模型可能需要一個包含數十個甚至數百個節點的大規模計算組。 集群中的每個節點都可能產生大量數據裝載請求,這些請求會擊中特定的 S3 碎片。 為了避免油門,我們建議在 S3 桶和 S3 文件夾上分割培訓數據。
為了取得良好的業績,它有助于擁有足夠大的文件大小,足以在特定文件上平行,但并不大,以致于我們根據培訓工作,在亞馬遜S3上達到該物體的輸送量極限。 最佳規模可能介于50-200 MB之間。
六. 結論和下一步措施
在此文章中,我們向您介紹了新的PyTorch IO DataPipes。新的 DataPipes 使用aws-sdk-cpp 縮略語并顯示與基于 Boto3 的數據裝載器相比的性能較好。
對于今后的步驟,我們計劃改進可用性、性能和功能,側重于以下特點:
S3授權,由IAM擔任- 目前,S3 DataPipes支持明確的準入證書、案例簡介和S3桶政策。 但是,有些使用案例更偏愛IMA角色。
雙重緩沖- 我們計劃提供雙重緩沖 支持多工人下載
本地緩存- 我們計劃使示范培訓能夠穿行培訓數據集以通過多個傳球。 第一個時代之后的本地緩沖可以縮短亞馬遜三世的飛行延誤時間,這可以大大加快隨后時代的數據檢索時間。
可定制配置- 我們計劃披露更多參數,如內部緩沖大小、多部分塊大小、執行人計數等,讓用戶進一步調整數據裝載效率。
亞馬遜 S3 上傳- 我們計劃擴大S3 DataPipes, 支持上傳檢查。
與 Fspec 合并 – 纖維用于其他系統,例如irch. save ()我們可以將新的 S3 數據 PDataPipes 與纖維這樣他們就可以有更多的使用案例。
審核編輯:彭菁
-
數據
+關注
關注
8文章
6892瀏覽量
88827 -
gpu
+關注
關注
28文章
4701瀏覽量
128705 -
亞馬遜
+關注
關注
8文章
2625瀏覽量
83190 -
pytorch
+關注
關注
2文章
803瀏覽量
13147
發布評論請先 登錄
相關推薦
企業服務器網絡的可用性設計
Spartan-6器件的可用性
基于可用性模型的志愿計算
UPS拓撲結構對供電系統高可用性的影響
各種機架電源冗余配置的可用性比較
云計算平臺對PACS的高可用性支持
UPS系統的可用性進行內部設計分析
如何使用馬爾可夫鏈與服務質量提高網絡可用性的性能模型說明







 工商網監
工商網監
評論