 如何加速生成2 PyTorch擴散模型
如何加速生成2 PyTorch擴散模型
產生性人工智能的近期進展大部分來自去除傳播模型,這些模型能夠從文本提示中產生高質量的圖像和視頻。 這個家族包括圖像、 DALLE、 延遲傳播等。 但是,這個家族的所有模型都有一個共同的缺點: 生成速度相當緩慢, 因為生成圖像的取樣過程具有迭接性。 這使得優化取樣圈內運行的代碼非常重要 。
我們以開放源實施流行文本到圖像傳播模式作為起點,利用PyTorrch 2:編集和快速關注實施中的兩種優化方法加快其生成速度,同時對代碼進行少量的記憶處理改進,這些優化使原實施速度比原實施速度加快49%。舊前和 39% 的推論比方使用舊前的原始代碼(不包括編譯時間)的速度加快,這取決于 GPU 架構和批量大小。重要的是,加速不需要安裝 舊前 或其他任何額外依賴關系。
下表顯示從安裝了舊前的最初實施到我們以PyTorch集成內存高效關注(最初為PyTorch集成內存有效關注開發并在舊前圖書館)和PyTorrch匯編,不包括匯編時間。
與原x格式相比,運行時間改善%%
見“基準設定和成果摘要”一節中的絕對運行時間數字。
| GPU | 批量大小 1 | 批量大小 2 | 批量大小 4 |
| p100 p100 (p100)(沒有匯編) | -3.8 -3.8 | 0.44 | 5.47 5.47 |
| T4 | 2.12 2.2.12 | 10.51 婦女 10.51 | 14.2 女14.2 |
| A10 | -2.34 | 8.99 | 10.57 10.57 |
| v100 (v100) | 18.63 | 6.39 | 10.43 |
| a100 (a100) | 38.5 | 20.33 | 12.17 12.17 |
人們可以注意到以下情況:
對于a100 (a100)和v100 (v100)等強大的GPU等強大的GPU來說,這些改進是顯著的。 對于這些GPU來說,第1批的改進最為顯著。
對于功率較小的GPUs,我們觀察到較弱的GPUs,我們觀察到較小的超速超速(或兩種情況下略有倒退 ) 。 這里的批量規模趨勢被逆轉:較大批量的改進更大
在以下各節中,我們介紹應用優化,并提供詳細的基準數據,將生成時間與不同最佳運行/關閉功能進行比較。
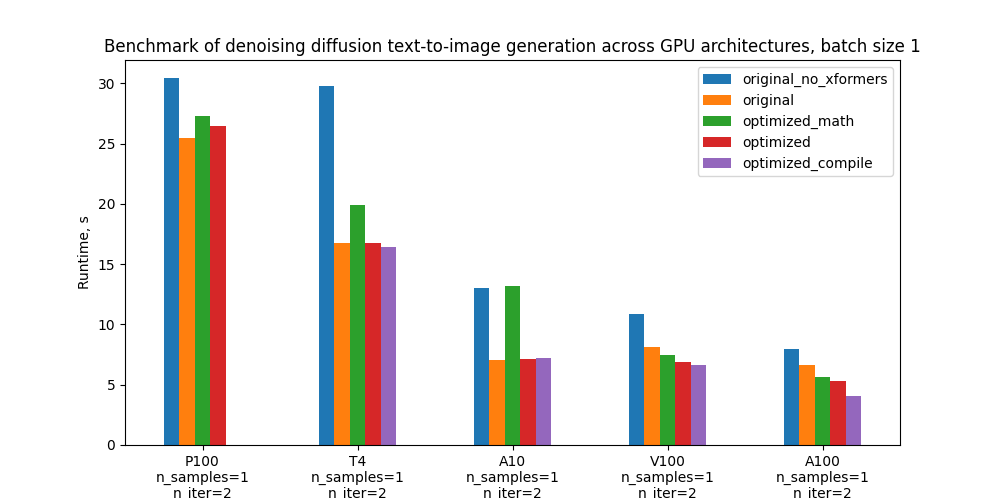
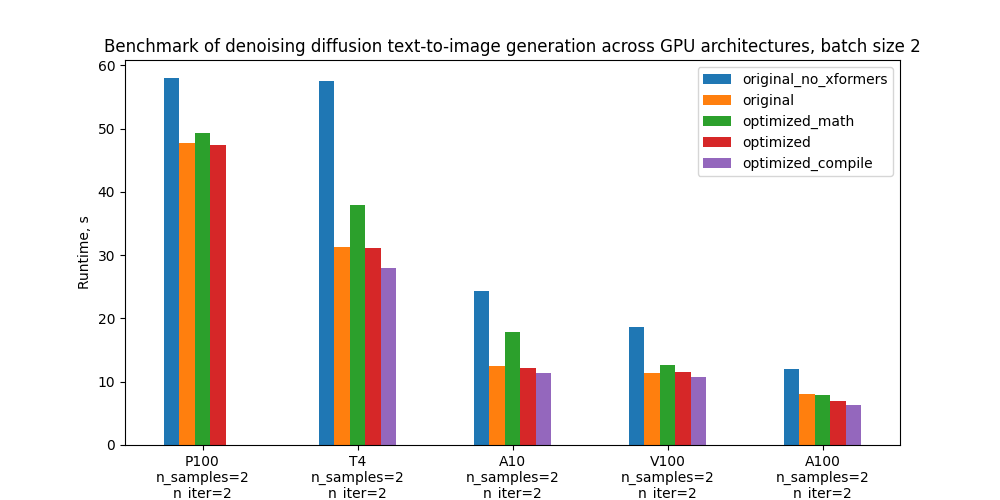
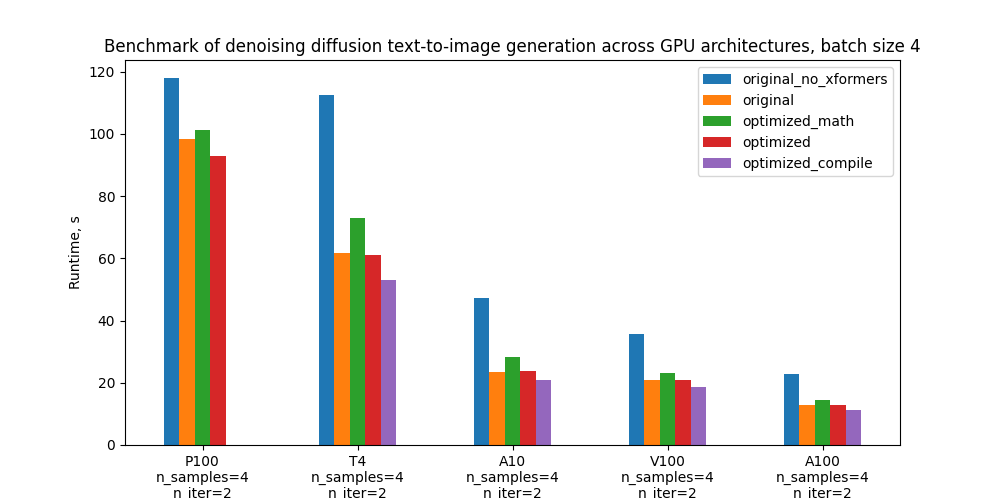
具體而言,我們以5個配置基準和下面的地塊為基準,比較其不同GPU和批量大小的絕對性性能,這些配置的定義見“基準設置和結果”一節。
優化優化
這里我們將更詳細地介紹在模式代碼中引入的優化。 這些優化依賴于最近發布的PyTorrch 2.0的特征。
優化關注
我們優化的代碼的一部分就是對點產品的關注比例。人們知道,注意是一個繁重的操作:天真地執行會影響關注矩陣,導致時間和記憶的復雜二次序列長度。擴散模型使用關注是常見的( 通常使用關注的 ) ( ) 。相互注意))作為U-Net多個部分的變換元塊的一部分。由于U-Net運行在每個取樣步驟,這成為優化的關鍵點。多頭目,PyTorrch 2 中優化了關注執行的功能, 并被納入其中。 這種優化的示意圖可歸結為以下偽代碼 :
類交叉注意( nn. module): def __ initt_( 自 己, ) :
替換為
類交叉注意(nn.Module): def __initt_( 本身, ......): 自我. mmha = nn. Multihead 注意 (...) def 前進( 自己, x, 上下文): 返回自我. mmha (x, 上下文, 上下文)
PyTorrch 1.13中已經提供了最佳的注意落實(見在這里和廣泛通過(例如,見A/CN.9/WG.III/WP.Huggging 紙面變壓器庫示例特別是,它吸收了《公約》和《公約》的記憶有效關注。舊前和閃閃著的注意http://arxiv.org/abs/2205.14135PyTorrch 2.0將這一功能擴大到更多的關注功能,如交叉關注和為進一步加速而定制的內核,使之適用于擴散模型。
在計算能力為SM 7.5或SM 8.x的GPU上可提供閃光關注,例如,在T4、A10和a100 (a100)上可提供閃光關注,這些都包括在我們的基準中(你可以檢查每個NVIDIA GPU的計算能力)。在這里然而,在我們對a100 (a100)a100 (a100)的測試中,由于關注頭和小批量數量少,因此對擴散模型特定案例的記憶有效關注比對傳播模型的閃光關注效果的注意效果好于對傳播模型的具體案例的閃光關注效果。在這里為了充分控制注意力后端(模擬有效關注、閃光關注、“香草數學”或任何未來數學),電力用戶可以在上下文管理員的幫助下手動啟用和禁用這些后端。后端... cudda. sdp_ 內核.
compilation
匯編是PyTorrch 2. 0 的新特性,從而能夠以非常簡單的用戶經驗實現巨大的超速。要援引默認行為,只需將一個 PyTorch 模塊或函數包成I. 火炬燃燒器:
模型 = 火炬. combile( 模型)
PyTorrch 編譯器然后將 Python 代碼轉換成一套指令, 可以在沒有 Python 管理費的情況下高效執行。 該編譯器在代碼首次被執行時動態發生。 在默認行為下, 在使用的 PyTorrch 頭罩下核電廠匯編代碼和火焚化器以進一步優化它。此教義以獲取更多細節。
雖然上面的單班條足以進行編譯, 但對代碼的某些修改可以壓縮更大的速度。 特別是, 人們應該避免所謂的圖形分解, 即PyTorrch無法編譯的代碼中的位置。 與先前的 PyTorrch 編譯方法( 如 火炬Script ) 相比, PyTorrch 2 編譯器在此情況下不會中斷。 相反, 它會回到急切的執行中 - 所以代碼運行, 但性能下降 。 我們對模式代碼做了一些小小改動, 以刪除圖形分解器 。 這包括刪除編譯器不支持的圖書館的功能, 比如 。檢查職能和電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電離電。 看看這個doc學習更多關于圖表分解和如何消除這些分解的信息。
從理論上講,可以適用I. 火炬燃燒器然而,在實踐中,僅僅匯編U-Net就足夠了。I. 火炬燃燒器還沒有環形分析器,因此將重新拼湊取樣循環的每一次迭代的代碼。 此外,已編譯的樣本代碼可能會生成圖形折斷符 — — 因此,如果人們想從已編譯的版本中獲得良好的性能,就需要調整它。
注意該匯編requires GPU compute capability >= SM 7.0以非傾向模式運行。這涵蓋了我們基準中的所有 GPU ----T4, v100 (v100), A10, a100 (a100) - p100 p100 (p100) 除外(見完整列表).
其他優化
此外,我們通過消除一些常見的陷阱提高了GPU內存操作的效率,例如直接在GPU上創建高壓GPU,而不是直接在CPU上創建高壓GPU,然后轉移到GPU,因此我們提高了GPU內存操作的效率。火焰圖.
制定基準和成果摘要
我們有兩種版本的代碼可以比較:原原件和優化優化除此以外,還可以打開/關閉若干優化功能(舊前、PyTorrch內存高效關注、編譯)。
沒有 舊前 的原始代碼
舊前 的原始代碼
與香草數學關注后端和無編譯的 香草數學關注優化代碼
最優化代碼, 包含內存高效關注后端, 沒有編譯
具有內存高效注意后端和編譯功能的優化代碼
作為原文原版我們采用了使用PyTorrch 1. 12的代碼版本,并按慣例執行了關注標準。優化版用途nn. 多頭目內相互注意PyTerch 2.0.0.dev20230111 cu117。 在與PyTerch有關的代碼中,它還有其他一些微小的優化。
下表顯示每個版本代碼的運行時間以秒計,與舊前原版相比的百分比改進百分比。 _ 匯編時間不包括在內。
1. 括號 -- -- " 原件與 x Formers " 行相對改進
| 配置配置配置 | p100 p100 (p100) | T4 | A10 | v100 (v100) | a100 (a100) |
| 沒有格式的原件 | 30.4s (19.3%) | 29.8s(-77.3%) | 13.0(-83.9%) | 10.9s(-33.1%) | 8.0s (19.3%) |
| 原件與 舊前 | 25.5秒(0%) | 16.8s (0.00%) | 7.1s 7.1s 7.1s 7.1s(0%) | 8.2s(0.00%) | 6.7s(0.00%) |
| 最優化的香草數學關注, 沒有編譯 | 27.3s (--7.0%) | 19.9s (18.7%) | 13.2% (87.2%) | 7.5s(8.7%) | 5.7s(15.1%) |
| 高效率的注意,沒有匯編。 | 26.5%(-3.8%) | 16.8s (0.2%) | 7.1s 7.1s 7.1s 7.1s(-0.8%) | 6.9s (16.0%) | 5.3s(20.6%) |
| 高效關注和匯編 | - 帶 | 16.4.4s 16.4.4s(2.1%) | 7.2(-2.3%) | 6.6.6s(18.6%) | 4.1s 4.1s(38.5%) |
批量規模 2 的運行時間
| 配置配置配置 | p100 p100 (p100) | T4 | A10 | v100 (v100) | a100 (a100) |
| 沒有格式的原件 | 58.0s (21.6%) | 57.6歲(84.0%) | 24.4s (95.2%) | 18.6秒 (-63.0%) | 12.0s (-50.6%) |
| 原件與 舊前 | 47.7s(0.00%) | 31.3s (0.00%) | 12.5s (0.00%) | 11.4秒 (0.00%) | 8.0s(0.00%) |
| 最優化的香草數學關注, 沒有編譯 | 49.3%(-3.5%) | 37.9s (-21.0%) | 17.8s (-4.2.2%) | 12.7s (10.7%) | 7.8s(1.8%) |
| 高效率的注意,沒有匯編。 | 47.5s 47.5s(0.4%) | 31.2% (0.5%) | 12.2% (2.6%) | 11.5%(-0.7%) | 7.0s (12.6%) |
| 高效關注和匯編 | - 帶 | 28.0秒(10.5%) | 11.4秒(9.0%) | 10.7s 10.7s(6.4%) | 6.4.4s(20.3%) |
批量大小 4 的批量運行時間
| 配置配置配置 | p100 p100 (p100) | T4 | A10 | v100 (v100) | a100 (a100) |
| 沒有格式的原件 | 117.9s(-20.00%) | 112.4s (-81.8%) | 47.2s (-101.7 %) | 35.8s (-71.9%) | 22.8s (-78.9%) |
| 原件與 舊前 | 98.3s(0.00%) | 61.8s(0.00%) | 23.4s(0.00%) | 20.8s (0.00%) | 12.7s (0.00%) |
| 最優化的香草數學關注, 沒有編譯 | 101.1s (-2.9%) | 73.0s(1.8.0%) | 28.3s (-21.0%) | 23.3s(11.9%) | 14.5s (13.9%) |
| 高效率的注意,沒有匯編。 | 92.9秒(5.5%) | 61.1s(1.2%) | 23.9s(-1.9%) | 20.8s (-0.1%) | 12.8s (-0.9%) |
| 高效關注和匯編 | - 帶 | 53.1s 53.1s(14.2%) | 20.9秒(10.6%) | 18.6秒(10.4%) | 11.2. 11.2(12.2%) |
為了盡量減少對基準代碼性能的波動和外部影響,我們逐個運行了代碼的每個版本,然后又重復了10次這個序列:A、B、C、D、E、A、B.......因此典型運行的結果將看起來像下面的圖片。請注意,人們不應該依賴對不同圖表之間絕對運行時間的比較,但是對內部運行時間的比較是相當可靠的,這要歸功于我們的基準設置。
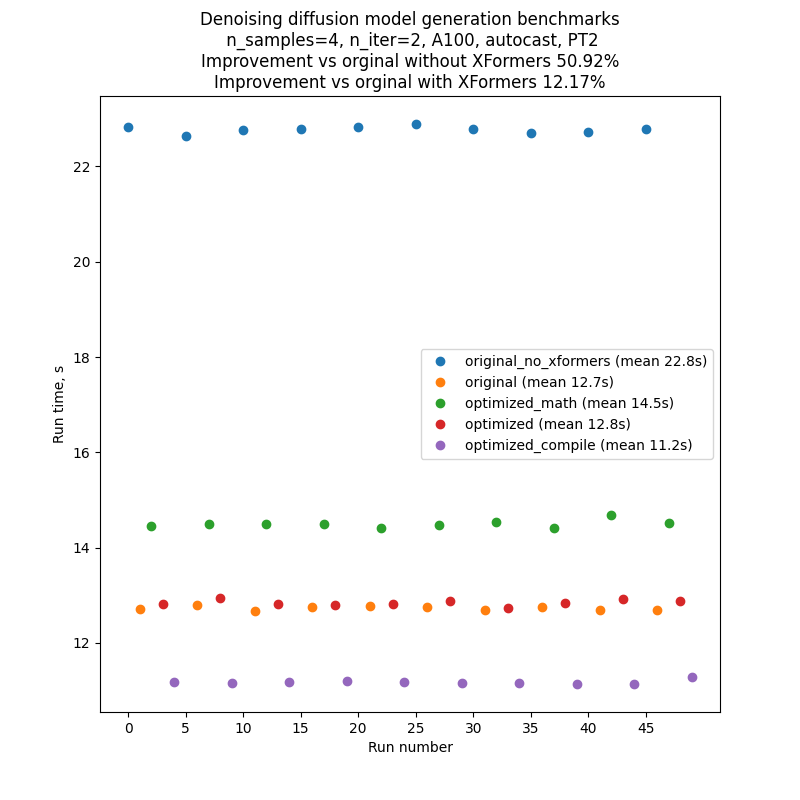
每卷文字到圖像生成腳本都產生幾批數,其數量受CLI參數管制--niter --niter。在我們使用的基準中n標準=2,但引入了額外的“暖化”迭代,這對運行時間沒有幫助。 這對編譯運行是必要的,因為編譯發生在代碼運行的第一次,因此第一次迭代的時間比后來的都要長。 為了比較公平,我們還將這種額外的“暖化”迭代引入了所有其他運行。
上表中的數字是迭代數2(加上“暖熱一號”),即時“A”照片,種子1,PLMS取樣器,自動打開。
基準使用p100 p100 (p100)、v100 (v100)、a100 (a100)、A10和T4GPUs完成,T4基準在Google Colab Pro完成,A10基準在G5.4xmall AWS實例中與1GPU完成。
結論和下一步步驟
我們已經表明,PyTorrch 2 - 編譯者和優化關注實施的新特點 -- -- 使性能改進超過或與以前要求安裝的外部依賴(舊前)的功能相仿;PyTorrch特別通過將舊前的內存有效關注納入代碼庫來實現這一點,這是對用戶經驗的重大改進,因為舊前是一家最先進的圖書館,在許多情形中,需要定制的安裝過程和長期建筑。
這項工作可以繼續往幾個自然方向發展:
我們在這里所實施和描述的優化只是為迄今為止的文字到圖像的推斷基準,有興趣了解它們如何影響培訓績效。 PyTorch匯編可以直接應用于培訓;PyTorch優化關注的扶持培訓正在路線圖中。
我們有意盡量減少對原示范守則的修改。 進一步的定性和優化可能帶來更多的改進。
目前,匯編工作只適用于取樣器內部的U-Net模型。由于在U-Net之外發生了很多事情(例如,在取樣環中直接作業),匯編整個取樣器將是有益的。然而,這需要對匯編過程進行分析,以避免在每一取樣步驟中進行重新匯編。
當前代碼僅在PLMS取樣器內應用編譯程序,但將其擴展至其他取樣器則微不足道。
除了文字到圖像生成外,還應用推廣模型來進行其他任務 -- -- 圖像到圖像和油漆。
審核編輯:彭菁
-
模型
+關注
關注
1文章
3173瀏覽量
48715 -
代碼
+關注
關注
30文章
4750瀏覽量
68357 -
編譯程序
+關注
關注
0文章
12瀏覽量
4129 -
pytorch
+關注
關注
2文章
803瀏覽量
13149
發布評論請先 登錄
相關推薦
基于擴散模型的圖像生成過程

如何在PyTorch中使用擴散模型生成圖像

Pytorch模型訓練實用PDF教程【中文】
將pytorch模型轉化為onxx模型的步驟有哪些
怎樣使用PyTorch Hub去加載YOLOv5模型
通過Cortex來非常方便的部署PyTorch模型
將Pytorch模型轉換為DeepViewRT模型時出錯怎么解決?
pytorch模型轉換需要注意的事項有哪些?
擴散模型在視頻領域表現如何?
如何改進和加速擴散模型采樣的方法1
如何改進和加速擴散模型采樣的方法2





 工商網監
工商網監
評論