 中科大&字節提出UniDoc:統一的面向文字場景的多模態大模型
中科大&字節提出UniDoc:統一的面向文字場景的多模態大模型
這篇文章是由中科大和字節跳動合作,在2023年8月23日上傳到arXiv上的文章。這篇文章提出UniDoc,一個統一的多模態大模型(LMM)。UniDoc主要聚焦于包含文字的圖像的多模態理解任務。相比于以往的多模態大模型,UniDoc具備它們所不具備的文字檢測、識別、spotting(端到端OCR)的能力。此外,文章中實驗表明,這些能力的學習能夠彼此促進。
方法框架
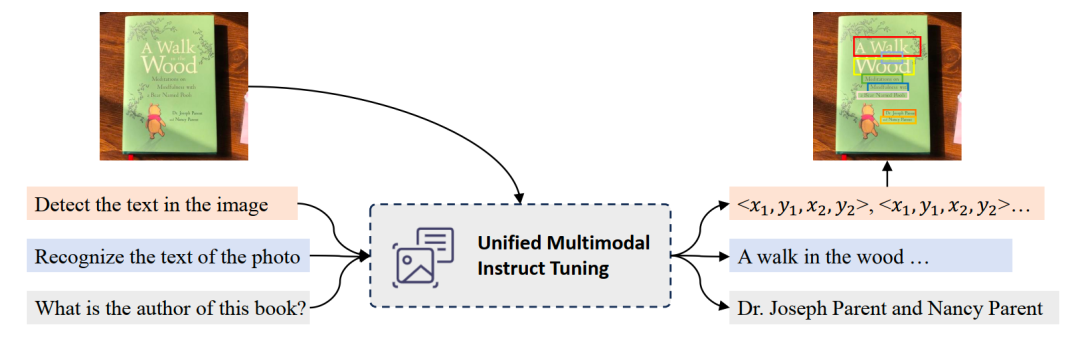
如上圖所示,UniDoc基于預訓練的視覺大模型及大語言模型,將文字的檢測、識別、spotting(圖中未畫出)、多模態理解等四個任務,通過多模態指令微調的方式,統一到一個框架中。具體地,輸入一張圖像以及一條指令(可以是檢測、識別、spotting、語義理解),UniDoc提取圖像中的視覺信息和文字信息,結合自然語言指令以及大語言模型的世界知識,做出相應回答。
訓練數據采集

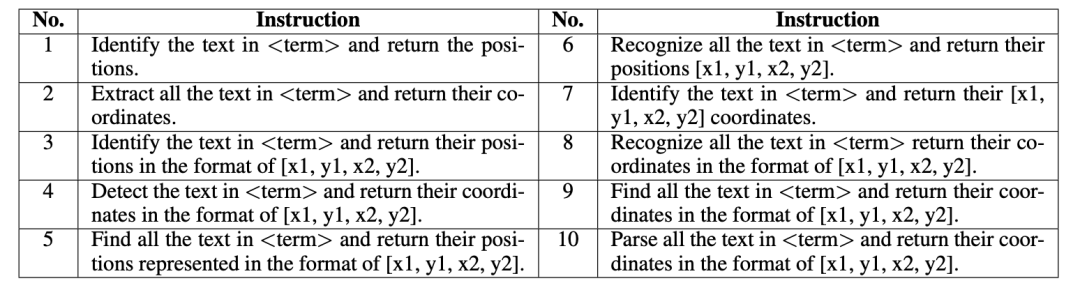
作者團隊收集了大量的PPT圖像,并提取其中文字實例和對應的bbox。在此基礎上構建多任務的指令微調數據集。文章認為,PPT圖片中文字具有各種各樣的大小、字體、顏色、風格等,且PPT中視覺元素豐富多樣,適合用于構建涉及文字圖像的多模態任務的訓練。以spotting任務為例,其指令如下圖所示。其中的 term 表示”imgae“,”photo“等隨機名詞,以增加指令多樣性。
實驗結果
多模態理解


從上述六個例子可以看到,UniDoc不僅可以有效提取圖像中的視覺信息、文字信息,更可以結合其豐富的世界知識進行合理地回答。

對于無文字的圖像,UniDoc同樣可以準確地進行問答。
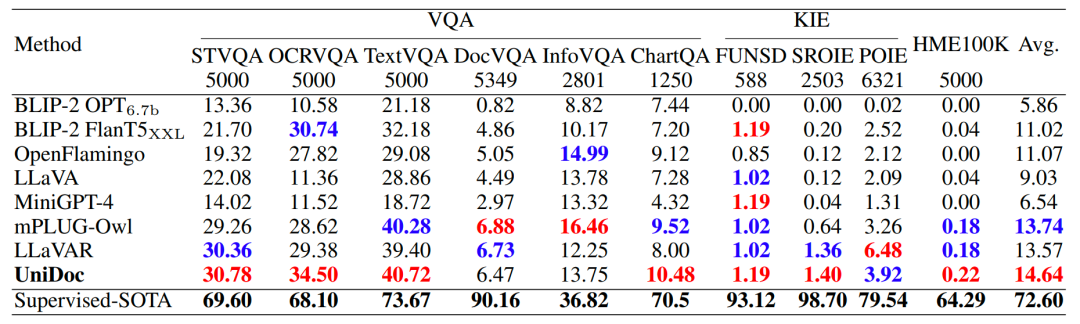
在多個多模態問答基準數據集上,UniDoc實現了優越的性能。
文字檢測、識別、spotting

上圖中,第一行的四個case來自于WordArt數據集,第二行的四個case來自于TotalText數據集。可以看到,雖然這些行級別的文字圖像呈現不同的字體以及不規則的文字分布,UniDoc仍然能夠進行準確地識別。

上圖中六個case中,文字存在部分的缺失,UniDoc仍然能夠進行準確地識別。

上圖中四個case展示了UniDoc在TotalText數據集上的檢測效果。
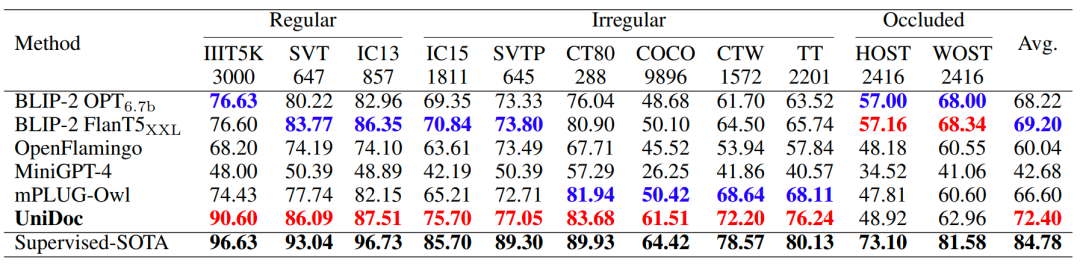
在多個文字識別基準數據集上,UniDoc實現了優越的性能。
消融實驗

有趣的消融實驗:對于同一張輸入圖像,spotting指令(右)規避了識別指令(左)的識別遺漏現象。
-
語言模型
+關注
關注
0文章
504瀏覽量
10245 -
數據集
+關注
關注
4文章
1205瀏覽量
24641 -
大模型
+關注
關注
2文章
2322瀏覽量
2479
原文標題:中科大&字節提出UniDoc:統一的面向文字場景的多模態大模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

《日本經濟新聞》報道:中科大為何能對中國AI領域產生很的影響?
在醫療AI領域砥礪前行的中科大學子
北大&amp;華為提出:多模態基礎大模型的高效微調






 工商網監
工商網監
評論