") ASR算法實(shí)踐及部署方案
ASR算法實(shí)踐及部署方案
一
引言
語(yǔ)音識(shí)別(Automatic Speech Recognition)是AI領(lǐng)域的一項(xiàng)重要應(yīng)用,是一種將人的語(yǔ)音轉(zhuǎn)換為文本的技術(shù)。
其主要的應(yīng)用場(chǎng)景有:?jiǎn)为?dú)使用該技術(shù)的字幕生成,會(huì)議轉(zhuǎn)寫(xiě)以及聯(lián)合語(yǔ)音合成技術(shù)使用的智能助手、智能音箱、智能汽車等。
其中字幕生成包括視頻的離線字幕生成以及直播場(chǎng)景下的在線字幕生成。隨著短視頻和直播場(chǎng)景的興起,我們對(duì)自動(dòng)字幕的需求也越來(lái)越大,這對(duì)推理GPU的速度、延時(shí)和成本也是很大的挑戰(zhàn)。
本文將介紹ASR模型工作原理,離線字幕生成場(chǎng)景優(yōu)化,以及ASR在沐曦曦思N100人工智能推理GPU上如何做靜態(tài)部署,后者可作為其他序列生成模型的靜態(tài)化部署參考方案。
二
ASR模型介紹
一般聲音聲波輸入聲學(xué)模型前,會(huì)將語(yǔ)音預(yù)處理轉(zhuǎn)換為梅爾圖譜,即將聲音以一定的幀長(zhǎng)切成短幀,然后使用傅里葉變換得到頻譜,依照人類對(duì)不同頻率音頻的敏感程度不同,頻譜又經(jīng)過(guò)梅爾三角濾波器組,最后得到信息密度更高的梅爾頻譜作為ASR模型的輸入。
為了解決從梅爾頻譜到文字的對(duì)齊問(wèn)題,學(xué)界有兩種對(duì)齊方案:
對(duì)齊方案 1
不學(xué)習(xí)對(duì)齊,允許空格和重復(fù)輸出,直接在計(jì)算損失時(shí)使用CTC 損失得到規(guī)整后為正確結(jié)果的所有路徑概率和,讓概率和最大。本方案為非自回歸方案,速度快、易訓(xùn)練,但由于不考慮上下文,其結(jié)果容易造成結(jié)巴或漏字。
對(duì)齊方案 2
用序列到序列編碼器-解碼器的方式學(xué)習(xí)基于注意力的語(yǔ)音文字軟對(duì)齊。本方案為自回歸方案,考慮了上下文,精度更高,但對(duì)齊靈活性容易被干擾且解碼速度更慢。
目前效果較好且比較流行的語(yǔ)音識(shí)別端到端模型的一般結(jié)構(gòu)是結(jié)合前面兩種方案,即把兩種模型放在同一個(gè)模型結(jié)構(gòu)中,共享編碼器部分,以wenet模型[1]為例,其訓(xùn)練時(shí)的數(shù)據(jù)流向?yàn)椋?/p>
1
用語(yǔ)音預(yù)處理從語(yǔ)音波形中提取梅爾圖譜特征。
2
以conformer模型作為編碼器(綠色),進(jìn)一步提取和融合輸入特征。
3
注意力解碼器部分(紅色)在訓(xùn)練時(shí)為編碼器后接入一個(gè)基于注意力的解碼器,在只能看到歷史信息的掩碼限制下生成目標(biāo)句子,再對(duì)每個(gè)字得到平滑交叉熵?fù)p失。在前向推理時(shí),利用編碼器輸出和歷史解碼器結(jié)果自回歸生成下一個(gè)文字。(紅色部分)。
4
CTC 解碼器部分(黃色)在訓(xùn)練時(shí)為編碼器后接一個(gè)全連接層再接CTC損失,利用CTC規(guī)避訓(xùn)練時(shí)的語(yǔ)音文本對(duì)齊問(wèn)題,在前向推理時(shí)每幀得到空格或文字,對(duì)生成結(jié)果規(guī)整后即得到目標(biāo)語(yǔ)句。CTC 解碼器在前向推理時(shí)可以結(jié)合語(yǔ)言模型如n-gram語(yǔ)言模型一起使用,提升正確率。
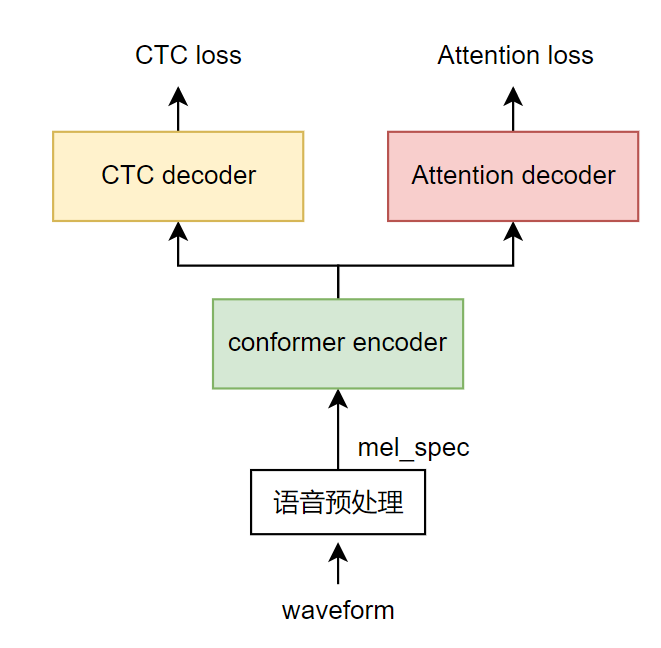
圖2 ASR模型結(jié)構(gòu)介紹
由于CTC head加ngram語(yǔ)言模型和注意力head均能生成結(jié)果文字,在落地使用時(shí)有多種解碼方式:
解碼方案 1
直接以CTC head結(jié)果為準(zhǔn),這種方案解碼速度很快,但正確率較低。
解碼方案 2
CTC head生成概率最高的topk句,由注意力 head分別為多句進(jìn)行評(píng)分,即整句每個(gè)字概率加和,選出top1的句子,這種方案正確率高于方案1,速度慢于方案1。
解碼方案 3
注意力head每個(gè)字生成后,結(jié)合該字在CTC head的分?jǐn)?shù)共同評(píng)估,得到當(dāng)前時(shí)刻的top1的字,這種方案正確率高于方案2,速度慢于方案2。
從方案1到方案3,正確率越來(lái)越高,解碼速度越來(lái)越慢。使用時(shí)可根據(jù)實(shí)際場(chǎng)景選擇。為確保正確率,一般采取后兩種方案。
三
字幕生成鏈路改進(jìn)
經(jīng)過(guò)調(diào)研和實(shí)驗(yàn),我們嘗試了一些讓生成字幕準(zhǔn)確率更高的方法,以下為完備有效的鏈路:

圖3 字幕生成鏈路
從視頻提取到音頻后,先使用傳統(tǒng)方法對(duì)背景音樂(lè)和噪聲進(jìn)行去除;然后啟用長(zhǎng)音頻切分,即利用深度學(xué)習(xí)方法檢測(cè)人聲,在合適的沒(méi)有檢測(cè)到人聲的地方把長(zhǎng)語(yǔ)音斷成許多短語(yǔ)音;接著將短語(yǔ)音送入ASR聲學(xué)模型,在熱詞的輔助下輸出識(shí)別結(jié)果;最后將結(jié)果送入糾錯(cuò)語(yǔ)言模型進(jìn)行一些簡(jiǎn)單的詞錯(cuò)誤糾正,得到最終的字幕文件。以上各模塊均能發(fā)揮一定的作用。
以下是鏈路中模塊加入前后的示例:
音頻原識(shí)別結(jié)果改進(jìn)后識(shí)別結(jié)果改進(jìn)原理
那這樣吧今天下午我來(lái)拿情臉那這樣吧今天下午我來(lái)拿行李前置去背景音樂(lè)模塊后ASR模型就能正確識(shí)別最后兩個(gè)字
不過(guò)你也知道我大姐的脾氣,他向來(lái)不主張明家的子弟去搞政治不過(guò)你也知道我大姐的脾氣,她向來(lái)不主張明家的子弟去搞政治原音頻為兩段,通過(guò)VAD后聚類后兩段合成一段,使得模型有更多前后信息,“她”字識(shí)別正確
喂清云我錯(cuò)了喂清俞我錯(cuò)了加入的熱詞中有角色名,解碼時(shí)優(yōu)先熱詞,“俞”字識(shí)別正確
下將具體介紹我們?cè)陂L(zhǎng)音頻切分模塊和ASR模型解碼模塊做的一些改進(jìn)。
3.1
長(zhǎng)音頻切分優(yōu)化
長(zhǎng)音頻切分模塊中,我們通過(guò)使用深度學(xué)習(xí)模型marblenet做語(yǔ)音活動(dòng)性檢測(cè),即判斷每一幀是人聲還是環(huán)境音,并通過(guò)模型蒸餾、構(gòu)造數(shù)據(jù)、加入更豐富影視數(shù)據(jù)等提升分類精度。
在得到幀分類后可通過(guò)設(shè)定pad_onset, pad_offset, min_duration.max_duration等參數(shù)找到切分點(diǎn),把長(zhǎng)句切分成多個(gè)短句,可根據(jù)實(shí)際需要調(diào)整以上參數(shù)數(shù)值。
同時(shí)由實(shí)驗(yàn)得到,多個(gè)相關(guān)短句合并成小長(zhǎng)句后識(shí)別效果常好于單個(gè)短句,原因是在解碼時(shí)能利用上文語(yǔ)義信息得到更好的結(jié)果,但太長(zhǎng)又會(huì)導(dǎo)致耗時(shí)和顯存增加。故在切分準(zhǔn)確的基礎(chǔ)上,我們通過(guò)一維時(shí)間聚類的方式,將距離較近的短句通過(guò)多輪融合,形成限定長(zhǎng)度內(nèi)的小長(zhǎng)句進(jìn)行識(shí)別。
具體的合并邏輯是所有短句按照由短到長(zhǎng)的優(yōu)先順序,每個(gè)短句左右擴(kuò)張pad_len,若觸達(dá)另一短句則合二為一。以上邏輯重復(fù)多次,pad_len也慢慢增大。同時(shí)在合并過(guò)程中如果長(zhǎng)度達(dá)到max_len則也不再擴(kuò)張。

圖4 短句聚合邏輯
以上邏輯能在合理范圍內(nèi),把時(shí)間上靠近的短句集合合成一句長(zhǎng)句,有利于在解碼時(shí)語(yǔ)言模型的信息獲取,使識(shí)別結(jié)果更加準(zhǔn)確。
3.2
ASR模型及解碼參數(shù)優(yōu)化
在電視劇場(chǎng)景中使用ASR模型首先會(huì)碰到背景噪聲問(wèn)題,我們?cè)谀P头矫嬉沧隽宋⒄{(diào)使得ASR模型對(duì)噪聲更加魯棒。具體的做法是取部分訓(xùn)練數(shù)據(jù),在訓(xùn)練時(shí)原語(yǔ)音隨機(jī)添加上腳步聲、人群嘈雜聲、環(huán)境聲等噪聲數(shù)據(jù),利用這些數(shù)據(jù)對(duì)原始模型進(jìn)行微調(diào),微調(diào)后字幕CER減少0.07%左右。
同時(shí),我們?cè)贑TC解碼時(shí)使用上了4_gram語(yǔ)言模型,以下是一些字幕生成場(chǎng)景下ASR模型解碼參數(shù)調(diào)整經(jīng)驗(yàn):
1
電視劇涉獵較廣,如古裝電視劇常出現(xiàn)成語(yǔ),商業(yè)電視劇常出現(xiàn)經(jīng)濟(jì)用語(yǔ)等,可根據(jù)實(shí)際需要針對(duì)性地增加4_gram語(yǔ)言模型的訓(xùn)練語(yǔ)料。
2
也可把上述4_gram語(yǔ)言模型換成bert或者加入bert,能提升一些識(shí)別正確率但是嚴(yán)重影響解碼速度,故工程上還是建議4_gram語(yǔ)言模型。
3
電視劇語(yǔ)氣詞較多,若要保留這些語(yǔ)氣詞,防止使用語(yǔ)言模型后語(yǔ)氣詞消失,需調(diào)高識(shí)別成空格的閾值,blank_skip_thresh可設(shè)為0.99。
4
與上同理,為保留更多語(yǔ)氣詞適當(dāng)增加WFST解碼時(shí)聲學(xué)模型的概率,acoustic_scale可設(shè)為2。
5
為讓熱詞發(fā)揮更好的效果,可適當(dāng)調(diào)大熱詞權(quán)重,context_score可設(shè)為10。
總的來(lái)說(shuō),在影視劇字幕生成領(lǐng)域中,我們發(fā)現(xiàn)長(zhǎng)音頻切分的好壞對(duì)字幕結(jié)果起到了決定性作用。同時(shí)將wenet模型用于部署時(shí)可根據(jù)使用場(chǎng)景對(duì)模型或者解碼參數(shù)進(jìn)行一些微調(diào),能在目標(biāo)領(lǐng)域變得更加準(zhǔn)確。通過(guò)以上改進(jìn)再加上鏈路上的前后處理,我們測(cè)試集上平均字錯(cuò)率由16.57%下降到12.11%。僅從識(shí)別準(zhǔn)確度看,比當(dāng)前最好的商用軟件效果略好。
四
ASR部署
出于對(duì)推理速度的要求,一般需要將訓(xùn)練好的模型部署在GPU上使用, ASR模型輸入shape是動(dòng)態(tài)變化的,為達(dá)到靜態(tài)化部署的目的,這里采用padding-分桶思路來(lái)支持動(dòng)態(tài)輸入,本方案對(duì)其他編碼器_解碼器類生成式任務(wù)的靜態(tài)化部署都有借鑒意義。
在ASR中,輸入的語(yǔ)音長(zhǎng)度是變化的,即編碼器的輸入輸出,CTC 解碼器的輸入輸出以及注意力解碼器的輸入輸出都是變化的,中間特征的長(zhǎng)度會(huì)隨著輸入語(yǔ)音長(zhǎng)度的變化而變化。
為固定輸入長(zhǎng)度,我們將輸入語(yǔ)音pad到最長(zhǎng)語(yǔ)音長(zhǎng)度max_speech_len,之后用mask控制計(jì)算的范圍,同時(shí)使用注意力解碼器時(shí)也把歷史文字輸出pad到最長(zhǎng)文字長(zhǎng)度max_word_len,之后用valid_len來(lái)表示本次前向要生成的文字編號(hào)。具體來(lái)說(shuō),需要對(duì)編碼器編碼模塊和注意力解碼模塊做一定的調(diào)整。
實(shí)踐使用中,可以設(shè)置多個(gè)梯度max_speech_len,實(shí)際使用中按照輸入語(yǔ)音長(zhǎng)度分桶,用對(duì)應(yīng)最大長(zhǎng)度模型解碼。
4.1
encoder模塊部署
其中,encoder的具體模型結(jié)構(gòu)如下:
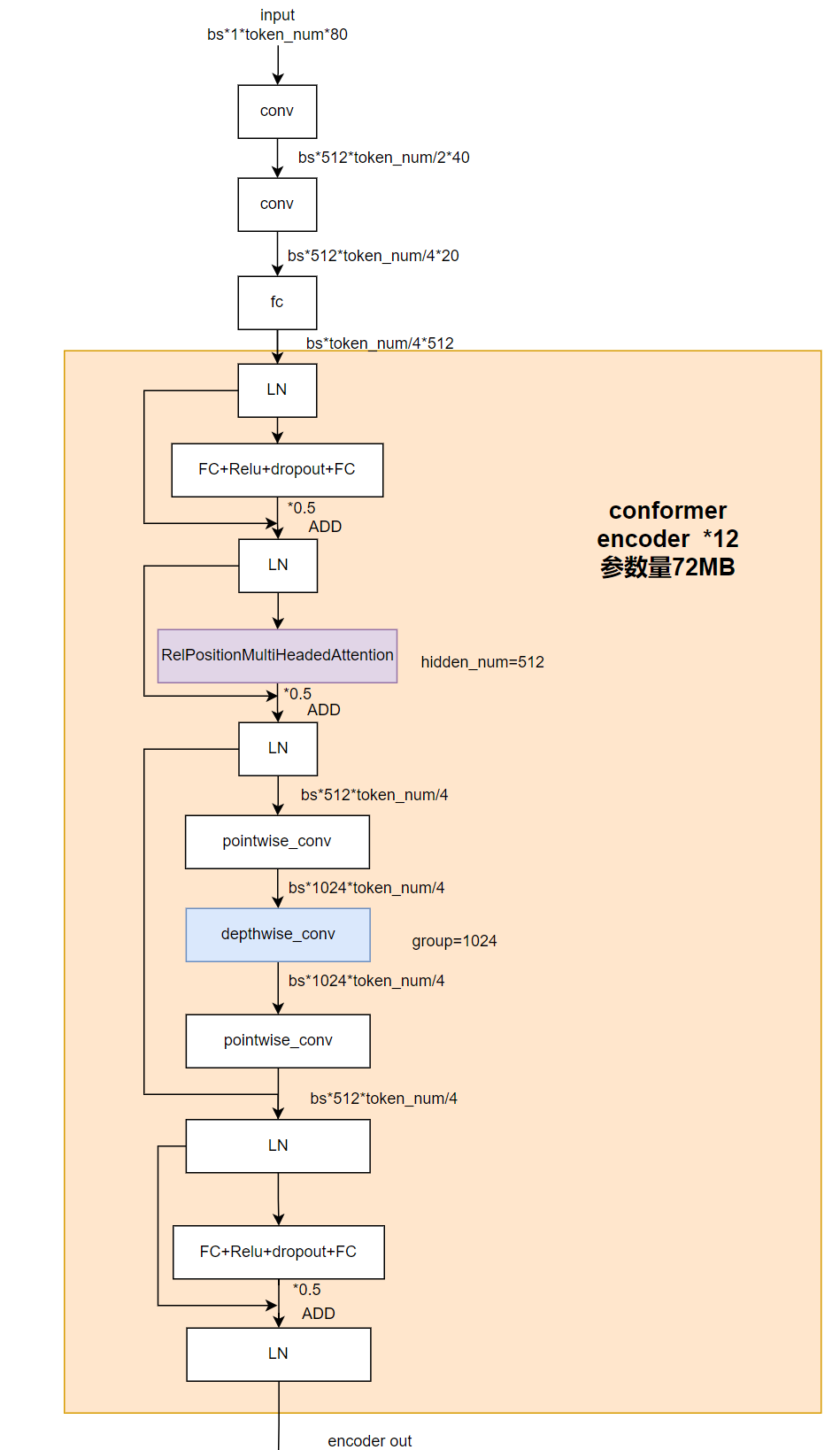
圖5 encoder部分細(xì)節(jié)結(jié)構(gòu)圖
其中token_num取決于輸入語(yǔ)音的長(zhǎng)度,是可變的,為剔除動(dòng)態(tài)性我們將該維度pad到最大,但是直接padding會(huì)影響softmax計(jì)算和conformer結(jié)構(gòu)里相對(duì)位置編碼以及depthwise卷積部分,為了消除對(duì)計(jì)算結(jié)果的影響,需要對(duì)模型結(jié)構(gòu)進(jìn)行微調(diào)。
4.1.1
消除Padding對(duì)softmax計(jì)算的影響
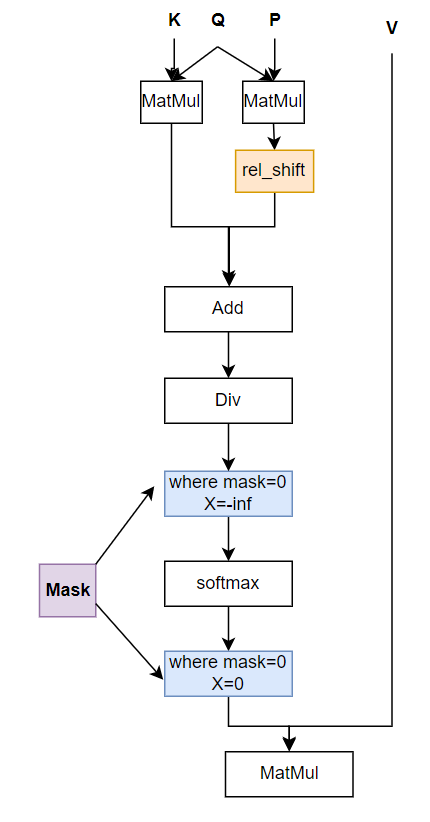
圖6 encoder部分RelPositionAttention模塊前向圖
模型的輸入改為:
input_pad:pad后的input
mask:記錄了input_pad中有效的長(zhǎng)度,其中mask的前valid_len個(gè)為1,后面為0
mask中包含有效長(zhǎng)度信息后能去除掉計(jì)算中pad部分的影響。
4.1.2
消除Padding對(duì)rel_shift的影響
如上圖中所示,espnet工程中matrix_bd會(huì)先經(jīng)過(guò)rel_shift來(lái)達(dá)到把matrix_bd中絕對(duì)位置編碼改成相對(duì)位置編碼的目的,原代碼的實(shí)現(xiàn)方式為:
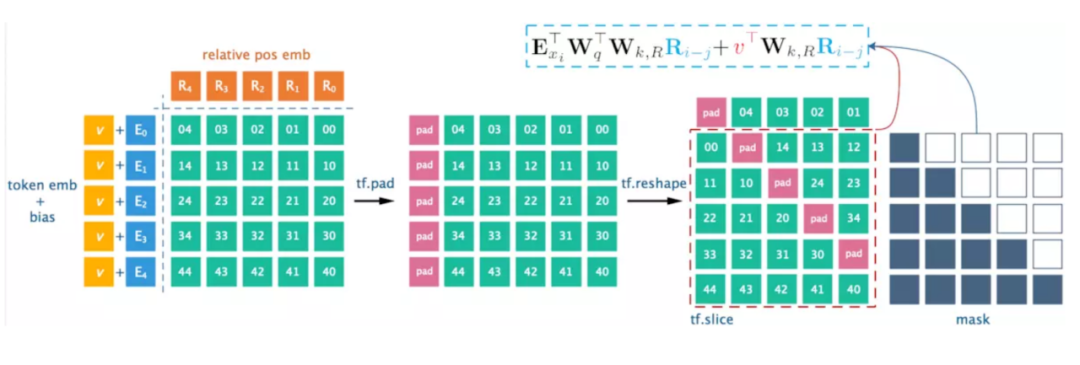
圖7 rel_shift 實(shí)現(xiàn)方式
來(lái)源:https://zhuanlan.zhihu.com/p/74485142
通過(guò)對(duì)矩陣的pad+reshape達(dá)到相對(duì)位置編碼的作用。
輸入作pad填充后token_emb后面為無(wú)效特征,再用pad+reshape方式rel_shift,會(huì)導(dǎo)致無(wú)效特征前移錯(cuò)位。
我們這里先分別用gather操作得到左下角和右上角矩陣,再利用一個(gè)半角mask將兩個(gè)矩陣進(jìn)行合并。最后對(duì)多余部分進(jìn)行置0操作,得到和原rel_shift操作結(jié)果一致(只是做了pad)的結(jié)果。
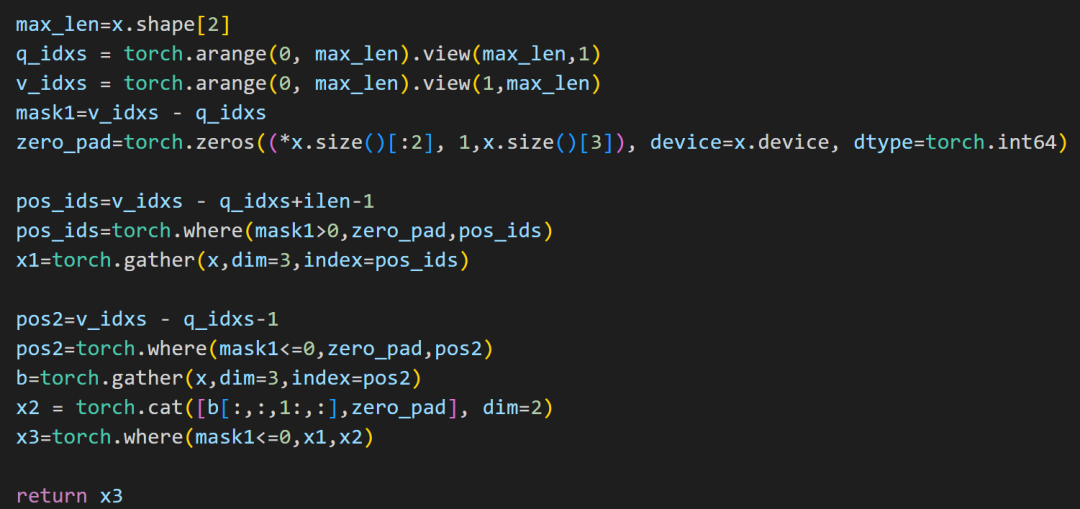
圖8 輸入pad后復(fù)現(xiàn)rel_shift 方案
4.1.3
消除Padding對(duì)depthwise_conv的影響
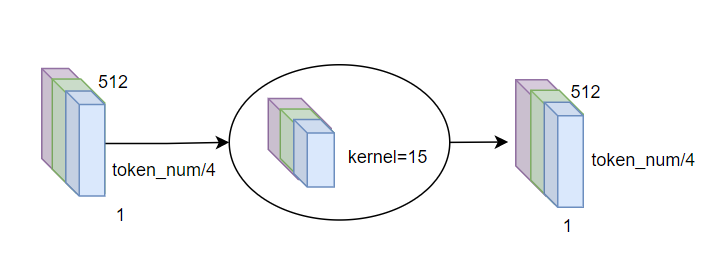
圖9 輸入pad后復(fù)現(xiàn)rel_shift方案
conformer模塊中使用了分組卷積,前后分別進(jìn)行pointwise conv和1D depthwise conv。由于token_num/4維度我們會(huì)pad到最大,此時(shí)由于depthwise conv kernel》1,會(huì)讓無(wú)效特征也參與計(jì)算干擾結(jié)果。
解決方案是在depthwise前加一步根據(jù)mask的歸0操作,把pad進(jìn)去部分的特征都?xì)w0。
4.2
Attention decoder模塊部署
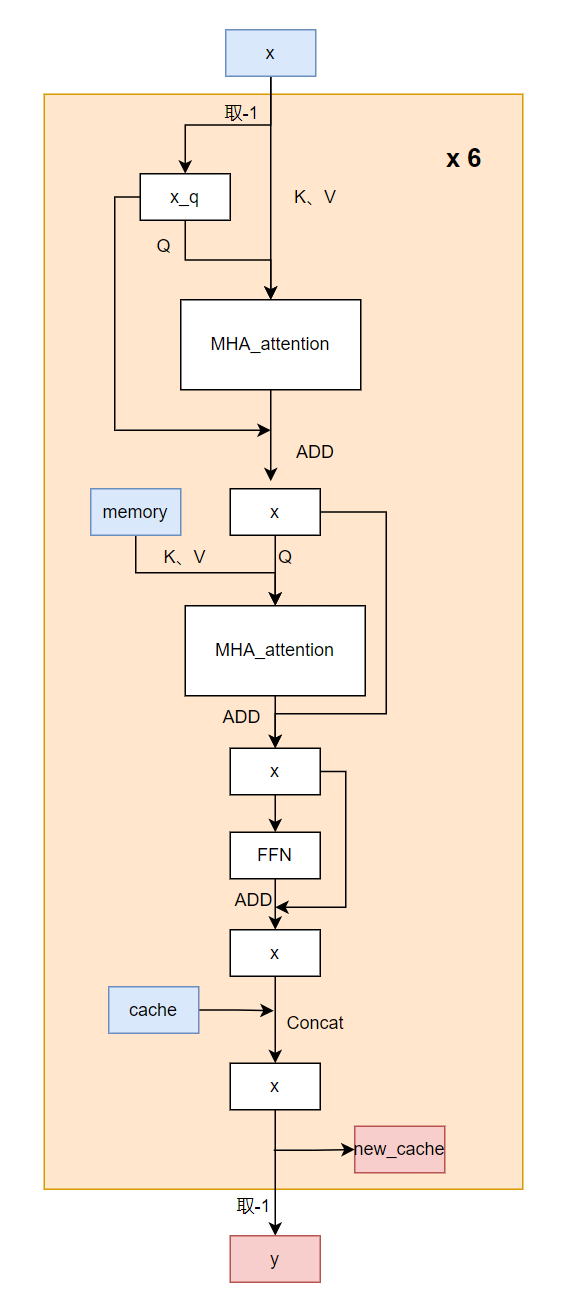
圖10 encoder部分細(xì)節(jié)結(jié)構(gòu)圖
Attention decoder每次調(diào)用只生成一個(gè)字。其輸入是encoder output特征,我們記作memory,以及歷史生成的字x,輸出是語(yǔ)音的下一個(gè)字。生成一句N個(gè)字的句子需要調(diào)用Attention decoder N+1次,在遇到標(biāo)簽或者達(dá)到最高字?jǐn)?shù)時(shí)停止。
這里模型調(diào)用了6層decode layer,每層由一個(gè)self attention以及一個(gè)cross attention組成,為減少重復(fù)計(jì)算,會(huì)保存每次每層decoder layer的輸出(我們記作cache),在下一次計(jì)算時(shí)只計(jì)算每層最新的一個(gè)token結(jié)果然后和保存的concat,再輸往下一層,同時(shí)為下一次decoder保存當(dāng)前new_cache。
原始輸入為x,memory和cache。
要把Attention decoder改為固定長(zhǎng)度輸入,需要做的修改如下:
1
self attention部分:x改為x_pad和x_q,這里x表示歷史的n無(wú)法根據(jù)index動(dòng)態(tài)抽取,我們提前將最后一個(gè)token單獨(dú)提取出來(lái)作為外部傳入的輸入x_q,x_q為x_pad里有效的最后一個(gè)token,注意需手動(dòng)加上對(duì)應(yīng)位置的position embedding。
2
cross attention部分:保持前面self attention的結(jié)果作為把原始的不定長(zhǎng)的memory改為encoder output輸入的pad后memory,同時(shí)加上memory mask以指示有效長(zhǎng)度,防止關(guān)注到pad的部分,用于cross attention部分。
3
self attention和cross attention組成一層完整的decoder層,在生成一層decoder輸出x_q后,在動(dòng)態(tài)輸入操作中,需要把之前保存的該層輸出前面token結(jié)果concat到x_q上去,這也屬于動(dòng)態(tài)維度的操作,部署中無(wú)法使用,而在我們靜態(tài)輸入中,則選擇where操作把x_q拷貝到pad后的state的第valid_len-1位置上去,故這里需要valid_len作為輸入來(lái)進(jìn)行拷貝引導(dǎo),這里的valid_len是用于指示當(dāng)前共有幾個(gè)字,即我們關(guān)注的是第幾個(gè)token的輸出,在使用時(shí)每次調(diào)用valid_len加一。
4
取最后一層decoder的輸出的x_q,經(jīng)過(guò)一層softmax層得到最終的token概率分布。
修改后的輸入為x_pad,x_q,memory,memory_mask,cache和valid_len,
修改后的代碼流程如下:
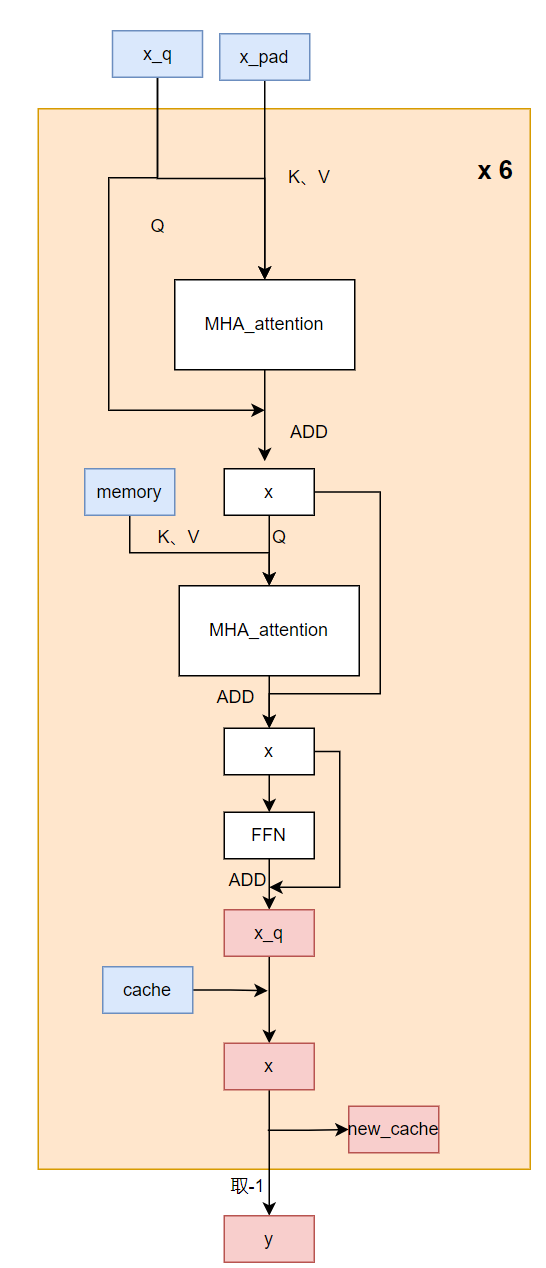
圖11 attention decoder部分修改后示意圖
五
小結(jié)
以上介紹了語(yǔ)音識(shí)別技術(shù)的應(yīng)用場(chǎng)景,語(yǔ)音識(shí)別算法的原理、難點(diǎn)和解決方案,也介紹了我們?cè)谧帜簧蓤?chǎng)景中所做的實(shí)踐。微調(diào)開(kāi)源模型加上細(xì)致的前后處理,在我們的測(cè)試集上能夠達(dá)到較好的可使用效果。未來(lái)ASR瓶頸更多的在于如何提升識(shí)別速度,以及在復(fù)雜場(chǎng)景下怎樣結(jié)合其他技術(shù)優(yōu)化ASR結(jié)果。
最后我們?yōu)锳SR在沐曦曦思N100人工智能推理GPU上做了較好的靜態(tài)部署,通過(guò)pad加mask的方案使動(dòng)態(tài)輸入達(dá)成固定長(zhǎng)度,為保持計(jì)算邏輯不變,我們也對(duì)模型編碼器和注意力解碼器部分做了許多調(diào)整,該解決方案可作為其他序列生成模型的靜態(tài)化部署參考。
-
算法
+關(guān)注
關(guān)注
23文章
4601瀏覽量
92677 -
ASR
+關(guān)注
關(guān)注
2文章
42瀏覽量
18701 -
模型
+關(guān)注
關(guān)注
1文章
3178瀏覽量
48731 -
傅里葉變換
+關(guān)注
關(guān)注
6文章
438瀏覽量
42566
原文標(biāo)題:【智算芯聞】ASR算法實(shí)踐及部署方案
文章出處:【微信號(hào):沐曦MetaX,微信公眾號(hào):沐曦MetaX】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
最新一款LoRa 集成了單芯片SoC ASR6501/ASR6502
國(guó)內(nèi)全新LoRa系統(tǒng)芯片ASR6505 內(nèi)置SOC
ASR6501與SX1262優(yōu)勢(shì)區(qū)別
簡(jiǎn)化針對(duì)云服務(wù)的語(yǔ)音檢測(cè)算法的部署
怎樣去驗(yàn)證可部署目標(biāo)硬件與軟件算法模型之間的算法性能一致性?
asr翱捷LORA系列芯片選型參考推薦ASR6601/asr6505/asr6501/asr6500
ASR控制系統(tǒng),ASR控制系統(tǒng)是什么意思
基于粒子群優(yōu)化PSO算法的部署策略
docker compose一鍵打包部署項(xiàng)目的實(shí)踐
解決自動(dòng)語(yǔ)音識(shí)別部署難題





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論