 2.0優化PyTorch推理與AWS引力子處理器
2.0優化PyTorch推理與AWS引力子處理器
由來自AWS的蘇尼塔·納坦普alli 校對:Portnoy
新一代的CPU在機器學習(ML)推論中,由于專門的內置指令,其性能顯著改善。 這些普通用途處理器加上其靈活性、高速開發和低運作成本,為其他現有硬件解決方案提供了替代 ML 推論解決方案。
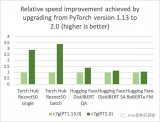
AWS、Arm、Meta等幫助優化了PyTorrch 2.0 武器化處理器的性能。 因此,我們高興地宣布,PyToch 2.0 武器基AWS Graviton案例的推論性能比先前的PyToch 釋放速度高達ResNet-50的3.5倍,比BERT速度高達1.4倍,使Graviton案例成為這些模型在AWS上最快速最優化的計算實例(見下圖 ) 。
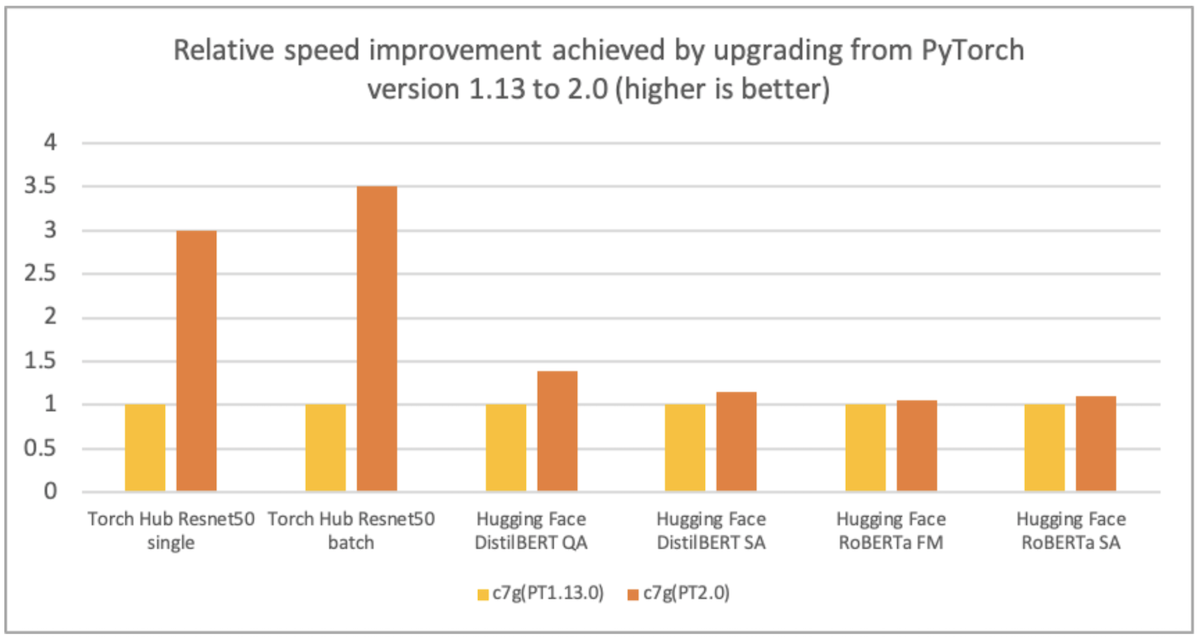
圖像1:通過從PyTorrch版本1.13升級到2.0(越高越好)實現相對速度的提高。
如下圖所示,我們測量到PyTorrch 以 Graviton3 為基礎的C7g 案例在火炬樞紐ResNet-50和多個擁抱面模型中產生的成本節約高達50%,而可比的以x86為基礎的計算優化了亞馬遜EC2案例。對于該圖表,我們首先測量了五種案例類型的每百萬次計算成本。然后,我們將每百萬次計算成本的結果與C5.4x大案例(這是該圖表Y軸上的“1”的基線衡量標準)標準化。
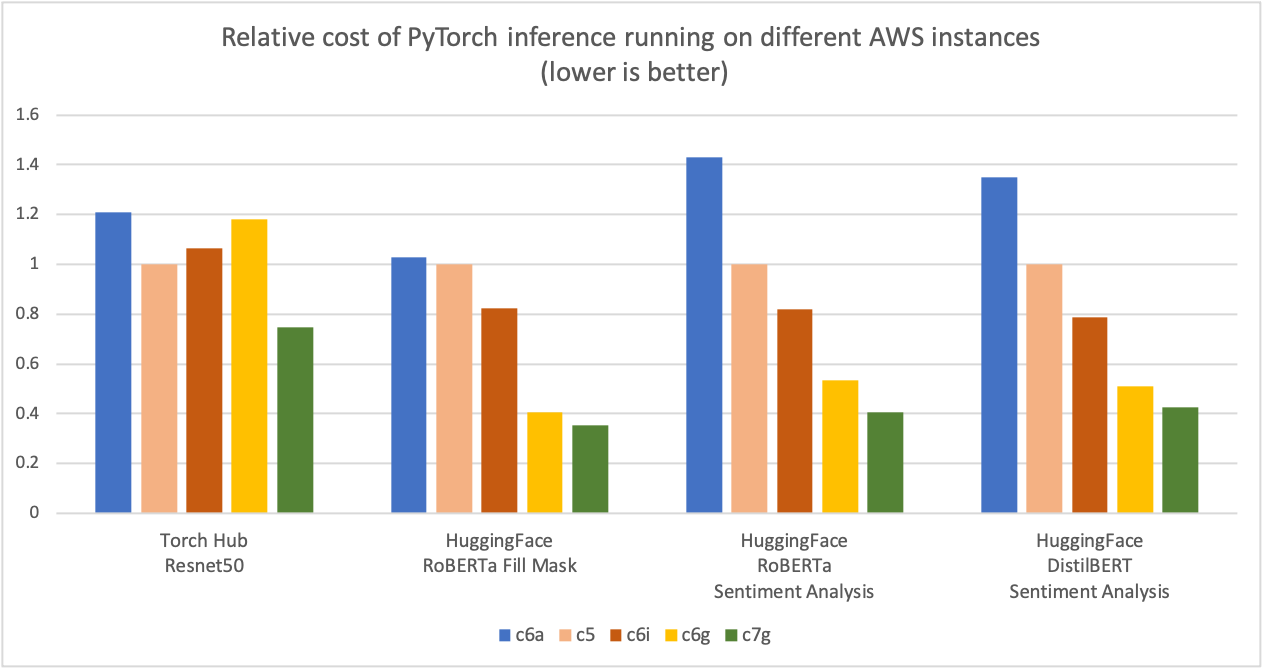
圖像2圖2:不同AWS實例中的PyTorch推論的相對成本(較低者更好)。
資料來源:AWS ML博客。Graviton PyTerch2.0 推推性能.
與前面的推論成本比較圖相似,下圖顯示了相同五例類型的模型p90延遲度。我們將延遲值結果與C5.4x大實例(這是圖Y軸上的“1”基線測量標準)正常化。 c7g.4x大(AWS Graviton3)模型推導延遲度比C5.4x大、C6i4x大和C6a.4x大的延遲度高出50%。
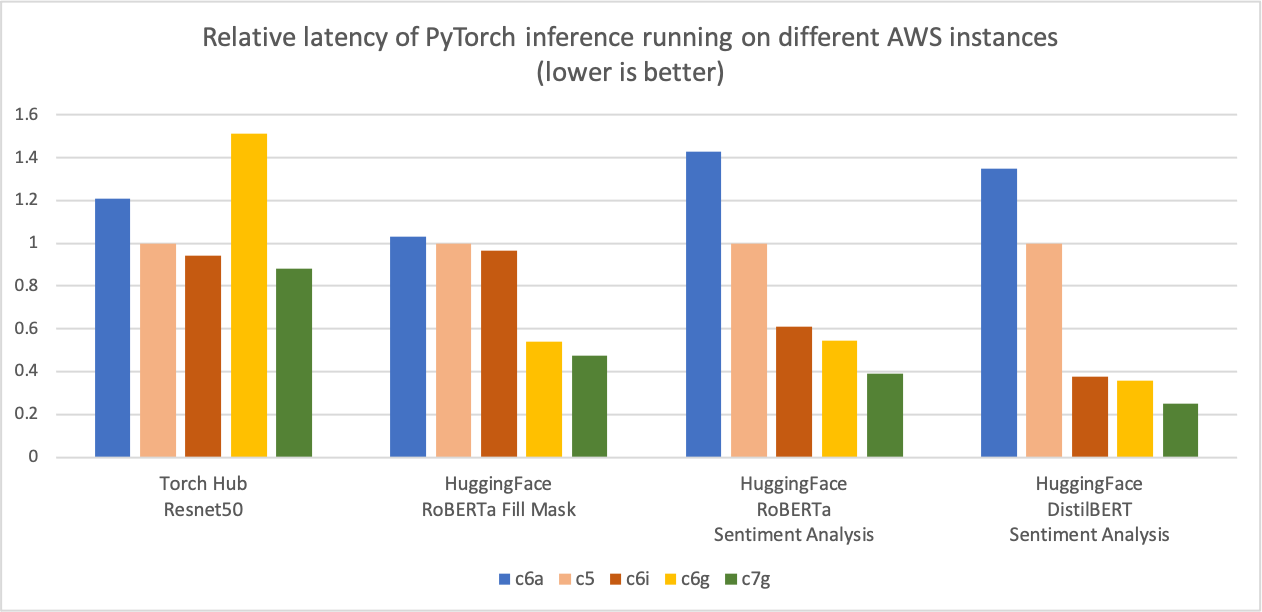
圖像 3:不同AWS實例中的PyTocher推論的相對延遲度(第90頁)(較低者更好)。
資料來源:AWS ML博客。Graviton PyTerch2.0 推推性能.
優化詳情
PyTorrch 支持計算 Armá 建筑(ACL) GEMM 核心庫的計算, 通過 AArch64 平臺的 oneDNNN 后端( 原稱“ MKL- DNN ”) 計算 。 優化主要針對 PyTorrch ATen CPU BLAS 、 fp32 和 bfloat16 的 ACL 內核以及 1DN 原始緩存。 沒有前端 API 更改, 因此在應用層面無需修改, 以使這些優化適用于 Graviton3 實例 。
Py火點級優化
我們擴展了ATen CPU BLAS 接口, 通過 anDNN 后端加速 Aarch64 平臺的更多操作員和高壓配置。 下圖突出顯示( 橙色) 優化組件, 改善了 Aarch64 平臺上的 PyTorrch 推斷性能 。
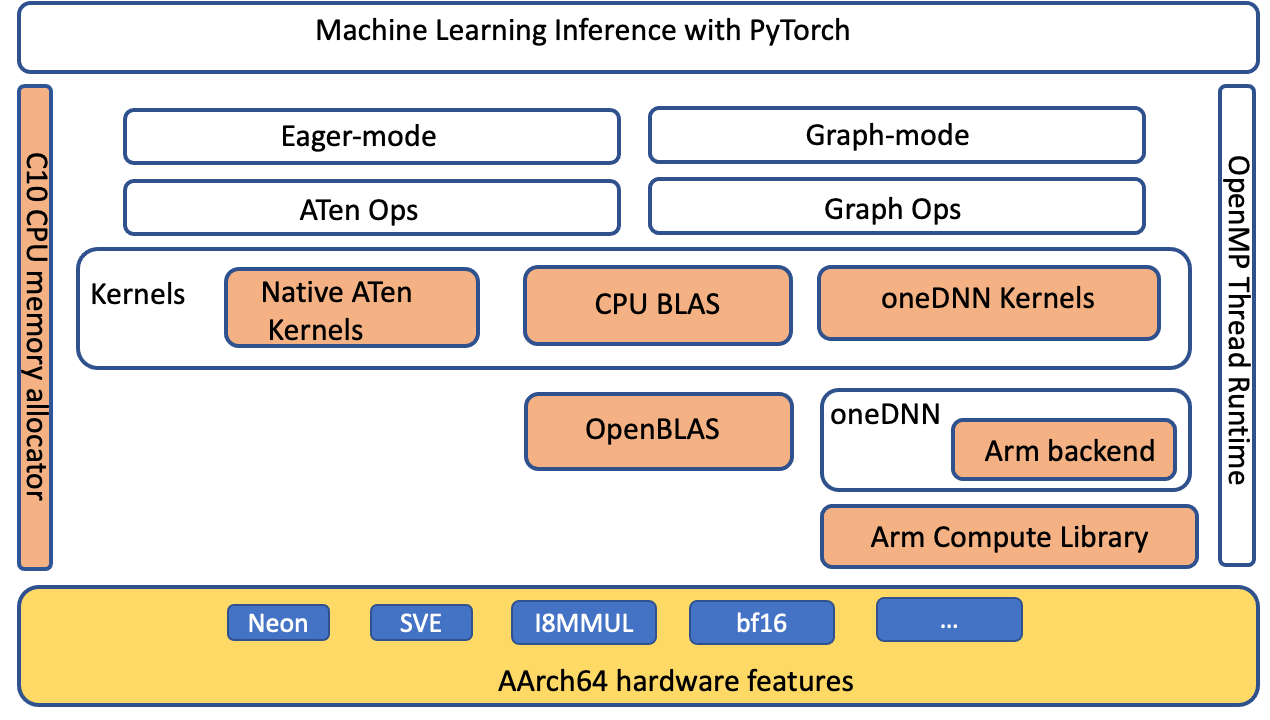
圖像 4 圖像 4:PyTorrch軟件堆加亮(橙色)AArch64平臺上為改進推論性能而優化的組件
ACL 內核和 BFloat16 FFmatath 模式
ACL 圖書館為 fp32 和 bfloat 16 格式提供 Neon 和 SVE 優化的 GEMM 內核: 這些內核提高了SIMD 硬件的利用率,并將結束時間縮短到最終推導延遲。 Graviton 3 的 bloat 16 支持使使用 bfloat 16 fp32 和 自動混合精密( AMP) 培訓的模型得到有效部署。 標準的 fp32 模型通過 oneDNN FPmath 模式使用 bfloat 16 內核,而沒有模型量化。 這些內核的性能比現有的 fp32 模型推力快兩倍,沒有 bfloat16 FPmath 支持。 關于ACL GEM 內核支持的更多細節,請參見 ACL GEMM 內核支持。Arm 計算庫 Github.
原始緩存
以下調序圖顯示了ACL運算符是如何融入 oneDNN 后端的。 如圖所示, ACL 對象以 oneDNN 資源而不是原始對象來處理 ACL 對象。 這是因為 ACL 對象是明確和可變的 。 由于 ACL 對象是作為資源對象處理的, 因而無法以 oneDNN 支持的默認原始緩沖特性來緩存 。 我們用“ 遞增”、“ 配制” 和“ 內制產品” 運算符在 ideep 操作員級別上進行原始的遞歸, 以避免 GEMM 內核啟動和 Exronor 分配管理 。
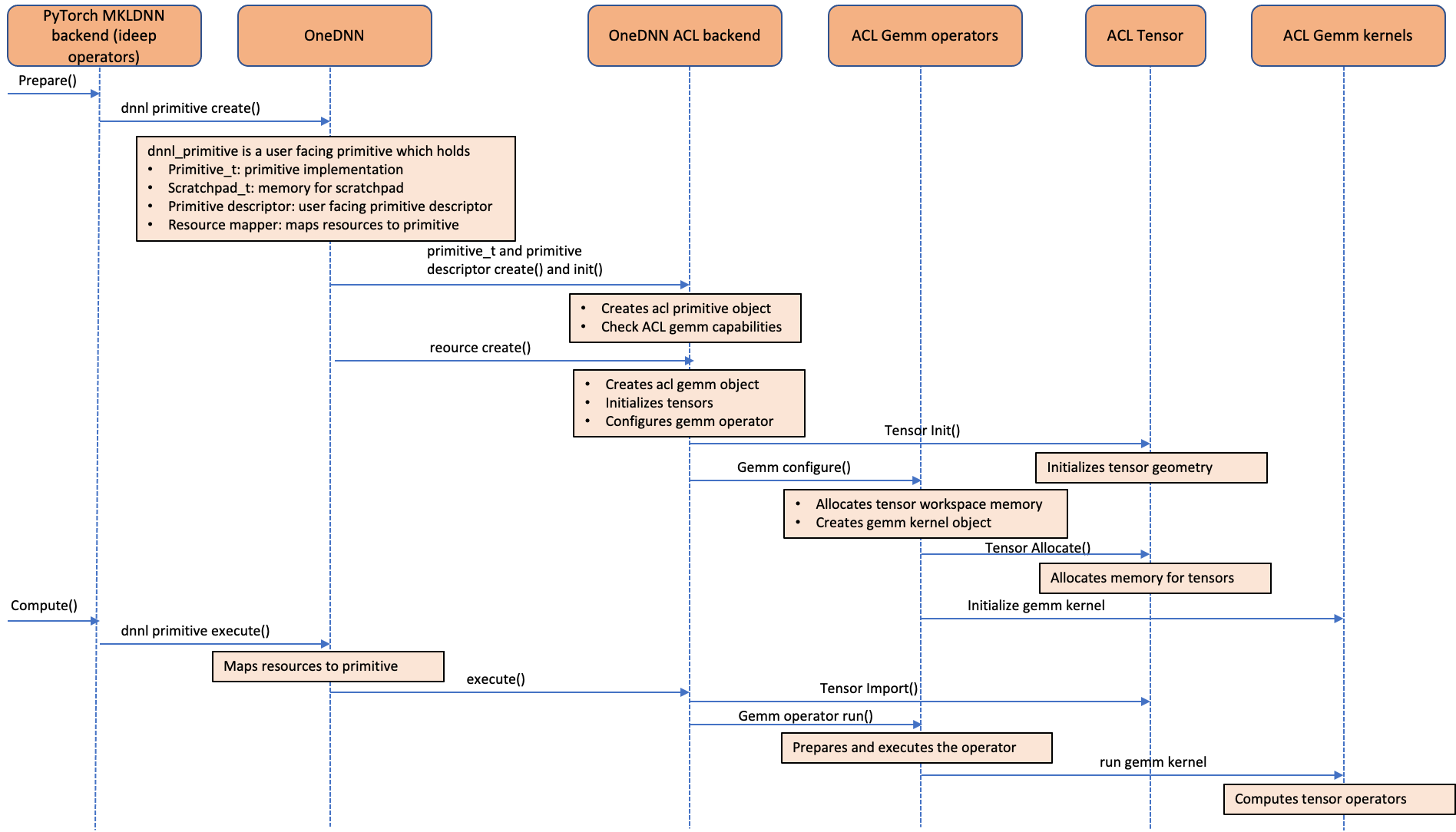
圖像5:呼叫序列圖表,顯示如何將 Armatia 建筑(ACL) GEMM GEMM 內核計算庫整合到一個 DNN 后端
如何利用優化
從官方回購中安裝 PyTorrch 2. 0 輪, 并設置環境變量, 以允許額外優化 。
調
正在運行一種推論
您可以使用 PyTork火炬燃燒以測量 CPU 推斷性能改進,或比較不同實例類型。
調
業績分析
現在, 我們將使用 PyTorrch 配置器分析 ResNet- 50 在 Graviton3 的 c7g 實例上的 ResNet- 50 的推論性能 。 我們用 PyTorrch 1. 13 和 PyTorrch 2. 0 運行下面的代碼, 并在測量性能之前將幾處迭代的推論進行 。
調
從火炬進口模型樣本中導入的點火炬 樣本_input = [火炬.rand(1, 3, 224, 224)] 熱度_ 模型 = 模型.resnet50 (重量=模型.ResNet50_Weights.DEFAULAT) 模型 = 火炬.jit. stat. stript.jet.no_grad () 模型 = 模型.eval () 模型 = 火炬.jit.optimize_ for_ inference () 模型 :
我們用電壓儀查看剖面儀的結果,分析模型性能。
安裝以下 PyTollch 配置配置程序 Tensorboard 插件插件
pip 安裝火炬_ tb_ 色彩描述器
使用電壓板啟動
色色板 -- logdir=./logs
在瀏覽器中啟動以下內容以查看剖析器輸出。 剖析器支持“ 概覽” 、 “ 操作器” 、 “ 跟蹤” 和“ 模塊” 的觀點, 以洞察推論執行 。
http://localhost:6006/
下圖是剖析器“ Trace” 視圖, 顯示調用堆和每個函數的執行時間。 在剖析器中, 我們選擇了前方() 函數以獲得整個推算時間。 如圖所示, 以 Graviton3 為基礎的 7g 實例 ResNet- 50 模型的推算時間比 PyTorch 1. 13 高出 PyTorrch 2. 0 的三倍左右。
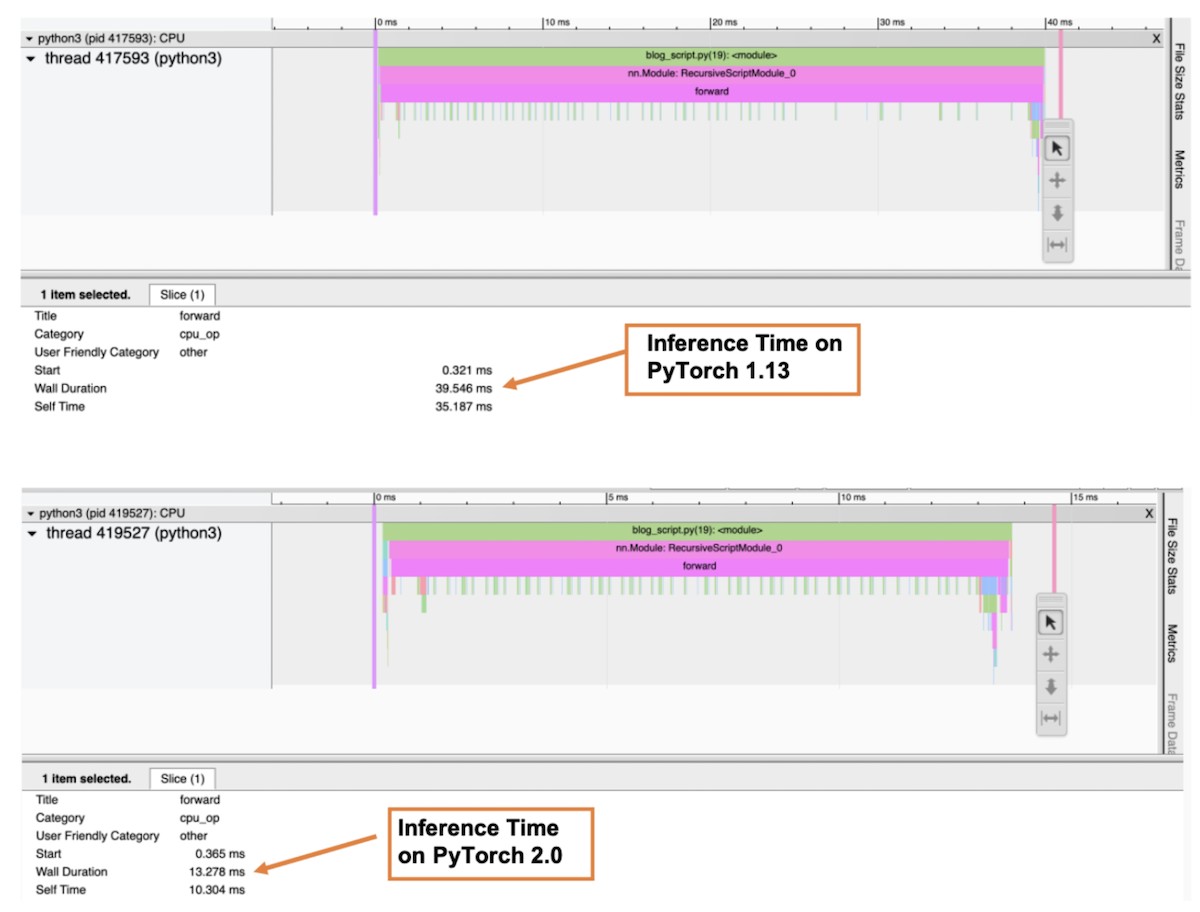
圖像 6: 剖析器跟蹤視圖: PyTorch 1. 13 和 PyTorch 2. 0 上的前穿墻長度
下一個圖表是“ 操作器” 視圖, 該視圖顯示 PyTorrch 操作器及其執行時間列表。 與前面的 Trace 視圖類似, 操作器視圖顯示, 以 Graviton3 為基礎的 c7g 實例 ResNet- 50 模型的操作器主機運行時間比 PyTorrch 1. 13 高出 3 倍左右 。
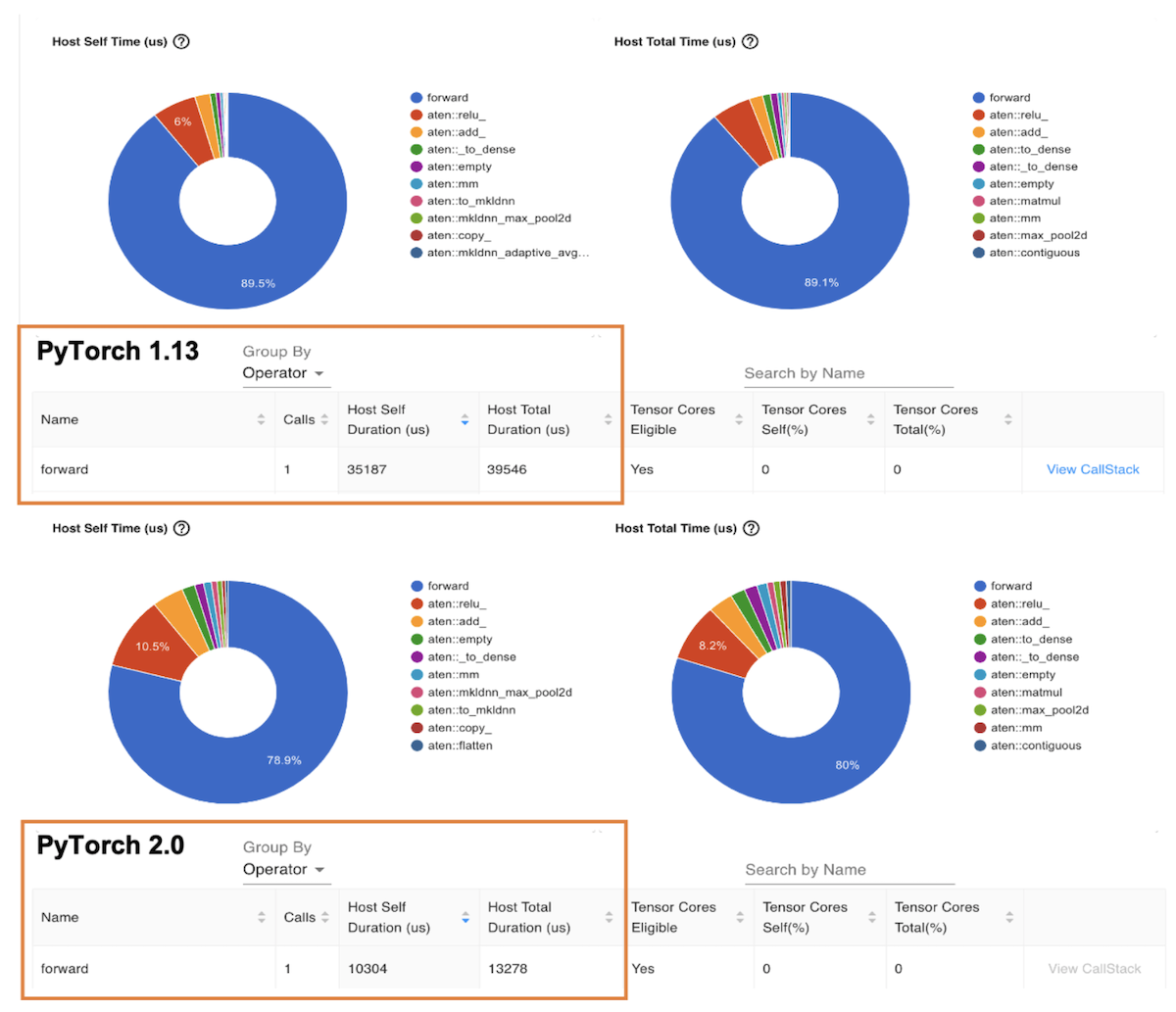
圖像 7PyTorch 1. 13 和 PyTorch 2. 0 的主機時間
B. 基準制定 " 擁抱模型 " 的基準
您可以使用Amazon Sage-Maker 推斷建議在不同實例中自動設定性能基準參數的實用性, 在不同實例中自動設定性能基準。 使用推推建議, 您可以找到實時推論端點, 該端點以給定 ML 模型的最低成本提供最佳性能。 我們通過在生產端點上部署模型, 收集了上述數據 。 關于推論建議方的更多細節, 請參考亞馬孫 -- -- 種植者 -- -- 實例GitHub repo。我們為這個職位設定了以下模式基準:ResNet50 圖像分類,發盤感應分析,RoBERTA 填充遮罩, 和RoBERTATA情緒分析.
結 結 結 結
對于PyTorrch 2. 0, 以 Graviton3為基礎的C7g實例是計算最符合成本效益的最優化亞馬遜EC2案例的推論。師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師 師和亞馬遜 EC2。AWS 重力技術指南提供最佳圖書館和最佳做法清單,幫助您在不同工作量中利用Graviton案例實現成本效益。
如果您發現在Graviton沒有觀察到類似的績效收益的使用情況,請就Graviton的績效收益提出問題。啟動 aws -graviton - greviton - 啟動我們將繼續進一步改進性能,使以AWS Graviton為基礎的案例成為使用PyTorrch進行推論的最具成本效益和效率的通用處理器。
收到確認
我們還要感謝AWS的Ali Saidi(首席工程師)和Csaba Csoma(軟件開發經理)、Ashok Bhat(產品經理)、Nathan Sircombe(工程經理)和Milos Puzovic(首席軟件工程師)在Graviton PyTorch推論優化工作中的支持。 我們還要感謝Meta的Geeta Chauhan(應用AI工程師領袖)在博客上提供的指導。
關于提交人
蘇尼塔·納坦普alli系AWS的ML工程師和軟件開發經理。
安基思·古納帕在Meta(PyTorrch)是AI合伙人工程師。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19165瀏覽量
229129 -
AI
+關注
關注
87文章
30146瀏覽量
268415 -
機器學習
+關注
關注
66文章
8377瀏覽量
132409 -
pytorch
+關注
關注
2文章
803瀏覽量
13148
發布評論請先 登錄
相關推薦
Arm Neoverse V1的AWS Graviton3在深度學習推理工作負載方面的作用
在AWS云中使用Arm處理器設計Arm處理器
通過Cortex來非常方便的部署PyTorch模型
地球引力位函數在流處理器上的實現與分析
如何選擇嵌入式處理器來推理
AWS基于Arm架構的Graviton 2處理器落地中國
使用AWS Graviton處理器優化的PyTorch 2.0推理






 工商網監
工商網監
評論