 ChatGPT和OpenAI都在用的Redis,是如何從傳統數據庫升級為向量數據庫的?
ChatGPT和OpenAI都在用的Redis,是如何從傳統數據庫升級為向量數據庫的?
各行業的公司越來越認識到,制定數據驅動的決策是現在、未來 5 年、未來 20 年甚至更長時間內競爭的必要條件。數據增長(尤其是非結構化數據增長)達到了前所未有的水平,數據泛濫和人工智能時代已經來臨。
這一現實隱含的是,人工智能可以對海量數據進行有意義的分類和處理——不僅對 Alphabet、Meta 和微軟等擁有龐大研發業務和定制人工智能工具的科技巨頭是這樣,對普通企業甚至中小型企業而言也是如此。
精心設計的基于人工智能的應用程序可以極快地篩選極其龐大的數據集,以產生新的見解并最終推動新的收入來源,從而為企業創造真正的價值。但是,如果沒有新出現的新事物——向量數據庫,任何數據增長都無法真正實現可操作性和民主化。
隨著大語言模型的爆火,向量數據庫也成為了熱門話題。只需幾行簡單的 Python 代碼,向量數據庫就可以充當大語言模型廉價但高效的“外部大腦”。但我們真的需要一個專門的向量數據庫嗎?向量數據庫究竟是炒作還是剛需?
近期,在北京 QCon 大會之際,InfoQ 有幸采訪到了 Redis 高級架構師史磊,聽他聊一聊 Redis 向量數據庫技術實踐。
在 9 月 3-5 日即將召開的 QCon 北京 2023 上,Redis 高級架構師史磊將帶來以 《搜索、探索、求索:Redis 向量數據庫》 為主題的演講分享。會前,InfoQ 對史磊老師進行了專訪,聽他聊一聊 Redis 向量數據庫技術實踐。
以下為訪談實錄,經編輯。
InfoQ:史磊老師您好,能先做下自我介紹嗎?
史磊:我目前在 Redis 工作,擔任高級產品架構師,負責管理 Redis 在亞太區的技術事務。我的主要職責是協助 Redis 客戶優化他們的 Redis 實例,指導他們在使用 Redis 的新功能時能夠得到最佳體驗;以及幫助 Redis 在中國的服務商取得成功。
作為 Redis 原廠,我們維護著開源社區版,并且提供了企業版(Redis Enterprise)的軟件。在亞太區,越來越多的客戶開始了解 Redis 企業版的價值。然而,目前大多數人對 Redis 的理解還停留在開源版本或者一些經過修改的第三方版本上,對于 Redis 的核心功能和應用場景可能了解有限。因此,我主要的使命是幫助客戶更好地利用 Redis 提供的工具,解決實際問題,滿足業務需求。
我在去年加入 Redis,之前我在新加坡從事科研工作,后來在一家金融科技創業公司負責開發 AI 產品。在那個公司,我已經使用 Redis 大約七八年時間,但主要限于開源版。加入 Redis 原廠后,我更深入地了解了 Redis 企業版,掌握了更多強大的功能。我希望借助自己的經驗,幫助客戶充分發揮 Redis 的潛力。
InfoQ:您是什么時候開始關注向量數據庫這個領域的?
史磊:在加入 Redis 之前,我主要從事 AI 和大數據方面的產品開發。我涉獵過特征生成、存取方式以及實時 AI 處理等領域,并使用了許多工具。然而,直到我加入 Redis 原廠,我才真正了解到 Redis 也在向量數據庫方向提供支持。Redis 的這種布局實際上已經有一段時間了。
我們最初是通過一個搜索模塊來支持搜索功能,這個模塊從大約 2018 年開始就存在了。Redis 2.0 的搜索功能將其提升到了一個新的水平,使其更加容易和方便。從 Redis 2.4 開始,也就是去年 3 月份開始,我們正式支持向量搜索。在大型語言模型引起轟動之前,Redis 就已經開始在向量數據庫領域布局。由于 Redis 在各行業廣泛應用,一經推出向量搜索功能,全球范圍內的許多客戶就開始使用了。
隨著大型語言模型的興起,向量數據庫的應用進入了新的階段。起初,人們可能只是用向量查詢來處理簡單的圖片、視頻、音頻或文檔等內容,提取和搜索一些基本的向量特征。但隨著大型模型的普及,人們開始探索如何更好地使用向量數據庫,將其應用到更高的維度、更廣泛的范圍以及更快的請求速度上。對于一個向量數據庫而言,以前大家的認識更多是小眾、性能要求不高,而現在這些觀念正在被快速轉變。在這個過程中,Redis 經歷了很多考驗。作為一個向量數據庫,隨著大型模型的興起,許多核心企業應用,比如像 ChatGPT、OpenAI 這樣的應用,開始在后臺使用 Redis。這使得 Redis 在滿足客戶需求方面有了更多的合作機會。
同時,Redis 的搜索模塊也在不斷發展壯大。我們通過收集來自客戶的第一手資料,產品團隊將客戶在實際應用中遇到的需求以及在 AI 和大數據環境下的新需求,迅速轉化為產品,更好地為客戶提供服務。
Redis 向量數據庫技術實踐
InfoQ:我注意到您提到了 ChatGPT 和 OpenAI,他們已經在使用 Redis。那他們是否將 Redis 作為唯一的向量數據庫使用?這方面有哪些信息可以分享嗎?
史磊:根據我了解,ChatGPT 和 OpenAI 并不僅僅使用 Redis 作為唯一的向量數據庫,他們也在與其他向量數據庫合作。因為技術的更新和迭代非常迅速,Redis 已經成立了專門的團隊來負責向量數據庫的研究和開發,并與多個不同的企業合作。
在 Redis 的官網上,我們已經展示了與許多 AI 大模型領域的合作案例,包括與 ChatGPT 等的合作。然而,具體細節和哪些實際用例正在使用 Redis,以及它們的具體情況,因為這些領域變化迅速,所以我目前沒有最新的相關信息。
InfoQ:您之前提到的是在 2018 年,Redis 引入了向量搜索的模塊。當時具體是什么情況?我們是基于客戶需求開發這個功能的嗎?還是我們自己看到了這個大的趨勢?
史磊:從 2018 年開始,Redis 引入了一個搜索模塊。當時,這個搜索模塊主要支持標量搜索,而不是向量搜索。在那時,Redis 使用中的一個痛點是,盡管它是一個內存中的鍵值存儲系統,查詢時如果不逐個掃描每個鍵,就沒有很好的方法來根據查詢條件檢索數據。
因此,2018 年的版本主要是為了解決搜索這一痛點。它允許用戶在 Redis 中存儲大量的鍵,而且這些鍵的檢索速度非常快。但是,如何在這些鍵中快速找到滿足特定條件的數據呢?通過內部迭代和升級,從 1.0 版本到 2.0 版本,我們收集了許多客戶的需求。這些需求主要集中在如何快速創建索引、如何快速執行查詢,以及如何讓應用程序自動完成這些操作。2020 年我們推出的 2.0 版本中就著重于這些方面。隨后,在 2.4 版本中(從去年 3 月開始,在 ChatGPT 等大模型流行之前),我們正式引入了向量搜索功能。在這個過程中,我們收到了許多客戶的請求,他們問是否可以將 Redis 的快速標量搜索擴展到向量化數據的搜索。我們的產品團隊聽取了這些客戶的需求,在初期支持了基本的向量相似性搜索功能。
隨著時間的推移,我們不斷地加入各種主流搜索模式和算法,逐步完善這個功能,使其變得更加成熟。現在,Redis 在 7.2 版本中進行了重大更新,帶來了許多新功能。值得注意的是,我們不再將搜索作為一個模塊進行推廣,而是將其視為 Redis 提供的主要功能之一。這意味著 Redis 不僅可以用作緩存和主數據庫,還可以用作向量數據庫。
InfoQ:隨著功能的增加,Redis 的定位也發生了一些變化?
史磊:是的。最初,Redis 的產品定位確實是作為一種內存數據庫,專注于提供內存存儲,并通過模塊來擴展其功能。然而,隨著時間的推移,我們對 Redis 進行了重新定位。現在,我們提供了 Redis 企業版軟件,將所有功能集成在其中。只要使用 Redis 企業版,就能夠獲得全部功能,無需額外購買或部署特定組件,即可直接使用。
對于客戶而言,如果他們已經在使用 Redis 作為緩存,他們現在只需將向量存儲到 Redis 中,便可以直接進行向量搜索。這對客戶來說非常直觀且易用,同時也不會增加額外的系統復雜性,無需引入其他產品或功能。
InfoQ:我想了解一下關于這個模組研發歷程的情況,以及它在研發過程中所經歷的一些迭代。此外,當它與 Redis 數據庫結合時,是否遇到了什么問題?如果有技術上的難題,您是如何解決的?能介紹一下相關的技術實踐過程嗎。
史磊:Redis 在不同領域的廣泛應用促使我們從各個領域收集了對 Redis 搜索的需求。起初,有客戶提出了希望在內存中進行向量搜索的需求。我們認真傾聽了這些客戶的意見,并著手實現這個功能。
在實現過程中,從初始的 POC(Proof of Concept)項目開始,我們將這個功能作為一個附加組件添加到 Redis 中。隨著時間的推移,我們將它演變成了 Redis 的主推功能。在這個過程中,Redis 的主產品與我們的模組功能相互協同進化。舉個例子來說,Redis 企業版在解決日常應用中的痛點方面擁有許多特性,比如內建的強大代理(proxy)。這個代理能夠自動將請求導向相應的分片,不管是單一分片還是集群模式,從而保證了 Redis 的存儲和吞吐量能夠自動調整,無需額外干預。對客戶而言,借助內建的代理,可以簡化業務邏輯,無需關心是單一模式還是集群模式。這同時也解決了搜索的難題,因為 Redis 每個分片是單線程模式,如果請求集中在一個分片上,性能會受到影響。但如果使用集群模式,客戶端需要維護連接并了解每個分片上的數據,這會使得業務邏輯變得復雜。
企業版解決了這些困難,同時也使得搜索更加容易。在 Redis 集群版中,由于已經內置了代理,搜索請求能夠自動分配到各個分片上執行,并以最低的成本整合結果。這確保了 Redis 在搜索中不再受制于單一分片的性能,同時提供更大量、更快速的搜索。這種搜索的擴展性和速度得益于 Redis 企業版內置的代理。
在開發 Redis 搜索過程中,由于需要維護額外的數據結構,如索引,我們的產品團隊進行了優化,確保快速的分配和查詢這些結構,使得 Redis 企業版性能比開源版有了顯著提升。
此外,我們正在推出的企業版本中,包括最新的 7.2 版本,已經引入了預覽版的功能。在搜索方面,我們解決了每個分片上搜索仍然受限于單線程限制的問題。通過多線程方式,我們實現了同時搜索,這在測試中已經實現了超過 10 倍甚至 16 倍的性能提升。這也說明了搜索有許多方法可以進一步優化性能,這是一個不斷進化和不斷完善的過程。
InfoQ:把上述功能融入到 Redis ,賦能 Redis 數據庫,時間上花了多久呢?
史磊:這項技術的演進過程從最初的討論到研究,再到研發,以及現在的預覽版功能,經歷了相當長的時間。根據我了解,這個功能的實際測試時間至少超過一年,從最初的討論到實際測試的過程確實需要一段時間。而在規劃和實施這些功能之前,所花費的時間絕對不止一年。
Redis 的產品團隊投入了大量的時間和精力,甚至設立了一個專門的團隊,負責確定 Redis 作為向量數據庫需要實現的功能。這個團隊需要思考有哪些核心組件可以完成這些功能,還需要與其他團隊合作。整個過程需要跨足多個團隊的合作,因此這是一個長期發展的過程。
InfoQ:鑒于大模型如此受歡迎,以及數據庫的重要性,您是否認為在這個人工智能與大數據的時代,數據庫變得尤為重要?是否必須要研發新的數據庫,以滿足不斷增長的需求?
史磊:我認為現在的向量數據庫已經成為剛需,因為它解決了傳統數據庫無法解決的幾個核心問題。傳統數據庫主要基于關鍵詞進行精確搜索,即存在或不存在的模式。而向量數據庫提供的是近似搜索,當我提供一張圖片、一段文字或者一個語音時,它能夠找到相似的匹配項,而不僅僅是 0 和 1 的結果。它通過打分機制給出近似值,這是傳統數據庫無法實現的。
同時,傳統的關系型數據庫的索引方法也無法直接適用于現在的向量數據庫。因為在底層,包括計算、數據存儲以及應用層面,向量數據庫與傳統數據庫完全不同。起初,向量數據庫可能只是作為關系數據庫的一個補充。然而,隨著大數據、大模型和人工智能的發展,對于向量的存儲和查詢以及快速性能都提出了更高的要求,只有向量數據庫才能夠滿足這些要求。
向量數據庫的需求會持續上升嗎
InfoQ:未來向量數據庫的需求會持續上升嗎?
史磊:我認為這是一個持續上升的過程。隨著大模型的興起,對向量數據庫的需求不斷增加。許多傳統的向量數據庫也在不斷進行迭代和更新,一些以前不支持向量數據庫的產品也在聲稱自己支持,不斷地添加這一功能。因此,這種需求將持續存在,這是一個不斷洗牌、淘汰不足的過程。
InfoQ:目前有一些人認為未來的每個數據庫都會自然而然地、本地支持向量嵌入和向量搜索。您對這種觀點有何看法?如果這種趨勢確實出現,它會對向量數據庫行業產生什么影響,可能會有哪些積極的方面,或者可能會帶來哪些挑戰?
史磊:從技術角度來看,幾乎任何存儲系統或查詢系統都可以通過添加功能來支持向量搜索、查詢或存儲。從這個角度來說,技術上并沒有問題。然而,在實際應用中,我們可能會逐漸趨向于一種或兩種常用的類型,其他的方式可能會逐漸淘汰。盡管它們都是數據存儲或數據庫系統,但它們通過不同的方法來滿足索引和查詢的需求。傳統的數據庫很難直接支持向量查詢,因為在底層設計上缺乏對向量查詢的有效支持。盡管可以通過添加功能來實現,但這可能變得笨拙且不夠便捷。
新興的向量數據庫可能更適應當前的需求,但它們可能會引入系統的復雜性。例如,客戶可能需要同時使用傳統數據庫、關系數據庫和向量數據庫,這會增加維護、成本和開銷。因此,我們需要找到一個良好的平衡點,一個系統既能滿足向量數據庫的要求,同時也能滿足傳統查詢功能的需求。找到這樣的組合是關鍵。作為客戶,如果能夠使用一個系統來高效地完成不同類型的功能,而不是選擇傳統系統再另外添加功能,維護成本和各種成本都會降低。
在這種情況下,我認為 Redis 可以很好地實現這種平衡。Redis 不僅是廣泛使用的應用,作為企業版,它還提供了完整的企業級應用生態系統,可以幫助客戶滿足各種需求。無論是向量搜索還是標量搜索,在 Redis 中都是以 key-value 的方式存儲在內存中,查詢效率都很高。此外,Redis 還具有強大的混合查詢功能,允許同時查詢向量和其他類型的數據,如文本、數值或 GPS 信息。這種原生的混合查詢功能使得 Redis 在向量數據庫領域具有顯著優勢,同時保持高性能。
AIGC 浪潮下,開發者該如何“武裝”自己?
InfoQ:作為一個在數據庫領域有多年經驗的老師,您認為現在程序員如果希望在 AI 和向量數據庫領域發展,需要掌握哪些關鍵技能呢?
史磊:當前技術的迭代速度極快,去年使用的產品和經驗可能在今年已經變得過時,或者新的技術已經涌現。在這種情況下,我認為首先我們需要更深入地了解現有系統。以 Redis 為例,大多數人可能知道它在緩存方面表現出色,但除此之外,Redis 在其他領域的應用可能并不為人所知。作為技術從業者,了解主流產品的底層架構和功能,以及它們能夠實現的功能非常重要。
我們需要不斷地更新知識,尤其是在向量數據庫和大模型等新興技術興起之后。作為技術人員,要積極擁抱新技術,深入了解它們的工作原理和應用場景。不是從已有技術跳躍到嶄新的技術,而是要利用自身積累的經驗,將新技術應用于現有的工作中。雖然這種技術轉換是存在成本的,但我們需要找到最有效的方法來將轉換成本降至最低,讓技術為我們服務,而不是成為技術的奴隸。這需要經驗、技術洞察力和不斷的探索精神來實現。
未來向量數據庫市場會正向地“卷”
InfoQ:老師的話確實給了我們很有價值的啟示。最后,我們可以探討一個廣泛受關注的話題,即向量數據庫未來的發展。當前,向量數據庫已經進入了熱門階段,許多相關技術也變得非常成熟,包括向量索引和傳統數據庫技術。然而,人們普遍關心的是,未來的發展將會走向何方,以及我們應該關注哪些趨勢?
史磊:根據我的個人觀點,結合我多年來在 AI 和大數據領域的經驗,以及對傳統數據庫的了解,我要說,幾年前我無法預料到數據庫領域能夠如此迅速地發展至今的程度。
在向量數據庫方面,我認為它的出現受到了強烈的驅動力,這種驅動力能夠快速淘汰那些不合適的技術,同時也會促使新技術的不斷涌現,這是一個逐步篩選的過程。從長遠來看,我堅信向量數據庫將不斷成熟,同時也會為不同的應用場景提供更加精準的向量搜索結果。
以一個簡單的例子來說明,我們可能需要實時、快速的搜索,也可能需要大規模特征搜索。在未來,這些需求可能會逐漸演變成不同的維度。我相信會有一些特定領域的向量數據庫逐漸嶄露頭角,可能會涌現出一兩個或者更多的適應特定場景的數據庫類型。每個類型可能會在特定的領域得到優化,這將是一個整合與優化的過程。
InfoQ:未來向量數據庫會不像傳統數據庫那樣,在國內涌現 200 多家出來?
史磊:我認為數據庫市場的持續擴張是不可避免的,這主要是因為技術的迭代速度非常快,同時技術門檻也在逐漸降低。當前存在著大量的需求,這將吸引越來越多的數據庫甚至向量數據庫加入競爭。然而,從業界角度看,這種市場擴張是有利的。它可以促使更多的技術和業務參與,盡管市場在一定范圍內會有限制,但這將在一場競爭中篩選出更優秀的技術和解決方案,以更好地滿足需求。
我希望看到更多競爭者涌現在這個領域,同時也期待看到哪些技術能夠經受住應用的考驗,證明自己在實踐中的可行性。對我而言,這種市場擴張應當是良性的。我們不希望看到惡性競爭,也不應該是通過貶低其他應用來凸顯自身的優越性。我認為這對于行業的生態是不利的。相反,我期待一種良性競爭,讓人們有更多優質的選擇,從而推動整個領域的進步。
-
數據庫
+關注
關注
7文章
3767瀏覽量
64280 -
OpenAI
+關注
關注
9文章
1045瀏覽量
6411 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507 -
AIGC
+關注
關注
1文章
357瀏覽量
1512
原文標題:ChatGPT 和 OpenAI 都在用的 Redis,是如何從傳統數據庫升級為向量數據庫的?
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

恒訊科技分析:云數據庫rds和redis區別是什么如何選擇?
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例

搭載英偉達GPU,全球領先的向量數據庫公司Zilliz發布Milvus2.4向量數據庫
選擇 KV 數據庫最重要的是什么?
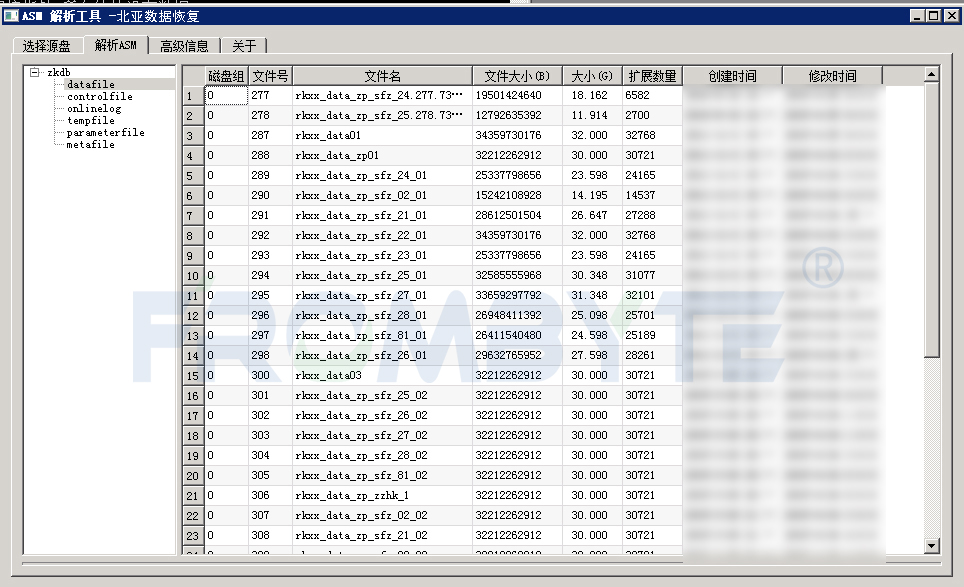
【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例
誠邀報名 | AI 向量、云原生、開源,今年的數據庫熱點技術都在這里
數據庫數據恢復—未開啟binlog的Mysql數據庫數據恢復案例
關于JSON數據庫

oracle數據庫的基本操作
redis是關系型數據庫嗎
什么是JSON數據庫






 工商網監
工商網監
評論